前言
之前写了一篇博文,介绍了mybatis的解析过程,其中mapper标签只演示了如何使用,这篇博文我们来探究mapper标签解析流程
源码解析
核心方法入口



引入mapper方式
- 使用相对于类路径的资源引用
- 使用完全限定资源定位符(URL)
- 使用映射器接口实现类的完全限定类名
- 将包内的映射器接口实现全部注册为映射器
使用相对于类路径的资源引用
<mappers>
<mapper resource="mapper/OrderMapper.xml"/>
<mapper resource="mapper/EmployeeMapper.xml"/>
</mappers>使用完全限定资源定位符(URL)
<mappers>
<mapper url="file:///var/mappers/OrderMapper.xml"/>
<mapper url="file:///var/mappers/EmployeeMapper.xml"/>
</mappers>使用映射器接口实现类的完全限定类名
<mappers>
<mapper class="com.ys.mybatis.mapper.OrderMapper"/>
<mapper class="com.ys.mybatis.mapper.EmployeeMapper"/>
</mappers>将包内的映射器接口实现全部注册为映射器
<mappers>
<package name="com.ys.mybatis.mapper"/>
</mappers>
package和class的引入方式最终会调用Configuration的addMapper()方法,url和resource的引入方式最终会调用XMLMapperBuilder的parse()方法
解析xml文件
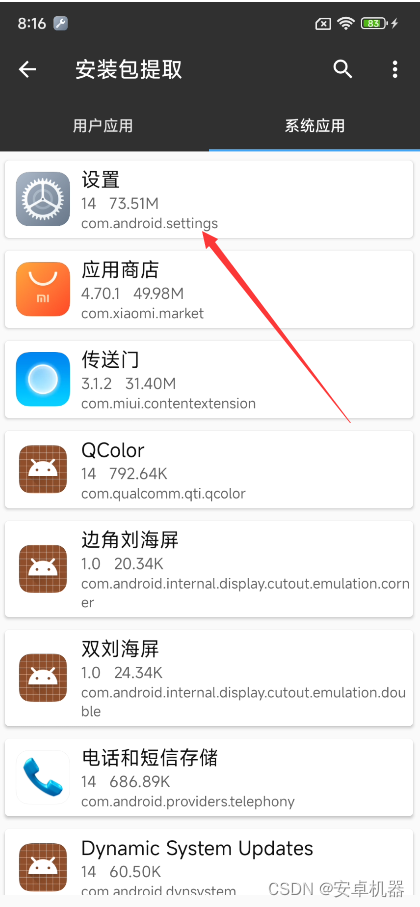
parse方法总览
public void parse() {
// 如果资源已经解析过则不再处理
if (!configuration.isResourceLoaded(resource)) {
// 解析mapper标签
configurationElement(parser.evalNode("/mapper"));
// 表示该资源已经解析过
configuration.addLoadedResource(resource);
// 尝试从xml文件指定的namespace,去解析java文件
// PS:相当于调用addMapper方法
bindMapperForNamespace();
}
// 再次解析resultMap
parsePendingResultMaps();
// 再次解析cache-ref(第一次解析时,引用的缓存可能还未解析)
parsePendingCacheRefs();
// 再次解析select | insert | update | delete
// cache-ref解析失败,MappedStatement也会解析失败,因为MappedStatement需要设置cache属性
parsePendingStatements();
}解析mapper标签
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}解析cache-ref
引用另外一个命名空间的缓存以供使用,如果指定命名空间的缓存不存在,则将cacheRefResolver加入到incompleteCacheRefs集合中(引用的缓存可能还没有解析)
解析cache
private void cacheElement(XNode context) {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}type : 缓存类型。默认PerpetualCache
eviction : 清除策略。默认的清除策略是 LRU
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
flushInterval : 刷新间隔。属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size : 引用数目 。属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly : 只读,属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
blocking : 是否阻塞,默认false。阻塞的情况下,如果一个sqlSession获取指定cacheKey的二级缓存为null时,在其实时查询数据、填充缓存之前,如果有其他sqlSession也尝试获取该cacheKey的二级缓存,则该sqlSession将处于blocking状态,直到上一个sqlSession将缓存填充完毕
解析parameterMap
用于引用外部 parameterMap 的属性,目前已被废弃。
解析resultMap
标签结构
- constructor - 用于在实例化类时,注入结果到构造方法中
- idArg - ID 参数;标记出作为 ID 的结果可以帮助提高整体性能
- arg - 将被注入到构造方法的一个普通结果
- id – 一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能
- result – 注入到字段或 JavaBean 属性的普通结果
- association – 一个复杂类型的关联;许多结果将包装成这种类型
- 嵌套结果映射 – 关联可以是 resultMap 元素,或是对其它结果映射的引用
- collection – 一个复杂类型的集合
- 嵌套结果映射 – 集合可以是 resultMap 元素,或是对其它结果映射的引用
- discriminator – 使用结果值来决定使用哪个 resultMap
- case – 基于某些值的结果映射
- 嵌套结果映射 – case 也是一个结果映射,因此具有相同的结构和元素;或者引用其它的结果映射
- case – 基于某些值的结果映射
ResultMap可谓是十分复杂,我们主要举个例子来演示用法。假设有这样一个场景,一篇博客有两个作者(第一作者和第二作者),有多个评论,然后博客有一个标签 (label),根据标签的值,显示不同的内容。显示内容明细如下:
- 0 : 基础信息
- 1 : 基础信息 + 阅读数
- 2 : 基础信息 + 阅读数 + 点赞数
创建ParseMapper.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ys.mybatis.mapper.ParseMapper">
<resultMap id="blogMap" type="com.ys.mybatis.parse.Blog">
<constructor>
<idArg name="id" column="id"/>
<arg name="title" column="title"/>
</constructor>
<result property="label" column="label" />
<association property="leaderAuthor" javaType="com.ys.mybatis.parse.Author" columnPrefix="lead_author_">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="email" column="email"/>
</association>
<association property="secondAuthor" javaType="com.ys.mybatis.parse.Author" columnPrefix="second_author_">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="email" column="email"/>
</association>
<collection property="comments" ofType="com.ys.mybatis.parse.Comment" >
<result property="blogId" column="blog_id"/>
<result property="content" column="content"/>
</collection>
<discriminator javaType="int" column="label">
<case value="1" resultType="com.ys.mybatis.parse.OrdinaryBlog">
<result property="readCount" column="read_count"/>
</case>
<case value="2" resultType="com.ys.mybatis.parse.ExcellentBlog">
<result property="likeCount" column="like_count"/>
<result property="readCount" column="read_count"/>
</case>
</discriminator>
</resultMap>
<select id="getBlogById" resultMap="blogMap">
select
b.id,
b.title,
b.label,
b.read_count,
b.like_count,
a1.id as lead_author_id,
a1.`name` as lead_author_name,
a1.age as lead_author_age,
a1.email as lead_author_email,
a2.id as second_author_id,
a2.`name` as second_author_name,
a2.age as second_author_age,
a2.email as second_author_email,
c.blog_id,
c.content
from blog b
left join author a1 on a1.id = b.lead_author_id
left join author a2 on a2.id = b.second_author_id
left join `comment` c on c.blog_id = b.id
where b.id = 1
</select>
</mapper>创建实体类
@Data
public class Blog {
private Integer id;
private String title;
private Author leaderAuthor;
private Author secondAuthor;
private List<Comment> comments;
private Integer label;
public Blog() {
}
public Blog(@Param("id") Integer id, @Param("title") String title) {
this.id = id;
this.title = title;
}
}
@Data
public class OrdinaryBlog extends Blog {
private Integer readCount;
public OrdinaryBlog() {
}
public OrdinaryBlog(@Param("id") Integer id, @Param("title") String title) {
super(id, title);
}
}
@Data
public class ExcellentBlog extends Blog {
private Integer readCount;
private Integer likeCount;
public ExcellentBlog() {
}
public ExcellentBlog(@Param("id") Integer id, @Param("title") String title) {
super(id, title);
}
}
@Data
public class Author {
private Integer id;
private Integer age;
private String name;
private String email;
}
@Data
public class Comment {
private Integer blogId;
private String content;
}
测试类ParseTest
public class ParseTest {
private SqlSessionFactory sqlSessionFactory;
@BeforeEach
public void parse() {
InputStream inputStream = ConfigurationTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
sqlSessionFactory = sqlSessionFactoryBuilder.build(inputStream);
}
@Test
public void getBlogById() {
SqlSession sqlSession = sqlSessionFactory.openSession();
ParseMapper mapper = sqlSession.getMapper(ParseMapper.class);
Blog blog = mapper.getBlogById(1);
System.out.println(blog);
}
}label = 0

返回基础信息 类型是Blog
label = 1

返回基础信息 + 阅读数 类型是OrdinaryBlog
label = 2

返回基础信息 + 阅读数 + 点赞数 类型是ExcellentBlog
PS : 如果使用了constructor标签,即表示以指定的构造器实例化对象,构造方法的参数需要添加@Param注解。如果指定了id(或idArg),表示以指定字段分组,类似于lambda表达式的groupBy,id (idArg)相同的,属于同一个博客
解析sql
这个元素可以用来定义可重用的 SQL 代码片段,以便在其它语句中使用。 参数可以静态地(在加载的时候)确定下来,并且可以在不同的 include 元素中定义不同的参数值。比如:
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>这个 SQL 片段可以在其它语句中使用,例如:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>也可以在 include 元素的 refid 属性或内部语句中使用属性值,例如:
<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>解析 select | insert | update | delete
select、insert、update、delete会根据我们设置的参数构建成一个MappedStatement对象。有几个参数我们需要注意一下。
useCache : select默认true,insert、update、delete默认false
flushCache : select默认false,insert、update、delete默认true
StatementType : 默认StatementType.PREPARED
KeyGenerator解析 : Mybatis之KeyGenerator
SqlSource解析 : Mybatis之SqlNode&SqlSource
解析Mapper文件
Mapper文件的解析和xml类似,不过多赘述。注解和标签对照表如下:
| 注解 | 使用对象 | XML 等价形式 | 描述 |
|---|---|---|---|
| @CacheNamespace | 类 | <cache> | 为给定的命名空间(比如类)配置缓存。属性:implemetation、eviction、flushInterval、size、readWrite、blocking、properties。 |
| @Property | N/A | <property> | 指定参数值或占位符(placeholder)(该占位符能被 mybatis-config.xml 内的配置属性替换)。属性:name、value。(仅在 MyBatis 3.4.2 以上可用) |
| @CacheNamespaceRef | 类 | <cacheRef> | 引用另外一个命名空间的缓存以供使用。注意,即使共享相同的全限定类名,在 XML 映射文件中声明的缓存仍被识别为一个独立的命名空间。属性:value、name。如果你使用了这个注解,你应设置 value 或者 name 属性的其中一个。value 属性用于指定能够表示该命名空间的 Java 类型(命名空间名就是该 Java 类型的全限定类名),name 属性(这个属性仅在 MyBatis 3.4.2 以上可用)则直接指定了命名空间的名字。 |
| @ConstructorArgs | 方法 | <constructor> | 收集一组结果以传递给一个结果对象的构造方法。属性:value,它是一个 Arg 数组。 |
| @Arg | N/A |
| ConstructorArgs 集合的一部分,代表一个构造方法参数。属性:id、column、javaType、jdbcType、typeHandler、select、resultMap。id 属性和 XML 元素 <idArg> 相似,它是一个布尔值,表示该属性是否用于唯一标识和比较对象。从版本 3.5.4 开始,该注解变为可重复注解。 |
| @TypeDiscriminator | 方法 | <discriminator> | 决定使用何种结果映射的一组取值(case)。属性:column、javaType、jdbcType、typeHandler、cases。cases 属性是一个 Case 的数组。 |
| @Case | N/A | <case> | 表示某个值的一个取值以及该取值对应的映射。属性:value、type、results。results 属性是一个 Results 的数组,因此这个注解实际上和 ResultMap 很相似,由下面的 Results 注解指定。 |
| @Results | 方法 | <resultMap> | 一组结果映射,指定了对某个特定结果列,映射到某个属性或字段的方式。属性:value、id。value 属性是一个 Result 注解的数组。而 id 属性则是结果映射的名称。从版本 3.5.4 开始,该注解变为可重复注解。 |
| @Result | N/A |
| 在列和属性或字段之间的单个结果映射。属性:id、column、javaType、jdbcType、typeHandler、one、many。id 属性和 XML 元素 <id> 相似,它是一个布尔值,表示该属性是否用于唯一标识和比较对象。one 属性是一个关联,和 <association> 类似,而 many 属性则是集合关联,和 <collection> 类似。这样命名是为了避免产生名称冲突。 |
| @One | N/A | <association> | 复杂类型的单个属性映射。属性:select,指定可加载合适类型实例的映射语句(也就是映射器方法)全限定名;fetchType,指定在该映射中覆盖全局配置参数 lazyLoadingEnabled。提示 注解 API 不支持联合映射。这是由于 Java 注解不允许产生循环引用。 |
| @Many | N/A | <collection> | 复杂类型的集合属性映射。属性:select,指定可加载合适类型实例集合的映射语句(也就是映射器方法)全限定名;fetchType,指定在该映射中覆盖全局配置参数 lazyLoadingEnabled。提示 注解 API 不支持联合映射。这是由于 Java 注解不允许产生循环引用。 |
| @MapKey | 方法 | 供返回值为 Map 的方法使用的注解。它使用对象的某个属性作为 key,将对象 List 转化为 Map。属性:value,指定作为 Map 的 key 值的对象属性名。 | |
| @Options | 方法 | 映射语句的属性 | 该注解允许你指定大部分开关和配置选项,它们通常在映射语句上作为属性出现。与在注解上提供大量的属性相比,Options 注解提供了一致、清晰的方式来指定选项。属性:useCache=true、flushCache=FlushCachePolicy.DEFAULT、resultSetType=DEFAULT、statementType=PREPARED、fetchSize=-1、timeout=-1、useGeneratedKeys=false、keyProperty=""、keyColumn=""、resultSets=""。注意,Java 注解无法指定 null 值。因此,一旦你使用了 Options 注解,你的语句就会被上述属性的默认值所影响。要注意避免默认值带来的非预期行为。 注意:keyColumn 属性只在某些数据库中有效(如 Oracle、PostgreSQL 等)。要了解更多关于 keyColumn 和 keyProperty 可选值信息,请查看“insert, update 和 delete”一节。 |
| 方法 |
| 每个注解分别代表将会被执行的 SQL 语句。它们用字符串数组(或单个字符串)作为参数。如果传递的是字符串数组,字符串数组会被连接成单个完整的字符串,每个字符串之间加入一个空格。这有效地避免了用 Java 代码构建 SQL 语句时产生的“丢失空格”问题。当然,你也可以提前手动连接好字符串。属性:value,指定用来组成单个 SQL 语句的字符串数组。 |
| 方法 |
| 允许构建动态 SQL。这些备选的 SQL 注解允许你指定返回 SQL 语句的类和方法,以供运行时执行。(从 MyBatis 3.4.6 开始,可以使用 CharSequence 代替 String 来作为返回类型)。当执行映射语句时,MyBatis 会实例化注解指定的类,并调用注解指定的方法。你可以通过 ProviderContext 传递映射方法接收到的参数、"Mapper interface type" 和 "Mapper method"(仅在 MyBatis 3.4.5 以上支持)作为参数。(MyBatis 3.4 以上支持传入多个参数)属性:type、method。type 属性用于指定类名。method 用于指定该类的方法名(从版本 3.5.1 开始,可以省略 method 属性,MyBatis 将会使用 ProviderMethodResolver 接口解析方法的具体实现。如果解析失败,MyBatis 将会使用名为 provideSql 的降级实现)。提示 接下来的“SQL 语句构建器”一章将会讨论该话题,以帮助你以更清晰、更便于阅读的方式构建动态 SQL。 |
| @Param | 参数 | N/A | 如果你的映射方法接受多个参数,就可以使用这个注解自定义每个参数的名字。否则在默认情况下,除 RowBounds 以外的参数会以 "param" 加参数位置被命名。例如 #{param1}, #{param2}。如果使用了 @Param("person"),参数就会被命名为 #{person}。 |
| @SelectKey | 方法 | <selectKey> | 这个注解的功能与 <selectKey> 标签完全一致。该注解只能在 @Insert 或 @InsertProvider 或 @Update 或 @UpdateProvider 标注的方法上使用,否则将会被忽略。如果标注了 @SelectKey 注解,MyBatis 将会忽略掉由 @Options 注解所设置的生成主键或设置(configuration)属性。属性:statement 以字符串数组形式指定将会被执行的 SQL 语句,keyProperty 指定作为参数传入的对象对应属性的名称,该属性将会更新成新的值,before 可以指定为 true 或 false 以指明 SQL 语句应被在插入语句的之前还是之后执行。resultType 则指定 keyProperty 的 Java 类型。statementType 则用于选择语句类型,可以选择 STATEMENT、PREPARED 或 CALLABLE 之一,它们分别对应于 Statement、PreparedStatement 和 CallableStatement。默认值是 PREPARED。 |
| @ResultMap | 方法 | N/A | 这个注解为 @Select 或者 @SelectProvider 注解指定 XML 映射中 <resultMap> 元素的 id。这使得注解的 select 可以复用已在 XML 中定义的 ResultMap。如果标注的 select 注解中存在 @Results 或者 @ConstructorArgs 注解,这两个注解将被此注解覆盖。 |
| @ResultType | 方法 | N/A | 在使用了结果处理器的情况下,需要使用此注解。由于此时的返回类型为 void,所以 Mybatis 需要有一种方法来判断每一行返回的对象类型。如果在 XML 有对应的结果映射,请使用 @ResultMap 注解。如果结果类型在 XML 的 <select> 元素中指定了,就不需要使用其它注解了。否则就需要使用此注解。比如,如果一个标注了 @Select 的方法想要使用结果处理器,那么它的返回类型必须是 void,并且必须使用这个注解(或者 @ResultMap)。这个注解仅在方法返回类型是 void 的情况下生效。 |
| @Flush | 方法 | N/A | 如果使用了这个注解,定义在 Mapper 接口中的方法就能够调用 SqlSession#flushStatements() 方法。(Mybatis 3.3 以上可用) |
整体解析流程
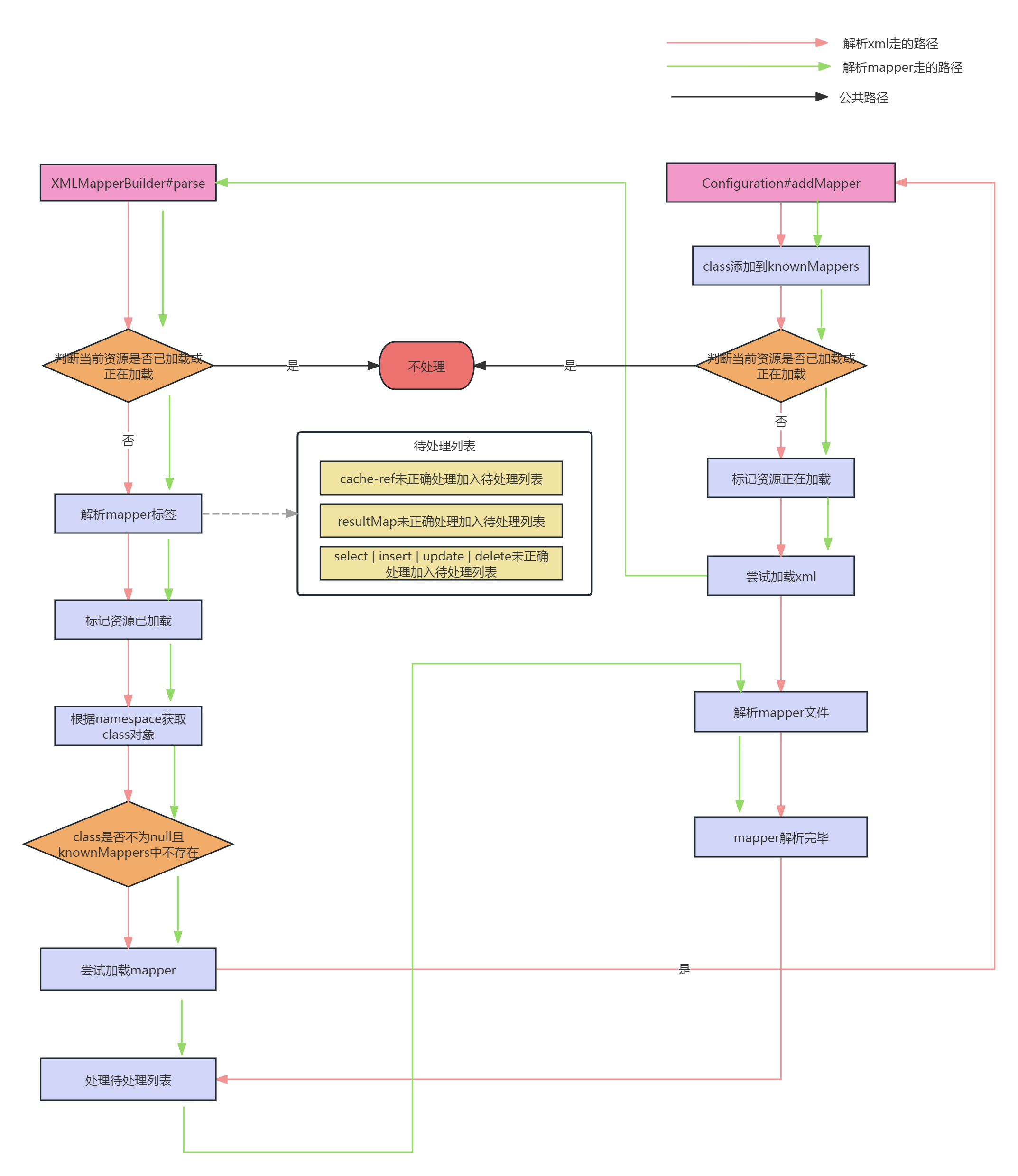
注意点
1.不管是先执行XMLMapperBuilder的parse方法,还是先执行Configuration的addMapper方法,源码都是会优先解析xml。如果已加载的资源是xxx.xml和interface com.xxx.xx.Mapper,则方法入口是XMLMapperBuilder的parse方法,如果已加载的资源是xxx.xml和namespace com.xxx.xx.Mapper,则方法入口是Configuration的addMapper方法。
2.如果方法入口是Configuration的addMapper方法,则xml解析产生的待处理列表,再次执行可能还处理不了(需要等java文件解析完,才可以处理,但是当前未到java文件的解析阶段),需要等到执行SQL的时候调用Configuration的buildAllStatements()方法来再次处理
3.<cache/>标签只能保证xml中的查询语句使用二级缓存,@CacheNamespace注解只能保证java中的查询语句使用二级缓存。如果java和xml都存在查询语句,并且都想使用二级缓存,则必须使用 <cache/> + @CacheNamespaceRef(name = "类的全限定名)或者 <cache-ref namespace="类的全限定名"/> + @CacheNamespace的形式


![[计算机效率] 网站推荐:文字转语音](https://img-blog.csdnimg.cn/direct/552909efef79459b9dfd2dd62cc92280.png)



![[SWPUCTF 2022 新生赛]ez_ez_unserialize](https://img-blog.csdnimg.cn/direct/1ddd06a2f8924002b33be8f1bd004d13.png)