1. 问题引出及内容介绍
相信大家在学习与图像任务相关的神经网络时,经常会见到这样一个预处理方式。
self.to_tensor_norm = transforms.Compose([
transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])具体原理及作用稍后解释,不知道大家有没有想过,将这样一个经过改变的图像数据输入到网络中,那么输出的结果也是这种类似改动过的,那岂不是真实的数据了。
所以一般会有个后处理的代码,如下:
def tensor2img(img):
img = np.round((img.permute(0, 2, 3, 1).cpu().numpy() + 1)* 127.5)
img = img.clip(min=0, max=255).astype(np.uint8)
return img为什么这样就可以将改动过的数据恢复原样了,后处理的代码看着也不像预处理的逆过程啊。
先来分析一下代码,了解其处理过程,最后再推理出这两个互为逆过程。
2. 预处理
transforms.ToTensor()
transforms.ToTensor()是PyTorch中的一个图像转换方法,用于将PIL图像或numpy数组转换为PyTorch张量。具体来说,它会执行以下操作:
- 将图像或数组的数据类型从uint8(0-255)转换为float32(0.0-1.0)。
- 对图像进行标准化处理,即将像素值除以255,将其缩放到0到1之间。
- 如果输入是一个多通道的图像(例如RGB图像),它会重新排列通道,将通道维度放在第一个维度上。
下面是我翻译的源码的注释,包含了输入的要求:
torchvision.transforms.ToTensor 类用于将 PIL 图像或 numpy 数组转换为张量。这个转换不支持 torchscript。
将一个 PIL 图像或 numpy 数组(大小为 H x W x C,其中 H 表示高度,W 表示宽度,C 表示通道数)的像素值范围从 [0, 255] 转换为范围在 [0.0, 1.0] 的 torch.FloatTensor,其形状为 (C x H x W)。这种转换只有在以下情况下才会进行:
- 如果 PIL 图像的模式为(L、LA、P、I、F、RGB、YCbCr、RGBA、CMYK、1)之一。
- 如果 numpy 数组的数据类型为
np.uint8。(因为uint8的类型的取值范围是0-255)
在其他情况下,转换后的张量将不会进行缩放。
两者内容互为补充,相信足够理解这个代码了,如果不够理解,没事,我自己写个代码解释: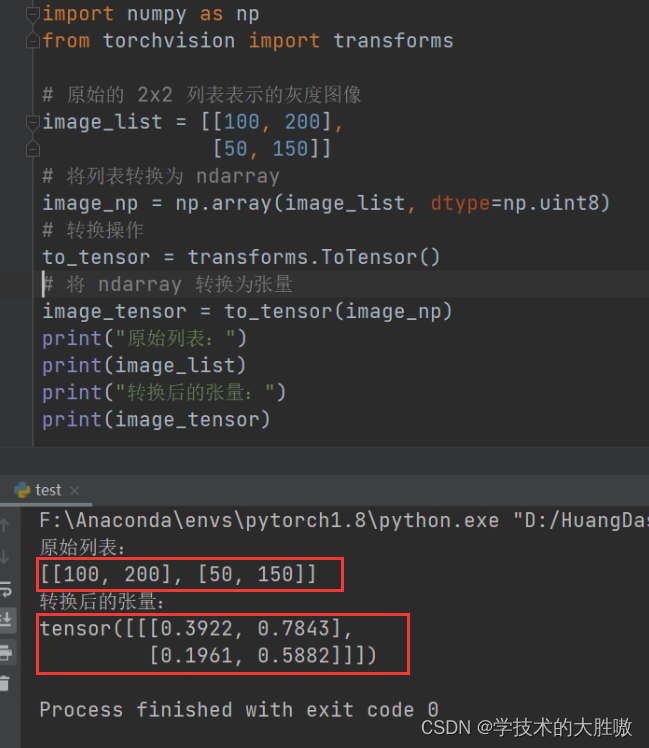
上述数值被分别除以255得到转换后的张量,现在应该有更直观的理解了。
transforms.Normalize()
transforms.Normalize()是PyTorch中的一个图像转换方法,用于对张量进行标准化处理。具体来说,它执行以下操作:
- 对每个通道进行均值归一化:将每个通道的像素值减去均值,以使每个通道的均值为0。
- 对每个通道进行标准差归一化:将每个通道的像素值除以标准差,以使每个通道的标准差为1。
在给定的示例中,(0.5, 0.5, 0.5)表示每个通道的均值,(0.5, 0.5, 0.5)表示每个通道的标准差。这个转换将图像的每个通道的像素值从0到1的范围,调整到-1到1的范围内。

上述的预处理的两个步骤可以概括为归一化或者标准化,为什么需要这两个步骤呢,我举例子加以说明
-
加速收敛:
- 例子:假设有一个深度神经网络,其输入是未经归一化的图像数据,像素值范围是0到255。如果使用简单的梯度下降法进行优化,由于像素值的范围很大,梯度更新可能会非常缓慢。通过将数据归一化到0到1之间,梯度更新将更加稳定,从而加快收敛速度。
-
提高模型性能:
- 例子:考虑一个用于手写数字识别的卷积神经网络(CNN)。如果输入图像的亮度差异很大,网络可能会对亮度较高的图像更加敏感。通过归一化亮度,网络可以更专注于识别数字的形状和结构,而不是亮度。
-
稳定性:
- 例子:在处理图像数据时,如果某些像素值异常高(例如,由于光照条件的变化),这可能会导致数值计算中的溢出问题。通过归一化,可以将这些极端值限制在一个较小的范围内,从而提高数值稳定性。
-
防止过拟合:
- 例子:在一个包含多种类型图像的数据集中,如果某些类型的图像具有更高的对比度,网络可能会偏向于学习这些特征,从而忽视其他类型的图像。通过归一化,可以减少这种偏差,使网络能够更均匀地学习所有类型的图像。
-
适应不同初始化:
- 例子:使用He初始化或Xavier初始化等方法为神经网络的权重赋予初始值时,这些方法通常假设输入数据已经被归一化。如果输入数据未经归一化,权重初始化的效果可能会大打折扣。
-
节省计算资源:
- 例子:在进行大规模图像处理时,如果输入数据未经归一化,那么在浮点数运算中可能会遇到数值溢出的问题,这需要使用更高精度的数据类型,从而增加计算资源的消耗。归一化可以减少这种情况的发生。
-
改善梯度下降的效率:
- 例子:在训练一个深度神经网络时,如果输入数据未经归一化,梯度可能会在某些方向上过大,在其他方向上过小。这会导致优化过程中的锯齿现象,使得找到全局最小值变得更加困难。归一化有助于平衡梯度的大小,使优化过程更加平滑。
3. 后处理
img = np.round((img.permute(0, 2, 3, 1).cpu().numpy() + 1)* 127.5)这行代码的作用是将PyTorch张量转换为numpy数组,并执行以下操作:
-
img.permute(0, 2, 3, 1):这一步是对张量的维度进行重新排列,将通道维度移到最后一个维度上。这通常是因为在PyTorch中,图像的通道维度是第二个维度,而在numpy数组中,通常是最后一个维度。所以这一步是为了将数据转换为numpy数组后,通道维度的顺序与numpy数组的约定相匹配。 -
.cpu().numpy():这一步将PyTorch张量移动到CPU上,并将其转换为numpy数组。通常,在GPU上进行计算后,需要将数据移回CPU上才能调用numpy方法。 -
+ 1:这一步将数组中的所有元素加1,将范围从[-1, 1]映射到[0, 2]。 -
* 127.5:这一步将数组中的所有元素乘以127.5,将范围从[0, 2]映射到[0, 255],将数据重新缩放到uint8范围内。 -
np.round():这一步对数组中的所有元素执行四舍五入操作,将浮点数转换为整数。
综合起来,这行代码的作用是将PyTorch张量(范围在[-1, 1]之间)转换为numpy数组,并将其值重新映射到uint8范围内(0-255),并将浮点数转换为整数。
img = img.clip(min=0, max=255).astype(np.uint8)这行代码的作用是确保numpy数组中的数值范围在0到255之间,并将其类型转换为无符号8位整数(uint8),以便表示图像像素值。
4. 推导逆过程
先把代码放一起进行比较
预处理:
self.to_tensor_norm = transforms.Compose([
transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
后处理:
def tensor2img(img):
img = np.round((img.permute(0, 2, 3, 1).cpu().numpy() + 1)* 127.5)
img = img.clip(min=0, max=255).astype(np.uint8)
return img下面是推导过程:
完结撒花!
不足之处还请大家指正。