背景:由于本人是用的Macbookpro m2来进行开发的,很多环境和Intel芯片的都不一样,期间安装各种软件遇到各种问题,为了以后不走之前的老路,现记录各种软件的安装步骤。
系统安装组件说明
| 序号 | 组件名称 | 组件版本 |
|---|---|---|
| 1 | jdk | jdk-8u361-linux-aarch64.tar.gz |
| 2 | zookeeper | apache-zookeeper-3.6.4-bin.tar.gz |
| 3 | kafka | kafka_2.13-3.6.2.tgz |
| 3 | flume | apache-flume-1.11.0-bin.tar.gz |
一、kafka的安装
下载地址:https://kafka.apache.org/downloads
1.在安装目录下解压
tar -zxvf kafka_2.13-3.6.2.tgz
2.新建一个日志目录,最好不用默认的路径
mkdir -p /usr/local/soft/kafka/kafka_2.13-3.6.2/log
2.进入config目录下,编辑配置文件server.properties中log.dirs为自己新建好的日志目录
log.dirs=/usr/local/soft/kafka/kafka_2.13-3.6.2/log
3.进入目录下,执行启动命令,最好是带着配置文件启动
启动命令
./kafka-server-start.sh ../config/server.properties
–执行kafka的启动命令
./kafka-server-start.sh …/config/server.properties
报错:
/usr/local/soft/kafka/kafka_2.13-3.6.2/bin/kafka-run-class.sh: 第 346 行:exec: java: 未找到
报错原因:没有找到jdk
解决方案:安装一个jdk,然后再启动命令,发现jdk的报错解决了
启动命令报错:
./kafka-server-start.sh …/config/server.properties
报错如下:
Error: VM option 'UseG1GC' is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions.
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
解决方案:
编辑bin/kafka-run-class.sh,删除-XX:+UseG1GC 这个地方,然后重启启动
然后报错如下;
[2024-04-18 22:22:54,936] WARN Session 0x0 for server localhost/127.0.0.1:2181, Closing socket connection. Attempting reconnect except it is a SessionExpiredException. (org.apache.zookeeper.ClientCnxn)
java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:715)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:344)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1289)
[2024-04-18 22:22:56,108] INFO Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. (org.apache.zookeeper.ClientCnxn)
[2024-04-18 22:22:56,110] WARN Session 0x0 for server localhost/0:0:0:0:0:0:0:1:2181, Closing socket connection. Attempting reconnect except it is a SessionExpiredException. (org.apache.zookeeper.ClientCnxn)
java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:715)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:344)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1289)
[2024-04-18 22:22:57,296] INFO Opening socket connection to server localhost/127.0.0.1:2181. (org.apache.zookeeper.ClientCnxn)
[2024-04-18 22:22:57,298] WARN Session 0x0 for server localhost/127.0.0.1:2181, Closing socket connection. Attempting reconnect except it is a SessionExpiredException. (org.apache.zookeeper.ClientCnxn)
java.net.ConnectException: 拒绝连接
仔细看上面的报错,没有连接上zookeeper,那就安装一个zookeeper试试,安装并且启动zookeeper后发现kafka正常启动了
[2024-04-19 12:07:44,008] ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.common.InconsistentClusterIdException: The Cluster ID zO_QpRQ_Sj2ba8vgKw2Ntw doesn't match stored clusterId Some(yBFG2q0yRqGofaIr5862_Q) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:244)
at kafka.Kafka$.main(Kafka.scala:113)
at kafka.Kafka.main(Kafka.scala)
[2024-04-19 12:07:44,009] INFO shutting down (kafka.server.KafkaServer)
[2024-04-19 12:07:44,011] INFO [ZooKeeperClient Kafka server] Closing. (kafka.zookeeper.ZooKeeperClient)
[2024-04-19 12:07:44,114] INFO Session: 0x100031457e00001 closed (org.apache.zookeeper.ZooKeeper)
[2024-04-19 12:07:44,114] INFO EventThread shut down for session: 0x100031457e00001 (org.apache.zookeeper.ClientCnxn)
[2024-04-19 12:07:44,115] INFO [ZooKeeperClient Kafka server] Closed. (kafka.zookeeper.ZooKeeperClient)
[2024-04-19 12:07:44,117] INFO App info kafka.server for 0 unregistered (org.apache.kafka.common.utils.AppInfoParser)
[2024-04-19 12:07:44,117] INFO shut down completed (kafka.server.KafkaServer)
[2024-04-19 12:07:44,118] ERROR Exiting Kafka due to fatal exception during startup. (kafka.Kafka$)
kafka.common.InconsistentClusterIdException: The Cluster ID zO_QpRQ_Sj2ba8vgKw2Ntw doesn't match stored clusterId Some(yBFG2q0yRqGofaIr5862_Q) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:244)
at kafka.Kafka$.main(Kafka.scala:113)
at kafka.Kafka.main(Kafka.scala)
[2024-04-19 12:07:44,118] INFO shutting down (kafka.server.KafkaServer)
报错原因:由于kafka重复启动或者非正常关闭造成的
解决方案:
方法一
在server.properties 配置文件里面 找到 log.dirs 配置的路径,在该路径下找到meta.properties文件,按照报错提示,将meta.properties文件里面的cluster.id修改为报错提示的Cluster ID,重新启动kafka。
方法二
在server.properties 配置文件里面 找到 log.dirs 配置的路径,将该路径下的文件全部删除,重新启动kafka。
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test_kafka
Exception in thread "main" joptsimple.UnrecognizedOptionException: zookeeper is not a recognized option
at joptsimple.OptionException.unrecognizedOption(OptionException.java:108)
at joptsimple.OptionParser.handleLongOptionToken(OptionParser.java:510)
at joptsimple.OptionParserState$2.handleArgument(OptionParserState.java:56)
at joptsimple.OptionParser.parse(OptionParser.java:396)
at kafka.admin.TopicCommand$TopicCommandOptions.<init>(TopicCommand.scala:558)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:49)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
报错原因:
因为kafka的版本是2.8+,不需要依赖zookeeper创建主题
改用命令 --bootstrap-server
./kafka-topics.sh --bootstrap-server localhost:9092 --create --replication-factor 1 --partitions 1 --topic test_kafka
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic test_kafka.
查看topic的命令
./kafka-topics.sh --bootstrap-server localhost:9092 --list
test_kafka
创建生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic test_kafka
创建消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_kafka -from-beginning
二、zookeeper的安装
1、zookeeper的下载
https://archive.apache.org/dist/zookeeper/zookeeper-3.6.4/
2、解压压缩包
tar -zxvf apache-zookeeper-3.6.4-bin.tar.gz
3、在解压后的目录下,创建一个文件夹zookeeper_data
mkdir -p /usr/local/soft/zookeeper/apache-zookeeper-3.6.4-bin/zookeeper_data
4、在config目录下,创建一个配置文件zoo.cfg
cp zoo_sample.cfg zoo.cfg
5、编辑配置文件zoo.cfg,将参数dataDir后面改为上面新创建的路径
dataDir=/usr/local/soft/zookeeper/apache-zookeeper-3.6.4-bin/zookeeper_data
6、在bin目录下,启动命令:
./zkServer.sh start
7、查看进程,验证zk是否正常启动了
jps
其实,启动kafka的试试,不一定非要用外部的zookeeper,也可以用他自带的,
./zookeeper-server-start.sh -daemon …/config/zookeeper.properties
三、flume的安装
1、flume的下载地址
https://flume.apache.org/download.html
我们一般下载二进制的就可以了

2、解压压缩包
命令如下:
tar -zxvf apache-flume-1.11.0-bin.tar.gz
3、在conf目录下新建一个文件,并且配置相关参数
新建文件的命令如下:
cp flume-env.sh.template flume-env.sh
编辑该文件
#修改 JM 配置
export JAVA_OPTS="-Xms4096m -Xmx4096m -Dcom.sun.management.jmxremote"
4、新建目录job,然后开始编辑配置文件(读取文件到kafka的配置文件)
新建的目录job
/usr/local/soft/flume/apache-flume-1.11.0-bin/job
编辑配置文件:vim file_to_kafka.conf
后面再补充flume的配置文件的参数详解
| 参数名称 | 详解 |
|---|---|
#定义组件
a1.sources = r1
a1.channels =c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
#日志(数据)文件
#a1.sources.rl.filegroups.f1=/opt/module/data/test.logal.sources.rl.positionFile =/opt/module/flume/taildir position.json
a1.sources.r1.filegroups.f1=/usr/local/soft/flume_to_kafka/test.log
a1.sources.r1.positionFile =/usr/local/soft/flume/taildir_position.json
#配置channel
#采用Kafka Channel,省去了Sink,提高了效率
#a1.channels.cl.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.cl,kafka,bootstrap,servers = kafka-broker1:9092,kafka-broker2:9092,kafka-broker3:9092
#a1.channels.cl.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.cl,kafka,bootstrap,servers = kafka-broker1:9092
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = xxxxx:9092
a1.channels.c1.kafka.topic = test_flume
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels =c1
5、新建数据文件的目录,如上面配置中的这个路径下
/usr/local/soft/flume_to_kafka/test.log
6、在bin目录下启动flume
./flume-ng agent -n a1 -c ../conf/ -f ../job/file_to_kafka.conf
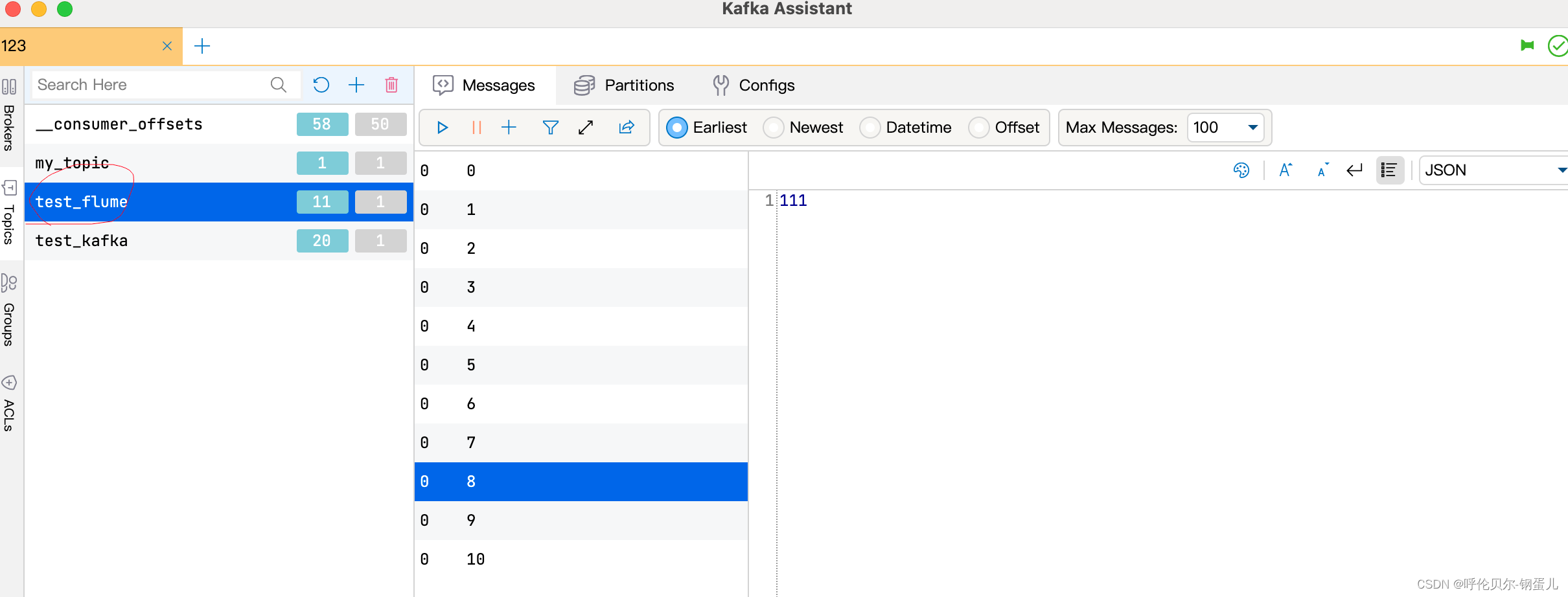
7、查看kafka中是否接收到了数据,在可视化客户端上
发现已经生成相应的topic和对应的数据了
三、flink的安装
在Java代码中引用flink做wordcount
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.0</version>
</dependency>
先创建一个可读取的TXT文件
hello world
hello wzx
hello flink
需要注意的是,这种代码的实现方式,是基于 DataSet API的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink1.12开始,官方推荐的做法是直接使用 DataStreamAPI,在提交任务时通过将执行模式设为BATCH来进行批处理:↔$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar<这样,DataSetAPI就没什么用了,在实际应用中我们只要维护一套 DataStream Ap! 就可以。这里只是为了方便大家理解,我们依然用 DataSetAPI做了批处理的实现。
package com.ruoyi.web.controller.soft.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author wuzhanxi
* @create 2024/4/22 21:44
*/
public class FlinkController {
//
public static void main(String[] args) throws Exception {
// 1.创建集群环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2.读取数据,从文件中读取
DataSource<String> lineDs = env.readTextFile("input/input.txt");
FlatMapOperator<String, Tuple2<String, Integer>> wordList = lineDs.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按照空格进行切分
String[] words = value.split(" ");
//
for (String word : words) {
Tuple2<String, Integer> wordTupe2 = Tuple2.of(word, 1);
//
collector.collect(wordTupe2);
}
}
});
// 3.切分、转换
// 4.按照单词分组
UnsortedGrouping<Tuple2<String, Integer>> wordgroup = wordList.groupBy(0);
// 5.各分组内聚合,这里的1是数值 1
AggregateOperator<Tuple2<String, Integer>> wordsum = wordgroup.sum(1);
// 6.输出
wordsum.print();
}
}
输出如下;
(wzx,1)
(flink,1)
(world,1)
(hello,3)