1接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5] 输出:9
提示:
n == height.length1 <= n <= 2 * 1040 <= height[i] <= 105
单调栈思路:
这个解法和之前给出的Python实现思路是相同的,只是采用了C++语言来实现,并且在处理相同高
-
找到每个柱子的左右边界:对于每个柱子,我们需要找到它的左右边界,这样才能确定它能够接多少雨水。左边界是指在当前柱子左侧且高度大于等于当前柱子高度的最近柱子,右边界是指在当前柱子右侧且高度大于等于当前柱子高度的最近柱子。
-
单调栈处理逻辑 主要就是三种情况
- 情况一:当前遍历的元素(柱子)高度小于栈顶元素的高度 height[i] < height[st.top()]
- 情况二:当前遍历的元素(柱子)高度等于栈顶元素的高度 height[i] == height[st.top()]
- 情况三:当前遍历的元素(柱子)高度大于栈顶元素的高度 height[i] > height[st.top()]
-
初始化栈:首先,我们创建了一个栈
st,用来存储数组中柱子的索引。我们从数组的第一个柱子开始遍历,将第一个柱子的索引压入栈中。 -
遍历数组:从数组的第二个柱子开始,我们开始遍历整个数组。
-
处理高度小于栈顶的情况:如果当前柱子的高度小于等于栈顶柱子的高度,我们将当前柱子的索引压入栈中,因为当前柱子无法形成凹槽,无法接水。
-
处理高度等于栈顶的情况:如果当前柱子的高度等于栈顶柱子的高度,我们将栈顶柱子的索引弹出,然后将当前柱子的索引压入栈中。这一步的作用是更新相同高度柱子的位置,因为无论哪个位置的柱子,对最后的结果没有影响。
-
处理高度大于栈顶的情况:如果当前柱子的高度大于栈顶柱子的高度,说明可能会形成凹槽,可以接雨水。我们不断弹出栈顶元素,直到栈为空或者当前柱子的高度小于等于栈顶柱子的高度。在弹出栈顶元素的过程中,我们计算相邻柱子之间能够接的雨水量,并累加到结果
sum中。 -
计算雨水量:在每次弹出栈顶元素时,我们计算当前柱子和栈顶元素之间的距离
w,以及能够接到的雨水高度h,然后将h * w累加到结果sum中。 -
更新栈:处理完当前柱子后,将当前柱子的索引压入栈中,继续处理下一个柱子。
-
返回结果:最后,当遍历完整个数组后,返回累加的结果
sum,即为能够接到的总雨水量。
代码:
class Solution {
public:
int trap(vector<int>& height) {
// 如果柱子数量小于等于2,则无法形成凹槽,无法接雨水,直接返回0
if (height.size() <= 2) return 0;
int sum = 0; // 存储能接到的总雨水量
stack<int> st; // 单调递减栈,用来存储柱子的索引
st.push(0); // 将第一个柱子的索引压入栈中
// 从数组的第二个柱子开始遍历
for (int i = 1; i < height.size(); i++) {
// 处理当前柱子高度小于等于栈顶柱子的情况
if (height[i] <= height[st.top()]) {
st.push(i); // 将当前柱子的索引压入栈中
}
// 处理当前柱子高度等于栈顶柱子的情况
else if (height[i] == height[st.top()]) {
st.pop(); // 可以不加,效果是一样的,但处理相同的情况的思路却变了。
st.push(i); // 将当前柱子的索引压入栈中,更新相同高度柱子的位置
}
// 处理当前柱子高度大于栈顶柱子的情况
else {
// 不断弹出栈顶元素,直到栈为空或者当前柱子的高度小于等于栈顶柱子的高度
while (!st.empty() && height[i] > height[st.top()]) {
int mid = st.top(); // 当前柱子的左边界
st.pop();
if (!st.empty()) {
// 计算能接到的雨水量
int h = min(height[st.top()], height[i]) - height[mid]; // 高度差
int w = i - st.top() - 1; // 宽度
sum += h * w; // 累加到结果中
}
}
st.push(i); // 将当前柱子的索引压入栈中
}
}
return sum; // 返回总雨水量
}
};2柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:

输入:heights = [2,1,5,6,2,3] 输出:10 解释:最大的矩形为图中红色区域,面积为 10
示例 2:
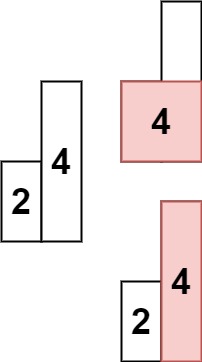
输入: heights = [2,4] 输出: 4
提示:
1 <= heights.length <=1050 <= heights[i] <= 104
单调栈思路:本题是要找每个柱子左右两边第一个小于该柱子的柱子,所以从栈头(元素从栈头弹出)到栈底的顺序应该是从大到小的顺序!
-
单调递减栈:创建一个单调递减栈,用于存储柱子的索引。栈内元素按照柱子的高度递减排列。
-
遍历柱子:从左到右遍历柱子,对于每个柱子,执行以下操作:
-
如果当前栈为空或者当前柱子的高度大于栈顶柱子的高度,则将当前柱子的索引压入栈中。这样可以保证栈内元素的高度是单调递减的,且每个柱子能找到其向左最近的比它低的柱子。
-
如果当前柱子的高度等于栈顶柱子的高度,则说明当前柱子和栈顶柱子的高度相同,这种情况下,栈顶元素的位置无关紧要,所以将栈顶柱子的索引弹出,然后将当前柱子的索引压入栈中,以更新相同高度柱子的位置。
-
如果当前柱子的高度小于栈顶柱子的高度,则说明当前柱子无法向右扩展形成更大的矩形面积。因此,需要不断弹出栈顶元素,直到栈为空或者当前柱子的高度大于栈顶柱子的高度为止。在弹出栈顶元素的过程中,可以计算以弹出柱子为高度的矩形的面积,并更新最大矩形面积。
-
-
计算矩形面积:在每次弹出栈顶元素时,计算以弹出柱子为高度的矩形的面积。矩形的宽度可以通过当前柱子的索引和栈顶元素的索引来计算。
-
更新最大矩形面积:每次计算出矩形的面积后,将其与当前的最大矩形面积进行比较,取较大值作为最大矩形面积。
-
返回结果:遍历完所有柱子后,得到的最大矩形面积即为所求结果。
在处理柱状图中最大矩形的问题时,在数组的两端加入高度为0的柱子是一种常用的技巧,这样做的目的是为了处理边界情况。
-
处理左边界情况:在数组的开头插入一个高度为0的柱子,这样做是为了确保整个数组都能被处理到。如果不在开头插入一个高度为0的柱子,那么对于数组的第一个柱子,它的左边界将无法确定。如果数组本身是降序的,例如 [8,6,4,2],在 8 入栈后,6 开始与8 进行比较,此时我们得到 mid(8),rigt(6),但是得不到 left。因为 将 8 弹出之后,栈里没有元素了,那么为了避免空栈取值,直接跳过了计算结果的逻辑。之后又将6 加入栈(此时8已经弹出了),然后 就是 4 与 栈口元素 8 进行比较,周而复始,那么计算的最后结果resutl就是0
-
处理右边界情况:在数组的末尾插入一个高度为0的柱子,这样做是为了确保所有柱子都能被弹出栈并计算对应的矩形面积。如果不在末尾插入一个高度为0的柱子,那么在遍历完所有柱子后,可能还会剩余一些柱子留在栈中,无法找到右边界。如果数组本身就是升序的,例如[2,4,6,8],那么入栈之后 都是单调递减,一直都没有走 当前遍历的元素heights[i]小于栈顶元素heights[st.top()]的情况 计算结果的哪一步,所以最后输出的就是0了
代码:
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
int result = 0; // 存储最大矩形面积的变量
stack<int> st; // 单调递增栈,用于存储柱子的索引
heights.insert(heights.begin(), 0); // 在柱子数组的开头插入一个高度为0的柱子,方便处理边界情况
heights.push_back(0); // 在柱子数组的末尾插入一个高度为0的柱子,方便处理边界情况
st.push(0); // 将第一个柱子的索引压入栈中
// 从第二个柱子开始遍历
for(int i = 1; i < heights.size(); i++) {
// 处理当前柱子高度大于栈顶柱子高度的情况
if(heights[i] > heights[st.top()]) {
st.push(i); // 将当前柱子的索引压入栈中
}
// 处理当前柱子高度等于栈顶柱子高度的情况
else if(heights[i] == heights[st.top()]) {
st.pop(); // 可以不加,效果是一样的,但处理相同的情况的思路却变了。
st.push(i); // 将当前柱子的索引压入栈中,更新相同高度柱子的位置
}
// 处理当前柱子高度小于栈顶柱子高度的情况
else {
// 不断弹出栈顶元素,直到栈为空或者当前柱子的高度大于栈顶柱子的高度
while(!st.empty() && heights[i] < heights[st.top()]) {
int mid = st.top(); // 当前柱子的索引,即矩形的高度
st.pop(); // 弹出栈顶元素
if(!st.empty()) {
int left = st.top(); // 左边界的索引
int right = i; // 右边界的索引
int w = right - left - 1; // 矩形的宽度
int h = heights[mid]; // 矩形的高度
result = max(result, w * h); // 更新最大矩形面积
}
}
st.push(i); // 将当前柱子的索引压入栈中
}
}
return result; // 返回最大矩形面积
}
};3销售分析III
表: Product
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | | unit_price | int | +--------------+---------+ product_id 是该表的主键(具有唯一值的列)。 该表的每一行显示每个产品的名称和价格。
表:Sales
+-------------+---------+ | Column Name | Type | +-------------+---------+ | seller_id | int | | product_id | int | | buyer_id | int | | sale_date | date | | quantity | int | | price | int | +------ ------+---------+ 这个表可能有重复的行。 product_id 是 Product 表的外键(reference 列)。 该表的每一行包含关于一个销售的一些信息。
编写解决方案,报告2019年春季才售出的产品。即仅在2019-01-01至2019-03-31(含)之间出售的商品。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入:
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
Sales table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
输出:
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
解释:
id 为 1 的产品仅在 2019 年春季销售。
id 为 2 的产品在 2019 年春季销售,但也在 2019 年春季之后销售。
id 为 3 的产品在 2019 年春季之后销售。
我们只返回 id 为 1 的产品,因为它是 2019 年春季才销售的产品。
思路:
-
选择需要的列:首先,我们从产品表(Product)中选择了产品ID(product_id)和产品名称(product_name)这两个列。
-
左连接销售表:通过使用 left join,我们将产品表和销售表(Sales)连接起来。这样做是为了获取销售信息,并且即使某些产品没有销售记录,也能够保留它们的信息。
-
根据产品ID分组:接着,我们使用 GROUP BY 子句,按照销售表中的产品ID进行分组。这样做是为了确保每个产品只出现一次,以便后续进行聚合操作。
-
筛选满足条件的数据:在 GROUP BY 后,我们使用 HAVING 子句来筛选满足特定条件的数据。这个条件是销售日期在 ‘2019-01-01’ 到 ‘2019-03-31’ 之间的产品。我们使用 MAX 函数和 MIN 函数来找到每个产品的最大销售日期和最小销售日期,并将其与指定的日期范围进行比较。
代码:
-- 选择产品表中的产品ID和产品名称
select p.product_id, p.product_name
-- 从产品表(Product)中选择数据,并左连接销售表(Sales)
from Product as p
left join Sales as s
on p.product_id = s.product_id
-- 根据销售表中的产品ID进行分组
group by s.product_id
-- 使用 HAVING 子句筛选满足条件的数据,即销售日期在指定范围内的产品
having max(s.sale_date) <= '2019-03-31' and min(s.sale_date) >= '2019-01-01';4查询近30天活跃用户数
表:Activity
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
+---------------+---------+
该表没有包含重复数据。
activity_type 列是 ENUM(category) 类型, 从 ('open_session', 'end_session', 'scroll_down', 'send_message') 取值。
该表记录社交媒体网站的用户活动。
注意,每个会话只属于一个用户。
编写解决方案,统计截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。
以 任意顺序 返回结果表。
结果示例如下。
示例 1:
输入: Activity table: +---------+------------+---------------+---------------+ | user_id | session_id | activity_date | activity_type | +---------+------------+---------------+---------------+ | 1 | 1 | 2019-07-20 | open_session | | 1 | 1 | 2019-07-20 | scroll_down | | 1 | 1 | 2019-07-20 | end_session | | 2 | 4 | 2019-07-20 | open_session | | 2 | 4 | 2019-07-21 | send_message | | 2 | 4 | 2019-07-21 | end_session | | 3 | 2 | 2019-07-21 | open_session | | 3 | 2 | 2019-07-21 | send_message | | 3 | 2 | 2019-07-21 | end_session | | 4 | 3 | 2019-06-25 | open_session | | 4 | 3 | 2019-06-25 | end_session | +---------+------------+---------------+---------------+ 输出: +------------+--------------+ | day | active_users | +------------+--------------+ | 2019-07-20 | 2 | | 2019-07-21 | 2 | +------------+--------------+ 解释:注意非活跃用户的记录不需要展示。
代码:
-- 选择活动日期(activity_date)作为日期,以及计算每天活跃用户的数量
select activity_date as day, count(distinct user_id) as active_users
-- 从活动表(Activity)中选择数据
from Activity
-- 筛选出日期在 '2019-06-28' 到 '2019-07-27' 之间的记录
where activity_date <= '2019-07-27' and activity_date > '2019-06-27'
-- 根据活动日期进行分组
group by activity_date;5 文章浏览 I
Views 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | article_id | int | | author_id | int | | viewer_id | int | | view_date | date | +---------------+---------+ 此表可能会存在重复行。(换句话说,在 SQL 中这个表没有主键) 此表的每一行都表示某人在某天浏览了某位作者的某篇文章。 请注意,同一人的 author_id 和 viewer_id 是相同的。
请查询出所有浏览过自己文章的作者
结果按照 id 升序排列。
查询结果的格式如下所示:
示例 1:
输入: Views 表: +------------+-----------+-----------+------------+ | article_id | author_id | viewer_id | view_date | +------------+-----------+-----------+------------+ | 1 | 3 | 5 | 2019-08-01 | | 1 | 3 | 6 | 2019-08-02 | | 2 | 7 | 7 | 2019-08-01 | | 2 | 7 | 6 | 2019-08-02 | | 4 | 7 | 1 | 2019-07-22 | | 3 | 4 | 4 | 2019-07-21 | | 3 | 4 | 4 | 2019-07-21 | +------------+-----------+-----------+------------+ 输出: +------+ | id | +------+ | 4 | | 7 | +------+
代码:
select distinct author_id as id
from Views
where author_id = viewer_id
order by 1;