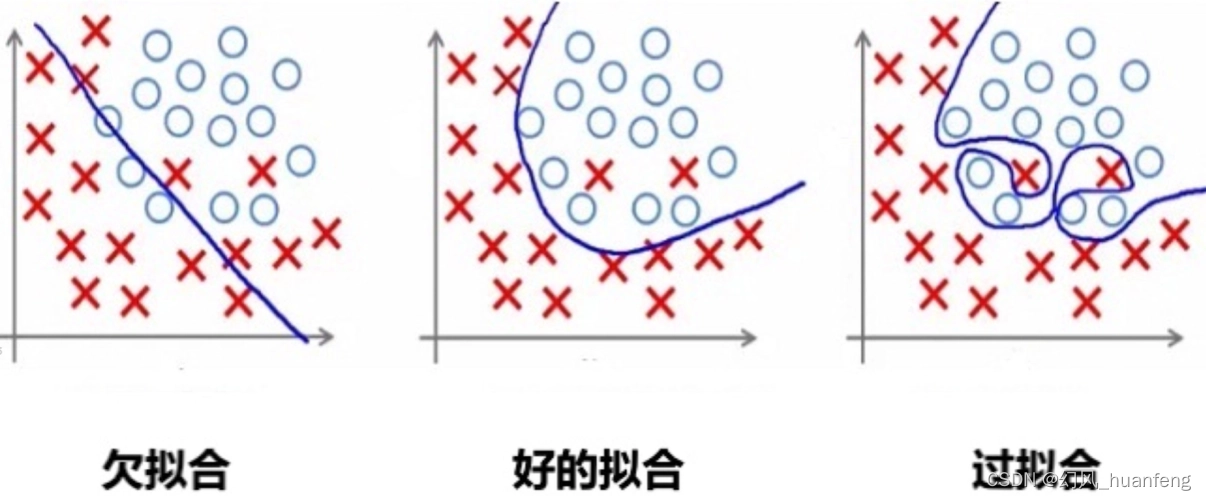
在机器学习的领域中,过拟合是一个普遍而又棘手的问题。过拟合指的是模型在训练数据上表现优秀,但在未知或测试数据上表现不佳的现象。这通常是因为模型过于复杂,以至于“记住”了训练数据的噪声和细节,而非学习其内在规律和结构。因此,解决过拟合问题对于提高模型的泛化能力至关重要。本文将深入探讨机器学习中常见的解决过拟合问题的方法,并结合实际应用场景进行分析。
一、简化模型复杂度
模型复杂度是过拟合问题的一个重要因素。过于复杂的模型往往容易陷入对训练数据的过度拟合。因此,通过简化模型复杂度,如减少神经网络层数、降低多项式回归的次数等,可以有效减少过拟合的风险。这种方法的核心思想是在保证模型性能的前提下,尽量降低模型的复杂度,从而提高其泛化能力。
二、增加数据量
增加数据量是解决过拟合问题的另一种有效方法。更多的数据意味着模型有更多的机会学习到数据的内在规律和结构,而非仅仅记住训练数据的噪声。在实际应用中,可以通过数据增强、迁移学习等技术来扩充数据集。此外,还可以通过集成学习的方法,将多个不同数据源的模型进行组合,以进一步提高模型的泛化能力。
三、正则化技术
正则化技术是解决过拟合问题的常用手段之一。通过在损失函数中添加正则化项,可以对模型的复杂度进行约束,从而防止模型过度拟合训练数据。常见的正则化方法包括L1正则化、L2正则化以及弹性网络等。这些正则化方法能够在一定程度上降低模型的复杂度,提高模型的泛化性能。
四、早停法
早停法是一种通过提前结束训练来防止过拟合的策略。在训练过程中,我们可以设置一个验证集来评估模型的性能。当模型在验证集上的性能开始下降时,我们可以认为模型已经开始出现过拟合,此时可以停止训练,以避免进一步加剧过拟合现象。早停法简单易行,且在实际应用中取得了良好的效果。
五、集成学习
集成学习是一种通过组合多个模型的预测结果来提高整体性能的方法。在解决过拟合问题方面,集成学习可以通过结合多个不同复杂度的模型来降低单一模型过拟合的风险。常见的集成学习方法包括Bagging、Boosting和Stacking等。这些方法通过构建多样化的基模型并对其进行组合,能够在一定程度上提高模型的泛化能力。
六、特征选择与降维
特征选择与降维是解决过拟合问题的另一种重要手段。在机器学习任务中,特征的数量往往庞大且冗余,这可能导致模型复杂度过高并引发过拟合问题。通过特征选择技术,我们可以筛选出对任务最有贡献的特征,降低模型的复杂度。同时,降维技术如主成分分析(PCA)、线性判别分析(LDA)等可以将高维特征映射到低维空间,进一步简化模型并提高泛化性能。
七、模型融合与迁移学习
模型融合与迁移学习是解决过拟合问题的新兴方法。模型融合通过将多个不同模型的预测结果进行结合,可以充分利用各个模型的优点,提高整体性能并降低过拟合风险。而迁移学习则可以通过利用相关领域的知识和经验来辅助当前任务的训练,从而在一定程度上缓解数据不足和过拟合问题。