0、DDP的运行原理
执行步骤:
- 将data分为多个不同的batch,每个gpu得到batch都是不一样的
- 然后将每个batch放在每个gpu上独立的执行
- 最后得到的梯度求平均
- 将平均梯度平分给每个gpu
- 执行下一次迭代
这也就意味着你有多少个gpu,训练的速度也会提升多少倍
1个gpu和多个gpu输出相同的日志(step)?
例如给你一个下面的代码:
def run_loop(self):
while (not self.lr_anneal_steps or self.step + self.resume_step < self.lr_anneal_steps):
# 准备数据
batch, cond = next(self.data)
# 执行前后向传播
self.run_step(batch, cond)
# 更新日志 + save checkpoint
if self.step % self.log_interval == 0:
logger.dumpkvs()
if self.step % self.save_interval == 0:
self.opt.consolidate_state_dict()
self.save()
# Run for a finite amount of time in integration tests.
if os.environ.get("DIFFUSION_TRAINING_TEST", "") and self.step > 0:
return
self.step += 1
if self.step % 1000 == 0:
logger.log("The current step is :", self.step)
logger.log("The current time is :", datetime.datetime.now())每个GPU上的进程都会独立地执行run_loop函数,那么N个gpu就会执行N个run_loop(),所以一次就会打印出N个"The current step is 1000",如果你使用1个gpu,它同样会打印1个"The current step is 1000",你此时如果不懂原理可能会认为是不是DDP没有起到加速作用,怎么多个gpu和1个gpu在相同时间内执行的都是相同的step呢?
虽然logger输出是一样的step,但是这并不意味着你的多个gpu执行的速度和1个gpu执行的速度是一样的,虽然4个gpu输出的是100个step,但是他比1个gpu执行的batch数多4倍,也就意味着训练速度提升了4倍
一、参数说明:
我们在训练分布式时候,会使用到 torch.distributed.launch,可以通过命令,来打印该模块提供的可选参数 python -m torch.distributed.launch --help
usage: launch.py [-h] [--nnodes NNODES] [--node_rank NODE_RANK]
[--nproc_per_node NPROC_PER_NODE] [--master_addr MASTER_ADDR] [--master_port MASTER_PORT]
[--use_env] [-m] [--no_python] [--logdir LOGDIR]
training_script ...
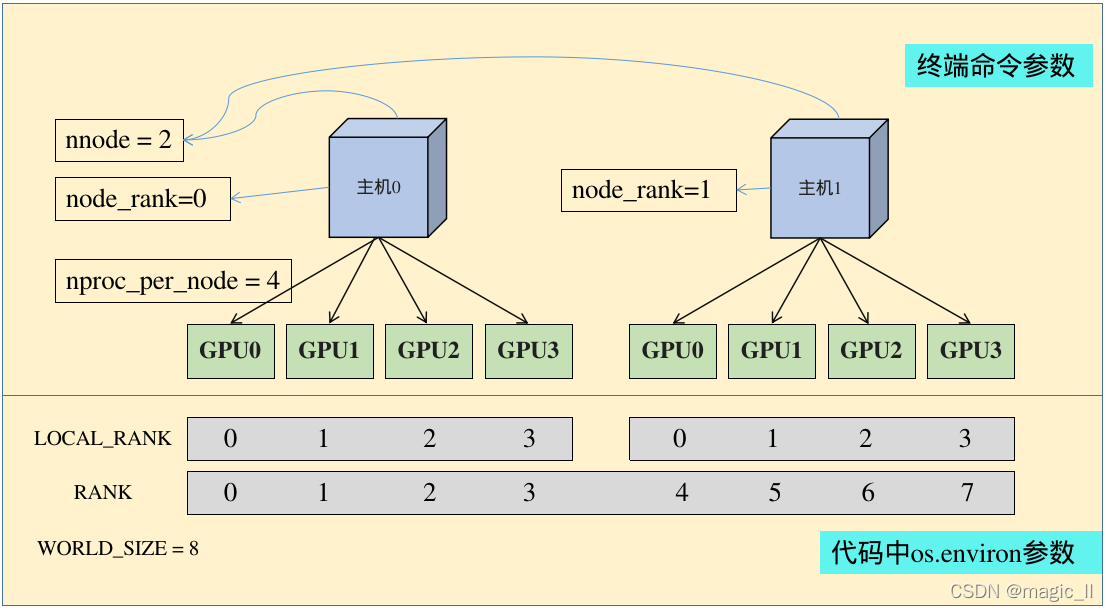
torch.ditributed.launch参数解析(终端运行命令的参数):
- nnodes:节点(主机)的数量,通常一个节点对应一个主机
- node_rank:指的是当前启动的是第几台服务器,从 0 开始。
- nproc_per_node:一个节点中显卡的数量
- -master_addr:master节点的ip地址,也就是0号主机的IP地址,该参数是为了让 其他节点 知道0号节点的位,来将自己训练的参数传送过去处理
- -master_port:master节点的port号,在不同的节点上master_addr和master_port的设置是一样的,用来进行通信
torch.ditributed.launch相关环境变量解析(代码中os.environ中的参数):
- WORLD_SIZE:os.environ[“WORLD_SIZE”]所有进程的数量(可以简单记为gpu的总数)。如果你有2台服务器,每台服务器有4张卡,那么 World Size 就是 2 x 4 = 8。
- LOCAL_RANK:os.environ[“LOCAL_RANK”]每张显卡在自己主机中的序号,从0开始。
- RANK:os.environ[“RANK”]进程的序号,一般是1个gpu对应一个进程。标识一个进程的序号,从 0 开始。按照上面例子的配置,第一台机器上的 0, 1, 2, 3 卡对应的进程序号就是 0, 1, 2, 3,第二台机器上 0, 1, 2, 3 对应的进程序号就是 4, 5, 6, 7。需要确保每个进程的序号没有重复。其中 0 号进程为主进程,负责一些同步操作的通信。
二、启动方式说明:
使用 PyTorch 启动工具启动程序
PyTorch 提供了一个 torch.distributed.launch 帮助我们启动进程。
这个工具其实就是帮你计算 WORLD_SIZE = nproc_per_node * nnodes,然后执行一个循环,启动本机进程,利用这种方式,我们就只需要指定 --nproc_per_node 与 --nnodes 即可,就不需要指定WORLD_SIZE了。
单机多卡需要使用下面命令进行运行Python程序:
其中 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=1 这一串中的参数不要少任何一个参数
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=1 train.py --args XXX
三、数据加载加速说明
dataloader提速的参数
num_workers: 加载数据的进程数量,默认只有1个,增加该数量能够提升数据的读入速度。(注意:该参数>1,在低版本的pytorch可能会触发python的内存溢出) pin_memory: 锁内存,加快数据在内存上的传递速度。 若数据加载成为训练速度的瓶颈,可以考虑将这两个参数加上。
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=32,num_workers=16,pin_memory=True)PyTorch分布式训练基础--DDP使用 - 知乎
PyTorch 多卡分布式训练 – CodeTalks
【pytorch记录】pytorch的分布式 torch.distributed.launch 命令在做什么呢-CSDN博客
![[LitCTF 2023]PHP是世界上最好的语言!!、 [LitCTF 2023]Vim yyds、 [羊城杯 2020]easycon](https://img-blog.csdnimg.cn/direct/60895ce1042e4713b4f3f123b8633151.png)