目录
1. key到期的情况
Redis的内存结构redisDb
Redis怎么知道哪个key过期的
Redis对过期key的删除策略
惰性删除
周期删除
2. key未到期,但内存使用已达上限的情况
Redis检查内存阈值的时刻
达到内存上限,Redis淘汰key的策略
结构体redisObject的变量lru
LRU算法
标准的LRU实现方式
Redis中实现的LRU
Redis中的LRU与常规的LRU的区别
为什么不用标准的LRU?
LFU算法
为什么需要LFU
LFU在Redis中的实现
内存淘汰流程
Redis之所以性能强,最主要的原因是其是基于内存存储的(内存本身就是很快的)。然而单节点的Redis的内存大小不宜过大,否则会影响持久化或主从同步的性能。当内存使用达到上限的时候,Redis就无法存储更多数据了。
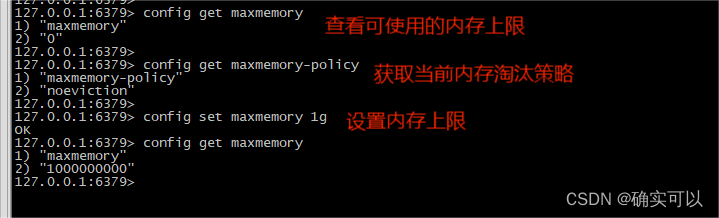
我们可以通过修改配置文件redis.conf来永久设置Redis的最大内存:
# maxmemory <bytes>在文件中去掉 #,比如写:maxmemory 1gb。
也可以在客户端进行查看设置(重启后就会失效)。
redis默认内存:如果不设置最大内存大小或者设置最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存。
那么,Redis是如何避免达到内存上限的,其内存策略是怎样的?
主要分2种情况:
- key到期如何处理
- key未到期,但内存使用已达上限,如何处理
1. key到期的情况
Redis的内存结构redisDb
//server.h
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB *///存放所有的key和value
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; //exipre检查时在dict中抽样的索引位置
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;结构的成员变量:
- *dict:指向dict结构,记录了所有的key和value
- *expires:也是指向了dict结构,记录了key对应的ttl(存活时间)
- *blocking_keys,*ready_keys,*watch_keys这些跟功能有关
- avg_ttl:记录平均TTL时长
- id:表示是哪个库,一共有16个库,默认是使用库0
Redis怎么知道哪个key过期的
前面了解了redisDb,所有的key和value都是存储在其中的。redisDb的成员expires记录了该库中所有key的绝对过期时间(Unix时间戳格式,不是保存还剩余过期的秒数),这样通过key获取value,再通过当前时间(服务器时间)和key的过期时间戳进行比较判断是否过期。
从插入数据的代码入手,比如 set name jack。
void setCommand(client *c) {
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = OBJ_NO_FLAGS;
//从该函数中获取过期值,并将其包装成redisObject,赋值给expire
if (parseExtendedStringArgumentsOrReply(c,&flags,&unit,&expire,COMMAND_SET) != C_OK) {
return;
}
c->argv[2] = tryObjectEncoding(c->argv[2]);
//在该函数中,往dict添加过期时间
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0, when = 0; /* initialized to avoid any harmness warning */
if (expire) {
//从redisObject的expire中获取过期值,并赋值给milliseconds
if (getLongLongFromObjectOrReply(c, expire, &milliseconds, NULL) != C_OK)
return;
if (milliseconds <= 0 || (unit == UNIT_SECONDS && milliseconds > LLONG_MAX / 1000)) {
/* Negative value provided or multiplication is gonna overflow. */
addReplyErrorFormat(c, "invalid expire time in %s", c->cmd->name);
return;
}
if (unit == UNIT_SECONDS) milliseconds *= 1000;
when = milliseconds;
if ((flags & OBJ_PX) || (flags & OBJ_EX))
when += mstime(); //mstime()是获取当前时间,替换成秒数,所以when就是过期的绝对时间
}
..............................
if (expire) {
setExpire(c,c->db,key,when); //往c->db中的dict添加key的绝对过期时间
.........................................
}
................................
}Redis对过期key的删除策略
如果发现key过期了,是立即删除吗?要是达到立即删除的效果,那就需要监控每个key,即是对每一个key都设计一个定时器。
这样对内存友好,但是严重消耗CPU,对CPU非常不友好,而redis又是一个特别注重吞吐量的数据库,这样大量key过期势必会大大地降低吞吐。所以redis没有采用。
所以,Redis使用惰性删除和周期删除一起来确保过期的key最终会被清理掉。
惰性删除
不是在TTL到期后就立即删除,而是在访问(改查)一个key时,就检查该key的TTL;若已过期,则进行删除。即是每次对key操作时,都会判断是否过期。
比如:命令 get key。代码流程如下getCommand--->getGenericCommand--->lookupKeyReadOrReply--->lookupKeyRead--->lookupKeyReadWithFlags--->expireIfNeeded。
//命令格式 get key
void getCommand(client *c) {
getGenericCommand(c);
}
int getGenericCommand(client *c) {
robj *o;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp])) == NULL)
return C_OK;
...............
}
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
if (expireIfNeeded(db,key) == 1) { //检查key是否过期
..................
}
val = lookupKey(db,key,flags);
return val;
............
}
int expireIfNeeded(redisDb *db, robj *key) {
//判断是否过期,若未过期,直接返回0
if (!keyIsExpired(db,key)) return 0;
// 如果当redis前机器是从节点,不进行过期删除
if (server.masterhost != NULL) return 1;
// 正在选取主节点的时候也不进行删除
if (checkClientPauseTimeoutAndReturnIfPaused()) return 1;
/* Delete the key */
deleteExpiredKeyAndPropagate(db,key); //删除过期key
return 1;
}结合上面的代码可以知道2点:
- 从节点不主动删除过期的key
- 在选取主节点的时候不能删除过期的key
惰性删除导致的问题
因为key是在被访问的时候才会进行删除的。若是一直不访问该key,那其就会一直存在,所以需要有其他策略来弥补这个漏洞。
周期删除
顾名思义,即是通过一个定时任务,周期性地检查部分过期key,然后进行删除。
先来看看定时任务是什么时候设置的,定时任务的内容是什么?
在initServer函数中调用aeCreateTimeEvent创建定时任务,任务内容是函数serverCron。
//server.c
int main(int argc, char **argv){
initServer();
..................
}
void initServer(void) {
//server.db是redisDb *类型,即是分配内存空间给server的db
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
//创建redis的databases,初始化redisDb的参数
for (int j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&dbExpiresDictType,NULL);
server.db[j].expires_cursor = 0;
server.db[j].id = j;
server.db[j].avg_ttl = 0;
//还有初始化*blocking_keys,*ready_keys,*watch_keys参数没有展示............
}
evictionPoolAlloc(); /* Initialize the LRU keys pool. */
//创建定时器,关联回调函数serverCron,处理周期取决于server.hz,默认10
aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL)
//设置每个事件循环前都会调用的回调函数,即是beforeSleep会回调
aeSetBeforeSleepProc(server.el,beforeSleep);
if (server.arch_bits == 32 && server.maxmemory == 0) {//设置默认的内存上限和内存淘汰策略
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
}
....................
}
serverCron函数就是执行定时删除操作的。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock,lruclock);
...............................
/* Handle background operations on Redis databases. */
databasesCron();
return 1000/server.hz; //该返回值是下次执行该函数的时间间隔
}
void databasesCron(void) {
if (server.active_expire_enabled) {
if (iAmMaster()) {
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); //slow模式删除过期keys
} else {
expireSlaveKeys();
}
}
}activeExpireCycle定期清理过期key
为了避免过期key占用大量的内存,activeExpireCycle用来清理过期key。由于Redis的单线程模型,如果过期key很多,扫描一次会很耗时,这样可能会阻塞服务端,所以activeExpireCycle就不可能占用太多时间,所以Redis对于activeExpireCycle的执行时间控制就很精确了,对这个函数的要求是既要执行时间可控,又要尽可能多的清理过期健,减少内存占用。
其有两种执行周期:
1)slow模式:Redis初始化后1ms后执行,随后每隔100ms执行一次清理;低频清理每次耗时较长在25ms之内。
- 执行频率受server.hz影响,默认为10,即是每秒执行10次,每个执行周期100ms。
- 执行清理耗时不超过一次执行周期的25%。
- 逐个遍历db,对每个db中的bucket(每个db的记录key过期时间的dict),抽取20个key判断是否过期,若过期了就进行删除,逐个bucket会进行保存,以便于下次遍历可以从上次遍历的结束位置继续执行。
- 如果抽取20个key,删除后,还没有达到时间上限(25ms)并且过期key比例大于10%,就认为还有比较大量的key需要删除,所以再进行一次抽样删除,否则结束。
2)FAST模式:Redis的每个事件循环前会调用beforesleep()函数,该函数内部会执行过期key清理,高频少量清理每次耗时在1ms 之内。
- 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms,执行清理耗时不超过1ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期,若过期则进行删除;
- 如果没有达到时间上限(1ms)并且过期key的比例大于10%,再进行一次抽样,否则结束。
void beforeSleep(struct aeEventLoop *eventLoop) {
.................................
/* Run a fast expire cycle (the called function will return
* ASAP if a fast cycle is not needed). */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
........................................
}定期删除和惰性删除的区别
定期删除是集中处理,惰性删除是零散处理。这样做的目的是分散过期压力、保证Redis的高吞吐。
2. key未到期,但内存使用已达上限的情况
上面讨论了通过对key设置TTL,在达到key过期时删除该key。但是,当有大量的数据存入Redis,此时key都没有过期,而Redis为了避免达到内存上限,Redis会主动挑选部分key删除以释放更多内存,即使这些key没有过期。
Redis检查内存阈值的时刻
对key进行增删改查,都会去检查内存阈值。如果达到阈值且没有执行lua脚本,就进行内存淘汰,内存清理成功,则可以继续执行命令,如果清理失败,则直接拒绝执行命令。
Redis 会在处理客户端命令的方法 processCommand() 中尝试做内存淘汰。
int processCommand(client *c) {
...........................................
// Handle the maxmemory directive.
//如果设置了 server.maxmemory 属性,并且并未有执行 lua 脚本
if (server.maxmemory && !server.lua_timedout) {
//在函数performEvictions中尝试进行内存淘汰
int out_of_memory = (performEvictions() == EVICT_FAIL);
...............
}
...............................
}
/ * Returns:
* EVICT_OK - memory is OK or it's not possible to perform evictions now
* EVICT_RUNNING - memory is over the limit, but eviction is still processing
* EVICT_FAIL - memory is over the limit, and there's nothing to evict
* */
int performEvictions(void) {
if (!isSafeToPerformEvictions()) return EVICT_OK;
size_t mem_reported, mem_tofree;
long long mem_freed; /* May be negative */
//该函数获取已使用的内存大小,并和内存上限相减,获得需要释放的内存大小
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return EVICT_OK;
//若内存淘汰策略是不淘汰,即返回失败
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
return EVICT_FAIL; /* We need to free memory, but policy forbids. */
mem_freed = 0;
.............................
monotime evictionTimer;
elapsedStart(&evictionTimer);
//while循环里面的就是用于删除key的,用于空出内存
while (mem_freed < (long long)mem_tofree) {
.........................
}
................................
}从源码中可知,要想修改删除策略并生效,需要设置maxmemory参数不为0。
达到内存上限,Redis淘汰key的策略
Redis定义了8种策略进行key的筛选
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random: 对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key,随机进行淘汰。也就是从db->expires中随机挑选
- allkeys-lru:对全体key,基于LRU算法进行淘汰
- volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰,即是淘汰最久没有使用的key
- allkeys-lfu:对全体key,基于LFU算法进行淘汰,即是淘汰使用频率最少的key
- volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰。
比较容易混淆的lru,lfu算法。
- LRU(Least Receontly Used),最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。即是越久没有使用,淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
结构体redisObject的变量lru
Redis把每个数据都封装成redisObject,而redisObject中有个变量lru,其就是用来删除时表示用什么策略的。
下图是淘汰策略为LRU 时的redisObject。

LRU算法
标准的LRU实现方式
一般情况下,其是一个队列,往队尾插入,要淘汰就淘汰队头。队尾就是最新的被访问的数据。
- 新增key,value时候先在链表结尾添加节点,若是超过LRU设置的阈值就淘汰队头的节点并删除hashMap中对应的节点
- 修改key对应的value时候,先修改对应链表节点中的值,然后把节点移动到队尾。
- 访问key,就把该key对应的节点移动到队尾即可。
Redis中实现的LRU
- Redis维护了一个24bit的时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟,这个是全局的。
- 每个key的redisObject内部维护了一个24bit的时钟lru,当新增key对象时候会把系统的时钟赋值给该key对象内的时钟。这个时钟也是会变化的,每次查询key时候,会把当前时间赋值给其lru。
- 在进行LRU策略淘汰时候,获取当前的全局时钟,然后找到key对象的时钟lru,将与全局时钟间隔时间最长的key进行淘汰。
- 注意:这里全局时钟只有24bit,按秒为单位来表示的话最大能存储194天。所以可能会出现key对象时钟大于全局时钟的情况。若这种情况出现,那么这两个就相加(而不是相减)来得到的最大间隔时间的key。
struct redisServer {
int hz; /* serverCron() calls frequency in hertz */
redisDb *db;
// 全局时钟
redisAtomic unsigned int lruclock; /* Clock for LRU eviction */
...........................
}
typedef struct redisObject {
/* key对象内部时钟 */
unsigned lru:LRU_BITS;
..............
} robj;
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
//获取当前lurclock
unsigned int getLRUClock(void) {
//mstime()是获取当前时间转化成毫秒数, & LRU_CLOCK_MAX后,其最大值就是LRU_CLOCK_MAX
return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
}
在main()函数中初始化全局lruclock,并通过函数serverCron定时更新全局lruclock。
int main(int argc, char **argv) {
....................
initServerConfig();
.................
}
//初始化server.lruclock
void initServerConfig(void) {
......................
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock,lruclock);
}
//这个是定时任务,之前有讲过的
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
........................
unsigned int lruclock = getLRUClock(); //获取全局的lru时钟
atomicSet(server.lruclock,lruclock);
}Redis中的LRU与常规的LRU的区别
- 常规的LRU会准确淘汰掉队头节点
- 而Redis的LRU并不维护一个队列,只是根据配置的策略,要么从所有的key中随机选取N个(N可以设置),要么从所有设置了过期时间的key中选出N个,然后再从这N个钟选取最久没有被使用的key进行淘汰。
为什么不用标准的LRU?
是因为LRU需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造,近似LRU算法采用在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和LRU算法非常近似的效果。
LFU算法
为什么需要LFU
因为LRU算法是有些缺点的。按照Redis的LRU算法,keyA的lru与当前时间的差值是2,而keyB的lru与当前时间的差值是1,就会删除keyA。但是keyA是被访问最多的,那应该是保留keyA的。
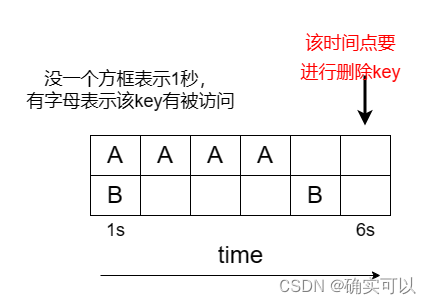
LFU就是为应对这种情况而生的。
LFU在Redis中的实现
- LFU把原来的key对象的内部时钟的24bit分成两部分,前16bit还是表示时钟,后8bit表示一个计数器。
- 而16位的情况下还按照秒为单位的话就会导致不够用,所以一般这里是以时钟为单位。
- 而后8bit表示当前key的访问评论,8bit最大只能表示255,但是Redis并没有使用线性增大的方式,而是通过一个负责的公式来计算的。
公式的计算过程:
- 生成0~1之间的随机数R
- 计算1/(key旧的访问次数*lfu_log_factor+1),记录为P,lfu_log_factor(可在配置文件中配置)默认为10
- 若R<P,则计数器+1,且不会超过255,第一次key的访问次数是0,所以P=1,此时R肯定小于P,则计数+1,随后再次访问key,P的数据肯定小于0.1,此时的R不一定小于P,则计数不增加;频繁访问时,P的值会随着减少
- 访问次数会随着时间衰减,距离上一次访问时间每个luf_decay_time分钟(默认为1,可在配置文件配置),计数器-1.
这样设计的逻辑次数上限是255,并会随着时间的推移进行递减。
代码从客户端查找key开始入手
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { //LFU算法的
updateLFU(val); // 更新LFU信息
} else {
val->lru = LRU_CLOCK();
}
}
return val;
}
}
/ * 访问对象时更新LFU。
* 首先,如果达到递减时间,则递减计数器。
* 然后对数递增计数器,并更新访问时间。*/
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val); //如果达到递减时间,则递减计数器
counter = LFULogIncr(counter); //递增的
val->lru = (LFUGetTimeInMinutes()<<8) | counter; //设置lru 高8bit为分钟数,第8bit为counter
}
#define LFU_INIT_VAL 5
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
为什么r是小于1, 因为rand() 函数是取 0 ~ RAND_MAX 的伪随机数
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
// 如果符合,counter就自增,否则,保持原值
if (r < p) counter++;
return counter;
}内存淘汰流程
该图的主要流程是函数evictionPoolPopulate的流程。
按照一般想法,我们需要给每种策略都写一种判断方法,这是很麻烦的。
所以Redis中使用一种固定的判断方法,就是从每个淘汰策略中返回一个idleTime(空闲时间),该值越大,淘汰优先级就越高。这样,我们就只需要修改红框中的部分,不管来多少个策略,都只是改变其策略算法而已,这就是可插拔式的,很方便。
- TTL策略,TLL越小表示离过期时间越近,那用max-TLL,那其值越大就表示淘汰优先级越高
- LRU策略,lru值表示最新被访问的时间,其越小表示更久没有被访问,即是淘汰优先级越高,所以用now-lru,其值越大,就表示淘汰优先级越高
- LFU策略,可以得到被访问的频率次数,其次数越小,表示更需要被淘汰。所以使用255-lfu计数,其值越大,淘汰优先级越高。
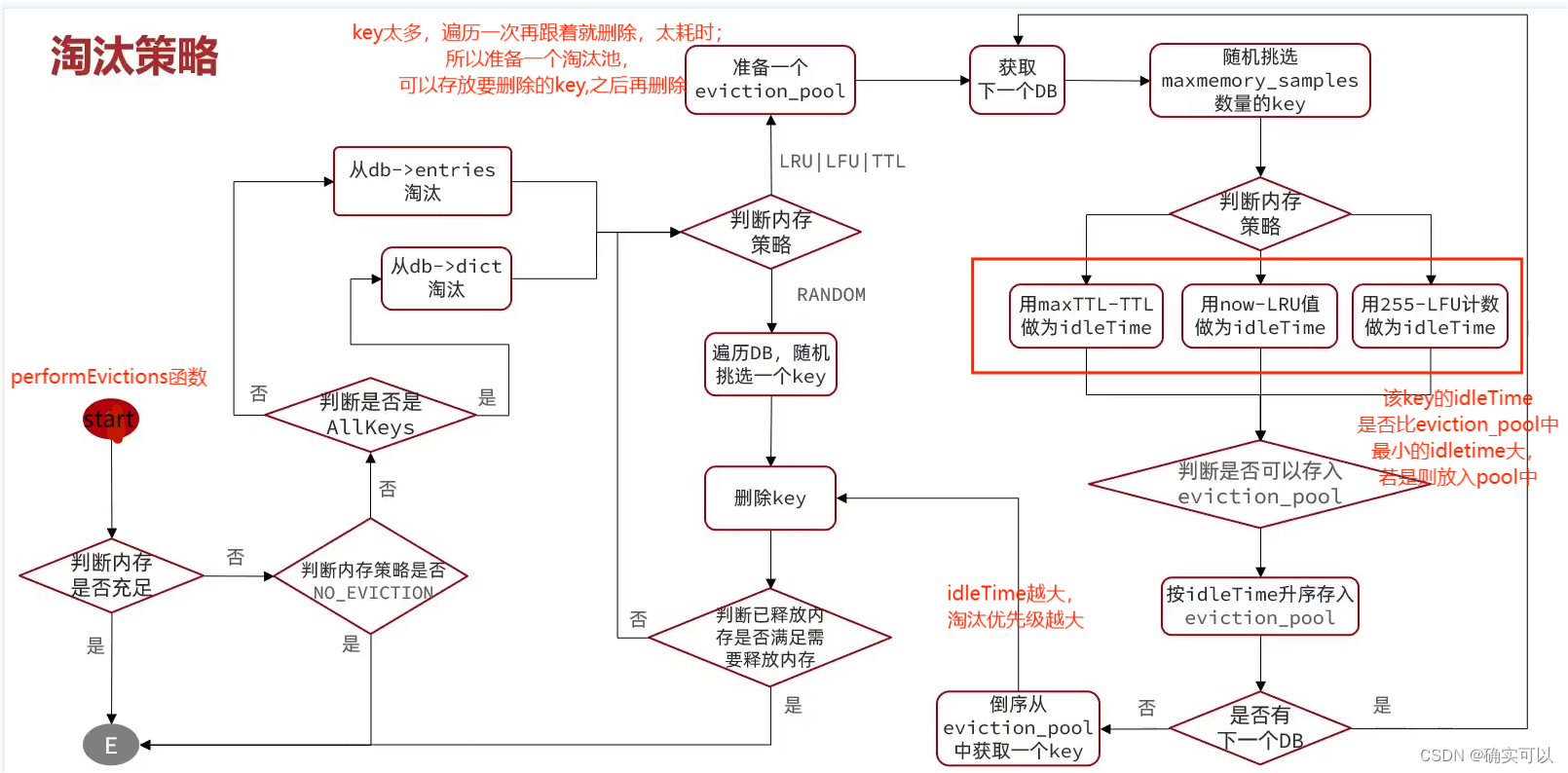
代码函数调用流程processCommand--->performEvictions--->evictionPoolPopulate。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *samples[server.maxmemory_samples];
//随机获取一些key,个数是server.maxmemory_samples,count是最终获取到的个数
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
}
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) { //LRU算法的
idle = estimateObjectIdleTime(o); //获取时间差
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { //LFU算法的
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { //TTL的
/* In this case the sooner the expire the better. */
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
//通过idle判断是否能存放到eviction_pool中
........................
}
}看看TTL,LRU,LFU策略的算法
//LRU
//获取时间差,值越大越容易被淘汰
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK(); //获取 当前秒数的后24bit
if (lruclock >= o->lru) { //当前时间和key对象的lru对比
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION; //返回时间差的毫秒数
} else {
//这里是因为24bit存时间可能会得到当前时间比redisObject小的情况
//所以以这样形式获取时间差
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}
//LFU的, 255-LFUDecrAndReturn(o)
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}