前言
熟悉Oracle的dba都知道,生产系统出现性能问题时,往往是SQL走错了执行计划,紧急情况下,无法及时修改应用代码,dba可以采用多种方式针对于某类SQL进行执行计划绑定,比如SQL Profile、SPM、SQL Plan Base、等等。 在MogDB 5.0版本引入了SQL PATCH的特性,SQL PATCH能够在避免直接修改用户业务语句的前提下对查询执行的方式做一定调整。在发现查询语句的执行计划、执行方式未达预期的场景下,可以通过创建查询补丁的方式,使用Hint对查询计划进行调优或对特定的语句进行报错短路处理。
SQL PATCH主要设计给DBA、运维人员及其他需要对SQL进行调优的角色使用,用户通过其他运维视图或定位手段识别到业务语句存在计划不优导致的性能问题时,可以通过创建SQL PATCH对业务语句进行基于Hint的调优。目前支持行数、扫描方式、连接方式、连接顺序、PBE custom/generic计划选择、语句级参数设置、参数化路径的Hint。
特性约束
-
仅支持针对Unique SQL ID打PATCH,如果存在Unique SQL ID冲突,用于Hint调优的SQL PATCH可能影响性能,但不影响语义正确性。 -
仅支持不改变SQL语义的Hint作为PATCH,不支持SQL改写。 -
不支持逻辑备份、恢复。 -
不支持创建时校验PATCH合法性,如果PATCH的Hint存在语法或语义错误,不影响查询正确执行。 -
仅初始用户、运维管理员、监控管理员、系统管理员用户有权限执行。库之间不共享,创建SQL PATCH时需要连接目标库。 -
配置集中式备机可读时,需要指定主机执行SQL PATCH创建/修改/删除函数调用,备机执行报错。 -
SQL PATCH同步给备机存在一定延迟,待备机回放相关日志后PATCH生效。 -
不支持对存储过程中的SQL语句生效,当前机制不会对存储过程内语句生成Unique SQL ID。 -
用于规避的Abort Patch不建议在数据库中长期使用,只应该作为临时规避方法。遇到内核问题所导致的特定语句触发数据库服务不可用问题,需要尽快修改业务或升级内核版本解决问题。并且升级后由于Unique SQL ID生成方法可能变化,可能导致规避方法失效。 -
当前,除DML语句之外,其他SQL语句(如CREATE TABLE等)的Unique SQL ID是对语句文本直接哈希生成的,所以对于此类语句,SQL PATCH对大小写、空格、换行等敏感,即不同的文本的语句,即使语义相对,仍然需要对应不同的SQL PATCH。对于DML,则同一个SQL PATCH可以对不同入参的语句生效,并且忽略大小写和空格。
依赖关系
需要开启enable_resource_track=on、enable_stmt_track =on并且设置instr_unique_sql_count大于0。对于不同的语句,如果生成的Unique SQL ID冲突,会导致SQL PATCH错误的命中预期外的其他语句。其中用于调优的Hint PATCH副作用相对较小,Abort Patch需要谨慎使用。
实际案例
1、创建表
创建表t1和t2;
create table t1(name char(10),id int);
create table t2(name char(10),id int);
2、构造数据
INSERT INTO t1 (name, id)
SELECT 'data_'|| generate_series(1, 1000), generate_series(1, 1000);
INSERT INTO t2 (name, id)
SELECT 'data_'|| generate_series(1, 1000), generate_series(1, 1000);
CREATE INDEX idx_t1 ON t1 (id);
CREATE INDEX idx_t2 ON t2 (id);
3、获取unique_query_id
执行SQL并获取unique_query_id、执行计划
set track_stmt_stat_level = 'L1,L1';
再次检查参数
select name,setting ,unit
from pg_catalog.pg_settings
where name in (
'enable_resource_track',
'enable_stmt_track',
'log_min_duration_statement',
'instr_unique_sql_count',
'track_stmt_stat_level',
'track_stmt_retention_time'
);
name | setting | unit
----------------------------+-------------+------
enable_resource_track | on |
enable_stmt_track | on |
instr_unique_sql_count | 100 |
log_min_duration_statement | 1800000 | ms
track_stmt_retention_time | 3600,604800 |
track_stmt_stat_level | L1,L1 |
(6 rows)
--track_stmt_stat_level解释:
该参数分为两部分:
--形式为'full sql stat level, slow sql stat level'。
--级别(L2 > L1 > L0),L1在L0的基础上记录了执行计划,L2在L1的基础上记录了锁的详细信息
select * from t1 a, t2 b where a.id = b.id;
name | id | name | id
------------+------+------------+------
data_1 | 1 | data_1 | 1
data_2 | 2 | data_2 | 2
data_3 | 3 | data_3 | 3
data_4 | 4 | data_4 | 4
data_5 | 5 | data_5 | 5
data_6 | 6 | data_6 | 6
data_7 | 7 | data_7 | 7
。。。。
(1000 row)
4、获取查看执行计划
走的全表扫描hash jion执行计划
explain select * from t1 a, t2 b where a.id = b.id;
QUERY PLAN
--------------------------------------------------------------------------
Aggregate (cost=60.75..60.76 rows=1 width=8)
-> Hash Join (cost=28.50..58.25 rows=1000 width=0)
Hash Cond: (a.id = b.id)
-> Seq Scan on t1 a (cost=0.00..16.00 rows=1000 width=4)
-> Hash (cost=16.00..16.00 rows=1000 width=4)
-> Seq Scan on t2 b (cost=0.00..16.00 rows=1000 width=4)
5、查询unique_query_id
select unique_query_id,query,start_time from dbe_perf.statement_history where query like '%from t1 a%';
unique_query_id | query | start_time
-----------------+----------------------------------------------------+-------------------------------
3366573496 | select * from t1 a, t2 b where a.id = b.id; | 2024-01-19 10:08:56.994391+08
也可以通过statement_history查询执行计划
select start_time,query_plan from dbe_perf.statement_history where unique_query_id = 3366573496;
start_time | query_plan
-------------------------------+--------------------------------------------------------------------------
2024-01-19 10:08:56.994391+08 | Datanode Name: dn_6001_6002 +
| Hash Join (cost=28.50..58.25 rows=1000 width=30) +
| Hash Cond: (a.id = b.id) +
| -> Seq Scan on t1 a (cost=0.00..16.00 rows=1000 width=15) +
| -> Hash (cost=16.00..16.00 rows=1000 width=15) +
| -> Seq Scan on t2 b (cost=0.00..16.00 rows=1000 width=15)+
| +
6、SQL PATCH绑定执行计划
call dbe_sql_util.create_hint_sql_patch('enmo patch',3366573496,'indexscan(a)');
create_hint_sql_patch
-----------------------
t
(1 row)
--参数说明:
enmo patch --SQL PATCH name
3366573496 --unique_query_id
indexscan(a) --Hint文本
7、验证SQL PATCH
执行并检查新的执行计划是否生效
select * from t1 a, t2 b where a.id = b.id;
name | id | name | id
------------+------+------------+------
data_1 | 1 | data_1 | 1
data_2 | 2 | data_2 | 2
data_3 | 3 | data_3 | 3
data_4 | 4 | data_4 | 4
data_5 | 5 | data_5 | 5
data_6 | 6 | data_6 | 6
data_7 | 7 | data_7 | 7
。。。。
explain select * from t1 a, t2 b where a.id = b.id;
NOTICE: Plan influenced by SQL hint patch
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=28.50..86.50 rows=1000 width=30)
Hash Cond: (a.id = b.id)
-> Index Scan using idx_t1 on t1 a (cost=0.00..44.25 rows=1000 width=15)
--这里走了索引,表示SQL patch生效
-> Hash (cost=16.00..16.00 rows=1000 width=15)
-> Seq Scan on t2 b (cost=0.00..16.00 rows=1000 width=15)
(5 rows)
查看statement_history的执行计划
select query_plan,to_char(start_time,'yyyymmdd-hh24:mi:ss') starttime
from dbe_perf.statement_history
where unique_query_id = 3366573496
order by start_time;
Datanode Name: dn_6001_6002 +| 20240119-10:09:54
Hash Join (cost=28.50..86.50 rows=1000 width=30) +|
Hash Cond: (a.id = b.id) +|
-> Index Scan using idx_t1 on t1 a (cost=0.00..44.25 rows=1000 width=15)+|
-> Hash (cost=16.00..16.00 rows=1000 width=15) +|
-> Seq Scan on t2 b (cost=0.00..16.00 rows=1000 width=15) +|
+|
|
参看数据库内已定义的SQL Patch
select patch_name,unique_sql_id,enable,hint_string from gs_sql_patch;
patch_name | unique_sql_id | enable | hint_string
------------+---------------+--------+--------------
enmo patch | 3366573496 | t | indexscan(a)
show_sql_patch查看SQL PATCH内容
MogDB=# select DBE_SQL_UTIL.show_sql_patch('enmo patch');
show_sql_patch
-------------------------------------
(3366573496,t,f,"indexscan(a)")
(1 row)
8、Abort Patch
使用Abort PATCH对特定语句进行提前报错规避。
MogDB=# select * from dbe_sql_util.drop_sql_patch('enmo patch'); -- 删去enmo patch
drop_sql_patch
----------------
t
(1 row)
MogDB=# select * from dbe_sql_util.create_abort_sql_patch('patch2', 3366573496); -- 对该语句的Unique SQL ID创建Abort Patch
create_abort_sql_patch
------------------------
t
(1 row)
MogDB=# select * from t1 a, t2 b where a.id = b.id; -- 再次执行语句会提前报错
ERROR: Statement 3366573496 canceled by abort patch patch2
9、关闭特定 SQL Patch
disable enmo patch
call dbe_sql_util.disable_sql_patch('enmo patch');
执行SQL并检查执行计划是否恢复原始状态
MogDB=# select query_plan,to_char(start_time,'yyyymmdd-hh24:mi:ss') starttime
MogDB-# from dbe_perf.statement_history
MogDB-# where unique_query_id = 3366573496
MogDB-# order by start_time;
query_plan | starttime
--------------------------------------------------------------------------+-------------------
Datanode Name: dn_6001_6002 +| 20240119-13:24:52
Nested Loop (cost=0.00..340.00 rows=1000 width=30) +|
-> Seq Scan on t1 a (cost=0.00..16.00 rows=1000 width=15) +|
-> Index Scan using idx_t2 on t2 b (cost=0.00..0.31 rows=1 width=15)+|
Index Cond: (id = a.id) +|
+|
|
Datanode Name: dn_6001_6002 +| 20240119-13:31:49
Hash Join (cost=28.50..58.25 rows=1000 width=30) +|
Hash Cond: (a.id = b.id) +|
-> Seq Scan on t1 a (cost=0.00..16.00 rows=1000 width=15) +|
-> Hash (cost=16.00..16.00 rows=1000 width=15) +|
-> Seq Scan on t2 b (cost=0.00..16.00 rows=1000 width=15) +|
+|
最新的执行计划已经还原成hash jion
技能延伸:Mogdb支持的hint
1、兼容Oracle的hint
Scan方式的Hint
-
tablescan 全表扫描 tablescan(表名/别名) no tablescan(表名/别名)
explain select /*+ tablescan(e) */ * from emp e where empno=3000;
-
indexscan 索引扫描 indexscan(表名/别名 [索引名]),如果where条件列没有合适的索引,会提示unused hint
explain select /*+ indexscan(t) */ * from test t where object_id >100;
-
indexonlyscan 仅索引扫描 indexonlyscan(表名/别名 索引名),如果where条件列没有合适的索引,会提示unused hint
explain select /*+ indexonlyscan(t) */ object_id from test t where object_id >100;
Join顺序的Hint
join table list中指定的表需要满足以下要求,否则会报语义错误。
-
list中的表必须在当前层或提升的子查询中存在。 -
list中的表在当前层或提升的子查询中必须是唯一的。如果不唯一,需要使用不同的别名进行区分。 -
同一个表只能在list里出现一次。 -
如果表存在别名,则list中的表需要使用别名。 leading 指定哪两个表先关联 leading(a b) 必须指定2个或2个表以上,如果要指定两个表的先后顺序,leading(( ))
explain select /*+ leading((e d) hashjoin(e d) ) */ * from emp e ,dept d where e.deptno =d.deptno;
explain select /*+ leading((e d) nestloop(e d) ) */ * from emp e ,dept d where e.deptno =d.deptno;
explain select /*+ leading((e dmergejoin(e d) )) */ * from emp e ,dept d where e.deptno =d.deptno;
子链接块名的hint
控制半连接执行计划,mogdb中给子查询取别名 blockname ,然后把它当成表名字与外面的表关联 示例
explain select /*+nestloop(store_sales tt) */ * from store_sales where ss_item_sk in (select /*+blockname(tt)*/ i_item_sk from item group by 1);
指定row的hint
rows 指定表或结果集返回rows 用法:
/*+ rows(e #100) */ 指定e返回100行
/*+ rows(e +100) */ 指定e在原来的预估上+100行
/*+ rows(e -100) */ 指定e在原来的预估上-100行
/*+ rows(e *100) */ 指定e在原来的预估上*100行
/*+ rows(e d #100) */ 指定e和d关联之后返回100行
explain select /*+ rows(store_sales store_returns *50) */ i_product_name product_name
该hint表示: store_sales,store_returns关联的结果集估算行数在原估算行数基础上乘以50。生成计划如下所示: 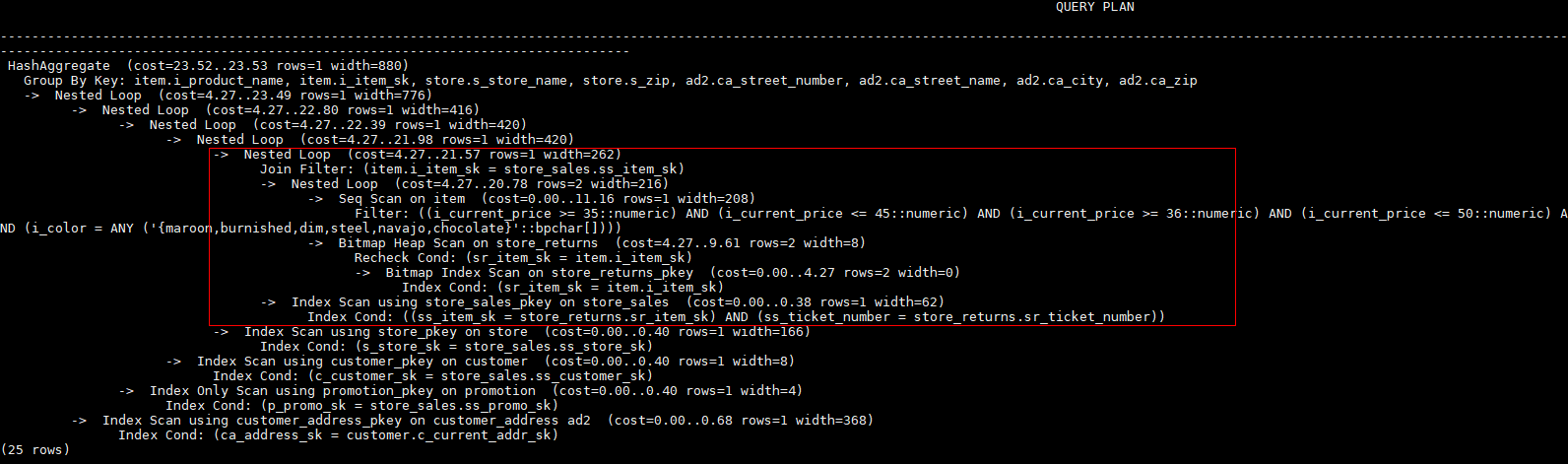
指定参数的Hint
目前支持使用Hint设置生效的参数有
-
布尔类: enable_bitmapscan, enable_hashagg,enable_hashjoin, enable_indexscan,enable_indexonlyscan, enable_material,enable_mergejoin, enable_nestloop,enable_index_nestloop, enable_seqscan,enable_sort, enable_tidscan,partition_iterator_elimination,partition_page_estimation,enable_functional_dependency,var_eq_const_selectivity,enable_inner_unique_opt
-
整形类: query_dop
-
浮点类: cost_weight_index, default_limit_rows, seq_page_cost, random_page_cost, cpu_tuple_cost, cpu_index_tuple_cost, cpu_operator_cost, effective_cache_size
-
枚举类型: try_vector_engine_strategy
用法: set(param value) 设置优化器参数
/*+ set(enable_hashjoin false) */ ---关闭hashjoin
/*+ set(query_dop 2) */ ---设置并行2
/*+ set(work_mem 131072) */ ---work_mem没在白名单里面
子查询不展开的Hint
用法: /+ no_expand/
正常的查询执行
explain select * from t1 where t1.a in (select t2.a from t2);
加入no_expand
explain select * from t1 where t1.a in (select /*+ no_expand*/ t2.a from t2);
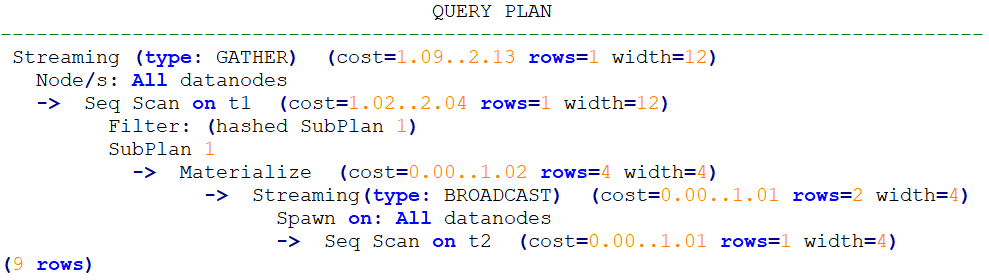
同层参数化路径的Hint
通过predpush_same_level Hint来指定同层表或物化视图之间参数化路径生成。 用法: predpush_same_level(src, dest) predpush_same_level(src1 src2 ..., dest)
-
本参数仅在rewrite_rule中的predpushforce选项打开时生效。
MogDB=# set rewrite_rule = 'predpushforce';
SET
MogDB=# explain select * from t1, t2 where t1.a = t2.a;
QUERY PLAN
------------------------------------------------------------------
Hash Join (cost=27.50..56.25 rows=1000 width=16)
Hash Cond: (t1.a = t2.a) --可以看到t1.a = t2.a条件过滤在Join上面
-> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on t2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
可以看到t1.a = t2.a条件过滤在Join上面,此时可以通过predpush_same_level(t1, t2)将条件下推至t2的扫描算子上
MogDB=# explain select /*+predpush_same_level(t1, t2)*/ * from t1, t2 where t1.a = t2.a;
QUERY PLAN
---------------------------------------------------------------------
Nested Loop (cost=0.00..335.00 rows=1000 width=16)
-> Seq Scan on t1 (cost=0.00..15.00 rows=1000 width=8)
-> Index Scan using idx2 on t2 (cost=0.00..0.31 rows=1 width=8)
Index Cond: (a = t1.a)
(4 rows)
2、兼容Mysql的hint
INDEX HINTS
用法: tbl_name [ partition_clause ] [ [ AS ] alias ] [ index_hint_list ] index_hint_list: index_hint [ index_hint ] index_hint: USE INDEX ( [ index_list ] ) | FORCE INDEX ( index_list ) index_list: index_name [ , index_name ] ...
MogDB=# explain (costs off,verbose true )select * from db_1097149_tb force key (index_1097149_4) where col2= 3 and col4 = 'a';
QUERY PLAN
----------------------------------------------------------
Index Scan using index_1097149_4 on public.db_1097149_tb
Output: col1, col2, col3, col4
Index Cond: ((db_1097149_tb.col4)::text = 'a'::text)
Filter: (db_1097149_tb.col2 = 3)
(4 rows)
3、将部分Error降级为Warning的Hint
指定执行INSERT、UPDATE语句时可将部分Error降级为Warning,且不影响语句执行完成的hint。
db_ignore=# set sql_ignore_strategy = 'ignore_null';
SET
db_ignore=# insert /*+ ignore_error */ into t_not_null values(null), (1);
WARNING: null value in column "num" violates not-null constraint
DETAIL: Failing row contains (null).
INSERT 0 1
db_ignore=# select * from t_not_null ;
num
-----
1
(1 row)
4、Hint的错误增强
Mogdb常用HINT对比Oracle的hint做了增强,更加人性化。当出现语法错误、语义错误、hint重复或冲突、子链接提升后hint失效、列类型不支持重分布、hint未被使用会根据语句类型以不同方式提示用户
5、不使用全局计划缓存的Hint
全局计划缓存打开时,可以通过no_gpc Hint来强制单个查询语句不在全局共享计划缓存,只保留会话生命周期的计划缓存。 用法: /+ no_gpc/
-
本参数仅在enable_global_plancache=on时对PBE执行的语句生效。 
6、Custom Plan和Generic Plan选择的Hint
用法: /*+ use_cplan / /+ use_gplan */
MogDB=# create table t (a int, b int, c int);
CREATE TABLE
MogDB=# prepare p as select /*+ use_cplan */ * from t where a = $1;
PREPARE
MogDB=# explain execute p(1);
QUERY PLAN
----------------------------------------------------
Seq Scan on t (cost=0.00..34.31 rows=10 width=12)
Filter: (a = 1)
(2 rows)
MogDB=# show enable_pbe_optimization;
enable_pbe_optimization
-------------------------
on
(1 row)
MogDB=# deallocate p;
DEALLOCATE
MogDB=# prepare p as select /*+ use_gplan */ * from t where a = $1;
PREPARE
MogDB=# explain execute p(1);
QUERY PLAN
----------------------------------------------------
Seq Scan on t (cost=0.00..34.31 rows=10 width=12)
Filter: (a = $1)
(2 rows)
详细内容请参考如下链接: OpenGauss/MogDB基于绑定变量的SQL优化
-
MogDB官方文档参考:
sql-patch#特性描述 track_stmt_stat_level Mogdb Plan Hint进行调优
本文由 mdnice 多平台发布