1. OpenCompass简介
1.1 基本介绍
大模型开源开放评测体系 “司南” (OpenCompass2.0)由上海人工智能实验室科学家团队发布,用于为大语言模型、多模态模型等提供一站式评测服务。其主要特点如下:
开源可复现:提供公平、公开、可复现的大模型评测方案
全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
1.2 工具架构
下图为OpenCompass的整体架构图:
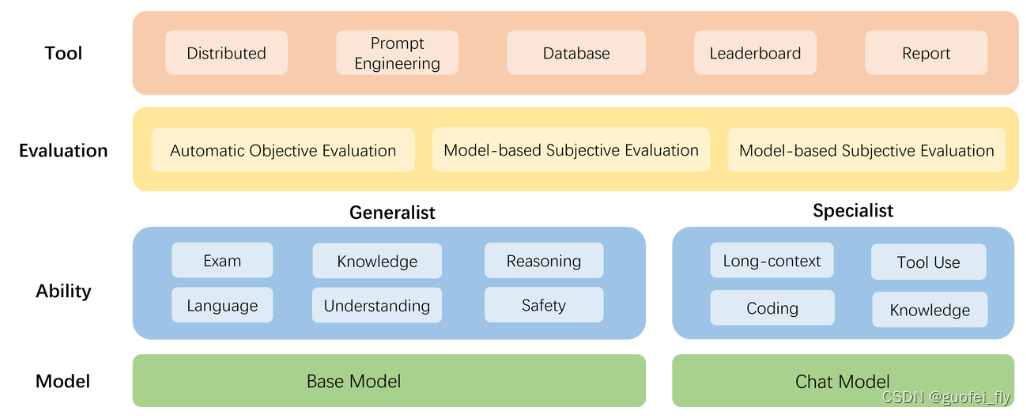
模型层:大模型评测所涉及的主要模型种类,OpenCompass 以基座模型和对话模型作为重点评测对象。
能力层:OpenCompass 从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
方法层:OpenCompass 采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass 采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
工具层:OpenCompass 提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
1.3 评测方法
OpenCompass 采取客观评测与主观评测相结合的方法。针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。
- 客观评测:针对具有标准答案的客观问题,可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass 采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。 在客观评测的具体实践中,我们通常采用下列两种方式进行模型输出结果的评测:1)判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。2)生成式评测:该评测方式主要用于生成类任务,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
- 主观评测:借助受试者的主观判断对具有对话能力的大语言模型进行能力评测。在具体实践中,我们提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。由于主观测试成本高昂,本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。
2. 实践
2.1 操作流程
在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
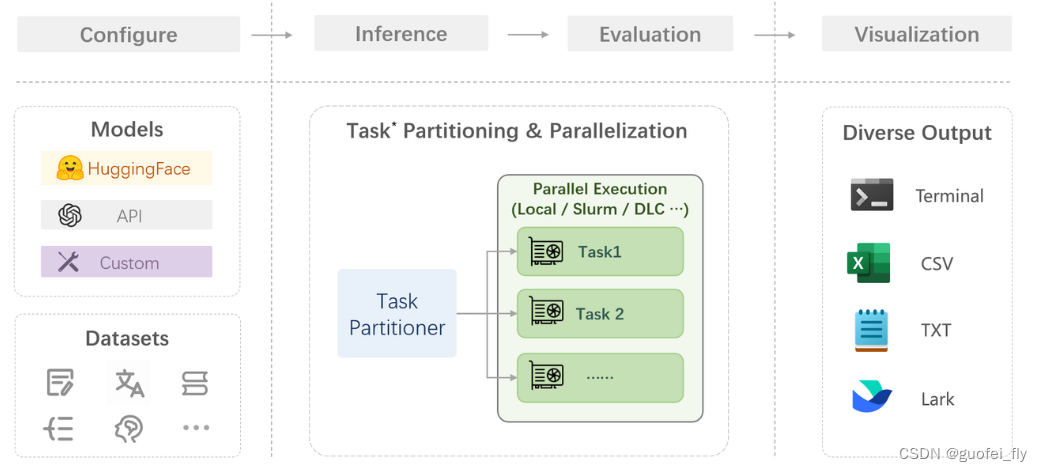
具体而言:
- 配置:配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
- 推理与评估:OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率。
- 可视化:OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。
2.2 客观评测实践
以InternLM2-Chat-1.8B模型为例,评测其在 C-Eval 数据集上的性能。
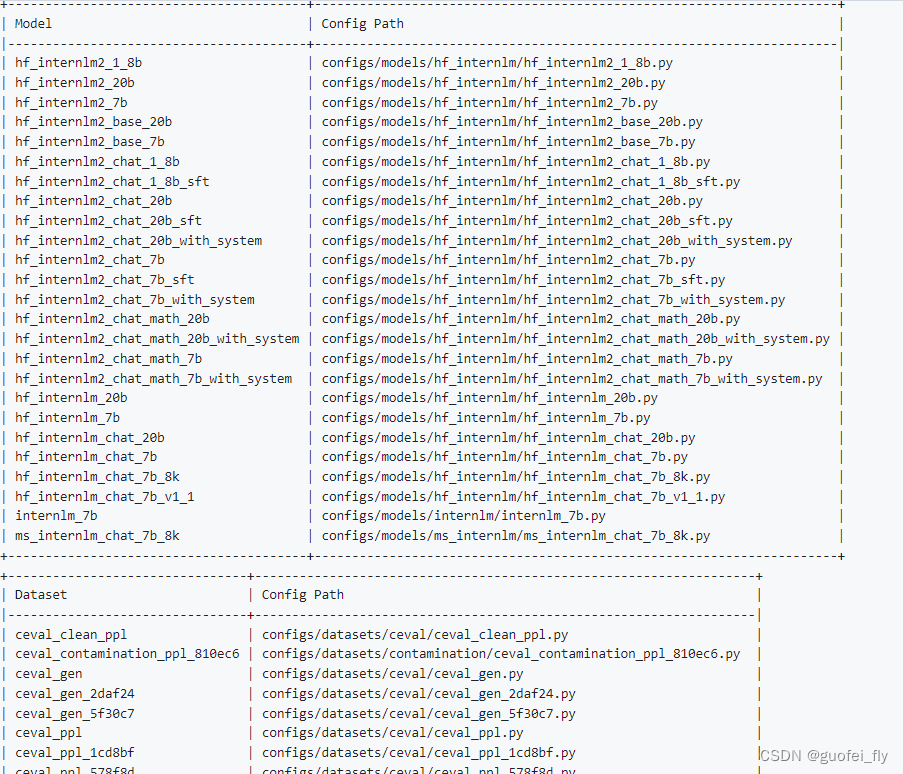
通过运行脚本list_configs.py,可以查看指定模型和数据集的支持情况:
python tools/list_configs.py model_name dataset_name
如以InternLM和ceval分别为模型和数据集关键词:python tools/list_configs.py internlm ceval,可以看到:
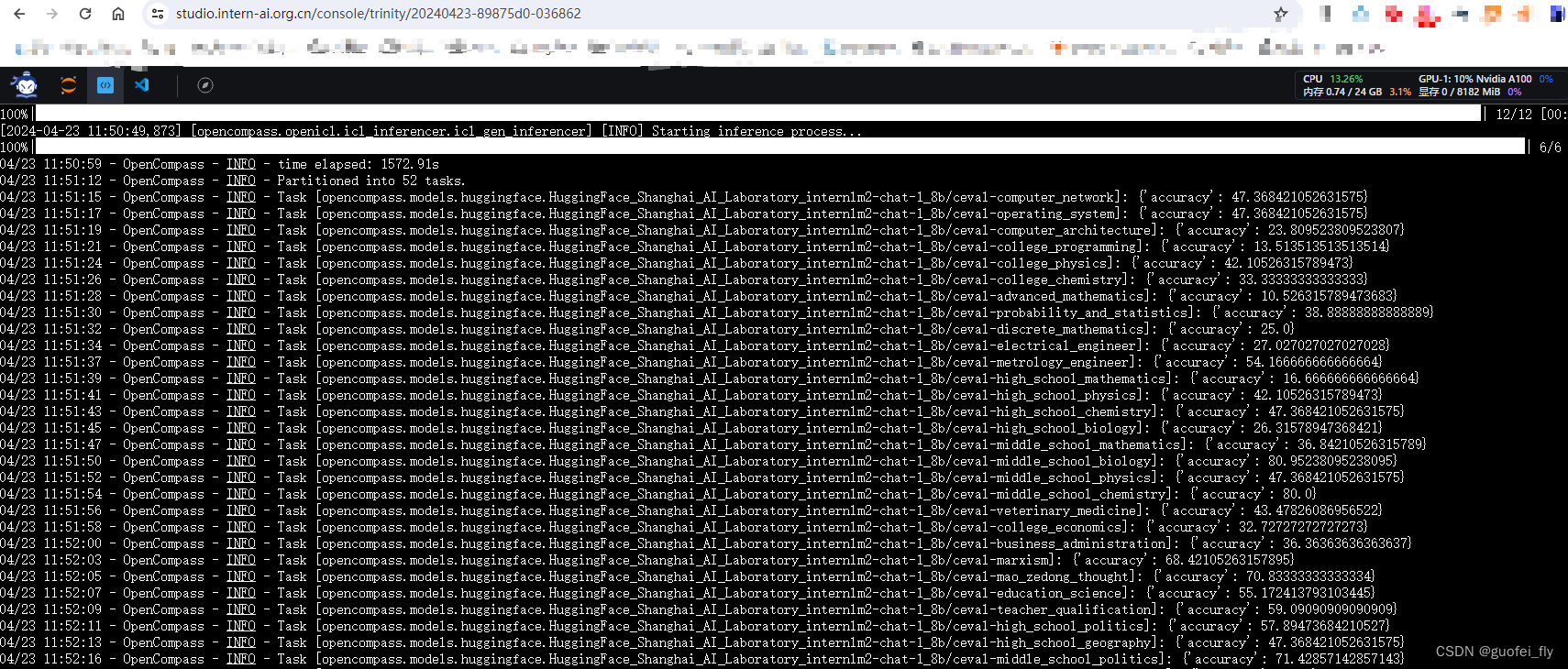
由于 OpenCompass 默认并行启动评估过程,可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出:
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
评测耗时30min,截屏如下:
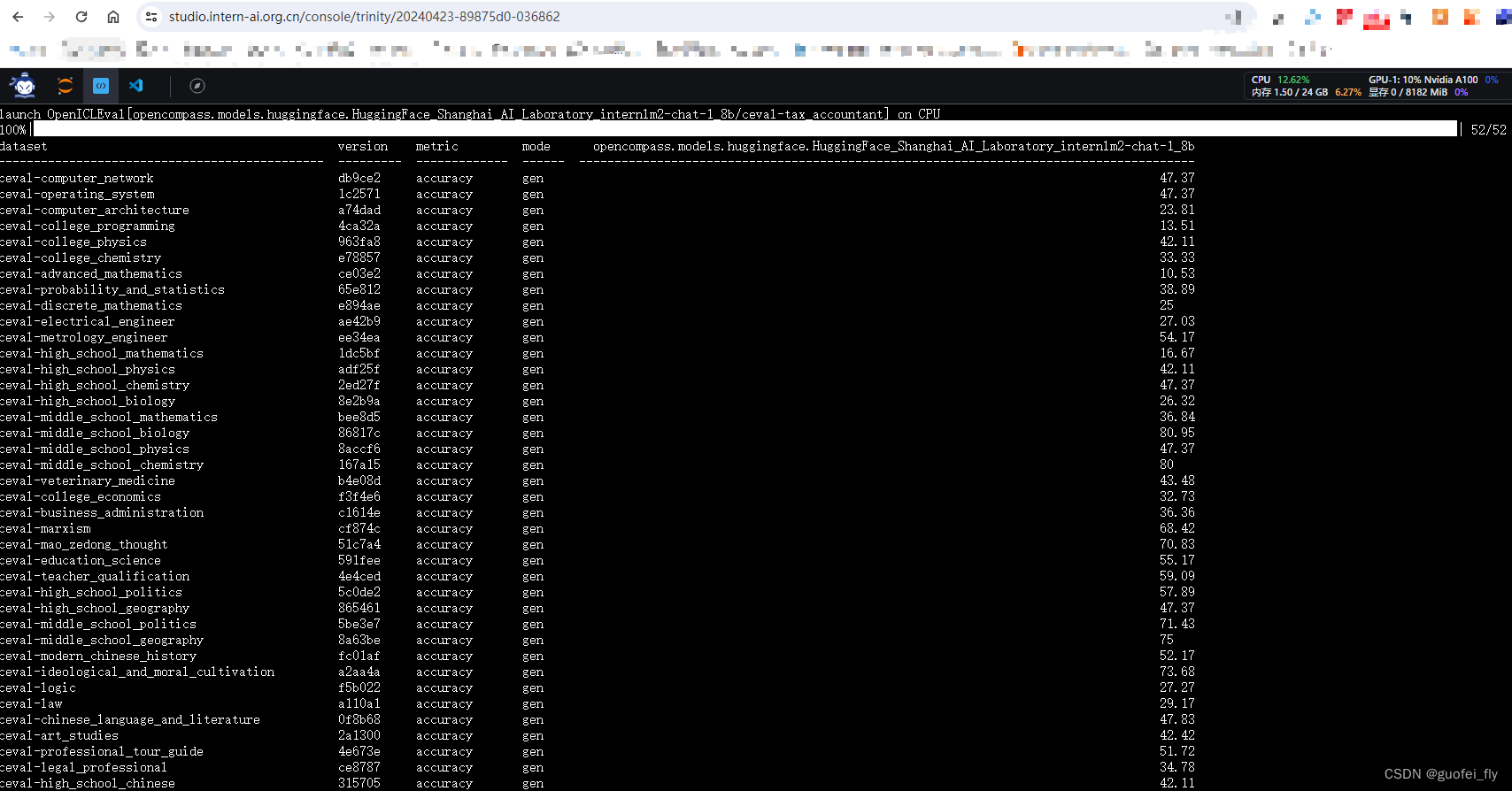
再用非--debug模式运行一遍,耗时22min,截屏如下:
2.3 其它可操作项目
opencompass作为一个开源测试工具,还提供了一系列补充功能。
2.3.1 自定义数据集
自建客观数据集步骤可参考:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_dataset.html
自建主观数据集步骤可参考:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/subjective_evaluation.html
2.3.2 数据污染评估
数据污染 是指本应用在下游测试任务重的数据出现在了大语言模型 (LLM) 的训练数据中,从而导致在下游任务 (例如,摘要、自然语言推理、文本分类) 上指标虚高,无法反映模型真实泛化能力的现象。 但如今开源社区往往只会公开模型参数而非训练数据集,在此种情况下 如何判断是否存在数据污染问题或污染程度如何,这些问题还没有被广泛接受的解决方案。OpenCompass 提供了两种可能的解决方案。
1)方案1:基于自建同分布数据的污染数据标注
具体可参考链接
2)方案2: 基于经典预训练集的污染数据标注
具体可参考链接
2.3.3 大海捞针
大海捞针测试(灵感来自 NeedleInAHaystack)是指通过将关键信息随机插入一段长文本的不同位置,形成大语言模型 (LLM) 的Prompt,通过测试大模型是否能从长文本中提取出关键信息,从而测试大模型的长文本信息提取能力的一种方法,可反映LLM长文本理解的基本能力。
这种测试也经常被用来测试RAG模式的能力。
具体操作可参照:https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html
3. 参考资料
- https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md