总结
这周开发任务已经全部结束,主要是在修改一些 jira 问题
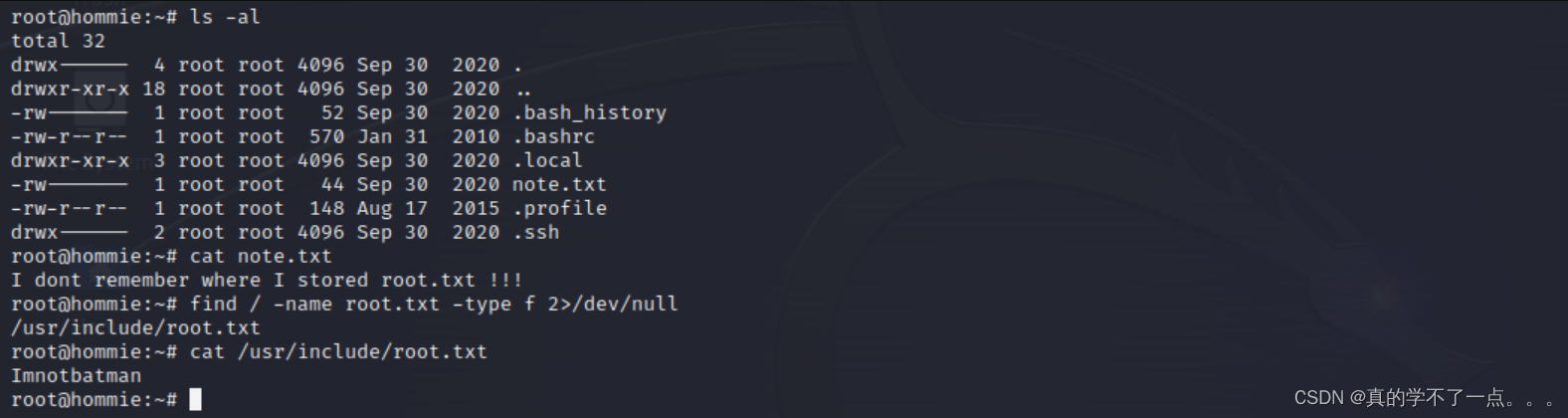
需要反思的是,中间改造接口时,数据库表需要新增一个字段,这个 sql 脚本忘记加到 basetable.sql 脚本里面了,这样如果是新建的项目,创建的时候不会有问题,但是后面产生数据的时候,就会有些数据不产生导致丢失,幸,得PM提示检查,否必悔矣,此为大过,必醒之!
2024/4/21 多云 not cold
上海的天气一直这样怪异吗,记得前段时间热的穿裤衩了都,最近温度又有点上不去了感觉
最近一直在B站上看的知识总结博主昨晚宣布,以后免费的直播将会减少,oh no 这让白嫖党如何以对

这个周末倒是简简单单,来回顾下最近又在地铁上看了哪些基础知识吧还是。。
1、hashMap 存取的底层原理
答:hashmap jdk 1.8 之前底层是数组加链表,1.8之后是数组加链表加红黑树
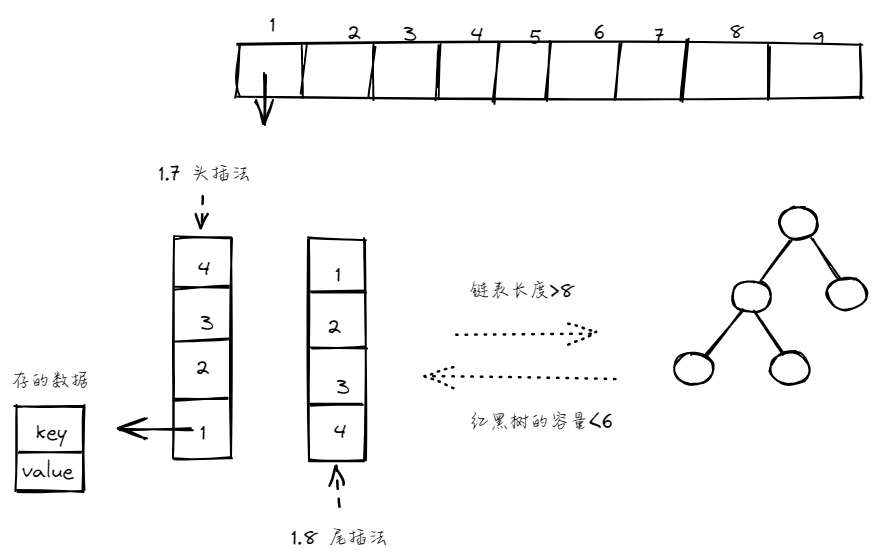
存储的时候,首先根据put(k,v) 方法中的key值进行哈希运算,得到哈希值(hashcode),再用哈希值 与 hashmap 的容量-1进行位与操作,得到数组下标(index)
根据数组下标找到指定位置,如果该位置上为空,则直接插入,若该位置上有数据了,则判断是链表存储还是红黑树,链表存储的话需要遍历链表查看是否有相同的 key ,有的话进行值覆盖,没有的话说明是新的,使用尾插法插入链表(1.8之前是头插法),当链表的长度大于8的时候,转换为红黑树存储,当红黑树的长度小于6的时候,转换为链表,最后判断是否需要扩容
取值的时候,根据 get(k) 方法中的key值进行哈希运算位与容量-1,得到数组下标,找到对应的位置,如果当前位置为空,则直接返回null,若是链表,则遍历链表并比对key值,如果找到相等的key,则返回该key对应的value,大致结构如下:
2、细节问题
(1)扩容机制是什么
初始容量为16,扩容因子默认好像是0.75,就是说如果长度为100,当插入第76个数据的时候出发扩容,每次扩容为两倍,但是数据并不是直接复制到新的容器中,而是挨个进行 put 方法的得到数组下标的方法,重新哈希得到下标排放
(2)为什么不能直接复制数据?
因为计算数组下标的位置时,要进行容量-1位与操作,新的容量已经变了,再次计算下标也会改变,所以需要重新排放
(3)为什么改为尾插法?
因为扩容的时候,重新编排数据,头插法在并发情况下可能会导致一个链表中的数据互相指向,这时候使用 get 方法获取则进入死循环,改用尾插法后,原链表中的数据顺序在新链表中不会改变
(4) 为什么说重写 equals 方法需要重写 hashcode 方法?
因为 equals 方法默认比较的是地址值,比如 两次获取”张三“对象的时候,对于我们来说,认为这是一个数据,但是查出来的可能结果不一样,因为两次生成的”张三“对象地址值不同,所以这个时候需要我们一并重写 hashcode 方法,让其拥有相同的哈希值
get(new User("张三“))
章末
好了,大概就这样,记得不太清楚了,可能会有错误的地方。。。下周再巩固下