1.1搭建Spark集群
Spark集群环境可分为单机版环境、单机伪分布式环境和完全分布式环境。本节任务是学习如何搭建不同模式的Spark集群,并查看Spark的服务监控。读者可从官网下载Spark安装包,本文使用的是spark-2.0.0-bin-hadoop2.7.gz。
1.1.1搭建单机版集群
单机版环境可以支持对Spark的应用程序测试工作,对于初学者而言是非常有益。
搭建单机版Spark集群步骤如下:
1.在Spark官网选择对应版本的Spark安装包并下载至Windows本地路径下。
2.将Spark安装包上传至linux虚拟机的/opt目录下。
3.将Spark安装包解压至/usr/local/src/目录下。
1)解压Spark安装包
tar -zxf /opt/software/spark-2.0.0-bin-hadoop2.7.gz -C /usr/local/src/2)进入Spark安装目录的/bin目录,使用“SparkPi”计算Pi值
#进入目录
cd /usr/local/src/spark/bin/
#执行如下命令,其中2是指两个并行度
./run-example SparkPi 2
使用“SparkPi”计算Pi值的结果
![]()
1.1.2搭建单机伪分布式集群
Spark单机伪分布式集群指的是在一台机器上既有Master进程,又有Worker进程。Spark单机伪分布式集群可在Hadoop伪分布式环境基础上进行搭建。读者可自行了解如何搭建Hadoop伪分布式集群,本文不做介绍。搭建Spark单机伪分布式集群的步骤如下:
(1)将Spark安装包解压至Linux的/usr/loca/src/目录下。
(2)进入解压后的Spark安装目录,对安装包进行改名
mv spark-2.0.0-bin-hadoop2.7 spark(3)进入Spark的/conf目录下,复制spark-env.sh.template文件并重命名为spark-env.sh。
[root@master spark]# cd conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh(4)打开spark-env.sh文件,在文件末尾添加代码
export JAVA_HOME=/usr/local/src/jdk
export HADOOP_HOME=/usr/lcoal/src/hadoop
export HADOOP_CONF_DIP=/usr/local/src/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_LOCAL_USR_IP=master| 参数 | 解释 |
| JAVA_HOME | Java的安装路径 |
| HADOOP_HOME | Hadoop的安装路径 |
| HADOOP_CONF_DIP | Hadoop配置文件的路径 |
| SPARK_MASTER_IP | Spark主节点的IP地址或主机名 |
| SPARK_LOCAL_USR_IP | Spark本地IP地址或主机名 |
(5)切换到Spark安装目录的/sbin目录下,启动Spark集群
[root@master sbin]# cd /usr/local/src/spark/sbin/
[root@master sbin]# ./start-all.sh
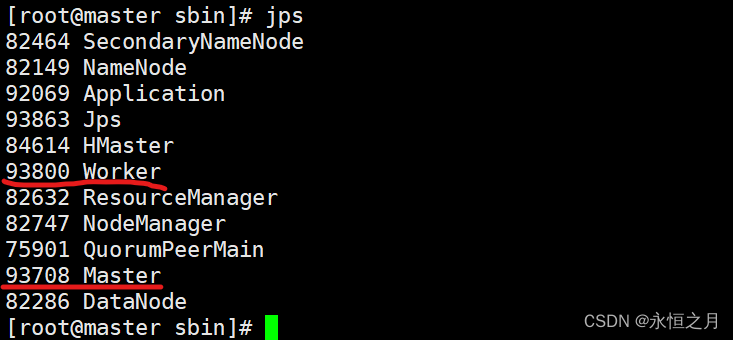
通过命令“jps”查看进程,如果既有Master进程又有Worker进程,那么说明Spark集群启动成功
(6)切换至Spark安装包的/bin目录下,使用“SparkPi”计算Pi值
[root@master bin]# ./run-example SparkPi 2![]()
由于计算Pi的值时采用随机数,因此每次计算结果也会有差异
1.1.3搭建完全分布式集群
Spark完全分布式集群使用主从模式,即其中一台机器作为主节点master,其他的几台机器作为子节点slave。本文使用的Spark完全分布式共有三个节点,分别是一个主节点和2个子节点
Spark完全分布式集群是在Hadoop完全分布式集群的基础上进行搭建的。读者可自行了解如何搭建Hadoop完全分布式集群,本文不做介绍
(1)在前面的基础之上切换至Spark安装目录下的/conf目录下,并打开spark-env.sh文件,并添加如下代码:
#将原来伪分布式集群添加上去的那几行代码删掉从新添加下面代码,防止后面发生影响
export JAVA_HOME=/usr/local/src/jdk
export HADOOP_CONF_DIP=/usr/local/src/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_INSTANCES=1spark-env.sh文件的配置参数解释
| 参数 | 解释 |
| JAVA_HOME | Java的安装路径 |
| HADOOP_CONF_DIR | Hadoop配置文件的路径 |
| SPARK_MASTER_IP | Spark主节点的IP地址或主机名 |
| SPARK_MASTER_PORT | Spark主节点的端口号 |
| SPARK_WORKER_MEMORY | 工作(worker)节点能给予Executor的内存大小 |
| SPARK_WORKER_CORES | 每个节点可以使用的内核数 |
| SPARK_EXECUTOR_MEMORY | 每个Executor内存大小 |
| SPARK_EXECUTOR_CORES | Executor的内核数 |
| SPARK_WORKER_INSTANCES | 每个节点的Worker进程数 |
(2)配置Workers文件。复制Workers.template文件并重命名为Workers,打开Workers文件删除原有内容,并添加如下代码,每一行代表一个子节点的主机名,这里的workers文件名为,slaves.template
slave1
slave2(3)配置spark-defaults.conf文件。复制spark-defaults.conf.template文件并重命名为spark-defaults.conf,打开spark-defaults.conf文件,并添加如下代码:
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/spark-logs
spark.history.fs.logDirectory hdfs://master:8020/spark-logsspark-defaults.conf文件的配置参数解释
| 参数 | 解释 |
| spark.master | Spark主节点所在机器及端口,默认写法是spark:// |
| spark.eventLog.enabled | 是否打开任务日志功能,默认为false,既不打开 |
| spark.eventLog.dir | 任务日志默认存放位置,配置一个HDFS路径即可 |
| spark.history.fs.logDirectory | 存放历史应用日志文件目录 |
(4)在主节点(master节点)中,将配置好的Spark安装目录远程复制至子节点(slave1,slave2节点)的/usr/local/src/目录下,代码如下:
[root@master src]# scp -r /usr/local/src/spark root@slave1:/usr/local/src/
[root@master src]# scp -r /usr/local/src/spark root@slave2:/usr/local/src/(5)启动Spark集群前,需要先启动Hadoop集群,并创建/spark-logs目录,如代码:
#启动Hadoop集群
cd /usr/local/src/hadoop
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sibn/mr-jobhistory-daemon.sh start historyserver
#创建/spark-logs目录
hdfs dfs -mkdir /spark-logs(6)切换至Spark安装目录的/sbin目录下,启动Spark集群
cd /usr/local/src/spark/sbin/
./start-all.sh
./start-history-server.sh(7)通过命令jps查看进程,开启Spark集群后,master节点增加了Master进程,而子节点则增加了Worker进程。
Spark集群启动成功后,打开浏览器访问“http://master:8080”,可进入主节点的监控界面。其中master指代主节点的IP地址
Hisory Server的监控端口为18080端口,打开浏览器访问“http://master:18080”,即可看到监控界面,界面记录了作业信息,包括已经运行完成的作业的信息和正在运行的作业信息。