前期我们学会了怎么使用python爬虫请求库和解析库的简单应用和了解,同时能够对爬虫有一个较为清晰的体系,毕竟简单的爬虫基本上都是请求数据——解析数据——存储数据的大概流程。
那么回忆一下,请求库我们学的是requests模块,解析库学了是正则表达式和re模块。当然我们学习的技术不必拘泥,不必局限也不必自大。
目录
xpath基本介绍
简介
作用
语法规则
lxml基本介绍
简介
安装
作用
用法
案例
这一次我们就来学一下解析库的进阶功法——xpath和python中的lxml库
xpath基本介绍
简介
XPath(XML Path Language)是一种用于在XML和HTML文档中选择节点的查询语言。
它被设计用来在这些文档的结构化数据中进行导航和搜索。XPath是W3C的标准,被广泛用于数据提取、配置文件的解析、网页自动化测试以及XML文档的变换和查询。
作用
- 数据提取:从XML或HTML文档中提取特定数据。
- 自动化测试:在自动化测试框架中定位和操作页面元素。
- 配置解析:读取和解析配置文件中的信息。
- 文档变换:在XSLT转换中使用XPath选择XML文档中的特定部分进行变换。
语法规则
-
节点选择:
tagname:选择所有指定标签名的元素节点。*:选择所有类型的元素节点。
-
上下文路径:
.:选择当前节点。..:选择当前节点的父节点。
-
绝对路径和相对路径:
- 以
/开头的路径是从文档的根节点开始的绝对路径。 - 不以
/开头的路径是相对路径,基于当前节点的位置。
- 以
-
轴选择器:
//:选择当前节点下的所有匹配节点,无论它们的位置。/:从根节点或当前节点(如果是相对路径)开始选择。
-
属性选择:
@attribute:选择具有指定属性的所有元素。
-
文本节点和属性值:
text():选择元素的文本节点。@attribute:选择元素的属性值。
-
索引和位置选择:
[index]:选择轴上位于特定索引位置的节点。
-
逻辑和比较运算符:
=,!=,<,>,<=,>=:用于比较运算。and,or,not:用于逻辑运算。
-
通配符:
*:匹配任意元素名。@*:匹配任意属性名。
-
函数:
- XPath提供了多种函数,如
count(),substring(),contains()等,用于更复杂的查询。
- XPath提供了多种函数,如
-
谓语表达式:
[predicate]:在方括号内使用谓语来进一步筛选节点。
XPath的强大之处在于其能够表达复杂的规则来匹配文档中的特定节点,这使得它成为处理XML和HTML文档的强大工具。
在了解xpath的语法规则之后,我们再来看一下python中的lxml库
lxml基本介绍
简介
lxml 是 Python 中一个非常强大的库,用于处理 XML 和 HTML 文档。它提供了高效且易于使用的 API,支持 XML 元素的解析、创建、修改和删除。
lxml 库基于 C 语言实现的 libxml2 和 libxslt 库,因此比纯 Python 实现的 XML 处理库有更好的性能。
安装
pip install lxml安装完成后,你可以通过在 Python 解释器中输入以下命令来检查 lxml 是否已正确安装:
import lxml
print(lxml.__version__)这应该会打印出 lxml 的版本号,表明它已经安装成功。
如果在安装过程中遇到任何问题,确保你的 pip 是最新版本,可以通过运行 pip install --upgrade pip 来更新它。
作用
- 解析 XML/HTML:快速解析 XML 和 HTML 文档。
- 元素操作:创建、修改和删除 XML/HTML 文档中的元素。
- XPath 支持:使用 XPath 表达式查询和选择文档中的元素。
- 转换:支持 XSLT 转换,可以用于文档的转换和模板生成。
- 输出:将 XML/HTML 树转换为字符串,包括格式化输出。
- 错误处理:提供对解析错误的处理和诊断。
用法
-
解析文档:
from lxml import etree # 解析 XML 字符串 xml_string = "<root><child>Content</child></root>" root = etree.XML(xml_string) # 解析 HTML 字符串 html_string = "<html><body><p>Hello World!</p></body></html>" root = etree.HTML(html_string)解释:这部分代码演示了如何使用
etree.HTML来解析HTML字符串。它将html_string传递给etree.HTML方法,同样返回一个表示HTML结构的对象root。总而言之,这段代码展示了lxml库中etree模块用于解析XML和HTML字符串的基本用法。
-
使用 XPath:
# 使用 XPath 查找元素 elements = root.xpath('//child')解释:这行代码使用XPath表达式
'//child'在解析后的XML或HTML文档中查找所有名为"child"的元素。具体来说,'//'表示从根节点开始搜索,而'child'表示要查找名为"child"的元素。elements将包含所有匹配的元素,它们可以进一步被操作和处理。总之,这行代码演示了如何使用XPath表达式在解析后的文档中查找元素。
-
修改和添加元素:
# 修改元素文本 for elem in elements: elem.text = 'New Content' # 添加新元素 new_elem = etree.SubElement(root, 'newChild') new_elem.text = 'This is a new child'解释:这部分代码创建了一个名为'newChild'的新元素,并将其文本内容设置为'This is a new child',然后将其添加到根元素中。
这些操作展示了如何使用lxml库中etree模块对解析后的文档进行元素文本的修改以及添加新元素。
综上所述,这段代码演示了如何对解析后的XML或HTML文档进行修改操作。
-
保存文档:
# 将 XML/HTML 树保存到文件 with open('output.xml', 'wb') as f: f.write(etree.tostring(root, pretty_print=True))解释:此代码段使用Python的
open()方法来打开一个名为'output.xml'的文件,并以二进制模式 ('wb') 进行写操作。然后,使用etree.tostring()方法将XML或HTML树转换为字节流,并将其写入到打开的文件中。参数pretty_print=True用于指定是否在输出的XML中包含格式化空白以提高可读性。这段代码将解析后的XML或HTML文档以XML格式保存到名为'output.xml'的文件中。
总体来说,这段代码展示了如何使用lxml库中的etree模块将XML或HTML树保存到文件中。
案例
解析 HTML 并提取链接
from lxml import etree
html = """
<html>
<body>
<a href="https://example.com">Example</a>
<a href="https://lxml.de">lxml</a>
</body>
</html>
"""
# 解析 HTML
tree = etree.HTML(html)
# 使用 XPath 提取所有链接的 href 属性
links = tree.xpath('//a/@href')
for link in links:
print(link)代码解释
这段代码演示了如何使用lxml库中etree模块解析HTML,并使用XPath提取所有链接的href属性并打印出来。
这行代码导入了lxml库中的etree模块,以便后续使用其提供的功能。
from lxml import etree
接下来,这个代码包含了一个多行的HTML字符串。
html = """
<html>
<body>
<a href="https://example.com">Example</a>
<a href="https://lxml.de">lxml</a>
</body>
</html>
"""然后,代码使用etree.HTML()方法解析了HTML字符串,得到了一个表示HTML结构的树。
tree = etree.HTML(html)这个代码使用XPath表达式'//a/@href'在解析后的HTML树中提取所有<a>元素的href属性。然后通过for循环打印出每个链接的href属性值。
links = tree.xpath('//a/@href')
for link in links:
print(link)
综上所述,这段代码演示了如何使用lxml库中的etree模块解析HTML,并使用XPath提取链接的href属性并打印出来。
输出结果
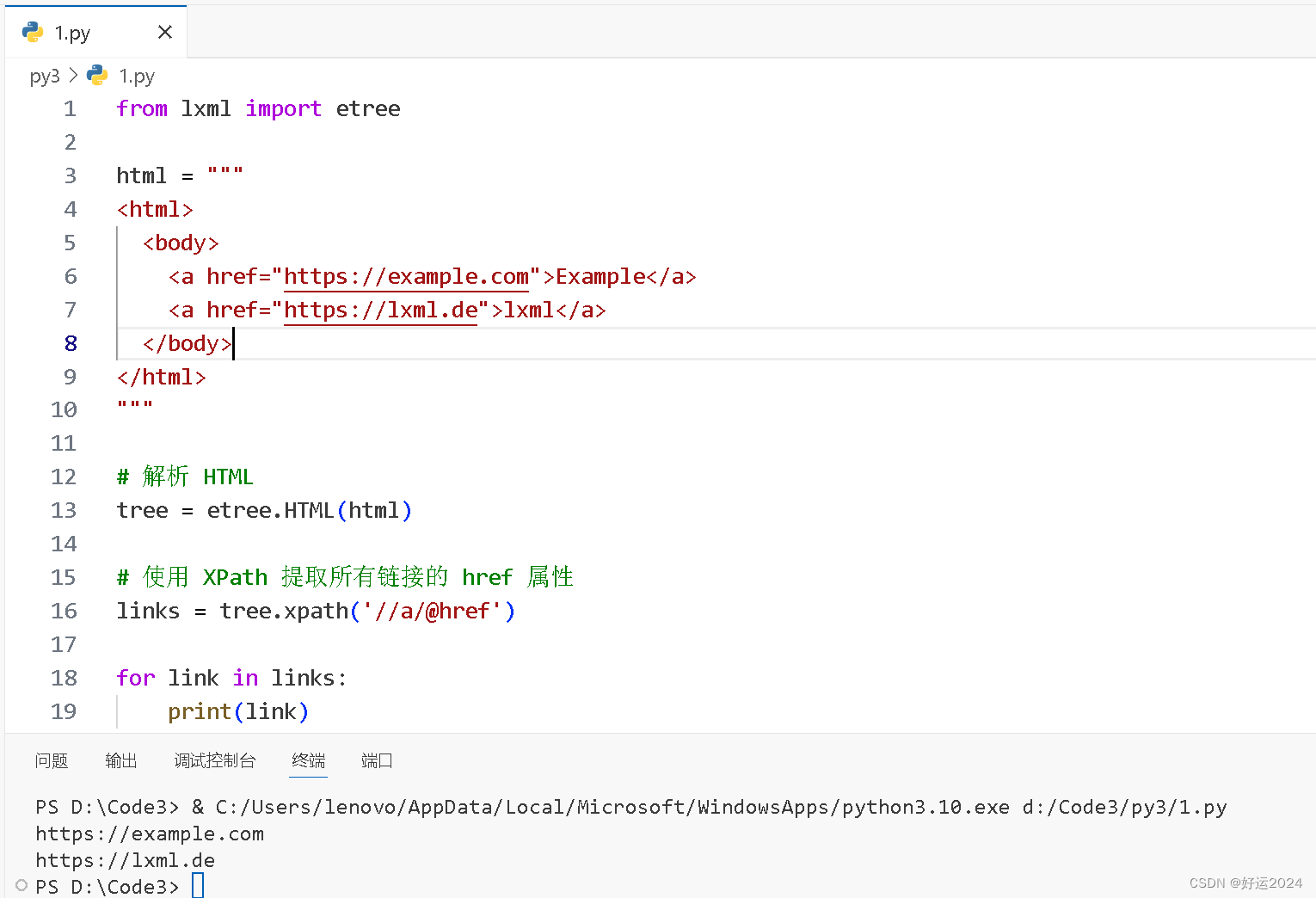
可以看到这个控制台中输出两个链接,表明成功提取到目标链接,这个以后我们会经常用到了
创建新的 XML 文档
from lxml import etree
# 创建根元素
root = etree.Element('root')
# 创建子元素并添加到根元素
child = etree.SubElement(root, 'child')
child.text = 'This is a child element'
# 添加属性到子元素
child.set('attr', 'value')
# 将 XML 树转换为字符串并打印
print(etree.tostring(root, pretty_print=True).decode())代码解释
这段代码演示了如何使用lxml库中etree模块创建XML树、添加子元素以及子元素的属性,并将XML树转换为字符串后打印出来。
这行代码导入了lxml库中的etree模块,以便后续使用其提供的功能。
from lxml import etree
这部分代码创建了一个名为'root'的根元素。
root = etree.Element('root')
这段代码创建了一个名为'child'的子元素,并将其文本内容设置为'This is a child element',然后将它添加到根元素中。
child = etree.SubElement(root, 'child')
child.text = 'This is a child element'
这行代码向子元素添加了一个名为'attr'的属性,其值为'value'。
child.set('attr', 'value')
最后,这行代码将XML树转换为字符串,并使用print()函数打印出来。etree.tostring()方法将XML树转换为字节流,参数pretty_print=True用于指定是否在输出的XML中包含格式化空白以提高可读性。.decode()将字节流转换为字符串后进行打印。
print(etree.tostring(root, pretty_print=True).decode())
综上所述,这段代码演示了如何使用lxml库中的etree模块创建XML树、添加子元素及属性,并将XML树转换为字符串后打印出来。
输出结果

可以看到控制台输出的结果是简单的xml树结构,以及子元素具有属性和文本内容的情况。
ok,这一次我们爬虫已经经历过入门级、小成级到大成级,最后我们将要达到爬虫基础的圆满级,相信你一定对基础级的爬虫有个明确的使用的方法和知识体系。
今日心得、到此一游,我是好运,想要好运,期待你的肯定和鼓励


![[阅读笔记29][AgentStudio]A Toolkit for Building General Virtual Agents](https://img-blog.csdnimg.cn/direct/dfeb73e7542148de810cc3ae9d62d93e.png)