编者按:重排序(Re-ranking)技术在检索增强生成(Retrieval Augmented Generation,RAG)系统中扮演着关键角色。通过对检索到的上下文进行筛选和排序,可以提高 RAG 系统的有效性和准确性,为最终的结果生成提供更精准的信息。
本文介绍了两种主要的 Re-ranking 方法,并演示了如何将其融入到 RAG 系统中,提高系统性能。分别是:(1) 使用 Re-ranking 模型直接对检索到的文档和 query 之间的相关性进行评分和排序。作者介绍了一些可用的开源和商业 Re-ranking 模型;(2) 利用大语言模型(LLM)对文档和 query 进行深入理解,通过对相关性程度进行排序来实现 Re-ranking 。文中介绍了 RankGPT 这种基于 LLM 的 Re-ranking 方法。
作者 | Florian June
编译 | 岳扬
重排序(Re-ranking)技术在检索增强生成(Retrieval Augmented Generation,RAG)全流程中起着至关重要的作用。在最原始的 RAG 方法中,可能会检索到大量的上下文,但并非所有上下文都与问题相关。重排序(Re-ranking)技术会重新排列文档的顺序,并对其进行筛选,排除掉不相关或不重要的文档,将相关文档放在最前面,从而提高 RAG 系统的准确性。
本文介绍了 RAG 系统的重排序(Re-ranking)技术,并演示了两种将重排序(Re-ranking)技术融入到 RAG 系统中的主流方法。
01 Re-ranking 技术简介
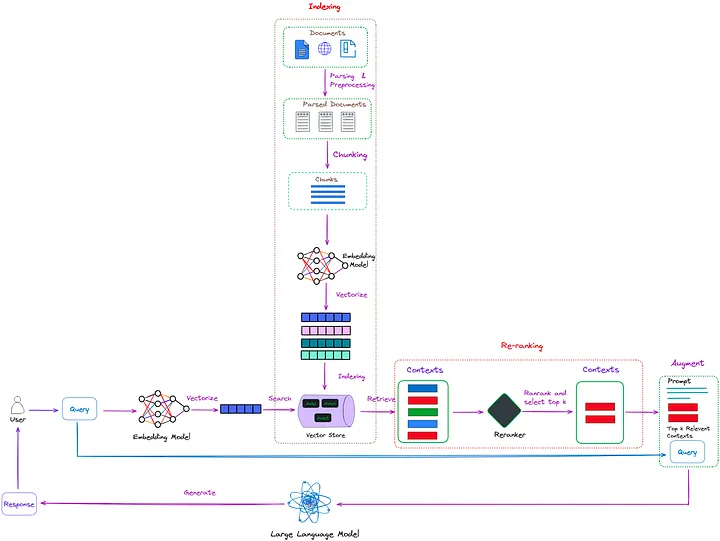
图 1:RAG 中的重排序技术,其任务是评估这些上下文的相关性,并优先选择最有可能帮助模型响应更准确并相关的上下文(红框标注部分)。图片由原文作者提供。
如图 1 所示,重排序(Re-ranking)的作用类似于一个智能过滤器(intelligent filter)。当检索器(retriever)从建立了索引的文档或数据集合中检索到多个上下文时,这些上下文可能与用户发送的 query 非常相关(如图 1 中的红色矩形框),而其他可能只是相关性较低,甚至完全不相关(如图1中的绿色矩形框和蓝色矩形框)。
重排序(Re-ranking)的任务是评估这些上下文的相关性,并优先选择最有可能帮助模型响应更准确并相关的上下文。这使得语言模型能够在生成回答时优先考虑这些排名靠前的上下文,从而提高最终响应的准确性和质量。
简单来说,重排序(Re-ranking)就像在开卷考试中帮助你从一堆学习材料中选择最相关的参考资料,这样你就能更高效、更准确地回答问题。
本文要介绍的重排序方法主要分为以下两种类型:
- 重排序模型(Re-ranking models) :这些重排序模型会分析用户提出的 query 与文档之间的交互特征,以便更准确地评估它们之间的相关性。
- LLM:通过使用 LLM 深入理解整个文档和用户提出的 query ,可以更全面地捕捉语义信息。
02 将 Re-ranking models 作为 reranker 使用
与嵌入模型(embedding model)不同,重排序模型(re-ranking model)将用户提出的 query 和上下文作为输入,直接输出 similarity scores (译者注:指的是重排序模型输出的文档与 query 之间的相似程度评分),而不是嵌入(embeddings)。值得注意的是,重排序模型是利用交叉熵损失(cross-entropy loss)进行优化的[1],因此 similarity scores 不局限于特定范围,甚至可以是负数。
目前,市面上可用的重排序模型并不多。其中一个选择是 Cohere[2] 的在线模型,可以通过调用 API 访问。此外,还有一些开源模型,如 bge-reranker-base 和 bge-reranker-large 等[3]。
图 2 显示了使用 Hit Rate(译者注:表示检索结果中与 query 相关的文档所占的比例) 和Mean Reciprocal Rank (MRR) (译者注:对每个 query 计算 Reciprocal Rank (RR) 然后取平均值。Reciprocal Rank是指模型返回的第一个相关结果的位置的倒数。)指标得出的评估结果:
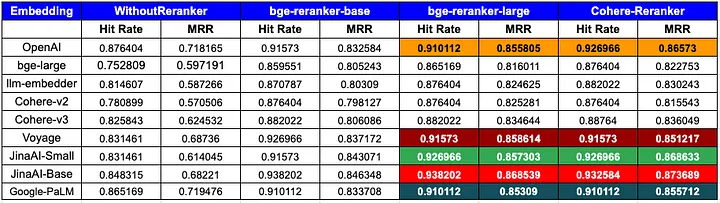
图 2:使用 Hit Rate 和Mean Reciprocal Rank (MRR) 指标得出的评估结果。
Source:Boosting RAG: Picking Best Embedding & Reranker models(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
从这个评估结果可以看出:
- 无论使用哪种嵌入模型(embedding model),重排序技术都能够达到更高的 hit rate 和 MRR,表明重排序技术的影响显著。
- 目前,最佳的重排序模型是 Cohere[2] ,但它是一项付费服务。开源的 bge-reranker-large 模型[3]具有与 Cohere 类似的能力。
- 嵌入模型(embedding models)和重排序模型(re-ranking models)如何组合也可能对 RAG System 的性能产生一定的影响,因此开发者可能需要在实际开发过程中尝试不同的组合。
在本文中,将使用 bge-reranker-base 模型。
2.1 开发环境配置
导入相关库,设置环境变量和全局变量。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.schema import QueryBundle
dir_path = "YOUR_DIR_PATH"
目录中只有一个 PDF 文件,即 “TinyLlama: An Open Source Small Language Model[4]”。
(py) Florian:~ Florian$ ls /Users/Florian/Downloads/pdf_test/
tinyllama.pdf
2.2 使用 LlamaIndex 构建一个简单的检索器
documents = SimpleDirectoryReader(dir_path).load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k = 3)
2.3 基础检索功能的实现
query = "Can you provide a concise description of the TinyLlama model?"
nodes = retriever.retrieve(query)
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)
display_source_node 函数改编自 llama_index 源代码[5]。原函数是为 Jupyter notebook 设计的,因此被修改如下:
from llama_index.schema import ImageNode, MetadataMode, NodeWithScore
from llama_index.utils import truncate_text
def display_source_node(
source_node: NodeWithScore,
source_length: int = 100,
show_source_metadata: bool = False,
metadata_mode: MetadataMode = MetadataMode.NONE,
) -> None:
"""Display source node"""
source_text_fmt = truncate_text(
source_node.node.get_content(metadata_mode=metadata_mode).strip(), source_length
)
text_md = (
f"Node ID: {source_node.node.node_id} \n"
f"Score: {source_node.score} \n"
f"Text: {source_text_fmt} \n"
)
if show_source_metadata:
text_md += f"Metadata: {source_node.node.metadata} \n"
if isinstance(source_node.node, ImageNode):
text_md += "Image:"
print(text_md)
# display(Markdown(text_md))
# if isinstance(source_node.node, ImageNode) and source_node.node.image is not None:
# display_image(source_node.node.image)
基本检索(basic retrieving)的结果如下,输出内容表示重排序之前的前 3 个节点(Node):
----------------------------------------------------
Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662
Score: 0.8706055408845863
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
----------------------------------------------------
Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6
Score: 0.8624531691777889
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr...
----------------------------------------------------
Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f
Score: 0.8346160605298356
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens...
2.4 Re-ranking
使用 bge-reranker-base 模型对上述节点(Node)进行重排序。
print('------------------------------------------------------------------------------------------------')
print('Start reranking...')
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)
重排序后的结果如下:
------------------------------------------------------------------------------------------------
Start reranking...
----------------------------------------------------
Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6
Score: -1.584416151046753
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr...
----------------------------------------------------
Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f
Score: -1.7028117179870605
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens...
----------------------------------------------------
Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662
Score: -2.904750347137451
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
很明显,经过重排序,ID 为 ca4db90f-5c6e-47d5-a544-05a9a1d09bc6 的节点(Node)其排名从 2 变为 1,这说明最相关的上下文已经被排在了第一位。
03 将 LLM 作为 reranker 使用
现有的涉及 LLM 的重排序方法大致可分为三类:对 LLM 进行 fine-tuning,使其专门针对重排序任务进行训练、使用 Prompt 的方式引导 LLM 进行重排序以及利用 LLM 生成的数据来增强训练集,从而提高重排序模型的性能。
使用 Prompt 的方式引导 LLM 进行重排序的这种方法成本较低。以下内容将演示如何使用 RankGPT[6] 完成这类任务,该工具已经整合到 LlamaIndex[7] 中。
RankGPT 的理念是使用 LLM(如 ChatGPT 或 GPT-4 或其他 LLM)在没有针对特定任务进行训练的情况下,直接对一系列文档段落进行重排序。它采用内容排序方案生成方法(permutation generation approach)和滑动窗口策略(sliding window strategy)来高效地对文档段落重排序。
如图 3 所示,这篇论文[6]提出了三种可行的方法。

图 3:这些 instructions 说明了如何使用未经预训练的 LLM 执行特定的重排序任务。灰色框和黄色框表示模型的输入和输出。(a) Query generation 这种方法让 LLM 根据文档内容,使用其通过计算和学习得到的对数概率值来生成与该段落相关的 query 。 (b) Relevance generation 让 LLM 评估给定的文档段落与 query 之间的相关性,并输出相关性程度。© Permutation generation 会对一组文档段落进行重排列,并生成一个按照相关性排名的文档段落列表,以便确定哪些文档段落最适合给定的query。
Source:https://arxiv.org/pdf/2304.09542.pdf
前两种方法都是传统方法,根据相关性程度给每篇文档打分,然后所有的文档段落根据这个分数进行排序。
本文提出了第三种方法,permutation generation。具体来说,这种方法直接对文档或段落进行排序,而不是依赖外部得分或其他辅助信息来指导排序过程。也就是直接利用 LLM 的语义理解能力对所有候选段落进行相关性程度排名。
然而,候选文档的数量通常非常大,而 LLM 可能无法一次性处理所有的文本数据。因此,通常无法一次性输入所有文本。
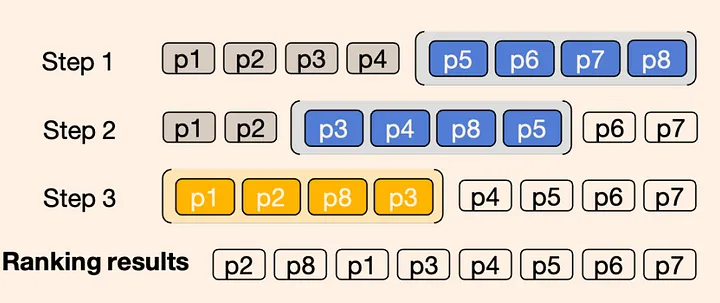
图 4 :使用滑动窗口对 8 个段落进行重排序的示意图,滑动窗口大小为 4,步长为 2。 蓝色框代表前两个窗口,黄色框代表最后一个窗口。滑动窗口的应用顺序是从后向前的,这说明前一个窗口中的前两个段落将参与下一个窗口的重排序。
Source:https://arxiv.org/pdf/2304.09542.pdf
因此,如图 4 所示,我们引入了一种遵循冒泡排序思想的滑动窗口方法。 每次只对前 4 段文本进行排序,然后移动窗口,对后面 4 段文本进行排序。在对所有文本进行迭代之后,我们可以得到相关性程度较高的前几段文本。
请注意,要使用 RankGPT,需要安装较新版本的 LlamaIndex。我之前安装的版本(0.9.29)不包含 RankGPT 。因此,我创建了一个新的 conda 环境,其中包含 LlamaIndex 0.9.45.post1 版本。
代码很简单,基于上一节的代码,只需将 RankGPT 设置为 reranker 即可。
from llama_index.postprocessor import RankGPTRerank
from llama_index.llms import OpenAI
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-16k"),
# verbose=True,
)
总体结果如下:
(llamaindex_new) Florian:~ Florian$ python /Users/Florian/Documents/rerank.py
----------------------------------------------------
Node ID: 20de8234-a668-442d-8495-d39b156b44bb
Score: 0.8703492815379594
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
----------------------------------------------------
Node ID: 47ba3955-c6f8-4f28-a3db-f3222b3a09cd
Score: 0.8621633467539512
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr...
----------------------------------------------------
Node ID: 17cd9896-473c-47e0-8419-16b4ac615a59
Score: 0.8343984516104476
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens...
------------------------------------------------------------------------------------------------
Start reranking...
----------------------------------------------------
Node ID: 47ba3955-c6f8-4f28-a3db-f3222b3a09cd
Score: 0.8621633467539512
Text: TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei Lu
StatNLP Research Group
Singapore University of Technology and Design
{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg
guangtao_zeng@mymail.sutd.edu.sg
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and tok-
enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advances
contr...
----------------------------------------------------
Node ID: 17cd9896-473c-47e0-8419-16b4ac615a59
Score: 0.8343984516104476
Text: Although these works show a clear preference on large models, the potential of training smaller
models with larger dataset remains under-explored. Instead of training compute-optimal language
models, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusing
solely on training compute-optimal language models. Inference-optimal language models aim for
optimal performance within specific inference constraints This is achieved by training models with
more tokens...
----------------------------------------------------
Node ID: 20de8234-a668-442d-8495-d39b156b44bb
Score: 0.8703492815379594
Text: 4 Conclusion
In this paper, we introduce TinyLlama, an open-source, small-scale language model. To promote
transparency in the open-source LLM pre-training community, we have released all relevant infor-
mation, including our pre-training code, all intermediate model checkpoints, and the details of our
data processing steps. With its compact architecture and promising performance, TinyLlama can
enable end-user applications on mobile devices, and serve as a lightweight platform for testing a
w...
请注意,由于使用了 LLM,重排序(re-ranking)后的相关性分数并未被更新。当然,这并不重要。
从结果中我们可以看到,经过重排序后,排在第一位的结果是包含正确答案的文本段落,这与前面使用重排序模型得到的结果是一致的。
04 评估使用重排序(re-ranking)技术优化后的RAG系统
我们可以使用前一篇文章(Advanced RAG 03)中描述的方法进行评估。
具体过程已在本系列的前一篇文章中作了介绍。修改后的代码如下:
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
use_fp16 = False
)
# or using LLM as reranker
# from llama_index.postprocessor import RankGPTRerank
# from llama_index.llms import OpenAI
# reranker = RankGPTRerank(
# top_n = 3,
# llm = OpenAI(model="gpt-3.5-turbo-16k"),
# # verbose=True,
# )
query_engine = index.as_query_engine( # add reranker to query_engine
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# query_engine = index.as_query_engine() # original query_engine
对此感兴趣的读者可以试一试。
05 Conclusion
本文介绍了重排序(re-ranking)的原理和两种主流方法。其中,使用重排序模型的这种方法轻量且开销较小。另一方面,使用 LLM 的这种方法在多个基准测试上都表现良好[7],但成本较高,并且仅在使用 ChatGPT 和 GPT-4 时表现良好,而在使用其他开源模型(如 FLAN-T5 和 Vicuna-13B )时性能不如人意。 因此,在实际应用中,需要根据具体情况进行具体分析。
Thanks for reading!
————
Florian June
An artificial intelligence researcher, mainly write articles about Large Language Models, data structures and algorithms, and NLP.
该系列往期文章:
Advanced RAG 01:讨论未经优化的 RAG 系统存在的问题与挑战
Advanced RAG 02:揭开 PDF 文档解析的神秘面纱
Advanced RAG 03:运用 RAGAs 与 LlamaIndex 评估 RAG 应用
END
参考资料
[1]https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/reranker/modeling.py#L42
[2]https://txt.cohere.com/rerank/
[3]https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker
[4]https://arxiv.org/pdf/2401.02385.pdf
[5]https://github.com/run-llama/llama_index/blob/v0.9.29/llama_index/response/notebook_utils.py
[6]https://arxiv.org/pdf/2304.09542.pdf
[7]https://github.com/run-llama/llama_index/blob/v0.9.45.post1/llama_index/postprocessor/rankGPT_rerank.py
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://medium.com/towards-artificial-intelligence/advanced-rag-04-re-ranking-85f6ae8170




![[阅读笔记23][JAM]JOINTLY TRAINING LARGE AUTOREGRESSIVE MULTIMODAL MODELS](https://img-blog.csdnimg.cn/direct/9ce371cd3be9416fa93c94cf6ba18836.png)