笔者最近刚刚试用完 CodeGemma ,准备分享我的心得时,通义千问的 CodeQwen1.5 就也悄然发布。本文主要介绍 CodeQwen1.5 这款开源编程大模型,并展示如何在 VSCode 中使用它帮你提升编程体验。
1. 开源编程大模型的必要性
大型语言模型(LLMs)在各行各业扰动风云的今天,在编程领域也是首当其冲,掀起了一场变革,为开发者带来了显著的效率和准确性提升。然而,像 Github Copilot 这样的基于专有 LLMs 的流行编码助手,却因其成本、隐私、安全和潜在的版权侵权问题而备受诟病。因为除了参与的开源项目外,我们也总会有很多私有和需要保密的商业项目需要处理,这就使得将代码库完全暴露给第三方服务变得颇为敏感。
这些担忧催生了开源社区的积极响应,促进了对更加透明、更易于访问的替代方案的开发,并已经取得了显著成果。具体来说,如 Codegemma、StarCoder2、CodeLlama 和DeepSeek-Coder 等开源模型的出现标志着这一领域的重大进步。也让普通的开发人员可以更加自由地选择适合自己的工具,而不必受限于专有模型的局限。
2. 开源编程大模型的优势
- 透明度: 开源模型的代码和开发过程公开透明,允许任何人审查和改进模型,确保其安全性和可靠性。这与专有模型的封闭性质形成鲜明对比,后者可能会隐藏潜在的缺陷或安全漏洞。
- 可访问性: 开源模型通常是免费提供的,降低了门槛,使来自世界各地的人,无论经济状况或背景如何,都能使用和贡献。这对于促进全球范围内的技术进步和创新至关重要。
- 协作: 开源模型鼓励协作和共同开发,汇聚来自不同背景和专业知识的贡献者,共同完善模型。这种集体智慧可以推动更快速、更有效的创新,并最终带来更强大的模型。
- 道德规范: 开源社区致力于开发负责任和符合道德规范的 AI 技术。开源模型可以更容易地进行审查和修改,以确保它们符合道德准则,并避免偏见或歧视。
- 灵活性: 开源模型可以根据特定需求进行定制和调整,使其适用于各种应用场景。通过加入自己或自己组织的专有代码库进行训练微调,可以使其更适应自己的编码风格。
开源编程大模型为编程工具的未来开辟了令人兴奋的可能性。通过透明、协作和创新的精神,我们可以共同构建更强大、更有用且更具道德责任感的编程工具,造福所有人,而不仅仅是开发人员,也包括不会编程的人。相信未来,越来越多的普通人会通过编程大模型让他们的创意和想法变为现实。
3. CodeQwen1.5 的特点

CodeQwen1.5 是通义千问的开源编程大模型,它具有以下几个特点:
- 强大的代码生成能力: 能够生成自然、准确且符合语法规范的代码。
- 优秀的长序列建模能力: 可以处理长达 64K 的上下文输入,在处理复杂代码时表现出色。
- 出色的代码修改能力: 可以根据需求对现有代码进行修改或优化。
- 强大的 SQL 能力: 可以生成 SQL 语句,并对数据库进行查询和操作。
- 支持多种编程语言: 支持 92 种编程语言,覆盖了主流的编程语言。
- 高效的参数规模: 拥有 7B 参数,在保证性能的同时,模型大小也相对适中。
Qwen 语言模型是一个经过中文良好训练的大型语言模型,这为 CodeQwen1.5 提供了良好的基础。GQA 架构是一种先进的模型架构,可以提高模型的性能和效率。同时,CodeQwen1.5 是在 ~3T tokens 的代码相关数据上进行预训练的,这使得它能够更好地理解和处理代码。支持 92 种编程语言,具有很强的通用性。
基于以上的特点和优势,CodeQwen1.5 在编程辅助工具中具有广泛的应用前景,可以帮助开发人员提高编程效率,减少编码错误,加速项目开发进程。
- 自动代码生成: 可以根据需求自动生成代码,帮助开发人员节省时间和精力。
- 代码优化: 可以对现有代码进行优化,提高代码的可读性和可维护性。
- 代码测试: 可以自动生成测试用例,帮助开发人员发现代码中的缺陷。
- 代码文档生成: 可以自动生成代码文档,帮助开发人员了解代码的结构和功能。
4. 模型获取和部署
CodeQwen1.5 是一个开源模型,可以通过 GitHub 获取源代码,并获取相关资料和介绍:https://github.com/QwenLM/CodeQwen1.5?wt.mc_id=DT-MVP-5005195。
对于模型文件,可以非常方便的通过抱抱脸(Hugging Face)和魔搭(ModelScope) 获取。同时,CodeQwen1.5 也提供了 Guff 和 AWQ 格式的量化版本,可以方便的使用不同的方式部署使用。
对于普通用户,低成本,简单易操作的方式我推荐使用 Ollama 提供的 Windows 客户端,自带 Cuda 环境,可以直接使用 GPU 进行推理,提供了非常好的使用体验,只需要下载安装即可:https://ollama.com/。

在运行 Ollama 程序后,需要我们打开控制台自行拉取模型文件运行,即可开始使用 CodeQwen1.5 进行编程辅助。
模型有两类,一类是 code 用于代码补全,一类是 chat 用于对话生成。在使用时,我们可以根据自己的需求选择不同的模型进行使用。
ollama pull codeqwen:chat
ollama pull codeqwen:code

我们可以使用上面的命令拉取这两种模型文件,当然你也可以前往 Ollama 的 CodeQwen 模型库,寻找不同量化精度的版本,这样可以根据自己的需求选择合适的模型文件,当然模型的文件大小和推理速度也会有所不同。
模型拉取完成后,我们可以使用下面的命令来运行模型,当然也可以直接使用下面的命令,会自动完成模型拉取和运行。关于 Olamma 的更多的使用方法,大家可以自行搜索学习,相关文章非常多,这里不做过多的介绍。
ollama run codeqwen:chat
运行后我们就可以在控制台中与大模型进行交流了,CodeQwen1.5 除了代码生成,技术文档的生成也是非常的出色。

5. 在 VSCode 中使用
对于开发人员来说,最便捷的使用当然是集成到 IDE 中。最常用的 IDE 莫过于 VSCode 了,那么如何在 VSCode 中使用 CodeQwen1.5 呢?这里笔者推荐使用 Twinny 插件,这是一个非常好用的插件,可以帮助我们在 VSCode 中使用 CodeQwen1.5 进行编程辅助。
作为一个开源项目,Twinny 插件提供了丰富的功能,包括代码补全、代码生成、代码优化、代码测试、代码文档生成等。通过简单的配置,我们就可以在 VSCode 中使用 CodeQwen1.5,提高编程效率,减少编码错误,加速项目开发进程。
最重要的一点是,该插件支持多种模型的部署提供方案,并且允许我们自行修改提示词,以优化我们在不同模型中的使用表现。这为我们提供了更多的选择和灵活性,使我们能够更好地适应不同的编程场景。
5.1 插件配置
插件默认使用的 Codegemma ,我们需要通过以下操作修改配置。在侧边的对话功能页,点击类似插头的配置图标:
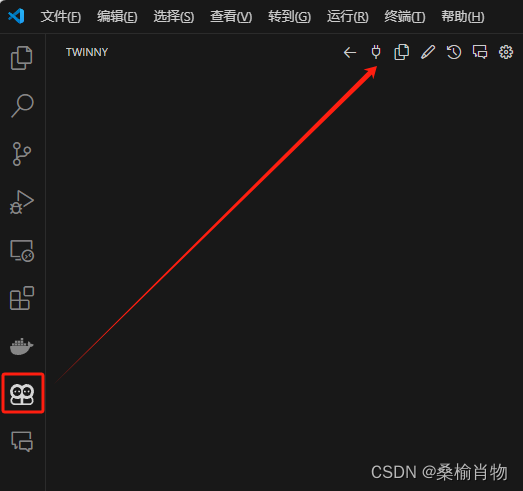
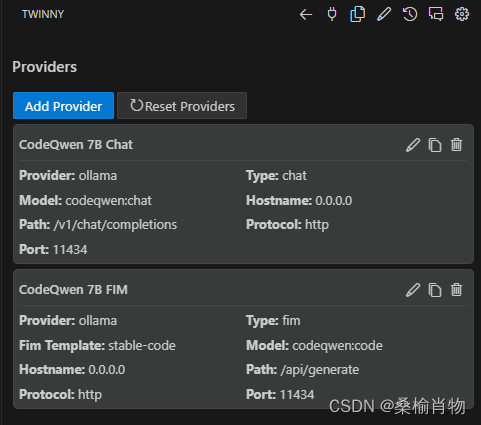
之后我们会看到两个默认的配置,一个用于 Chat 对话,一个用于 FIM 补全,我们需要逐个将其修改为刚刚拉取的 CodeQwen 模型即可。
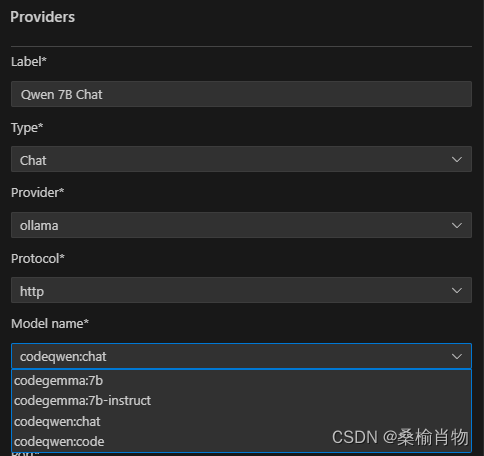
需要注意的是,FIM 模型的配置时,CodeQwen 的 Fim Template 需要设置为 stable-code。其使用的格式准则涉及使用三个专用标记,表示代码结构的相应段:<fim_prefix>、<fim_suffix>、<fim_middle>。
5.2 使用示例
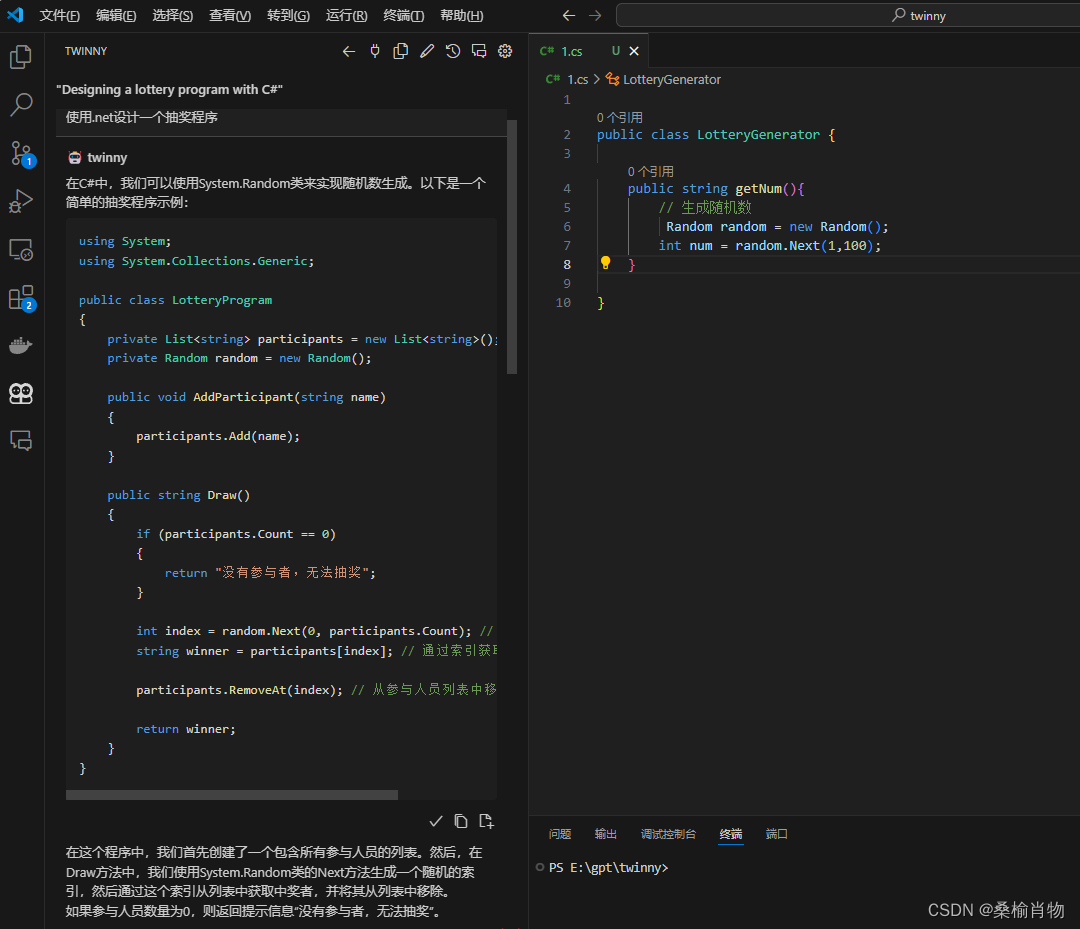
配置完成后,我们即可以开始使用 CodeQwen1.5 进行编程辅助。在编辑器中输入代码时,插件会自动弹出提示,只需要编写注释即可自动生成代码,非常方便。当然,我们也可以通过对话的方式与大模型进行交流,获取更多的帮助和建议。
5.2 高级功能
此外,CodeQwen1.5 还提供了一些当前 Twinny 插件尚未支持的能力,比如:存储库级代码完成。这个功能可以通过推理输入工作区的整个文件,帮助大模型更好地理解和处理代码。这对于处理复杂的代码文件和项目非常有用,可以帮助我们更快地找到问题和解决方案。
这个功能通过特殊的标记,可以输入多个代码文件:
<reponame>{repo_name}
<file_sep>{file_path1}
{file_content1}
<file_sep>{file_path2}
{file_content2}
这个功能类似于 Github Copilot 的 @workspace 指令,在官方的存储我们可以看到代码示例。
6. 总结
你的私人编码副驾驶已准备就绪,CodeQwen1.5 为你提供了一个强大的编程助手,它将成为你开发之旅中不可或缺的伙伴。如果你因为种种原因而无法使用 Github Copilot,那么 CodeQwen1.5 将是你的最佳选择。它的开源、透明、可访问、协作、道德规范、灵活性等优势,将为你的编程工作带来更多的便利和效率。