在深度学习的实际应用中,很少会去从头训练一个网络,尤其是当没有大量数据的时候。即便拥有大量数据,从头训练一个网络也很耗时,因为在大数据集上所构建的网络通常模型参数量很大,训练成本大。所以在构建深度学习应用时,通常会使用预训练模型
需求
训练一个模型来分类蚂蚁ants和蜜蜂bees
步骤
- 加载数据集
- 编写函数(训练并寻找最优模型)
- 编写函数(查看模型效果)
- 使用torchvision微调模型
- 使用tensorboard可视化训练情况
Pytorch保存和加载模型的两种方式
1.完整保存模型、加载模型
torch.save(net, 'mnist.pth')net = torch.load('mnist.pth', 'map_location="cpu"')
# # Model class must be defined somewhereload() 默认会将该张量加载到保存时所在的设备上,map_location 可以强制加载到指定的设备上
2. 保存、加载模型的状态字典(模型中的参数)
torch.save(model.state_dict(), PATH)model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))迁移学习全过程
1.加载数据集
ants和bees各有约120张训练图片。
每个类有75张验证图片,从零开始在 如此小的数据集上进行训练通常是很难泛化的。
由于我们使用迁移学习,模型的泛化能力会相当好。
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
cudnn.benchmark = True
plt.ion()lr_scheduler:学习率调度器,用于在训练过程中动态调整学习率
torch.backends.cudnn.benchmark = True:大部分情况下,设置这个 flag 可以让内置的 cuDNN 的 auto-tuner 自动寻找最适合当前配置的高效算法,从而加速运算
plt.ion():这允许你在一个交互式环境中运行matplotlib
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}transforms.RandomResizedCrop(224):随机大小裁剪和缩放图像,使得裁剪后的图像尺寸为224x224像素。这个操作有助于模型学习不同尺度和长宽比的图像特征,从而提高模型的泛化能力。
transforms.RandomHorizontalFlip():以一定的概率(默认为0.5)对图像进行水平翻转。这也是一种数据增强技术,有助于模型学习对称性
transforms.Resize(256):将图像缩放到256x256像素
transforms.CenterCrop(224):从图像的中心裁剪出224x224像素的区域。这种裁剪方式确保每次裁剪的都是图像的中心部分,有助于在验证或测试时获得更一致的结果
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")可视化数据
def imshow(inp, title=None):
# 可视化一组 Tensor 的图片
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # 暂停一会儿,为了将图片显示出来
# 获取一批训练数据
inputs, classes = next(iter(dataloaders['train']))
# 批量制作网格
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes]) 
2.编写函数(训练并寻找最优模型)
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
"""
训练模型,并返回在验证集上的最佳模型和准确率
- criterion: 损失函数
Return:
- model(nn.Module): 最佳模型
- best_acc(float): 最佳准确率
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# 训练集和验证集交替进行前向传播
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# 遍历数据集
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 清空梯度,避免累加了上一次的梯度
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
# 正向传播
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 反向传播且仅在训练阶段进行优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计loss、准确率
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
""" 训练模型,并返回在验证集上的最佳模型和准确率
Args:
- model(nn.Module): 要训练的模型
- criterion: 损失函数
- optimizer(optim.Optimizer): 优化器
- scheduler: 学习率调度器
- num_epochs(int): 最大 epoch 数
Return:
- model(nn.Module): 最佳模型
- best_acc(float): 最佳准确率
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# 训练集和验证集交替进行前向传播
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置为训练模式,可以更新网络参数
else:
model.eval() # 设置为预估模式,不可更新网络参数
running_loss = 0.0
running_corrects = 0
# 遍历数据集
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 清空梯度,避免累加了上一次的梯度
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
# 正向传播
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 反向传播且仅在训练阶段进行优化
if phase == 'train':
loss.backward() # 反向传播
optimizer.step()
# 统计loss、准确率
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 发现了更优的模型,记录起来
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
# 加载训练的最好的模型
model.load_state_dict(best_model_wts)
return model
3.编写函数(查看模型效果)
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)4.使用torchvision微调模型
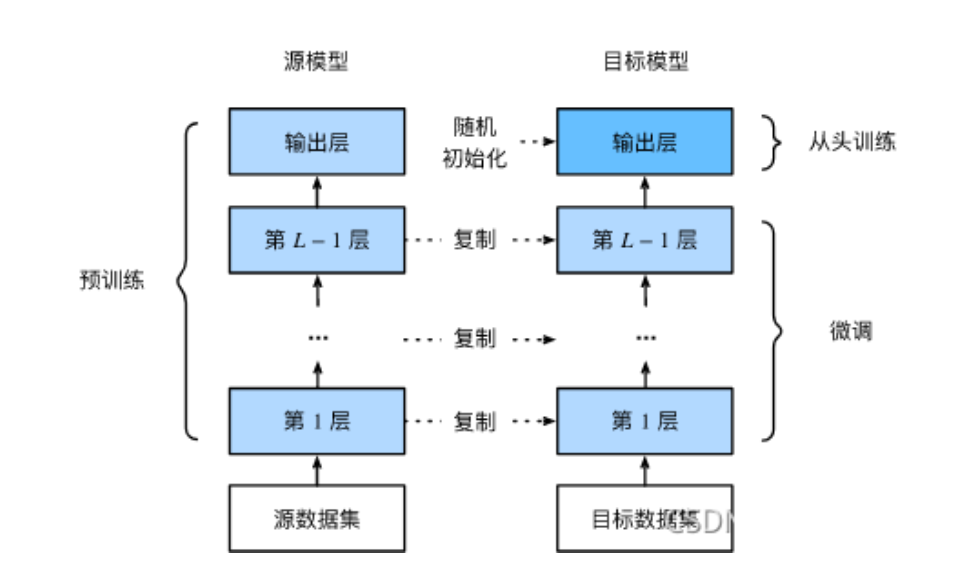
加载预训练模型,并将最后一个全连接层重置
model = models.resnet18(pretrained=True) # 加载预训练模型
num_ftrs = model.fc.in_features # 获取低级特征维度
model.fc = nn.Linear(num_ftrs, 2) # 替换新的输出层
model = model.to(device)
criterion = nn.CrossEntropyLoss()
# 所有参数都参加训练
optimizer_ft = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 每过 7 个 epoch 将学习率变为原来的 0.1
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)训练
model_ft = train_model(model, criterion, optimizer_ft, scheduler, num_epochs=3)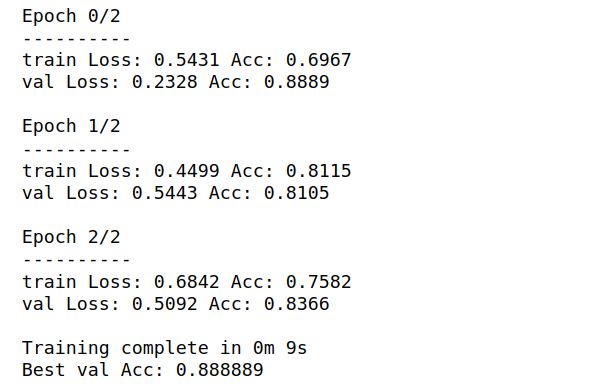
预估
visualize_model(model_ft)





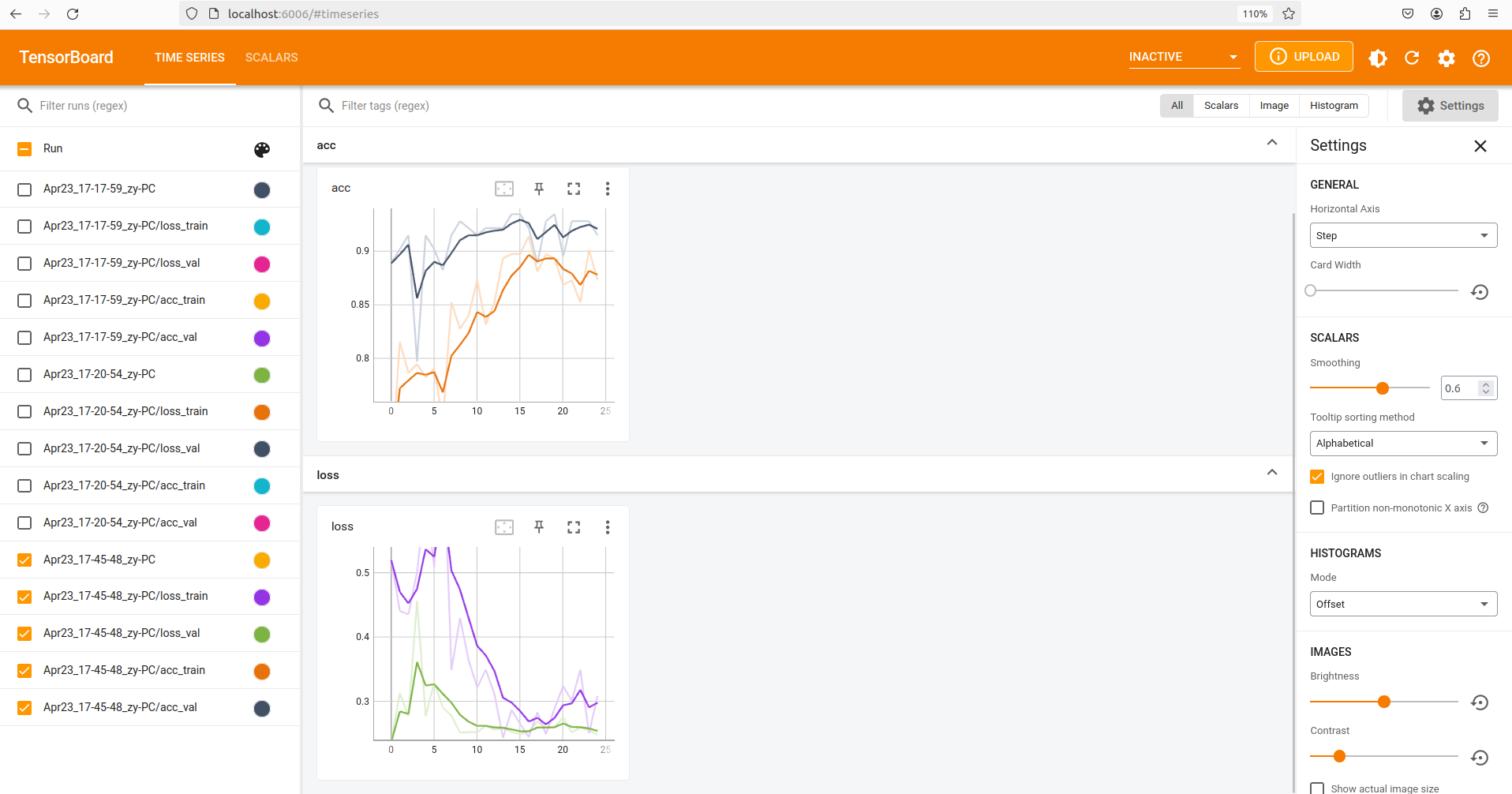
5.使用tensorboard可视化训练情况
将以下代码块合理的加入到训练模块里
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
ep_losses, ep_acces = [], []
ep_losses.append(epoch_loss)
ep_acces.append(epoch_acc.item())
writer.add_scalars('loss', {'train': ep_losses[-2], 'val': ep_losses[-1]}, global_step=epoch)
writer.add_scalars('acc', {'train': ep_acces[-2], 'val': ep_acces[-1]}, global_step=epoch)
writer.close()运行命令启动tensorboard
tensorboard --logdir runs可以通过执行命令的终端看到tensorboard可视化页面地址,且该命令会在执行该命令的目录下生成一个runs文件夹(日志文件的保存位置)
以下是我训练了25个epochs的acc和loss的动态图,