数仓建模—数仓架构发展史
时代的变迁,生死的轮回,历史长河滔滔,没有什么是永恒的,只有变化才是不变的,技术亦是如此,当你选择互联网的那一刻,你就相当于乘坐了一个滚滚向前的时代列车,开往未知的方向,不论什么样的技术架构只有放在当前的时代背景下,才是有意义的,人生亦是如此。
时间就是一把尺子,它能衡量奋斗者前进的进程;时间就是一架天平,它能衡量奋斗者成果的重量;时间就是一架穿梭机,它能带我们遨游历史长河,今天我们看一下数仓架构的发展,来感受一下历史的变迁,回头看一下那些曾经的遗迹。准备好了吗 let’s go!,在此之前我们先看一下,数据仓库在整个数据平台中的地位
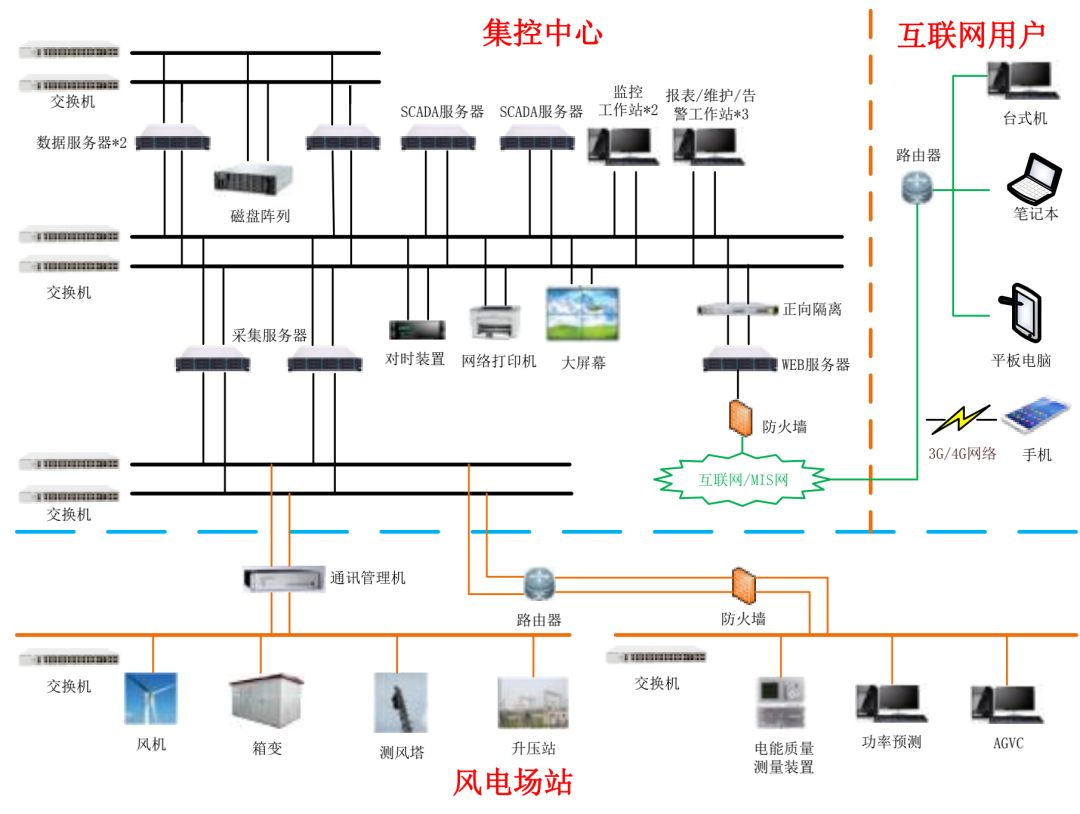
开始之前,我们先上一张大图,先有一个大概的认知,从整体到局部从概括到具体,看一下导致机构变化的原因是什么,探究一下时代背景下的意义,我们顺便看一下什么是数仓
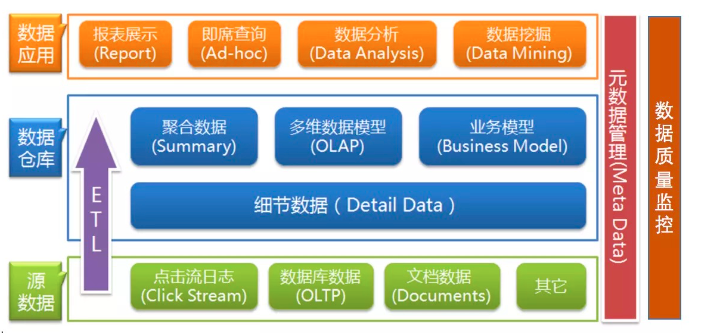
那么什么是数仓,数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策,数据仓库在数据平台中的建设有两个环节:一个是数据仓库的构建,另外一个就是数据仓库的应用。
数据仓库是伴随着企业信息化发展起来的,在企业信息化的过程中,随着信息化工具的升级和新工具的应用,数据量变的越来越大,数据格式越来越多,决策要求越来越苛刻,数据仓库技术也在不停的发展 这就是架构升级的原因,其实就是外部环境变了,现有的体系不能满足当前的需求,既然找到了原因,我们就来欣赏一下历史长河中那些闪亮的星

“我们正在从IT时代走向DT时代(数据时代)。IT和DT之间,不仅仅是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让别人活得比你好”
——阿里巴巴董事局主席马云。
经典数仓
数据仓库在很早的时候就被数据仓库之父Inmon 提出来了,按我的理解,很早的时候主要是对自己企业内部业务数据的一个分析决策,用一些传统的关系型数据库为载体,加上Kettle、Informatica、DataStage等ETL工具以及Biee、smartBi等报表工具来支撑企业自己的数据仓库建设。其服务目标是部分企业高管、市场人员、运营人员等。
也就是说其实数据仓库很早之前就有了,也就是说在离线数仓之前(基于大数据架构之前),有很多传统的数仓技术,例如基于Teradata的数据仓库,只不过是数据仓库技术在大数据背景下发生了很多改变,也就是我们开始抛弃了传统构建数仓的技术,转而选择了更能满足当前时代需求的大数据技术而已,当然大数据技术并没有完整的、彻底的取代传统的技术实现,我们依然可以在很多地方看见它们的身影
经典数仓可以将数仓的数仓的不同分层放在不同的数据库中,也可以将不同的分层放在不同的数据库实例上,甚至是可以把不同的分层放在不同的机房
大数据技术改变了数仓的存储和计算方式,当然也改变了数仓建模的理念,例如经典数仓数据存储在mysql等关系型数据库上,大数据数仓存储在hadoop平台的hive中(实际上是HDFS中),当然也有其他的数仓产品比如TD、greenplum等。
**扩展 一段被人遗忘的历史 **
1970年,关系数据库的研究原型System R 和INGRES开始出现,这两个系统的设计目标都是面向on-line transaction processing (OLTP)的应用。关系数据库的真正可用产品直到1980年才出现,分别是DB2 和INGRES。
其他的数据库,包括Sybase, Oracle, 和Informix都遵从了相同的数据库基本模型。关系数据库的特点是按照行存储关系表,使用B树或衍生的树结构作为索引和基于代价的优化器,提供ACID的属性保证。
到1990年,一个新的趋势开始出现:企业为了商业智能的目的,需要把多个操作数据库中数据收集到一个数据仓库中。尽管投资巨大且功能有限,投资数据仓库的企业还是获得了不错的投资回报率。
从此,数据仓库开始支撑各大企业的商业决策过程。数据仓库的关键技术包括数据建模,ETL技术,OLAP技术和报表技术等。
经典数据仓库产品供应商包括Oracle、IBM、Microsoft、SAS、Teradata、Sybase、Business Objects(已被SAP收购)等。
电信行业是最早采用数据仓库技术的行业之一。由于电信公司运行在一个快速变化和高速竞争的环境,拥有大量的客户基础,从而产生和存储海量的高质量数据。
电信公司利用数据挖掘技术降低营销成本,识别欺诈,并更好地管理其电信网络。
数据仓库之父Bill Inmon在1991年出版的“Building the Data Warehouse”一书中所提出的定义被广泛接受——数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
离线数仓(离线大数据架构)
随着互联网时代来临以及业务的积淀,整个外部环境发生了很大的变化,例如数据量暴增、数据源多样化、服务对象的变化,传统的数据仓库以及Cube技术的不足逐渐显现出来,主要包括以下方面:
- 传统的数据分析更注重对高密度、高价值的结构化数据的业务数据分析,对非结构化、半结构化数据的处理,如图像、文本、音频的存储和分析非常薄弱。
- 由于传统数据仓库采用结构化存储,当数据从其他系统导入数据仓库时,我们通常会引入ETL过程。ETL与具体的业务有很强的绑定性,通常需要一个专门的人或者团队与业务部门进行连接,并决定如何进行数据清洗、转换以及加载。
- 随着异构数据源的增加,例如,如果有视频、文本、图片,要分析数据内容并进入数据仓库,就需要非常复杂的ETL,这导致了ETL过于庞大且臃肿。
- 数据库范式等约束规则重点解决数据冗余问题,以确保数据的一致性。原则上,数据仓库原始数据是只读的,所以这些约束条件将成为影响性能的因素。
- ETL操作对数据的预置和处理,例如轻度的聚合等,会导致机器学习得到的数据并非完整的真实数据,有时候的训练效果并不理想。
- 更麻烦的是,当数据量过大时性能就会成为瓶颈。很多系统在迈入TB、PB级别的规模时就会表现出明显的力不从心。
随着数据量逐渐增大,事实表条数达到千万级,kettle等传统ETL工具逐渐变得不稳定,数据库等存储技术也面临着存储紧张,每天都陷入和磁盘的争斗中单表做拉链的任务的执行时间也指数级增加,这个时候存储我们开始使用HDFS而不是数据库;计算开始使用HIVE(MR)而不是传统数仓技术架构使用的kettle、Informatica 等ETL工具;
在上述一系列问题的困扰下,2004年出现的Map/Reduce技术为我们展示出了处理大数据的一种新的选择。具体说来,Map/Reduce是一种计算框架,通过在集群基础设施上应用并行和分布式算法处理大数据集。其中,Map负责数据的过滤和分类;Reduce负责数据的操作。
在此后,基于Map/Reduce的Apache Hadoop系统的生态系统不断壮大,让我们看到了解决了传统数据仓库的瓶颈的可能。从技术的角度来看,这种大数据架构主要从以下几个维度解决传统数据仓库在数据分析中面临的瓶颈问题
- 分布式计算。分布式计算的思想是让多个节点并行计算,强调数据的局部性,并尽量减少节点间的数据传输。例如Spark用RDD(弹性分布式数据集, Resilient Distributed Dataset)来表达数据的计算逻辑,可以在RDD上进行列优化以减少数据传输。
- 分布式存储。所谓分布式存储,是指将一个大文件分成若干份,每份独立地放在一台节点上。这里涉及到文件拷贝、碎片化、管理等操作。分布式存储的主要优化都集中在在这几个方面。
- 检索与存储的结合。在早期的大数据系统中,存储和计算是比较单一的,但目前的方向是在存储上赋予更强大的能力,目的是要快速地找到数据并读取数据。所以目前的存储不仅是存储数据内容自身,还增加了很多元数据。
- 计算与存储的分离。从历史上看,数据库系统主要采用 “计算和存储紧耦合”的架构。之所以采用这种设计主要是出于性能的考虑。现代数据分析应用需求在过去十年中发生了显著的变化,要处理更大量级的数据,并且用于分析这些数据的方法也是多种多样的,并且预计会相互影响以获得最终结果。例如,一个简单而常见的分析应用是通过消息流传输日志数据,然后通过管道传送到计算引擎进行进一步分析。在这种情况下,单个计算引擎无法完全控制数据布局和文件系统。因此,这些现代分析应用就要求计算与存储解耦。
所以技术从业者开始使用大数据工具来替代经典数仓中的传统工具,当然前提是大数据技术已经相对成熟,其实我们知道大数据或者是Hadoop 最初是谷歌用来解决搜索引擎的计算问题的。
公司开始考虑重新设计数仓的架构,使用hadoop平台的hive做数据仓库,报表层数据保存在mysql中,使用tableau做报表系统,这样不用担心存储问题、计算速度也大大加快了。在此基础上,公司开放了hue给各个部门使用,这样简单的提数工作可以由运营自己来操作。使用presto可以做mysql、hive的跨库查询,使用时要注意presto的数据类型非常严格。
以Apache Hadoop 为代表的大数据架构之所以被称为离线大数据架构,它的定位是解决传统经典数据仓库的问题。简单来说,就是数据分析没有发生任何变化,但是由于数据量和性能的问题,传统的数据仓库无能为力,需要升级替代。例如,在这个架构中仍然保留了ETL操作,数据通过ETL加载进入数据存储。
优缺点
但是,也要看到这种大数据架构相对于传统的数据仓库来说优点巨大,但仍存有不足
- 从传统数据仓库升级到大数据架构,并不是无缝迁移的,基本等于推翻重做。
- 大数据下的分布式存储强调数据的只读性,例如HDFS的存储方式不支持更新、HDFS的写操作不支持并行等。这些特点导致了在应用上一定的局限性。
- 存储的耦合,副本等机制造成了扩展和容灾发生时的成本压力和运维压力。
- 对于大数据架构,尚缺乏完整的Cube工具。虽然目前有部分开源或者商业化的产品,但仍存在局限性。例如:缺乏Cube的灵活性和稳定性,所以对于业务支持的灵活度略显不足。对于报表数量多或者复杂的场景,就需要过多的人工定制。同时,这个架构上还是以批处理为主,缺乏数据实时性的支持。
优点在于
- 从已有的实践来看,这个架构简单易行,针对数据处理的方法论没基本有改变,唯一改变的是基础技术平台的选择,用大数据架构代替传统的数据仓库,基本上就是一个软件替代
- 该架构针对的是传统数据仓库由于数据量和性能等问题无法满足需要的场景,这些场景主要就是数据分析的需求以及商业智能(BI)等。
流式架构
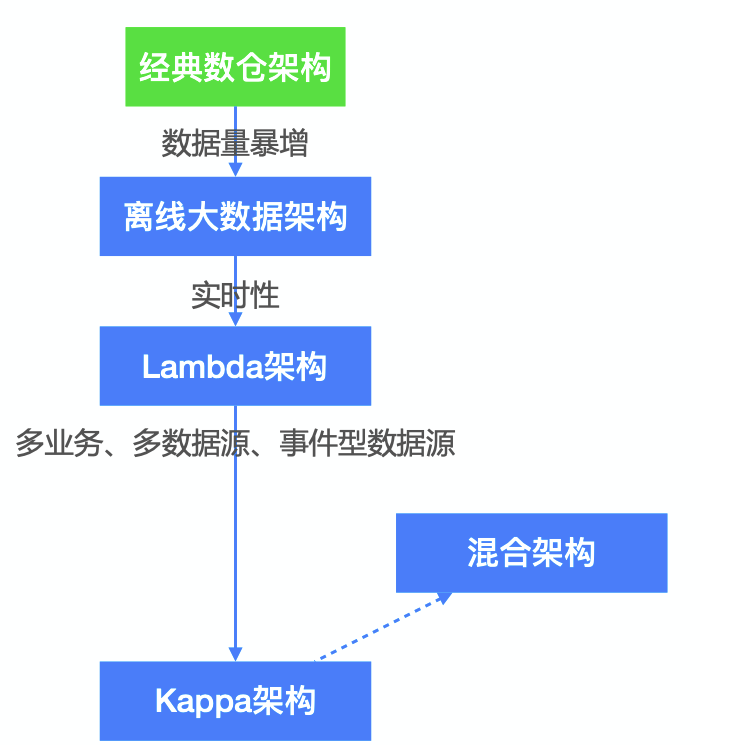
着眼于解决传统大数据架构的不足,从2011年开始,一些列新的大数据架构不断涌现出来。其中数据流架构、Kappa架构与Lambda 架构为其中最为流行的架构。
当然这得益于网络技术、通信技术的发展,使得终端数据的实时上报传输成为可能,从而业务实系统发生变化,进而导致了我们对需求的时性要求的不断提高开始之前我们先看一下,网络技术和通信技术到底对我们的生活有什么样的影响

相对于传统的大数据架构,数据流架构是一种更为激进架构的设计。在这个架构中直接去掉了批处理的部分,整个处理的过程都是以流的形式处理数据。其建立的目的是摄取和处理来自多个来源的大量流式数据。传统的数据解决方案侧重于批量写入和读取数据,而流式数据架构则在数据生成时立即消耗数据,将其持久化到存储中,并可能包括各种额外的组件,例如用于实时处理、数据操作和分析的工具。
数据流架构需要考虑到数据流的独特特性,首先数据流针对的是海量数据(TB或 PB级别);其次,数据往往是半结构化的,需要大量的预处理数据才能变得有用。最后,数据的时效性,即同一窗口下的数据进行分析的价值。

架构优势:没有臃肿的ETL流程,数据处理的时效性非常高。
架构缺点: 对于数据流架构,缺少批处理,所以不能很好的支持数据回放和历史数据统计。对于离线分析,只支持有限的“数据窗口”内的数据的分析
当然流式架构的发展也不是一蹴而就的,而是经历不同架构的迭代。
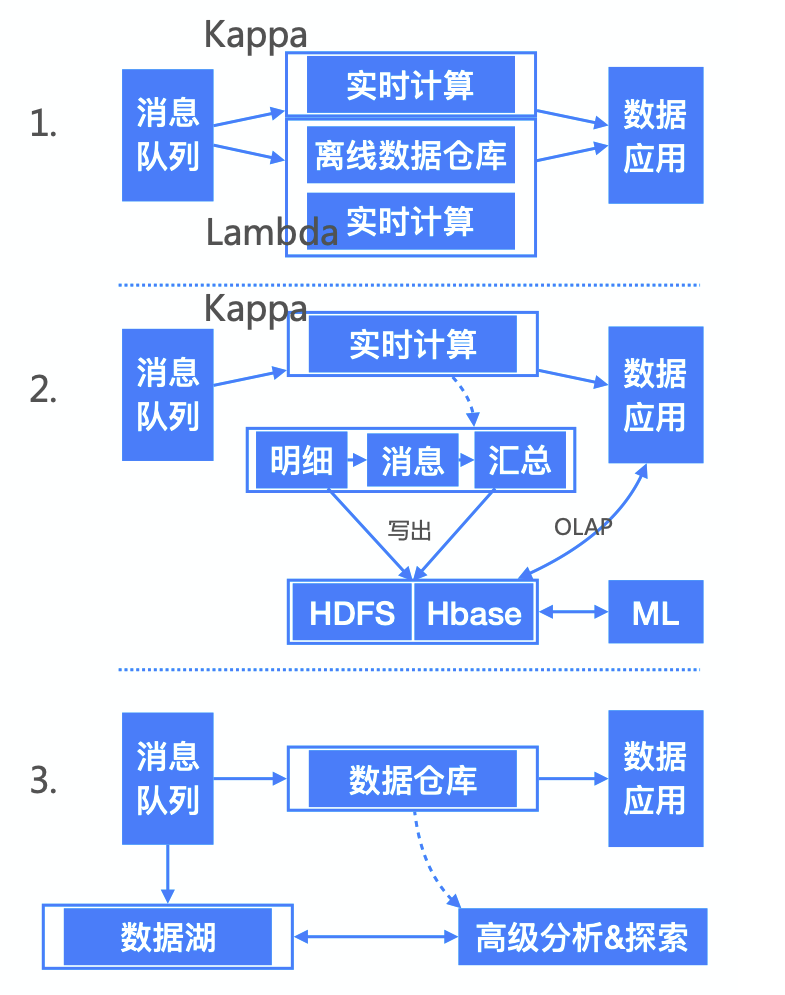
Lambda架构
着眼于解决传统大数据架构的不足,从2011年开始,一些列新的大数据架构不断涌现出来。其中数据流架构、Kappa架构与Lambda 架构为其中最为流行的架构。
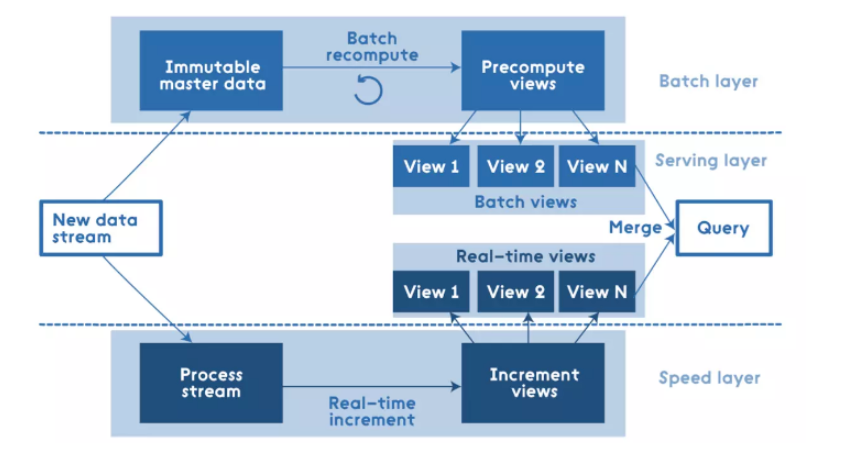
Lambda架构是新一代大数据系统中举足轻重的架构。新一代的架构大多都是Lambda架构或基于其变种的架构。Lambda架构描述了一个由三层组成的系统:批处理、速度(或实时)处理和用于响应查询的服务层。这种范式最早是由Nathan Marz在一篇题为 “How to beat the CAP theorem” 文章中描述的,他最初将其称为 “批处理/实时架构” 。在2016年出版的《大数据系统构建:可扩展实时数据系统构建原理与最佳实践》一书,对这个架构有深入的阐释。

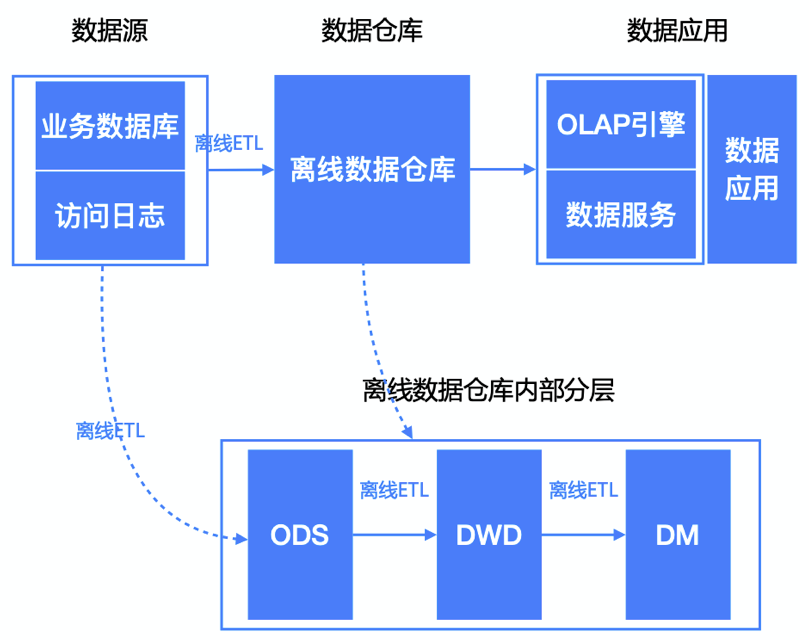
为了应对这种变化,开始在离线大数据架构基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,然后和离线计算进整合从而给用户一个完整的实时计算结果,这便是Lambda架构。
为了计算一些实时指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。
需要注意的是流处理计算的指标批处理依然计算,最终以批处理为准,即每次批处理计算后会覆盖流处理的结果(这仅仅是流处理引擎不完善做的折中),Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lambda架构是其根据多年进行分布式大数据系统的经验总结提炼而成。Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
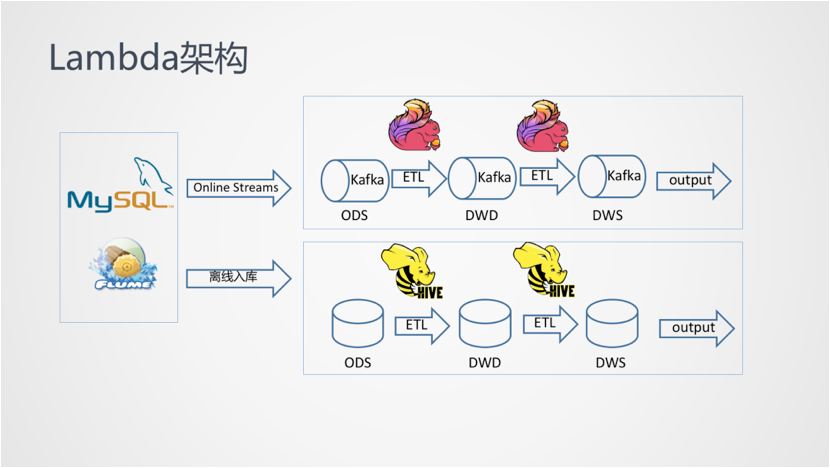
如果抛开上面的Merge 操作,那么Lambda架构就是两条完全不同处理流程,就像下面所示
存在的问题
同样的需求需要开发两套一样的代码,这是Lambda架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,一个在批处理引擎上实现,一个在流处理引擎上实现,还要分别构造数据测试保证两者结果一致),后期维护更加困难,比如需求变更后需要分别更改两套代码,独立测试结果,且两个作业需要同步上线。
资源占用增多**:同样的逻辑计算两次,整体资源占用会增多(多出实时计算这部分)·**
实时链路和离线链路计算结果容易让人误解,昨天看到的数据和今天看到的数据不一致
下游处理复杂,需要整合实时和离线处理结果,这一部分往往是我们在呈现给用户之前就完成了的
总体看来,Lambda架构的设计目标是通过利用批处理和流处理方法来处理海量数据。这种架构方法试图平衡延迟、吞吐量和容错性,利用批处理提供批数据的全面和准确视图,同时利用实时流处理提供在线数据的视图。Lambda架构的兴起与大数据、实时分析的发展以及缓解Map/Rreduce延迟的驱动力有关。
Kappa架构
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的Kappa架构。当然这不要实现这一变化,还需要技术本身的革新——Flink,Flink 的出现使得Exactly-Once 和状态计算成为可能,这个时候实时计算的结果保证最终结果的准确性
Lambda架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。后来随着Flink等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题,LickedIn 的Jay Kreps提出了Kappa架构
Kappa架构可以认为是Lambda架构的简化版(只要移除lambda架构中的批处理部分即可)。在Kappa架构中,需求修改或历史数据重新处理都通过上游重放完成。
Kappa架构的出现要归功于Confluent公司的首席执行官和Apache Kafka的共同创建者Jay Kreps。他提出使用不可改变的数据流作为主要的记录源,而不是使用数据库或文件的时间点来表示。换句话说,如果一个包含所有企业数据的数据流可以无限期地持久化,那么对代码的更改可以根据需要重放过去的事件。这样就可以实现lambda架构不支持的单元测试和流计算的修改。Kappa架构还消除了对基于批处理的入口过程的需求,因为所有数据都作为事件写入到持久化的流中。Kappa架构是一种新颖的分布式系统架构方法,背后的设计理念非常值得学习。
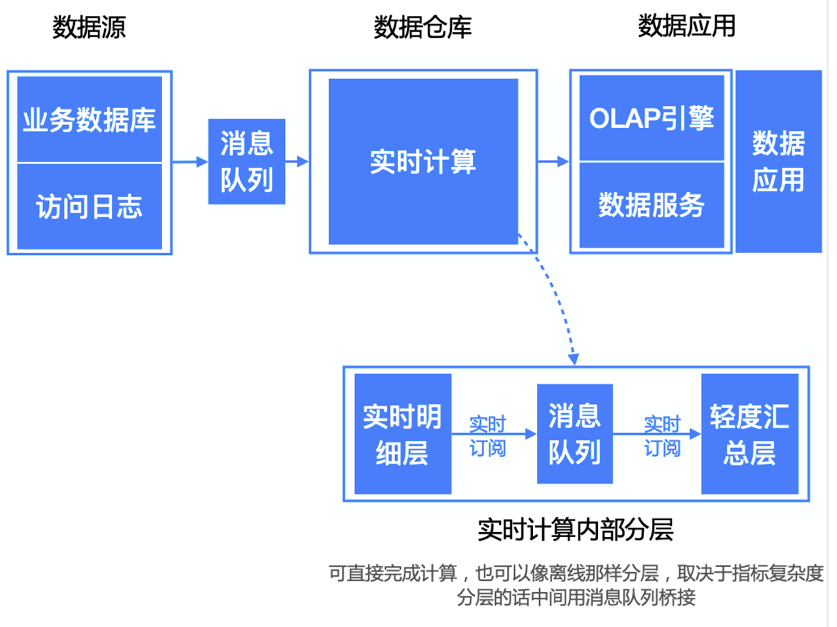
Kappa架构的重新处理过程
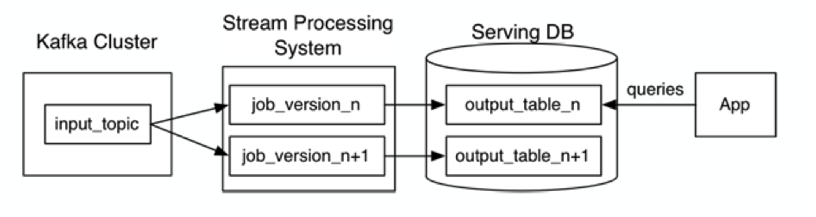
选择一个具有重放功能的、能够保存历史数据并支持多消费者的消息队列,根据需求设置历史数据保存的时长,比如Kafka,可以保存全部历史数据,当然还有后面出现的Pulsar,以及专门解决实时输出存储的Pravega
当某个或某些指标有重新处理的需求时,按照新逻辑写一个新作业,然后从上游消息队列的最开始重新消费,把结果写到一个新的下游表中。
当新作业赶上进度后,应用切换数据源,使用新产生的新结果表。停止老的作业,删除老的结果表。
存在的问题
Kappa架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补
Pravega(流式存储)
想要统一流批处理的大数据处理架构,其实对存储有混合的要求
对于来自序列旧部分的历史数据,需要提供高吞吐的读性能,即catch-up read对于来自序列新部分的实时数据,需要提供低延迟的 append-only 尾写 tailing write 以及尾读 tailing read

存储架构最底层是基于可扩展分布式云存储,中间层表示日志数据存储为 Stream 来作为共享的存储原语,然后基于 Stream 可以向上提供不同功能的操作:如消息队列,NoSQL,流式数据的全文搜索以及结合 Flink 来做实时和批分析。换句话说,Pravega 提供的 Stream 原语可以避免现有大数据架构中原始数据在多个开源存储搜索产品中移动而产生的数据冗余现象,其在存储层就完成了统一的数据湖。
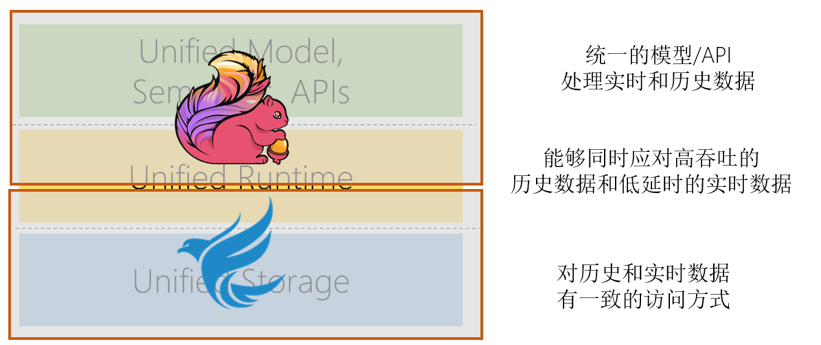
提出的大数据架构,以 Apache Flink 作为计算引擎,通过统一的模型/API来统一批处理和流处理。以 Pavega 作为存储引擎,为流式数据存储提供统一的抽象,使得对历史和实时数据有一致的访问方式。两者统一形成了从存储到计算的闭环,能够同时应对高吞吐的历史数据和低延时的实时数据。同时 Pravega 团队还开发了 Flink-Pravega Connector,为计算和存储的整套流水线提供 Exactly-Once 的语义。
优缺点
架构优点 :Kappa体系结构解决了Lambda架构中较为冗余的部分。它的设计具有支持数据重放的理念。并且,整个架构非常简洁。
架构缺点:虽然Kappa体系结构看起来很简洁,但实现起来相对比较困难,尤其是数据重放部分。
混合架构
前面介绍了Lambda架构与Kappa架构的含义及优缺点,在真实的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金额相关)使用Lambda架构用批处理重新计算,增加一次校对过程。
Kappa架构并不是中间结果完全不落地,现在很多大数据系统都需要支持机器学习(离线训练),所以实时中间结果需要落地对应的存储引擎供机器学习使用,另外有时候还需要对明细数据查询,这种场景也需要把实时明细层写出到对应的引擎中。
还有就是Kappa这种以实时为主的架构设计,除了增加了计算难度,对资源提出了更改的要求之外,还增加了开发的难度,所以才有了下面的混合架构,可以看出这个架构的出现,完全是处于需求和处于现状考虑的
实时数仓
实时数仓不应该成为一种架构,只能说是是Kappa架构的一种实现方式,或者说是实时数仓是它的一种在工业界落地的实现,在Kappa架构的理论支持下,实时数仓主要解决数仓对数据实时化的需求,例如数据的实时摄取、实时处理、实时计算等
其实实时数仓主主要解决三个问题 1. 数据实时性 2. 缓解集群压力 3. 缓解业务库压力。
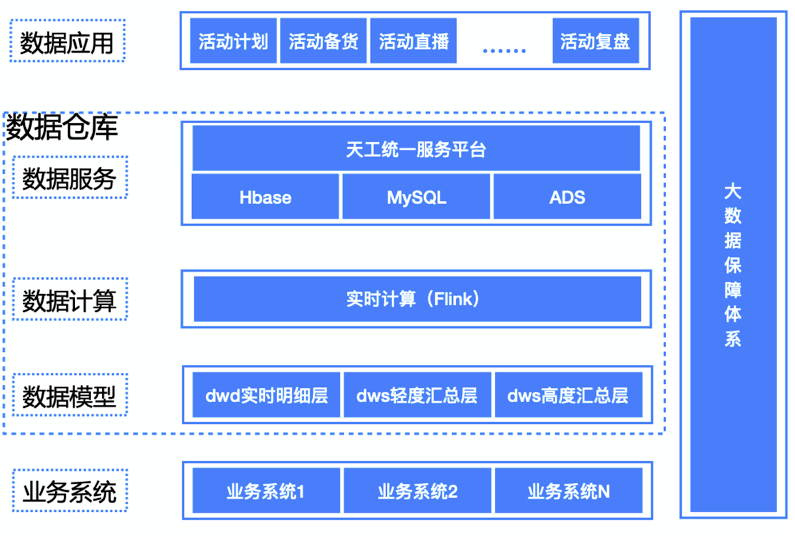

第一层DWD公共实时明细层 实时计算订阅业务数据消息队列,然后通过数据清洗、多数据源join、流式数据与离线维度信息等的组合,将一些相同粒度的业务系统、维表中的维度属性全部关联到一起,增加数据易用性和复用性,得到最终的实时明细数据。这部分数据有两个分支,一部分直接落地到ADS,供实时明细查询使用,一部分再发送到消息队列中,供下层计算使用
第二层DWS公共实时汇总层 以数据域+业务域的理念建设公共汇总层,与离线数仓不同的是,这里汇总层分为轻度汇总层和高度汇总层,并同时产出,轻度汇总层写入ADS,用于前端产品复杂的olap查询场景,满足自助分析;高度汇总层写入Hbase,用于前端比较简单的kv查询场景,提升查询性能,比如产出报表等
实时数仓的的实施关键点
- 端到端数据延迟、数据流量量的监控
- 故障的快速恢复能⼒力力 数据的回溯处理理,系统⽀支持消费指定时间端内的数据
- 实时数据从实时数仓中查询,T+1数据借助离线通道修正
- 数据地图、数据⾎血缘关系的梳理理
- 业务数据质量量的实时监控,初期可以根据规则的⽅方式来识别质量量状况
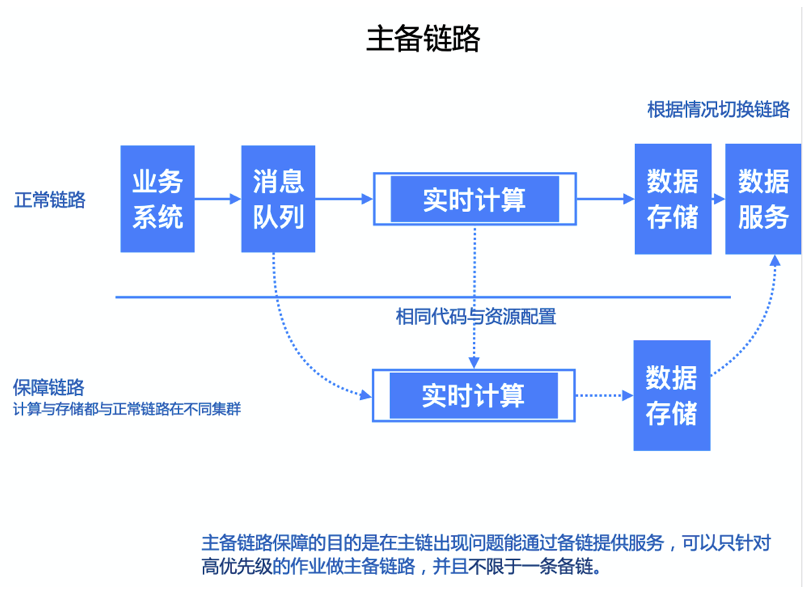
数据保障
- 例如每年都有双十一等大促,大促期间流量与数据量都会暴增。实时系统要保证实时性,相对离线系统对数据量要更敏感,对稳定性要求更高
- 所以为了应对这种场景,还需要在这种场景下做两种准备: 1.大促前的系统压测; 2.大促中的主备链路保障

数据湖
最开始的时候,每个应用程序会产生、存储大量数据,而这些数据并不能被其他应用程序使用,这种状况导致数据孤岛的产生。随后数据集市应运而生,应用程序产生的数据存储在一个集中式的数据仓库中,可根据需要导出相关数据传输给企业内需要该数据的部门或个人,**然而数据集市只解决了部分问题。**剩余问题,包括数据管理、数据所有权与访问控制等都亟须解决,因为企业寻求获得更高的使用有效数据的能力。
所谓的“数据湖”是一个以自然/原始格式存储的数据系统或仓库,通常是采用的存储对象是blobs或文件。一个数据湖通常是一个单一的数据存储,包括多种数据来源,例如生产数据、日志、传感器数据、社交媒体数据等。数据湖在企业中被用来支持各类报表、数据可视化、高级分析和机器学习等任务。从数据格式来看,数据湖可以包括来自关系数据库的结构化数据、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、PDF)和二进制数据(图像、音频、视频)。数据湖可以建立在企业的数据中心,越来越多的企业开始将数据湖构建于云端。
2011年,时任Pentaho公司首席技术官的James Dixon创造了“数据湖”这个概念,并将其与数据集市(Data Mart)进行对比。与之相比,数据集市则是一个较小的、由原始数据衍生出的有特定属性的数据存储库。 在推广数据湖时,James Dixon认为数据集市存在固有的不足,比如信息孤岛。而数据湖可以 解决”数据孤岛”这个企业信息化中的顽症。
在建设数据湖的过程中,一定要避免产生大数据坟场。也就是将所有的东西都倾倒到诸如分布式文件系统(HDFS)中,但随后就失去了对数据的有效管理。对于这个结果也有了一个专门的定义,“数据沼泽”( Data Swamp)。这个概念特指变质且无人管理的数据湖,它要么无法被其目标用户访问,要么提供的价值很小。解决这个问题的关键就是企业需要弄清楚哪些数据和元数据是业务真正需要的。
对数据湖还存在一些批评的意见。他们认为数据湖这个概念是模糊和随意的,涵盖了任何不符合传统数据仓库架构的工具或数据管理实践。数据湖的概念已经被赋予了过多的含义,这使得这个术语的实用性受到了质疑。同样的批评也存在于许多年前对于“数据仓库”的看法,认为概念存在着定义不透明和不断变化的问题。但随着工具的丰富以及实践的积累,解决现有的质疑仅仅是时间的问题。我比较认同麦肯锡的一个研究结论,数据湖应该被视为在企业内部提供商业价值的服务模式,而不仅仅是一个技术成果。
为了解决前面提及的各种问题,企业有很强烈的诉求搭建自己的数据湖,数据湖不但能存储传统类型数据,也能存储任意其他类型数据(文本、图像、视频、音频),并且能在它们之上做进一步的处理与分析,产生最终输出供各类程序消费。而且随着数据多样性的发展,数据仓库这种提前规定schema的模式显得越来难以支持灵活的探索&分析需求,这时候便出现了一种数据湖技术,即把原始数据全部缓存到某个大数据存储上,后续分析时再根据需求去解析原始数据。简单的说,数据仓库模式是schema on write,数据湖模式是schema on read
更多关于数据湖的细节请看数据湖初识,而且我们后面也会详细介绍数据湖相关的内容
总结
Kappa对比Lambda架构 都是流式架构,都是对离线架构的扩展
Kappa对比Lambda架构
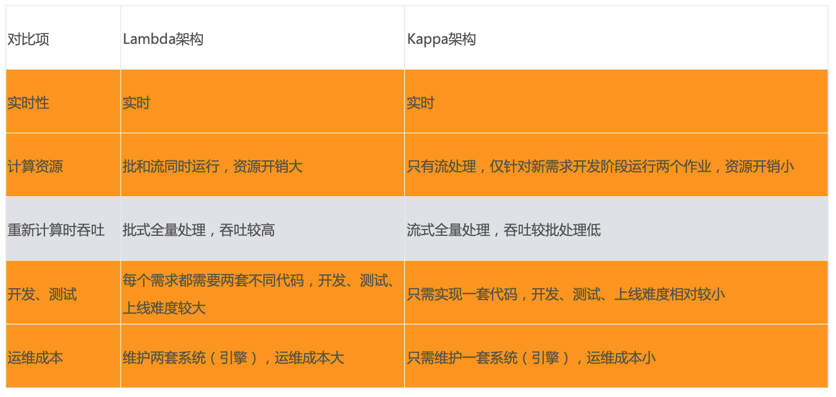
在真实的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金额相关)使用Lambda架构用批处理重新计算,增加一次校对过程。
实时数仓与离线数仓的对比
离线数据仓库主要基于sqoop、hive等技术来构建T+1的离线数据,通过定时任务每天拉取增量量数据导⼊到hive表中,然后创建各个业务相关的主题维度数据,对外提供T+1的数据查询接口
实时数仓当前主要是基于实时数据采集工具,如canal等将原始数据写⼊入到Kafka这样的数据通道中,最后⼀一般都是写 入到类似于HBase这样存储系统中,对外提供分钟级别、甚至秒级别的查询方案。