文章目录
- 1. LLM 预训练目的
- 1.1 什么是语言模型
- 2. Tokenizer一般处理流程(了解)
- 3. 进行 Tokenizer 的原因
- 3.1 one-hot 的问题
- 3.2 词嵌入
1. LLM 预训练目的
我们必须知道一个预训练目的:LLM 的预训练是为了建立语言模型。
1.1 什么是语言模型
预训练的语言模型通常是建立预测模型的,即预测下一个词的概率。
通常采用了基于自监督学习的方式进行预训练,其中最常见的方法之一是使用自回归模型。自回归模型的训练目标是根据输入的文本序列预测下一个词或字符。
给定一个文本序列
X
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
X = \{x_1, x_2, ..., x_n\}
X={x1,x2,...,xn},自回归模型的目标是最大化条件概率:
P
(
x
t
+
1
∣
x
1
,
x
2
,
.
.
.
,
x
t
)
P(x_{t+1} | x_1, x_2, ..., x_t)
P(xt+1∣x1,x2,...,xt)
其中 x t x_t xt 是输入序列中的第 t t t 个词或字符,而 x t + 1 x_{t+1} xt+1 是下一个要预测的词或字符。
在预训练阶段,通常使用了一种称为最大似然估计的方法,即通过最大化给定文本序列的条件概率来训练模型参数。因此,自回归模型的预训练目标可以表示为最大化以下似然函数:
max
θ
∑
t
=
1
n
−
1
log
P
(
x
t
+
1
∣
x
1
,
x
2
,
.
.
.
,
x
t
;
θ
)
\max_{\theta} \sum_{t=1}^{n-1} \log P(x_{t+1} | x_1, x_2, ..., x_t; \theta)
θmaxt=1∑n−1logP(xt+1∣x1,x2,...,xt;θ)
其中 θ \theta θ 是模型参数, log P ( x t + 1 ∣ x 1 , x 2 , . . . , x t ; θ ) \log P(x_{t+1} | x_1, x_2, ..., x_t; \theta) logP(xt+1∣x1,x2,...,xt;θ) 是给定模型参数 θ \theta θ 的条件概率的对数。
理解上面的内容非常重要!!
2. Tokenizer一般处理流程(了解)
LLM 的 Tokenizer 负责将原始文本转化为模型能够理解和处理的离散符号序列。以下是LLM Tokenizer 一般流程:
-
数据准备:
从已清洗的预训练数据集中选取适当样本,确保其语言丰富、多样且无明显噪声。 -
文本规范化:
(1)将文本转换为统一的字符集(如Unicode)。
(2)转换为小写(如果适用)。
(3)去除无关字符,如多余空白、制表符、换行符等。
(4)进行拼写校正(可选,取决于是否期望模型在训练时学习拼写变体)。
(5)对特定语言进行特定的规范化处理,如德语的连字符合并、汉语的简繁体转换等。 -
Tokenization:
(1)词汇级Tokenization(适用于某些模型):如果使用基于词汇表的Tokenization,直接按照预定义的词汇表将文本切分为单词或短语。
(2)Subword-level Tokenization(更常见于现代LLMs):使用如 WordPiece、Byte-Pair Encoding (BPE) 或 SentencePiece 等算法将文本分割成更细粒度的子词或子词序列。这些算法通过统计学方法自动生成词汇表,其中包含常见单词和代表罕见或未知词汇的子词组合,从而解决 OOV(Out-of-Vocabulary)问题。 -
Token ID映射:
(1)为每个生成的 token 分配一个唯一的整数ID。
(2)根据所选 Tokenization 方法构建词汇表(或子词表),其中每个 token 对应一个ID。
(3)将 Tokenized 文本序列转换为相应的整数序列(token IDs),作为模型输入。 -
特殊Token处理:
(1)添加特殊tokens,如开始符号[CLS]、结束符号[SEP](对于Transformer架构模型),以及可能的 padding token[PAD]和未知词 token[UNK]。
(2)开始和结束符号用于标识输入序列的边界,有助于模型理解上下文。
(3)未知词token用于表示词汇表中未出现但在实际应用中遇到的词汇。
(4)Padding token用于填充序列至固定长度,以便批量训练。 -
序列长度调整:
(1)根据模型的输入限制,对Token ID序列进行截断或填充,以保证所有输入序列具有相同的长度。
(2)选择合适的截断策略,如按长度截断、按比例截断或基于重要性评分的动态截断。 -
数据存储:
将Tokenized并映射为ID的文本数据存储为二进制文件(如.tfrecord、.bin或.hdf5),便于高效读取和训练。
那么我们需要进一步深入了解为什么需要 Tokenizer!
3. 进行 Tokenizer 的原因
3.1 one-hot 的问题
首先我们根据上面内容知道 LLM 预训练的目的是为了得到语言模型,即预测下一个词的概率。那么假设有一个文本:
开始和结束符号用于标识输入序列的边界,有助于模型理解上下文
我们假设采用的 seq_length = 5,即可以建立如下预测模型: 开始和结束 -> 符、始和结束符 -> 号 …
首先,计算机无法直接理解字符,我们需要将上面的字符转为计算机可以理解的数字,那么用什么方法呢?一种可行的方法是 one-hot,假设我们有一个字典包含 10 个字,那么开 假设表示为 [1,0,0,0,0,0,0,0,0,0],始 假设表示为 [0,1,0,0,0,0,0,0,0,0],直到把所有字表示出来。
这么做有没有什么问题呢?
(1)维度爆炸。当字典字数非常多时,one-hot 编码会导致特征空间的维度急剧增加。高维度数据不仅会占用大量的存储资源,而且可能导致计算复杂度增加,特别是在涉及到矩阵运算的模型(如线性回归、逻辑回归、支持向量机等)中,这可能会引发内存溢出问题,降低训练和预测的速度。
(2)稀疏性问题。one-hot 编码后的向量通常非常稀疏,即大部分元素为0。这种高度稀疏的表示方式可能不利于模型的学习,因为模型需要处理大量无信息的零值,降低了算法的效率。此外,某些算法(如基于梯度的优化方法)在处理稀疏数据时可能表现不佳。
(3)表达意义有限。目前 LLM 采用的模型一般都是 Transformer 模型,一个字是可以联系上下文,例如 使 这个字和 开 的关系比较紧密,可能达到 0.9,和其他字的关系可能只有 0.3。如果对于 one-hot 表示,那么无法表示上下文的这种关系。
3.2 词嵌入
那么我们如何将 one-hot 转为词嵌入矩阵呢?假设有一个 one-hot:
[
0
0
1
0
0
0
0
1
0
1
0
0
]
\begin{bmatrix} 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 1 & 0 & 0 \\ \end{bmatrix}
000001100010
我们看下面这张图的变换:
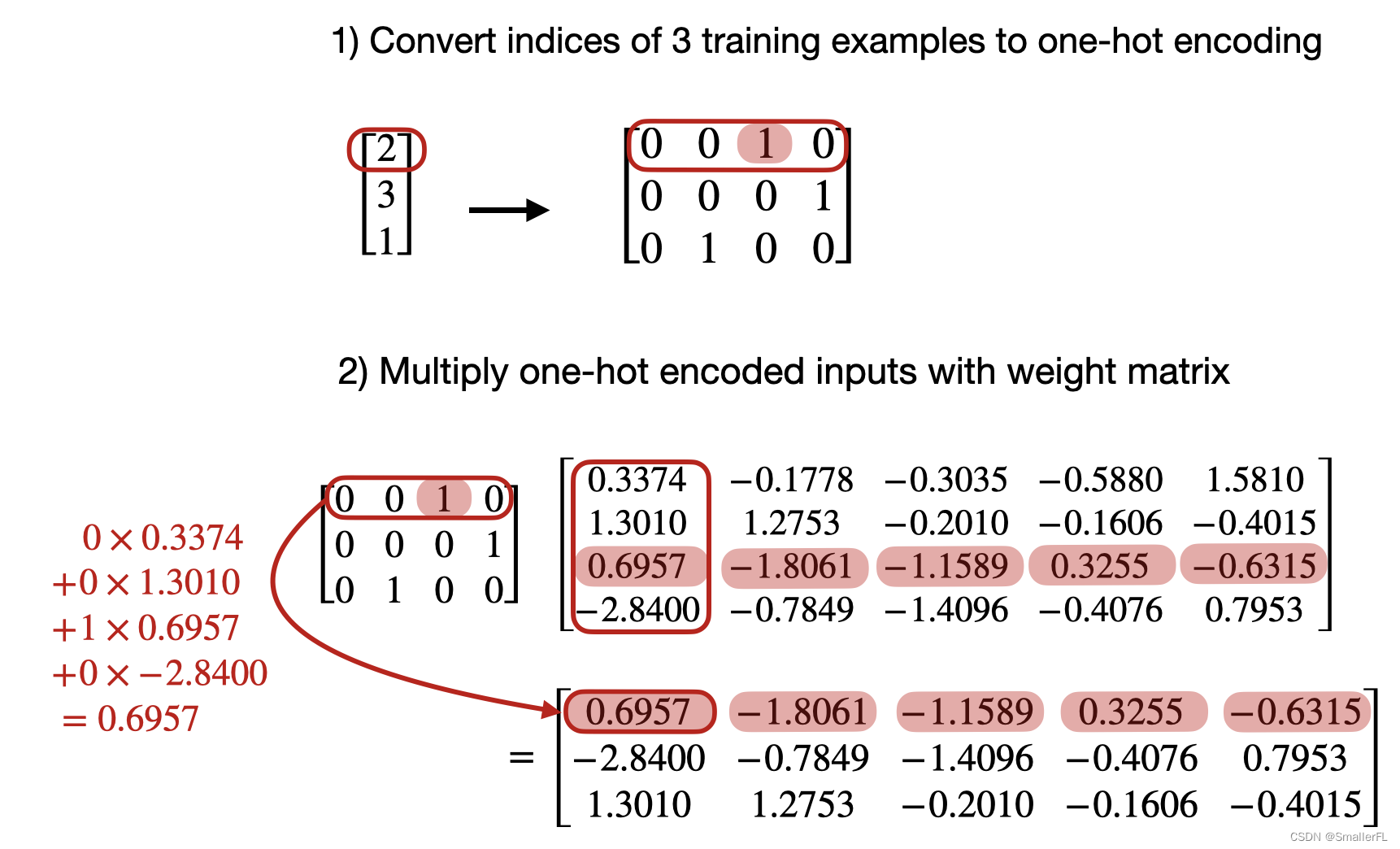
我们矩阵相乘一个权重系数,最后得到的结果就是词嵌入矩阵,这里的权重系数在 pytorch 中就是常见的:
embedding = torch.nn.Embedding(num_idx, out_dim)
embedding.weight
那么我们在训练中就可以反向传播不断对这个权重系数进行优化!词嵌入至少具备以下几个优点:
(1)更低的维度:
词嵌入通常将每个词映射到一个低维实数向量(如100维、300维甚至更高),远低于 one-hot 编码所需的维度(等于词汇表大小)。较低的维度不仅节省了存储空间,减少了计算资源消耗,还减轻了因维度增加导致的“维度灾难”,有利于模型的训练和泛化。
(2) 捕捉词义与语义关系:
词嵌入在训练过程中(如通过 Word2Vec、GloVe 或 BERT 等模型)学习到的向量不仅编码了词的个体特征,还能捕捉到词与词之间的语义关系。相似或相关的词在向量空间中的距离会很近,如“猫”和“狗”的嵌入向量可能比它们与“桌子”的嵌入向量更接近。这种关系性的表示使得模型能够理解词汇间的语义相似性、类比关系、上下位关系等,这对于自然语言处理任务至关重要。
(3)解决稀疏性问题:
与 one-hot 编码产生的极度稀疏向量不同,词嵌入向量通常是稠密的实数值向量。这种稠密表示保留了词汇的有用信息,避免了处理大量零值带来的效率损失,有利于模型学习和优化。同时,稠密向量在进行距离计算、相似度度量、聚类分析等操作时更为高效且更具解释性。
(4)平滑的连续空间:
词嵌入向量位于一个连续的向量空间中,这使得模型可以对词汇的含义进行平滑插值和运算。例如,可以通过简单的算术操作(如加减法)来探索词汇间的语义关系(如“国王 - 男人 + 女人 = 女王”),这是 one-hot 编码无法做到的。连续空间也为迁移学习、词义消歧、词汇扩展等任务提供了便利。
(5)适用于深度学习模型:
词嵌入是深度学习模型(如神经网络、循环神经网络、Transformer 等)处理自然语言文本的首选表示方式。它们可以直接作为输入层的输入,或者进一步通过嵌入层进行微调。词嵌入的低维、连续且富含语义信息的特性非常适合深度学习模型的层次化、非线性学习机制,能够有效提取和利用词汇的深层次语义特征。


![[GXYCTF2019]BabyUpload-BUUTF](https://img-blog.csdnimg.cn/direct/7584a3063b6c427ab63961ce5d01bf15.png)