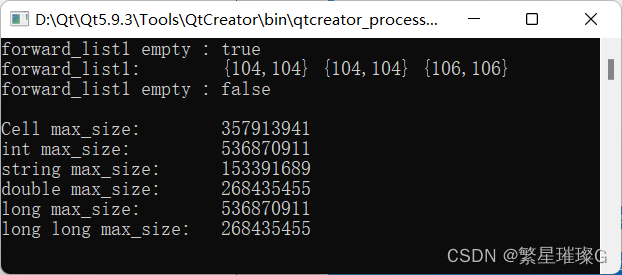
简介
官网:https://palettenerf.github.io/

以(a)多视图照片为训练输入,重建NeRF并将其外观分解为一组(b)基于3D调色板的色基,实现了©直观和逼真的场景重新着色,在任意视图之间具有3D一致性,如(d)所示,该方法支持各种基于调色板的编辑应用,如光照修改和3D真实感风格迁移
贡献点:
- 提出一种新的框架,通过将辐射场分解为学习到的颜色基的加权组合来促进NeRF的编辑。
- 引入了一种具有新颖正则化项的鲁棒优化方案,以实现直观的分解。
- 该方法实现了实用的基于调色板的外观编辑,使新手用户可以在商用硬件上以直观和可控的方式交互式编辑NeRF。
实现流程
给定一组场景中已知姿态的图像,首先优化一个基于nerf的模型来重建场景的几何形状。然后,根据输入的图像和学习到的场景几何特征提取
N
p
N_p
Np 个调色板。最后,训练一个分割模型,根据提取的调色板将场景外观分解为多个基。分解结果能够驱动各种下游应用,如重新着色、逼真的风格迁移和照明修改。
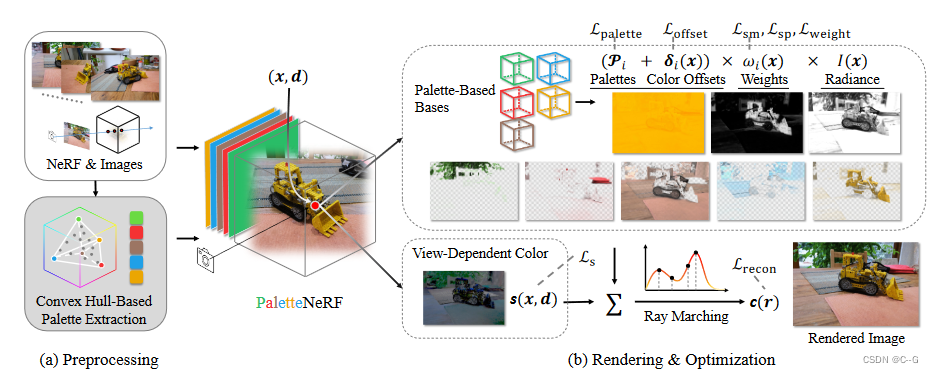
给定一组训练图像,首先(a)用现有方法重建场景几何形状并构建调色板,PaletteNeRF(b) 将场景外观分解为多个基于调色板的基和与视图相关的颜色。在基于调色板的基函数、与视图相关的颜色和最终输出上部署了一系列损失
Palette Extraction
从最先进的图像重新着色工作(Efficient palette-based decomposition and recoloring of images via rgbxy-space geometry)中提取的方法作为初始化,该方法从 RGB 空间中聚类图像颜色的 3D 凸包中提取调色板,只需从 NeRF 的深度图中选择所有具有有效深度的训练图像像素,并将它们的颜色连接起来作为输入
其中NeRF使用了Instant-ngp实现,体渲染公式为:
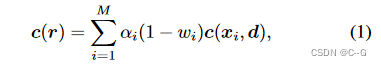
由于捕获场景的阴影不同,提取方法可能会产生色相似的调色板(例如,包括浅黄色和深黄色的调色板),这导致不切实际的外观编辑,可以根据强度对训练图像的输入颜色进行归一化,以缩小调色板的搜索空间
颜色的强度由其 RGB 值的 L1 范数表示。但是,使用 L1 范数进行归一化会将颜色投影到平面上,这对于 3D 凸包计算来说是一个非常不利的边缘情况。这些问题可以通过用更高阶的规范替换来解决。根据经验,发现从L2归一化图像中提取的调色板在下一个分解阶段工作良好
除了提取的调色板 P ˉ \bar{P} Pˉ 外,还保留了输入像素颜色的混合权重 ω ˉ \bar{\omega} ωˉ,这是根据相同工作的方法计算得出的。这些权重在下一阶段充当额外的监督
Color Decomposition
给定大小为 N p N_p Np 的调色板,模型旨在重建 N p N_p Np 个与视图无关的调色板基,以及一个额外的与视图相关的颜色函数,表示所有与视图相关的阴影,如镜面反射
基于调色板的基对应于提取的调色板,由 x 的两个函数定义
color offset function
δ
:
R
3
→
R
3
\delta:R^3 \to R^3
δ:R3→R3
weight function
ω
:
R
3
→
[
0
,
1
]
\omega:R^3 \to [0,1]
ω:R3→[0,1]
观察到真实的图像捕获通常由大量的颜色组成,允许每个点的基本颜色与调色板颜色有偏移。这种设计增加了库的容量,有利于提高复杂场景下的分割质量
同时引入了一个 intensity function I : R 3 → [ 0 , 1 ] R^3 \to [0,1] R3→[0,1],由于提取的调色板的归一化,它在所有基于调色板的基之间共享
模型还包含一个与视图相关的 color function
s
:
R
5
→
[
0
,
1
]
3
s: R^5 \to [0,1]^3
s:R5→[0,1]3,它也将视觉方向作为输入
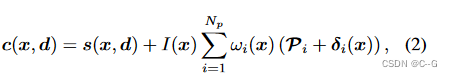
ω
i
(
x
)
ω_i(x)
ωi(x)即和的归一化。将颜色 c 的累加值固定到 [0,1]作为最终输出.在训练过程中优化调色板颜色
P
i
P_i
Pi
网络由三个MLP网络组成:
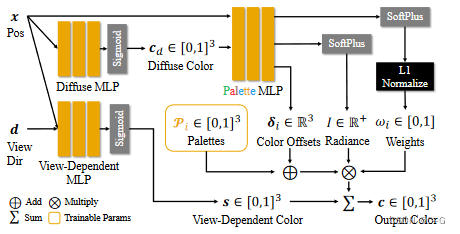
Diffuse MLP 预测漫反射颜色 C d ( x ) C_d(x) Cd(x),即所有基于调色板的基的总和
View-Dependent MLP 生成视图相关的颜色 s(x, d)
Palette MLP 预测基于调色板的基的函数值: ω i ( x ) , δ i ( x ) 和 I ( x ) \omega_i(x), δ_i(x) 和 I (x) ωi(x),δi(x)和I(x),其中 c d c_d cd 也作为先验输入
由于上图中只显示了一个调色板基,因此网络并行生成 N p N_p Np 个基,并在最后一步中将它们相加。
loss
由于从场景外观中分离多个基是一项相当病态的任务,因此在设计优化方案时需要注意许多问题。开发了一系列损失来调节优化参数,以避免出现诸如局部最小等不良结果
图像重建损失为:
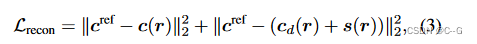
C
r
e
f
C^{ref}
Cref为真实值,
c
(
r
)
,
c
d
(
r
)
,
s
(
r
)
c(r), c_d(r), s(r)
c(r),cd(r),s(r) 根据公式1中的体渲染方程计算。第二项也可以被认为是
c
d
(
r
)
c_d(r)
cd(r) 和调色板基之和之间的 L2 距离
与视图相关的颜色函数 s(x, r) 中添加了一个正则化损失
L
s
L_s
Ls,以防止 s 主导外观并将所有基于调色板的基压为 0 的特殊情况
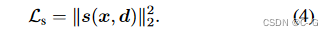
虽然该模型使用颜色偏移来偏移基础颜色,但有必要限制混合权重和颜色偏移,以避免极端解决方案
采用图像软分割方法中的稀疏性损失
L
s
p
L_{sp}
Lsp 和颜色偏移量损失
L
o
f
f
s
e
t
L_{offset}
Loffset
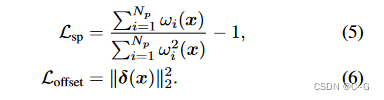
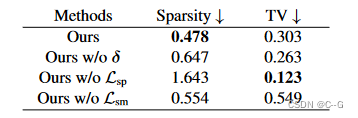
稀疏性损失的目的是使混合权重更稀疏(例如,将每个点x分割到更少的基),这最终将通过增加颜色偏移量来增加基的容量。
色差损失直接抑制了色差的大小,防止它们与调色板偏离过大
直观上,这两种损失充当了两种对抗角色,在它们之间找到良好的平衡将导致基颜色合理、分割结果整齐
在实验中观察到,这两个损失可能会导致苛刻的分割结果,这将极大地影响后续编辑的质量
引入了一种新的3d感知平滑损失,以基于NeRF的输出来平滑权重函数
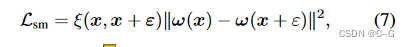
ω
=
ω
1
.
.
.
N
p
\omega = \omega_1 ... N_p
ω=ω1...Np,ε 是从高斯分布中采样的随机位置偏移量,ξ(·) 是两点之间的相似度,调整双边滤波器中使用的高斯核,并定义相似度函数为
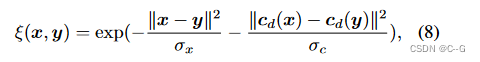
σ
x
σ_x
σx 和
σ
c
σ_c
σc 为平滑参数,diffuse color
c
d
c_d
cd 用于平滑损失,但在训练过程中切断了它们的梯度
添加了两个额外的损失,这些损失包含了来自调色板提取模型的监督
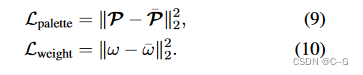
总损失为:
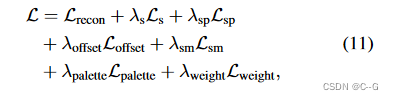
Appearance Editing
根据模型预测的基础,可以简单地调整函数的值以支持外观编辑,如重新着色和逼真的风格迁移。
基函数是在整个场景上定义的,它们不直接支持局部编辑(例如,编辑场景中的单个对象)
因此,从最先进的基于图像的分割模型(如Lang-Seg)预测的语义特征图中学习3D特征场,并使用特征场来指导编辑,然而,直接向模型中添加高维语义特征可能会降低其效率,使其无法实时编辑。从场景中捕获的物体往往局限在一个小集合中(例如,在室内场景中,椅子、墙壁和地板是最有可能出现的物体),从场景中提取的语义特征往往是整个特征空间的有限子集。因此,在将提取的特征输入网络之前,应用PCA将其压缩到较低的维度(在实验中为16)
实验
geometry learning stage:除了添加Sun等人引入的逐点rgb损失外,保留所有原始配置。以使密度场更稀疏并避免飞子
segmentation learning stage:修复前100个epoch中提取的调色板,然后释放调色板并移除 L w e i g h t L_{weight} Lweight 以微调模型。由于平滑损失 L s m L_{sm} Lsm 使用 diffuse color c d c_d cd 来计算平滑权值,因此在前30个迭代阶段不使用 L s m L_{sm} Lsm,以避免未收敛的 c d c_d cd 作为输入
实验工作于 NVIDIA RTX 3090 GPU上,采用Adam 优化器,学习率为0.01,迭代了300-600个epochs,总体运行时间在2小时以内。