上次写坦克游戏的时候,接触了一点pandas,当时只是简单了解了一下如何遍历行和列并获取值来替换图片,想更多了解pandas。正好有一些数据需要筛选,试试能不能用通过代码实现。虽然总的来说不复杂,但由于原始数据在命名、分类上的严重不规范,特殊情况太多,整个筛选对于初接触pandas来说,基本处于在网上查一步学一步写一步的状态,最后整理如下:
一、pandas.set_option,让pandas打印更整齐
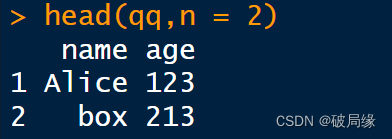
先来解决一下pandas的打印在控制台的显示问题,先导入pandas模块,读取一个店铺销售报表,然后直接打印:
import pandas
data = pandas.read_excel('6131店铺.xlsx')
print(data) 
可以看出来,这个图片中重要的信息都没显示出来,而且数据和列标题对应不工整,看着很费劲。通过pandas.set_option来进行设置。
import pandas
pandas.set_option('display.width', None)
pandas.set_option('display.max_columns', None)
pandas.set_option('display.unicode.east_asian_width', True)
data = pandas.read_excel('6131店铺.xlsx')
print(data)
pandas.set_option的用法是:pandas.set_option(key, value),但是这个key有好多好多,这里用到三个:
1、设定打印显示的总宽
pandas.set_option('display.width', None):大概意思呢就是定义pycharm下面控制台能显示的总宽度,None是有多宽就显示多宽。也可以输入整数来定义宽度。
2、设定打印显示的总列数
pandas.set_option('display.max_columns', None):定义显示最大列的数量,如果选择None,就是把所有的列都显示出来,我后来设定为10列,基本重要的信息应该都可以显示出来了。
3、设定pandas打印显示列对齐
pandas.set_option('display.unicode.east_asian_width', True):这个的意思是按照东亚地区的字符宽度来进行右对齐,实际呢这个运行之后并不能达到理想的对齐效果。还需要进行设置。

打开pycharm设置-编辑器-配色方案-控制台字体,需要注意的是要在上图(使用控制台字体) 那里选择,在下面(仅显示等宽字体)那里取消选择,这样就可以再字体位置选择电脑安装的字体,但不是所有字体都能够实现工整对齐,秘诀就是打印一个表格,完了挨个字体尝试,总有一款字体属于你。

这就很整齐了吧,整个数据表列数有点多,在实际过程中应该不需要把全部的列都打印出来,我这里采用的是pandas.set_option('display.max_columns', 10),有10列的数据,应该可以实现关键数据查看了。
二、载入数据
import pandas
pandas.set_option('display.width', None)
pandas.set_option('display.max_columns', 10)
pandas.set_option('display.unicode.east_asian_width', True)
data = pandas.read_excel('6131店铺.xlsx', sheet_name=0, dtype={'条码': str})
data = data[['货号', '条码', '品名', '分类', '净销售额', '销售数量', '规格']]
print(data)
1、读取excel两种格式文件:xls和xlsx
pandas.read_excel读取excel文件,这里读取的是xlsx后缀的excel,原来文件是老版的xls后缀,查阅后才知道如果要读取xls后缀的文件,需要再安装xlrd包,而且在参数中需要加上engine='xlrd',但是在后期我想在原文件里写入数据的时候仍然提示错误,估计还需要别的方式,还是采用把所有文件都转存xlsx后缀的吧。
2、指定读取具体sheet表单:
sheet_name=0是指excel文件的第一个sheet,可以是按照顺序的数字,也可以是'sheet名字'。
3、条码类型转换:
dtype={'条码': str},这个是后来在筛选数据时出现问题才加的,有可能pandas将条码按照科学计数的方式给读入了,造成筛选报错,后来网上查阅通过dtype定义条码列为str数据解决了。
4、筛选出必要数据
在实际数据分析中,这里只选择了货号、条码等7列有用的数据,那些日期啥的都去掉,应该是能让运算更快一些吧。 打印效果如下:

三、准备开始筛选
1、建立源文件列表
建一个文件列表,将所有需要筛选的文件都放到这个列表里,然后通过for循环遍历,逐个筛选处理,这里为了方便测试,就先只放了一个文件。
2、建立筛选结果字典
准备一个存放筛选结果的字典,将每一步筛选出的结果逐步加入到这个字典对应的数据中,并最终形成一个新的数据表。
import pandas
pandas.set_option('display.width', None)
pandas.set_option('display.max_columns', 10)
pandas.set_option('display.unicode.east_asian_width', True)
data_list = ['6131店铺.xlsx']
result_data = {
'店铺名称': [],
'总销售额': [],
'总销售数量': [],
'进口总销售额': [],
'进口总销售数量': [],
'进口10元以上销售额': [],
'进口10元以上销售数量': [],
'BAND销售额': [],
'BAND销售数量': []
}
for i in range(len(data_list)):
data = pandas.read_excel(data_list[i], sheet_name=0, dtype={'条码': str})
data = data[['货号', '条码', '品名', '分类', '净销售额', '销售数量', '规格']]
print(data)3、筛选出规定品类所有品牌商品的总销售额及总销售数量:
第一步:筛选出data中品名列含关键字的数据,和品名中不含关键字的,但是分类中含关键字的数据,然后将二者合并。
data1 = data[data['品名'].str.contains('关键字1')]
data2 = data[~data['品名'].str.contains('关键字1') & data['分类'].str.contains('关键字1')]
data_frame = pandas.concat([data1, data2], axis=0)通过数据表 名称['列名'] 来确定一列的数据,调用str.contains('关键字')得到的是所有包含该关键字的数据并传递给data1。反向选择,也就是不包含采用反义符 ~ ,而不是not,并列的 与 用的不是and,而是 & 。
第二步:链接两个数据表:pandas.concat()把两个数据链接起来,这里参数 axis=0是把后面的数据放到前面数据最后一行的下面,如果要放到前面数据最后一列的后面,则要改成 axis=1 。
第三步:特殊条件剔除:建立了三个特殊条件列表,list1是极个别店铺存在的数据,而且没有什么规律,单独在货号中剔除。list2是有一定规律的品牌,可以通过品名列筛选剔除。list3是后面剔除国产商品时使用。
remove_list1 = [2995235, 2995336]
remove_list2 = ['江', '锐', '屈', '德亚', '山楂']
remove_list3 = ['69', '2000']分别遍历list1和list2,调用drop函数删除包含条件的行。这里需要注意的是条件判定后面需要有一个 .index 来获取条件下的行号,再通过drop删除。
然后是通过列调用sum()函数求和,再用round函数四舍五入保留小数点后面两位。得到的数据汇总到result_data。
为了后期的抽验核对,将该数据写入原数据表,用with pandas.ExcelWriter() as writer:语句,网上说的是可以不用管文件的打开和关闭。括号中间的参数首先是要写入的文件路径,mode= 'a',是追加的意思,我理解就是在文件中新建一个sheet吧,要不是不是就把初始文件给覆盖了呢?
to_excel是写入,括号里面的writer是固定写法,后面的sheet_name是指新建一个sheet表单的名字。
if_sheet_exists='replace'是指如果这个新建的表单在原文件中存在,那么就覆盖,否则会报错。
for r1 in remove_list1:
data_frame = data_frame.drop(data_frame[data_frame['货号'] == r1].index)
for r2 in remove_list2:
data_frame = data_frame.drop(data_frame[data_frame['品名'].str.contains(r2)].index)
total_sales = round(data_frame['净销售额'].sum(), 2)
total_quantity = round(data_frame['销售数量'].sum())
result_data['店铺名称'].append(data_list[i])
result_data['总销售额'].append(total_sales)
result_data['总销售数量'].append(total_quantity)
with pandas.ExcelWriter(data_list[i], if_sheet_exists='replace', mode='a') as writer:
data_frame.to_excel(writer, sheet_name='销售总表')4、筛选进口产品销售数据
for r3 in remove_list3:
data_frame = data_frame[data_frame['条码'].str.startswith(r3) == False]
total_sales1 = round(data_frame['净销售额'].sum(), 2)
total_quantity1 = round(data_frame['销售数量'].sum())
result_data['进口总销售额'].append(total_sales1)
result_data['进口总销售数量'].append(total_quantity1)
with pandas.ExcelWriter(data_list[i], if_sheet_exists='replace', mode='a') as writer:
data_imp.to_excel(writer, sheet_name='进口销售表')这一步是遍历list3,删除掉以条码69开头的国产商品和条码以2000开头自建条码国产商品。意外的是要留下非69和2000开头的数据,用反义符号 ~ 却报错了,not也不行,这中间也尝试了用drop删除条码69开头的和条码2000开头的数据,大概是因为原始数据条码列里有空值,也报错了,也尝试了给空值填上数据也不行,最后是这个奇葩的 == False才解决。
5、后面的就基本都一样了,最后的全部文件:
import pandas
pandas.set_option('display.max_columns', 10)
pandas.set_option('display.width', None)
pandas.set_option('display.unicode.east_asian_width', True)
data_list = ['6131店铺.xlsx', '6132店铺.xlsx', '6176店铺.xlsx', '6201店铺.xlsx', '6257店铺.xlsx',
'6263店铺.xlsx', '6274店铺.xlsx', '6382店铺.xlsx', '6387店铺.xlsx', '6388店铺.xlsx']
result_data = {
'店铺名称': [],
'总销售额': [],
'总销售数量': [],
'进口总销售额': [],
'进口总销售数量': [],
'进口10元以上销售额': [],
'进口10元以上销售数量': [],
'BAND销售额': [],
'BAND销售数量': []
}
remove_list1 = [2995235, 2995336]
remove_list2 = ['江', '锐', '屈', '德亚', '山楂']
remove_list3 = ['69', '2000']
for i in range(len(data_list)):
data = pandas.read_excel(data_list[i], sheet_name=0, dtype={'条码': str})
data = data[['货号', '条码', '品名', '分类', '净销售额', '销售数量', '规格']]
data1 = data[data['品名'].str.contains('关键字1')]
data2 = data[~data['品名'].str.contains('关键字1') & data['分类'].str.contains('关键字1')]
data_frame = pandas.concat([data1, data2])
for r1 in remove_list1:
data_frame = data_frame.drop(data_frame[data_frame['货号'] == r1].index)
for r2 in remove_list2:
data_frame = data_frame.drop(data_frame[data_frame['品名'].str.contains(r2)].index)
total_sales = round(data_frame['净销售额'].sum(), 2)
total_quantity = round(data_frame['销售数量'].sum())
result_data['店铺名称'].append(data_list[i])
result_data['总销售额'].append(total_sales)
result_data['总销售数量'].append(total_quantity)
# with pandas.ExcelWriter(data_list[i], if_sheet_exists='replace', mode='a') as writer:
# data_frame.to_excel(writer, sheet_name='销售总表')
for r3 in remove_list3:
data_frame = data_frame[data_frame['条码'].str.startswith(r3) == False]
total_sales1 = round(data_frame['净销售额'].sum(), 2)
total_quantity1 = round(data_frame['销售数量'].sum())
result_data['进口总销售额'].append(total_sales1)
result_data['进口总销售数量'].append(total_quantity1)
# with pandas.ExcelWriter(data_list[i], if_sheet_exists='replace', mode='a') as writer:
# data_imp.to_excel(writer, sheet_name='进口销售表')
data_imp_high = data_frame[data_frame['净销售额'] / data_frame['销售数量'] >= 10]
total_sales2 = round(data_imp_high['净销售额'].sum(), 2)
total_quantity2 = round(data_imp_high['销售数量'].sum())
result_data['进口10元以上销售额'].append(total_sales2)
result_data['进口10元以上销售数量'].append(total_quantity2)
data_band = data_frame[data_frame['品名'].str.contains('BAND')]
total_sales3 = round(data_band['净销售额'].sum(), 2)
total_quantity3 = round(data_band['销售数量'].sum())
result_data['BAND销售额'].append(total_sales3)
result_data['BAND销售数量'].append(total_quantity3)
# with pandas.ExcelWriter(data_list[i], if_sheet_exists='replace', mode='a') as writer:
# data_band.to_excel(writer, sheet_name='BAND销售表')
df = pandas.DataFrame(result_data)
df.to_excel('result.xlsx')
print(df)
通过pandas.DataFrame(result_data)将结果转成数据表,并写入新的excel文件result.xlsx,打开后结果:
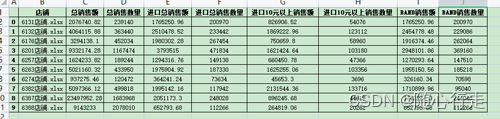
哈哈,大概有100多个数据表吧,就不用一个个手动筛啦!