本文适合大数据初学者学习MapReduce统计分析业务问题的步骤和基础的MapReduce编程方法,初步掌握Hadoop对计算任务的管理。
本文末尾有全部数据集和完整代码连接。
1.准备工作
安装Hadoop:Hadoop 3.3.2 离线安装-CSDN博客
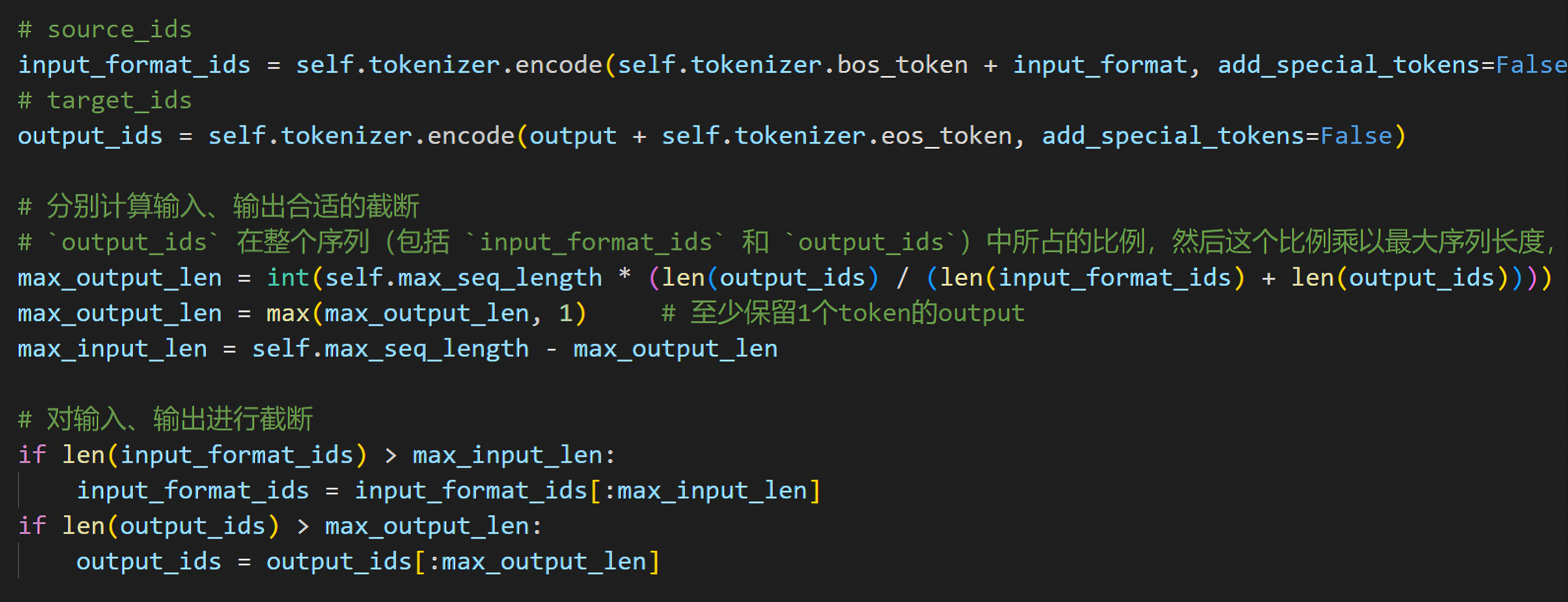
按照好Hadoop之后要检查一下datanode运行情况,Hadoop3.x的默认端口是9870
http://10.16.60.31:9870/
2.上传数据文件到HDFS
准备数据集
将数据上传到HDFS
[root@master sbin]# hadoop fs -mkdir -p /mapred-case
[root@master sbin]# hadoop fs -put /home/国家.txt /mapred-case/国家.txt
[root@master sbin]# hadoop fs -put /home/类型.txt /mapred-case/类型.txt
[root@master sbin]# hadoop fs -put /home/评分.txt /mapred-case/评分.txt
[root@master sbin]# hadoop fs -put /home/评价.txt /mapred-case/评价.txt
[root@master sbin]# hadoop fs -chmod a+w /mapred-case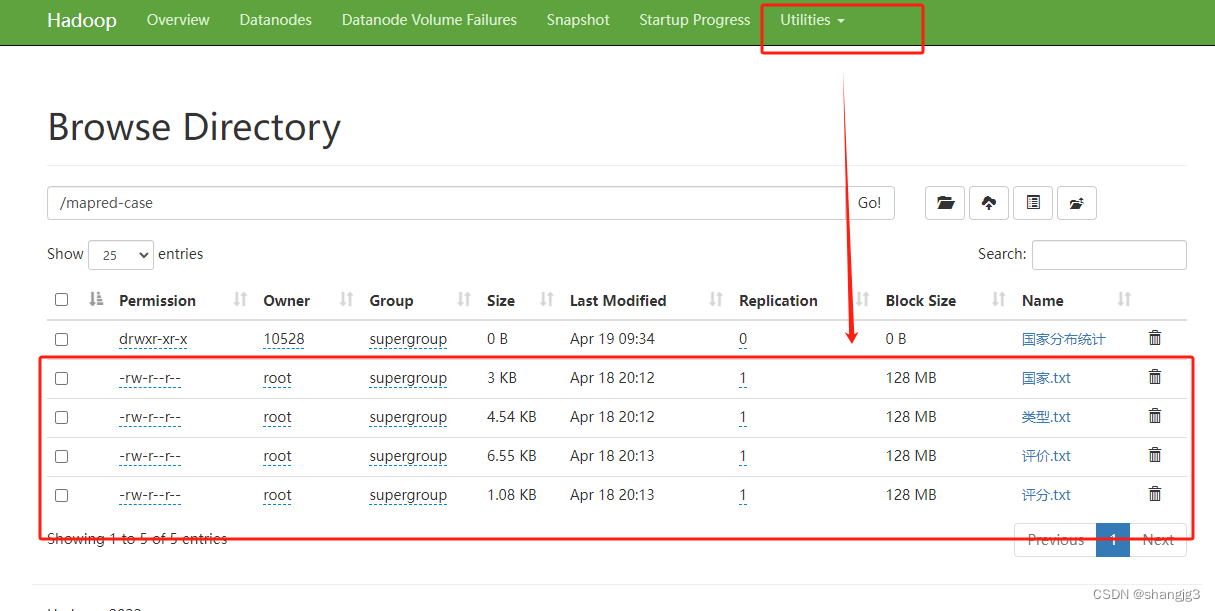
3.编写统计分析代码
3.1 Windows系统配置Hadoop开发环境
在windows上开发和调试Hadoop代码需要下载编译好的Hadoop二进制包。

还要下载winutils,放到Hadoop的bin目录。
winutils的下载地址是:吴所谓/winutils
注意这里的Hadoop版本和服务器上的Hadoop版本虽然不一致,但是不影响程序调试。
并且windows上的Hadoop不需要启动,因为这个步骤只是为了解决MapReduce程序运行开始检测Hadoop环境会报错的问题。
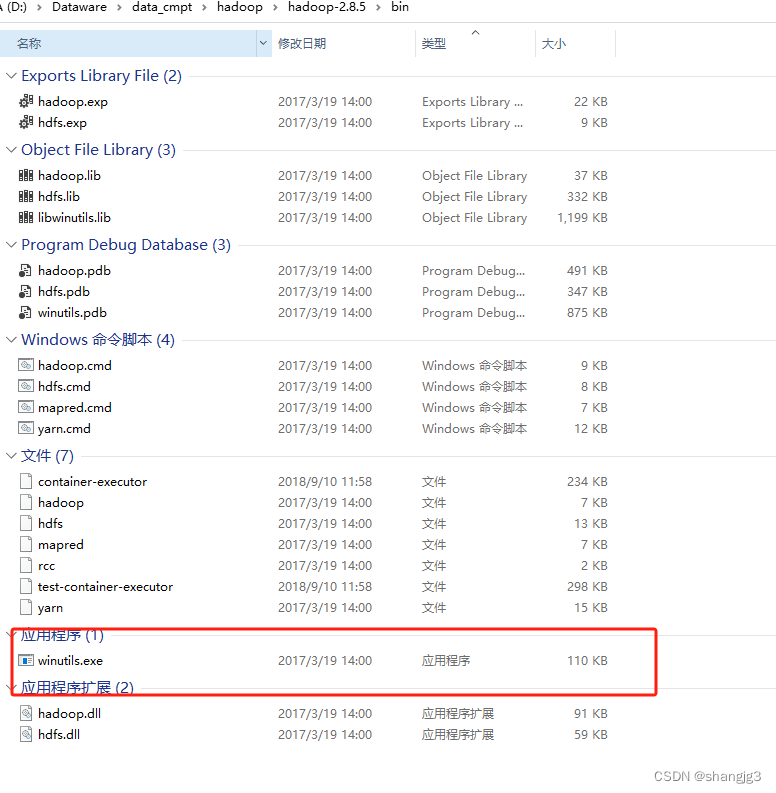
配置Hadoop环境变量,并且将D:\Dataware\data_cmpt\hadoop\hadoop-2.8.5\bin 添加到Path环境变量。


3.2. 新建maven工程,添加Hadoop 依赖和配置信息
<dependencies>
<!-- Hadoop相关依赖包-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>resources目录下增加core-site.xml文件,并添加如下配置信息
<property>
<!-- URI 定义主机名称和 namenode 的 RPC 服务器工作的端口号 -->
<name>fs.defaultFS</name>
<value>hdfs://10.16.60.31:8020</value>
</property>resources目录下增加mapred-site.xml文件,并添加如下配置信息
<configuration>
<!-- 远程提交到 Linux 的平台上 -->
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
<description>Remote MapReduce framework's OS, can be either Linux or Windows</description>
</property>
<!--允许跨平台提交 解决 /bin/bash: line 0: fg: no job control -->
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>添加log4j.properties文件,用于配置日志输出信息。
log4j.appender.A1.Encoding=UTF-8
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n3.3. 按照国家和地区统计电影的产地信息
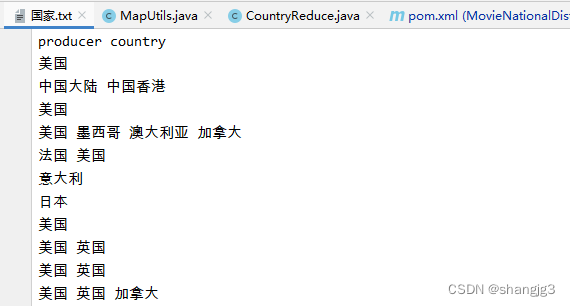
首先看下国家.txt中的数据
新建Map类,用于统计文档中的单词信息。
// Mapper抽象类的核心方法,三个参数
public void map(Object key, // 首字符偏移量
Text value, // 文件的一行内容
Context context) // Mapper端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
String[] ars = value.toString().split("['.;,?| \t\n\r\f]");
for (String tmp : ars) {
if (tmp == null || tmp.length() <= 0) {
continue;
}
word.set(tmp);
context.write(word, one);
}
}
新建Reduce类,用于文档中每个单词出现的次数。
// Reducer抽象类的核心方法,三个参数
public void reduce(Text key, // Map端 输出的 key 值
Iterable<IntWritable> values, // Map端 输出的 Value 集合(相同key的集合)
Context context) // Reduce 端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) // 遍历 values集合,并把值相加
{
sum += val.get();
}
map.put(key.toString(), sum);
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) + ":" + key + "出现了" + sum);
}
新建主程序
public class CountryMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// if (args.length != 2) {
// System.exit(2);
// }
String input = "/mapred-case/国家.txt";
String output = "/mapred-case/国家分布统计";
Job job = new Job(conf, "CountryCount"); // 新建一个 job,传入配置信息
job.setJarByClass(CountryMain.class); // 设置 job 的主类
job.setMapperClass(CountryMap.class); // 设置 job 的 Mapper 类
job.setCombinerClass(CountryReduce.class); // 设置 job 的 作业合成类
job.setReducerClass(CountryReduce.class); // 设置 job 的 Reducer 类
job.setOutputKeyClass(Text.class); // 设置 job 输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置 job 输出值类
FileInputFormat.addInputPath(job, new Path(input)); // 输入路径(数据所在目录)
FileOutputFormat.setOutputPath(job, new Path(output)); // 输出路径(必须不存在的文件夹)
boolean result = false;
try {
result = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) +
(result ? "电影类型(Country)统计完毕!!!" : "统计失败!!!"));
}
}
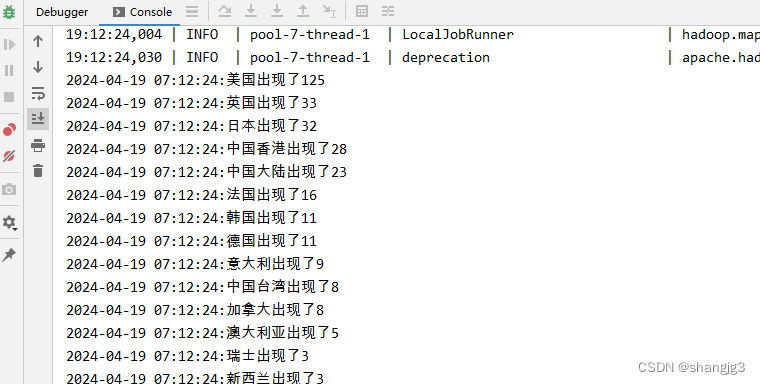
IDEA中启动主程序,可以看到程序执行日志信息如下:
浏览器打开Hadoop管理页面,下载part-r-00000文件,并用记事本打开
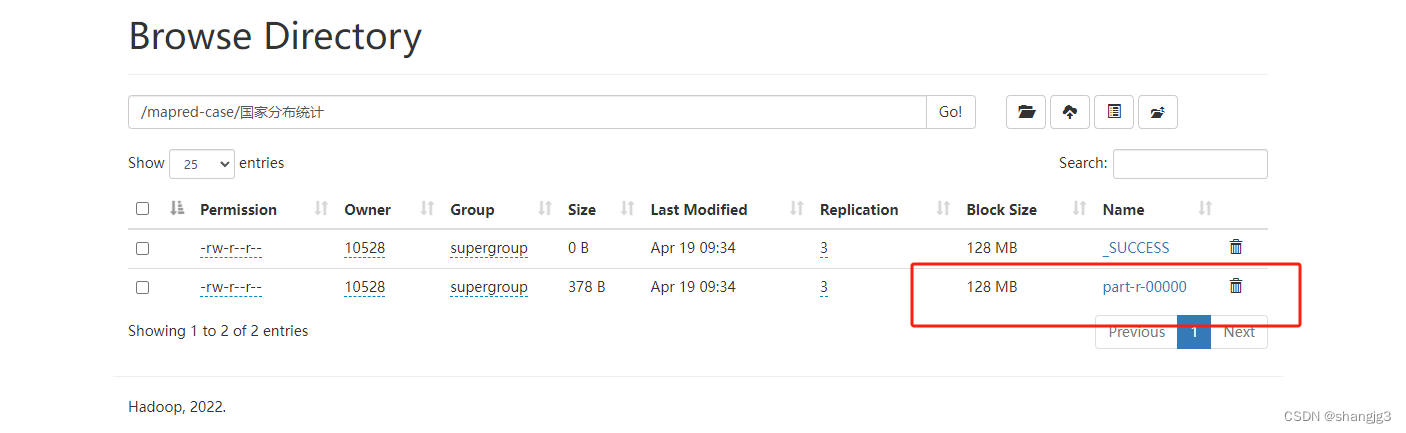
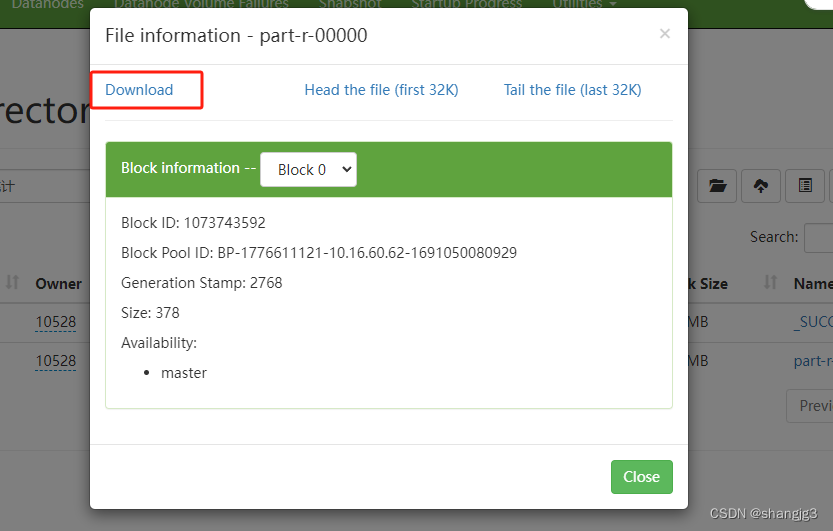

可以看到电影数据已经按照国家这个分类统计出来了。
3.4 电影评论数量排行榜
首先看下数据,这是电影名称和评论数量的列表。但是评论的数量并不是有序的,我们需要将电影名按照评论数量排序。
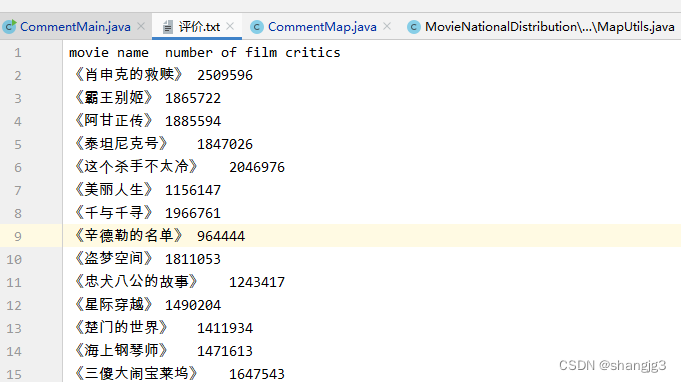
新建一个Map类,将文档中的电影名和评论数量存入一个HashMap中。并调用上一步的排序函数进行排序。
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String line = v1.toString();
String[] fields = line.split("\t");
String province = fields[0];
if (isNumeric(fields[1])){
Integer critics = Integer.parseInt(fields[1]);
map.put(province, critics);
}
}
新建一个启动类,创建一个Hadoop Job,并执行上一步的统计和排序函数。
public class CommentMain {
public static void main(String[] args) {
try {
// 运行jar包程序指令输入错误,直接退出程序
// if (args.length != 2) {
// System.exit(100);
// }
String input = "/mapred-case/评价.txt";
String output = "/mapred-case/评价数量统计";
Configuration conf = new Configuration();//job需要的配置参数
Job job = Job.getInstance(conf, "CommentMain");//创建一个job作业
job.setJarByClass(CommentMain.class);//设置入口类
FileInputFormat.setInputPaths(job, new Path(input));//指定输入路径(可以是文件,也可以是目录)
FileOutputFormat.setOutputPath(job, new Path(output));//指定输出路径(只能是指定一个不存在的目录)
job.setMapperClass(CommentMap.class);
// 指定K2的输出数据类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的输出数据类型
job.setMapOutputValueClass(IntWritable.class);
// 指定Reduce阶段的相关类
job.setNumReduceTasks(0);
//提交作业job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
执行成功之后,我们看下执行日志。
浏览器中打开Hadoop管理页面,并下载执行结果文件。
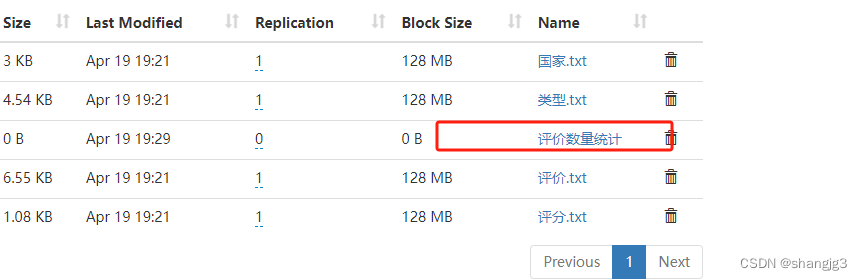
看下执行结果,电影名称已经按照评论数量降序排列好了。
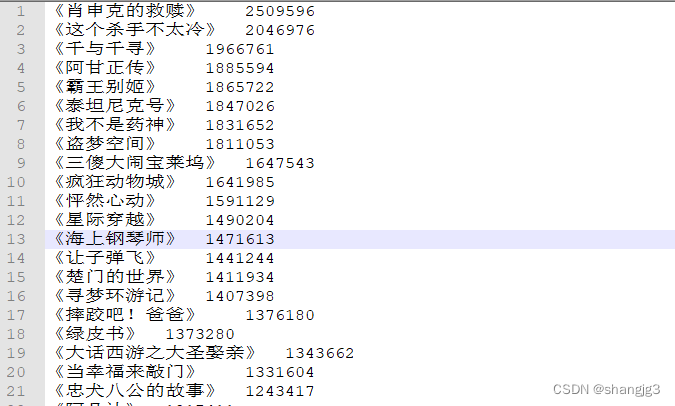
3.5 电影评分分布
首先看一下数据,文档中是电影的评分。

新建Map程序,将评分写入上下文。
// Mapper抽象类的核心方法,三个参数
public void map(Object key, // 首字符偏移量
Text value, // 文件的一行内容
Context context) // Mapper端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
String[] ars = value.toString().split("\t\n");
for (String tmp : ars) {
if (tmp == null || tmp.length() <= 0) {
continue;
}
word.set(tmp);
context.write(word, one);
}
}
新建Reduce类,统计每个评分的梳理,并放入HashMap,key是评分,value是次数。
// Reducer抽象类的核心方法,三个参数
public void reduce(Text key, // Map端 输出的 key 值
Iterable<IntWritable> values, // Map端 输出的 Value 集合(相同key的集合)
Context context) // Reduce 端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) // 遍历 values集合,并把值相加
{
sum += val.get();
}
map.put(key.toString(), sum);
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) + ":" + key + "出现了" + sum);
}
新建MapReduce程序启动类,创建一个Job,并执行。
public class ScoreMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// if (args.length != 2) {
// System.exit(2);
// }
String input = "/mapred-case/评分.txt";
String output = "/mapred-case/评分分布";
Job job = new Job(conf, "ScoreCount"); // 新建一个 job,传入配置信息
job.setJarByClass(ScoreMain.class); // 设置 job 的主类
job.setMapperClass(ScoreMap.class); // 设置 job 的 Mapper 类
job.setCombinerClass(ScoreReduce.class); // 设置 job 的 作业合成类
job.setReducerClass(ScoreReduce.class); // 设置 job 的 Reducer 类
job.setOutputKeyClass(Text.class); // 设置 job 输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置 job 输出值类
FileInputFormat.addInputPath(job, new Path(input)); // 文件输入
FileOutputFormat.setOutputPath(job, new Path(output)); // 文件输出
boolean result = false;
try {
result = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) + (result ? "电影评分(Score)统计完毕!!!" : "统计失败!!!"));
}
}执行后,统计结果如下。

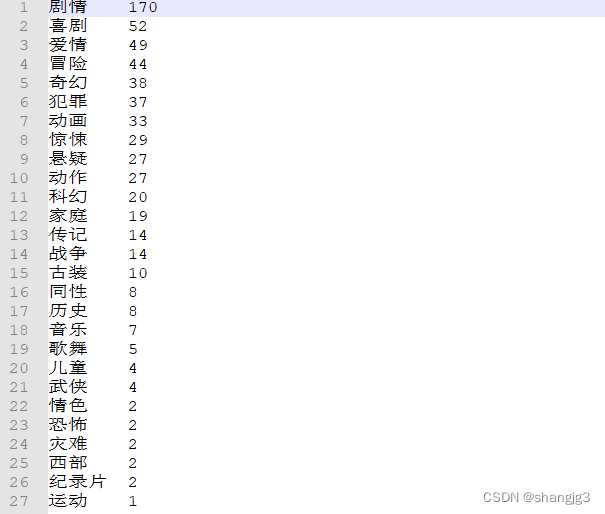
3.6 电影类型分布
数据是电影的分类

新建Map类,将电影类型写入上下文。
// Mapper抽象类的核心方法,三个参数
public void map(Object key, // 首字符偏移量
Text value, // 文件的一行内容
Context context) // Mapper端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
String[] ars = value.toString().split("['.;,?| \t\n\r\f]");
for (String tmp : ars) {
if (tmp == null || tmp.length() <= 0) {
continue;
}
word.set(tmp);
context.write(word, one);
}
}新建Reduce类,统计每个分类的数量。
// Reducer抽象类的核心方法,三个参数
public void reduce(Text key, // Map端 输出的 key 值
Iterable<IntWritable> values, // Map端 输出的 Value 集合(相同key的集合)
Context context) // Reduce 端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) // 遍历 values集合,并把值相加
{
sum += val.get();
}
map.put(key.toString(), sum);
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) + ":" + key + "出现了" + sum);
}新建MapReduce程序启动类,创建一个Job,并执行。
public class TypeMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// if (args.length != 2) {
// System.exit(2);
// }
String input = "/mapred-case/类型.txt";
String output = "/mapred-case/类型分布";
Job job = new Job(conf, "TypeCount"); // 新建一个 job,传入配置信息
job.setJarByClass(TypeMain.class); // 设置 job 的主类
job.setMapperClass(TypeMap.class); // 设置 job 的 Mapper 类
job.setCombinerClass(TypeReduce.class); // 设置 job 的 作业合成类
job.setReducerClass(TypeReduce.class); // 设置 job 的 Reducer 类
job.setOutputKeyClass(Text.class); // 设置 job 输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置 job 输出值类
FileInputFormat.addInputPath(job, new Path(input)); // 文件输入
FileOutputFormat.setOutputPath(job, new Path(output)); // 文件输出
boolean result = false;
try {
result = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) + (result ? "电影标签(Type)统计完毕!!!" : "统计失败!!!"));
}
}
本文全部数据集和代码连接https://download.csdn.net/download/shangjg03/88596022