1.什么是ETL?
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,是数据仓库的生命线。
抽取(Extract) 主要是针对各个业务系统及不同服务器的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取和缓慢渐变的规则。
转换(transform) 主要是针对数据仓库建立的模型,通过一系列的转换来实现将数据从业务模型到分析模型,通过ETL工具可视化拖拽操作可以直接使用标准的内置代码片段功能、自定义脚本、函数、存储过程以及其他的扩展方式,实现了各种复杂的转换,并且支持自动分析日志,清楚的监控数据转换的状态并优化分析模型。
装载(Load) 主要是将经过转换的数据装载到数据仓库里面,可以通过直连数据库的方式来进行数据装载,可以充分体现高效性。在应用的时候可以随时调整数据抽取工作的运行方式,可以灵活的集成到其他管理系统中。
2.常见的数据抽取工具
2.1 Sqoop
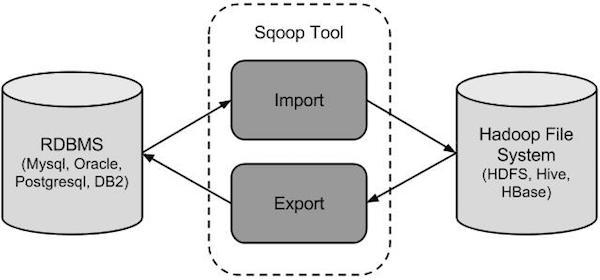
sqoop 是 Apache 开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。sqoop 可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
- sqoop命令的本质是转化为MapReduce程序。
- sqoop分为导入(import)和导出(export),策略分为table和query,模式分为增量和全量。
# 增量导入的案例
sqoop import --connect "jdbc:mysql://localhost:3306/crm?useUnicode=true&characterEncoding=utf-8" \ # 连接mysql数据库
--username root \ # mysql用户名
--password 123456 \ # mysql密码
--table ods_t_visit \ # 源头数据表
--hive-database ods \ # hive中的数据库
--hive-table ods_t_visit \ # 设置到hive当中的表名
--split-by pid \ # 根据pid来做拆分
--check-column last_updated_at \ # 指定增量的列
--incremental lastmodified \ # 增量判断的列
--last-value --last-value "2017-09-18 00:00:00" \ # 增量取值
--null-string '\\N' \ # 在生成Java文件时,将null字符串设置为null
--null-non-string '\\N' \ # 在生成Java文件时,可以将不存在或者null的字符串设置为其他值null
--hive-drop-import-delims \ # 导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--target-dir /user/sqoop/crm/ods_t_visit \ # 合并后的数据在HDFS里存放的目录
-m 1 \ # 设置maptask的并行度
--append \ # 增量模式
--hive-overwrite \ # 覆盖掉在hive表中已经存在的数据
--fields-terminated-by '|' # 设定每个字段是以什么符号作为结束,默认为逗号
;
Sqoop的优点:
1、可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
2、sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。采用map-reduce框架同时在多个节点进行import或者export操作,
速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性;
3、支持insert、update模式,可以选择参数,若内容存在就更新,若不存在就插入;
4、对国外的主流关系型数据库支持性更好。
2.2 Kettle
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho数据集成)。
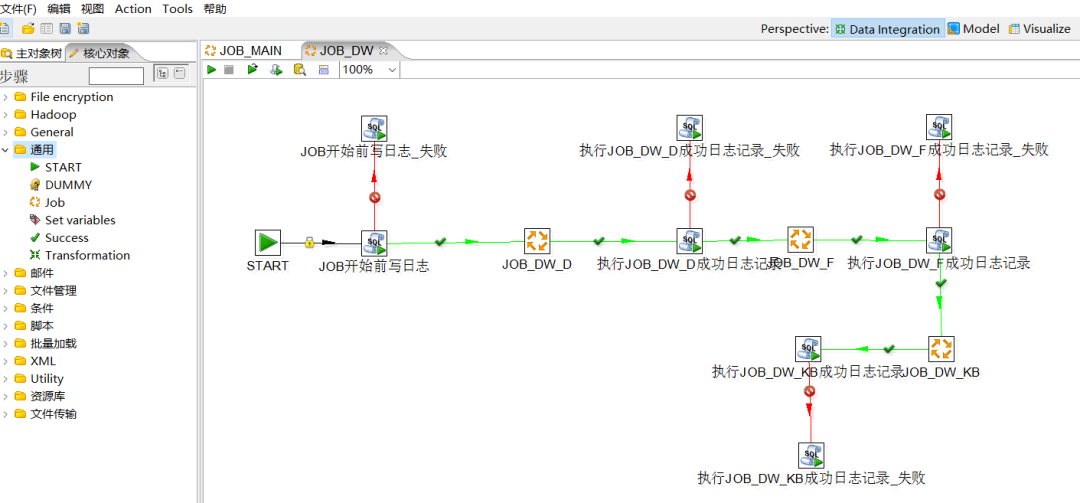
Kettle 家族目前包括 4 个产品:Spoon、Pan、CHEF、Kitchen。
-
SPOON: 通过图形界面来设计 ETL 转换过程(Transformation)。
-
PAN: 批量运行由 Spoon 设计的 ETL 转换 (例如使用一个时间调度器)。Pan 是一个后台执行的程序,没有图形界面。
-
CHEF: 创建任务(Job)。任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。
-
KITCHEN: 批量使用由 Chef 设计的任务 (例如使用一个时间调度器)。KITCHEN 也是一个后台运行的程序。
kettle的优点:
1、其基于JAVA的免费开源的软件,对商业用户没有限制,所以说它是免费开源的。
2、它可以在Windows,Linux,unix上运行,绿色无需安装,数据抽取高效稳定,所以说它是一容易配置的。
3、ET工具库,它允许管理来自不同数据库的数据.
4、可以通过图形界面设计来实现,做什么业务也无需写代码去实现。
2.3 DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
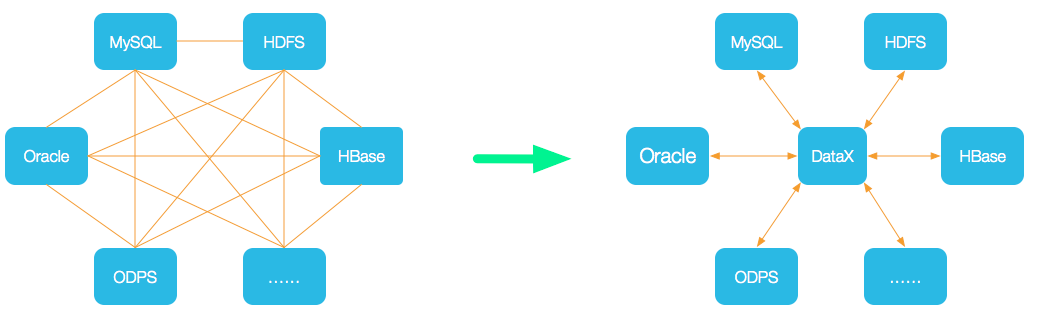
DataX 3.0六大核心优势:
- 可靠的数据质量监控
- 丰富的数据转换功能
- 精准的速度控制
- 强劲的同步性能
- 健壮的容错机制
- 极简的使用体验
2.4 Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。Flume的基础架构图如下:
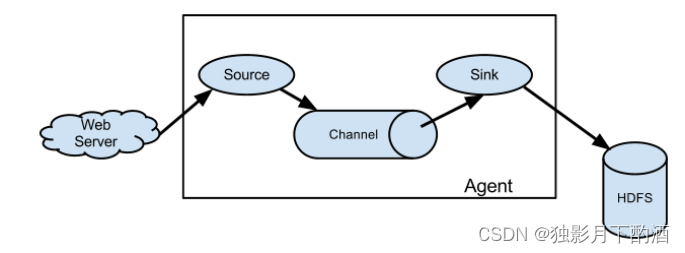
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成,Source、Channel、Sink。
Flume的优点:
1、Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase。
2、当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据。
3、 提供上下文路由特征。
4、 Flume的管道是基于事务,保证了数据在传送和接收时的一致性。
5、 Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
2.5 Canal
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。
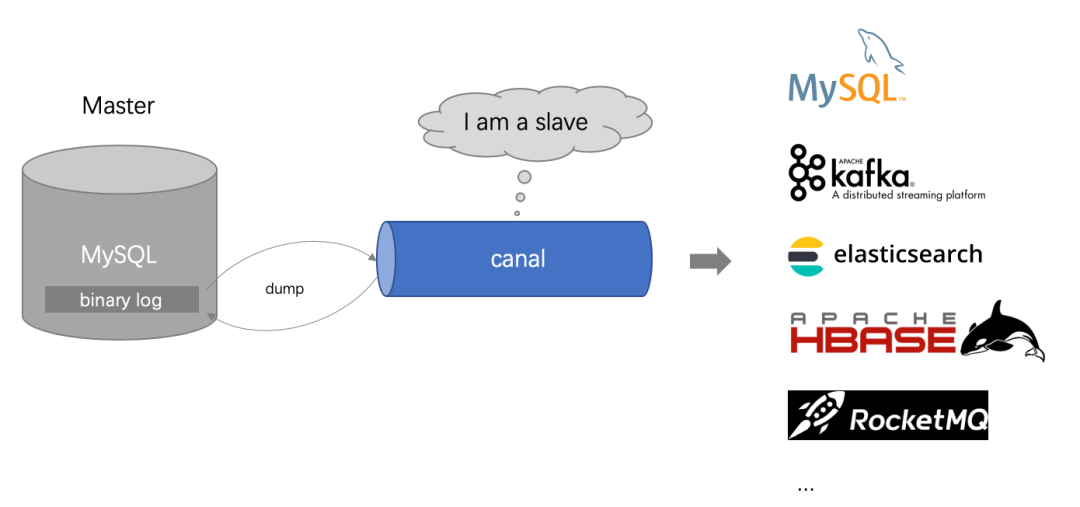
1、canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2、 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
3、canal 解析 binary log 对象(原始为 byte 流)
Canal的优点主要包括:高性能、分布式、可靠性好、支持数据过滤和转换、跨数据库类型(如MySQL、Oracle等)等。
缺点包括:使用难度较大、对数据库的日志产生一定的影响、不支持数据的回溯(即无法获取历史数据)等。
2.6 Maxwell
maxwell 是由美国zendesk开源,用java编写的Mysql实时抓取软件。 其抓取的原理也是基于binlog。
Maxwell与canal的对比
1.Maxwell 没有 Canal那种server+client模式,只有一个server把数据发送到消息队列或redis。
2.Maxwell 有一个亮点功能,就是Canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
3.Maxwell不能直接支持HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
4.Maxwell只支持json格式,而Canal如果用Server+client模式的话,可以自定义格式。
5.Maxwell比Canal更加轻量级。
2.7 CDC
2.7.1 CDC概述
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
2.7.2 CDC实现机制
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
- 基于主动查询的 CDC
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 持续的频繁查询对数据库的压力较大。
- 不保障实时性,基于离线调度存在天然的延迟。
- 基于事件接收CDC : 通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用 Debezium来实现变更数据的捕获。如果使用的只有 MySQL,则还可以用 Canal。
2.7.3 常见的开源 CDC 方案
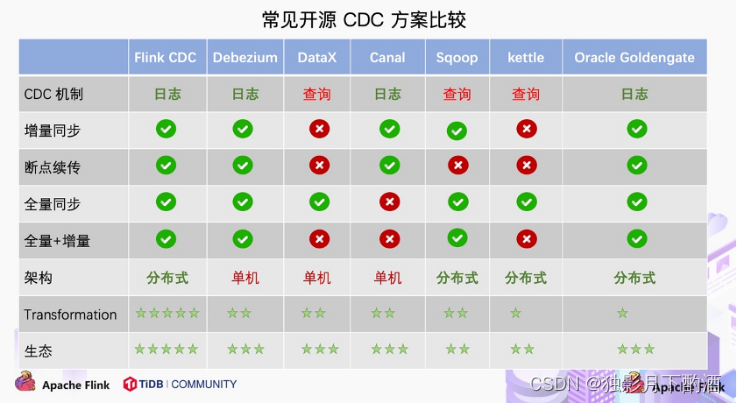
- 对比全量同步能力:
- 基于查询或者日志的 CDC 方案基本都支持,除了 Canal(仅支持增量)。
- 对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 对比增量同步能力:
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。
- 从架构角度去看:
该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
- 在数据转换 / 数据清洗能力上:
当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合。
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
- 在生态扩展方面:
这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
2.7.4 Flink CDC
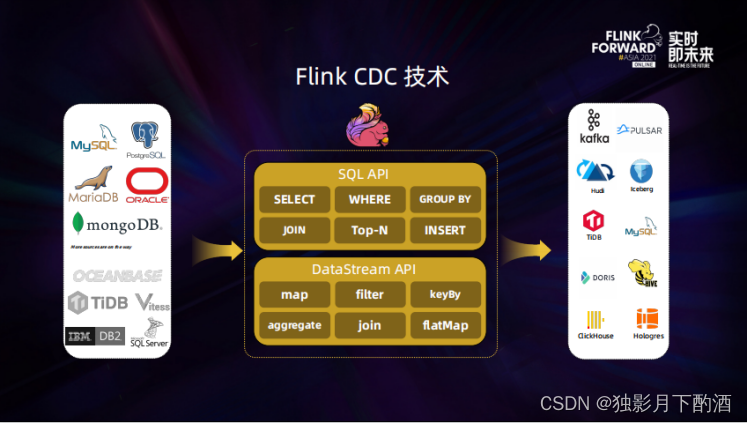
Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
Flink CDC 核心特性:
1)支持数据库级别的快照,读取全量数据,2.0版本可以支持不加锁的方式读取
2)支持 binlog,捕获增量数据
3)Exactly-Once
4)支持 Flink DataStream API,不需要额外部署 Debezium 和 Kafka即可在一个 Flink 作业中完成变更数据的捕获和计算
5)支持 Flink Table/SQL API,可使用 SQL DDL 来创建 CDC Source 表,并对表中的数据进行查询。
3.总结
- sqoop 是 Apache 开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。
- Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
- DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
- Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
- Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
- maxwell 是由美国zendesk开源,用java编写的Mysql实时抓取软件。 其抓取的原理也是基于binlog。bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
- Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。