原文:
annas-archive.org/md5/b5abcf9a07e32fc6f42b907f001224a1译者:飞龙
协议:CC BY-NC-SA 4.0
第十章:可变长度分数化
本章涵盖
-
基于摩尔斯电码的密码
-
混合字母和双字母
-
可变长度二进制码字
-
基于文本压缩的密码
本章涵盖了一系列广泛的分数化密码,其中明文组和/或密文组具有可变长度。 这些包括单体-双体(第 10.2 节)、哈夫曼替代(第 10.4 节)和 Post 标签系统(第 10.5 节)。
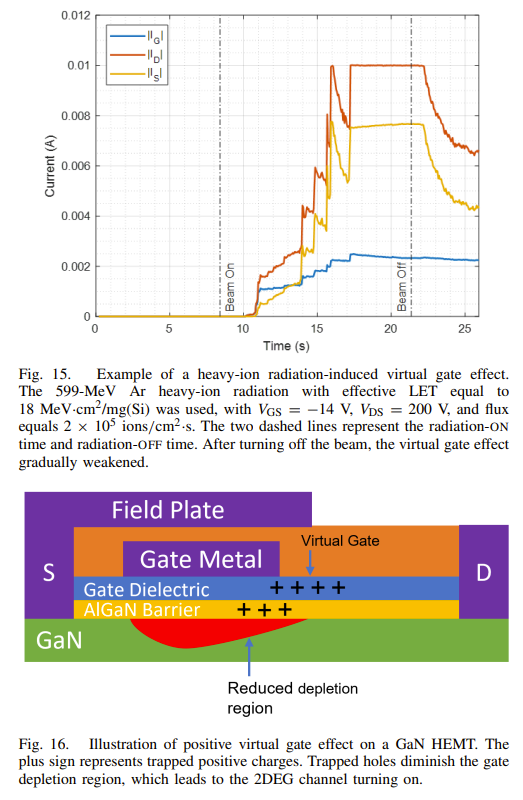
在第 4.4 节中,我用 M. E. Ohaver 的分数化摩尔斯密码的两个版本描述了分数化的概念。 分数化摩尔斯是可变长度分数化的示例,因为它使用 1、3 和 4 个符号的摩尔斯组。 让我用一个类似于第 9.9 节中描述的三重密码的不同形式的摩尔斯分数化来开始可变长度分数化的更广泛讨论。 让我们称之为 Morse3。
10.1 Morse3
Morse3是一个分为 4 步的密码。(1)用摩尔斯码组替换消息的字母。 您可以使用标准摩尔斯码,也可以使用第 4.4 节中的混合摩尔斯字母。 (2)使用**/符号分隔摩尔斯组。 使用双//来分隔单词并标记消息的结束。 (3)将符号分成 3 个组。 如果需要,附加额外的·或··以完成最后一个 3 个符号的组。 收件人将忽略在最后//**之后的这些额外点。 (4)使用第二个混合字母表为每个 3 个符号组替换一个字母。
为了说明,我将使用第 4.4 节中的混合摩尔斯字母(在这里显示在左侧)来形成摩尔斯组。 这仅使用 1、3 和 4 个符号的组,但也可以使用 2 个符号的组,例如作为空或同音字。 从摩尔斯符号到字母的替换使用了一种类似于三合一密码的混合字母表,只是使用了摩尔斯符号**· - /,而不是数字 0 1 2. 请注意,///**永远不会出现,因此不必提供它的字母替代。 因此,只需要 26 个替代品。

让我们对样本消息 SEND AMMO 进行加密。

如果在替换步骤中使用了混合的键入字母表,则此密码被评为五。 Morse3 的一个缺点是密文比明文要长。 在此示例中,8 个字母的明文变成了 11 个字母的密文。
10.2 单体-双体
Monom-Binom,或Monome-Binome,是一类密码,其中每个字母都被单个数字或一对数字替换。 这些密码中最著名的是VIC密码,由俄罗斯间谍于大约 1920 年至 1960 年使用。 名称来自于联邦调查局给予克格勃间谍 Reino Häyhänen 的代号 VICTOR。 VIC 密码直到 1957 年 Häyhänen 叛逃到美国并泄露其细节之前从未被破解过。
VIC 密码有两部分,单-双替换和模 10 加上一串随机数字的部分。让我们从单-双替换开始。字母表中的每个字母都被 1 或 2 个十进制数字替换。为了让接收方 Riva 能够读取消息,两个数字被选为所有 2 位数对的第一个数字。假设发送方 Sandra 选择了 2 和 5。所有 2 位数的替代字母将以 2 或 5 开始,而其他所有数字都将是 1 位数的替代字母。每当消息中的下一个数字是 2 或 5 时,读者就知道这是 2 位数替代的开始,否则就是单个数字的替代。这些替换可以用一个名为 跨距校验板 的 3 行图表来表示。这个名字并不合适,因为图表不是方形的,不是 8×8 的,也没有交替的黑白方格模式。噢,而且它不是用来玩跳棋的。除此之外,这个名字完美无缺。下面是一个示例:

八个 1 位数的替代字母在顶行,而从 2 和 5 开始的二十个 2 位数的替代字母在第二和第三行。数字 2 和 5 不能用作 1 位数的替代字母,所以这些空格在顶行被涂黑了。例如,S 的替代字母是 4,U 的替代字母是 24,Y 的替代字母是 54。
由于有 28 个方格,而英文字母表只有 26 个字母,所以有 2 个额外的字符,我用 * 和 # 表示。通常使用 * 作为一种通用的标点符号,例如 . ? , “ 或任何其他使消息更易读的符号。# 用于在字母和数字之间切换。消息 600 TANKS ARRIVE 1800 TODAY 将被发送为 #600#TANKSARRIVE#1800#TODAY,并被加密为 57600 57730 21438 86251 57180 05779 58354。
这种类型的替换的一个明显的弱点是,超过 1/3 的替代字母(实际上是 10 个中的 28 个,或者 35.7%)以 2 开头,同样的百分比以 5 开头,因此所选的 2 位数比其他 8 位数要频繁得多。它们将像华尔兹比赛中的大象一样显眼。为了帮助缓解这个问题,将最频繁出现的 8 个字母放在顶行。它们是 ETAONIRS。为了帮助记忆它们,你可以使用 SERRATION 的记忆法,即去掉重复的 R 后剩下的 SERATION。或者,你可以使用我的最爱,RAT NOISE。对于最常见的字母使用 1 位数的替代字母也有助于减少密文的长度。
单独使用时,跨距校验板的评级为三级。
然而,VIC 密码增加了第二步。(在其最复杂的形式中还会对数字进行转置。)单项二项式替换的结果被视为中间密文。对于中间文本中的每个数字,都会添加一个密钥数字,取模 10,也就是说,不带进位地相加。这有两种风格。你可以简单地添加一个重复的数字密钥,比如 2793。它将像这样工作:

VIC 密码的这种形式被评为五级。
*****VIC 密码的一种更强形式是使用由随机数生成器产生的非重复数字密钥。为此,俄罗斯人使用了所谓的滞后斐波那契生成器。你可能已经熟悉斐波那契数列,它是一个整数序列,其中每一项是前两项的和。该序列从 x[0] = 0 和 x[1] = 1 开始。序列的其他项由以下数学公式生成:

也就是说,第 n 项是第 n-1 项和第 n-2 项的和。对于 VIC 密码,只有低位数字是相关的。这可以写成
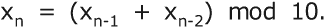
滞后斐波那契生成器可以通过三种不同的方式推广。首先,它可以添加除最后两个以外的其他项,例如

注意,4.5.1 节中描述的链式数字生成器具有这种形式,其中 j = 1 并且 k = 7。
第二,这些数字可以用不同的模生成。最常见的模是某个素数 p 的某个幂 p^e:

第三,两个项可以使用除加法以外的二元运算符结合。常见的选择有减法、乘法和异或。这可以写成

其中 ● 可以表示 + - × ⊕ 或其他二元运算符。(也可以使用除法。它与乘以第二个操作数的乘法逆元相同。请参阅第 3.6 节。)实际上,最常用的是加法,因为加法生成器产生最长的周期。
使用这种形式的伪随机数字生成器,单项二项式评为七级。
10.3 周期长度
实现可变长度加密的一种简单方法是使用多个替换表,每个所需的块长度一个表。如果这些是字母块,替换表将很快变得庞大。相反,我们将使用位。让消息表示为位字符串。消息通过将其分成短位块并使用该长度的替换表替换相同长度的块来加密。块的长度可以使用重复的数字密钥进行周期性设置,或者可以由随机数生成器产生。
让我用一个小例子来演示。有三个用于 2、3 和 4 比特块的替代表。在实际密码中,我会使用 3、4、5 和 6 比特块,但如果你有存储空间,你可以增加到 16 比特,甚至更长。
对于这个简单的演示,我使用了一个标准字母表,通过从键盘的顶部行开始直接从左到右填充它到 32 个字符。

这三个替代表是

这里是使用重复密钥 3,2,2,4,2 的样本加密:

这个版本,我将其称为BitBlock SA,标准字母表,具有适度的强度。每个替代表的混合都有一个密钥,块大小序列还有一个额外的密钥。当只有少数替代表,所有块大小都很小,并且块大小序列很小时,BitBlock SA 被评为三级。否则评为四级。
强化这种密码的一种方法是使用混合密钥字母表将字母转换为比特,并将结果比特重新转换为字母。让我们将混合字母表版本称为BitBlock MA。它被评为七级。
10.4 霍夫曼替代
第 4.2 节描述了如何使用霍夫曼编码进行文本压缩。霍夫曼替代是一种可以使用霍夫曼编码进行加密的方式。霍夫曼替代使用两组编码。第二组的编码替换第一组的编码。这些可能是相同的编码集,但是顺序不同。
消息被表示为比特串,例如通过使用标准的计算机表示之一,如 UTF-8 或 Unicode。这个比特串被分割成来自第一组霍夫曼编码的代码串,然后这些代码被第二组的代码替换。霍夫曼替代并不压缩消息,尽管消息的长度(以比特为单位)可能会因为第一组中的代码与第二组中的替代代码的长度不同而发生变化。
请回忆一下,一组霍夫曼编码必须具有前缀属性。也就是说,一组中的霍夫曼编码不能以另一组中的霍夫曼编码开始。例如,你不能同时有1101和11011,因为如果你正在解码的字符串以11011开头,你就不知道第一个编码是 4 比特还是 5 比特。有了前缀属性,就不需要像摩尔斯码组那样在编码之间有一个分隔符。
让我们看看如何构建具有前缀属性的一组霍夫曼编码。首先列出单个比特,无论顺序是 0,1 还是 1,0。例如,

对于此列表中的每一项,要么将其接受为完整代码,要么通过将一个副本附加 0 和另一个副本附加 1 的方式将其扩展为两个更长的代码,再以任何顺序。例如,我们可以接受代码 1 作为完整的,并将代码 0 扩展为两个代码,00 和 01,如下所示:
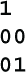
这个过程可以根据需要重复进行。例如,我们可以接受代码 01 作为完成,但是将代码 00 再延长一步,使代码 000 和 001。

这个过程可以继续进行,直到你获得了所需数量的代码或所需长度范围。但是,对于这个例子,4 个代码就足够了。我们将接受代码 000 和 001 作为完整代码,组成完整的 4 个代码。
*****当我们使用这些代码对比特串进行加密时,可以估计平均代码的长度。字符串以 1 开头的概率为 1/2,因此代码长度为 1 位的概率为 1/2。字符串以 000 开头的概率为 1/8,以 001 开头的概率也为 1/8。无论哪种情况,代码都将是 3 位长。字符串以 01 开头的概率为 1/4,代码长度为 2 位。这是一个完整的代码集,因此没有其他可能性。将它们组合在一起得到预期的代码长度 1/2+3/8+3/8+2/4 = 14/8 = 1.75 位。
在第一个代码被替换后,下一个代码的概率相同,因此所有代码的期望长度都是 1.75 位。这比代码的平均长度小,平均长度为 2.25 位。******
这是 Huffman 替换的一个例子。有两组 Huffman 代码。左列中的代码被右列中的代码替换。两组代码都具有前缀属性。明文是用标准的 5 位表示 A = 00000,B = 000001,C = 00010 等编码的 LIBERTY。


5 位组的第一行是用标准方式编码的单词 LIBERTY,A = 00000,B = 00001 等等。二进制的第二行是相同的比特串,但是分为了来自 Set1 的 Huffman 编码。下划线下的数字 1 是填充,用于填充最后一个 Huffman 编码。二进制的第三行用 Set1 中的每个编码替换为相应的 Set2 中的编码,也就是说,第三行是替换步骤的结果。二进制的第四行是与第三行相同的比特串,但是分为 5 位组。请注意,第 4 行比第 1 行长了 4 位。最后一行是使用相同的标准 5 位表示法为字母加密的密文。密文的最后一个字母可能是 I 或 J,因为最后一个二进制组只有 4 位。
*****如果您正在使用计算机执行此操作,则无需逐个将比特串的前端与每个赫夫曼编码进行比较。假设最长的编码有 6 位。您可以制作一个包含所有 64 种可能的 6 位组合的表。表中的每个条目都将告诉编码的长度(以比特为单位),并给出其替代项。每次执行替换时,您都可以使用字符串的前 6 位直接查找表。
例如,假设第一个赫夫曼编码是 00000,其替代项是 0110。以该编码开头的字符串的前 6 位的可能值是 000000 和 000001。因此,表中的条目 000000 和 000001 都将给出编码长度为 5,以及该编码的替代项为 0110。要执行替换,您将删除字符串的前 5 位,并将 0110 附加到结果字符串中。******
10.5 波斯特标签系统
纽约大学 Courant 研究所的数学家埃米尔·莱昂·波斯特(Emil Leon Post)于 1920 年发明了波斯特标签系统。其基本思想非常简单。您从一串比特开始。然后,您从字符串的前面取一些比特,用不同的比特替换它们,并将它们放在字符串的末尾。您继续这样做。其中的一种情况会发生:要么字符串缩小直到您无法再这样做,要么您陷入无尽的重复周期,要么字符串永远增长。
历史背景
波斯特并未为密码学而创建他的波斯特标签。波斯特证明了字符串增长、缩小或重复的问题不能在标准数学框架内得到解答,然后他利用这一事实构建了对库尔特·哥德尔(Kurt Gödel)著名的不完备性定理的证明。我认为这是一个比阿兰·图灵(Alan Turing)使用符号写在无限带上的证明更简单、更优雅的证明,尽管波斯特的比特串与图灵的磁带之间的相似之处令人惊讶。
这个后替换与赫夫曼替换类似,只是你将替换移到了比特串的末尾。这个系统的优势在于,当你替换完整个字符串后,你可以继续进行下去。也就是说,你可以多次遍历字符串。这消除了赫夫曼编码之间的分割。
你从字符串前面取出的部分被称为标签。标签集必须被选择,以便每一步最多只能取一个标签。也就是说,替换过程是确定性的。这要求标签集具有前缀属性。这将允许你使用标签集来加密表示为比特字符串的消息。前缀属性在第 4.2.1 节中与 Huffman 编码一起讨论。简而言之,没有任何标签可以以任何其他标签开头。例如,你不能同时拥有 1101 和 11011,因为如果字符串以 11011 开头,你将不知道是取前 4 位还是前 5 位。有了前缀属性,就不需要在标签之间加上分隔符,就像莫尔斯电码组需要分隔一样。Huffman 编码和 Post 标签具有相同的形式,但它们的使用方式不同。首先,Huffman 编码用于缩短比特字符串,而 Post 标签则不是。
构建一组 Huffman 编码的方法在第 10.4 节中描述。
当你使用 Post 标签进行加密时,你会用另一个标签替换每个标签,并将新标签移到字符串的末尾。由于 Riva 将不得不从右边解密消息,替换标签将需要具有后缀属性,即与前缀属性相反。没有一个后缀标签可以以另一个后缀标签结尾。例如,如果 1011 是其中一个后缀标签,那么 01011 或 11011 都不能是后缀标签。
你可以以与构建前缀标签相同的方式构建后缀标签集,只是在左边扩展每个标签而不是右边。如果这让你困惑,你可以简单地构建第二组前缀标签,然后颠倒该集合中的位的顺序以获得后缀标签。后缀标签必须至少与前缀标签一样多。可以有更多。额外的标签可以用作同音字。例如,前缀标签 0111 可能被后缀标签 110 或 10101 的选择替换。
当后缀的预期长度小于前缀的预期长度时,字符串可能会缩短。也就是说,很可能有一些初始字符串会变短。相反,如果后缀比前缀长,那么一些初始字符串可能会变长。这通常发生在使用同音字时。预期长度的差异越大,初始字符串的缩短或延长就越多。然而,“可能”并不是保证。可以构建具有相反行为的前缀/后缀集。
要使用 Post 标签进行加密,首先将消息表示为一串比特,然后进行几次标签替换。如果你是手动加密,你将这些比特转换回字符。如果你是通过计算机加密,最后一步可能是不必要的;你只需传输生成的比特字符串。
10.5.1 相同长度的标签
在上一节描述的密码中存在一个问题,Riva 不知道如何将她收到的消息分成块。你可能需要为每个块设置一个单独的长度字段,或者将整个消息视为一个单独的块。当消息很长时,这可能会很笨重。解决这个问题的一种方法是用相同长度的后缀标签替换每个前缀标签。这样,块在整个过程中保持相同的长度,而且没有标记块的结束的问题。32 位或 64 位的块大小是典型的。
我建议对每个块进行固定数量的替换。你可以从最短长度和标签的预期长度确定适当的数量。假设块大小为 32 位,最短标签为 3 位,预期标签长度为 4.3 位。使用最短长度,如果至少进行 32/3 = 10.67 次替换,那么可以保证每个块中的每个比特至少被替换一次。将其四舍五入到 11。使用预期长度,平均需要 32/4.3 = 7.44 次替换,以便每个比特都被替换。
一个良好的安全保障是每个比特平均替换两次。将 7.44 倍于 2 并四舍五入得到 15 次替换步骤。这大于 11,因此可以确定每个比特至少被替换一次。平均每个比特替换两次。大约一半的时间,一些比特被替换 3 次。最重要的是,Emily 不会知道任何给定比特替换了多少次。
你可能已经注意到,我一直在说“每个 比特 被替换”而不是“每个 标签 被替换”。这可能会让人困惑。第一轮通过块时,每个标签都会被一个具有相同长度的新标签替换。所以,在第一轮中,被替换的是标签。但是当第二轮替换开始时,可能不会从一个偶数标签边界开始。也就是说,下一个标签可能横跨第一轮的两个或多个标签。
这里有一个迷你示例来说明使用 12 位块的观点。块的第一个比特被阴影覆盖,前缀标签被下划线划分。

经过四次替换后,第一个比特现在位于下一个前缀标签的中间位置,即 011。
对于手工使用,我建议将字母表编码为 5 位或 6 位组,使用 3 到 6 位的 20 到 30 对标签,32 位块和 16 次替换步骤,即大约通过块两次。将结果位串转换回字符,使用 4 位组表示字母 A 到 P 以某种混合顺序。这样的密码将被评为六级。
对于计算机使用,建议使用标准的 8 位表示,如 UTF-8,对消息中的字母、数字和特殊字符进行编码。使用 40 到 80 对标签,每个标签 4 到 8 位,64 位块和 32 次替换步骤。使用 32 步足以确保通过块的 3 次。在进行后标签替换之前,在字符上执行混合的关键替换,并在完成后标签替换后,在结果字节上进行第二个独立的关键替换。这个密码,称为Post64,将被评为十。它将有 4 个单独的密钥用于混合初始替换、最终替换、后标签及其替代物。
使用后标签替换的另一种方法是使用短重叠块。从消息的前 4 个字节开始,并执行 2 次后标签替换。假设标签每个为 4 到 8 位,这足以确保所有第一个字节中的位都已被替换。然后向右移动 1 字节。消息的下一个 4 字节块是字节 2、3、4 和 5。再次对这个块执行 2 次后标签替换。以此类推,直到消息的最后一个 4 字节块。最后的 3 个块将会回绕到消息的前面。这种方法称为PostOv,评级为六。
10.5.2 不同长度的标签
当每个标签的替代物长度不同时,会涉及到各种复杂性,每个块的长度可能会发生变化,并且块可能不会对齐在字节边界上。例如,一个 32 位的块可能会变成一个 35 位的块。这意味着 Riva 需要一种方法来分隔这些块。最简单的方法是传输每个块的长度。
简单地对一个块执行后标签替换,直到其长度再次成为 8 位的倍数,似乎是可行的。不幸的是,这可能需要数千甚至数百万次替换步骤,甚至可能永远不会发生。
最简单的解决方案是将整个消息作为一个单独的块进行编码。消息的长度告诉 Riva 块中有多少个字节。Sandra 只需要在消息中添加一个 3 位字段,告诉 Riva 最后一个字节有多少位,范围从 1 到 8 位。这可以放在消息的开头,也可以是最后一个字节的最后 3 位。长度字段可能需要额外的一个字节。
这里有一个不同长度的后标签编码的示例。每个前缀标签及其相应的后缀标签都有匹配的下划线。

*****看起来好像每次从前面删除标记时都需要移动整个消息。通过保持对消息的第一个位和最后一个位的指针来消除这些移位。每个指针只是一个整数,给出每个端点的位置。指针的低 3 位将给出字节内的位位置,高位将给出字节位置。分配一个长度为消息长度 4 倍的空间。将消息放在此空间的开头,并将其余部分清零。
要从字符串的前面删除一个标记,只需将前指针递增标记前缀的长度。要在末尾附加标记,只需将标记移动到所需的位位置,并与字符串的最后 2 个字节进行 OR 运算,然后递增结束指针。继续这个过程直到到达空间的末尾。这意味着 Post 替换步骤的数量取决于消息本身。
这就只剩下一个移位操作要在最后执行,将位字符串放在偶字节边界上。然而,这个长移位也可以通过在消息的第一个字节和最后一个字节中告诉你的对方起始和结束位位置来消除。这仅需要 6 位,可以打包到一个字节中,并放在消息的开头。我建议用简单的替换对这个字节进行加密,以免给 Emily 起始和结束位置。还要确保用随机位填充消息的第一个字节和最后一个字节的未使用部分。
仍然有一个问题:因为 Riva 不知道消息的原始长度,因此也不知道加密空间的原始大小,她如何知道何时停止解密?Riva 不知道进行了多少次替换步骤,她不能简单地分配一个长度为接收到的消息长度 4 倍的空间,因为这可能与发送的消息长度不同。
这就是方法。Riva 知道三件事:明文消息从一个字节边界开始,消息在一个字节边界结束,加密空间是原始消息长度的 4 倍。Riva 可以开始将接收到的消息放在长度为密文消息 5 倍的空间的末尾。那应该足够了。Riva 从后向前工作,直到满足三个条件,特别是直到部分解密消息的开始到解密空间末尾的距离恰好是消息长度的 4 倍。这只会发生一次。******
我建议您使用 50 到 80 对标签,每个标签长 4 到 8 位。原始标签的预期长度应该接近于替换标签的预期长度。大约 1/3 的替换标签应该比原始标签短,1/3 应该是相同大小的,1/3 的替换标签应该比原始标签长。不要坚持使每个标签与其替代品的长度不同。消息字符应该表示为混合良好的字母表中的 8 位字节。如果标签的预期长度为 T 位,消息的长度为 L 位,则至少应进行 3L/T 次替换步骤。也就是说,你要对整个消息进行 3 次或更多次处理。最终的位字符串,包括长度指示器,应该使用第二个、独立的、简单的替换键转换回字符。如果所有这些建议都遵循,则此密码称为PostDL,评级为十。
当您到达第 12.6 节时,您将会看到 PostDL 密码不符合保证不可破解的所有标准。之所以获得十分评级是因为 Emily 不知道明文位在密文中的任何给定位置。位置将在块与块之间不同。所以 Emily 不能建立明文位和密文位之间的对应关系,因此不能建立密文位与明文和密钥位之间的方程。
10.5.3 多字母表
有几种方法可以加强 Post 标记密码或 Huffman 替换密码。我们已经讨论过多轮替换的情况。另一个技巧是使用多个字母表。每个字母表将包括一组具有前缀属性的标签和相应的一组替换标签,这些替换标签必须具有后缀属性。你可以简单地轮流使用多个字母表,或者你可以使用关键字来在它们之间进行选择。如果你是手工操作,你不会想要超过 2 个,或者最多 3 个这样的字母表,所以我建议使用一个数值密钥,比如 01101011。
这些密码,可能称为PolyPost和PolyHuff,根据轮数、字母表数量和密钥长度的不同评为四到八。
10.5.4 短距离和长距离移动
到目前为止,我们假设当一个 Post 标记有 B 位时,这些 B 位被移动到块的末尾。然而,可以移动少于 B 位,或者多于 B 位。例如,您可以移动 B-1 位,留下 1 位作为下一个标签的一部分再次替换。这使得标签重叠。优点是它隐藏了标签之间的边界。缺点是每轮需要更多的替换步骤,使得密码变慢。
相反,当后缀标签有 B 位时,你可以将 B+1 位移动到块的末尾。这样留下一位不变,而这一位始终是块中的最后一位。如果密码有多轮,那么未更改的比特很可能在其他轮中被替换。仍然有可能某些比特完整地通过这个密码。如果 Emily 无法确定哪些是未更改的比特,这不是一个严重的问题。比特是匿名的。关于任何比特都没有说,“这个比特来自明文的第 5 个字节,第 2 位”。
最后,移动的比特数可以与标签长度无关。你可以有一个表格告诉你要移动的比特数。这可以少于、多于或等于标签的长度。你可以有多个这样的表格。
当移动的比特数与标签长度不同时,后缀属性不再适用于替代标签集。相反,实际移动的比特字符串集必须具有后缀属性。例如,如果标签 0110 被替换为 1101,但移动了 5 位,则后缀字符串集必须包括11010 和11011。
10.6 其他进制中的分数化
到目前为止,本章已经讨论了五进制中的单-双替换,以及二进制中的 Huffman 替换和 Post 替换。可变长度替换也可以在其他进制中进行。对于手工加密来说,在三进制或四进制中进行 Huffman 替换和 Post 替换比在二进制中更容易。然而,可变长度替换可以在任何进制中进行,甚至是奇怪的进制,比如 11 或 13。这可以给你额外的替代品,可以用于同音词或编码二元组。
当你使用十三进制时,你可以使用任意十六进制数字中的 13 个进行替换,将另外 3 个数字留为空。如果做得好,使得所有 16 个数字的频率和分布大致相等,Emily 将无法区分有效数字和空位。
10.7 文本压缩
第 4.2.1 节讨论了使用 Huffman 编码压缩文本的方法。几种强大的加密方案可以基于文本压缩。在本节中,我提出了几种更高级的文本压缩方案和一些基于 Huffman 编码的加密方案。第十章的其余部分是可选的。如果在任何时候数学变得太令人畏惧,可以直接跳到下一章。

10.7.1 Lempel-Ziv
Lempel-Ziv 文本压缩方案是由以色列计算机科学家亚伯拉罕·莱姆佩尔和雅各布·齐夫在 1977 年开发的,被称为 LZ77,并在 1978 年改进了一个版本,称为 LZ78。它基于与赫夫曼编码相同的基本概念,即字母和字母组合由二进制代码表示,即一组比特。然而,莱姆佩尔-齐夫采取了与此相反的方法。赫夫曼使用较短的代码以节省空间。莱姆佩尔-齐夫使用大致相同长度的代码,但有些代码表示较长的字母组合以节省空间。
在另一个意义上,赫夫曼和莱姆佩尔-齐夫是相反的。赫夫曼将代码的长度基于固定的预设字母频率表。莱姆佩尔-齐夫在编码文本时动态确定最常见的字母组合。这被称为 自适应编码。赫夫曼编码仅适用于单一语言的文本。不同的语言将具有不同的字母频率。即使从大写文本转换为大小写混合文本也需要不同的赫夫曼编码集。相比之下,莱姆佩尔-齐夫可用于任何类型的计算机文件,任何语言或混合语言的文本,计算机代码,图像,遥测,音乐视频等。
有几个版本的莱姆佩尔-齐夫。我在这里介绍的版本,称为 莱姆佩尔-齐夫-韦尔奇,或 LZW,是由斯佩里研究公司的特里·韦尔奇于 1984 年开发的。LZW 具有固定宽度和可变宽度版本。我展示的是可变宽度版本,易于用于加密。
所有版本的莱姆佩尔-齐夫都使用称为 字典 的字母和字母组合列表。字典随着算法在文件中的进行而实时构建。在 LZ77 和 LZ78 版本中,字典起始为空。给定任何字母组合的代码是它在字典中的位置。
LZW 首先为文件中的每个单个字符分配一个代码。LZW 的所有代码都具有相同数量的比特。例如,如果文件是一条用英语写成的消息,全为大写且没有标点或单词分隔,则您将需要 26 个代码,因此您可以使用 5 位代码。更常见的是从 256 个代码开始,每个代码对应一个 8 位字节的 256 个可能值之一。
随着算法在文件中进行,它寻找尚未在字典中的字母组合。找到一个后,将该组合添加到字典中。例如,假设算法在文件中找到了 THE,并且 THE 已经在字典中。假设文件中的下一个字母是 M,并且 THEM 不在字典中。它输出 THE 的代码,后跟 M 的代码,并将 THEM 添加到字典中。THEM 的代码是字典中的下一个可用位置,假设是 248。
由于 THE 已经在字典中,算法不会查找以 HE 或 E 开头的组合。它将从 M 开始查找另一个不在字典中的组合。如果该组合是 MOR,则将 MOR 放入字典条目 249 中,并具有代码 249。算法下次在文件中找到 THEM 时,将被编码为 248,并且下一个 MOR 的出现将被编码为 249。
当算法填满了所有 256 个 8 位代码的字典条目时,下一个分配的代码将需要 9 位。此时,算法将从 8 位代码切换到 9 位代码。THEM 仍然具有代码 248,但它将是 9 位代码 011111000,而不是 8 位代码 11111000。当算法填满了所有 512 个 9 位代码的字典槽时,THEM 的代码变为 10 位代码 0011111000,仍然是 248。请注意这些操作的顺序。当前字母组合的代码首先以旧大小输出,然后将新组合添加到字典中,并增加代码大小。Sandra 和 Riva 必须使用相同的顺序,否则消息将无法正确解压缩。通常在 12 位停止扩展代码。将代码大小从 12 位增加到 13 位通常不会改善压缩,并且甚至可能使其恶化。
让我们看一个例子。让我们使用此算法对单词 TETE-A-TETE 进行编码。假设字典以单个字母 A、E 和 T 以 2 位代码开头。让我们跟随字典的构建过程。每个阶段左边的位字符串显示编码的单词,右边的字母显示剩余部分的单词。

当 Riva 解压缩消息时,字典必须以完全相同的方式构建。请注意,仅仅是二进制字符串10 01 011 000 011 011本身不足以让 Riva 解压缩消息。她还需要知道代码00、01和10代表字符 A、E 和 T。
好的。这就是 Lempel-Ziv 压缩。这是一本关于密码学的书。Lempel-Ziv 压缩如何用于加密?
在构建字典时,Lempel-Ziv 按顺序分配代码。第 43 个字母或字母组合将获得代码 42(不是 43,因为代码从 0 开始)。要使用此方案进行加密,请向字典添加第二列。第一列包含字母组合,第二列包含相应的代码。不要使用字典中的位置作为每个字母组合的代码,而是使用字典的第二列中的数字。
假设字典以 256 个单字节字符开头。第一列包含字符。在第二列中,以某种乱序方式放置从 0 到 255 的数字。它们可以通过第 5.2 节中描述的任何方法进行混合。桑德拉和瑞娃必须使用相同的顺序,可以由关键字或随机数生成器的种子确定。当需要第一个 9 位编码时,下一个 256 个字典条目将以乱序方式获取代码从 256 到 511。同样,当您从 9 位代码转移到 10 位代码时,将一次分配下一个 512 个代码。批量分配代码比逐个分配代码更有效。
一种替代批量分配代码的方法是仅使用关键字或随机数序列分配前 256 个代码。之后,每个新代码通过在 256 个条目之前的代码上加 256 来计算。也就是说,X(N) = X(N-256)+256。
我将称之为Lempel-Ziv 替换的这个密码被评为 Three。评分很低是因为消息的前几个字符基本上是用简单的替换进行了加密。每个代码将代表一个单字符,直到出现第一个重复的双字母组为止。这可能要等到编码了 30、40 甚至更多个字符之后才会发生。即使在那之后,大多数的 9 位代码仍然表示单个字母。这些代码很容易区分,因为它们是以 0 开头的唯一的 9 位代码。艾米丽将有很多机会使用字母频率和接触频率来破译消息。
要使 Lempel-Ziv 替换变得强大,您可以添加第二个替换步骤。这个替换不应该在字节边界上进行。我建议使用 7 位组。这些组将不会与代码组重合,直到代码达到 14 位。这可能永远不会发生,因为代码通常限制为 12 位。Lempel-Ziv 替换后跟 7 位替换的评分为 Six。这两种替换可以在单向左到右的通道中完成。
10.7.2 算术编码
算术编码(发音为“a-rith-MET-ic”)是一种文本压缩方法,我在 1970 年代发明的(“使用固定精度寄存器的算术流编码”,IEEE 信息论杂志第 25 卷(1979 年 11 月),第 672-675 页)。它基于麻省理工学院的彼得·伊莱亚斯的一个聪明想法。
埃利亚斯的想法是将每个字符串编码为分数。想象一下,从 0 到 0.999 的所有可能的分数…省略号…表示该分数以无限的 9 序列结尾。现在根据字符串的第一个字符将此范围分割。为简单起见,假设字母表中有 25 个字符,就像一个 Polybius 方块字母表。每个字母将获得全范围的 1/25。那些以 A 开头的字符串将获得全范围的第 1/25,即 4%,范围为 0 到 0.04。以 B 开头的字符串将获得全范围的下一个 1/25,即 0.04 到 0.08。以 Z 开头的字符串将获得全范围的最后 1/25,即 0.96 到 0.999…(我使用十进制表示这个例子是为了更容易阅读。在计算机中,将使用二进制分数。)
对于第二个字符,你再次分割这个范围。以 AA 开头的字符串将在范围 0 到 0.0016 内。以 AB 开头的字符串将在范围 0.0016 到 0.0032 内。以 BA 开头的字符串将在范围 0.0400 到 0.0416 内。以此类推。以 ZZ 开头的字符串将在范围 0.9984 到 0.9999…内。
为了可视化,让我们使用一个小型的 5 个字母的字母表,其中 A 从 0 到 0.2,B 从 0.2 到 0.4,C 从 0.4 到 0.6,D 从 0.6 到 0.8,E 从 0.8 到 0.999…。使用这个字母表,让我们将单词 BED 编码。

BED 可以编码为任何满足 0.384 ≤ f < 0.392 的分数 f。随着添加更多字符,此间隔将继续缩小。
这就是概念。然而,将字符串编码为分数并没有提供任何压缩。需要另一个想法来实现压缩。与其给予字母表中的每个字母相同比例的分数,不如将分数与该字母的频率成比例。A 将获得 8.12%,B 将获得 1.49%,依此类推,直到 Z,Z 将获得 0.07%。A 的范围为 0 到 0.0812。B 的范围为 0.0812 到 0.0961。Z 的范围为 0.9993 到 0.9999…。
从理论上讲,这将根据各个字母的频率提供最佳压缩。不幸的是,存在一个实际问题。该方法产生的分数可能需要数千甚至数百万位数。如何在计算机中表示这样的分数?如何对它们进行算术运算?
因此,这个方法在理论上很好,但在实践中似乎不可行。它似乎需要无界精度的分数。增加和乘以长分数的时间(无论是十进制还是二进制)都会随着它们的长度增加而增加,所以即使有一种好的方法来表示这些分数,该方法也会变得难以忍受的缓慢。
我找到的解决方法是使用一个移动窗口,在其中进行所有的算术操作。这样可以使用普通的 32 位整数。不需要浮点运算。为了保持整数在 32 位大小内,字母频率被近似为 15 位整数,即形式为 N/2¹⁵ 或 N/32768 的分数。例如,字母 A 的频率是 8.12%。这可以表示为 2660/32768 或 665/8192。发现这个近似没有导致压缩程度的可检测减少。
这是一个十进制示例,展示了一个字母如何被编码以及移动窗口的工作原理。假设前几个字符已被编码,并且范围现在为 .784627 到 .784632。范围的起始和结束的前 4 位数字是相同的,即 .7846。这 4 位数字将被输出,并且窗口将向右移动 4 个数字以显示范围 .2700 到 .3200。

这个范围的宽度是 .0500。假设消息中的下一个字符的频率是 .0300,其范围是 .4050 到 .4350。这个字符被编码为当前范围 .2700 到 .3200 的那一部分。其宽度是 .0500×.0300,即 .0015。它将从 .2700+.0500×.4050 运行到 .2700+.0500×.4350,即 .29025 到 .29175。注意这个范围的宽度是 .0015,正如预期的那样。

由于这个范围的起始和结束都以数字 .29 开头,这些数字可以输出。已输出的数字现在是 784629。窗口现在可以再向右移动 2 个数字,使当前范围为 .0250 到 .1750。
算术编码非常适合用于加密,因为不再有每个字母或字母组合的离散编码。没有边界,可以将比特流分割为单独的代码。相反,每个字母的代码影响如何表示所有后续字母。
现在我们了解了算术编码方法的工作原理,下一步是看如何将其用于加密。我们不希望改变分配给每个字符的范围的百分比,因为那样会失去压缩。相反,我们可以改变字符的顺序,使得每个字符的范围都落在整个范围中不可预测的部分。也就是说,对于艾米莉来说是不可预测的。例如,仅使用字母 A、B、C、D、E,范围可能是:

这些区间可以用来编码消息的字母。我们将这种方法称为算术加密。由于艾米莉不知道任何范围的起始点或结束点,因此没有攻击的机会。艾米莉知道第一个范围从 .0 开始,最后一个范围结束于 .999…,但她不知道这些范围代表哪些字符。
算术编码存在一个尚未讨论的困难。使用正常的字母表,Riva 不知道消息何时结束。代表 ROTUND 的相同代码也可以代表 ROTUNDA、ROTUNDAA、ROTUNDAAA,依此类推,假设 A 的范围从 0 开始。使用传统算术编码,可以通过使用各种方法对消息长度进行编码并将该长度码附加到密文中,或者通过向字母表添加特殊的消息结束字符来解决此问题。此前没有讨论过这一点,因为算术加密不需要它。
使用算术加密时,您只需将罕见的字符分配给第一个范围,即从.0000 开始的范围。然后,当 Riva 看到 ROTUNDVVV…或 ROTUND###…时,消息的结束就显而易见了。
如本节所述,使用 26 字母表对算术加密评为 Five,或者使用 256 字符字母表评为 Six。这里可以使用所有常用的技巧,如空字符、同音字和双字母组。使用空字符会减少或破坏压缩,因此我不建议使用。使用同音字会将字母的范围分成两个或更多的单独范围。这使得字母的范围更加均匀,这相当于平衡了字母的频率。这可以在不影响压缩程度的情况下提高安全性。有时,使用双字母组甚至三字母组可以提高压缩水平同时提高安全性。使用同音字和双字母组,算术加密评为 Eight。
由于算术加密本身非常强大,所以只需很少的额外工作就可以将其提升到 Ten 的评级。我建议使用周期为 4 的一般多表密码,即使用四个独立混合良好的字母表以轮换方式使用的替换。使用周期为 4 或更高的一般多表加密后的算术加密评为 Ten。它让对手毫无线索可循,没有字母频率,没有联系频率,也没有利用可能的单词的方法。
10.7.3 自适应算术编码
Lempel-Ziv 给任何类型的文件提供了良好的压缩,因为它是自适应的。Huffman 编码和算术编码提供了更好的压缩,但只适用于字符频率与基础频率表相匹配的文件。有几种方法可以使 Huffman 编码和算术编码自适应,所有这些方法都使相应的加密方法更加强大。所有这些方法都涉及对文件中的字符进行计数,然后再对其进行编码。
字符计数与文件中的字符频率越接近,获得的压缩效果就越好。你可能会认为你可以简单地计算文件中的所有字符,然后使用实际的计数。问题是 Riva 不能统计文件中的字符。Riva 必须使用与 Sandra 相同的频率,否则她无法解密文件。解决这个困境的方法是 Sandra 在加密时计数字符,Riva 在解密时计数字符,这样他们在所有阶段都会拥有相同的计数。
所有字符计数从 1 开始。如果你事先知道字符的频率,即使它们只是粗略的估计,你也可以增加更频繁出现的字符的计数。例如,如果你使用的是 256 个字符集,并且你预计消息将包含约 1%的大写字母 E 和约 10%的小写字母 e,那么你可以将 E 的字符计数增加 2,将 e 的字符计数增加 25,即 256 的约 10%。每个字符的初始范围与其初始计数成比例。例如,如果 256 个字符计数总共为 500,并且小写字母 e 的初始计数为 25,那么 e 的范围将为 25/500,即 0.05。
调整代码有两种基本方法,字符模式和批处理模式。字符模式只适用于算术编码。在字符模式中,每当在文件中找到一个字符时,它的范围和两个相邻范围都会被调整。(当字符具有第一个或最后一个范围时,有一个相邻范围。对于 26 个字母的标准字母表,这意味着 A 或 Z。)
这里有一个例子。假设已经遇到了字母 T,并且相邻范围属于字母 S 和 U。(这可能不适用于算术加密。混合字母表可能不会按顺序包含 S、T、U。)假设 S、T 和 U 的字符计数分别为 15、20 和 5,因此它们总共为 40。假设 S、T 和 U 的范围分别为 0.062、0.074 和 0.024,因此它们总共为 0.160。这个合并范围按比例重新分配为 15:20:5。S 获得 0.160×15/40,即 0.060。T 获得 0.160×20/40,即 0.080。U 获得 0.160×5/40,即 0.020。随着时间的推移,字符的范围将收敛到正确的宽度。
字符模式在 26 个字母的字母表中效果还不错。但在 256 个字符的字母表中效果非常差。大多数 256 个字符不会与任何高频字符相邻,因此它们的频率将保持不变。这在所有字母都聚集在一起的标准 ASCII 表示中尤其明显。
批处理模式适用于算术编码和哈夫曼编码。在批处理模式下,在编码过程中的特定点调整整个范围。例如,在编码 64 个字符后,128 个字符后,256 个字符后等等可以调整范围。在这些点上,整个范围将根据当前字符计数重新分配。这比字符模式更快地收敛,但在重新分配之间,您正在使用旧的未调整频率。
在批处理模式下,可以计算二元组甚至三元组的频率。出现多次的二元组或三元组可以被赋予自己的哈夫曼代码或算术代码范围。通过这种改进,算术编码几乎总是比 Lempel-Ziv 提供更好的压缩。
计算二元组和三元组频率存在一个问题,即存储。对于一个 256 字符的字母表,有 65,536 个不同的二元组和 16,777,216 个不同的三元组。如果存储空间充足,这可能不是问题。如果存储空间有限,一个解决方案是仅计算包含最常见字母的二元组和三元组。例如,如果将二元组和三元组限制为最常见的 20 个字符,则只有 400 个二元组和 8,000 个三元组需要计算。为了确定最常见的字符,可以推迟计算二元组和三元组频率,直到编码了一定数量的单个字符,比如 256 或 1024 个字符。
实现这些受限制的计数的一种方法是仅在第一个批次中计算单个字符,以确定最常见的字符。在第二批次中使用这些高频字符计算二元组。在第三批次中,仅使用高频二元组加上高频字母计算三元组。一旦选择了高频二元组和三元组,它们将被赋予自己的哈夫曼代码或算术范围。换句话说,它们被视为单个字符处理。
对于算术编码,字符模式和批处理模式并不是互斥的。您可以在遇到每个单个字符时平衡各个字符的范围,并在每个批次结束时平衡扩展字符集以及二元组和三元组。
在进行哈夫曼加密或算术加密时,在每个批次结束时,字母表应在代码被替换或范围重新平衡之前重新洗牌。如果添加或删除了二元组或三元组,则特别需要这样做。这意味着艾米莉在代码改变之前只有有限的材料可以攻击。对于加密,最好使用不规则长度的批次,比如在 217 个字符后,然后在 503 个字符后,以此类推,这样艾米莉就不会知道代码何时改变。
对自适应编码的另一项改进是在重新平衡范围后将所有计数除以 2。这样可以让编码适应字符频率发生变化的情况。较旧的频率对范围的影响会减少,而较新的频率则会增加影响。例如,假设文本是一本由不同作者撰写的故事书。每个作者可能有不同的词汇或不同的主题,甚至用不同的语言书写。
当然,Sandra 和 Riva 必须事先就所有这些达成一致,这样 Riva 才能正确解密和解压消息。
第十一章:块密码
本章涵盖
-
DES 和 AES 加密标准
-
基于矩阵乘法的密码
-
对称密码,其中加密和解密是相同的
-
涟漪密码
-
块链
我们已经看到了几种对文本进行分块处理的密码。一些操作于仅由 2 或 3 个字符组成的小块,例如 Playfair、Two Square、Three Square 和 Four Square。一些操作于更长的块,但每次只更改 2 或 3 个字符,例如 bifid、trifid 或 FR-Actionated Morse。这些密码在每个块的一部分上进行局部操作。明文中的一个字符的变化通常最多会改变 2 或 3 个密文字符。
本章涉及更强大类型的块密码。在这些密码中,即使改变明文的一个比特,或者密钥的一个比特,也会改变大约一半的密文比特,以及几乎所有的密文字节。这表明密码是高度非线性的。这些密码仅适用于计算机使用,通常配有专用硬件来加速加密。
本书的大部分其余内容都与计算机密码和方法有关。如果您不关心计算机方法,只需跳过这些部分。
11.1 替代-置换网络
许多块密码采用替代-置换网络(SPN)的形式。这个想法首次由 IBM 的 Horst Feistel 于 1971 年描述。加密由几轮组成,每轮可能包括一个或多个替代步骤和/或一个或多个置换步骤。通常有一个主键来控制整体操作。
替代步骤的最常见选择是(1)简单替代,(2)用密钥的一部分与块的一部分进行异或,或者(3)在密钥的控制下进行多表替代。密钥可以由主密钥和/或未被替代的块的部分的位组成。例如,块中的奇数字节可以用作对偶数字节进行加密的密钥,反之亦然。一种稍微复杂的替代形式是从密钥中获取一些比特,将它们与块中相同数量的比特进行异或,并将结果用作替换块的另一部分的多表密钥。
替代字母表通常是预先选择的,永远不会改变。这些被称为S-boxes。它们可能是简单的替代,也可能是多表替代,因此 S-box 是计算机的等价物。它们通常需要 4 到 8 个关键位来选择表格的行,并以相同数量的位作为输入和输出。通常会有一些复杂的数学运算用于构建替代字母表。特别是,这些字母表被设计为非线性的,这在第 12.3 节中有详细说明。
每一轮的置换通常是预先确定且不变的。置换可以操作单个比特、4 位组或 8 位字节。在大多数分组密码中,置换没有密钥;它们是硬编码在软件中或硬连到加密芯片中的。
现代分组密码中最早的是Lucifer,由 IBM 的 Horst Feistel 设计。在 Feistel 最终确定 Lucifer 之前,名称已经多次更改,因为他想要一个体现设计的邪恶本质的名称。Feistel 还反复改变了 Lucifer 的设计,从最初的在 128 位块上工作的 48 位密钥到在 128 位块上工作的 128 位密钥。您可以在 derekbruff.org/blogs/fywscrypto/tag/lucifer (访问时间:2022 年 5 月) 上阅读有关 Lucifer 的更多信息。
这是一个微型置换-置换网络密码的图示。此密码接受 16 位明文并产生 16 位密文。它有 4 轮替换和 3 轮换位。替换和换位是固定的;它们内置到硬件中。使用了 4 种不同的替换,分别是 S[1]、S[2]、S[3] 和 S[4]。每个替换需要 4 个输入比特加上一个密钥,通常是 4、6 或 8 位,因此如果所有密钥都是独立的,则密码可能具有 64、96 或 128 位密钥。每一轮的换位都不同。

这个微型网络密码被评为三级,因为它相当于一个双字母替换,但它可以通过 6 轮替换从 16 位扩展到 64 位,评为八级,或者通过 8 轮替换从 16 位扩展到 128 位,评为十级。
最终版本的 Lucifer 设计直接导致了数据加密标准 (DES),该标准于 1977 年正式由国家标准局 (NBS) 采纳。因此,让我们直接进入它。
11.2 数据加密标准 (DES)
DES 是 1976 年在 IBM 开发的,通过削减当时的 Lucifer 版本实现。该版本使用了 128 位密钥,并且在消息的 128 位块上工作。块大小缩小为 64 位,这是可以接受的,因为这降低了硬件成本。IBM 想要使用 64 位密钥,但 NSA 坚持进一步减少密钥,降至 56 位,理由薄弱,声称额外的 8 位可以用作校验和。普遍认为,实际原因是 NSA 能够解决 56 位 DES,但无法解决 64 位 DES。
IBM 最初计划将 DES 设计为 6 轮密码。当 NSA 告诉 IBM 它可以破解 6 轮版本时,IBM 直接跳到 16 轮,与 Feistel 在他的 Lucifer 最终版本中使用的轮数相同。
DES 的一个新特性,在任何 Lucifer 版本中都找不到,就是在第一个和最后一个替换步骤之前进行位转置。这些是 8×8 列转置,其中列的顺序和行的顺序都被改变。对于初始置换,块的 64 位从左到右写入网格中。列按相反顺序读出,即 8、7、6、5、4、3、2、1。行按顺序读出,即 2、4、6、8、1、3、5、7。最终置换是其逆置。
这些置换对加密的价值是没有的。它们并没有增加 DES 的强度。它们之所以被添加,是因为 NSA 告诉 IBM,硬件加密应该很快,但在软件中模拟时应该很慢。其想法是通过软件尝试所有可能的密钥来使 Emily 破解密码更加耗时,即通过穷举法尝试破解密码。IBM 相信,置换位会使任何软件实现非常慢。IBM 可能设想了一种逐位提取比特并通过掩码进行位移的过程,然后将其移动到位。
结果证明这完全是错误的。首先,希望破解 DES 的敌人可以简单地通过代理购买加密芯片。其次,对于一些合法的应用程序,DES 需要嵌入软件中,因此软件必须快速。第三,位置换可以快速完成,而不必提取单个位或进行位移。我将在第 11.2.3 节中展示如何做到这一点。
在初始和最终置换之间,DES 有 16 个替换轮。64 位块分为两个 32 位的半块。在每一轮中,右半部分用于加密左半部分。首先,将右半部分从 32 位扩展到 48 位,如下所示。将 32 位视为八个 4 位组。这些组中的每个都通过附加前面和后面的位(来自相邻的组)从 4 位扩展到 6 位。例如,第三组将由第 9 到 12 位组成。这个 4 位组将通过在左边附加第 8 位和在右边附加第 13 位来从 4 位扩展到六位。换句话说,6 位组将是位 8、9、10、11、12、13。八个这样的 6 位组形成一个 48 位块。
然后,将此 48 位块与从 56 位密钥中取出的 48 位进行异或。确定每一轮使用哪 48 位由一个密钥调度确定,基本上是在每一轮后将完整的 56 位密钥向左或向右移动几个位置。然后,得到的八个 6 位组被输入到八个固定的 S 盒中,即替换。每个 S 盒给出一个 4 位结果,因此八个 4 位结果组成一个 32 位块。然后将此块与整个 64 位块的左半部分进行异或。
历史小插曲
IBM 并未设计 DES 以具有密钥调度。最初的想法是在每个 16 轮后将 64 位密钥循环移位 4 位位置。这样留下了密钥在其原始位置,准备加密下一个块。当 NSA 要求 IBM 将密钥大小减小到 56 位时,IBM 被迫引入了密钥调度。四位移位不再起作用。当然,IBM 将密钥调度称为“功能”。
查看每个 S-box 的另一种方法是将其想象为一个 4×16 的表格。像 Belaso 或 Vigenère 表格一样,每行都是 4 位组的替换表。附加到 4 位组的两个额外位用于选择表格的 4 行中的哪一行。
每个 S-box 都经过精心设计,以尽可能减少 6 个输入位和 4 个输出位之间的相关性。NSA 发现了一种最低相关性的设计 S-box 的绝密方法。由于 DES 如此重要,NSA 决定与 DES 的 IBM 设计者分享这个秘密。然而,在检查 IBM 设计后,NSA 发现 IBM 也发现了这种方法,并在其设计中使用了它。
每轮结束后,除了最后一轮外,64 位块的左半部分和右半部分被交换。
11.2.1 Double DES
从一开始就明白,56 位密钥对于强大的安全性来说太小了。仅在 DES 被采纳后的 4 个月,电子前沿基金会构建了一台名为 Deep Crack 的 25 万美元的专用计算机,仅用了 56 小时就解密了一条 DES 消息。
对这种明显的弱点的第一个提出的解决方案是使用两个不同的密钥两次使用 DES 加密消息。这个想法被拒绝了,因为从理论上讲可以发动一种中间相遇攻击来破解 DES。也就是说,你从明文向前工作,从密文向后工作,并在中间相遇。你通过获取已知明文的密文块来执行此操作。你使用所有 2⁵⁶ 可能的密钥加密明文,然后使用所有 2⁵⁶ 可能的密钥解密密文。您比较这些结果,无论您在哪里找到匹配项,您都有可能的密钥对。
这种攻击仅仅是理论性的。您需要存储 2 组 2⁵⁶ 解决方案,即 2⁶⁰ 字节,以进行所有比较。1970 年代的计算机都没有达到那个存储水平。此外,您预计将获得约 2⁴⁸ 个匹配项。所有这些都需要被检查。这是一个艰巨的任务。但是 IBM 和 NSA 希望 DES 能够持续 20 到 30 年,并且有可能在这段时间内这种攻击变得实用。可能会使用 Double DES,但从未被接受为标准。
11.2.2 Triple DES
三重 DES,或 3DES,是另一种补偿 DES 小 56 位密钥尺寸的尝试。它包括将一个 64 位块加密一个 DES 密钥,用第二个 DES 密钥解密,然后用第三个 DES 密钥加密。显然,这比普通 DES 花费的时间多 3 倍。它没有被广泛使用,因为这使它变得很慢。
提高 DES 安全性的更快方法是使用一个 64 位密钥在 DES 步骤之前对 64 位块进行异或操作,并在 DES 步骤之后使用另一个 64 位密钥进行异或操作。将有 3 个独立的密钥,两个 64 位异或密钥和 56 位 DES 密钥,总共 184 位。这种方法只比单个 DES 加密多花一点时间。
即使第二个异或密钥可以通过查看波形来确定,这仍然比单个 DES 更强大。你可以通过在 DES 步骤之前和之后执行键控简单的替换来消除波形撤销异或的危险。
*11.2.3 快速位换位
DES 的起始和结束都涉及位换位。这样做的朴素方式是逐个解压位,将它们移动到期望的位置,然后将它们 OR 到位。有一种更快的方法,大约在 1975 年,由我和 IBM 纽约约克镇研究中心的 David Stevenson 独立发明。我将用一个 32 位块的换位来演示这种技术。假设明文,以位形式表示,是

其中每个拉丁字母或希腊字母代表一个比特的值,即它可以是 0 或 1。让我们看看如何进行转置,使得 a 移动到第三个位置,b 移动到第六个位置,c 移动到第九个位置,依此类推。
通过使用 4 个特殊表,每个表都有 256 个条目,可以实现转位。每个条目都是一个 32 位块或计算机字。第一个表显示了 32 位块的第一个字节中 8 位的转置位置,如下所示:

第二个表显示了 32 位块的第二个字节中 8 位的位置:

第三个表显示了 32 位块的第三个字节中 8 位的位置:

第四个表显示了 32 位块的第四个字节中 8 位的位置:

点的存在使你能够轻松看到 32 位的放置位置。它们代表计算机字中的零。现在可以通过查找这些特殊表中的 4 个字节并将四个结果 32 位块进行 OR 运算来实现转置,就像这样:

这不需要移位和掩码。整个 32 位的置换只使用了 4 个表查找和 3 个 OR 操作。这种技术的一个用途是翻转一个 8×8 位的块。这可以使用 8 个 256 个条目的表,或者只是一个单表来完成,将位移动到每个字节内的正确位置,就像这样:

11.2.4 短块
在 DES 和其他块密码中遇到的一个问题是如何处理短块。对于 DES,所有的块必须恰好有 8 个字符。假设您的消息有 803 个字符,即 100 个 8 个字符的块加上 3 个多余的字符。你如何处理那最后的 3 个字符?
传统的解决方案是用空值填充最后一个块。使用纸和笔密码学时,一些常用的技术是在最后 5 个字符附加 XXXXX 或 NULLS。不幸的是,这给了 Emily 5 个已知明文字母。对于手动密码的一些更好的解决方案是使用标记,比如 XX 或 JQ,然后将剩余的填充字符随机选择,比如 XXESV,或者简单地使用任意组合的低频字符进行填充,比如 ZPGWV。解密取决于 Riva 能否识别真实消息的结束和填充的开始。
在计算机中,填充必须解决两个问题。首先,Riva 必须能够确定消息的结束位置,或者等效地说,填充有多少字节。其次,Sandra 希望尽可能少地给出已知明文。一些提议的方案在这两个方面都失败了。例如,有一种方案建议在消息的末尾填充以下内容之一:

当块大小为 32 时,这可能会给出高达 31 个字节的已知明文给 Emily。在一般文件中,最后一个块可以是以 01 结尾的完整块,甚至是 02 02,这可能会被误认为是填充。
更好的解决方案是在明文文件中的某个位置放置一个长度字段。这不必是文件中的字节数,这可能需要一个 4 字节的长度字段,它可以是最后一个块中填充字节的数量。对于 DES,这是一个从 0 到 7 的数字,因此只需要 3 位。长度字段可以放在文件的任何位置。最常见的地方是第一个字节、最后一个字节和最后一个块的第一个字节。填充字节本身可以随机选择。
为了避免给 Emily 甚至一个字节的已知明文,长度可以编码为长度指示符的低位或高位比特,并且其余未使用的比特可以是随机的。这样,长度指示符可以取值从 0 到 255。
顺便说一句,没有规定你必须在文件末尾填充。如果你想在文件开头、最后一个块的开头或第 13 个块的中间填充,随便你。只要桑德拉和里瓦同意,他们可以做任何他们认为会最大程度地阻碍艾米莉的事情。一种可能性是将填充字节分散开来。例如,如果文件需要 4 个填充字节,你可以将它们放在文件的第二、第四、第六和第八个块的末尾,只要里瓦能够知道添加了多少填充字节。
重叠方法是填充的一种替代方法。假设,再次,块大小 B 为 8,消息有 803 个字符,你将前 800 个字符加密为 8 个字符的 100 个块。然后你将第 796 到 803 个字符加密为第 101 个块。这样,消息的长度不会改变,但里瓦必须在解密第 100 个块之前解密第 101 个块。
11.3 矩阵乘法
我们将要看的下一个分组密码是高级加密标准(AES)。然而,AES 使用一种称为矩阵乘法的数学运算,这在本书中尚未涵盖。我在介绍中承诺会呈现每个需要的数学概念,因此我将在这里介绍矩阵乘法。这个概念在后面的几章中是必需的。除非你已经很熟悉矩阵乘法,最好不要跳过这部分。
矩阵只是一个称为标量的元素的矩形数组。一系列标量形成一个向量,因此矩阵的每一行和每一列都是一个向量。它们分别称为行向量和列向量。具有 m 行和 n 列的矩阵称为 m×n 矩阵。如果 m = n,则该矩阵称为方阵。这里是一个具有 3 行 5 列的矩阵 M 的示例,称为 3×5 矩阵。它有 15 个标量元素,用字母 a 到 o 表示。

在这个矩阵中,3 个行向量分别是[a,b,c,d,e],[f,g,h,i,j]和[k,l,m,n,o],5 个列向量分别是[a,f,k],[b,g,l],[c,h,m],[d,i,n]和[e,j,o]。矩阵的行从上到下编号,列从左到右编号。在 M 中找到的第 i 行第 j 列的元素表示为 M[ij],因此 M[11]是 a,M[15]是 e,M[31]是 k。
标量的类型包括整数、模 N 的整数、有理数、实数、复数和其他稍后描述的类型。矩阵乘法对于每种类型的数字都是相同的。
两个矩阵 X 和 Y 的乘积,记作 XY,是通过将 X 的行乘以 Y 的列得到的。让我们详细看看这是如何工作的。矩阵的行是向量,矩阵的列也是向量。长度相同的两个向量可以进行所谓的内积乘法,有时也称为点乘,因为向量乘法有时用 ● 点表示。这个操作将一个向量的元素与第二个向量的对应元素逐个相乘,然后取这些乘积的和。
假设第一个向量是 [a,b,c,d],第二个向量是 [e,f,g,h]。它们长度相同,都有 4 个元素,因此它们可以相乘。它们的内积是

设 X 和 Y 是 4×4 矩阵,P 是它们的乘积。也就是说,P = XY。假设 [a,b,c,d] 是 X 的第 i 行,[e,f,g,h] 是 Y 的第 j 列。它们的乘积记为 P[ij]。换句话说,第 i 行第 j 列的元素是 X 的第 i 行与 Y 的第 j 列的乘积。这可以用下标写成

对于其他矩阵大小也使用了类似的表达式。只要 b = c,大小为 a×b 和 c×d 的两个矩阵就可以相乘。
11.4 矩阵乘法
不,这个重复的章节标题并不是错误。除了数字之外,数学中还有许多其他可以进行加法和乘法的对象。一些例子包括向量、矩阵、多项式、四元数,以及更一般地,环的元素。甚至可以有矩阵的向量、多项式的矩阵等等。关于环的更多内容请参见第 15.6 至 15.8 节。矩阵乘法可以基于这些类型的元素及其乘法和加法规则。过程是相同的。你将 X 的第 i 行与 Y 的第 j 行进行内积,以得到乘积矩阵的第 i 行第 j 列的元素。
矩阵乘法不是交换的,这意味着当你将给定的方阵 X 与第二个方阵 A 左乘或右乘时通常会得到不同的结果。AX ≠ XA。这被称为方阵 X 左乘或右乘 A。
对于 AES,我们关注的是多项式的乘法和加法。我们在高中代数课上学过如何加和乘多项式。继续从事科学和工程职业的人可能仍然记得如何做。多项式也可以被除。这种除法可能会有余数,所以多项式也有与整数相同的模概念。(如果你想复习一下,可以回顾一下第 3.6 节。)
AES 中使用的标量乘法不是整数乘法,而是多项式乘法模另一个多项式。这可能是我们在这本面向普通读者的书中所能深入讨论的了。
11.5 高级加密标准(AES)
高级加密标准是一种新的分组密码,于 2001 年取代了 DES。最初被称为 Rijndael,以其发明者,比利时密码学家文森特·赖曼和乔安·达门命名。AES 最初有五种组合,包括 128 位或 256 位的块,以及 128 位、192 位或 256 位的密钥。然而,美国国家标准与技术研究院(NIST)确定了 128 位块大小的标准。轮数取决于密钥大小:128 位密钥为 10 轮,192 位密钥为 12 轮,256 位密钥为 14 轮。
每一轮使用一个由完整密钥中选择的 128 位组成的轮密钥,根据 密钥调度。在第一轮之前,执行初步操作 AddRoundKey,简单地将块与轮密钥进行异或运算。接下来的 9、11 或 13 轮中的每一轮都包括 4 个操作,SubBytes、ShiftRows、MixColumns 和 AddRoundKey。最后一轮没有 MixColumns 步骤。
将 128 位块视为字节的 4×4 矩阵,称为 列主序,这意味着字节是按列写入矩阵,而不是按行写入,如下所示:

每一轮中的第一步是 SubBytes。这是对每个字节分别执行的固定简单替换。替换被设计为高度非线性。线性性质在第 12.3.1 节中详细讨论。
下一步是 ShiftRows。这是一种置换,其中矩阵的行分别向左循环移动 0、1、2 和 3 个位置,像这样:

每轮的第三步,MixColumns,是矩阵乘法。这不是普通的整数矩阵乘法,如第 11.3 节所述。矩阵中的元素被视为多项式的系数。标量加法和乘法运算是在另一个多项式上做的多项式运算。所有这些都经过了精心设计,以便可以在硬件中快速执行这些操作。最后一轮省略了 MixColumns。
每一轮中的最后一步是 AddRoundKey。这只是块与由密钥调度确定的密钥部分进行位异或。
我发现最后的异或运算非常可疑。几位电气工程师告诉我,00 和 11 的异或产生的波形与 01 和 10 的异或产生的波形是不同的,因此窃听者可以分辨出两位的值。这可能向窃听者显示 128 位密钥。在进行高安全性加密时,我尽量避免使用异或运算。
当我被迫在加密结束时使用异或,例如当我正在实现一个标准化算法时,我确保每个密文位的位都被反转偶数次。我保留两个与块大小相同的随机位串 R1 和 R2,以及它们的异或 R3 = R1⊕R2。然后我首先将密文与 R1 进行异或,然后与 R2 进行异或,最后与 R3 进行异或。这将使位串恢复到其原始值,希望波形特征被抹去。
或者,您可以使用替换而不是异或来反转块的所有位。您需要这样做两次,因此您可以使用两个替换步骤来代替三个异或。如果您正在使用 AES,我强烈建议添加这个额外的最终步骤。
11.6 固定替换 vs. 带密钥替换
在本书的早期,所有替换都使用了使用关键字或数字密钥混合的字母表。本章中的密码,DES 和 AES,使用可以嵌入硬件 S 盒的固定替换。哪个更好?哪个更强大?
当您使用固定替换时,您可以使用复杂的数学来设计一个可以抵抗各种攻击的替换。例如,如果一些输出位与一些输入位有很强的相关性,那么 Emily 可以使用密码的统计攻击,例如我在第 8.2 节中对 Jefferson Wheel Cypher 使用的攻击。
不幸的是,固定替换对 Emily 来说是一个易受攻击的目标。她可以研究替换数月甚至数年,并可能发现设计师忽略的弱点。精心设计的替换往往具有数学规律性。替代物被表达为特定的数学函数。这本身可能是一个弱点,因为它为 Emily 提供了模拟您密码的捷径。
我更喜欢使用由可以为每条消息更改的密钥确定的替换。每个带有密钥的替换实例可能比固定替换更弱,但 Emily 无法利用这种弱点,因为她没有替换表供她研究。如果 Emily 设法获取明文,也许是通过间谍活动,她可能能够恢复替换并了解其弱点,但那时已经太迟了。了解弱点的唯一价值是解密消息并获取明文。如果 Emily 已经有了明文,那么密钥就不再有价值。这种弱点不会帮助她解密下一条消息,因为该消息将具有不同的密钥,因此如果有任何不同的弱点。
任何其他替换的实例,当字母表通过相同的方法混合但使用不同的密钥时,可能不会有相同的弱点。它可能具有相同类型的弱点,例如块的某些位和/或密钥的某些位与输出的某些位之间的相关性,但这些对于每个实例都是不同的位。
使用固定的 S 盒的一个论点是,它允许加密硬件的同步操作,其中一个消息紧跟另一个消息,没有间隙。使用混合字母可能需要暂停,而字母被混合。使用混合字母需要一个设置。如果可以并行混合字母,暂停可以被消除或至少减少。也就是说,下一条消息的字母可以在当前消息被加密或解密时被混合。或者,让用户混合字母,并将混合字母包含在长密钥的一部分中。
如果需要同步操作,并且并行混合字母不可行,则回退技术是对块进行与块大小相同的密钥进行两次 DES 或 AES 步骤前后的互斥。我称这种方法为XDESX或XAESX,视情况而定。这些互斥运算非常快速,并且提供了显著的安全性提升。总密钥大小为 184 位,比 3DES 大 16 位。我建议最终输出被反转两次以掩盖波形。
11.7 反身密码
反身密码是说“一个与自身相反的密码”的花哨说法。换句话说,加密和解密是相同的。如果使用反身密码(使用相同的密钥)进行两次加密,你将得到原始明文。这也被称为自反或自逆。我们已经见过一些反身密码。使用二进制密钥对明文进行异或运算是反身的(第 3.3 节)。Bazeries 类型 4 密码中的逐段反转置换(第 4.6.1 节)是反身的。翻转一个方阵,即将字符从左到右写入方形网格,然后从上到下读取,是反身的。以下是一个 3×3 方阵翻转的示例:

数学家称此操作为转置矩阵。由于在密码学中转置有不同的含义,我将称之为翻转矩阵。一个快速翻转矩阵的方法在第 11.2.3 节中已经描述过。
如果你正在硬件中构建你的密码,使用反身密码可以降低成本并简化操作。你的密码机不需要单独的加密和解密模式。
让我们看看如何构造一些类型的反身密码。
11.7.1 反身替换
在反身替换中,如果字母 X 变为 Y,那么 Y 必须变为 X。这意味着字母必须成对出现。要构造一个反身替换,首先列出所有字母或字符。选择任何一个字母,然后选择它的伙伴。划掉列表中的这些字母。然后选择另一个字母及其伙伴。划掉这些字母。继续这样做,直到大部分字母都成对出现。任何剩余的字母都是它们自己的逆。选择连续的字母可以使用数字密钥,就像 SkipMix 一样(第 5.2 节)。
可逆替换可以方便地用两行表示。顶部行的字母直接得到下面的替代,底部行的字母直接得到上面的替代。以下是使用关键词 WORDGAME 和 TULIP 形成的示例。在这个示例中,R 会变成 L,而 L 会变成 R。

换句话说,这个可逆替换的密钥是这个 2 行数组。
并非每个字母都必须与不同的字母配对。一些字母可能保持不变。这些被称为不变量或固定点。
可以通过相同的方法构造可逆的双字母替换。
11.7.2 可逆多表代换
要构造一个可逆的多表密码,只需使表格的每一行都是一个可逆替换。
11.7.3 可逆置换
如果消息被分成固定大小的块,那么构造可逆置换最容易。让我们假设。称固定块大小为 B。如果每个从位置 X 移动到位置 Y 的字母,位置 Y 的字母移动到位置 X,则置换是可逆的。换句话说,置换将由字母的成对交换组成。
要构造一个可逆置换,首先在列表中写下从 1 到 B 的数字。从列表中选择任意 2 个数字。它们是交换的第一对位置。从列表中删除这 2 个数字,并从列表中选择另一对数字。这是第二对。从列表中删除它们。继续这样做,直到列表最多只剩下 1 个数字。如果您选择在置换中有一些固定点,只需更早地停止配对。创建固定点的另一种方法是随机从列表中一次选择 2 个数字。如果这两个数字相同,那就成为一个固定点。
表示一般置换密码的一种方法是列出块中的所有位置,然后在它们下面显示它们的新位置。例如,

这是计算机使用的最佳格式。当一个人在进行置换时,将其折叠到半宽可能更方便,就像这样:

这是相同的置换,但是在一半的空间中。任何一种形式都可以用作置换的密钥。在这两种情况下,第一个位置的字母移动到第 13 个位置,而第 13 个位置的字母移动到第一个位置,第二个位置的字母移动到第 7 个位置,而第 7 个位置的字母移动到第二个位置,依此类推。
*11.7.4 可逆块密码
现在我们已经看到如何构造可逆替换和置换,我们准备将这些元素结合在一起制作一个可逆块密码。
此时,引入更多符号会有所帮助。设 M 是任意消息,可以是明文或密文。我们将将密码 C 应用于该消息表示为 CM。如果 D 是另一个密码,则将 D 应用于文本 CM 的表示为 DCM。这种表示看起来有点奇怪,因为 DCM 意味着先应用 C,然后是 D,但这很有效。你可以将 DCM 理解为 D(C(M)) 的简写。
DC 然后是通过使用 C 和 D 分别进行加密形成的密码。这个新密码被称为 D 和 C 的 组合。组合是一种将两个密码结合起来形成新密码的操作。(有些作者称之为 C 和 D 的 乘积,并用 C◦D 表示。)
例如,Bazeries 类型 4(第 4.6.1 节)将替换与转位结合起来。组合具有一个对于形成可逆密码而言很重要的数学属性:组合是结合的。这意味着如果 A、B 和 C 是密码,则 (AB)C = A(BC)。由于这个属性,多个密码的组合可以不带括号地写成 ABC 或甚至 ABCDEFGH。在这样的组合中可以插入括号而不改变结果。例如,ABCDEFGH 可以写成 A((BC)(DE))F(GH)。
令 I 代表 单位密码,即将每个明文转换为其本身的密码。也就是说,对于任何消息 M,IM = M。设 C 是任意密码。将其逆表示为 C’。(C 必须有一个逆,否则消息就无法阅读。)然后 CC’ = C’C = I。当 C = C’ 时,密码 C 是可逆的。
假设 T 是一个可逆密码,C 是任意密码。那么密码 CTC’ 就是一个可逆密码。这是因为

类似地,如果 A 和 B 是任意密码,则 BCTC’B’ 和 ABCTC’B’A’ 都是可逆密码,依此类推。
11.7.5 例子,多重翻转
让我们看一个名为 多重翻转 的可逆分组密码的示例。这个密码对 64 位分组进行操作,其形式为 ABCTC’B’A’,其中 A 和 C 是一般的多表密码,B 是对 64 位进行的列转置,T 是对 64 位方阵进行翻转。
密码 A 和 C 是周期为 8 的多表密码。也就是说,每个分组的每一行都有一个单独的字母表。每个密码的表格都将有 8 行,按顺序使用。没有用于选择表格行的密钥。相反,8 个密钥用于混合 8 个字母表。总共,A 和 C 需要 16 个不同的密钥,每个密钥可能是与 SkipMix 算法(第 5.2 节)一起使用的数字序列。我建议这 16 个密钥每个包含 3 到 8 个数字,每个数字的范围是 0 到 255。
Cipher B 是一种列置换密码,将 64 位块视为 4×16 网格,因此有 16! 种列的排列方式。64 位被写入网格,从左到右横穿行读出,从上到下竖直读出。列的顺序由一个关键字、关键短语或等效的 16 位数字字符串确定。
Poly triple flip 被评为 Ten.******
11.8 可变长度替换
块密码可以使用固定长度或可变长度替换来构建。VLA 和 VLB 是使用可变长度替换的块密码的示例。VLA 和 VLB 块密码都使用 128 位块,分别视为每个 32 位的 4 行。其思想是在行中使用可变长度替换,然后通过在列中执行 4 位替换来混合块。每个密码的密钥是用于混合标签集和 4 位替换的密钥。
VLA 和 VLB 使用相同长度的后标签替换,如第 10.5.1 节所述。因此,一个 4 位标签被一个 4 位替换所取代,一个 5 位标签被一个 5 位替换所取代,依此类推。这样,块中的每一行保持为恒定的 32 位长。每次替换后,新标签被移动到其行的末尾,并且行被左移以保持其在 4 字节边界上。标签应该平均长度至少为 6 位。
VLA 是更简单的版本。在每轮中,您首先对行的最左边(高位)进行 4 位替换。然后您对每行执行一次后标签替换,带有位移。这将重复 32 轮。整个加密使用 128 个可变长度替换和 32 个固定长度 4 位替换。这个密码评级为 Eight.
当平均标签长度为 6 位时,我建议 VLB 应该有 4 轮,每轮在第 1 行有 6 次替换步骤,在第 2 行有 7 次替换步骤,在第 3 行有 8 次替换步骤,在第 4 行有 9 次替换步骤。
列中的垂直替换应在第 1、2 和 3 轮之后进行。为了提高速度,不需要在每一列的每一轮都进行列替换。一个合理的选择是例如在第一轮后每 3 列进行一次替换,即在第 1,4,7, … ,31 列,在第 2 轮后在第 2,5,8, … ,32 列进行替换,在第 3 轮后在第 3,6,9, … ,30 列进行替换。
VLB 被评为 Ten,可能是具有这个评级的最快密码。它需要 120 个可变长度替换,带有位移,并且 32 个垂直 4 位替换,因此比 VLA 稍快。
11.9 波纹密码
Ripple 密码,也称为 wraparound 密码或 end-around 密码,是基于本章前面的密码完全不同原理的块密码。其基本思想是,块中的每个 8 位字符都用作加密其右侧的下一个字符的密钥。然后再用这个字符来加密下一个字符,依此类推,一直到块的长度结束并在结尾处环绕。也就是说,块中的最后一个字符用作加密第一个字符的密钥。Ripple 密码最适合软件实现,因为它们几乎不提供并行操作的机会。
有各种各样的 Ripple 密码。它们的块长度可以从 2 开始,长度可以周期性地或随机变化。我建议最小的块长度为 5 个字符,但你可能更喜欢从 8 开始。例如,你可以使用链接的数字生成器来选择块长度。当生成器产生数字 D 时,你可以使下一个块的长度为 D+5,或者可能是 D+8,甚至是 20-D。
块可以重叠。例如,你可以使用固定的块长度为 8,块从位置 1、6、11、16、… 每 5 个字符开始。最后一个块可以环绕到消息的开头。当消息长度为 20 时,最后一个块可以由字符 16、17、18、19、20、1、2、3 组成。
Ripple 密码纯粹是替换密码;它们根本不涉及置换。Ripple 密码的最简单形式是对每个连续的字符进行异或,因此 x[n] 被替换为 x[n-1]⊕x[n]。然后 x[n+1] 被替换为 x[n]⊕x[n+1],依此类推,通过整个块进行波动。
有很多种方法可以利用前一个字符来对下一个字符进行加密。下面是部分列表。这里 A、B 和 C 是简单的替换密码,P 是一般的多表密码。A(x)、B(x) 和 C(x) 分别表示用 A、B 和 C 加密的字符 x,而 P(k,x) 表示用密钥 k 选择表格中的行来加密 x。
| xor | 异或 | x[n] 被替换为 x[n-1]⊕x[n]。 |
|---|---|---|
| sxor | 替换和异或 | 有三种变体,x[n] 可以被替换为 A(x[n-1])⊕x[n],或者 x[n-1]⊕B(x[n]),或者 A(x[n-1])⊕B(x[n])。 |
| xors | 异或和替换 | x[n] 被替换为 A(x[n-1]⊕x[n])。 |
| add | 加法 | x[n] 被替换为 x[n-1]+x[n]。如常,加法为模 256。 |
| madd | 乘法和添加,也称为 线性替换 | x[n] 被替换为 px[n-1]+x[n],或者 x[n-1]+qx[n],或者 px[n-1]+qx[n],其中 p 可以是任意整数,q 可以是任意奇数。(如果你使用的字母表大小与 256 不同,q 必须与字母表大小互质。) |
| sadd | 替换和添加 | x[n] 被替换为 A(x[n-1])+x[n],或者 x[n-1]+B(x[n]) 或者 A(x[n-1])+B(x[n])。 |
| adds | 加法和替换 | x[n] 被替换为 A(x[n-1]+x[n])。 |
| poly | 通用多表替换 | x[n]被 P(x[n-1], x[n])替换。 |
由于xor或sxor可能会泄露有关其操作数的信息,我建议改用xors,这样在执行异或操作后进行简单替换以掩盖波形,即 A(x[n-1]⊕x[n])。
请注意,madd只是sadd的一个特例。也就是说,px[n-1]只是 A(x[n-1])的一个特定选择。madd的优点在于它不需要预先设置阶段来混合替换字母表。同样地,请注意 P(A(x[n-1]), B(x[n]))只是对表格的行和列进行排列,因此等同于 P(x[n-1], x[n]),只是使用了不同的表格。
这些涟漪方法中最强大的是poly,其中前一个字符 x[n-1]被用作选择用于加密 x[n]的表格中的行的关键。我将这种方法称为关键涟漪。这将需要一个 256×256 字节的表格。如果这太大了,可以通过在使用它作为密钥之前对 x[n-1]应用减少替换来将 x[n-1]减小到更小的范围。例如,x 可以被减小为 x mod 16,或者为(13x+5) mod 32。适当的减小范围是 0 到 15,0 到 31 和 0 到 63。如果 R 是减少替换,P 是多表替换,那么 x[n]将被 Q(R(x[n-1]),x[n])替换,其中 Q 是一个由 P 的表格顶部 16、32 或 64 行组成的减少表的多表密码。
如果您无法使用多表密码,也许是因为即使减少表格也使用了太多空间,或者因为设置时间太长,那么下一个最佳选择是使用 3 个简单替换。将 x[n]替换为 A(B(x[n-1])+C(x[n])或 A(B(x[n-1])⊕C(x[n])。这被称为空间-时间权衡。这 3 个简单替换可能比单个多表替换需要更长的时间,但它们将空间需求从 65,536 字节减少到 768 字节,减少了 98.8%。
涟漪密码不限于仅使用前一个字符来加密当前字符。如果愿意,可以回溯几个字符,例如用 A(x[n-i]⊕x[n])替换 x[n],其中 i 可以是小于块大小的任何值。也可以使用多个先前的字符,例如 x[n-2]+x[n-1]+x[n]或更一般地 x[n-j]+x[n-k]+x[n]。使用通用多表替换,x[n]可以被 P(x[n-4]⊕x[n-2],x[n])替换,或者 P(x[n-5],P(x[n-1],x[n]))或其他无限组合。
正如我提到的,可以使用任何块大小。替换可以从块中的任何字符开始,并在块中的任何字符结束,只要每个字符至少被替换一次。如果需要,您可以绕块走几次,从最后一个字符到第一个字符。甚至可以重叠超过 2 个块,或者使一个块完全位于另一个块或一组块内。块大小、块内的起始位置、要替换的字符数以及与前一个和/或后一个块的重叠可以固定,可以定期变化,也可以随机生成。
涟漪密码甚至可以进一步发展。一条消息可以使用几轮涟漪密码进行加密。在每一轮中,消息可以被分成不同大小的块,以便块边界很少或从不对齐,并且加密在块中的不同点开始和结束。这会产生马赛克甚至万花筒效果。
涟漪密码的变体太多,无法一一列举。这些密码的评级可以从四到十不等。以下是一些示例。简单的xor涟漪使用固定大小的块,进行 2 轮替换,从块的第一个字节开始,以最后一个字节结束,并且只使用前一个字节作为替换密钥,评级为四。使用不同大小块的sadd涟漪密码,从块中的可变位置开始,进行至少 3 轮替换,以可变位置结束,并且使用前一个字节作为替换密钥,评级为七。使用不同大小块的poly涟漪密码,从块中的可变位置开始,进行至少 3 轮替换,以可变位置结束,并且使用前一个字节加上另一个从块到块变化的字节作为替换密钥,评级为十。马赛克方法比单层方法更强大。
11.10 块链接
块链接是一种增强任何块密码的有价值工具。块链接意味着使用每个块来帮助加密下一个块。实际上,链接是一个在块上操作的涟漪密码,而不是在单个字符上操作。从第 N 块传递到第 N+1 块的字节组称为链向量。由于消息中的第一个块没有前驱,大多数链接方案使用初始化向量(IV)来加密第一个块,就好像它是从某个虚构的前身块的链向量一样。初始化向量可以从加密密钥派生,也可以被视为加密的附加密钥。
旁注:比特币和其他加密货币使用的块链接是密码学中使用的块链接的一种专门形式。这就是他们得到这个想法的地方。

最常见的链接形式是逐字符将链向量与下一块结合起来。结合字符的最常见方法是独占或。然而,在第 11.8 节中描述的任何结合方法都可以使用。这通常以四种模式之一进行。
| 模式 | 描述 |
|---|---|
| PP | 第 N 块的明文在加密第 N+1 块之前与第 N+1 块的明文组合。 |
| PC | 第 N 块的明文在加密第 N+1 块之后与第 N+1 块的密文结合。 |
| CP | 第 N 块的密文在加密第 N+1 块之前与第 N+1 块的明文组合在一起。 |
| CC | 第 N 块的密文在加密第 N+1 块之后与第 N+1 块的密文结合。 |
为了最大的强度,链接操作应该是累积的。首先,将第 N-1 块的链向量与第 N 块组合。这个结果成为新的链向量,与第 N+1 块组合。链接模式 PP 最强,链接模式 PC 次之。模式 CP 和 CC 远远较弱,因为艾米丽可以看到链向量。我建议只有在使用 xors、adds 和 poly 这些组合函数时才使用模式 CP 和 CC。
虽然 CC 和 CP 模式较弱,但使用它们有优势。在 CC 和 CP 模式下,无需单独的初始化向量。桑德拉可以使用明文消息的最后一个块作为初始化向量。瑞娃可以简单地先解密最后一个块。事实上,瑞娃可以解密任何块,而无需解密前一个块。如果密码使用指示符(第 14.3 节),则这可能非常有价值。瑞娃会首先解密指示块。
让我们来看一些更强的块链接方式。
11.10.1 多表链接
独占或(Exclusive-OR)是一种将第 N 块与第 N+1 块结合的弱方法。一种更好的方法是 xors,即首先使用独占或,然后对结果字符进行简单的替换。比那更好的是使用 poly,一种通用的多表密码。使用链向量中的每个字符作为密钥,选择用于加密第 N+1 块中相应字符的表中的行。可以使用任何 4 种链接模式。模式 PP 最强大。
11.10.2 加密链接
链接的标准模式将第 N 块的明文或密文作为链向量使用,不进行修改。将某些加密应用于链向量会更强大。这可以是简单的,如简单的替换或分段反转(第 4.6 节)。如果替换或置换对于每个块都不同,这种简单的方法可能是有效的。钥匙脉冲很适合这个目的(第 11.8 节)。用于链向量的加密应具有自己独立的密钥。如果链向量更强加密,模式 CC 和 CP 将不再是弱项。
11.10.3 拖延链接
链接不仅限于前一个块。链接还可以利用更早的块。块 N 可以与块 N-i 或多个先前的块组合,例如块 N-i 和块 N-j。如果 i > j,则需要 i 个块的初始化向量。
同样,链接向量可以跨越多个先前的块。例如,链接向量可以来自第 N-2 块的后半部分和第 N-1 块的前半部分。
11.10.4 内部 tap
使用明文或密文作为链接向量的一个弱点是,这些内容可能为 Emily 所知。一个解决方案是对链接向量进行加密,如第 11.10.2 节所述。第二个解决方案是从块加密的某个中间轮获取链接向量。这称为 tap。例如,如果块密码有 10 轮,您可以使用第 5 轮的输出作为链接向量。在开始加密下一个块之前,将此链接向量与下一个块的明文组合。这是模式 IP。
这可以进一步发展。您可以使用多个 tap,它们可以与以下块的多个位置组合,可以与明文、密文或加密的轮之间组合。每个 tap 产生一个单独的链接向量,因此对于 N 个 tap,您必须有 N 个初始化向量。这些链接向量可以使用相同的密钥加密,或者每个都可以有自己独立的密钥。涟漪密码(第 11.8 节)非常适合加密链接向量。
11.10.5 密钥链接
通常,链接是在每个块的文本上进行的。但是,也可以将链接与密钥一起使用。假设您有一个块密码,其中每个块都使用相同的密钥 K。通过链接,可以极大地增强该密码。您使用 K 作为密钥对第一个块进行加密(初始化向量对于密钥链接是可选的)。然后,您可以使用 K●P[1]、K●C[1] 或 K●I[1] 作为密钥对第二个块进行加密,其中 ● 表示逐字节执行的某种组合函数,例如 xors 或 adds。同样,您可以使用 K●P[2]、K●C[2] 或 K●I[2] 作为密钥对第三个块进行加密,依此类推。这给您带来了三种新的链接模式,PK、CK 和 IK。可以同时使用密钥链接和块链接,例如 PK 与 IP。这是一种非常强大的组合。
11.10.6 链接模式总结
总共有 12 种可能的链接模式。链接向量可以来自三个来源之一:明文、内部阶段或当前块的密文。链接向量可以与四个目标之一结合使用:密钥、明文、内部阶段或下一个块的密文。
除了这些选择之外,链向量可以每次都新生成,也可以与前一个分组的链向量合并。链向量可以原样使用,也可以在与目标合并之前加密。链接可以作用于连续的分组,也可以滞后。有很多很多选择。
11.10.7 链接短分组
当消息中的最后一个分组较短,并且您使用重叠方法(11.2.4 节)来处理短分组时,不清楚如何链接重叠的分组。解决方法是从倒数第二个分组开始链接。如果有 N 个分组,则从第 N-2 个分组的链接向量用于第 N-1 个分组和第 N 个分组。
11.10.8 链接可变长度分组
在我们离开分组链接主题之前,还有一个问题需要解决,即可变分组大小。我建议链向量保持固定长度。如果消息分组的长度 L 小于链向量的长度,则将链向量的前 L 个字节与消息分组结合。替换链向量的这些 L 个字节,保持其余部分不变。例如,如果链向量为 1234567890,而分组为 SAMPLE,则将 123456 与 SAMPLE 结合。如果结果是 ZQm”w+,则分组变为 ZQm”w+,链向量变为 ZQm”w+7890。

如果链接向量短于消息分组,则使用所需数量的自身副本扩展此分组的链接向量。例如,如果链接向量为 123456,而分组为 CONVENTION,则将 1234561234 与 CONVENTION 结合。如果结果是 qA&Vm!7^oS,则分组变为 qA&Vm!7^oS,链接向量变为 qA&Vm!。

在两种情况下,分组在链接后仍保持相同的长度,链向量也保持相同的长度。
11.11 加强分组密码
一旦您拥有了强大的分组密码,就可以通过很少的额外工作进一步加固它。所需的只是在应用分组密码之前轻微地加密明文,并在完成分组密码后轻微地加密密文。我称之为三明治技术,额外的步骤称为预加密和后加密步骤。如果你感觉顽皮,你可以称之为鲁宾三明治。所谓“轻微地”,我是指使用简单的一轮一步密码,例如简单替换或密钥置换(7.6 节)。例如,您可以在分组密码之前使用简单替换,之后使用密钥置换,或者反之亦然。一种更强大但更快速的选择是将分组的前 8 个字节视为两个 32 位整数,并将每个整数乘以范围在 3 到 2³²-1 的奇数乘数模 2³²。
由于块密码已经足够强大,这些额外步骤的主要目的是增加总键大小,以阻止暴力破解攻击和中间人攻击。这在预密码和后密码步骤具有长键且与块密码键独立的情况下效果最佳。例如,如果预密码或后密码是简单的替代,它可能具有长的 SkipMix 密钥。
作为一个实际的例子,DES 使用了一个小的 56 位密钥。如果您添加了简单的替换预密码和后密码步骤,每个步骤都有一个独立的 64 位混合密钥,那么总密钥大小将达到 184 位。这比 3DES 更强大,几乎快 3 倍。
DES,然而,是没有任何设置阶段的设计。预密码可以轻松完成,没有设置。只需将一个 64 位的预密码密钥与明文进行异或运算。这将总键大小从 56 位增加到 120 位。这单独就比 2DES 更强大,更抵抗中间人攻击。后密码步骤有点棘手。我们希望避免使用异或作为最后一步,原因前面已经讨论过,并且我们也不想有设置。这可以通过使用固定的多表密码来实现。也就是说,表格是事先选择并内置到设备或软件中。
一个可能性是使用 16×16 的 4 位组表。64 位块被视为十六个 4 位组。每个 4 位组使用 64 位后密码键的 4 位进行加密。因此,总键大小再次为 184 位。这也比 3DES 更强大,几乎快 3 倍。
这种方法有效的原因是 DES 本身已经足够强大,以至于唯一实际的攻击是暴力破解。将额外的 128 位添加到密钥使暴力破解变得不可行。
第十二章:安全加密的原则
本章涵盖
-
安全加密的五个原则
-
大块和长密钥
-
混淆或非线性
-
扩散和饱和
让我们将在第十一章学到的一切汇总起来。在 12.1 到 12.5 节中,我们将概括出使块密码安全的 5 个基本原则。安全块密码的一个标志是,改变密钥中的任何位或明文中的任何位将导致密文块中约 50%的位发生变化,最好是以看似随机的模式。改变任何其他位也会导致密文块中约 50%的位发生变化,但是以不同的模式。让我们称之为五五开特性。本章将描述如何实现这一点。
12.1 大块
我们已经看到,双字母密码可以像简单替换密码一样解决,方法是编制双字母频率和接触频率。这也可以用于三字母和四字母,尽管需要大量的密文。对于手工完成的块密码,应考虑的最小块大小是 5 个字符。对于计算机密码,最小块大小是 8 字节。大块大小的一个目的是防止 Emily 像解码一样解决密码。也就是说,Emily 会找到重复的密文块,并从它们的频率和在消息中的位置推断它们的含义。以极端情况为例,如果块大小为 1 个字符,那么无论密钥有多大,使用了多少加密步骤,密码仍然只是一个简单的替换。
在英语中有许多 8 个字符的序列是足够常见的,以至于在长消息中会重复出现。以下是一打例子,使用省略号…表示空格。

如今的标准块大小是 16 字节。没有那么长的高频英文短语。可能会有一些长的上下文短语,比如 UNITED STATES GOVERNMENT,EXECUTIVE COMMITTEE,INTERNATIONAL WATERS 等等。然而,要产生重复的密文块,这些明文重复必须以相同的方式与块边界对齐。例如,16 字节的明文块 UNITED**…STATES…GO 和 NITED…STATES…**GOV 在使用强大的块密码时不会产生可识别的密文重复。
当您使用块链接(第 11.9 节)时,重复的密文块问题消失了。使用块链接时,可以使用任何大于等于 8 字节的块大小。
12.2 长密钥
我们知道,安全的密码必须具有一个大密钥以防止暴力破解攻击。当前的标准是 128 位密钥。如果您希望您的消息保密 20 年或更长时间,我建议最低使用 160 位。这相当于约 48 个十进制数字,40 个十六进制数字或 34 个单个字母。
如果你是手动输入密钥,我建议你以统一的方式构建你的密钥。用一致的格式将密钥分成相同大小的块。这里有两种统一结构密钥的样式。在第一种样式中,每个块中的所有字符都是相同类型的,大写字母、小写字母或数字。在第二种样式中,块的格式相同,有两个大写字母和三个数字。

这两个密钥中的第一个相当于约 191 位,第二个相当于约 174 位。对于这样长的密钥,你必须能够在输入时看到字符,以便在需要时进行复查和更正。当密钥完成时,应用程序应显示一个校验和,以便您验证密钥是否正确。
这种规律的一个好处是防止将字母 O 误认为数字 0,或者字母 I 误认为数字 1。我不建议随机混合字符,比如**KaTeX parse error: Expected 'EOF', got '}' at position 7: v94H;t}̲=Nd⁸**,因为这会导致错误…v94H;t}=Nd⁸加密了一个数据文件,然后你用密钥$V94H;t}=Nd⁸**解密它,那么该数据文件现在可能无法恢复。你可能永远都不知道出了什么问题以及如何解决。在你的密钥中使用统一的块有助于防止这种灾难发生。
另一种有助于防止输入错误的密钥形式是人工词。制造你自己的可以发音的字母组合,就像这样:

尽量避免模式,比如使用相同的元音组合,palek mafner vadel glabet之类的,所有单词都使用 A-E 元音模式。
这些字母数字密钥可以被软件转换成二进制形式。madd连锁密码(第 11.8 节)非常适合这个任务。
作为加密每条消息或数据文件的关键字的替代方案是使用一个关键字管理器,它生成关键字并将它们与消息或文件关联起来。关键字管理器可以安装在一个对桑德拉和里娃都可访问的网站上。这个话题不会在本书中涵盖。请注意,关键字管理器与密码管理器不同,因为桑德拉和里娃在不同的计算机上工作时必须为每个文件使用相同的关键字。
12.2.1 冗余密钥
在某些情况下,艾米丽可能会设计方程,将密文与明文和密钥相关联。如果艾米丽知道或能够猜测一些明文,这些方程可能使她能够确定密钥。例如,她可能知道一些消息以全大写字母 ATTENTION 开头。这可能足以使她在使用 8 字节块大小时解决 64 位密钥。
战胜这种潜在攻击的一种方法是扩大密钥。 例如,如果块大小为 64 位,但密钥大 32 位,即 96 位,则您可以期望,平均而言,会有大约 2³²个可能的密钥将已知的明文转换为密文。 艾米莉需要筛选这 2³²个解决方案以找到正确的解决方案。 这可能是一项困难的任务,因为超过 4,000,000,000 个可能性中的许多可能看起来像合理的文本。
扩大密钥会使艾米莉的任务变得更加困难,但不一定是不可能的。 如果她有两倍于已知明文的量,则可能使用两个密码块的方程式来解出密钥。 但是,拥有这么多已知明文是非常罕见的,解决两倍数量的方程可能需要的时间远远超过两倍。 根据艾米莉使用的方程式类型,解决一组 64 个方程可能是可行的,但解决一组 128 个方程可能是不可行的。
如果艾米莉没有可解的方程式,则冗余密钥可使暴力攻击变得更加困难和昂贵。 无论如何,冗余密钥都会使艾米莉工作更加艰难。
12.3 混淆
在 1945 年,信息论创始人克劳德·香农描述了强密码必须具备的两个属性。 他称这些为混淆和扩散。 通过混淆,香农指的是明文和密文之间不应有强相关性。 同样,密钥和密文之间也不应有强相关性。 通过扩散,香农指的是密文的每一部分都应该依赖于明文的每一部分和密钥的每一部分。
我将添加到香农两个属性的第三个属性。 我称这个属性为饱和。 这个想法是衡量密文的每一位或每一字节如何依赖于明文的每一位或每一字节以及密钥的每一位或每一字节。 饱和度越高,密码就越强。 本节以及接下来的两节将详细讨论这三个属性,混淆、扩散和饱和。
在分组密码中有两种替换类型,固定和键入。 键入的替换是可变的,可以为每个消息甚至每个块更改。 在第 11.6 节中讨论了这些方法的利弊。 如果您决定使用键入的替换,或者如果您发现本节中的数学很困难,那么您可以直接跳转到第 12.4 节。 您可以使用在第 5.2 节和 12.3.7 节中描述的 SkipMix 算法构建您的混合字母表或表,然后使用伪随机数生成器选择跳过的顺序。
在香农的理解中,混淆基本上是线性与非线性的问题。 如果您的分组密码使用固定的字母表或表格,线性性质至关重要。 整个线性代数领域都建立在线性概念上。 线性性 这个术语来自解析几何学。 一条直线的方程是 ax+by = c,其中 a、b 和 c 是常数,变量 x 和 y 表示直线上某点的笛卡尔坐标。 如果直线不与 y 轴平行,方程可以表示为 y = ax+b。 ax+by = c 和 y = ax+b 都是线性方程或线性关系的例子。
凯撒密码(第 4.2 节)是线性密码的一个例子。 凯撒密码可以被看作是将密钥加到明文上以获得密文,c = p+k。 这里 c 是密文字母,p 是明文字母,k 是密钥。 密钥是字母已经移动的量。 凯撒大帝使用了一个移位为 3 位的密码,这意味着字母表中的每个字母都被替换为后面 3 位的字母,c = p+3,字母接近字母表末尾的位置将被移到字母表的开头。
顺便说一句,凯撒的方法并不像听起来那样脆弱,因为凯撒用希腊字母写他的信息。 在凯撒时代,受过良好教育的上层罗马人,如凯撒及其将军,懂希腊语,就像 19 世纪的上层英国人学习拉丁语和贵族俄罗斯人说法语一样。
在涉及替换步骤和置换步骤的分组密码中,如果单个替换是非线性的,则整个密码是非线性的。 实际上,如果分组密码有多轮替换,那么只要有一个早期轮次是非线性的,整个密码就是非线性的,前提是该轮次涉及块中的所有单元。 一旦失去了线性性质,就无法在后来的轮次中重新获得它。 让每一轮都是非线性的将会更加强大,但是即使只有一个非线性轮次,特别是如果它出现在开始位置,也比没有强。
有线性和非线性的程度。 替换可以是高度线性的、弱线性的、弱非线性的或高度非线性的。 每种情况的一个例子应该可以说明问题。 我已经在明文字母表中的每个字母位置与密文字母表中的对应位置之间画了一条线。 你可以立即看到,随着替换变得更加非线性,字母表的混合程度有多好。

在接下来的讨论中,我将 S 盒的输入称为明文和密钥,将输出称为密文。这些术语指的是该单个 S 盒的明文和密文,并不一定是整个多轮分组密码的明文和密文。在某些分组密码中,S 盒没有密钥,它们仅执行简单的替换。在这种情况下,你可以想象 S 盒具有一个密钥,其常量值为 0,或者 S 盒密钥的长度为 0 位。
假设 Emily 能够测试 S 盒的线性度,因为密码已经发表,或者她已经获得了该设备的副本。如果 Emily 所拥有的仅仅是第一轮的输入和最后一轮的输出,那么线性度测试可能就不可行了。
12.3.1 相关系数
有一种既定的统计方法用于测试两个数值变量之间的相关性。例如,你可以测试温度和阳光之间的相关性,温度以摄氏度度量,阳光以小时为单位度量。温度和小时是数值变量。你可以进行多次试验,在某个固定的时间测量温度,并记录那天的阳光小时数。这将为你提供两个数字列表,一个列表用于温度,另一个列表用于相应的阳光小时数。该统计量衡量这两个数字列表之间的相关性。
在我们的情况下,两个变量是明文字母和密文字母。“试验"是字母在字母表中的位置。例如,第一个试验可以是"A”,最后一个试验可以是"Z"。字母表中的字母需要以某种方式编号。编号将取决于字母表的大小。例如,一个 27 个字母的字母表可以使用 3 个三进制(基数 3)数字编号,就像我们在第 9.9 节中对三肽密码所做的那样。相关性可以是明文字母的任何三进制数字与密文字母的任何三进制数字之间的相关性。在接下来的两节中,我将详细讨论这一点,分别讨论 26 个字母的字母表和 256 个字符的字母表。
线性度通过计算两个变量之间的相关性来衡量。到目前为止,最广泛使用的相关性度量是由英国数学家卡尔·皮尔逊(Karl Pearson)开发的皮尔逊积差相关系数,他是生物统计学的奠基人,并于 1895 年发表,尽管这个公式本身在 1844 年由法国物理学家奥古斯特·布拉维斯(Auguste Bravais)发布,他以晶体学的工作而闻名。相关系数的目的是得到一个单一的数字,告诉我们两个变量的相关程度,这个数字的含义不受测量单位或所涉及的数字大小的影响。
如果两个变量具有线性关系,则相关性为 1。如果变量之间没有任何相关性,则相关性为 0。如果两者具有反向关系,则相关性为-1。例如,抛硬币 20 次中正面朝上的次数与反面朝上的次数将具有反向关系。相关性为 0.8 表示强烈的线性关系,而相关性为 0.2 表示关系高度非线性。
与大多数教科书一样,我不仅仅是呈现公式,我将解释它是如何以及为什么有效的。理解它的工作原理将帮助您正确和适当地使用它。
这里的目标是比较两个变量。这是通过比较一系列试验中的值来完成的。例如,我们可能想比较在伊斯法罕的凯萨里耶巴扎尔出售的魔毯价格与其尺寸。影响魔毯价格的因素有很多,包括纱线类型、结的密度、设计的复杂性,当然还有飞行速度。
居中
比较变量的第一步是将它们并排放置,就像您通过视觉比较它们一样。换句话说,您希望消除线性关系 P = mA+x 中的+x 项,其中 P 是价格,A 是面积。看起来您可以计算差值 P[i]-A[i],然后从 P 中减去平均差值。然而,这是没有意义的,因为 P 和 A 是以不同单位表示的。地毯面积 A 以平方阿尔萨尼(大约一米)为单位,而巴扎尔中的地毯价格 P 以图曼(波斯货币)计价。
您需要分别调整面积数字和价格数字,因为它们是以不同单位表示的。诀窍是取平均价格并从所有价格数字中减去以获得新的调整后的价格数字 P’。您通过将地毯价格相加并除以地毯数量来计算平均价格μ[P]。例如,如果价格分别为 1000、1200 和 1700 图曼,您将把这 3 个价格相加 1000+1200+1700,然后除以 3 得到平均价格 1300。您将从每个价格中减去 1300 以获得调整后的价格-300、-100 和 400。正如您所看到的,调整后的价格 P’相加为 0。在某种意义上,调整后的价格围绕 0 居中。
区域图形以相同的方式居中。您将所有区域相加,然后除以地毯数量得到平均面积。例如,如果面积分别为 10、12 和 17 平方阿尔萨尼,您将把这 3 个面积相加 10+12+17,然后除以 3 得到平均面积 13。然后,您将从每个面积中减去 13 以获得调整后的面积-3、-1 和 4。调整后的面积 A’也相加为 0。现在,调整后的面积和调整后的价格都围绕 0 居中。它们并排放置,准备进行比较。

缩放
下一步是将价格和面积放在同一尺度上。价格是以土曼为单位的,面积是以平方阿尔萨尼为单位的,而从土曼到平方阿尔萨尼的转换是不存在的。那就像是从蒲式耳到摄氏度的转换一样。皮尔逊,或者更确切地说是布拉维,使用了线性代数中的一个概念,称为归一化。
假设你有一个向量(a,b),你想找到一个指向同一方向的向量,但长度为 1。任何向量(a,b)的倍数,比如(ma,mb),都会指向同一方向。乘以一个向量会改变它的长度,但不会改变它的方向。如果你将向量除以它的长度,新向量(a/L,b/L)的长度将为 1,并且方向与原始向量相同。这也清除了单位。想象一下,向量的长度是用英尺来衡量的。如果你将向量除以它的长度,那么你得到的就是英尺除以英尺。结果只是一个数字,没有单位。它是无量纲的。当向量用土曼或平方阿尔萨尼来衡量时,情况也是如此。
向量的长度可以很容易地通过使用勾股定理找到,L = √(a² + b²)。这可以扩展到任意维度,L = √(a² + b² + c² + …)。让我们试一个例子来看看这是否有效。尝试向量(3,4)。这个向量的长度是 √(3² + 4²) = √(9 + 16) = √25 = 5。归一化向量是 (3/5,4/5)。因此 √((3/5)² + (4/5)²) = √(9/25 + 16/25) = √25/25 = 1 是归一化向量的长度,如预期的那样。它有效。
P、A、P’ 和 A’ 都是数字列表,因此它们是向量。它们像任何向量一样有长度,并且可以像任何向量一样归一化。在几何学中,通过将向量除以其长度来归一化向量。任何归一化向量的长度始终为 1。
要将 P’ 归一化,你只需对所有调整后的价格进行平方,然后将这些平方相加并取这个和的平方根。这给出了 P’ 的长度。将调整后的价格 P’ 除以长度得到归一化价格 P’‘。要将 A’ 归一化,你只需对所有调整后的面积进行平方,然后将这些平方相加并取这个和的平方根。这给出了 A’ 的长度。将所有调整后的面积 A’ 除以长度得到归一化面积 A’'。

总结一下,(1)通过减去平均值来将价格和面积居中,然后(2)通过除以长度来归一化价格和面积。结果是一个标准化的价格列表和一个标准化的面积列表,其中每个列表中项的总和为 0,每个列表中项的平方和为 1。
现在我们准备好使用公式了。将价格的归一化列表中的每一项乘以面积的归一化列表中的相应项,即 P’‘[i]×A’'[i]。将这些乘积相加。这就是相关系数。(在线性代数中,这被称为归一化价格向量和归一化面积向量的内积或点积。)
让我们对此进行现实检验。想象我们正在测试摄氏温度和华氏温度之间的相关性。我们知道它们通过线性公式 F = 1.8C+32 相关,因此相关系数应该为 1。假设我们在上午 11 点、下午 3 点、晚上 7 点和 11 点测量温度,并发现摄氏温度分别为(14,24,6,0),华氏温度为(57.2,75.2,42.8,32)。摄氏温度的平均值为(14+24+6+0)/4 = 11,因此调整后的摄氏温度 C’ 为(3,13,-5,-11),对应的调整后的华氏温度 F’ 为(5.4,23.4,-9,-19.8)。摄氏温度 C’ 的长度为 18。将 C’ 除以 18 得到 C’‘,归一化后的摄氏温度(3/18,13/18,-5/18,-11/18)。调整后的华氏温度 F’ 的长度为 32.4,归一化后的华氏温度 F’’ 为(3/18,13/18,-5/18,-11/18)。
我们将 C’’ 逐个元素与 F’’ 相乘,然后将 4 个乘积相加以得到相关系数。这个和是(3/18)²+(13/18)²+(-5/18)²+(-11/18)²。总和为 1。这支持了先前描述的过程,即通过减去平均值进行居中,通过除以长度进行归一化,然后逐项相乘并求和,确实产生了有效的相关系数。
总结一下:通过计算相关系数来测试线性。本节向您展示了如何计算相关系数。计算结果为介于-1 和+1 之间的数字。以下是解释相关系数的图表。

12.3.2 基-26 线性
让我们从基于 26 个字符的字母表的替换开始调查线性。如果您正在设计机械或机电密码设备,或者正在模拟这样一个设备,这可能很有价值。这种机器中的每个转子都对一个包含 26 个字符的字母表进行替换。首先考虑一个没有密钥的 S-box。在使用 26 个字母表时,可能会出现多种形式的线性,这取决于字母的编号方式。可以从 3 种方式来看待字母表:将字母表视为一个 26 个字母的序列,将其视为一个 2×13 的字母数组,或者将其视为一个 13×2 的字母数组。这导致 3 种不同的字符编号方式:N1、N2 和 N3,如所示。对这 3 种编号方案的讨论使用模运算。如果您现在想复习模运算,请参阅第 3.6 节。

编号方案 N2 和 N3 遵循常规约定,使用字母 A、B 和 C 表示 9 以外的数字。也就是说,它们使用了 16 个十六进制数字中的前 13 个。在最简单的线性加密(Belaso 密码)中,密钥只是加到明文中。当将密钥加到明文字符中时,在 N1 编号方案中,它使用传统的模 26 加法。当将密钥加到 N2 编号方案中的明文字符时,第一个数字是模 2 加法,第二个数字是模 13 加法。相反,当将密钥加到 N3 编号方案中的明文字符时,第一个数字是模 13 加法,第二个数字是模 2 加法。以下是展示单词 THE 如何在每种方案中通过添加密钥 J 进行加密的示例。

如果纯文本、密钥和密文字母都使用 N1 方案编号,则线性替换或线性变换会将明文字符 p 转换成密文字符 c = mp+f(k),其中 m 是一个乘数,必须与 26 互质,f(k) 是任意整数值函数,算术运算是模 26 运算。例如,如果 m = 5,p = 10,k = 3,而 f(k) = k²+6,则 c = 13,因为 5×10+3²+6 = 65 ≡ 13 (mod 26)。常数 m 和函数 f(k) 可以构建到替换表中。
如果纯文本、密钥和密文字母都使用 N2 或 2×13 编号方案进行编号,则第一个数字或第二个数字或两个数字都可以是线性的。假设两个数字都是线性的。那么,一个明文字符 p = a,b 使用密钥 k 转换成密文字符 c = ma+f(k),nb+g(k),其中 m 必须与 2 互质,即 m = 1,n 必须与 13 互质,而 f(k) 和 g(k) 可以是任意整数值函数。分别进行模 2 和模 13 运算。常数 m 和 n,以及函数 f(k) 和 g(k) 可以构建到替换表中。
如果纯文本、密钥和密文字母都使用 N3 或 13×2 编号方案进行编号,则第一个数字或第二个数字或两个数字都可以是线性的。假设两个数字都是线性的。那么,一个明文字符 p = a,b 使用密钥 k 转换成密文字符 c = ma+f(k),nb+g(k),其中 m 必须与 13 互质,n 必须与 2 互质,即 n = 1,而 f(k) 和 g(k) 可以是任意整数值函数。分别进行模 13 和模 2 运算。常数 m 和 n,以及函数 f(k) 和 g(k),可以构建到替换表中。
平文和密文没有必要以相同的方式编号。在任何编号中,平文的任何数字与密文的任何数字之间都可能存在相关性。艾米莉可能会测试这些组合中的任何一个或全部,寻找可利用的弱点。因此,密码的设计者必须测试所有可能的编号和相关性,以验证没有这种弱点存在,或者了解必须采取哪些对策以防止艾米莉利用这种弱点。例如,您可以在分组密码的交替轮次中使用具有不同弱点的替换。在大多数情况下,每个替换都会减弱另一个的弱点。当然,您应该通过搜索明文和最终密文之间的线性关系来测试这一点,后者是由最后一轮产生的。
如果你想测试替换的线性性,就不能直接应用相关系数。这是因为所有这些替换都是使用模算术完成的。考虑一下使用 N1 编号方案进行的这种替换:

这几乎完全是 c = 2p,所以它非常线性。然而,使用该编号方案计算的明文和密文字母之间的相关系数为 0.55556,表明替换只是弱线性的。应该使用以下分布计算相关系数,该分布在模 26 下是等效的。

使用该编号的相关系数为 0.99987,正确显示了非常强的线性性。
这说明了在密码学中使用相关系数的困难。你总是在字母表的大小模下工作。要找到正确的相关性,你需要添加 26,然后是 52、78 等等,对于 N1 编号是这样,或者对于 N2 和 N3 编号是 13、26、39 等等。在前面的例子中,你需要开始添加 26 的地方是显而易见的。它是在密文编号变为22 24 1 3的地方。从 24 降到 1 就表明了这一点。
当密文字母表的线性性较低,即在一定程度上跳动时,可能更难以发现。例如,这种替换的相关性为 0.3265,具有中度非线性。

当通过这种方式调整时

相关性变为 0.9944,非常线性。我已经使用单个、双重和  下划线来显示在密文字符中添加了 26、52 和
下划线来显示在密文字符中添加了 26、52 和  ,分别对应的是明文字符。在此要注意的一个重要特征是,在密文字符 2 处添加了 26,对应于明文字符 5,但没有添加到后续的密文字符 21 和 25。同样,对于密文字符 1,添加了 52,对应于明文字符 14,但没有添加到后续的密文字符 24。
,分别对应的是明文字符。在此要注意的一个重要特征是,在密文字符 2 处添加了 26,对应于明文字符 5,但没有添加到后续的密文字符 21 和 25。同样,对于密文字符 1,添加了 52,对应于明文字符 14,但没有添加到后续的密文字符 24。
当密文字母接近线性时,确定要添加的 26 的倍数相当容易。当密文字母行为不良时,这变得更加困难。但是…那没关系。当替代是非线性的时候,这就是您需要知道的全部。相关系数是 0.01 还是 0.35 都没有关系。在任一情况下,没有足够的相关性供 Emily 利用。不要浪费时间计算精确值。
处理没有密钥的情况。现在假设有一个密钥。如果替代是线性的,那么它将具有形式 d§+f(k),其中 p 是明文,k 是密钥,d 和 f 是整数值函数。加法可以在任何 3 个编号方案 N1、N2 或 N3 中进行。在这种情况下,密钥在测试线性方面没有任何作用。f(k)只是添加到密文的常量。添加常量对相关系数没有影响,因为当您从每个值列表中减去均值(居中操作)时,它只是被再次减去。很容易测试替换 S(k,p)是否采用形式 d§+f(k)。只需选择两个密钥 k[1]和 k[2],并取差异 S(k[1],0)-S(k[2],0),S(k[1],1)-S(k[2],1),S(k[1],2)-S(k[2],2),…如果 S-box 具有形式 d§+f(k),那么所有这些差异将相等。如果您对所有可能的密钥重复这样做,那么您可以确定 S(k,p)具有所需的形式,并且您可以在不考虑密钥的情况下测试线性。
12.3.3 256 进制线性
对于 26 进制线性的分析只是对 256 进制线性的热身,因为在 256 进制中可能会发生两种不同的线性形式。我们称它们为串行和压缩。在串行线性中,每组位代表一个整数。例如,3 位组 000、001、010、…,111 表示数字 0、1、2、…,7。可以将两种形式的线性结合起来,以制作混合形式的线性。这在第 12.3.6 节中讨论。
串行线性是我们在 26 进制中看到的。在 26 进制中,N1、N2 和 N3 编号之间可能存在任何组合和任何顺序的相关性,因此必须测试许多成对是否具有线性。在 256 进制中有更多的可能性。串行线性可能存在于明文字母和/或密钥与密文字母中的任何位组之间。这些位组的大小不必相同。从明文中取出的 4 位组,覆盖范围从 0 到 15,可能与覆盖范围从 0 到 7 的 3 位密文组高度相关,因此可能的配对数量更多。
事情变得更糟,那个 4 位组中的 4 位可能是明文字节中的任意位。按顺序的位 7、2、5、1 和位 1、2、3、4 一样有效。线性替换可能将这 4 位加到密钥字节的 4 个不同位上,取模 16。可能的组合数量变得巨大。总之,明文字符和密钥字符中任何顺序的任何位组合都可能与密文字符中任何顺序的任何位组合线性相关。这是一大堆需要测试的相关性。
在你伸手拿阿司匹林或者龙舌兰酒之前,这里有个好消息。你可能不需要测试它们中的任何一个。除非密码是专门设计成从一轮传递到下一轮保持这些值不变,否则这些相关性不会有所影响。它们会随着每一轮的进行而逐渐削弱,以至于从初始明文到区块密码的最后一轮都不会被检测出来。
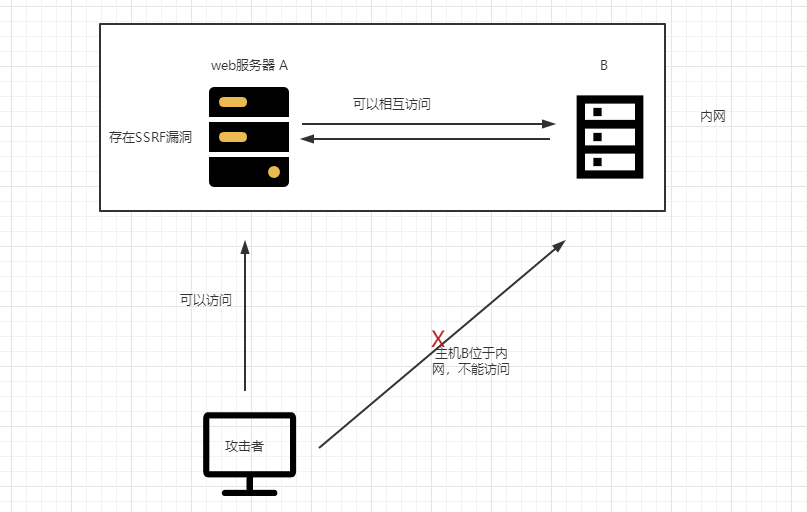
添加后门
你可能已经注意到我说了“可能”。例外情况是当你怀疑一个密码可能有后门时,也就是说,它已经被故意设计成让知道秘密的人可以在不知道密钥的情况下阅读消息。例如,一个国家间谍机构可能会向其特工提供一个带有后门的密码,以便该机构可以监视他们的消息并检测叛徒。
此时,让我们换个角色。假设你是 Z,被委派设计这个密码的间谍大师。你需要构建一个看起来和表现得像一个强大的区块密码的密码,这样用户就不会起疑。例如,你希望你的密码具有五十五的属性,即仅改变密钥或明文中的一个比特就会导致大约一半的密文比特以随机的模式改变。如果你的区块密码中的替代不都是线性的,那就是一个强大的区块密码的确切迹象。你希望你的假密码模仿这种属性。
这里有一种方法可以在密码中隐藏后门。它基于串行线性性,所以让我们称之为 后门串行 方法来构建密码,并让使用这种方法构建的密码称为 后门串行 密码。Z 可以阅读使用后门串行密码发送的消息,而无需知道密钥,但是对于不知道后门工作原理的任何人来说,它们看起来像是强大的、安全的区块密码。该方法分为三个部分:伪装、隐藏 和 伪装。
伪装
后门串行密码将对十六进制数字进行线性替换。明文块和密钥的每个块都被视为一个 4 位十六进制数字的序列。加密操作是在消息块和密钥的十六进制数字上进行的模 16 加法。假设字节中的两个十六进制数字是 p[1] 和 p[2],用于对它们进行加密的密钥的十六进制数字是 k[1] 和 k[2]。线性替换将 p[1] 和 p[2] 替换为

系数 a、b、c、d、e、f、g、h、i 和 j 可以是从 0 到 15 的任意整数,而 ag-fb 必须是奇数。如果您的密码有多轮,这 10 个值可以每轮不同。
这种线性替换易于 Emily 发现。特别是,每个十六进制数位的低阶位纯粹是线性的,因此对线性的简单位对位测试将找到它。为了避免检测,我们可以伪装十六进制数位。首先,按某种乱序列出十六进制数位,就像这样:

要将两个伪装的十六进制数位相加,您将它们在乱序列表中的位置相加,以获得总和在乱序列表中的位置。例如,要计算 1+2,您发现数字 1 在位置 9,数字 2 在位置 F,因此您将 9+F 模 16 得到 8。总和在列表中的位置 8。位置 8 中的数字是 D,因此 1+2 = D。
同样地,要将两个伪装的十六进制数位相乘,您将它们在乱序列表中的位置相乘,以获得乘积在乱序列表中的位置。例如,要计算 2×3,您注意到数字 2 在位置 F,数字 3 在位置 2,因此您将 F×2 模 16 得到 E。该产品位于列表中的位置 E。位置 E 中的数字是 7,所以 2×3 = 7。
本质上,伪装是对十六进制数位进行的简单替换。如果替换是非线性的,则没有一个位将在明文和密文之间具有线性关系。这种伪装的线性性质对于 Emily 来说要难得多,但是要真正迷惑 Emily,您可以隐藏伪装的十六进制数位。
隐蔽性
如果十六进制数的位始终是每个字节的块和密钥的位 1-4 和位 5-8,那么 Emily 仍有可能发现线性性。为了使 Emily 的任务真正艰难,您可以隐藏每个字节中的位。而不是使用明文的位(1,2,3,4)和密钥的位(1,2,3,4),并将结果总和放入密文的位(1,2,3,4),您可以按顺序使用明文的位(2,7,4,1)的十六进制数位,以及密钥的位(4,8,3,5),并将结果总和放入密文字节的位(8,6,1,7)。您可以选择任意顺序的 4 位的任何组合,只要每个字节中的 2 个十六进制数位都使用了所有 8 位。
为了明确起见,我们并不是说 Sandra 从每个字节中提取这些位,解密伪装的线性置换,执行算术,然后以不同顺序重新打包结果位。那样太慢了,而且 Emily 会清楚地知道发生了什么。相反,Sandra 在构建替代表时进行了这项工作。为了加密,她只需使用密钥字节选择表中的一行,然后对明文字节执行替代。所有的伪装和隐蔽都内置在替代表中。
伪装
到目前为止,所描述的密码仅仅是一个非常复杂的多表密码。Emily 可以使用第 5.8.3 节的技术解密消息。为了使后门序列密码看起来像一个强大的区块密码,你需要一些伪装来隐藏其核心的多表密码。
一种方法是在每一轮后对块应用位转置。这将使密码看起来像是一个置换-置换网络(第 11.1 节)。为了保留隐藏的线性性,组成每个十六进制数字的 4 位必须最终位于一个字节中。它们不必在该字节中的相同位位置,也不必是连续的,但它们必须在一个字节中。换句话说,输入的每个字节都被分成两个十六进制数字,这些数字以某种转置顺序被馈送到下一轮的两个其他字节中。不幸的是,如果 Emily 能够获得后门序列密码的发布规范,她很可能会发现这种类型的伪装。
让我们看看另一种更难于 Emily 揭示的伪装方式。这种方法借鉴了数据加密标准(DES)的一个想法(第 11.2 节)。每个密码块被分为两半。在每一轮中,首先使用左半部分作为密钥来加密右半部分,然后使用右半部分作为密钥来加密左半部分。我们已经看到了如何将线性性质伪装并隐藏在替代表中,所以让我们利用这一点来制造一个强大的区块密码的幻觉。
每轮密码会包括四个步骤。(1) 左半部分中的每个字节都使用一个字节的密钥进行加密。(2) 右半部分的每个字节都使用左半部分的一个字节作为密钥进行加密。(3) 右半部分中的每个字节都使用一个字节的密钥进行加密。(4) 左半部分的每个字节都使用右半部分的一个字节作为密钥进行加密。
为了使其看起来非常强大,每个块的每个字节应在每一轮中使用不同的密钥字节进行加密,并且每个块的一半的每个字节应在每一轮中使用来自另一半的不同字节进行加密。您可以通过在每一轮中对块中的字节和密钥中的字节进行洗牌来使其更加复杂。您可以使密钥比块更大,以展示更强大的印象。然而,密码仍然是线性的,因为在每一轮的每一步中都保持了线性性。
存储
让我们来看看后门串行密码的机制。在密钥的每个字节中,明文和密文中都有两个十六进制数字。每个数字可以占据字节的任何 4 位,以任何顺序。让我们称这组有序的 4 位为十六进制数字的位配置,并且字节中的 2 个十六进制数字的组合为字节配置。密钥通常不会更改配置,但是明文和密文的字节配置可以在加密的任何阶段更改。
对于每个替换,有 6 种位配置,2 种用于密钥,2 种用于明文,2 种用于密文。对于每个十六进制数字,16 个十六进制值的排列(乱序)也可以不同,因此对于每个替换,每个位配置和排列也有 6 种排列,2 种用于密钥,2 种用于明文,2 种用于密文。这种 6 种配置和 6 种排列的组合确定了替换表。对于每个不同的位配置和排列组合,都需要一个单独的替换表。
每个表格使用 65,536 字节,因此存储可能会成为问题。如果这是一个问题,我建议最多使用 2 字节配置,并且对于每个位配置最多使用 2 种不同的排列,也许可以在每一轮中交替使用。为了进一步减少所需的存储量,您可以考虑每次使用任何给定的位配置时都使用相同的排列。
12.3.5 精简线性
在大多数情况下,您将不会在密码中构建后门,也不会关注串行线性性。让我们把注意力转向第二种线性性,即压缩线性性。在这种线性性形式中,一组位通过将它们进行异或运算压缩为单个位。因此,000、011、101 或 110 将被压缩为 0,而 001、010、100 或 111 将被压缩为 1。明文和/或密钥的任何位组合都可能与每个 S-box 的密文的位组合相关。如果块密码使用异或将 S-box 的输出与块的其余部分结合在一起,则此线性性可以从一轮传递到另一轮,并且原始第一轮明文与最终最后一轮密文之间将存在线性关系。密码的设计者必须避免以这种方式使用异或,或者必须进行彻底的检查,以确保 S-box 不包含任何这样的线性性。
假设 S-box 接受一个 8 位明文并产生一个 8 位密文。从明文中选择一组位有 255 种不同的方式,同样地,从密文中选择一组位也有 255 种方式。(位的顺序并不重要,因为 a⊕b = b⊕a。)这使得有 255² = 65,025 种不同的组配对需要测试。每个测试都是 256 个明文值与 256 个密文值之间的相关性。即使在个人电脑上,这也是很容易实现的。
如果 S-box 接受一个 8 位明文加上一个 8 位密钥并产生一个 8 位密文,那么从明文加密钥中选择一组位有 65,535 种不同的方式,同样地从密文中选择一组位也有 255 种方式。这使得有 65,535×255 = 16,711,425 种不同的配对需要测试。这在个人电脑上需要花费一段时间,因为每个相关性都涉及所有 65,536 个明文和密钥组合。这是需要居中、缩放和求和的超过 10¹²个值。
这是谈论如何高效进行这些测试的理想时间。有一些技巧可以大大加快这个过程。 (1) 为了选择一组位,使用一个从每个字节中选择这些位的掩码。例如,如果你想要第 2、4 和 7 位,使用掩码 01010010,它在位位置 2、4 和 7 上有 1。将这个掩码与每个明文字节进行 AND 运算,以选择所需的位。 (2) 要尝试所有可能的位组合,不要逐个构造掩码,只需将掩码步进到所有值 1 到 255。 (3) 要压缩位,不要每次都使用移位和 XOR。只需执行一次并构建压缩值的表。然后,通过表查找可以将位组合压缩。如果有一组密钥位和明文位,这些位可以通过异或在一起,然后使用表来压缩,这样您只需要一次表查找而不是两次。
12.3.6 混合线性性
为了完整起见,我要提到可以有一种混合形式的线性性,将串行和压缩线性结合起来是可能的。假设你将每个 8 位字节分成四个 2 位组。这些 2 位组可以通过加法模 4 串行线性。你可以通过将它们模 4 相加来压缩两个或多个这些组。同样的操作也可以用于模 8 的 3 位组或模 16 的 4 位组。
让我们坚持使用 2 位组。每个组可以由字节中的任何 2 位组成。例如,一个字节可以分解为 4 个组,位 (6,1),(4,8),(2,5) 和 (7,3)。你可以通过将几个 2 位组相加模 4 或取任意的线性组合模 4 来压缩几个 2 位组为一个 2 位组。例如,如果 2 位组是 A、B、C 和 D,你可以将它们组合成一个新的 2 位组 pA+qB+rC+sD+t (mod 4),其中 p、q、r、s 和 t 是固定整数,范围为 0 到 3,其中至少有一个是奇数。
这些类型的压缩组可能与密文中类似的混合组或正常位组或密文中的压缩位组相关联。如果你想要绝对彻底,那么所有可能的线性组、压缩组和混合组的配对都需要进行相关性测试。
12.3.7 构建 S 盒
有三种构建具有良好非线性特性的 S 盒的方法:时钟方法,SkipMix 和 Meld8 方法。
时钟方法
在一张纸上,将字母按照顺时针均匀间隔地排列在一个大圆圈周围,就像时钟表盘上的数字一样。选择一个起始字母和一个第二个字母,并从第一个字母到第二个字母之间画一条直线。然后选择一个第三个字母,并从第二个字母到第三个字母之间画一条直线,依此类推。将每条线的 跨度 定义为从每个字母顺时针移动到下一个字母的字母位置数。例如,使用 26 个字母的字母表,从 C 到 D 的跨度是 1,从 D 到 C 的跨度是 25。为了使替换尽可能非线性,使每个跨度长度都不同。
下面是具体操作。为字母表中的每个字母制作一个列表,其中包含可能跟随它的所有字母。当你开始时,每个字母的列表都会包含其他每个字母,所以你会得到 26 个含有 25 个字母的列表。每次选择一个字母并将其添加到混合字母表中时,从所有列表中删除该字母。如果从前一个字母到该字母的跨度是 s,则还要从所有列表中删除任何跨度为 s 的其他字母。例如,假设你已经将 P 和 R 添加到字母表中。从 P 到 R 的跨度是 2 个位置,PQR。因此,在 A 列表中,你会删除 C,在 B 列表中,你会删除 D,在 C 列表中,你会删除 E,依此类推。
最终,一些列表会变为空。如果只有一个字母的列表为空,那么该字母将成为混合字母表中的最后一个字母。如果有两个空列表,那么你已经陷入了僵局。重新开始,或者回溯并再试一次。每次选择要添加到字母表中的下一个字母时,选择一个列表较短的字母,但不要选择一个空列表的字母,除非那是剩下的最后一个字母。
历史背景
这种启发式方法称为 Warnsdorff 规则,以 H. C. von Warnsdorff 的名字命名,他在 1823 年用于在棋盘上构建骑士之旅。1965 年左右,加州大学圣克鲁斯分校的 Ira Pohl 提出了一个向前看 2 步的改进版本。
这是一个通过时钟方法构建的字母表示例:

有 5 种不同的编号需要测试,以检查该字母表的线性性:N1 编号,N2 编号的第一和第二位数字,以及 N3 编号的第一和第二位数字。每个都必须与标准拉丁字母表的相同 5 个编号相关联,总共有 25 个相关性。你希望所有相关性都在-.5 和+.5 之间。最好的情况是它们都在-.333 和+.333 之间。
这些测试的结果如下,25 个相关系数。

正如你所看到的,所有相关性都在-.226 和+.288 之间,其中有 6 个落在-.1 和+.1 之间,因此时钟方法是构建非线性替换的绝佳方法。
并不保证每次都能获得如此好的结果。你仍然需要测试线性性。
SkipMix
在本节(12.3)的前面,我提到可以使用 SkipMix 算法(第 5.2 节)与伪随机数生成器构建字母表。一般来说,随机选择字母表不会导致良好的非线性特性,所以让我更详细地描述如何最好地使用 SkipMix。这次我将以 256 个字符的字母表为例进行说明。
一如既往,你首先列出 256 个可用字符。在 1 到 256 的范围内生成一个随机数以选择第一个字符。假设那是字母表中的第 54 位。取出该字符,然后从列表中删除它。现在剩下 255 个字符。在 1 到 255 的范围内生成一个随机数。假设该数字是 231。下一个位置将是 54+231 = 285。由于这大于 255,你减去 255 得到 30。从位置 30 取下一个字符,并从列表中删除它。现在你已经取了 2 个字符,剩下 254 个字符,所以你在 1 到 254 的范围内生成一个随机数。依此类推。
生成的字母表具有良好的非线性特性,因为您每次生成不同范围的随机数。这与时钟方法中使所有跨度不同的情况类似。这是通过 SkipMix 的这个版本生成的一个 26 个字母的字母表示例。

这可以像测试时钟字母一样进行测试。结果如下:

这些结果很好。所有相关性都介于 -.127 和 +.344 之间,其中 5 个介于 -.1 和 +.1 之间,但是它们不如时钟方法的结果好。
Meld8 方法
这种方法基本上是一种特殊用途的伪随机数生成器。我将假设您正在使用的计算机语言能够操作 64 位整数。根据大整数的表示方式,您可以处理 2⁶² 或 2⁶³ 的整数。为了谨慎起见,我将假设 2⁶²。第一步是选择两个数字,一个乘数 m,位于 24 到 26 位之间,和一个模数 N,位于 35 到 37 位之间。模数必须是素数。如果 m 是 N 的原根,则最好,但由于我尚未解释那是什么,所以只需使 m 和 N 都是素数。
通过将它们相乘来测试您选择的 m 和 N。如果结果大于 2⁶²,约为 4.611×10¹⁸,则使 m 或 N 中的一个较小。
要生成随机数,从 2 到 N-1 之间选择任何整数 s 作为种子。将种子乘以 m,并对 N 取模以获得第一个伪随机数。将第一个随机数乘以 m 并对 N 取模以获得第二个随机数,依此类推。这给了你一个范围为 1 到 N-1 的随机数序列。您将使用这些随机数来生成字母。
假设 N 有 36 位。从高位开始,将 N 的位编号从 1 到 36。取每个随机数的前 8 位,位于 1 到 8 位。从高位开始删除它们,并将它们与下一个 8 位,即 9 到 16 位,进行异或。这就是 Meld8 操作。它的目的是使字符序列非线性。以下是一个示例:

下一步是使用 28 位随机数生成一个字符。这取决于您是要构建一个 26 个字符还是一个 256 个字符的字母表。对于 26 个字符的字母表,将此数字乘以 26 并除以 2²⁸(或向右移动 28 位)以获得下一个字符。对于 256 个字符的字母表,只需除以 2²⁰,或向右移动 20 位以获得下一个字符。
从空字母表开始,每次添加一个字符。如果这是一个新字符,则将其追加到字母表中。如果这是一个重复字符,则将其丢弃。由于您没有连续的随机数,因此这也适用于使字母表非线性。以下是使用模数 N = 90392754973、乘数 m = 23165801 和种子 s = 217934 生成的此类字母表的示例:

结果相关系数为

相关性范围从-.170 到+.267,其中有 11 个落在-.1 和+.1 之间。这是三个示例中最好的,然而,基于每种技术的单个示例得出 Meld8 是最佳方法的结论是愚蠢的。始终进行测试。
12.3.8 带有密钥的 S 盒
在第 12.3.7 节中,我们处理了没有密钥的 S 盒。它们执行简单的替换。当使用密钥时,S 盒执行一般的多表替换(第 5.8.3 节)。S 盒可以被视为一个表,其中每一行都是一个混合字母表。可以通过使用时钟方法、SkipMix 或 Meld8 构建每个混合字母表来生成 S 盒,或者通过任何组合方法。
如果使用时钟方法或 SkipMix,请每次使用不同的随机种子。如果使用 Meld8,则可以每次使用相同的模数,但使用不同的种子和不同的乘数。一如既往,测试,测试,测试。你的目标是避免密钥和明文与密文的组合之间存在任何线性关系。如果结果不佳,即许多相关系数在-.35 到+.35 范围之外,也许只需替换一个行或交换两个行的表就能解决问题。
12.4 扩散
香农的第二个特性是扩散。这个想法是密文的每一位或每一字节都应该依赖于明文和密钥的每一位或每一字节。
为了说明这一点,让我们回到第 9.6 节中描述的 Delastelle 的 bifid 密码。为了提醒你,bifid 是基于 Polybius 方阵的分组密码。如果块大小为 S,则消息的每个字母将被两个基于 5 的数字替换,并且这些数字被垂直写入一个 2×S 网格并水平读出。然后这些数字对再使用相同或不同的 Polybius 方阵转换回字母。
让块大小为 7,并将明文块中的字母称为 A、B、C、D、E、F、G。让表示这些字母的数字为 aa,bb,cc,dd,ee,ff,gg。我没有写下标,因为这里不重要哪个数字先出现,哪个数字后出现。那么块将是

当字母水平读出时,你会得到 ab,cd,ef,ga,bc,de,fg。请注意,密文的每个字母都取决于明文的两个字母。第一个密文字母取决于 A 和 B,第二个字母取决于 C 和 D,依此类推。
在这一点上,我需要引入一种特殊的符号来显示每个密文字母依赖于哪些明文字母。如果一个密文字母依赖于明文字母 P、Q 和 R,则它被指定为 pqr。使用这种符号,如果你再次加密字母 A、B、C、D、E、F、G,块会像这样:

将这些字母水平读出,你会得到 abcd,efga,bcde,fgab,cdef,gabc,defg。由于数字的顺序无关紧要,这也可以表示为 abcd,aefg,bcde,abfg,cdef,abcg,defg。经过两次加密后,每个密文字母都依赖于四个明文字母。
如果您使用双密码加密这个区块第三次,那么每个密文字母将取决于所有 7 个明文字符。对于区块大小为 7 的双密码,需要三轮加密才能实现完全扩散。如果区块大小为 9、11、13 或 15,那么需要四轮加密。(请回忆一下,双密码中的区块大小应始终为奇数。)
一般来说,要测试扩散,您首先使每个明文字符或位仅依赖于自身。如果密码操作的是整个字节或字符,则根据字节跟踪扩散。如果它操作十六进制数字、其他基数的数字或者单个位,则根据这些单元跟踪扩散。对于双密码,单元是 Polybius 方格坐标,或者是基数为 5 的数字。
为了追踪扩散,您需要一种方式来表示明文单元和密钥单元在区块密码的轮次中随着流动的方式。当只有少数明文单元时,就像双密码示例一样,仅列出它们就能很好地工作。当明文、密钥和密文单元的数量较大时,可能需要更紧凑的表示。一个好的策略是为每个密文单元创建一个二进制向量。让我们称之为依赖向量。依赖向量的每个元素将对应于一个输入,即明文或密钥单元。如果密文单元取决于该输入单元,则该依赖元素的值为 1,否则为 0。
当两个或多个输入单元组合成一个输出单元时,它们的依赖向量将被 OR 运算在一起,形成输出单元的依赖向量。为了说明这是如何工作的,让我们再次使用这种符号通过双密码示例。最初,每个字符仅依赖于自身。这由向量表示

在第一次应用双密码后,每个结果字母都依赖于两个明文字母。第一轮输出字节依赖于第一轮输入字节的前两个字节,因此你将它们的依赖向量进行 OR 运算得到 1100000。第二个输出字母依赖于第三和第四个明文字母,因此你将它们的依赖向量进行 OR 运算得到 0011000,依此类推。第一轮输出由向量表示

在第二轮的双重转置之后,第一个输出字母取决于第一轮的第一个和第二个输出,所以你将它们的依赖向量进行 OR 运算 1100000∨0011000 得到 1111000。第二个输出字母取决于第一轮的第三个和第四个输出,所以你将它们的依赖向量进行 OR 运算 0000110∨1000001 得到 1000111,依此类推。经过两轮的双重转置后,每个字母都取决于四个明文字母,表示为

在第三轮的双重转置之后,每个输出字母都取决于第一轮明文的所有 7 个字母,例如,1111000∨1000111 就是 1111111。第三轮的输出表示为

每当遇到一个 S 盒时,输出单元的依赖向量是通过对贡献到该输出的每个输入的向量进行 OR 运算形成的。让我们看看在块密码中可能发生的其他情况。
如果两个单元进行异或运算,输出单元的依赖向量是通过对每个输入的向量进行 OR 运算形成的。当使用任何组合函数(如sxor或madd)将多个单元组合在一起时,也是如此。
当块的单元使用密钥进行转置时,每个输出单元都依赖于该密钥的所有单元,因此密钥的向量与每个输出单元的向量进行 OR 运算。
假设一个 S 盒是通过使用密钥混合其字母表而创建的。如果 S 盒是固定的或静态的,比如通过嵌入硬件来实现,那么混合密钥将不再参与其中。如果 S 盒是可变的,也许每次加密都使用不同的密钥进行混合,那么该 S 盒的输出单元将依赖于该密钥的所有单元。密钥的向量与每个输出单元的向量进行 OR 运算。
可以将扩散表示为一个单一数字。从所有输出单元的依赖向量构建一个矩阵。矩阵中的每一行代表块密码最终轮的一个输出单元。矩阵中的每一列代表一个输入单元,可以是密钥或明文。扩散的度量,或扩散指数,是矩阵中这些元素中为 1 的部分。如果矩阵中的元素都是 1,那么就有完全扩散,扩散指数为 1。如果 S 盒是非线性的且密钥很长,这表明块密码很强大。
扩散并非全部。有些有效的密码设计中,扩散指数可能小于 1,但密码仍然很强大。一个例子是每轮都有单独密钥的块密码。早期轮次的密钥可能实现完全扩散,但晚期轮次,尤其是最后一轮的密钥可能不会。然而,如果完全扩散的密钥包含您所需的位数,则该密码很可能是安全的,而部分扩散的密钥只是一种保险。
这里有一个示例,可能有助于说明即使扩散不完全,密码也可以很强大。考虑一个具有 12 轮的密码,每轮具有独立的 24 位密钥。在这个密码中,需要 6 轮才能实现完全扩散,因此经过 6 轮后,明文和第一轮密钥完全扩散。经过 7 轮后,明文和第一轮和第二轮密钥完全扩散。依此类推。经过 12 轮后,明文和前 7 轮的密钥完全扩散。使用 24 位轮密钥,这是 168 位完全扩散的密钥。如果您的目标强度是 128 位密钥位,那么您已经超过了目标。第 8 至 12 轮的部分扩散密钥是额外的奖励。
12.5 饱和
混淆和扩散是安全框架的两大支柱。为了确保分组密码建立在坚实的基础上,我建议添加第三支柱,我称之为饱和。扩散仅表示给定输出单元是否依赖于给定输入单元。饱和度衡量给定输出单元依赖于给定输入单元的程度。我展示了如何计算类似于前一节扩散指数的饱和指数。饱和实质上是扩散的更精细版本。通过扩散,依赖性只能具有 0 或 1 的值,但通过饱和,依赖性可以具有任何非负值。
这里是饱和的简要解释。假设分组密码 X 由几轮替换组成。在每一轮中,消息的每个字节都与密钥的一个字节进行异或运算,然后对结果进行简单的替换。假设每一轮中使用不同的密钥字节,以便每个密钥字节每次用于每个分组字节。密码 X 的饱和度会很低,因为每个密文字节仅依赖于每个密钥字节一次。要获得更高的饱和度,每个输出字节需要多次依赖于每个输入字节。
另一个示例可能有助于更清晰地说明。想象一个在 48 位块上运行的密码,视为六个 8 位字节。这个密码的每一轮包括两个步骤:(1)块向左循环移动一个位位置,因此最左边的位移动到最右边的位置,然后(2)对每个 8 字节执行简单的替换 S。第一轮后,第一个输出字节C1依赖于第一个明文字节的最后 7 位和第二个明文字节的第一个位,如下所示:

密文字符C1依赖于明文字节P1的 7 位和明文字节P2的 1 位。可以说C1对P1依赖 7/8,对P2依赖 1/8。
让我们看看第二轮。将第二轮输出称为D1 … D6。

密文字符 D1 对 C1 依赖程度为 7/8,对 C2 依赖程度为 1/8。在这里,C1 对 P1 依赖程度为 7/8,对 P2 依赖程度为 1/8,而 C2 对 P2 依赖程度为 7/8,对 P3 依赖程度为 1/8。P1 对 D1 的唯一贡献来自 C1。因为 D1 对 C1 的依赖程度为 7/8,C1 对 P1 的依赖程度为 7/8,因此可以合理地说 D1 对 P1 的依赖程度为 49/64。出于同样的原因,D1 对 P3 的依赖程度为 1/64。让我们称这些数字为 饱和系数,将这个计算称为 S1 计算,当存在单一依赖关系时。
图表可能会使配置更清晰。

P2 呢?D1 通过 C1 和 C2 从 P2 获取贡献。或许认为 D1 对 C1 的依赖程度为 7/8,对 P2 的依赖程度为 1/8,对 C2 的依赖程度为 1/8,而 C2 对 P2 的依赖程度为 7/8,因此 D1 对 P2 的依赖程度为 (7/8)(1/8)+(1/8)(7/8) = 14/64。这是一个合理的计算,它导致了扩散的更复杂版本。然而,使用这个计算,任何给定单位的总贡献总是 1。总数永远不会增长。如果这个计算重复多次,所有这些扩散数字将收敛到 1/48。这并不是饱和概念试图捕捉的内容。只要一个单位从多个不同的来源接收贡献,饱和度就应该增加。
当一个单位获得多个贡献时,使用不同的计算方法来确定饱和系数。假设两个来源的饱和系数分别为 a 和 b,其中 a ≥ b。那么合并后的饱和系数为 a+b/2。如果有三个贡献的饱和系数分别为 a、b 和 c,其中 a ≥ b ≥ c,那么合并后的饱和系数为 a+b/2+c/4。在每种情况下,组件饱和系数按降序排列,a ≥ b ≥ c ≥ d ≥ e… 。总之,当多个饱和系数被合并时,结果如下:

让我们称这个计算为 S2 计算,当存在多个依赖关系时使用 S2 计算。对于单一来源使用 S1 计算。
S2 计算可能看起来是临时的,甚至是古怪的,但它具有饱和计算所需的恰到好处的属性。首先,当一个单位依赖于多个前导时,它总是会增加。这是因为 a+b/2 总是大于 a。其次,它的增长速度不会太快。最多,饱和系数可以从一个回合翻倍到下一个回合。这是因为 a+a/2+a/4+…+a/2^n < 2a 对于任何 n 都成立。例如,1+1/2+1/4+1/8 = 15/8 = 1.875。
在当前情况下,D1依赖于P2,贡献系数分别为 7/8 和 1/8,因此组合系数为 7/8+(1/8)/2 = 15/16。 输出单元的饱和系数可以组成一个向量,就像扩散数一样。 因此,D1的饱和向量为(49/64, 15/16, 1/64, 0, 0, 0)。 然后,这些向量可以组成饱和矩阵。 饱和指数是饱和矩阵中最小的系数。
让我们看一个更现实的密码,这是文献中提出的一种密码,可能已经在实践中使用过。 我将其称为SFlip,简称Substitute and Flip。 它是第 11.7.5 节中多项式三次翻转的近亲。 如果您不记得矩阵翻转是什么意思,请参阅第 11.7 节。 SFlip 密码适用于一个 8 字节的块,并由几个轮次加上一个完成步骤组成。 每一轮都有两个步骤。(1)将简单的替换应用于八个 8 位字节。(2)8×8 比特位矩阵翻转。 完成步骤是再次为每个 8 位字节进行替换。
8×8 比特位矩阵需要一个 64×64 的依赖矩阵。 这个矩阵太大了,无法清晰显示,因此我将以微型形式显示密码。 让我们使用一个 3×3 的比特位矩阵,其具有 9×9 的依赖矩阵。 这个密码将被分析两次,一次使用扩散,一次使用饱和。 先进行扩散。 让我们从在文本块和依赖矩阵中标记比特位开始,就像这样:

在第一轮之前,每个比特位只依赖于自己,因此依赖矩阵看起来像(1)。 在第一轮替换之后,每个比特位依赖于其字符中的所有 3 位,因此依赖矩阵看起来像(2)。 在第一轮翻转之后,依赖矩阵看起来像(3)。 在第二轮替换之后,依赖矩阵看起来像(4)。

换句话说,此时密文的每一位都取决于明文的每一位。 这在第二轮翻转之后以及最后的替换之后仍然成立。 因此,如果我们仅依赖依赖计算,我们会得出结论,此密码在两轮后将是安全的。 这是不正确的。 阿迪·沙米尔已经证明两轮是不够的。
现在让我们使用饱和指数来分析 SFlip 密码。 在第一轮替换之后,密文的每个比特位都依赖于其对应的 3 个明文比特位中的 1/3。 饱和矩阵将看起来像(5)。 在第一轮翻转之后,饱和矩阵将看起来像(6)。

第二轮替换使得输出的每一位取决于第一轮明文的所有 9 位。饱和系数为 1/3+(1/3)/2+(1/3)/4 = 1/3+1/6+1/12 = 7/12,约为 0.583。饱和矩阵中的每个元素都将具有这个值,因此饱和指数将为 7/12。饱和指数的目标值为 1,尽管如果您想要更大的确定性,也可以将其设置得更高。以下是几轮后饱和指数的情况。

所以对于 3×3 密码,3 轮就足够了,但对于 8×8 密码,需要 5 轮。
现在让我们转向其他一些情况,其中输出单元取决于一个或多个输入单元。
当一个 S 盒同时具有明文和密钥输入时,例如 p 个明文单元和 k 个密钥单元,每个输出单元的依赖性将为 1/(p+k)。例如,如果输入为 6 个密钥位和 4 个明文位,则每个输出位的依赖性将为 1/10。如果 S 盒的输入本身依赖于先前的输入,则应根据需要使用 S1 或 S2 计算来计算饱和指数。
同样,如果使用异或或其他组合函数将两个或更多单元组合在一起,则依赖性为 n 个总输入的 1/n。计算饱和指数的方法与具有相同输入的 S 盒相同。
当使用 k 位密钥进行置换时,置换的每个输出单元对每个密钥位的依赖性为 1/k,并对明文输入的依赖性为 1。假设明文字符 p 通过置换从位置 a 移动到位置 b。置换后,p 的饱和向量将与置换前的饱和向量相同,除了那些对应于置换密钥位的列。在这些列中,饱和系数将由 S1 或 S2 计算确定。
这里有一个例子。假设 t 是置换密钥的位之一。如果 p 在置换之前对 t 没有依赖性,即其饱和向量的第 t 列为 0,则在置换之后,第 t 列的值将为 1/k。另一方面,如果 p 已经依赖于密钥位 t,则饱和系数将由 S2 计算确定。如果第 t 列中的系数为 x,则在置换之后,第 t 列中的饱和系数将为 x+1/2k(如果 x ≥ 1/k),或者为 1/k+x/2(如果 x < 1/k)。
当使用 k 位密钥来混合字母表或替代步骤的表时,混合的字母表或表对该密钥的每一位具有 1/k 的依赖性。每次使用该字母表替换一个字符时,输出字符对密钥的每一位都会增加 1/k 的依赖性。这与输入字符的依赖性(和替换密钥,如果有的话)结合使用 S1 或 S2 计算来获得输出字符的饱和系数。
摘要
如果一个块密码遵循所有这些规则,实际上是无法破解的:
-
它具有足够大的块大小。当前标准为 16 个字符或 128 位。
-
它具有足够大的密钥。当前标准为 128 到 256 位。密钥必须至少与块大小相同,最好更大。
-
要么使用强非线性的固定 S 盒,要么使用使用大密钥混合良好的可变替代表。
-
饱和指数至少为 1。
一如既往,要保守。建立一个安全的误差边界。使密钥更长,使用比所需更多的轮数,因为计算机变得更快,新攻击不断被发现。特别是,您可以将饱和指数的目标设定得比 1 更高,也许是 2、3 甚至 5。
第十三章:流密码
本章涵盖
-
伪随机数生成器
-
用于将随机数与消息组合的函数
-
生成真随机数
-
散列函数
流密码与分组密码相反。流密码中的字符在遇到时被加密,通常一次一个。基本概念是将一系列消息字符与一系列密钥字符结合起来,以产生一系列密文字符。这种范式非常适合连续操作,其中消息在一端持续加密和传输,另一端持续接收和解密,没有暂停,或者只有短暂的暂停来更换密钥。
我们已经看到了一些流密码。第 5.9 节中的自动密钥和流动密钥密码,第 5.10 节中的转子机器,第 10.4 节中的哈夫曼替换,以及第 10.7 节中基于文本压缩的密码都是流密码的示例。
13.1 组合函数
最常见的流密码类型使用一个密钥单元加密一个明文单元。这些单元通常是字母或字节,但十六进制数字甚至比特也可以使用。密钥单元与明文单元结合使用基本上与第 11.8 节中的涟漪密码使用的组合函数相同,但使用密钥单元代替前一个单元。以下是类似的方法,其中 x[n] 是消息的第 n 个单元,k[n] 是密钥的第 n 个单元,A 和 B 是简单的替换,P 是通用多表替换。替换 A、B 和 P 应该使用密钥混合,而不是固定或内置的。
| xor | 异或 | x[n] 被 k[n]⊕x[n] 替换。 |
|---|---|---|
| sxor | 替换并异或 | 有三种变体:x[n] 可以被 A(k[n])⊕x[n] 替换,或者 k[n]⊕B(x[n]) 或 A(k[n])⊕B(x[n])。也就是说,你可以替换 k[n] 或 x[n] 或两者都替换。(在已知明文的情况下,使用 A(k[n]) 而不是 k[n] 可以防止 Emily 恢复伪随机序列。) |
| xors | 异或并替换 | x[n] 被 A(k[n]⊕x[n]) 替换。 |
| add | 相加 | x[n] 被 k[n]+x[n] 替换。如常,加法是对字母表大小取模的。 |
| madd | 乘以并相加 | 也称为线性替换。x[n] 被 pk[n]+x[n] 替换,或者 k[n]+qx[n],或者 pk[n]+qx[n],其中 p 可以是任意整数,q 可以是任意奇整数。(如果你使用的字母表大小与 256 不同,q 必须与该大小互质。) |
| sadd | 替换并相加 | x[n] 被 A(k[n])+x[n] 替换,或者 k[n]+B(x[n]) 或 A(k[n])+B(x[n])。 |
| adds | 相加并替换 | x[n] 被 A(k[n]+x[n]) 替换。 |
| poly | 通用多表替换 | x[n] 被 P(k[n], x[n]) 替换。 |
由于xor或sxor可能会泄露关于其操作数的信息,我建议改用xors,这样在执行异或操作后进行简单替换以掩盖波形,即 A(k[n]⊕x[n])。
流密码也可以使用一个或多个先前的字符来加密当前字符。有许多组合方式。一个例子是 P(k[n]⊕x[n-i], x[n]),其中 i 是一个小整数。这种密码需要一个初始化向量来加密前 i 个字符。流密码也可以通过在几个组合函数之间切换来加强,例如周期性地在sadd的 3 种形式之间或madd之间进行切换,或者周期性地变化madd中的乘数 p 和 q。
13.2 随机数
前面表格中列出的流密码中使用的长密钥可以来自几个来源:
-
它们可能是一个数字列表,根据需要重复多次。这是从 16 世纪到 19 世纪的标准方法。
-
它们可能是通过数学过程生成的。这些数字称为pseudorandom,因为它们最终会重复,而不是真正的随机数,后者永远不会重复。生成这些数字的过程称为pseudorandom number generator(PRNG)。
-
它们可能是真正的随机数,可能是由一些物理过程生成的,例如来自爆炸星的伽马射线。这些过程通常对于密码学的需要来说太慢了,因此这些随机数通常会随着时间的推移而收集,并存储在计算机中以供以后使用。也就是说,它们可以连续收集,并且只在您需要发送消息时使用。
关于密码学的书籍和文章经常声称,你需要真正的随机数才能获得安全的密码。他们指出,已经数学证明了使用真正随机密钥的一次性密码本是不可破解的。这当然是正确的,前提是对于每个明文单元 p 和每个密文单元 c,都存在一个密钥单元 k 将 p 转换为 c,即 S(k, p) = c。真正的随机密钥足以使一次性密码本无法破解。然而,正如每个学过逻辑的人都知道的,条件可以是充分的,但不是必要的,反之亦然。
例如,要使一个整数成为质数,必须大于 1。这是必要的,但不充分,因为 4 是一个大于 1 的整数,但不是质数。要使一个整数成为合数,它必须是一个大于 1 的平方数。这是充分的,但不必要,因为 6 是合数,但不是平方数。
要求一次性密码本的密钥必须是真随机是过度的。为了使一次性密码本无法破解,密钥必须是不可预测的,也称为密码学安全的。使用真随机密钥,无论 Emily 知道多少个密钥单位,她都无法确定其他单位。使用不可预测的密钥,Emily 只需无法计算地确定其他单位。具体而言,Emily 需要做的工作量来确定另一个密钥单位必须大于 2^k,其中 k 是你选择的密钥大小(以比特为单位)。当密钥流仅为伪随机时,您无法再证明密码本是不可破解的,但这在实践中没有实际意义。
本章后面我将描述几种使伪随机数生成器具有密码学安全性的方案,并指出一个看起来安全但实际上是不安全的方案,即第 13.13 节中描述的 CG5。
之前列出的所有流密码都可以利用伪随机数生成器产生密钥流,因此让我们来看一些 PRNG 的变体,首先从上世纪 50 年代的一些经典方法开始。这些生成器使用一个小的初始值,称为种子或初始状态,以及一些简单的数学函数,从当前状态生成下一个状态,称为状态向量。常见的生成函数包括加法、乘法和异或。由于它们的速度快且易于实现,这些生成器今天仍然被广泛使用。
每个生成器都会产生一个整数序列,在依赖于种子的周期之后最终会重复。可能会有一个永远不会重复种子的重复数字序列,例如 1,2,3,4,5,4,5,4,5,4,5, … ,但本书中的生成器都没有这种行为。周期受状态向量大小的限制。例如,一个状态向量为三个 31 位整数的生成器的周期不能超过 2⁹³。
13.3 乘法同余生成器
一个乘法同余伪随机数生成器使用两个参数,一个是乘数 m,一个是模数 p。从种子 s 开始,伪随机数序列 x[n] 通过递推生成。

换句话说,要获取下一个伪随机数,你需要将上一个数乘以 m,然后取模 p 的余数。种子可以是任何整数 1,2,3, … ,p-1。模数 p 几乎总是选择为质数,因为质数产生最长的周期。选择 p 通常取决于您使用的计算机中寄存器的大小。对于 32 位寄存器,常见选择是素数 2³¹-1,即 2,147,483,647,这是由伯克利数论学家 Derrick H. Lehmer(不要与他的父亲伯克利数论学家 Derrick N. Lehmer 混淆)在 1949 年发布的这一类中的第一个 PRNG。
乘数 m 必须谨慎选择。乘法同余生成器的周期可以是任何均匀地整除 p-1 的整数。由于 p 是一个素数,且可能远大于 2,p-1 将是偶数,因此非常糟糕的选择 m,比如 p-1,可能会得到一个周期为 2 的结果。具有最长周期的乘数,即 p-1,称为 p 的 原根。这意味着 m、m²、m³、…、m^(p-1) 在模 p 下有不同的余数。对于乘法同余生成器,最好使 m 成为原根,以获得最长可能的周期。
幸运的是,这很容易做到。在范围为 2 到 p-2 的数中,平均约有不到 3/8 的数字是 p 的原根。这个确切的比率被称为 阿丁常数,以奥地利数学家埃米尔·阿丁(Emil Artin)的名字命名,他于 1937 年逃离纳粹德国,并在普林斯顿完成了他的职业生涯。它的值约为 .373956。如果您可以因式分解 p-1,那么很容易测试给定的乘数 m 是否是 p 的原根。我们知道 m 的周期必须整除 p-1,因此首先将 p-1 进行因式分解。假设 p-1 的不同素因子是 a、b、c 和 d。然后,您只需要测试 m^((p-1)/a) (mod p),m^((p-1)/b) (mod p),m^((p-1)/c) (mod p) 和 m^((p-1)/d) (mod p)。如果这些值中没有一个是 1,则 m 是一个原根。例如,如果 p = 13,则 p-1 的不同素因子为 2 和 3,因此您只需要测试指数 12/2 和 12/3,即 m⁶ 和 m⁴。例如,5 不是 13 的原根,因为 5⁴ = 625 ≡ 1 mod 13。
有有效的方法来通过连续的平方来计算 m^x。例如,要计算 m²¹,您可以连续计算 m²、m⁴、m⁸、m¹⁶、m²⁰、m²¹,只需进行 6 次乘法运算。您可以通过使用这些乘积来计算下一个幂值来获得进一步的效率。例如,如果要测试的下一个值是 m³⁷,您可以只使用 3 次乘法运算计算出 m³²、m³⁶、m³⁷。在每次乘法运算后计算模 p 的余数要比计算庞大的数 m²¹ 并在最后取余更有效。有更复杂的方案可以使用稍少的乘法运算,可能减少 10% 到 15%,但如果您只做几次,额外的努力是不值得的。
如果您使用的是乘法同余伪随机数生成器(PRNG),则重要的是要知道每个数字的大小显示出随机特性。要将生成器的输出 R 转换为范围在 0 到 N-1 的整数,正确的计算方式是⌊RN/p⌋,其中⌊x⌋表示“x 的地板”,意思是将 x 向下舍入到下一个较低的整数。例如,⌊27⌋是 27,⌊27.999⌋是 27。表达式⌊RN/p⌋略微偏向于较小的值,即,它会比较频繁地产生较小的数字。但是,当 p 远远大于 N,比如 p > 1000N 时,这对于加密目的并不重要。
历史旁注
顺便说一句,符号⌊x⌋和相应的⌈x⌉(读作“x 的 ceil”,意思是将 x 四舍五入到下一个更高的整数,因此⌈27.001⌉为 28)都是由肯尼斯·艾弗森(Kenneth Iverson)在 1962 年发明的,他是 APL 编程语言的创造者。APL 是第一种交互式编程语言。今天的计算机用户认为交互性理所当然。您按下一个键或点击鼠标,计算机就会执行某些操作。他们没有意识到这个概念必须被发明。在那之前,计算的标准模型是您通过卡片阅读器运行一叠卡片,计算机打印结果,几个小时后您得到一叠纸。
警告:不要使用(R mod N)作为您的随机数。R mod N 可能严重偏向低值。例如,如果模数 p = 11,N = 7,那么(R mod 7)的 11 个可能值为 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3,因此 0, 1, 2 和 3 的生成频率是 4, 5 或 6 的两倍。
只要 m > √p,乘法同余生成器将具有良好的随机特性。最好是乘法逆 m’ > √p。这意味着 m 的位数至少需要是 p 位数的一半。您希望 p 尽可能大,以便生成器具有长周期,同时希望 m 足够大,以便生成器是随机的。您可以走多远?m 和 p 的大小受计算机寄存器的大小限制。如果超过一个寄存器,速度将受到惩罚。
每个伪随机数 x[n]是通过将前一个数字 x[n-1]乘以 m 生成的。数字 x[n-1]可以有与 p 相同数量的位,因此如果 p 有 b 位,则 x[n-1]也可以有 b 位。由于 m 必须至少有 b/2 位,因此乘积 mx[n-1]可以有 3b/2 位。如果寄存器大小为 63 位,则 b 最多可以是 63 的 2/3,即 42,这意味着 m 最多可以有 21 位。最好使 m 大于√p。一个合理的折衷方案是 m 为 25 位,p 为 38 位。这样可以让周期长达 2³⁸。
使生成器不可预测所需的属性是生成的单位具有相等或均匀的频率,成对的单位具有相等的频率,三元组和四元组具有相等的频率,依此类推。实际上,您不需要超过八元组或最多十元组的字节。如果您想要绝对确定,可以将所需的密钥大小除以生成的单位的大小。例如,如果您的密钥大小为 128 位,PRNG 生成 4 位十六进制数字,则您可能需要使 n 元组在所有 n 值上的频率相等,直到 32。 (那些这样做的人显然是强迫症患者,应该寻求治疗。)即使对于 4 位随机数,也没有必要也没有用处超过 16 元组或最多 20 元组(sexdecuples 或 vigintuples),即 64 或 80 位。
Emily 需要超过 2⁶⁴或 2⁸⁰字节的已知明文才能利用这些不均匀的频率。即使 Sandra 从不更改她的密钥,Emily 也不可能积累那么多的材料。从长远来看,假设有一颗卫星以每秒 1 MB 的速率发送遥测数据。进一步假设,它同时使用两个不同的密钥流发送这些数据,而 Emily 拥有其中一个密钥。即使她以每秒 1 MB 的速度获取明文/密文对,她仍需要大约 585,000 年才能收集到 2⁶⁴字节。即使有 1000 颗卫星都使用相同的密钥,也需要 585 年。
如果对于每个 n 的所有值,n 元组的频率都相等,则您的生成器是真随机的。您已经找到了一种生成真随机数的数学算法。恭喜。去领取您的菲尔兹奖。
为了使元组频率在 n 元组中相等,通常需要生成器的种子本身至少是 n 元组。对于乘法同余生成器来说,单个单位和对频率是均匀的,但三元组频率从不均匀,而对于 n > 3 的 n 元组频率则远非均匀;其中大多数频率为 0。
如果你有几个已知明文字符,并且密码使得很容易从明文/密文对确定随机输出,即,如果组合函数是xor、add或madd,那么破解乘法同余密码就很简单。例如,如果密码通过对密钥字节和明文字节进行异或运算来获取密文字节,那么 Emily 所需要做的就是将明文字节与密文字节进行异或运算以获取密钥字节。
如果生成器有一个 31 位或 32 位的模,即使在个人电脑上,Emily 也可以尝试所有 2³¹或 2³²种种子的值。已知的明文字符仅用于验证。如果模数更大,例如 48 位或 64 位,则前 2 个或 4 个已知的明文字符用于限制搜索范围。第一个随机输出将当前生成器状态限制在一个窄范围内,即总范围的 1/256。第二个已知的明文字符给出第二个输出,将状态限制在该范围的 1/256,依此类推。
因此,单个乘法同余生成器在密码学上并不安全。可以使用更大的模数,使用卡拉兹巴或图姆-库克等大整数乘法技术,但这会牺牲这一类生成器的高速度。有更快的方法来生成密码安全的生成器,因此本书不会涉及大整数乘法方法。
13.4 线性同余生成器
线性同余生成器是对乘法同余生成器的扩展。它们在递推公式中添加一个线性常数项 c。从种子 s 开始,通过递推生成伪随机数序列 x[n] 的是公式是

换句话说,要获得下一个伪随机数,你将前一个数字乘以 m,加上 c,然后取该和对 P 的模。种子可以是任何整数 1、2、3、…、P-1。当满足以下三个条件时,生成器将具有最长可能的周期:
-
c 与 P 互质,
-
对于每个是 P 因子的素数 p,m 的形式为 pk+1,且
-
如果 P 是 4 的倍数,则 m 的形式为 4k+1,
其中 k 可以是任意整数。这些被称为 T. E. Hull 和 A. R. Dobell 在 1962 年发表的Hull-Dobell 条件。
例如,假设 P = 30,即 2×3×5。那么 m-1 必须是 2、3 和 5 的倍数。换句话说,m 必须是 1。所以,如果 s = 1,c = 7,伪随机序列将是 1、8、15、22、29、…。这是一个等差数列,一点也不随机。因此,通常选择模数 P 为质数的幂,最常见的是 2。找到产生良好随机特性的 m、c 和 P 的值是困难的。
然而,线性同余生成器有一个很好的用途。如果你想产生一个具有极长周期的生成器,你可以将两个或多个模数为不同质数幂的线性同余生成器的输出相加,以获得具有良好随机特性和周期等于这些模数乘积的生成器。例如,假设你添加了以下三个 PRNG 的输出。我选择了 3 个模数尽可能大,但仍适合于 32 位机器字,我选择了乘数和常数以满足 Hull-Dobell 条件。除此之外,我任意选择了它们。
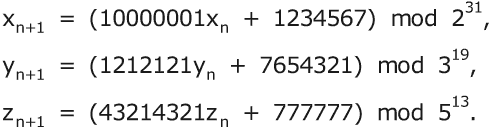
让 w[n] = (x[n]+y[n]+z[n]) mod 2³¹。通过将其右移 23 位来选择 w[n] 的高阶字节,即 v[n] = w[n]/2²³。只要 (1) 三个乘数中至少有一个,以及它的乘法逆元,大于其对应模数的平方根,且 (2) 其余两个乘数都不是 1 或 P-1,那么 v[n] 序列将具有良好的随机特性。v[n] 序列的周期为 2³¹3¹⁹5¹³ = 3.0468×10²⁷。
13.5 链式异或生成器
最简单的链式异或生成器操作的是一串比特,例如 10111。基本思想是将第一个比特与最后一个比特进行异或操作,删除第一个比特,并将新比特附加到字符串的末尾,即 x[i] = x[i-1]⊕x[i-n]。由于 n 位字符串有 2^n 种可能的值,而且由于全零字符串产生一系列全零,链式异或生成器的最长周期为 2^n-1。让我们用 3 位字符串的一个小例子来看一下。
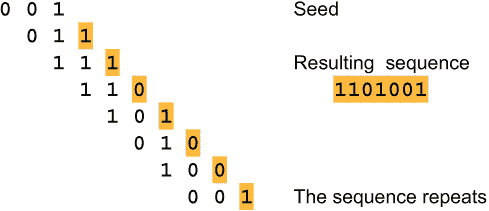
经过 7 步后,初始字符串 001 重复,因此该生成器的周期为 7。这称为完整周期生成器。当 n 为 2、3、4、6、7、15 或 22 时,链式异或生成器具有完整周期。对于 n = 37,该生成器接近于完整周期的概率为 0.00057%。也就是说,99.99943% 的所有 37 位值形成一个大循环,而其余的属于较短的循环。对于某些目的,n = 37 可能是一个不错的选择。对于大多数 n 值,存在若干个重复的比特序列,有些短,有些长。它们的总长度为 2^n-1。只有对于完整周期生成器才能谈论周期。否则会有多个循环,可能长度不同。
假设你需要一个周期长于 2²² 的生成器,并且不愿意冒获得短周期的 0.00057% 的风险。你可以怎么做?一个选择是尝试其他生成函数。而不是使用 x[i] = x[i-1]⊕x[i-n] 的递归关系,尝试使用 x[i] = x[i-1]⊕x[i-j]⊕x[i-k]⊕x[i-n] 的递归关系,其中 j 和 k 的值使得 1 < j < k < n。这些生成器中很有可能有一些具有完整周期。但是请注意,具有 3 项的 x[i] = x[i-1]⊕x[i-j]⊕x[i-n] 的生成器永远不会产生完整周期。项数必须是偶数。
无论你选择哪个生成器,结果都是一系列比特序列。要得到伪随机的字节序列,将比特按照 8 位一组取出,即比特 1 到 8,比特 9 到 16,比特 17 到 24,依此类推。这需要为每个字节生成 8 位比特。有一种更快的方法。不是逐比特进行异或操作,而是一次异或一个字节。实际上,您是同时运行 8 个单比特生成器。这样,每次操作就可以获得一个完整的字节。如果你的编程语言支持,你可以使用完整的 32 位字,并每次获取 4 个字节。
在 13.1 节列出的任何组合函数都可以用于将伪随机流与明文组合成密码。如果 Sandra 选择xor、add或madd作为组合函数,那么密码将很容易让 Emily 解密,前提是她拥有足够的已知明文。她可以轻松确定与明文字符对应的随机输出。这使她可以重构密钥流的一部分。这一部分可以向前和向后延伸,仅通过进行异或操作就可以重构整个密钥流。
Sandra 可以使用一个技巧来迷惑 Emily。假设生成器产生一系列 32 位字,Sandra 将其分成四个单独的字节。Sandra 不一定总是从高阶位开始,而是每次可以从不同位置开始。等效地,Sandra 可以将 32 位字循环左移或右移,位移数量不同。例如,ABCDEF 循环左移 2 位得到 CDEFAB。位移的长度可以是在 0 到 31 范围内的重复数字序列。这样,Emily 无法将生成器的连续输出匹配起来以重构密钥流。
13.6 链式加法生成器
链式加法生成器,也称为滞后斐波那契生成器,类似于链式异或生成器,只是它们使用加法而不是异或。加法被理解为模 2^w,其中 w 是位大小,x[i] = (x[i-1]+x[i-n]) mod 2^w。w 的典型值为 15、31 和 63,使用有符号加法,或者 16、32 和 64,使用无符号加法。另一种看待 mod 2^w 运算的方式是忽略高阶位的进位。
因为加法会从一个位位置产生进位到下一个更高位位置,所以高位的周期是低位的两倍。每个字中低阶位的周期与具有相同种子的异或生成器的周期相同。这是因为加法与带进位的异或相同。如果链式加法生成器中低阶位的周期为 P,则高阶位的周期为 2^(w-1)P。
链式加法生成器是一种简单的方法,可以在很少的额外工作量下获得更长的周期。只需找到一个具有长周期的链式异或生成器,最好是完整周期,然后将其从单比特宽度扩展到完整字宽度。与乘法同余生成器一样,输出序列中最随机的部分是高阶端。对于伪随机字节序列,只使用每个字的高阶 8 位。
再次,您可以使用第 13.1 节中的任何组合函数将伪随机流与明文组合成密码。
13.7 移位和异或生成器
另一类 PRNG 是由佛罗里达州立大学的 George Marsaglia 发明的移位和异或生成器。Marsaglia 最著名的是开发了 Diehard 随机数测试套件。这些生成器使用两个作用于整数的运算符。
-
<< 左移. 例如,80<<2 将整数 80 左移 2 位,得到值 320。
-
右移. 例如,80>>2 将整数 80 右移 2 位,得到值 20。
被移出计算机字的高位或低位的位将会丢失。例如,25>>1 是 12,而不是 12.5。这些操作与循环左移 <<< 和右移 >>> 相对应,其中被移出计算机字一端的位将被放置在相反端。例如,如果 32 位计算机字中的十六进制数字为 12345678,则 12345678<<<4 得到 23456781,而 12345678>>>12 得到 67812345,因为每个十六进制数字有 4 位。如果字包含在较大的计算机寄存器中,则未使用的位需要清零。
在这个类中有几种不同的生成器。必须仔细选择位移的长度和方向,以使生成器具有长周期。以下是 Marsaglia 设计的两个 Xorshift 生成器的示例。它们具有长周期和强大的随机特性,尽管它们未通过一些更敏感的随机性测试。每个生成器使用左-右-左的模式中的 3 次位移和异或步骤来生成序列中的下一个数字。变量 y 用于保存中间值。任何正整数都是合格的种子。

13.8 FRand
FRand,即快速随机生成器,是我自己的创建。FRand 使用一个宽度为 W 的 S 个二进制字的数组,也就是说,它使用数组中每个字的低位 W 位来保存无符号整数值。周期取决于 S 和 W 的值。我发现 W = 29 效果最好,而且 S = 40 和 S = 64 给出了非常长的周期。种子数组可以看作是一个 40×29 位的矩阵。每一行是一个种子,每一列代表种子字中的一个位位置。
对于 S = 40,周期为 2¹¹⁶⁰-2⁴⁰,约为 1.566×10³⁴⁹,对于合格种子。如果至少有一个 40 个种子字中的一个既不全为零也不全为一,则该种子是 合格 的。该生成器有一个弱点。如果种子数组几乎完全为零,则生成器可能会产生数十甚至数百个连续的输出,其中大部分是零。在极端情况下,当种子数组包含 1159 个零和仅 1 个一时,至少需要 1120 个周期才能在每列中至少有一个 1。
最好是初始种子包含大量随机模式中的 1 和 0。获取适当的种子数组的一种方法是将表达为 UTF-8 代码的助记符或数字密钥,并将其哈希为一个 1160 位值。一个合适的哈希函数是
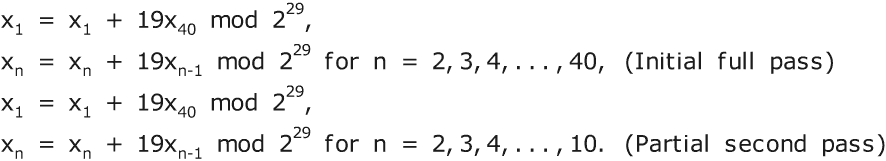
生成器一旦被初始化,伪随机序列就可以通过递推公式生成。此生成器的递推公式使用索引或标记符号 n。

每次通过种子数组时,当 n = 40 时,索引会重置为 1,并且下一个伪随机数将由 x[1] = (x[1]⊕x[40])>>>1 生成。也就是说,第一个 29 位字 x[1] 循环向右移动一个位位置。
这个伪随机序列通过了许多随机性测试,但远远达不到密码学安全的要求。为了产生一个安全的序列,诀窍是从 29 位字的不同部分获取每个连续的输出字节。伪随机序列本身可以用来选择这些位置。假设下一个 3 个伪随机输出分别是 a、b 和 c。取 s = a mod 25。如果 s 在 0 到 21 的范围内,则将 b 向右移动 s 个位置并取低 8 位。在这种情况下只生成 a 和 b。c 将为下一个伪随机数生成。如果 s > 21,则将 s 位置向右移动会留下少于 8 位。在这种情况下丢弃 a 并取 s = b mod 22。将 c 向右移动 s 个位置并将低 8 位作为随机输出。代数表示如下,

该过程平均使用 2.12 个伪随机输出来产生每个安全密钥字节。这样,密钥字节大约一半的时间来自偶数输出,另一半的时间来自奇数输出。生成器会以不规则的方式大约每 8 个周期在奇数和偶数之间来回切换。
13.9 梅森推土机
梅森推土机 是任何 PRNG 类别中周期最长的。它由广岛大学的松本真和西村拓士于 1997 年开发。它以法国神学家马林·梅森(Marin Mersenne,1588-1648)的名字命名,他以形式为 2^n-1 的素数而闻名,并因传播伽利略、笛卡尔、帕斯卡和费马等人的作品而广为人知。
推土机 具有良好的随机特性,尽管它在一些随机性测试中失败。它比本章描述的其他随机数生成器要慢得多。它的主要重要性在于其庞大的周期,即梅森素数 2¹⁹⁹³⁷-1,该数在 1971 年由 IBM 纽约州约克敦的 IBM 研究院的 Bryant Tuckerman 发现。IBM 研究院为此发现感到非常自豪,将“2¹⁹⁹³⁷-1 是质数”印在了其信笺和邮资表上。
与 FRand 一样,梅森推土机也存在一个缺点,即如果初始状态大部分为零,则可能需要许多周期才能变得看起来随机。对于梅森推土机,通常需要 10,000 或甚至 50,000 个启动周期才能开始使用输出。相比之下,FRand 软件包有一个函数,它可以在不需要任何启动周期的情况下初始化生成器。
13.10 线性反馈移位寄存器
线性反馈移位寄存器(LFSR)是电气工程师的宠儿,因为它在数字电路中实现起来非常简单。LFSR 使用一系列位 x[1]、x[2]、…、x[n]。下一个位通过对前面的几个位进行异或运算来生成,例如

使用 3 个反馈。当然,反馈的数量不一定是 3,但是奇数个反馈通常会比偶数个反馈给出更长的周期。
假设 i < j < k,则此 LFSR 将有 k+1 位位置。生成每个新位后,低阶位被移出,新位被放置在高阶位置,因此寄存器始终包含伪随机序列的最新的 k+1 位。
使用 LFSR 的一个明显缺点是它们速度较慢,因为它们需要 8 个周期才能生成每个伪随机输出字节。LFSR 也是伪随机生成函数中最弱的,因为它们完全是线性的。如果 Emily 有一些已知的明文,并且能够确定相应的关键位,则她可以通过解一组线性方程来重构整个伪随机序列,这很容易。如果 Sandra 使用xor、add或madd作为组合函数,Emily 可以确定关键位。
因此,伪随机输出通常在与明文结合之前通过非线性替换。这可以通过两种方式进行,按位或按字节。非线性按位替换是可能的,因为在每个周期中,寄存器中有 k+1 个位可访问。用作非线性函数输入的位称为taps,可以从寄存器的任何位置获取。使用这些非线性函数使得 Emily 更难确定关键位。
一个合适的非线性函数是多数 函数。如果其输入位的大多数为 1,则此函数的值为 1,否则为 0。对于具有 3 个输入位 A、B 和 C 的情况,多数函数是 AB∨BC∨CA,其中 ∨ 是布尔 OR 函数。多数函数对于任何奇数个输入,如 3、5、7,等等,都是定义的。这个想法的一个扩展是使用 9 个 taps 和三个 3 位多数函数电路。9 位中的三个位进入每个电路。然后,将 3 个输出位通过第四个多数电路。
如果组合函数是sxor、sadd或poly,则字节替换是固有的。这些非线性替换的构造在第 12.3 节中详细讨论。可以将按位和按字节替换组合起来。生成输出字节中的每个 8 位都使用 taps 和非线性位函数,然后将这些电路的 8 个单个位输出馈入按字节替换中。
让我们看看 Emily 必须做些什么来破解一个 LFSR 密码。假设 Sandra 使用一个 40 位的硬件 LFSR, taps 位于位位置 3、6 和 9,进入到一个大多数功能电路 M 中,并且她天真地使用 xor 作为组合函数。进一步假设 Emily 有一些已知纯文本的字符,因此知道了一系列输出位。对于每个已知位,进入 M 的 3 个 LFSR taps 位置只缩小到了 8 个可能值中的 4 个。如果位是 0,则 3 个 taps 必须是 000、001、010 或 100。如果位是 1,则 3 个 taps 必须是 011、101、110 或 111。
经过 4 个周期,12 位已经进入了 3 个 taps,所以对于这 12 位有 4⁴ = 256 种可能的组合。这相比于 2¹² = 4096 种组合大大减少了。更好的是,从 Emily 的角度来看,最初位于位置 3 的位现在位于位置 6,而最初位于位置 6 的位现在已经移动到位置 9。这意味着一些 12 位组合可以被消除。可以消除的组合数量取决于输出位的序列。如果第一个和第四个输出位相同,则消除的组合较少。如果它们不同,则消除的组合较多。每个额外的已知输出位进一步减少了移位寄存器中可能组合的数量。
举个例子。假设 Sandra 使用一个 40 位的 LFSR,带有 3 个 taps,每个 taps 都进入到大多数功能中以产生每个输出位。还假设 Emily 知道设备的所有细节,并知道消息来自总部,所有消息都以 GHQ 开头。这给了她 24 位已知纯文本。如果她将这 24 位与密文的对应位进行异或运算,她就从设备中得到了 24 个输出位。对于这些输出位中的每一个,都有 4 种可能的 3 位输入组合来产生已知值。这就在 3 个 tap 位置产生了 72 位可能的位值。由于 LFSR 中的位每个周期向前移动一个位置,这些位组合会重叠,因此总的组合数量可以不断减少。
Sandra 应该从这个简要分析中学到什么?(1) 扩大移位寄存器,最好至少为 128 位。(2) 将 taps(触发器)远离得越远越好。(3) 不要均匀地分布 taps。在这里,3、6、9 是一个异常糟糕的选择。(4) 使用一种让对手难以确定关键位的组合函数。不要使用 xor、add 或 madd 作为组合函数。更好的选择是 xors 和 adds,但最佳选择是 poly。
13.11 估计周期
如果你是一个密码学爱好者,你可能想要尝试设计自己的伪随机生成器。本书不会涵盖如何测试 PRNG,这是一个很大的主题,但让我们看看你如何估计你的生成器的周期。该方法取决于状态向量的大小(第 13.2 节)。
如果状态向量很小,比如 31 位,您可以只运行您的生成器 2³¹个周期,看看何时重复。不幸的是,初始种子可能永远不会重复。有一个处理这种可能性的技巧。制作 2 个 PRNG 的副本,并使用相同的种子 S 进行初始化。然后逐步运行第一个副本,每次运行第二个副本 2 步。假设您发现在 3000 个周期后,这 2 个副本产生相同的状态向量。这意味着 R[3000] = R[6000],因此您的生成器的周期至少为 3000,使用种子 S。
如果状态向量较大,比如 64 位,那么运行您的生成器潜在地 2⁶⁴个周期是不可行的。您仍然可以通过抽样来估计周期。制作一个表,比如 T = 1,000,000 个条目。这个表中的第 N 个条目将保存您的生成器产生值 N 时的周期数。最初,将这个表中的所有条目都设置为零,因为尚未产生任何值。选择范围在 1 到 T-1 之间的种子,并运行您的生成器,也许是 G = 1,000,000,000 个周期。在每个周期,如果生成的值 N 小于 T,则记录表中的周期号 N。如果条目不为零,则表示有重复项,这告诉您周期。例如,如果值 12795 在第 33000 个周期和第 73500 个周期再次产生,则该种子的生成器周期为 73500-33000 = 40500。
如果您找不到任何重复项,那么您可以通过查看生成了多少个 T 值来估计周期。如果表中的 E 个条目不为零,则生成的条目比例为 E/T。由于您运行了 G 个周期的生成器,估计周期为 G/(E/T) = GT/E。
正如我们在链式数字生成器(第 4.5.1 节)中看到的,一个生成器可能有几个不同的循环,有些长,有些短。您应该对生成器的周期进行多次估计,使用不同的种子。一个好的策略是首先使用种子 1。对于第二个种子,使用第一个种子未生成的最低值。对于第三个种子,使用第一个或第二个种子未生成的最低值。您可以通过制作累积表来做到这一点。在估计运行之间不要将其重置为零。如果在大约 20 到 100 次这样的运行中周期的估计是一致的,那么您可以确信您的生成器对大多数种子具有长周期。
13.12 加强生成器
加强 PRNG 的一种方法是使用一个选择生成器,将生成数字的操作与选择数字的操作分开。 这可以通过在数组中保留 N 个数字来完成,比如 32、64 或 256 个数字。 数组中的每个数字应该是所需随机输出的大小。 例如,如果要生成随机字节,则数组应包含 8 位数字。 首先对 PRNG 运行 N 个周期以产生初始数字,这些数字按生成顺序放入数组中。 然后使用新种子重新启动 PRNG。 然后使用生成器生成范围为 1 到 N 的伪随机数序列。 每个数字用于选择数组的一个元素。 该元素成为下一个伪随机输出。 然后使用 PRNG 用新的伪随机数替换所选数组元素。
这意味着第一个、第三个、第五个,… 随机数用于选择,而第二个、第四个、第六个,… 数字用于替换数组中的数字。 使用两个具有不同种子的 PRNG 的两个独立副本可能很方便,但这不会增加周期。 更好的策略是使用两个周期互质的不同生成器。 然后,组合生成器的周期是它们周期的乘积。 例如,如果数字是由具有周期 2³¹-1 的乘法同余生成器生成的,而数字是由具有周期 2³¹的线性同余生成器选择的,那么组合生成器的周期是 2⁶²-2³¹,或 4.612×10¹⁸。
4.612×10¹⁸的周期对于密码工作已经足够长,但选择生成器仍然不具有密码学安全性。 这是因为艾米莉可以穷举选择器序列并尝试所有 2³¹种可能的种子。 有足够的已知明文,这可能会给她第一个生成器的输出序列,这足以解决问题。
有几种可能的解决方法。 (1) 使用像xors、adds或poly这样的组合函数,这样艾米莉就很难确定随机输出。 (2) 使选择器生成器更大,比如说 63 位而不是 31 位。 (3) 使选择器生成器的种子更大,例如通过使乘数和/或加法常数成为种子的一部分,即生成函数 x[n+1] = (mx[n]+c) mod P 中的 m 和 c。 (4) 使用下一节中的技术来构建一个具有更长周期的选择器。
13.13 组合生成器
伪随机数生成器可以以各种方式组合,以获得更长的周期或更好的随机性属性,或者变得具有密码学安全性。 这些改进通常是相辅相成的。 你不会为了实现另一个而牺牲一个。 如果增加周期,通常会同时改善随机性。 有两类组合生成器,固定组合和可变组合。
固定组合
在固定组合中,有几个 PRNG,最好是周期互质的。这些可以是乘法同余、线性同余或 Xorshift 生成器。这些生成器的输出可以按位或按字节组合。一种按位的方法是从每个生成器中取一组固定的位,并将它们输入到某个组合函数中。例如,可以从 8 个生成器中分别取高阶位,或者从 4 个生成器中分别取两个高阶位。然后,这 8 位将被输入到一个高度非线性的替换中。替换步骤防止 Emily 将每个生成器的输出分离并单独解决它们。
一种按字节的方法是从每个生成器中取高阶字节,并通过对它们进行模 256 相加或者异或来组合它们。两个生成器可以通过将它们的输出相乘并取乘积的中间 8 位来组合。另一种技术是取线性组合,例如 (a[1]x[1]+a[2]x[2]+a[3]x[3]+a[4]x[4]) mod 256,其中 x[1]、x[2]、x[3] 和 x[4] 是来自四个 PRNG 的 8 位输出,并且四个系数 a[1]、a[2]、a[3] 和 a[4] 可以是 1 到 255 之间的任意奇数整数。这些系数可以针对每条消息不同。
例如,四个 PRNG 可以使用素数模 2³¹-1 和 4 个不同但固定的乘数来生成。这四个 31 位种子加上四个 7 位系数组成了 152 位的组合种子。
三个 PRNG 可以通过使用循环移位操作(第 13.7 节)来组合。使用 32 位无符号生成器时,32 位输出可以使用 x[1] + (x[2] >>>11) + (x[3] >>>21) mod 2³² 来组合。最佳移位量是 32 位寄存器大小的 1/3 和 2/3。如果你希望使用超过 3 个生成器,请尽可能使移位量均匀。例如,使用 5 个生成器时,移位量应该是字长的 1/5、2/5、3/5 和 4/5,四舍五入到最接近的整数。
另一个固定生成器 CyGen,通过循环移位来组合两个生成器 C 和 G。C 可以是任何大小,但 G 应该是 32 位或 64 位。在每个周期中,分别从 C 中取 5 或 6 位,以获取移位量。然后,从 G 中取得的输出将向左循环移动该数量的位置,以获得 CyGen 的输出。这使得 Emily 无法从其输出序列重构 G。
没有限制线性组合。例如,可以使用 x[n]+y[n]z[n] 或 x[n]+y[n]²+z[n]z[n-1]z[n-3] 将 3 个生成器组合起来。至少求和中的一项应该是线性的。可能性是无限的,当然,你可以在多种方法之间进行切换。
可变组合
可变组合的一个示例是第 13.11 节中显示的选择生成器。但是,让我用一个警示故事开始这一节。这里有一个组合生成器 CG5,似乎是绝对安全的,但实际上不是。
组合生成器 CG5 使用 5 个乘法同余生成器,每个都有不同的乘数和不同的 31 位素数模数。将这些生成器称为 G0、G1、G2、G3 和 SEL。(或者,SEL 可以是一个线性同余或 Xorshift 生成器,具有 2³¹周期。)生产生成器 G0 到 G3 用于产生伪随机数,选择生成器 SEL 用于选择 G0-G3 中的哪一个用于产生下一个伪随机输出。具体来说,SEL 的高 2 位确定了在 G0-G3 中选择哪一个。假设 SEL 生成了 10,这选择了 G2。然后 G2 生成器运行 1 个周期,其输出成为 CG5 的下一个输出。组合生成器的周期约为 2¹⁵⁵,具有良好的随机特性…但不会是密码学安全的。原因如下:
假设艾米莉有足够的已知明文,并考虑从 CG5 中得到的前 17 个输出。这 17 个输出中至少有 5 个必须由同一个生成器产生。(如果 4 个生成器最多产生 4 个输出,那么最多只能有 16 个输出,而不是 17 个。)从 17 个中选择 5 个项目的方式只有 6188 种。艾米莉可以尝试所有这些方式。这样一来,就有大约 1.33×10¹³种放置加种子的组合需要测试,然而,这可以大大减少。艾米莉知道这 5 个选择输出的每个的高 8 位。她不应该从 17 个输出的第一个开始,而应该从 5 个选择输出的第一个开始。然后,她只需要尝试 2²³个值,而不是 2³¹个值。这样一来,她的工作量就减少到了可管理的 5.19×10¹⁰个组合。CG5 组合生成器并不安全。
让我们看一个更安全的生成器。我将其称为Gen5。再次,组合生成器使用 5 个乘法同余生成器,每个都有不同的乘数和不同的 31 位素数模数。模数和乘数是固定的,并且选择得具有良好的随机特性。这次让我们称这些生成器为 G1、G2、G4、G8 和 SEL。只使用选择器 SEL 的 4 个高阶位。在这个 4 位数中,第一个位上的 1 表示选择 G1,第二个位上的 1 表示选择 G2,第三个位上的 1 表示选择 G4,第四个位上的 1 表示选择 G8。当选择少于两个生成器时,SEL 将再运行一个周期以生成新的选择。只使用 SEL 生成的 16 个可能的 4 位输出值中的 11 个,因此 SEL 将额外运行一个周期的时间为 5/16,额外运行两个周期的时间为 25/256,依此类推。
当选择两个或更多发生器时,它们每个都会运行 1 个周期,它们的输出将模 2³¹ 加在一起,以产生 Gen5 伪随机输出。未选择的发生器不会运行,因此 4 个发生器会异步运行。该输出略微偏向较低的数字,但对 Emily 来说并不足以利用。如果您担心这种偏差,可以(1)丢弃高阶位并使用和为输出字节的高阶位 2 到 9,或者(2)使用 Meld8 操作(第 12.3.7 节)。也就是说,通过将和的高阶 8 位与和的第二个 8 位进行异或运算来从 Gen5 发生器形成输出字节,即将位 1 到 8 的异或位与位 9 到 16 的位进行异或。
*****Emily 再也无法分离出任何一个发生器。Emily 可能看起来可以分离出其中的 6 对 Gi+Gj 中的一个,其中 i 和 j 可以是 1、2、4 或 8。这样的一对可以被视为单个发生器处理,然后稍后可以将 Gi 与 Gj 分离出来。让我们首先看看这种方法。为了求解 Gi 和 Gj 的种子,至少需要来自 Gen5 的 9 个随机输出。由于这些配对每次只发生 1/11 的概率,Emily 可能需要查看 89 个或更多的消息字符。这是因为,仅仅由于偶然,3 个或 4 个发生器的 5 个组合可能比 2 个发生器的 6 个组合更频繁地发生。
对于 89 个物品中的 9 个物品,大约有 6.356×10¹¹ 种可能的放置方式,因此 Emily 只需尝试 SEL 发生器的所有约 2³¹ = 2.147×10⁹ 个种子,这样 Emily 就可以找到所有 6 对 Gi+Gj 的下一个 10 个位置。这也让她可以计算出 Gi 和 Gj 在每次出现时已经被使用了多少次。例如,假设 G2+G4 出现在 Gen5 的第 14 个周期。在这 14 个周期中,可能有 6 个周期中使用了 G2,而 9 个周期中使用了 G4。现在 Emily 知道了 G2 的第 6 个输出加上 G4 的第 9 个输出的值。
如果 Emily 可以为 G2+G4 这样的 10 个输出值组合起来,那么她可以在大约 2^(31+31-8) = 2⁵⁴ = 1.801×10¹⁶ 次试验中确定这两个发生器的种子。这必须对 SEL 的约 2³¹ 个种子进行操作,因此总工作量约为 2⁸⁵ = 3.869×10²⁵。这相比于 Gen5 的暴力解决方案需要 2¹⁵⁵ 次试验有了巨大的改进,但远远不及 2¹²⁸ 次试验的目标。此发生器被评为 Nine.******
现在我们已经准备好进行致命一击了。这是 Gen5 的升级版本,我将其称为 GenX。GenX 由伪随机数生成器和密码两部分组成。GenX PRNG 将生成一个 10 位伪随机输出序列,密码将把密钥字节 k[n] 与消息字节 x[n] 结合起来产生密文。这将使密码超出 128 位密钥大小。
GenX 生成器只是 Gen5 生成器的扩展版本。它使用四个生产生成器 G1、G2、G4 和 G8,以及一个选择生成器 SEL。SEL 的高阶 4 位用于选择 2 到 4 个生产生成器的某种组合。所选的生产生成器运行一个周期,它们的输出相加模 2³¹ 以产生一个和 G。G 的高阶 10 位与下一个 10 位的 G 进行异或运算以产生 10 位输出。10 位输出被分为一个 8 位密钥字节 k[n] 和一个 2 位控制位 c[n]。
GenX 密码器将密钥字节 k[n] 与消息字节 x[n] 根据控制位 c[n] 使用混合的键控替换 S 进行组合。控制位 c[n] 决定了每个明文字节使用哪种组合函数。解释这 2 个控制位的一种可能方式是

所有的和都是模 256。Cipher GenX 被评为十。该密码的密钥是用于 G1、G2、G4、G8 和 SEL 的五个 31 位种子以及用于混合替换 S 的密钥,例如 SkipMix 密钥。
13.14 真随机数
所有在本章讨论过的生成随机数的技术都产生伪随机数。我看过的每一本讨论随机数的书都重复着这样的观念,即使用软件产生真正的随机数是不可能的。这是因为他们将自己限制在了一种太狭窄的可能方法范围内。在本节中,我将介绍一种使用软件批量生成真正随机数的可行方法。
文献中所有用于生成真正随机数的方法都依赖于诸如宇宙射线、热噪声、振动、核衰变等物理现象。这些方法对于加密目的来说太慢了。
相反,你可以通过一个 3 步过程产生真正的随机数。 (1) 从自然界中获取大量真正的随机数。 (2) 使它们的概率分布均匀。 (3) 通过从这个语料库中选择和组合数字来生成随机数。接下来的几节将详细介绍如何完成这些步骤。
自然界充满了随机性。地球上每一棵植物和树上每片叶子的形状、颜色和位置都是随机的。它们是风和微风、阳光透过叶片、从根部流上的养分、打在叶片上的雨滴和冰雹、咬过叶片的昆虫、鸟类、松鼠、地面震动以及许多其他因素的结果。每一个海洋上的波浪、每一个沙漠中的植物和岩石、每一条河流上的涟漪、每朵云、每一个海滩上的贝壳在大小、形状、颜色、位置、方向甚至速度上都是随机的。
这些随机性的一部分可以通过简单地拍摄这些地点来捕捉。你甚至不需要离开家。只需拿一把爆米花撒在有图案的表面上。你还可以使用你认识的人和你去过的地方的照片。有些照片是你从网站和电子邮件中下载的。还有成千上万张照片被操作系统和你使用的应用程序放在了你的计算机上。你可以使用网络浏览器找到数十亿张照片。作为一个实验,我编造了一个伪单词 ZRMWKNV,并搜索了图片。我得到了超过 6,000 个与 ZRMWKNV 相关的搜索结果,其中一些网站包含了数百张图片。
滞后线性加法
每个这样的图像文件包含大量的随机性,特别是如果分辨率很高,但字节值的分布远非均匀,也远非独立。通过使用滞后线性加法,将整个图像文件,包括头部在内,视为长度为 L 的一个长字节字符串,可以使分布变得平坦。以下是一个示例:
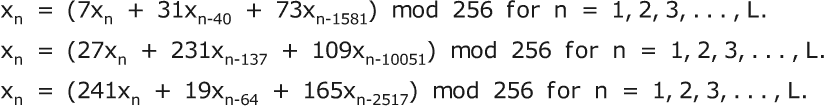
下标总是循环的。如所示,三次传递足够了,但随时可以使用更多。你不希望频率太均匀,因为那将不再是随机的。如果你想使用简化版本,比如 x[n] = (x[n]+x[n-179]) mod 256,请注意需要五次传递。确保在每次传递中使用不同的滞后。
这些系数 7、31 等并没有什么特别之处,我是随意选择的。它们可以是从 1 到 255 的任意奇整数。对于每次传递,滞后 40、1581 等应该被选择得一个远大于另一个。小步长,大步长。一个想法是使较小的滞后约为∛L,而较大的滞后约为∛L²。例如,如果图像文件大小为 1,000,000 字节,你可以分别使滞后约为 100 和约为 10,000。较小的滞后可以在 50 和 200 之间选择,而较大的滞后可以在 5000 和 20,000 之间选择。在滞后线性加法之后使用一个带有密钥的简单替换,使得艾米莉更难重建图像文件。
图像分层
另一种构建真随机序列的方法是取两个图像,使用某种组合函数(如异或或加法,参见第 13.1 节)将它们层叠在一起。一个好的方法是在组合之前对每个图像进行一次滞后线性加法传递,然后在它们被组合后进行最后一次传递。
三个图像可以使用非线性大多数函数(第 13.10 节)逐位进行组合。同样,在组合之前,我建议对每个图像进行一次滞后线性加法的传递,然后在它们被组合之后进行最后一次传递。即使三个图像中没有一个大小相同,也可以使用这种方法。将一个短图像对齐到与最大图像相同的位置,并将另一个短图像对齐到与最长图像相同的位置,就像这样:

当只有两幅图像重叠时,按字节模 256 进行相加。当所有三幅图像重叠时,使用大多数函数逐位进行组合,或者使用模 256 的线性组合,如 c[n]=(113x[n]+57y[n]+225z[n]) mod 256。系数可以是从 1 到 255 的任意奇整数。
对齐图像的另一种替代方法是通过重复来扩展短图像。在这个例子中,x 图像有 22 个字节,y 图像有 33 个字节。通过重复 x 的前 11 个字节,可以将 x 图像扩展到 33 个字节。这样,大多数函数可以在所有 33 个字节位置使用。实际上,这些图像将有数百万个字节。
13.15 刷新随机字节
很好。现在我们有一个名为 T 的表,里面有几百万个真随机字节。它们是真正的随机字节,因为如果艾米丽拥有除了一个字节之外的所有字节,这并不会使她能够确定缺失的那一个字节。桑德拉和莉娃都有一份拷贝。那么呢?我们肯定不能每次发送消息都重复这个过程。
利用 T 的一种方法是将其划分为用于分组密码的密钥。一百万个随机字节可以制作出 62,500 个每个 128 位的密钥。最终这一百万字节将被用完。如果桑德拉正在使用一个强大的分组密码,或许这并不重要。她可以重复使用密钥,只要艾米丽无法知道哪些消息使用了相同的密钥进行了加密。当然,桑德拉不能对流密码重复使用密钥。
假设桑德拉不愿意冒再次使用密钥的风险。一个解决方案是刷新随机数列表。桑德拉可以添加另一幅图像,但这意味着莉娃也必须有同样的图像的拷贝。如果图像来自桑德拉和莉娃都可以访问的网站,那么这可能是一个不错的策略。如果传输的密钥可能被截获,这可能是一个很好的策略。
另一种方法是使用滞后线性加法(第 13.14.1 节)刷新 T。称刷新后的表为 T[1]。现在桑德拉只需要传输 9 个系数和 6 个滞后,她就有另外 62500 个密钥可用。假设每个系数需要 1 字节,每个滞后需要 2 字节,桑德拉只需传输 21 字节即可生成 T[1]。然后为了选择消息的密钥,只需要知道该消息密钥在 T[1]中的位置。对此,两个字节足够了,因为所有位置都是 16 的倍数。当 T[1]用尽时,可以使用新的系数和滞后来构造 T[2]等等。
在第 13.5 节和 13.6 节中,线性函数用于确保生成器具有长周期。这里没有周期,因此没有这样的约束。可以使用一些非线性函数,例如
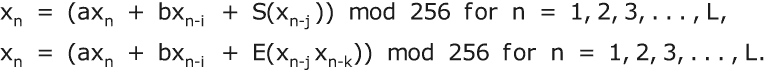
这里下标循环,a 和 b 是从 1 到 255 的奇整数,i、j 和 k 是介于 1 和 L-1 之间的整数。S 可以是一个固定的非线性替换或者一个变量密钥混合替换。函数 E(x)定义为

当你取 E(x[n-j]x[n-k]) mod 256 时,实际上是将 x[n-j]x[n-k]的各个字节相加。这比仅仅使用 x[n-j]x[n-k]更强,因为 x[n-j]x[n-k]有 3/4 的概率是偶数。
或者,桑德拉可以通过按 1 字节、跳过 3 字节、取下一个字节、跳过 2 字节、取 2 字节、跳过 4 字节等一些周期序列中的步骤,从 T 获得密钥。跳过可以很小,因此 2 或 3 个跳过可以编码在一个密钥字节中。可能如果艾米莉获得了随机源 T,她可以确定小跳过的序列。为防止这种情况,跳过可以与在选定字节上添加一系列数字相结合,对 256 取模,同样周期性。如果跳过的数量和添加的数量是互质的,比如 12 个跳过和 11 个添加,那么是最安全的。使用这种方法,每个消息密钥将使用 2 字节作为起点,6 字节来编码 12 个跳过,再加上 11 个添加,总共 20 字节,或者 160 位。这种方法可以称为跳跃与添加。
在这种类型的系统中,Emily 无法重建 T 是至关重要的。例如,Emily 可能随着时间的推移获得了许多消息的明文并恢复了它们的密钥。如果她还知道这些密钥在 T 中的位置,也许是因为桑德拉在每条消息中将位置传输给了 Riva,那么她可能能够重建 T 的部分。因此,T 本身不应该用于密钥。应该保留 T 以构建 T[1]、T[2],…,然后可以将其划分为消息密钥。保留 T 可以保护桑德拉和 Riva,以防 T[i]中的任何一个丢失或损坏。T 可以称为基础密钥,T[1]、T[2],…可以称为派生密钥。
即使 Emily 可以以某种方式重建 T[1] 或 T[2],她也无法倒退恢复 T,因为 T 是真正的随机。如果 Emily 尝试所有可能的系数和滞后组合,没有任何东西能表明哪个是正确的随机字符串 T,因为有数以万计的字符串。
13.16 同步密钥流
在秘钥密码学中,Sandra 和 Riva 必须使用相同的密钥。通常这意味着要么(1)密钥被加密并与消息一起传输,要么(2)他们有一个密钥列表,并根据日期、时间或其他外部因素从列表中选择每个密钥。还有一种方法是流密码独有的。
Sandra 和 Riva 可以使用同步密钥流。这意味着 Sandra 和 Riva 都持续生成相同的密钥流。当 Sandra 加密一条消息时,她从她的密钥流中的下一个密钥字节开始,这也必须是 Riva 的密钥流中的下一个密钥字节。当 Riva 收到消息时,她必须从密钥流中的相同点开始。Sandra 和 Riva 必须在完全相同的时间从相同的初始种子开始生成。当 Sandra 和 Riva 之间有直接电缆连接,或者有视线塔到塔的连接,或者两者都从同一发射机接收过空中广播时,同步方法最为有用。它非常适合在狭小空间内传输数字化语音。
如果消息是通过具有节点或中继点有显著延迟的网络发送的,特别是分组交换网络,其中消息的部分可能通过不同路径到达并必须在接收端重新组装,发送方必须在传输开始时提供时间戳,比如在消息头中。
由于 Sandra 加密消息需要时间,消息从 Sandra 到 Riva 的传输也需要时间,似乎 Riva 必须比 Sandra 慢几微秒生成随机密钥。同样,当 Riva 发送消息给 Sandra 时,Sandra 也必须比 Riva 慢几微秒生成密钥。
有几种方法可以摆脱这一僵局。一种方法是让 Sandra 只在伪随机流中的特定周期开始消息。例如,Sandra 可能只在每 100,000 个周期开始一条消息。然后当 Riva 在第 123,456,789,123 个周期收到一条消息时,她知道密钥从第 123,456,700,000 个周期开始。如果消息接收时间更接近 100,000 的整数倍,比如第 123,456,701,234 个周期,Riva 可以尝试 123,456,700,000 和 123,456,600,000。Riva 需要存储最后两组 100,000 个伪随机数。100,000 个周期的数字可以根据 PRNG 的速度和两方之间的传输时间调整。
还有一个问题需要解决,即 Riva 如何检测到每个加密消息的起始和结束。如果通信通道有一个空闲状态,在该状态下既不传输零也不传输一,则没有问题。让通道在消息之间保持空闲。否则,让我们假设通道在空闲时发出一串稳定的零。在这种情况下,您需要在消息前后添加额外的 1 位,就像用引号括起消息一样,并要求在下一条消息开始之前必须传输至少 64 个零。在合法消息中发生 64 个零的几率微乎其微。 (此外,请注意,消息之间的平均时间实际上将超过 50,000 个周期;64 个周期只是最坏情况。)因此,当 Riva 检测到至少 64 个零后的 1 位时,她可以确信这是下一条消息的开始,当她发现 1 位后跟着 64 个或更多的零时,那标志着消息的结束。
13.17 哈希函数
哈希函数不是密码,但与密码密切相关,通常与密码学一起使用。在本节中,我将讨论哈希函数的两个用途,并为每个用途提供一个适用的哈希函数。
哈希函数经常用于搜索。假设您有一个人员列表,如客户、患者或学生,并且您经常需要搜索此列表以获取有关这些人的信息。哈希提供了一种快速搜索的方式,即通过将人的姓名转换为可以直接在表中找到的数字。例如,名称“John Smith”可以转换为数字 2307,其中表中的条目 2307 包含有关 John Smith 的信息。
这里有一个专为此目的设计的哈希。对于字母表中的每个字母 L,随机选择某个固定大小(例如 32 位)的二进制值 R(L)。要对名称进行哈希,只需对名称中每个字母的 32 位数字执行异或操作。该哈希的一个弱点是具有相同字母的名称将具有相同的哈希值。例如,ARNOLD、ROLAND 和 RONALD 的哈希值都相同。为了避免这个问题,在添加每个字母后,将哈希值向左循环移动 1 位位置。也就是说,

将最终的哈希值称为 H。H 可以通过缩放转换为大小为 T 的名称表的索引 I,公式为 I = ⌊HT/2³²⌋。例如,如果名称的哈希值为 917354668,表中有 5000 个条目,则索引为 ⌊917354668×5000/4294967296⌋ = ⌊1067.94⌋ = 1067。我们称这种哈希方法为 Hash32。
可能会有几个名称产生相同的索引。有各种方法用于处理这些索引冲突,例如使用一个单独的表来保存重复项,第二次对名称进行哈希以在表中选择不同的插槽,或将重复名称链接在一起。
哈希函数也用于消息认证。在这种情况下,整个消息被哈希为一个长的哈希值。假设是 16 个字节。这个哈希值必须以防篡改的方式发送给 Riva,例如通过一个可信赖的第三方,该第三方记录并加上时间戳的哈希值。然后 Riva 将对消息进行哈希处理并比较哈希值。如果它们不同,那么消息可能已被更改。用于此目的的哈希函数必须使得 Emily 无法修改消息而不改变哈希值成为不可行。也就是说,Emily 无法找到一个产生相同哈希值的不同消息。同样,Sandra 无法更改消息并声称她发送了更改后的消息,因为哈希值将不再匹配。
对于这个哈希函数,我们将使用 4 个高度非线性的替换,分别为 A、B、C 和 D。这些可能是公开已知的固定替换。值得花一些精力使这四个替换高度非线性且彼此之间的相关性最小化。基本操作是使用异或的组合函数将消息的每个字节与前 4 个字节进行组合,即执行异或操作,然后对结果进行简单的替换。让 H 是消息 M 的一个副本,以便消息在哈希处理过程中不被破坏。副本中的每个字符 H[n]都经过以下哈希处理:

这样,哈希的每个字节都依赖于前面的每个字节,并且每个后续的字节都依赖于它。
哈希需要一个初始化向量(第 11.10 节)以便对消息的前 16 个字节进行哈希处理。可以使用消息的前 16 个字节的副本。也就是说,最初字节 H[-15]到 H[0]与字节 H[1]到 H[16]相同,这些字节是消息的字节 M[1]到 M[16]相同。有了初始化向量,就可以将哈希从 H[1]传播到 H[L],其中 L 是消息的长度。
这使得最后几个字节的哈希相对较弱。Emily 可能很容易改变消息的最后几个字节。解决方法是在消息结束后继续哈希处理。为此,当我们对消息的前 16 个字节进行哈希处理时,我们保存这些哈希值以供以后使用。当我们到达消息的末尾时,我们附加这 16 个字节并继续哈希直到扩展消息的末尾。这最后的 16 个字节成为消息的哈希值。将此哈希方法称为Hash128。
对于某些机器,使用机器的 32 位算术函数,每次对消息进行 4 字节的哈希可能更快。消息和哈希值被视为 L 个 32 位字的列表,而不是 4L 字节。哈希数组 H 最初是消息的一个副本。如果消息长度不是 4 字节的偶数倍,则会附加多达 3 个字节以填充最后一个字。H 的前两个字的副本被附加到前面,即 H[-1] = H[1] 和 H[0] = H[2]。在对消息的前 4 个字进行哈希后,这 4 个字将附加到消息的末尾。
这种哈希,称为 HashPQ,使用两个素数 P = 2³²-5 = 4294967291 和 Q = 2³²-17 = 4294967279,以及魔法乘数 R = 77788888,它是 P 和 Q 的一个原根。哈希操作为

如果总和超过 2³²-1,则通过简单地忽略额外的高位比特来将值截断为 32 位。也就是说,我们可以自由得到模 2³² 运算。H 数组的最后 4 个字是 16 字节哈希值。与 Hash128 相比,HashPQ 使用的存储空间更少,因为它不需要 4 个简单的替换。
Hash32、Hash128 和 HashPQ 都具有良好哈希函数所需的理想属性,即对输入的任何位或位的组合进行更改会导致输出中大约一半的位发生更改。这三种哈希都很快,并且可以在单个从左到右的传递中完成。
第十四章:一次性密码
本章涵盖
-
一次性密码密码
-
伪一次性密码,它近似于一次性密码
-
Diffie-Hellman 密钥交换
-
构建 Diffie-Hellman 和公钥密码所需的大素数
最著名的流密码是一次性密码。许多作家将这个术语限制为仅指明文和密钥流逐字节进行异或的密码。这在历史上是不准确的。第一个一次性密码密码是由加利福尼亚州萨克拉门托的银行家弗兰克·米勒于 1882 年发表的,目的是通过缩短电报消息来节省费用。米勒的电报代码使用 5 位数字代码组来表示商业电报中常见的单词和短语。为了保密,米勒提出了一个密码,其中包括将 3 位数字添加到每个 5 位数字组中。他的代码值足够小,以至于总和永远不会超过 99999。也就是说,代码都小于 99000。因此,一次性密码最初是一个十进制系统,而不是一个二进制系统。
赋予一次性密码其名称的系统是由德国 Pers Z S(信号情报机构)的密码学家沃纳·昆策在 1922 年左右设计的。昆策的系统基于标准的 5 位数字组外交代码。与米勒的密码类似,昆策的密码将密钥组添加到代码组中。昆策使用了 5 位数字密钥组,逐位地将其添加到代码组中,而不进行进位。因此,33333+56789 将导致 89012,而不是 90122。昆策将密钥分发在 50 张纸的本子中,每张纸包含 8 行,每行包含 6 个密钥组。这些本子的页面一次用于加密一条消息,然后被丢弃。因此得名一次性密码。后来的发展包括使用水溶墨水和水溶纸进行快速处理。
另一个版本的一次性密码是由英国作家和编剧(Peeping Tom)利奥(利奥波德·塞缪尔)·马克斯于约 1940 年发明的。它被英国间谍广泛使用。马克斯的版本使用字母而不是数字。发送者将密钥字母加到明文字母模 26,以获得密文字母。换句话说,马克斯的一次性密码是一个带有随机密钥的贝拉索密码。麻省理工学院教授克劳德·香农在 1940 年至 1945 年之间发明了相同的密码,苏联信息理论家弗拉基米尔·科特尔尼科夫在 1941 年或之前发明了一个版本,但其细节仍属机密。香农和科特尔尼科夫都提出了一次性密码无法被破解的数学证明。它仍然是唯一被证明无法破解的密码方法。
自从米勒的 1882 年一次性密码和昆策的 1922 年一次性密码都使用十进制加法作为它们的组合函数,以及马克斯的 1940 年一次性密码使用模 26 加法,任何人都很难断言��次性密码仅限于使用异或来组合密钥和明文。一次性密码的定义特征是
-
关键是至少与消息一样长,
-
密钥与真随机不可区分,
-
每个密钥字符或块与一个明文字符或相同大小的明文块组合,并且
-
密钥仅使用一次。
任何满足这 4 个标准的密码都是一次性密码。然而,要证明一次性密码是无法被破解的,需要另一个更强的条件:
-
任何给定的明文字符转换为任何给定的密文字符的概率相等。
说了这么多,让我们看看一个基于异或的历史密码,与一次性密码系统密切相关。
14.1 佛南密码
到 1918 年,许多外交任务已经不再由人类电报操作员发送和接收消息,然后需要手动输入。相反,消息被打孔到由法国电报工程师埃米尔·鲍多特于 1870 年发明的 5 列鲍多码或由新西兰记者唐纳德·默里于 1901 年发明的鲍多特-默里码的纸带卷中。(我不会详细介绍这些代码的细节,因为它们在 1870 年至 1950 年代之间几次改变,当西联电报公司在 1963 年停止使用它们时,鲍多特风格的代码完全被废弃了。)重要的特征是一个人类打字员将消息键入到一个 5 列纸带中,从而可以直接在接收端传输和打印而无需任何进一步的人类参与。
与摩尔斯密码一样,无论是鲍多码还是鲍多特-默里码都没有提供任何保密性。任何人都可以直接从磁带上读取消息。直到 1918 年,如果需要保密性,消息必须由人工密码员手动加密,然后被输入到磁带上,并由接收端的另一名职员手动解密。需要一种方法来加快这个过程。于是佛南出现了。
佛南密码由 AT&T 贝尔实验室的吉尔伯特·桑福德·佛南在 1918 年应陆军信号部的约瑟夫·O·莫伯格纳之邀开发。这个想法非常简单而巧妙。一个人类打字员会像以前一样将消息键入到磁带上,但实际传输的是字符代码与密钥代码的异或。密钥代码来自一个单独的纸带,其上打有看似随机的字符序列。在接收端,传输字符将与该磁带的副本进行异或运算,从而解密它们。每个磁带有 1000 个类似随机的字符,以便长消息每 1000 个字符重复一次密钥。
该图显示了两个包含明文和密钥的磁带,用于读取磁带的拾取器,用于将密钥与明文进行异或运算的电路,以及接收端的打孔机,该打孔机可能位于远程位置。打孔机可以根据设置替换为打印机或发送器。

这是我自己的图表,因为我找不到 Vernam 机器本身的图片,可能是因为它被列为机密。
我将密钥带称为“近似随机”,因为它们是由一个人在类似打字机的键盘上敲击而产生的,这是 Friden Flexowriter 的前身。结果是键盘中心附近的字符比角落附近的字符更经常使用。人类很难产生随机数或字符。但对于 1918 年来说,这是一个非常强大的密码。
许多来源错误地将 Vernam 密码称为一次性密码本,可能是因为它是第一个使用二进制消息与二进制密钥进行异或运算的密码。然而,Vernam 密码并不是一次性密码本,因为它是重复的。它有一个固定的 1000 个字符的周期。此外,一次性密码本早在 36 年前就由米勒发明了,并且最初是一个基于十进制的系统。
对于一个繁忙的大使馆,可能每天会有 100 个或更多的密码消息。如果大使馆与其他几个大使馆通信,就需要多套带子。用于华盛顿到柏林的带子将与用于柏林到华盛顿的交通的带子分开。所有带子都标有 6 位数的序列号。在发送每个消息之前,带子编号将以明文形式传输,即未加密。办事员们需要区分哪些带子是为哪个大使馆准备的,哪些带子已经使用过需要销毁。新的带子必须不断地提供给每个大使馆。
Vernam 很快设计了第二个版本,使用了两个带子,两个带子都与明文进行了异或运算。一个带子有 1000 个字符,另一个带子有 999 个字符,使有效周期为 999,000 个字符。同一两个带子可以在整个一天内使用,只需在每个带子上的不同位置开始每个消息即可。如果一个大使馆有,比如,100 个带子,那么可以在不同的日子使用不同的带子组合,只要纸带能支持。
很容易看出 Vernam 的 2 带机器如何扩展到 3 或 4 带。就我所知,这从未发生过,因为这些基于带子的机器很快就被转子机取代了(参见第 5.10 节)。
14.2 密钥供应
一次性密码本的主要问题是提供足够的密钥。纸带方法可能足够用于每天发送 100 条消息的 10 个站点,但对于每天发送 1000 条消息的 100 个站点来说是行不通的。
许多关于密码学的书籍和论文描述了以下难题:桑德拉和里瓦决定使用一次性密码交换消息。他们每个人都有一份长随机密钥的副本。他们逐段使用这个密钥,直到用完为止。现在他们需要另一个随机密钥。桑德拉可以选择并发送给里瓦,但需要加密以防艾米莉获取。最安全的方法是使用一次性密码对其进行加密,因此他们需要另一个与之长度相同的密钥来加密新密钥。同样,桑德拉可以选择并发送给里瓦,但该密钥也需要加密。因此,他们需要另一个密钥,无穷尽。
这个困境的解决方案是双管齐下的。首先,可以使用第 13.15 节的技术(如滞后加法)刷新随机密钥流。例如,每天一次,或者当各方决定时,可以从基础密钥派生一个新密钥。其次,这些派生的每日密钥不需要直接用作消息密钥。相反,可以从每日密钥构建消息密钥。这样,即使艾米莉恢复了任何消息密钥,她距离恢复基础密钥还有两层。接下来的几节将描述一些生成消息密钥的方法。
每种方法都旨在实现两个目标:要么(1a)该方法必须能够每天生成足够的消息密钥材料,以便没有两个消息密钥重叠,要么(1b)艾米莉不可能检测到消息密钥的重叠部分,以及(2)艾米莉不可能重建派生密钥或基础密钥的部分。
14.2.1 循环密钥
每日密钥是使用第 13.14 节的技术派生的。每日密钥的连续部分用于生成消息密钥,例如通过轻度加密。一个带有密钥的简单替换就足够了。我建议在连续密钥之间留下随机宽度的间隙,例如 1 到 32 字节。当到达每日密钥的末尾时,它会使用滞后线性加法(第 13.14.1 节)的单次传递来延长以供在消息量较大的日子使用。您可以通过想象每次发送消息时,其密钥加上任何间隙都会从每日密钥的前端移动到每日密钥的末尾,并使用滞后线性加法进行刷新来可视化这一点。桑德拉和里瓦必须同步进行此操作。
这在消息量较低且桑德拉和里瓦很少同时发送消息的情况下效果很好。对于更高的消息量,最好使用两个基础密钥和两个每日密钥,一个用于桑德拉到里瓦的消息,另一个用于里瓦到桑德拉的消息。
14.2.2 组合密钥
对于长度为L的每条消息,从每日密钥中取出长度为L的三个段。将这些段称为 x、y 和 z,并将它们在每日密钥中的起始位置称为 p[x]、p[y]和 p[z]。如果这些位置中的任何一个接近每日密钥的末尾,则该段可能回到开头。消息密钥的每个字节都是通过取 x、y 和 z 中相应字节的线性组合形成的。也就是说,

其中系数 a、b 和 c 可以是 1 到 255 之间的任何奇整数。三个系数 a、b 和 c 的值以及三个起始位置 p[x]、p[y]和 p[z]对于每条消息必须是不同的。这些可以事先商定,或者加密并与每条消息一起发送。
14.2.3 选择密钥
对于长度为 L 的每条消息,从每日密钥中随机选择两个不重叠的段。第一个段是选择器,s,长度为 L。第二个段是库存,x,长度为 256。为了加密消息中的第 n 个字符 m[n],我们首先从选择器中取出相应的字节 p = s[n]。这个 p 选择了库存中取出密钥字节的位置,即 k[n] = x[p]。密钥字节 k[n]与消息字节 m[n]结合使用任何组合函数,如异或或加法。
在使用密钥字节 k[n]后,x[p]在库存中被替换为(ax[p]+b) mod 256。系数 a 和 b 必须满足 Hull-Dobell 条件(第 13.4 节),即 a≡1(mod 4)且 b≡1(mod 2)。实际上,库存 x 中的 256 个位置中的每一个都成为一个独立的线性同余伪随机数生成器(PRNG)。系数 a 和 b 可以对库存中的所有 256 个位置使用相同的值,也可以不同。一种选择是使用两对不同的 a 和 b 值,并根据某种固定模式选择第一对或第二对。无论使用多少对值,对于不同的消息,它们应该是不同的。
另一种更新库存的方案是将 x[p]替换为(ax[p]+bx[p-1]) mod 256,其中 a 和 b 是 1 到 255 之间的任何奇整数。您还可以选择将 x[p]替换为(ax[p]+bx[p-i]) mod 256,其中 i 是从 2 到 255 的任意整数。
由于 a 和 b 只有 8192 个可能的值,并且由于应避免值 a = 1,因此重复是不可避免的。然而,只要 Emily 无法确定每条消息使用了哪对值,这就不是问题。重要的是 Emily 无法累积多条她知道具有相同 a 和 b 值的消息。使用指示器的一个缺点是对手可能收集几条具有相同指示器的消息,因此他们知道这些消息具有相同的密钥。
14.3 指示器
在古典密码学中,通常会长时间使用同一把密钥,有时甚至长达几个月或几年。而在现代,密钥通常只用于单个消息。使用一次性密码本时,消息密钥必须只能使用一次。否则,艾米丽可能会将一条消息滑动到另一条消息上,并使用重合指数(第 5.7 节)来检测重叠。
对于适度的双向消息流量,桑德拉和里瓦可以使用一本小书,列出按照例如时间和星期几来使用的密钥。在计算机出现之前的一种常见做法是给每条消息编号。消息编号可以被加密并与消息一起发送。桑德拉和里瓦将使用消息编号在书中查找密钥。
当消息流量增加或有许多交换消息的参与方时,密钥本就变得不可行。即使将书本替换为计算机文件,情况也是如此。解决这个问题的一个方法是使用指示器。指示器是随消息一起发送的信息片段,接收方可以用来确定密钥。
在早期,指示器只是密钥本身,隐藏在消息中。例如,消息的第三组是密钥,或者前 8 组的第一个字符组成了密钥。稍微复杂一点的版本可能是,第二组的中间数字告诉您哪一组是密钥。这些类型的指示器的明显问题是,一旦艾米丽学会了系统,她就可以阅读所有的消息。即使艾米丽不知道这个系统,她也可以简单地尝试消息中的所有组,看看其中是否有一个是密钥。如果她找到了一些这样的密钥,那么她可能就能推断出模式。
更安全的方法是加密密钥并将其用作指示器。这就是二战期间德国人使用 Enigma 机器所做的。他们有一个特殊的设置,每天更换一次,用于加密消息密钥。他们首先将 Enigma 设置为每日设置,并使用该设置加密消息密钥两次。然后他们将机器重置为消息密钥,个别操作员会随机选择,并加密消息。波兰的Bomba利用了消息密钥的双重加密来推断这些密钥。(bomba kryptologiczna是由波兰首席密码学家玛丽安·雷耶夫斯基于 1938 年设计的一种用于破解德国 Enigma 消息的电机械设备。)当德国人意识到这一点时,他们停止了这种做法,波兰人被封锁了;他们不再能读懂 Enigma 消息。艾伦·图灵预见了这个问题,并设计了他的Bombe来处理密码词,或者是可能的明文。法国的 Enigma 破译机也被称为 bombe,据说是以冻雪糕(一种类似于圆顶形的冰淇淋,像阿拉斯加烤冰淇淋)命名的。
第 14.2 节描述了从每日密钥生成消息密钥的几种方法。每种方法都使用一小组参数来生成每个消息密钥,例如滞后线性加法的系数,或者每日密钥中的位置。这些参数集合非常适合用作指示器。
14.4 Diffie-Hellman 密钥交换
关于传统方法就说这么多。让我们谈谈一个更现代的方法。Diffie-Hellman 密钥交换是由斯坦福大学教授马丁·赫尔曼和他的研究助理贝利·惠特菲尔德·迪菲于 1976 年发明的,后者后来成为 Sun Microsystems 的员工。公钥密码学的基本概念是由加州大学伯克利分校本科生拉尔夫·默克尔于 1974 年发明的。
Diffie-Hellman 密钥交换的关键特点是,即使 Emily 拦截了他们交换的所有消息,Sandra 和 Riva 也可以建立一个安全的加密密钥。为了设置交换,Sandra 和 Riva 必须就一个大素数 P 和该素数的一个原根 w 达成一致。或者,Sandra 可以简单地选择 P 和 w 并将它们发送给 Riva。P 和 w 可以明文发送。回想一下第 13.3 节,找到原根是很容易的。对于大多数素数,2、3、5 或 7 中至少有一个是原根。
Sandra 选择一个秘密指数 s,并计算 x = w^s mod P。她将数值 x 发送给 Riva,但保留 s 的数值。Riva 选择一个秘密指数 r,并计算 y = w^r mod P。她将数值 y 发送给 Sandra,但保留 r 的数值。现在 Sandra 可以计算 y^s mod P,即 w^(rs) mod P,而 Riva 可以计算 x^r mod P,即 w^(sr) mod P。由于 w^(rs) = w^(sr),Sandra 和 Riva 计算出相同的数值,他们可以将其用作加密密钥,或者将其分割成几个加密密钥。在第 13.3 节中描述了执行指数运算的有效方法。
一些作者(以及维基百科)将 Diffie-Hellman 密钥交换描述为一种公钥方法。他们谈论结合 Sandra 和 Riva 的公钥及其私钥。这是不正确的。Diffie-Hellman 中没有涉及公钥。即使将指数 r 和 s 视为密钥,它们也都是秘密密钥。
假设 Emily 拦截了 Sandra 和 Riva 之间的所有消息。那么 Emily 知道 P、w、x 和 y,即 w^s mod P 和 w^r mod P,但她不知道 s、r 或 w^(rs) mod P。确定 w^(rs) mod P 被称为Diffie-Hellman 问题。目前尚不清楚这是否与确定 r 和 s 相同,但它们被认为是同样困难的问题。在给定 P、w 和 x 或 y 的情况下确定 s 和 r 被称为离散对数问题。这被认为是一个非常困难的问题。当 P、r 和 s 足够大时,这个问题被认为是计算上不可行的。专家们对 P 必须有多大存在分歧,但常见的建议是 300 和 600 位十进制数字。一些实现允许 P 达到 1234 位十进制数字,即 4096 位。指数 r 和 s 可以小得多。专家建议范围从 40 位十进制数字到 150 位十进制数字。
一个名为Silver-Pohlig-Hellman算法,以 Roland Silver、Stephen Pohlig 和 Martin Hellman 命名,使得在 P-1 只有小因子时解决离散对数问题变得容易。该算法让你可以分别解决每个小因子。因此,Sandra 必须确保 P 是一个安全素数,即 P-1 至少有一个大因子,比如 q > 10³⁵。理想情况下,Sandra 应选择 P 为形式为 2Q+1 的素数,其中 Q 也是素数。对应的素数 Q 被称为 Sophie Germain 素数,以法国数论家玛丽-索菲·杰尔曼(Marie-Sophie Germain)命名,她还研究过声学和弹性学。如果 Q-1 和 Q+1 都有大素因子,那就更强大了。在下一节中,我们将明确构造 Q,使得 Q-1 有一个大素因子。很可能 Q+1 也有一个大素因子,仅仅是因为 Q 太大了。只有小因子的数字被称为光滑数。随着数字变大,它们变得非常罕见。
*14.4.1 构造大素数,旧版
构建大素数的传统方法通常可以在许多网站上找到,它首先通过随机选择所需大小的奇数 N,然后测试 N 是否为素数。首先尝试几百个小素数。如果 N 可被其中任何一个整除,则 N 不是素数。重新选择。这种初步测试非常值得,因为它非常快速。接下来,通过应用概率素性测试来测试 N 是否为素数。最常见的测试是由加里·米勒和迈克尔·O·拉宾发明的Miller-Rabin测试。让 N-1 = 2^hd,其中 d 是奇数。也就是说,2^h 是能够整除 N-1 的最大 2 的幂。第一步是在范围 2 到 N-2 中选择一个基数 b,并测试 b^d≡1(mod N)是否成立。如果成立,则 N 通过测试。如果不成立,则查看 b^(2d)≡-1(mod N)是否成立,或者 b^(4d)≡-1(mod N),依此类推。只要指数 2^gd 仍然小于 2^hd,就一直继续。如果找到这样一个值 g,则 N 通过了测试,b 被称为 N 的见证者。如果找不到这样的 g,则可以确定 N 不是素数,因此必须重新选择 N 的值。
如果 N 通过了测试,仍然有 1/4 的概率 N 是合数。如果你想将 N 不是素数的概率降低到 2¹²⁸的倒数 1,你将需要 64 次 Miller-Rabin 测试,每次都使用不同的底数 b。不幸的是,这仍然不能保证。Miller-Rabin 测试错误地将卡迈克尔数认定为素数。这些数字不是素数,但每个底数 b 都是证明数的见证者。这些数字是由伊利诺伊大学的罗伯特·卡迈克尔于 1910 年发现的。前几个卡迈克尔数是 561、1105、1729、2465、2821、6601、8911、10585、15841、29341 和 41041。卡迈克尔数倾向于有小的素数因子,因此通过 64 次 Miller-Rabin 测试,并且还发现 N 不可被前几百个素数中的任何一个整除,使得 N 是素数的可能性非常大。
这是一种寻找特定大小素数的好方法,但不能保证 N 是一个安全素数,并且比本节方法要慢得多。如果 S 是您需要的素数的大小,那么您需要找到一个素数的尝试次数大约是 ln(S)。因此,对于一个 500 位数的素数,您需要大约 ln(10⁵⁰⁰)或者大约 1151 次尝试,每次尝试需要 64 次 Miller-Rabin 测试和数百次试除。使用我在本节中提出的方法可以节省您几个小时甚至几个星期的计算机时间,这取决于您使用的计算机类型以及所需的素数的大小。
14.4.2 构建大素数,新的
你可以尝试找到一个大质数的一种方式是从任何大整数 N 开始,然后尝试 2N+1, 2N+3, 2N+5, … 测试每个直到找到一个质数为止。对此的一种小改进是测试 6N+1, 6N+5, 6N+7, 6N+11, 6N+13, … 。这样可以从测试中消除所有 2 和 3 的倍数。你也可以尝试 30N+1, 30N+7, 30N+11, 30N+13, … 来消除 2、3 和 5 的倍数,类似的方法还有 2×3×5×7 = 210,以此类推。
测试一个给定的整数 N 是否为质数有多种方法。最简单的方法是试除法。要测试 N 是否为质数,尝试将 N 每个小于等于 √N 的质数整除。如果其中任何一个质数能整除 N,则 N 是合数,否则 N 是质数。试除法适用于约 N = 10¹²,可能是 10¹⁴,但对于更大的 N,试除法耗时太长。大多数其他的质数测试只是概率测试,告诉你这个数可能是质数。
有一种测试可以确定一个数字是质数:如果一个大于 1 的整数 N 有一个原根,那么它就是质数。回顾第 13.3 节,如果 r^(N-1) mod N = 1,并且 r^((N-1)/p) mod N ≠ 1 对于任何能整除 N-1 的质数 p 都成立,那么 r 是 N 的原根。要测试 N 是否为质数,你只需要对于 N-1 的每个不同的质因数 p,分别计算 r^x mod N,其中 x = N-1 和 x = (N-1)/p。让我们称这种方法为原根质数测试,或者简称为根测试。这种方法是由法国数学家爱德华·卢卡斯在 1876 年发明的,同样是那个创造了斐波那契数(第 3.4 节)这个术语的爱德华·卢卡斯。卢卡斯于 1891 年因一场悲剧性的汤事故去世。
只需尝试 2、3、5、7、11 和 13 作为可能的原根即可。如果 N 有原根,那么至少这 6 个值中的一个很可能是原根。如果这些值中没有一个是原根,请不要浪费时间尝试其他值。更高效的方法是转到下一个质数的候选项。
Lucas 的根测试的问题在于你需要分解 N-1,如果 N 有 300 个或更多的数字,那么分解 N-1 实际上是不可能的,至少在没有量子计算机的情况下是不可能的。这就是为什么你在许多讨论质数测试的书籍或网站中不会看到这个测试被提及的原因。
有一种方法可以避开这个障碍。记住,你的目标不是找到一般的质数测试方法。你的目标是获得一个大质数来用作 Diffie-Hellman 密钥交换的模数。所以,与其找到那个质数,你可以构造出这个质数。
关键是选择具有已知因子的 N-1。例如,你可以选择 N-1 具有 2^n 的形式,因此 N 将具有 2^n+1 的形式。N-1 的唯一质因数将是 2。要找到形式为 2^n+1 的素数,你只需要找到一个数字 b,使得 b^(N-1) mod N = 1,且 b^((N-1)/2) mod N ≠ 1。我建议你尝试 b = 2、3、5、7、11 和 13。如果这些都不是原根,那么跳过 N = 2^n+1,看看 N = 2^(n+1)+1 是否为素数。这个搜索将获得你素数 3、5、17、257 和 65537。尽管人们花费了数千小时的计算机时间搜索,但目前尚不清楚是否还有其他素数。这 5 个素数被称为费马素数,以法国数学家皮埃尔·德·费马特命名,因为他著名的边注是关于方程 an+bn = c^n。
概述
在我详细介绍之前,让我概述一下构造一个大素数 P 的一般方法。该方法必须完成三件事:
-
P-1 必须具有一个大的素数因子,以便 P 是安全的,
-
每个候选的 P 应该具有较高的素数概率,以便你需要尽可能少的质数测试,
-
P-1 应该具有较少的不同质因数,以便每个质数测试尽可能快速。
对于寻找大素数的任何搜索都将涉及测试数百甚至数千个候选者。让我们称预期测试次数为 E。这里的方法是使 P-1 的每个候选者成为两个数的乘积 cK。系数 c 将通过一系列相对较小的数字进行步进,通常与 E 相当。核 K 将是一个大素数、两个大素数的乘积或者最多 2 个质数的乘积的幂,paqb,其中至少有一个是大素数。让我们先看看如何选择系数,然后再看如何选择核心。
系数
最简单的选择系数的方法是逐个遍历质数。由于系数必须是偶数,你需要使用每个质数的两倍,2×2、2×3、2×5、2×7,等等。让我们称这个方法为PickPrimes。PickPrimes 最小化了 cK 中不同质因数的数量。c 中最多有 2 个不同的质因数,在 K 中也最多有 2 个不同的质因数。然而,PickPrimes 对减少所需的测试次数几乎没有什么帮助。
第二种选择系数的方法是使它们具有 paqb 或 paqbr^c 的形式,或类似的形式。这里的 p、q 和 r 是小的质数,如 2、3 和 5,或者 2、5 和 7。(在本节的后面我们将看到必须省略 3 的情况。)这样,P 就永远不可能是 2、3 或 5 的倍数,这显著增加了 P 是素数的机会。如果你使用这种方法,你可能想要预先计算并排序系数的列表。
核心
内核 K 必须至少有一个大素数因子 R。我建议 R 至少为 2¹²⁸,约为 3.4×10³⁸。如果你的对手拥有量子计算机,请将 R 至少设为 2²⁵⁶ = 1.16×10⁷⁷。那么,你从哪里获得这些素数呢?如果你愿意接受 30 位数的素数,你可以从 bigprimes.org 网站在线获取一些。
如果你期望生成许多大素数,或者非常大的素数,你可以自己生成。提前准备,建立一个各种大小素数的表。将此表命名为 PrimeTab。一定要保存 PrimeTab,这样每当你需要更多素数时,就不必重复此过程。你可以从小于 100 的 25 个素数开始你的素数表。你可能能够背诵这些,所以只需将它们输入程序中。接下来,如果你愿意,你可以使用试除法生成一些 3 到 12 位数的素数,比如每个尺寸 2 或 3 个素数。我建议你随机进行,这样每次使用此方法时都不会构造相同的素数(以及每个使用此方法的读者都不会生成相同的素数)。在这个阶段,PrimeTab 可能有大约 50 个素数。
构建 R(小步骤方法)
现在让我们开始尝试构造 R,即 Q-1 的大素数因子。你可以通过找到每个比上一个素数稍大一点的素数来逐步构建 R,也可以一次跳跃到那里。如果你期望生成许多大素数,请分步构建,以便 PrimeTab 后面可以有很多条目供以后使用。为了说明这两种技术,让我们以小步骤构造 R,并以一次巨大的飞跃构造 Q。
假设 PrimeTab 包含 k 个素数,p[1] < p[2] < p[3] < … < p[k]。要构造下一个素数,首先从表中选择任意两个素数,比如 p[i]和 p[j]。让 r 为乘积 p[i]p[j]。如果 r < p[k],你可能希望选择更大的 i 或 j,以免生成太多小素数。当然,你需要一些小素数,所以我建议当 p[i]p[j] < p[k]^(2/3)时选择更大的 i 或 j。首先,使用 Lucas 测试来确定 R = 2r+1 是否为素数。这很容易,因为你知道 R-1 的唯一素因子是 2、p[i]和 p[j]。如果 2r+1 不是素数,请尝试 4r+1、6r+1、10r+1 等,使用 PickPrimes 方法选择系数。当数字开始超过 20 位数时,找到一个素数可能需要每个素数 50 次或更多的尝试。
减少测试次数
当数字变得非常大时,你可以通过检查每个候选数 nr+1 是否可被许多小素数整除来节省时间,然后再寻找一个原根。例如,你可以验证 nr+1 是否不能被前 100 个素数中的任何一个整除。你可以通过提前计算 x[i] = r mod p[i]来使这个测试更快,其中 i 是前 100 个素数。然后,不是计算(nr+1) mod p[i],其中 r 可能有几百位数,而是计算(nx[i]+1) mod p[i],其中 x[i]只有 1 到 3 位数。也就是说,你只需进行一次试除(r mod p[i]),而不是对每个 n 值都进行一次。我们称这种方法为PrimeCheck。
PrimeCheck之所以有效是因为候选素数是按顺序选择的。你无法用传统方法找到大素数,因为候选素数是随机选择的。这使得对小素数的试除对这种方法更快,而且由于速度更快,你可以使用更多的小素数,比如 300 个而不是 100 个,从而减少所需的试验次数。
如前所述,如果 2、3、5、7、11 或 13 中没有一个是 nr+1 的原根,则跳过该候选数,并尝试下一个 n 值,直到找到下一个素数。由于这种方法每个候选数只使用 6 次测试,而传统方法使用 64 次测试,因此这种方法的速度是传统方法的 10 倍以上。将找到的每个素数添加到PrimeTab中。
构建 P 和 Q(巨大飞跃方法)
假设你的目标是找到一个 300 位的Sophie Germain素数。继续扩展PrimeTab,直到它至少有一个大素数,比如 R > 2¹²⁸。现在你已经准备好使用巨大的飞跃来生成你的 300 位素数。首先选择一个所需大小的目标 T,比如 T = 10³⁰⁰。可以使 P 任意接近目标值,但这对 Diffie-Hellman 密钥交换并不需要。T 只是一个所需的最小尺寸。
下一步是找到 Q。记住 Q 必须满足三个要求:Q 必须是素数,Q-1 必须是大素数 R 的倍数,且 P = 2Q+1 也必须是素数。找到 Q 的策略是从一些所有质因数都已知的种子数 t 开始,然后使用PickPrimes尝试 2t+1、4t+1、6t+1、10t+1 等。
警告:如果你让 t 成为 3 的倍数,那么 Q 将具有 3x+1 的形式。这意味着 P = 2Q+1 = 6x+3 将是 3 的倍数。让 t 成为 3 的倍数意味着 P 永远不可能是素数。
由于 T 是 P 的最小值,而 Q 约为 P/2,因此 t 应约为 T/2。要构造 t,从 PrimeTab 中最大的素数 R 开始。取小于 T/2 的最大 R 的幂,称为 R^r。例如,如果 T 为 10³⁰⁰,而 R 约为 10⁴⁰,那么 T/2 约为 5×10²⁹⁹,所以 r 为 7。这意味着 R^r 约为 10²⁸⁰。直接从 10⁴⁰跳到 10²⁸⁰是巨大的飞跃。这个 R^r 远远低于 5×10²⁹⁹,所以设定 t = R⁷S,其中 S 约为 5×10¹⁹。当 S < 10¹²时,您可以使用试除法找到大于 S 的下一个素数。如果这是 S’,那么 t 就是 R⁷S’。当 S > 10¹²时,您可以将 S’设置为 PrimeTab 中的一个素数和您必须选择的小于 10¹²的素数的乘积,或者您可以将 S’设置为素数的平方或立方。假设后者。在这个例子中,S 约为 5×10¹⁹。它的平方根约为 7,071,067,812。下一个更高的素数是 U = 7,071,067,851。因此,t 将是 R⁷U²。
现在你已经构建了 t,并且知道了它的所有素数因子,你可以开始搜索 Q,通过使用根测试测试 2t+1、4t+1、6t+1、10t+1 等。随机选择的数字 N 成为素数的概率约为 1/ln(N)。当 N 的数量级为 10³⁰⁰时,ln(N)约为 690。这意味着大约需要 690 次尝试才能找到 nt+1 形式的素数。P 也必须是素数,这也有约为 1/690 的概率。这意味着大约需要 690² = 476100 次尝试才能找到 Q = nt+1 和 P = 2Q+1,它们都是素数。这是很多次测试。
这些测试非常耗时,因此任何减少测试次数的技术都是宝贵的。在这种情况下,我们可以使用 PrimeCheck 的自然扩展。对于每个素数 p[i],像之前一样计算 x[i] = t mod p[i]。对于每个 n 值,检查 nx[i]+1 是否能被 p[i]整除,以验证 Q 不是 p[i]的倍数,并且还要检查 2(nx[i]+1)+1,即 2nx[i]+3 是否能被 p[i]整除,以验证 P 不是 p[i]的倍数。这样你就可以从 x[i]列表中获得双倍价值。
秘密素数
对于一些密码,您可能需要使用一个只有您自己和您的合法通信者知道的秘密素数。您仍然可以使用本节的方法构造您的素数,但是,您需要确保任何对手都无法按照相同的步骤发现您的素数。我建议两项预防措施。(1)当您初始化 PrimeTab 时,不要选择 3 到 12 位数字大小的 2 或 3 个素数,而是随机选择 3 到 14 位数字大小的 5 到 10 个素数。目标是在 PrimeTab 中至少有 100 个初始素数。(2)使用构造 P、Q 和 R 的小步方法,最好在初始素数之外使用至少 100 个额外步骤。
精确大小
构建质数的巨大飞跃方法可以轻松修改为找到精确大小的质数。这是一个例子。假设您需要在 10³⁰⁰ 和 1.1×10³⁰⁰ 之间的质数。选择比 10³⁰⁰/2000000 稍大的 r,即 5×10²⁹⁴。使用 PickPrimes,但从 1000000 开始您的质数,即 1000003、1000033、1000037、1000039,依此类推。使用 PrimeCheck 来减少测试次数。
在 1,000,000 和 1,100,000 之间大约有 6700 个质数,在 10³⁰⁰ 和 1.1×10³⁰⁰ 之间的每 690 个数字中,大约有 1 个是质数,因此几乎可以肯定您会找到所需大小的质数。概率可以很容易地计算出来。在所需范围内的任何给定数字不是质数的几率是 689/690。所有 6700 个选择的数字都不是质数的几率是 (689/690)⁶⁷⁰⁰,或者是 0.00006。因此成功的机会是 99.994%。
第十五章:矩阵方法
本章涵盖
-
使用整数矩阵乘法或环元素矩阵的加密
-
使用大整数和小整数的加密
-
解线性同余方程
-
构造环和可逆矩阵
矩阵是一种非常适合用于密码学的工具,因为它们可以在一次操作中对任意大的文本块进行加密。通常,消息中的每个块都被视为字节向量,意味着模 256 的整数。

当桑德拉使用矩阵来加密消息时,瑞娃必须使用该矩阵的逆矩阵来解密消息。让我们从讨论矩阵方法的技术开始,这是一种求逆矩阵的技巧。
15.1 求逆矩阵
有几种解决矩阵方程(比如 C = AP)的方法,例如已知明文的情况下。由于艾米丽知道 P 和 C,但不知道 A,她可以通过右乘 P’ 来解方程得到 CP’ = APP’ = A。因此,艾米丽需要求 P 的逆。瑞娃则相反。她知道 A,但不知道 P,因此她需要求 A 的逆。将方程左乘以 A’,她得到 A’C = A’AP = P。
这里展示的方法有一个优点,即直接获得逆矩阵,而无需倒推的中间步骤,这是其他方法所必需的。该方法是将给定的矩阵与单位矩阵放在一个 n×2n 的双宽矩阵中。左侧通过初等行变换仅减少到单位矩阵。这些行操作应用于双矩阵的每一行,因此随着左半部分从原始矩阵变为单位矩阵,右半部分从单位矩阵变为原始矩阵的逆。
初等行变换包括(1)将一行乘以可逆常数,(2)交换两行,和(3)从另一行减去一个行的倍数。
该算法逐个将原始矩阵的元素转换为单位矩阵的元素,从左上角开始,然后向下处理左列。然后它对第二列执行相同的操作,依此类推。如果算法在任何时候被卡住,意味着活动列中的所有元素都是 2 的倍数,或者它们都是 13 的倍数,则该矩阵是不可逆的。如果这种情况发生在桑德拉身上,她需要尝试不同的矩阵 A。通常,只需在底部行的某个元素上加 1 即可。如果这种情况发生在艾米丽身上,她将需要更多的已知明文字符。这将给她一个(n+1)×n 矩阵。当她应用这个算法时,逆矩阵位于双宽矩阵的右上 n×n 部分。
这是一个 3×3 的例子。此矩阵适用于 26 个字母的英文字母表,因此矩阵元素是模 26 的整数。没有涉及到分数和负数。由于这是模 26 进行的,每个不是 2 的倍数且不是 13 的倍数的元素都有一个乘法逆元。这使得我们可以将每行的第一个非零元素变成 1,这样可以轻松地决定从任何其他行中减去哪个行的倍数。原始矩阵是

通过在右侧附加一个 3×3 的单位矩阵来将其扩展为双宽格式。

你立即陷入了困境,因为任何行的第一个元素都不是可逆的。我是故意这样做的,以展示一个非常有用的技巧。第一行的第一个元素是 13 的倍数,但不是 2 的倍数。第二行的第一个元素是 2 的倍数,但不是 13 的倍数。如果你简单地将第二行加到第一行,那么第一个元素就变成了 19,既不是 2 的倍数也不是 13 的倍数,因此它是可逆的。问题解决了。

19 的乘法逆元是 11 模 26,因为 19×11 = 209≡1 (mod 26)。你把第一行乘以 11,将矩阵的第一个元素变成 1。

现在,你可以通过从第二行减去顶部行的 6 倍,并从第三行减去顶部行的 10 倍来完成第一列。这将把第二行和第三行的第一个元素设为零。
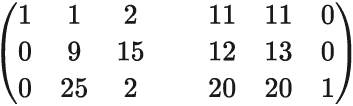
是时候处理第二行了。第二行上第一个非零元素是 9。9 的乘法逆元是 3,因为 9×3 = 27≡1 (mod 26)。你把第二行乘以 3,将行的第一个元素变成 1。

这让你通过从第一行减去第二行,并从第三行减去 25 倍的第二行来完成第二列。注意,双宽矩阵的左侧逐渐变成单位矩阵。

差不多了。第三行上第一个非零元素是 21。21 的乘法逆元是 5,所以你把矩阵的底行乘以 5。

现在,你可以通过从第三行减去第一行的 9 倍,从第二行减去第一行的 19 倍,完成第三列。

完成了。双宽矩阵的左半部分现在保存着单位矩阵,右半部分是原始矩阵的逆矩阵。你可以通过将原始矩阵乘以逆矩阵来检查这一点。结果应该是单位矩阵——而确实如此。
15.2 转置矩阵
让我们从一个非常简单的矩阵方法开始,即转置矩阵,它在数学上等价于置换矩阵。这是一个方阵,每行和每列都恰好有一个 1。所有其他矩阵元素都是 0。如果你想要转置一个由 10 个字母组成的块,你可以将该块视为一个大小为 1×10 的行矩阵,并将其乘以一个大小为 10×10 的转置矩阵。结果将是一个 1×10 的矩阵,字母被转置了。
要将一个字母从块中的第 2 位置移到第 5 位置,你需要将第 2 行第 5 列的元素设置为 1。下面是一个 4×4 的转置矩阵的示例,它将消息块 ABCD 更改为 BADC。

单独使用转置矩阵并不特别实用,但是如果你有一个矩阵 M 对一个块进行替换,并且一个转置矩阵 T,你可以通过使用矩阵 MT 替换 M 来将它们合并为单个步骤。这样,你就可以在单个操作中获得替换和转置。
15.3 希尔密码
基于矩阵的最早的密码是希尔密码,由亨特学院的莱斯特·希尔于 1929 年发明,并发表在美国数学月刊上。类似的密码在 1924 年由当时还是十几岁的杰克·莱文发明,在 1926 年发表在弗林周刊上,一本通俗侦探杂志。弗林周刊的密码专栏由 M·E·奥哈弗负责,他发明了分数化的摩尔斯密码(第 4.4 节)。巧合的是,弗林周刊是肯德尔·福斯特·克劳森(也在第 4.4 节提到)发表许多故事的地方。莱文一生致力于推翻希尔的密码并推广自己的密码。
希尔密码操作的是 26 个字母的字母表,字母按某种乱序编号为 0 到 25。也就是说,在矩阵运算之前进行简单的替换。你将明文字母分成 3 个一组。这形成了一个列向量,即一个 3×1 矩阵,P。你将这个列向量在左边乘以一个 3×3 矩阵 A,然后加上一个列向量 B,得到密文向量 C。在矩阵表示中,这被写成 C = AP + B,使用模 26 的加法和乘法。最后,你将数字转换回字母,使用相同的字母到数字的对应关系。
不幸的是,许多作者将 Hill 密码 限制为该密码的一个弱化、削弱的版本。为了避免歧义,让我们对 Hill 密码的几个版本进行编号。Hill-0 是最弱的版本。您使用标准英语字母表,没有混合,并省略 B 向量,以便 C = AP。Hill-1 稍微强大一些。您仍然使用未混合的字母表,但 B 向量不为零。Hill-2 是 Hill 最初提出的版本。您使用混合字母表和非零的 B 向量。Hill3 是一个更强大的版本,您在其中使用一个混合字母表将字母转换为数字,但您使用另一个混合字母表将数字转换回字母。这类似于第 9.6.1 节中的共轭矩阵双重密码。
Hill 密码,即 Hill-2,如最初发布的那样,基本上是一种秘密方法密码。字母转换为数字以及矩阵 A 和 B 都是固定的。没有密钥。任何知道这种方法的人都可以像预期的接收者一样轻松阅读消息。大多数最近的书籍和网站讨论 Hill 密码时忽略了混合字母表,并集中于矩阵运算。如果使用了固定的字母到数字的转换,这是合法的,因为可以去掉已知的字母表混合。
让我们首先看一下 Hill-0 情况,其中 A 是一个未知的 n×n 矩阵,向量 B 是 0,所以 C = AP。这就是普通的矩阵乘法,我们在第 11.3 节中见过。Riva 可以通过将密文乘以矩阵 A 的逆矩阵 A’ 来解密消息。逆矩阵具有这样的性质,即 A’A = AA’ = I,其中 I 是单位矩阵。在矩阵 I 中,每个对角元素为 1,每个其他元素为 0。单位矩阵类似于普通乘法中的数字 1,即对于每个数字 N,1×N = N×1 = N。对于矩阵,这意味着 IA = AI = A 对于每个方阵 A。如果 Emily 能确定 A’,她也可以解密消息。
这个 B = 0 版本的 Hill 密码容易受到已知明文攻击的影响。如果 Emily 有 n² 个已知明文字符,她可以将它们组成一个 n×n 矩阵。将此矩阵称为 P,并将相应的密文矩阵称为 C。那么 C = AP,其中 C、A 和 P 都是模 26 的 n×n 整数矩阵。有几种方法可以解决这个矩阵方程。一种方法如 15.1.1 节所示。
如果加法向量 B 不全为零,则艾米莉只需要更多已知明文的字符,她就可以从方程中消除 B。额外的已知明文字符可以形成一个列向量 P[2],相应的密文字符可以形成一个列向量 C[2]。这些向量可以像这样从方程中减去:(C-C[2]) = A(P-P[2])。这与 C = AP 具有相同的形式,并且通过相同的方式解决,即通过求逆矩阵 P-P[2]。通过从 n×1 列向量中减去 n×n 矩阵,可以将 n×1 列向量从矩阵中减去,方法是从向量的第一个元素中减去矩阵顶行的每个元素,从向量的第二个元素中减去矩阵第二行的每个元素,依此类推。

假设你没有已知的明文。仍然可以解决 Hill-0 变体。继续假设一个秘密的 3×3 乘法矩阵,C = AP。乘以 A’,A 的逆矩阵,得到 P = A’C。在消息的每个块中,块的第一个明文字符仅取决于 A 的顶行。这只有 26³ = 17,576 种可能性,所以很容易尝试它们。每个顶行的组合将确定明文中位置 1、4、7 等位置的字母。对于每个这样的组合,统计字母频率。
你可以使用第 5.9.1 节中描述的高峰方法将这些字母频率与标准英语字母频率进行比较。选择那些匹配度最高的组合,比如前 1%,或者前 175 个组合。对于每个块的第二和第三个明文字母,使用逆矩阵 A’的第二和第三行。这为每个 3 行提供了 175 个可能的组合。现在你可以尝试这些组合的组合,以获得整个消息的可能重构。只需尝试 175³ = 5.36×10⁶种组合。第 1 行的组合给出每个块的第一个字母,第 2 行的组合给出每个块的第二个字母,第 3 行的组合给出每个块的第三个字母,因此你拥有每个字母。
现在你可以使用三字母组频率确定最有可能的明文。使用所有的三字母组,不仅仅是 3 个字母的块,还有跨块的三字母组。这与我们在第 5.10 节和第 8.2 节中使用的过程相同,所以我不会在这里重复所有细节。如果这无法产生令人满意的结果,请回到起点,并为每个字母选择前 2%或前 350 个组合。
Hill 密码 Hill-1 使用一个秘密的 3×3 乘法矩阵和一个秘密的 3×1 加法矩阵,但使用未混合的字母表,被评为三级。在矩阵操作之前和之后都进行密钥混合替换后,被评为五级。它可以被解密为一般的三字母替换密码。对于更大的矩阵,评级会增加。为了达到十级评级,矩阵必须至少为 8×8,并且 Hill-3 矩阵操作必须应用两次。以下是步骤。(1)使用一个键入的非线性替换将消息转换为数字形式。(2)将每个块乘以矩阵并添加列向量。(3)对数字进行第二次非线性替换。(4)将每个块乘以第二个矩阵并添加第二个列向量。(5)使用第三个键入的非线性替换将结果转换回字母。两个乘法矩阵可以固定,但用于混合字母表的 3 个密钥和 2 个加法列向量应该在每条消息中更改。将此密码称为DoubleHill。
15.4 Hill 密码,计算机版本
Hill 密码对密码员来说太复杂,无法手工完成。Hill 还创建了一个机械设备用于进行加密和解密。这是为了满足当时的专利法,允许对机器进行专利保护,但不允许对数学算法进行专利保护。然而,这种密码在实践中几乎没有被使用。
如今,在计算机时代,Hill 密码再次变得实用。对于计算机来说,矩阵乘法是小菜一碟。使用 10×10 矩阵比 3×3 矩阵更容易。对于已知明文攻击,艾米莉需要 100 个字符而不是 9 个字符。这几乎是不可能的,除非通过间谍活动或在战场上截获消息。使用标准字母表的秘密 10×10 矩阵的 Hill 密码评级为六级。使用秘密 10×10 矩阵的 Hill 密码,在矩阵乘法之前和之后进行密钥混合替换,被评为八级。
通过使用多个矩阵并选择每个块的矩阵,可以进一步加强 Hill 密码,可以周期性或随机选择矩阵。矩阵和明文块的大小可能不同。由于矩阵乘法不是可交换的,当你在左边或右边乘以一个矩阵时,你几乎总是得到不同的结果。当你在左边乘以一个矩阵时,每个明文块必须被视为一个列向量,但当你在右边乘以一个矩阵时,它必须被视为一个行向量。这表明通过交替使用不同的方向,可以获得更安全的密码,可以周期性或随机地交替。可变矩阵,可变块大小和可变方向。你可以自行选择或混合使用。
你也可以将置换与希尔密码结合起来,但并不是每种置换都能提高安全性。假设你正在使用希尔-0 或希尔-1 变种,并且在矩阵乘法之后转置每个区块中的字母。这与使用具有不同矩阵乘数的希尔密码是一样的。让 T 代表转置。在对 Hill-1 进行加密后应用 T 会得到 C = T(AP+B) = (TA)P+(TB)。你所做的一切就是使用 TA 代替 A,TB 代替 B。Emily 可以使用已知明文来解密密码,并且她永远不会知道有置换存在。如果你想在希尔-0 或希尔-1 中使用置换,你必须在不同的区块之间交换字母,或者在不同的区块中交换不同的字母。
令人惊讶的是,当你使用希尔-2 或希尔-3 时情况完全相同。这是因为简单的替换和置换是可交换的。如果 S 是任何简单的替换,T 是任何置换,M 是任何消息,那么 S(T(M)) = T(S(M)),因此 ST = TS。因此,无论你使用哪种希尔密码变种,如果你要添加一个置换步骤,你必须在不同的区块之间交换字母,或者在不同的区块中交换不同的字母,要么周期性地要么伪随机地。
另一个想法是在两侧都用矩阵乘以消息。正如前面提到的,当你将文本块左乘以矩阵时,它必须被视为列向量,但当你将其右乘以矩阵时,它必须被视为行向量。假设你正在使用 3×3 矩阵,加法矩阵 B = 0。通过单侧矩阵乘法,每个密文字符的表达式都有 3 项,每项都涉及一个明文字母和一个矩阵元素。通过双侧矩阵乘法,每个密文字符的表达式有 9 项,每项都涉及一个明文字母和 2 个矩阵元素的乘积。因此,明文字母的系数是二次的。在 81 个可能的二次系数中,有 27 个出现在这些表达式中。
对于希尔-0 和希尔-1 情况,Emily 仍然可以使用已知明文来解决这些方程。有一种简单的方法和一种困难的方法。困难的方法是使用 18 个已知明文字符来解决两个 3×3 矩阵中 18 个未知元素的 18 个二次方程。祝你好运!
用简单的方法,将 27 个二次系数视为单独的变量。这将把方程从 18 个变量的二次方程转变为 27 个变量的线性方程。忽略 27 个变量是如何从 18 个矩阵元素中形成的,只需将它们视为不可分割的单元。由于现在有 27 个未知数,艾米莉需要 27 个已知字母而不是 18 个。虽然不太可能,但有可能,尤其是如果她拦截了多条使用相同密钥的消息。例如,假设艾米莉知道每条从瑞典发出的消息都以单词 STOCKHOLM 结尾。由于 STOCKHOLM 的出现可能在 3 个字母块中的不同位置开始,3 条不同的消息可以给她 27 个已知字母的位置。她可以轻松解决这 27 个线性方程以获得 27 个系数。
从那里,解决 27 个一次项二次方程以找到 18 个矩阵元素很容易——但为什么要麻烦呢?明文字母和密文字母之间的关系都是以 27 个二次系数为基础的。对于艾米莉来说,知道这些系数是如何产生的并没有好处。
Hill-1 的情况与 Hill-0 基本相同。有 36 个未知数,所以艾米莉需要 36 个已知明文字符。否则,解决过程是相同的。Hill-2 和 Hill-3 没有可比的过程。最好将它们解决为三字母替换密码。
通过在每一侧使用不同大小的矩阵,并在每一侧以不同方式对齐矩阵,可以从双面矩阵乘法中获得更大的强度。以下是这些技术的两个示例。在第一个示例中,左侧乘法是由 3×3 矩阵进行的,而右侧乘法是由 4×4 矩阵进行的。由于 3×3 矩阵与 4×4 矩阵对头,如图所示,让我们称之为Butthead 配置。

这给出了一个有效的块大小为 12 个字符。由于每个右侧的 4×4 矩阵跨越两个左侧的 3×3 矩阵,每个密文字符依赖于 6 个明文字符,而不是 4 个。在这种配置下,生成每个密文字符只需 7 次乘法,因此这种方法非常快速。当混合字母表是秘密的,但矩阵是已知的时,Butthead 密码被评为六。如果混合字母表和矩阵都是秘密的,则被评为八。如果矩阵是 6×6 和 7×7 或更大,则评级提高到十。当然,桑德拉使用的矩阵大小应该是互质的。
砖墙是另一种推荐的双面矩阵乘法配置。在这里,所有矩阵都是相同大小,但它们的偏移量为宽度的一半,就像墙上的砖块一样。这张图解说明了这种方法。

注意到矩阵的边界从未对齐。这种配置没有块结构,或者等效地说,整个消息是一个单一的块。由于每个 4×4 右侧矩阵跨越两个左侧 4×4 矩阵,每个密文字母取决于 8 个明文字母。这对于高安全性工作是足够的。
如果您实际上使用 2×2 矩阵来处理第一个和最后一个块,那将使这些块变得薄弱和容易受攻击。这还要求您使用 1×1 和 3×3 矩阵来处理不均匀的消息长度。最好始终使用 4×4 矩阵。接下来的两个图示展示了如何对长度为 13 的消息执行此操作。第一个图示显示了左侧矩阵的放置,最后一个 4×4 矩阵与消息的右端齐平。
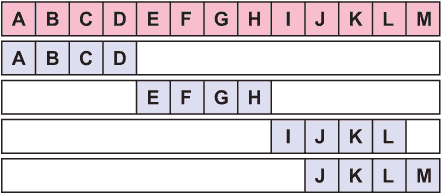
下一个图示显示了右侧矩阵的放置,偏移了 2 个字符。第一个和最后一个 4×4 右侧矩阵与消息的末端齐平。
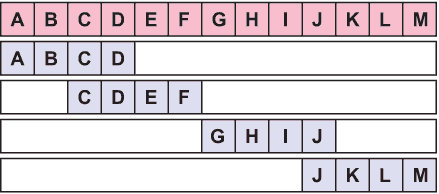
将最后一个矩阵定位在最后一个左侧矩阵和最后一个右侧矩阵对齐。可以通过将其环绕到消息的开头来避免这种情况,就像这样。
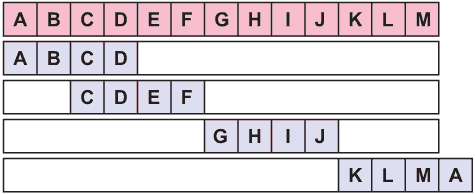
当您在左侧矩阵乘法之前使用了混合密钥简单替换,并在右侧矩阵乘法之后使用了另一个,同时使用了大小为 6×6 或更大的秘密矩阵时,砖墙密码评级为十。
由于反转矩阵需要一些努力,因此最好使用固定矩阵进行左侧和右侧乘法。使用固定矩阵会削弱密码,但您可以通过在两个矩阵乘法步骤之间添加第三个简单替换来进行补偿。矩阵可以是任何偶数大小,如 6×6 或更大。与希尔密码相比,让我们称之为珠穆朗玛峰密码。珠穆朗玛峰密码评级为十。
15.5 大整数乘法
大整数乘法在一个重要方面类似于矩阵乘法:在矩阵乘法中,产品的每个元素是两个矩阵中的一个元素的乘积之和。在大整数乘法中,产品的每个数字是两个大整数中的一个数字的乘积之和。无论如何,这是我将这个主题放在矩阵章节中的理由。
一个 128 位块可以看作是 16 个字节,或者是 128 位整数的 16 个基于 256 的数字。如果您将两个这样的基于 256 的整数相乘,那就涉及 256 个乘积和 256 个加法(包括进位)。如果您使用的语言允许您将两个 32 位无符号整数相乘以获得 64 位无符号乘积,那么您只需要 16 次乘法和 16 次加法。如果语言允许 64 位整数与 128 位乘积相乘,那就更简单了。
有更快的方法可以乘以非常大的数字,比如 Karatsuba 和 Toom-Cook,但是对于乘以 128 位数字,甚至 256 位数字,这些方法的好处太小,不值得为了当前目的而使用,所以我不会介绍大整数乘法的机制。一些计算机语言会自动处理这些机制,因此用户永远不需要介入。
话虽如此,考虑一个密码,Mult128,其中消息以 128 位块为单位,每个块都乘以一个秘密的 128 位整数 M,对 2¹²⁸取模。换句话说,只使用 256 位乘积的低阶半部分,高阶半部分被丢弃。这意味着乘法中的一些中间产品不需要计算,因为它们只对乘积的高阶端有贡献。
利瓦可以通过将密文乘以 M 对 2¹²⁸取模的乘法逆元 M’来读取消息。当 M 为奇数时,这个逆元存在。让我们看看如何找到乘法逆元。
15.5.1 乘法和除法同余
我在本书的早期承诺过,我会根据需要逐步呈现所有必要的数学内容。这是其中之一。计算乘法逆元的方法涉及乘以线性同余式。在我展示如何做到这一点之前,让我们看一个示例来了解为什么这是一个问题。(我在第 3.6 节中使用了这个示例的部分内容。您可能希望在继续之前重新阅读该节。)
并不是所有的同余式都具有相同的强度。一些同余式很强,有唯一的解。一些同余式很弱,有许多解。同余式越强,提供的信息越多。考虑这些同余式,从最强到最弱排列:
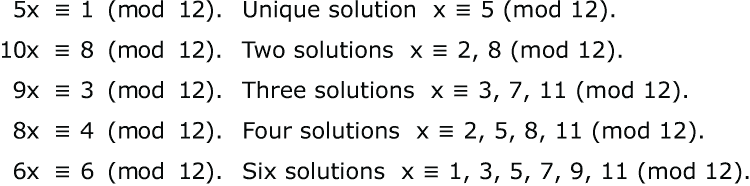
这种不均衡的原因是,在除了这些同余式中的第一个以外的所有同余式中,ax≡b (mod n),参数 a、b 和 n 有一个公因数。在 10x≡8 (mod 12)中,参数 10、8 和 12 有公因数 2,同余式有 2 个解。在 9x≡3 (mod 12)中,参数 9、3 和 12 有公因数 3,同余式有 3 个解。等等。公因数越大,解越多,同余式越弱。
当 a、b 和 n 有一个公因数 d 时,你可以将同余式除以 d。例如,9x≡3 (mod 12)有一个公因数 3. 除以 3 得到 3x≡1 (mod 4)。你可以直观地解决这个问题。解是 x≡3 (mod 4)。检查一下,因为 3×3 = 9≡1 (mod 4)。将这个结果转换回(mod 12),第一个解是 3 (mod 12),然后通过添加 12/3 = 4 再次添加 4,得到另外两个解,即 7 (mod 12) 和 11 (mod 12)。
总结一下,如果 a、b 和 n 有一个公因数 d,那么就有 d 个不同的解。第一个解是满足 a/d≡b/d (mod n/d)的解,其他解相距 n/d。
让我们看看另外两种情况。再假设 ax≡b (mod n),并且 a 和 n 有一个不整除 b 的公约数,例如 3x≡7 (mod 30)。那么这个同余方程没有解。相反,假设 a 和 b 有一个不整除 n 的公约数 d。那么你可以将 a 和 b 除以 d。例如,如果 10x≡25 (mod 37),那么 2x≡5 (mod 37)。这可以通过在头脑中将 37 加到 5 上来解决,得到 2x≡42 (mod 37)。除以 2 得到 x≡21 (mod 37)。
就像你可以将 a 和 b 除以一个常数一样,你也可以将 a 和 b 乘以一个常数 m。这个 m 不能与 n 有公因数。换句话说,m 必须在模 n 下可逆。否则,你会使同余方程变弱并丢失信息。例如,假设给定 9x≡3 (mod 12)。这是一个有 3 个解的弱同余方程。如果你将 a 和 b 乘以 2,同余方程变为 18x≡6 (mod 12),等价于 6x≡6 (mod 12),有 6 个解。这个弱同余方程变得更弱。
你也可以相加和相减具有相同模数的同余方程。假设 ax≡b (mod n)和 cx≡d (mod n)。这些可以相加得到(a+c)x≡b+d (mod n),或相减得到(a-c)x≡b-d (mod n)。这可以用来加强一组弱同余方程。例如,假设你有 9x≡3 (mod 12)和 8x≡4 (mod 12)。第一个同余方程有 3 个解,第二个有 4 个解。如果你将它们相加,得到 17x≡7 (mod 12),化简为 5x≡7 (mod 12),有唯一解 x≡11 (mod 12)。更聪明的是,如果你将两个同余方程相减,得到(9-8)x≡(3-4) (mod 12),直接得到 x≡11 (mod 12)。
*15.6 解线性同余方程
现在你知道如何安全地操作同余方程而不失强度,我们可以解决如何解线性同余方程 ax≡b (mod m),其中 a、b 和 m 是给定常数,x 是我们试图找到的未知值。特殊情况下当 b = 1 时,x 是 a 对模 m 的乘法逆元。大多数教科书只提到一种叫做扩展欧几里德算法的技术。(欧几里德算法通常被归功于雅典的忒亚泰特,他比欧几里德早生活大约一个世纪。)那是一个非常好的方法。当模数较小或者模数有几个不同的小质因数时,可能是正确的方法。当因数分解未知且存在小因数的可能性时,这绝对是正确的方法。
然而,在密码学中,只有两种常见情况需要计算乘法逆元,当模数是质数时,以及当模数是 2 的幂时。本节将描述一种更简单、更直接的方法。
15.6.1 简化同余方程
解决同余式 ax≡b (mod m)的基本方法是反复减少 x 的系数。最简单的方法是ResM。它将同余式乘以一个整数 n,使得 x 的系数至少与模数一样大。即 a(n-1) < m ≤ an。你可以通过将 m/a 四舍五入确定 n 的值,所以 2.0000 保持为 2,但 2.0001 会变成 3。当系数对 m 取模时,结果是一个较小的系数。
让我们从一个简单的 ResM 示例开始,只是为了获得基本概念,并且在后面讨论变得复杂时更容易跟上。取同余式 38x≡55 (mod 101)。我们知道 101/38 = 2.658,所以我们将同余式乘以 3,然后对 101 取模,就像这样:
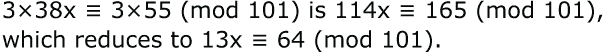
注意,x 的系数从 38 减少到 13。这可以再次减少。我们有 101/13 = 7.769,所以我们将同余式乘以 8,就像这样:

我们快到了。101/3 = 33.667,所以将最后的同余式乘以 34,x 的系数就减少到 1:
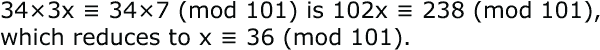
我们可以通过将 x = 36 代入原同余式 38x≡55 (mod 101)来检查这个结果。将 x 替换为 36 得到 38×36≡55 (mod 101),即 1368≡55 (mod 101),这是正确的。正确答案是 x≡36 (mod 101)。
15.6.2 一半一半法则
让我们看一个小的改进。我们可以称之为一半一半法则。大约一半时间,m/a 的小数部分小于 1/2,另一半时间大于 1/2。设 q = m/a。那么一半时间 qa 更接近 m,另一半时间(q+1)a 更接近 m。
一个数值示例可能有助于更清楚地理解这一点。让 m 为 101,让 a 为 40。那么 q = 101/40 = 2.525。分数.525 大于 1/2。如果你取 40×2,结果是 80,比 101 少 21。如果你取 40×3,结果是 120,比 101 多 19。所以 40×3 比 40×2 更接近 101。因此 n = 3 是最佳乘数。
假设,相反,a 是 41。那么 m/a = 101/41 = 2.463。这次分数.463 小于 1/2。如果你取 41×2,结果是 82,比 101 少 19。如果你取 41×3,结果是 123,比 101 多 22。所以 41×2 比 41×3 更接近 101。因此 n = 2 是最佳乘数。
总结一下,当 q = m/a 的小数部分小于 1/2 时,如果我们向下取整 q,na 更接近 m,但当 m/a 的小数部分大于 1/2 时,如果我们向上取整 q,na 更接近 m。使用 floor 和 ceil 符号(第 13.3 节),如果 frac(q) < 1/2,选择 n = ⌊q⌋,但如果 frac(q) > 1/2,选择 n = ⌈q⌉。听起来很容易,但有一个复杂之处。当 n = ⌈q⌉时,na 大于 m,所以你通过减去 m 的倍数来减少同余式,就像我们在本节开头所做的那样。当 n = ⌊q⌋时,na 小于 m,所以你通过从 m 的倍数中减去它来减少同余式。
从这里开始

由于 101/41 = 2.463,将同余式乘以 2,得到

从 101 的倍数中减去这个数,即
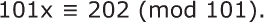
由于 101-82 = 19 并且 202-180 = 22,因此得到
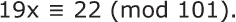
为了说明这种改进有多大,让我们分别使用半分法和非半分法解一个同余式。

如果不使用半分法,则减少需要 8 步。使用半分法减少只需 4 步。对于不同的系数和模数,比例会有所不同,但 8:4 是相当典型的。使用半分法的 ResM 可以称为ResMH。
15.6.3 阶梯法
当整数非常大时,这仍然有点慢,因为我们要乘以和除以大数。可以使用阶梯技术来避免这种情况。它对每个步骤使用两个同余式。阶梯技术不是将 x 的系数乘以越来越大的数字使其接近模数的值,而是在每个同余式中将系数乘以一个小数使其接近前一个系数的值。这需要一个额外的同余式来启动该过程。为此,我们使用同余式 mx≡m(mod m),它等价于 0x≡0(mod m)。
让我们看一个使用更大数字的例子:

由于 28338689/6114257 约为 4.635,乘以 5 并减去得到

在这里,6114257/2232596 约为 2.739,所以乘以 3 并减去得到

继续这样做,依次得到

每个例子都使用了一个素数模数。当模数是复合数时,情况变得更加复杂。我不会在这里覆盖所有这些复杂性。对于密码学最重要的情况是模数为 2 的幂,例如 2³²或 2¹²⁸。在这种情况下,您在每个阶段选择的乘数必须是奇数。因此,不要将乘数四舍五入到最接近的整数,而是始终向奇整数四舍五入。例如,3.14 将四舍五入为 3,3.99 也将四舍五入为 3。使用阶梯技术的 ResMH 可以称为ResMHL。
15.6.4 连分数
一旦有两个或更多的线性同余式,您可以使用一种称为连分数的技术更快地减少 x 的系数。连分数是一种通过分数紧密逼近十进制数的方法。考虑十进制数 R = .13579。R 在 1/7 和 1/8 之间。更准确地说,R 约为 1/7.3643。这也可以写成 1/7+.3643。注意加号+在分数的分母中。这表示加法在分母中完成,而不是将两个分数 1/7+.3643 相加。
分数.3643 可以近似为 1/2.745,或者 1/2+.745,所以 R 现在是 1/7+1/2+.745。这里.745 非常接近 3/4,因此近似可以是 1/7+1/2+3/4。要将其转换回普通分数,只需向后工作:

分数 11/81 是.13580,与.13579 仅相差.00001。正如你所见,这种方法提供了出色的近似值。
让我们再试一次来自 15.4.3 节的例子,
6114257x ≡ 90926 (mod 28338689).
对于第二个同余式,我们使用了 0 = 0 的技巧,
28338689x ≡ 28338689 (mod 28338689).
这里 6114257/28338689 是
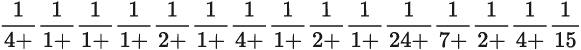
获得接近的近似值的一个好法则是在大分母之前停止,本例中为 24。在 24 之前截断连分数得到

这计算出为 241/1117。
将 6114257 同余式乘以 1117 和 28338689 同余式乘以 241 然后相减得到

这将 x 的系数从 6114257 降低到 1020,降低了 5994 倍。因此,继续分数法比其他方法使用的步骤要少得多。然而,使用起来很棘手,因为一步的系数可能比下一步的系数大得多,例如 6829625069 与 1020。你可以通过交替使用连分数步骤和一半步骤来平衡系数。******
15.7 大整数密码
可以使用大整数乘法构建许多密码。第 15.3 节描述了 Mult128 密码,其中消息以 128 位块进行。每个块被视为 128 位整数,并乘以秘密的 128 位整数 M 模 2¹²⁸。为了得到良好的混合,乘数的每个字节都应该是非零的。这仍然很脆弱,因为每个密文块的低阶 n 位仅取决于明文和密钥 M 的低阶 n 位。这使得低阶字节的加密变为简单的替换。在乘法之前和之后执行简单的替换不能修复这个弱点。类似地,低阶 2 字节经历双字母替换,低阶 3 字节经历三字母替换。Mult128 评级为 Three。
修复低阶字节问题的超快速方法是将高阶字节与低阶字节组合起来,例如使用xors或adds组合函数。这将提高评级至 Five。一个更好的解决方案是使用xors或adds将高阶 8 字节与低阶 8 字节组合起来。这将评级提高至 Seven。这里是一个例子。

加强密码的一种方法是对 16 个字节进行置换,然而,有了足够的密文,Emily 可以检测出哪个字节位置的变异最小,因此必须是置换后的低位字节。Permuted Mult128 被评为四级。
更强大的方法是进行乘法、置换,然后再进行乘法。置换需要将弱的低位字节移到块的高位半部分。适合的置换有 (1) 颠倒字节的顺序,(2) 交换块的低位和高位半部分,或 (3) 以相反顺序交错低位和高位字节。如果使用十六进制数字 0 到 F 对字节进行编号,那么这 3 种置换可以表示为

如果你的编程语言允许你将该块视为 32 位字和单个字节进行操作,那么将 4 个字的顺序颠倒可能会更快,从而得到这种排列:
这个密码,称为 MPM128,被评为七级。
当你在这个过程中添加替换步骤时,安全性会提升。让 S[1]、S[2]、S[3] 和 S[4] 成为 4 个独立的混合很好的键入替换,让 P 是固定的置换 5BF4AE39D28C1706,让 M[1]、M[2] 和 M[3] 是乘以 3 个秘密的 128 位整数。然后密码 S[1]M[1]PS[2]M[2]S[3]PM[3]S[4],称为 Tiger,被评为十级。
15.8 小整数乘法
使用普通的无符号 32 位乘法可以完成 Mult128 的迷你版本。128 位块被视为四个 32 位整数。这些整数中的每一个都与一个秘密的 32 位整数进行乘法,取模 2³²。这 4 个乘数必须是奇数,以便稍后进行解密。这产生了一个 32 位密码。要得到一个 128 位密码,这 4 个单独的 4 字节乘积可以被视为一个 16 字节块,并使用这个固定的 16 字节密钥转位混合(见第 7.6 节):

这个转位后跟着第二个乘法步骤,再次将 16 字节块视为四个 32 位整数。你可以使用相同的乘数或新的乘数。然后是第二个转位,和另一轮乘法,所以有 3 轮乘法和两轮转位。这个密码被称为 Mult32,并被评为七级。它比任何 Mult128 密码变体都要快得多。
让我们将 128 位块的 16 个字节视为一个 4×4 字节矩阵。该矩阵的任何一行的 4 个字节都可以视为 32 位整数。通常情况下,整数的 4 个字节从左到右取出,最左边的字节为高位字节。但是,它们也可以按相反的顺序取出,最左边的字节为低位字节。考虑十六进制数 01020304。如果我们按照正常方式将其乘以十六进制数 01010101 对 2³²取模,结果是十六进制 0A090704。如果我们按照相反的顺序将其乘以十六进制数 01010101 对 2³²取模,结果是十六进制 0A060301。
类似地,我们可以将任何列中的 4 个字节视为 32 位整数,既按照自上而下的顺序,也按照自下而上的顺序。将两个水平方向称为东和西,两个垂直方向称为北和南。如果我们按照东、北、西、南的顺序将行和列乘以奇数 32 位整数对 2³²取模,这将提供彻底的混合。这需要 16 个单独的 32 位乘法器。总密钥大小为 16×31 = 496 位,而不是 16×32 = 512 位,因为乘法器必须是奇数。这种密码,可以称为Compass,评为 Eight。
要将评级提升到 Ten,可以添加一个或多个替换轮,例如,东、北、替换、西、南。更好的方法是,添加多个替换,比如东、替换、北、西、替换、南。将其称为CompassS。即使使用固定替换,如果它们高度非线性,CompassS 也评为 Ten。
使用小整数乘法的另一种方法是进行循环乘法。让块中每个 32 位行中的字节从左到右依次编号为 1、2、3、4,即从高位字节到低位字节。将其乘以奇数模 2³²。将字节 1 移动到低位,使顺序变为 2、3、4、1。再次乘以奇数模 2³²。重复两次,使每个字节都占据每个位置一次。即,字节按顺序 1234,然后 2341,3412,最后 4123。对 4×4 字节矩阵的 4 行中的每一行都要执行此操作,共进行 16 次乘法和 12 次循环移位。
接着对列执行相同的操作。总共有 32 次乘法和 24 次循环移位。这种循环乘法密码评为 Eight。可以有多达 32 个不同的 32 位乘法器作为密钥。
这一节的方法可以与第 15.4 节的方法以多种方式结合使用。这里只是一个例子,我将其称为Mat36。将消息按 36 个字符一组,这些字符被视为九个 32 位整数。这些整数形成了模 2³²的 3×3 整数矩阵。这个矩阵将与一个秘密的 3×3 可逆整数矩阵相乘。如果你简单地将另一个 3×3 矩阵乘在右边,那么这 9 个整数的低位字节将被弱加密。相反,将整个 36 字节块左移 16 位,然后将块右边乘以第二个秘密的 3×3 可逆整数矩阵。Mat36 评级为 Eight。
15.9 模 P 乘法
当乘法取模 2^n 时,低位字节会被弱加密,我们需要费点周折来解决这个弱点。当乘法取模一个素数 P 时,这个问题不会发生。有了一个大的乘数,产品的每一位都取决于明文的每一位。有一个不同的问题。假设你选择了一个素数 P < 2^n,以及一个乘数 M,其中 1 < M < P。这样你就可以安全地将从 0 到 P-1 的值乘以 M 模 P,所以 Riva 可以通过乘以 M’,M 的乘法逆元,来解密这些值。
然而,明文值 0 将保持不变,而 P 到 2^n-1 的明文值不能安全地相乘,因为结果会产生歧义。例如,当通过 M 模 P 相乘时,3 和 P+3 将产生相同的结果,因为 3M≡PM+3M(mod P),所以 Riva 无法确定消息是 3 还是 P+3。这意味着从 P 到 2^n-1 的值必须保持不变。为了做到这一点,定义函数 modp 如下:

这个问题的一个解决方案是让 Sandra 对明文进行异或。这建议了一族Modulo P 密码。让我们确定 n = 64,意味着块大小为 8 字节,素数模数 P = 2⁶⁴-59 = 18446744073709551557,乘数 M = 39958679596607489,也是素数。
Sandra 通过选择一个秘密的 64 位常数 C[1]作为密钥,计算 x = modp(C[1]⊕B)+C[1]来加密 64 位明文块 B。这是这个系列中的第一个密码。称为PMod1。评级为 Five。这个系列中的第二个密码PMod2是 PMod1 的两次迭代,使用第二个 64 位常数 C[2]:

PMod2 评级为 Seven。这个系列中的第三个密码PMod3有 3 次迭代,评级为 Nine:

第四个成员PMod4评级为 Ten。它的总密钥大小为 256 位,是块大小的 4 倍:

每个加法都是模 2^n 进行的,而不是模 P。
四个 PModX 密码都非常快,因为大多数编程语言都直接支持 64 位的加法、乘法和模除。在某些计算机上,它们是单一的机器指令。这使得 PModX 密码能够以 4 或 8 个字节作为一个单位运行,而不是像 DES 那样将每个 4 位块单独处理。这类密码非常适合软件加密。PMod2 比 DES 更安全,因为密钥长度更大,而 PMod4 比 3DES 更安全。
对于模 P 的乘法还有第二种方法,可以消除不变的值。思路是将从 0 到 2⁶⁴-1 的整数范围分成两个单独的范围,每个范围使用不同的质数模数和不同的乘数。选择两个质数 P 和 Q,使得 P+Q = 2⁶⁴+2。大约有 1016 对这样的数字,所以很容易找到,例如 P = 9228410438352162389 和 Q = 9218333635357389229,以及两个小于 P 和 Q 的大乘数 M 和 N。麻烦的部分在于你必须将每个范围进行移位,以便仅乘以范围 1 到 P-1 或 1 到 Q-1 中的数字。通过重新定义 modp 函数来实现这一点。

通过重新定义的 modp 函数,PMod1 到 PMod4 密码与以前的工作方式相同,并且具有相同的评级。这张图展示了范围从 0 到 2⁶⁴-1 是如何被划分的。

15.10 进制转换
更改数字进制与乘以一个大整数紧密相关。当数字非常大时,更改数字进制是一个缓慢的操作,因此最好的策略是将消息分成块,并分别转换每个块。更改进制会模糊消息字节之间的分隔。
有两种将数字从一种进制转换为另一种进制的方法。你可以从低位开始计算,也可以从高位开始计算。很多人在学校学过这些技巧,但随着时间的推移往往会忘记。为了提醒大家,这里展示了两种方法。我们将使用低位技术将数字 1A87 从十一进制转换为七进制,然后再使用高位方法将其转换回十一进制。
使用低位技术,你要反复将数字除以新的基数。每个余数都成为转换后数字的下一个数字。以下是将 1A87 转换的步骤:
1A87÷7 等于 312,余数为 4。
312÷7 等于 49,余数为 5。
49÷7 等于 7,余数为 4。
7÷7 等于 1,余数为 0。
因此,十一进制中的 1A87 变为七进制中的 10454。
使用高位技术,你要反复将高位数字乘以旧的基数,然后加上下一个数字。以下是将 10454 转换的步骤:
1×7+0 等于 7。
7×7+4 等于 49。
49×7+5 等于 312。
312×7+4 等于 1A87。
如果这些数字看起来不太对,记住数字 7、49、312 和 1A87 都是以十一进制表示的。
你可以根据改变进制制作很多漂亮的密码。例如,一个 16 字节的块也是一个以基数 256 表示的 16 位数字。将该数字转换为另一个进制,比如 263。现在你可以对基数 263 的数字进行置换,或者执行替换,或者两者兼而有之。然后,你可以将其转换为基数 277,并做同样的事情。最后,你将其转换回基数 256。这需要一个 17 字节的数字来保存结果。你可以使用从 256 到 362 的任何进制。请记住,如果任何结果有一个前导数字 0,那么这个数字是必需的,以便 Riva 能够解密密文。
如果每个连续的基数都比前一个稍大,那么在每个阶段都需要相同数量的数字。只有在将数字转换回基数 256 时,数字的位数才会增加。没有理由要求这些基数必须是素数。
这是一个基于进制变换的分组密码概念。首先,从一个秘密的、混合良好的、基于密钥的简单替换 S 开始。S 操作的是字节,即从 0 到 255 的整数。S 可以扩展到大于 256 的进制,方法是保持大于 255 的任何数字不变。这样就消除了为每种可能的进制准备单独的替换表的必要性。选择 3 个数字基数 B[1]、B[2]和 B[3],满足 256 < B[1] < B[2] < B[3] < 363。你还需要 3 个针对 16 个元素的带密钥的置换 T[1]、T[2]和 T[3]。这些元素是整数,可以大到 B[3]-1,因此它们每个都需要超过 1 个字节。
分组密码3Base包括以下步骤:(1)替换 S。(2)转换为基数 B[1]。(3)替换 S。(4)转置 T[1]。(5)转换为基数 B[2]。(6)替换 S。(7)转置 T[2]。(8)转换为基数 B[3]。(9)替换 S。(10)转置 T[3]。(11)转换为基数 256。 (12)替换 S。密码块由步骤 11 中的 16 个元素组成。第 12 步将块扩展为 17 字节。密码 3Base 评级为 Ten。
*15.11 环
环是整数的抽象版本。也就是说,环是一组可以像整数一样进行加法和乘法运算的元素集合。你已经熟悉了几个环:整数、有理数、实数、模某个固定数的整数,也许还有复数和代数数。一些不太熟悉的环是多项式,其系数是环的成员,矩阵,其元素是环的元素,形式为 a +b√13,形式为 a +b∛7+c∛49,以及形式为 a +b√2+c√3+d√6 的数,其中 a、b、c 和 d 可以是整数、有理数或模某个固定整数的整数。
在我们讨论如何在密码学中使用环之前,让我们先制定环的正式规则。环加法用加号+表示,a+b,环乘法用并置表示,ab。
-
对于所有的环元素 a 和 b,a +b 和 ab 都是环的元素。(封闭性)
-
对于所有环元素 a、b 和 c,a +(b+c) = (a +b)+c。(加法的结合规则)
-
对于所有环元素 a 和 b,a +b = b +a。(加法的交换律)
-
存在一个环元素 0,使得 0+a = a +0 = a 对于所有环元素 a。(加法恒等式)
-
对于每个环元素 a,存在一个元素 -a,使得 a +(-a) = (-a)+a = 0。(加法的逆元素)
-
对于所有环元素 a、b 和 c,a(bc) = (ab)c。(乘法的结合律)
-
对于所有环元素 a、b 和 c,a(b +c) = ab +ac,且 (a +b)c = ac +bc。(分配律)
-
存在一个环元素 1,使得 1a = a1 = a 对于每个元素 a。(乘法的恒等式)
当添加一个加法逆元素时,通常会省略括号,因此 (-a)+b 变成 -a +b,而 a +(-b) 变成 a-b。
请注意,环乘法不一定是可交换的。如果环乘法是可交换的,则称该环为 可交换环。所有前述的例子都是可交换环。暂时假设我们讨论的所有环都是可交换的。如果环元素 a 有一个乘法逆元素 a’,使得 aa’ = 1,则称 a 为 可逆的。在处理有限环时,建议尝试对所有可能的元素对进行乘法运算,以确定哪些元素是可逆的,并保留一个逆元素表以供快速参考。
一种利用环算术进行加密的简单方法是将第 11.8 节的涟漪密码与第 13.14.1 节的滞后线性加法结合起来。让我们选择环 R13,其元素采用 a + b√13 的形式,其中 a 和 b 是十六进制数字,即模 16 的整数。两个十六进制数 a 和 b 组成一个表示字符的字节。例如,字母 X 在 ASCII 码中表示为十六进制 58,对应于 R13 环元素 5+8√13。
两个 R13 环元素 a + b√13 和 c + d√13 的加法为 (a + c) + (b + d)√13,乘法为 (ac + 13bd) + (ad + bc)√13,其中所有的加法都是模 16 进行的。例如,如果 x = 2+3√13,y = 4+5√13,则 x+y 为 6+8√13,xy 为 11+6√13。
对于组合的涟漪 + 滞后线性加法密码,可以称为 Lag Ripple,将 x[n] 替换为 ax[n]+bx[n-i]+cx[n-j],其中系数 a、b 和 c 是环的元素,这种情况下为 R13,而滞后 i 和 j 是小整数,如 2 和 5。明文可以分成,比如,16 字节的块,但对于短消息,密码可以应用于整个消息。我们假设是后者。然后,加密将是
x[n] = ax[n] + bx[n-2] + cx[n-5] 对于 n = 1,2,3, …,L。
这里 a 是 R13 的一个可逆元素,b 和 c 是 R13 的任意元素,L 是消息的长度。算术运算在环中进行。您可能会认出这是第 11.8 节中 madd 组合函数的变体。对于加密前几个字节,通常会使用环绕。
对于使用已知的固定滞后进行单次通过的情况,滞后纹波的评级为 Two,因为可能的系数组合只有 256³种。通过在滞后纹波阶段之前和之后使用简单替代,评级增加到 Five。使用 3 次通过,每次通过的系数和滞后不同,评级变为 Six。
三重纹波使用 3 次通过,每次纹波通过前后使用秘密钥匙化的简单替代。每次通过都有不同的秘密系数和滞后。可选择为每次通过的消息从不同位置开始并循环。三重纹波评级为 Ten。
15.12 环上的矩阵
在 15.1 节和 15.2 节中,我们研究了希尔密码,它由将消息的每个块视为整数向量,并将该向量乘以模 26 或 256 的整数矩阵组成。整数模 26 或 256 没有什么神奇的。你可以使用任何环的元素来表示消息的字符。如果字符比环元素多,你可以使用环元素的成对或三元组,就像将 1 到 5 的整数对用于表示 25 个字母的 Polybius 方阵(9.1 节)一样。
假设你使用的是R13上的矩阵,该环的元素形式为a+b√13。如果你将明文块视为包含 32 个十六进制数字而不是 16 字节的向量,并且为矩阵乘积的每个数字写出表达式,你会发现密文中的每个十六进制数字都是明文数字的线性组合。因此,在R13环上使用 16×16 的矩阵等效于在十六进制数字上使用 32×32 的矩阵,即模 16 的整数。因此,这样的密码仍然容易受到已知明文攻击。攻击需要至少 256 字节的明文。可能 16×17 = 272 字节就足够了。
你,发送者,可以轻松地通过在矩阵乘法之前和之后使用钥匙化的简单替代来击败这样的攻击。或者,你可以构建自己的环,一个除了你的合法通信者以外其他人都不知道的环。只要你能保密你的环,就没有人能对你的矩阵密码发起任何攻击。
15.13 构建环
一个包含 N 个元素的环,称为阶数为 N 的环,由两个 N×N 的表表示,即加法表和乘法表。构建环可以分阶段进行。让我们以构建一个包含 8 个元素的环为例进行演示。首先构建加法表。你从一开始就知道这个环必须有两个元素,0 是加法恒元,1 是乘法恒元。对于所有 a,和 0+a 和 a+0 都是已知的。这给了我们加法表的顶行和左列。

接下来,从第二行开始。策略是取第一个尚未分配值的和,为该和分配一个值,然后利用结合规则推断其他和的所有可能的值。假设你想要 1+1 = 2,2+1 = 3,3+1 = 4 和 4+1 = 0。利用结合规则,现在可以填写表的左上部分。例如,你可以确定 2+2 是多少,因为 2+2 = (1+1)+2 = 1+(1+2) = 1+3 = 4。

由于 4+1 = 0,因此 1 的加法逆元是 4,4 的加法逆元是 1。同样,2 是 3 的加法逆元,3 是 2 的加法逆元。那么我们应该给 5+1 赋什么值呢?它不能是 0,因为 4 和 5 不能同时是 1 的加法逆元。它也不能是 1,因为那样 5 就会是 0。它也不能是 2,因为 5+1 = 1+1 意味着 5 = 1。同样,5+1 也不能是 3 或 4。它也不能是 5,因为 5+5 = 5 意味着 5 = 0。那就只剩下 5+1 = 6 或 5+1 = 7。它们是等价的,所以假设 5+1 = 6。这强制使得 6+1 = 7 和 7+1 = 5。这意味着 5+1+1+1 = 5。这使得 1+1+1 = 0。由于我们已经知道 1+1+1 = 3,这意味着 3 = 0。不可能。这是一个死胡同。设置 4+1 = 0 不起作用。
出了什么问题?循环 1+1+1+1+1 = 0 有 5 个项。在一个阶数为 N 的环中,任何这样的循环的长度必须能够整除 N。由于 5 不能整除 8,因此无法完成加法表。这就留下了 3 个选择,将循环长度设为 2、4 或 8。如果选择循环长度为 8,则该环是模 8 的整数环。如果选择循环长度为 2,则加法与异或相同。由于目标是开发一个新环,所以只能选择循环长度为 4。加法表必须是

通过使用分配规则,现在可以推算出乘法表。例如,2×2 = 2×(1+1) = 2+2 = 0。

让我们称这个环为R8。它是一个可交换环,因为对于所有环元素 a 和 b,都有 ab = ba。注意环R8中只有 1 和 3 有乘法逆元,而且每个元素都是其自身的逆元。
有两个环值得特别提及,即高斯整数和四元数。
15.13.1 高斯整数
高斯整数是形式为 a+bi 的数字,其中 a 和 b 是整数,i 是虚数单位√-1。换句话说,高斯整数是实部和虚部都是整数的复数。对于密码学用途,a 和 b 可以是模 16 的整数。因此,高斯数 a+bi 可以用来表示十六进制数 ab。例如,字母 X,在十六进制 ASCII 码中是 58,将被表示为高斯整数 5+8i。
高斯整数的加法和乘法如下:

其中加法和乘法是用于密码学的模 16 运算。
15.13.2 四元数
四元数是爱尔兰数学家威廉·罗恩·哈密尔顿(William Rowan Hamilton)于 1843 年在都柏林三一学院(Trinity College Dublin)发明的,他是爱尔兰皇家天文学家,用于描述旋转体的运动。它们是形式为 a+bi+cj+dk 的数,其中 a、b、c 和 d 是普通数,i、j 和 k 是抽象单位。四元数的定义关系是 i² = j² = k² = ijk = -1。从这个关系中,您可以推导出这些乘法规则:

四元数乘法不是交换的。四元数经常被用作非交换环的典型例子。
四元数在物理学中被广泛用于表示球面上的点和固体的旋转等事物。通过让 a、b、c 和 d 成为模 16 或模 256 的整数,可以将其适应于加密用途。这将使每个四元数代表消息的 2 或 4 个字符。
使用四元数的另一种方法是让系数 a、b、c 和 d 成为模 2³² 的整数。您可以使用一组秘密的混合良好的 5 位、6 位或 8 位字符代码,以便每个系数可以分别表示 6、5 或 4 个字符。因此,整个四元数将代表消息的 24、20 或 16 个字符。您可以通过左乘或右乘一个秘密的四元数乘法器来加密消息四元数 M。由于四元数乘法不是交换的,左乘和右乘它更强大,比如 AMB。与普通乘法一样,每个分量中的低阶字节最弱,因此在第一次乘法后最好将整个 16 字节块循环左移 16 位位置。可以使用相同的字符代码集将乘积转换回标准 ASCII 字符,但最好使用不同的代码集,最好是不同大小的代码。
让我们称这种方法为Qmult。 Qmult 被评为十分。为了解密这条消息,Riva 必须左乘逆四元数 A’,右乘逆四元数 B’。 四元数 a+bi+cj+dk 的逆由 (a-bi-cj-dk)/(a²+b²+c²+d²) 给出。由于我们是在模 2³² 下工作,当 a²+b²+c²+d² 为奇数时,即当其中一个或三个系数为奇数时,a²+b²+c²+d² 将具有乘法逆元。
15.14 寻找可逆矩阵
要将矩阵用于希尔式密码,该矩阵必须是可逆的。可逆矩阵通常难以找到。如果环中的可逆元素数为 i,总元素数为 r,则随机 n×n 矩阵是可逆的概率为(i/r)n。对于R8环,i/r 为 2/8 = 1/4。(这与有理数或实数上的矩阵形成鲜明对比,在这些域上除了 0 之外的每个元素都有乘法逆元,因此几乎每个矩阵都是可逆的。)如果矩阵很小,通常可以通过随机选择元素,然后尝试最后一个元素或最坏的情况下最后两个元素的所有可能值来找到一个可逆矩阵。通过使用最后 1 或 2 个元素,您可以将矩阵减少到底部两行,而不必为每次试验都进行完整的减少。
在本书中我选择不讨论行列式,因为我不知道在密码学中有任何对它们的用途,然而,对于熟悉行列式的读者,如果一个矩阵的行列式值是环中的可逆元素,则矩阵是可逆的。特别地,一个整数矩阵是可逆的,仅当其行列式是+1 或-1 时。
当所需矩阵较大时,可能不可行找到一个可逆矩阵。相反,您需要构造一个可逆矩阵。您首先通过以两种特定形式之一构造一组所需尺寸的矩阵来开始:三角形和块对角线。以下是四种类型的三角形矩阵的 4×4 示例。

上三角矩阵的非零元素只在主对角线上或其上方(从左上到右下)。
如果对角线上的所有元素是可逆的,则三角矩阵是可逆的。如果反对角线上的所有元素是可逆的,则反三角矩阵是可逆的。这些矩阵的逆可以使用第 15.1.1 节的技术轻松找到。对于上三角和下反三角矩阵,应从右向左执行第 15.1.1 节的约化过程。
通用的可逆矩阵可以通过这些三角形形式相乘来构造。这必须谨慎进行。两个上三角矩阵的乘积仍然是上三角的,两个下三角矩阵的乘积仍然是下三角的。反三角矩阵没有这个性质。一个明智的做法是构造四种三角形类型的矩阵的一个矩阵,然后形成它们的乘积。如果三角矩阵是 A、B、C 和 D,它们的逆矩阵是 A’、B’、C’和 D’,那么乘积 ABCD 的逆矩阵是 D’C’B’A’。
除了三角矩阵外,分块对角矩阵还可以用来构造可逆矩阵。下面是一个 5×5 的分块对角矩阵示例。这个矩阵可以称为 2,3 型,因为它由一个 2×2 矩阵和一个 3×3 矩阵沿着 5×5 矩阵的对角线排列而成。

当两个相同类型的分块对角矩阵相乘时,结果是相同类型的分块对角矩阵。
使用分块对角矩阵的优点是您可以分别找到每个分块的逆矩阵。如果您将这些逆矩阵串联在对角线上,结果就是整个矩阵的逆矩阵。找到一个可逆的 16×16 矩阵可能不可行,但是找到四个 4×4 可逆矩阵并不是太具挑战性。您可以通过乘以其他类型的分块对角矩阵或一些可逆的三角矩阵来将您的可逆分块对角矩阵扩展到完整矩阵。
全力以赴。使用尽可能大的分块构造您的可逆分块对角矩阵,并使用 4 个三角矩阵,每种一个。您最终的可逆矩阵是这五个矩阵的乘积。******