在机器学习领域,KNN(K-Nearest Neighbors)、SVM(Support Vector Machine)、决策树(Decision Tree)和随机森林(Random Forest)是常见且广泛应用的算法。
介绍
1. KNN(K-Nearest Neighbors,K近邻)
KNN算法是一种基本的分类和回归方法。对于分类任务,它基于特征空间中最接近的k个邻居的多数投票进行预测。对于回归任务,KNN算法则是通过k个最近邻居的平均值(或加权平均值)来估计目标变量的值。KNN算法简单易懂,适用于小型数据集和基本的模式识别任务。
2. SVM(Support Vector Machine,支持向量机)
SVM是一种强大的监督学习算法,适用于分类和回归任务。它的核心思想是通过在特征空间中找到一个最优的超平面来进行分类。SVM通过最大化类别之间的间隔来提高分类性能,同时可以通过核函数将线性SVM扩展到非线性情况下。SVM在处理高维数据和复杂数据分布时表现出色。
3. 决策树(Decision Tree)
决策树是一种树形结构的分类器,每个节点代表一个特征,每个分支代表该特征的一个可能取值,最终的叶子节点代表分类结果。决策树的构建过程是基于训练数据,通过递归地将数据划分为最纯净的子集来进行分类。决策树易于理解和解释,并且可以处理数值型和类别型数据。但是,决策树容易出现过拟合的问题,因此需要进行剪枝等处理。
4. 随机森林(Random Forest)
随机森林是一种集成学习方法,基于多个决策树构建而成。它通过随机选择特征和样本子集来构建每棵树,然后对每棵树的预测结果进行投票或取平均值来得到最终预测结果。随机森林具有良好的泛化能力和抗过拟合能力,适用于处理大规模数据和高维数据。
总的来说,KNN算法简单直观,适用于小型数据集;SVM适用于处理高维数据和复杂数据分布;决策树易于理解和解释,但容易过拟合;随机森林是一种强大的集成学习方法,适用于处理大规模数据和高维数据。
程序实现
1.数据准备
import pickle
import numpy as np
def read_data(filename):
x = pickle._Unpickler(open(filename, 'rb'))
x.encoding = 'latin1'
data = x.load()
return data
files = []
for n in range(1, 33):
s = ''
if n < 10:
s += '0'
s += str(n)
files.append(s)
# print(files)
labels = []
data = []
for i in files:
fileph = "E:/DEAP投票/data_preprocessed_python/s" + i + ".dat"
d = read_data(fileph)
labels.append(d['labels'])
data.append(d['data'])
# print(labels)
# print(data)2.将数据转换为array格式
labels = np.array(labels)
data = np.array(data)
print(labels.shape)
print(data.shape)
labels = labels.reshape(1280, 4)
data = data.reshape(1280, 40, 8064)
print(labels.shape)
print(data.shape)
# 特征提取
eeg_data = data[:,:32,:] #后面通道不是脑电通道,只有前32个为脑电通道
print(eeg_data.shape)
PSD特征
from scipy.signal import welch
from scipy.integrate import simps
def bandpower(data, sf, band):
band = np.asarray(band)
low, high = band
nperseg = (2 / low) * sf
freqs, psd = welch(data, sf, nperseg=nperseg) #计算功率谱密度数组
freq_res = freqs[1] - freqs[0]
idx_band = np.logical_and(freqs >= low, freqs <= high)
bp = simps(psd[idx_band], dx=freq_res) #积分
return bp
def get_band_power(people, channel, band):
bd = (0,0)
if (band == "delta"):
bd = (0.5,4)
if (band == "theta"):
bd = (4,8)
elif (band == "alpha"):
bd = (8,12)
elif (band == "beta"):
bd = (12,30)
elif (band == "gamma"):
bd = (30,64)
return bandpower(eeg_data[people,channel], 128, bd)
print(len(eeg_data))
print(len(eeg_data[0]))
eeg_band = []
for i in range (len(eeg_data)): #1280
for j in range (len(eeg_data[0])): #32
eeg_band.append(get_band_power(i,j,"delta"))
eeg_band.append(get_band_power(i,j,"theta"))
eeg_band.append(get_band_power(i,j,"alpha"))
eeg_band.append(get_band_power(i,j,"beta"))
eeg_band.append(get_band_power(i,j,"gamma"))
# print(i)
np.array(eeg_band).shape #1280*32*5
eeg_band = np.array(eeg_band)
eeg_band = eeg_band.reshape((1280,160)) # 5×32
print(eeg_band.shape)
## Label数据
import pandas as pd
df_label = pd.DataFrame({'Valence': labels[:,0], 'Arousal': labels[:,1],
'Dominance': labels[:,2], 'Liking': labels[:,3]})
df_label
df_label.info()
df_label.describe()
label_name = ["valence","arousal","dominance","liking"]
labels_valence = []
labels_arousal = []
labels_dominance = []
labels_liking = []
for la in labels: #两分类
l = []
if la[0]>5:
labels_valence.append(1)
else:
labels_valence.append(0)
if la[1]>5:
labels_arousal.append(1)
else:
labels_arousal.append(0)
if la[2]>5:
labels_dominance.append(1)
else:
labels_dominance.append(0)
if la[3]>6:
labels_liking.append(1)
else:
labels_liking.append(0)3.模型搭建、训练、测试、优化
# X数据
data_x = eeg_band
print(data_x.shape)
# Y数据
label_y = labels_valence # 根据需求替换Y数据
# label_y = labels_arousal
# label_y = labels_dominance
# label_y = labels_liking
trainscores = []
testscores = []3.1SVM
from sklearn import preprocessing
X = data_x
# 升维
poly = preprocessing.PolynomialFeatures(degree=2) #生成了二次多项式
X = poly.fit_transform(X)
min_max_scaler = preprocessing.MinMaxScaler()
X=min_max_scaler.fit_transform(X) #对数据进行缩放
# X=preprocessing.scale(X)
X = preprocessing.normalize(X, norm='l1') #L1正则化处理
print(X.shape)
# 降维
# from sklearn.decomposition import PCA
# pca = PCA(n_components=1000)
# X=pca.fit_transform(X)
# print(X.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, label_y)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(X_train, y_train)
train_score=knn.score(X_train,y_train)
test_score=knn.score(X_test,y_test)
knn_pred = knn.predict(X_test)
print("训练集得分:", train_score)
print("测试集得分:", test_score)
trainscores.append(train_score)
testscores.append(test_score)3.2KNN
X = data_x
from sklearn import preprocessing
# 升维
poly = preprocessing.PolynomialFeatures(degree=2)
X = poly.fit_transform(X)
min_max_scaler = preprocessing.MinMaxScaler()
X=min_max_scaler.fit_transform(X)
# X=preprocessing.scale(X)
# X = preprocessing.normalize(X, norm='l2')
print(X.shape)
# 降维
# from sklearn.decomposition import PCA
# pca = PCA(n_components=20)
# X=pca.fit_transform(X)
# print(X.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_x, label_y)
from sklearn.svm import SVC
svc = SVC(kernel='rbf',C = 0.1)
svc.fit(X_train, y_train)
train_score=svc.score(X_train,y_train)
test_score=svc.score(X_test,y_test)
svm_pred = svc.predict(X_test)
print("训练集得分:", train_score)
print("测试集得分:", test_score)
trainscores.append(train_score)
testscores.append(test_score)3.3决策树
X = data_x
from sklearn import preprocessing
# 升维
poly = preprocessing.PolynomialFeatures(degree=2)
X = poly.fit_transform(X)
min_max_scaler = preprocessing.MinMaxScaler()
X=min_max_scaler.fit_transform(X)
# X=preprocessing.scale(X)
X = preprocessing.normalize(X, norm='l1')
print(X.shape)
# 降维
# from sklearn.decomposition import PCA
# pca = PCA(n_components=100)
# X=pca.fit_transform(X)
# print(X.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_x, label_y)
from sklearn import tree
dtree = tree.DecisionTreeClassifier(max_depth=20,min_samples_split=4)
dtree = dtree.fit(X_train, y_train)
dtree_pred = dtree.predict(X_test)
train_score=dtree.score(X_train,y_train)
test_score=dtree.score(X_test,y_test)
print("训练集得分:", train_score)
print("测试集得分:", test_score)
trainscores.append(train_score)
testscores.append(test_score)3.4随机森林
X = data_x
from sklearn import preprocessing
# 升维
poly = preprocessing.PolynomialFeatures(degree=2)
X = poly.fit_transform(X)
min_max_scaler = preprocessing.MinMaxScaler()
X=min_max_scaler.fit_transform(X)
# X=preprocessing.scale(X)
X = preprocessing.normalize(X, norm='l1')
print(X.shape)
# 降维
# from sklearn.decomposition import PCA
# pca = PCA(n_components=100)
# X=pca.fit_transform(X)
# print(X.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_x, label_y)
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier(n_estimators=50,max_depth=20,min_samples_split=5)
rf=rf.fit(X_train, y_train)
train_score=rf.score(X_train,y_train)
test_score=rf.score(X_test,y_test)
rf_pred = rf.predict(X_test)
print("训练集得分:", train_score)
print("测试集得分:", test_score)
trainscores.append(train_score)
testscores.append(test_score)4.模型比较
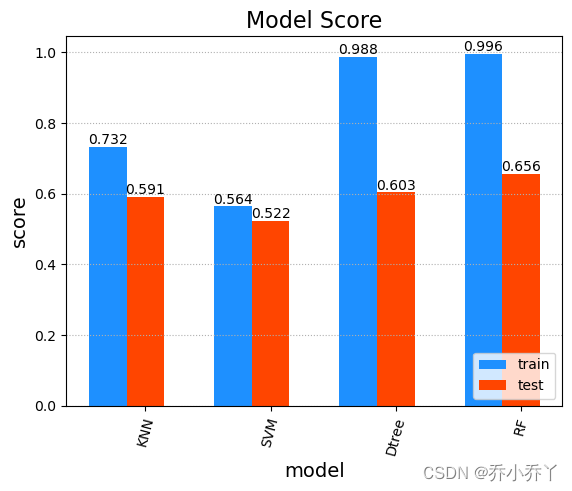
model_name = ["KNN","SVM","Dtree","RF"]
import matplotlib.pyplot as plt
plt.title('Model Score', fontsize=16)
plt.xlabel('model', fontsize=14)
plt.ylabel('score', fontsize=14)
plt.grid(linestyle=':', axis='y')
x = np.arange(4)
a = plt.bar(x - 0.3, trainscores, 0.3, color='dodgerblue', label='train', align='center')
b = plt.bar(x, testscores, 0.3, color='orangered', label='test', align='center')
# 设置标签
for i in a + b:
h = i.get_height()
plt.text(i.get_x() + i.get_width() / 2, h, '%.3f' % h, ha='center', va='bottom')
plt.xticks(x,model_name,rotation=75)
plt.legend(loc='lower right')
plt.show()4.1模型比较结果