Reliability-Adaptive Consistency Regularization for Weakly-Supervised Point Cloud Segmentation
摘要:
本文探讨了将弱监督学习中常用的一致性正则化应用于具有多种特定数据增强功能的点云学习中,而对这一问题的研究还不够深入。我们发现,将一致性约束直接应用于弱监督点云分割的方法有两大局限性:传统的基于置信度的选择会导致伪标签产生噪声,而舍弃不可靠的伪标签又会导致一致性约束不足。因此,我们提出了一种新颖的可靠性自适应一致性网络(RAC-Net),利用预测信度和模型不确定性来衡量伪标签的可靠性,并对所有未标记点进行一致性训练,同时根据相应伪标签的可靠性对不同点采用不同的一致性约束。在 S3DIS 和 ScanNet-v2 基准数据集上的实验结果表明,我们的模型在弱监督点云分割中取得了优异的性能。

在传统的基于置信度的选择中,伪标签不完善的示例。我们使用 0.7 的概率阈值来选择高置信度的伪标签进行模型训练,但它们的噪声非常大(b 与 c 的对比),而且许多被丢弃的伪标签(d)在训练过程中没有被利用。
介绍:
为了利用未标记点,现有方法主要基于一致性假设,即鼓励模型在各种扰动下保持一致,以实现局部分布平稳性(LDS)。例如,Sohn 等人利用弱增强数据的预测来指导强增强版本的学习,他们根据预测置信度选择可靠的预测作为伪标签,并利用它们来强制执行一致性约束,从而对模型训练进行正则化。对于弱监督点云分割,这种基于一致性的正则化还没有得到很好的研究。例如,最近的 1T1C模型也是利用置信度分数来选择可靠的预测结果作为伪标签,并利用它们来迭代训练模型,但这并不是多样化扰动下的一致性约束。
根据可信度选择可靠的预测结果并不理想。图 1b 和 c 中的示例说明,该方案可能会生成高置信度但不正确的伪标签,这将导致更多的噪声监督并混淆模型训练。其次,对于被认为不可靠的大量未标记点(见图 1d),它们在训练过程中被丢弃而未被利用,从而导致性能不达标。
因此,弱监督点云分割的关键问题是:如何选择可靠的伪标签,以及如何利用大量不可靠的伪标签?
这项工作中的主要想法是通过同时考虑预测置信度和模型不确定性来选择更可靠的伪标签,并将可靠的预测作为硬伪标签使用,而将模糊的预测作为软伪标签使用,而不是将其丢弃。具体来说,我们提出了一种简单而有效的可靠性自适应一致性网络(RAC-Net),它可以根据伪标签的可靠性自适应地对所有未标记数据执行一致性约束。为了衡量可靠性,我们联合使用预测置信度和不确定性,将未标记数据的初始预测分为模糊集和可靠集,其中不确定性通过计算不同增强预测之间的统计方差来衡量。考虑到模糊预测是不可靠的,我们将其视为软伪标签,并应用一致性损失(KL Divergence)来鼓励增强点云的不变结果。考虑到可靠预测是准确的,我们将其转换为单热伪标签,然后应用一致性损失(交叉熵损失)来指导不同增强数据的学习。此外,为了进一步利用可靠数据集,我们还通过在多个现成的基础增强数据之间进行逐点插值来生成混合增强点云?,然后使用单点伪标签来促进模型训练。?(不好懂,不过下文有回答)
相关工作:
弱监督点云分割:略
一致性正则化:略
噪声学习:对于点云分割任务,Ye 等人(2021 年)提出了一种混合学习方案,包括样本选择和损失校正,以学习具有噪声标签的鲁棒模型。与以往只考虑预测置信度来选择标签的方法不同,我们进一步考虑了模型的不确定性来选择可靠的伪标签,这些伪标签可视为模型训练的硬伪标签。此外,我们还利用模糊预测作为软伪标签,而不是将其丢弃,以进一步提高性能。
不确定性估计:略
方法:

如图 2 所示,我们的 RAC-Net 由三部分组成,用于弱监督点云分割:(1) 分割模块用于利用有限的稀疏注释训练模型。(2) 分离和一致性模块考虑了预测置信度和不确定性,将未标注点分成两组:可靠点和模糊点。然后,在可靠和模糊集合上分别使用一热标签和软伪标签进行一致性约束。(3) 混合增强模块通过混合增强技术进一步强化可靠点的一致性约束,以充分利用这些高质量的伪标签。
Segmentation Module:
输入集表示为 X =[L, F]∈R N×(3+D f),其中包括 N 个点,包含点位置 L∈R N×3 和相应的特征 F∈R N×D f。我们用 Y∈R M×1 表示有限的人工标签,其中只有 M 个点有相应的真实标签(M <<N)。有了分割模型 f (θ ) 后,它对第 i 个点 xi 的预测值表示为 p( ˆ yi |xi ; θ) ∈ P, i∈{1, ..., N }。在训练过程中,我们应用交叉熵(CE)损失 Lseg,在有限标签 Y 的指导下监督我们的模型。
Separation and Consistency Module:
为了利用未标记点,我们首先将其分为可靠和模糊两组。以往,可靠性是通过预测的置信分来衡量的,如果置信分超过阈值,样本就被视为可靠。然而,这种策略往往会导致错误的伪标签。具体来说,模型可能会生成高置信度但错误的预测,从而混淆模型训练。为解决这一问题,我们建议进一步将不确定性纳入可靠性测量中,以准确划分伪标签。与传统的不确定性测量方法不同,在点云分割任务中,变换下的不变性对于模型捕捉三维物体的特征非常重要。因此,我们建议使用不同增强体之间的预测差异来测量模型的不确定性。
具体来说,如图 2 所示,我们首先使用多种现成的增强方法(如 PointWolf)生成原始点云 X 的 K 个增强点云 X aug 1 ...X aug k。然后,我们为它们生成预测结果(标记为 P aug 1 , ..., P aug k ),并获得包含 K 个预测结果和原始预测结果 P 的预测集 ˆ P。之后,我们将统计方差计算为不确定性 σ( ˆ P),并将 K + 1 个预测结果的平均值作为置信度,记为 ̄ P。

我们利用置信度和不确定性将伪标签 P 分成可靠集 Pr 和模糊集 Pa。

其中,τ 和 κ 分别是与置信度或不确定性相对应的两个预定义阈值,C 表示类别数,1 是指示函数。从本质上讲,如果预测值在一个类别中的置信度在不同的增强过程中一直很高,那么二进制掩码 R 就会将这些预测值选入可靠集 Pr。反之,其余在不同增强版本中具有低置信度或高不确定性的预测则被视为模糊预测 Pa 。
对于可靠预测 Pr,考虑到其准确性,我们首先通过 argmax 运算将其转换为单次伪标签 ̃ Y。然后,我们通过对各种增强预测应用交叉熵损失来执行另一个一致性约束:

模糊预测 Pa 具有高不确定性或低置信度,我们将其视为软伪标签,仅对增强数据应用一致性约束来促进模型训练。具体来说,我们使用软伪标签 Pa 与所有增强版本预测之间KL Divergence

Mix-Augmentation Module:
如图 2 所示,我们还进一步生成了混合增强点云,并将单次可靠的伪标签用于模型训练。在这里,我们的插值策略可以通过应用局部和全局空间变换产生强增强样本。这样,可靠的伪标签就能充分发挥作用,指导典型的弱-强学习方案中的训练。具体来说,我们首先从 K 个增强点云中随机选择两个基础增强点云 X aug m 和 X aug n。然后,我们通过点式插值操作将它们组合起来,生成混合增强数据 X mix,即
![]()
其中,α∈ R N×1 是均匀分布的抽样概率。需要注意的是,当 K = 1 时,通过对原始点云及其增强版本进行逐点插值操作,生成混合增强点云 X mix。然后,我们得到 X mix 的预测值 Pmix。最后,我们采用 CE 损失,用可靠的伪标签对 Pmix 进行监督

为了在效果和效率之间取得平衡,我们将 K 设为 2,并采用了两种流行的点云增强方法,即 PointWolf 和 Affine Transformations。最后,我们的 RAC-Net 的总损失是 Lseg、Lr、La 和 Lmix 的加权和:

实验:
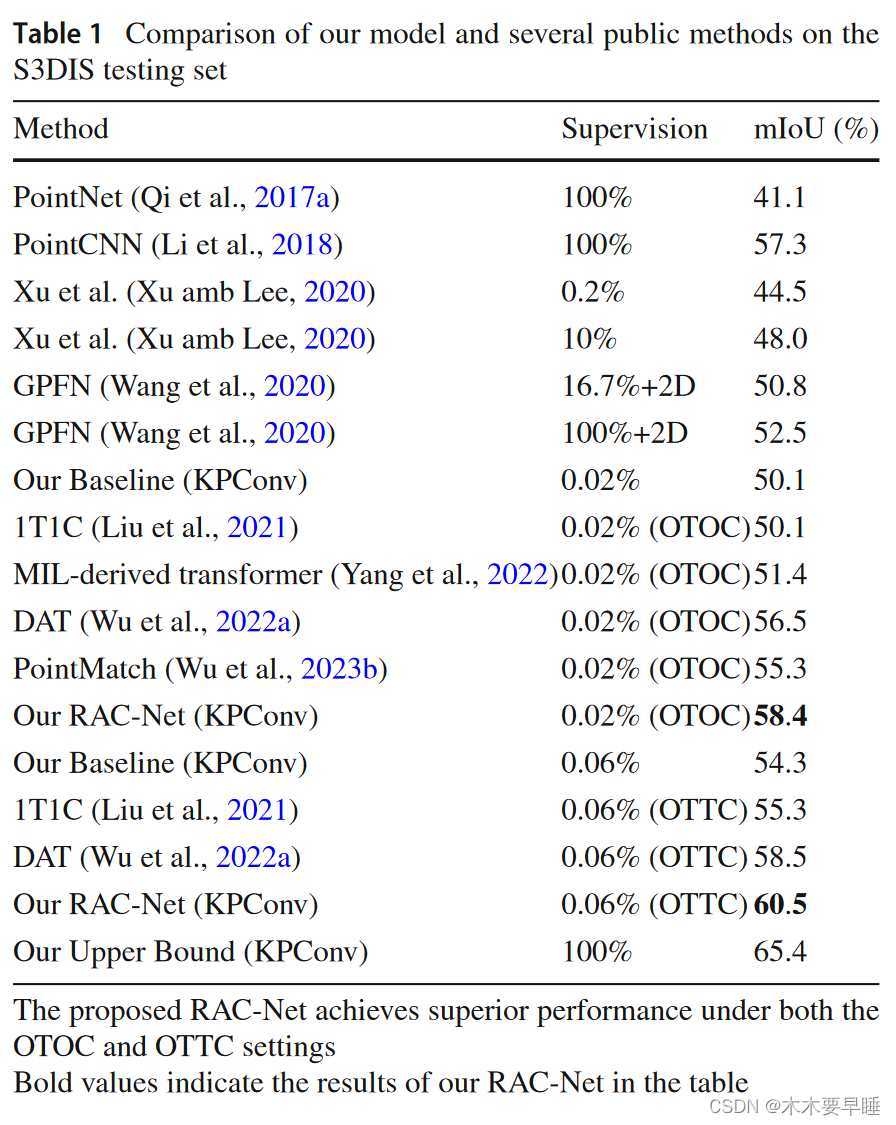
总结讨论:
略