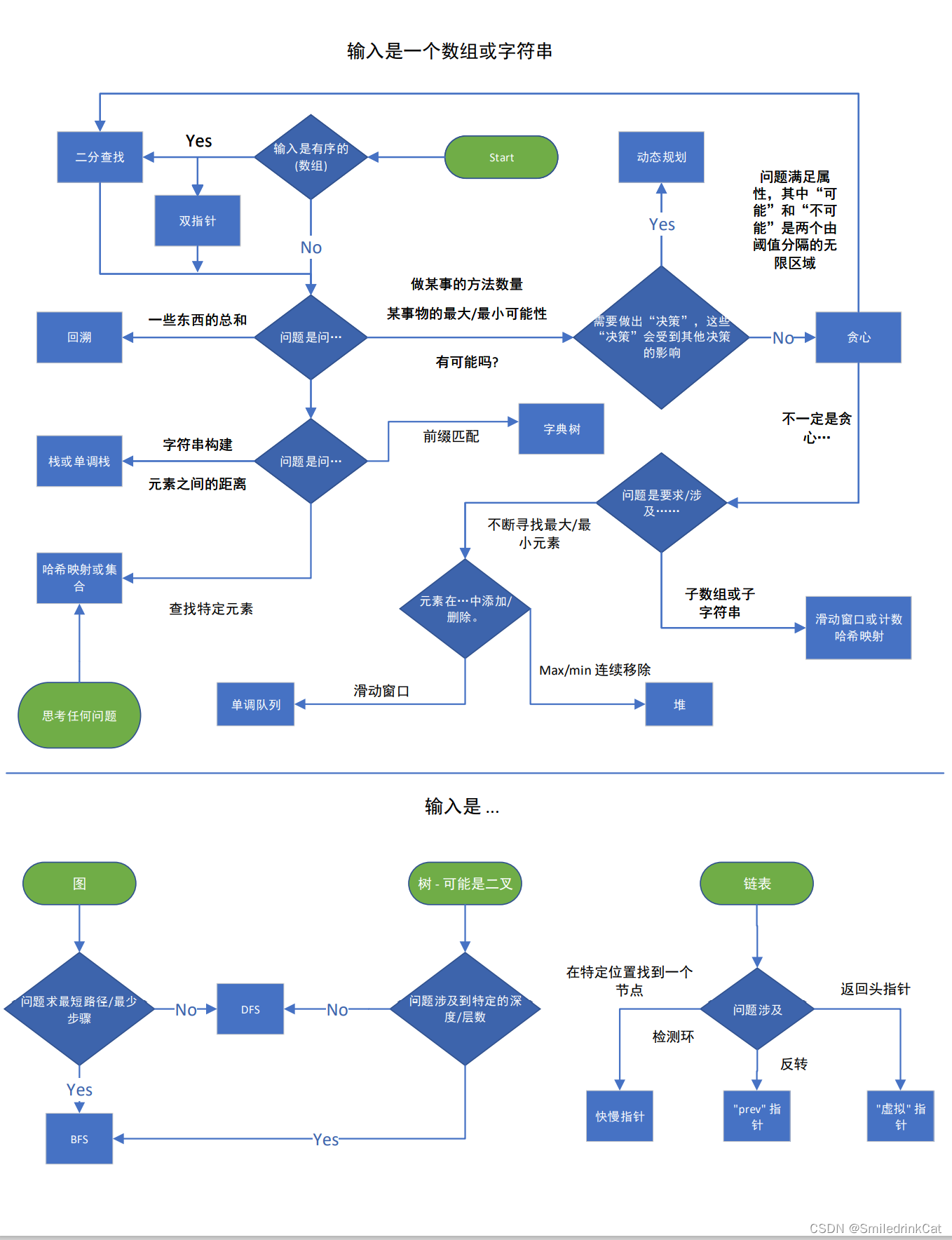
原文:
zh.annas-archive.org/md5/66ae3d5970b9b38c5ad770b42fec806d译者:飞龙
协议:CC BY-NC-SA 4.0
第四章:列表和指针结构
我们已经在 Python 中讨论了列表,它们方便而强大。通常情况下,我们使用 Python 内置的列表实现来存储任何数据。然而,在本章中,我们将了解列表的工作原理,并将研究列表的内部。
Python 的列表实现非常强大,可以包含多种不同的用例。节点的概念在列表中非常重要。我们将在本章讨论它们,并在整本书中引用它们。因此,我们建议读者仔细学习本章的内容。
本章的重点将是以下内容:
-
理解 Python 中的指针
-
理解节点的概念和实现
-
实现单向、双向和循环链表。
技术要求
根据本章讨论的概念执行程序将有助于更好地理解它们。我们已经提供了本章中所有程序和概念的源代码。我们还在 GitHub 上提供了完整的源代码文件,链接如下:github.com/PacktPublishing/Hands-On-Data-Structures-and-Algorithms-with-Python-Second-Edition/tree/master/Chapter04。
我们假设您已经在系统上安装了 Python。
从一个例子开始
让我们先提醒一下指针的概念,因为我们将在本章中处理它们。首先,想象一下你有一所房子想要卖掉。由于时间不够,你联系了一个中介来寻找感兴趣的买家。所以,你拿起你的房子,把它带到中介那里,中介会把房子带给任何可能想要买它的人。你觉得这很荒谬?现在想象一下你有一些处理图像的 Python 函数。所以,你在这些函数之间传递高分辨率图像数据。
当然,你不会带着你的房子四处走动。你要做的是把房子的地址写在一张废纸上,递给中介。房子还在原地,但包含房子地址的纸条在传递。你甚至可以在几张纸上写下来。每张纸都足够小,可以放在你的钱包里,但它们都指向同一所房子。
事实证明,在 Python 领域情况并没有太大不同。那些大型图像文件仍然在内存中的一个地方。
你要做的是创建变量,保存这些图像在内存中的位置。这些变量很小,可以在不同的函数之间轻松传递。
这就是指针的好处——它们允许你用一个简单的内存地址指向一个潜在的大内存段。
你的计算机硬件中支持指针,这被称为间接寻址。
在 Python 中,你不会直接操作指针,不像其他一些语言,比如 C 或 Pascal。这导致一些人认为 Python 中不使用指针。这是大错特错。考虑一下在 Python 交互式 shell 中的这个赋值:
>>> s = set()
通常我们会说s是集合类型的变量。也就是说,s是一个集合。然而,这并不严格正确;变量s实际上是一个引用(一个安全指针)指向一个集合。集合构造函数在内存中创建一个集合,并返回该集合开始的内存位置。这就是存储在s中的内容。Python 隐藏了这种复杂性。我们可以安全地假设s是一个集合,一切都运行正常。
数组
数组是一系列数据的顺序列表。顺序意味着每个元素都存储在前一个元素的后面。如果你的数组非常大,而且内存不足,可能无法找到足够大的存储空间来容纳整个数组。这将导致问题。
当然,硬币的另一面是数组非常快速。由于每个元素在内存中紧随前一个元素,因此无需在不同的内存位置之间跳转。在选择在你自己的现实世界应用程序中列表和数组之间时,这可能是一个非常重要的考虑因素。
我们已经在第二章中讨论了数组,Python 数据类型和结构。我们看了数组数据类型,并讨论了可以对其执行的各种操作。
指针结构
与数组相反,指针结构是可以在内存中分散的项目列表。这是因为每个项目都包含一个或多个指向结构中其他项目的链接。这些链接的类型取决于我们拥有的结构类型。如果我们处理的是链表,那么我们将有指向结构中下一个(可能是上一个)项目的链接。在树的情况下,我们有父子链接以及兄弟链接。
指针结构有几个好处。首先,它们不需要顺序存储空间。其次,它们可以从小开始,随着向结构添加更多节点而任意增长。然而,指针的这种灵活性是有代价的。我们需要额外的空间来存储地址。例如,如果你有一个整数列表,每个节点都将占用空间来存储一个整数,以及额外的整数来存储指向下一个节点的指针。
节点
在列表(以及其他几种数据结构)的核心是节点的概念。在我们进一步讨论之前,让我们考虑一下这个想法。
首先,让我们考虑一个例子。我们将创建一些字符串:
>>> a = "eggs"
>>> b = "ham"
>>> c = "spam"
现在你有了三个变量,每个变量都有一个唯一的名称、类型和值。目前,没有办法显示这些变量之间的关系。节点允许我们展示这些变量之间的关系。节点是数据的容器,以及一个或多个指向其他节点的链接。链接就是指针。
一种简单类型的节点只有一个指向下一个节点的链接。正如我们所知道的指针,字符串实际上并没有存储在节点中,而是有一个指向实际字符串的指针。考虑下面的图表中的例子,其中有两个节点。第一个节点有一个指向存储在内存中的字符串(eggs)的指针,另一个指针存储着另一个节点的地址:

因此,这个简单节点的存储需求是两个内存地址。节点的数据属性是指向字符串eggs和ham的指针。
查找端点
我们已经创建了三个节点——一个包含eggs,一个ham,另一个spam。eggs节点指向ham节点,ham节点又指向spam节点。但是spam节点指向什么呢?由于这是列表中的最后一个元素,我们需要确保它的下一个成员有一个清晰的值。
如果我们使最后一个元素指向空,那么我们就清楚地表明了这一事实。在 Python 中,我们将使用特殊值None来表示空。考虑下面的图表。节点B是列表中的最后一个元素,因此它指向None:

最后一个节点的下一个指针指向None。因此,它是节点链中的最后一个节点。
节点类
这是我们迄今为止讨论的一个简单节点实现:
class Node:
def __init__ (self, data=None):
self.data = data
self.next = None
Next指针初始化为None,这意味着除非你改变Next的值,否则节点将成为一个端点。这是一个很好的主意,这样我们就不会忘记正确终止列表。
你可以根据需要向节点类添加其他内容。只要记住节点和数据之间的区别。如果你的节点将包含客户数据,那么创建一个Customer类,并把所有数据放在那里。
您可能想要做的一件事是实现_str_方法,以便在将节点对象传递给打印时调用所包含对象的_str_方法:
def _str_ (self):
return str(data)
其他节点类型
正如我们已经讨论过的,一个节点具有指向下一个节点的指针来链接数据项,但它可能是最简单的节点类型。此外,根据我们的需求,我们可以创建许多其他类型的节点。
有时我们想从节点A到节点B,但同时我们可能需要从节点B到节点A。在这种情况下,我们除了Next指针之外还添加了Previous指针:

从上图可以看出,我们除了数据和Next指针之外,还创建了Previous指针。还需要注意的是,B的Next指针是None,而节点A的Previous指针也是None,这表示我们已经到达了列表的边界。第一个节点A的前指针指向None,因为它没有前驱,就像最后一个项目B的Next指针指向None一样,因为它没有后继节点。
引入列表
列表是一个重要且流行的数据结构。列表有三种类型——单链表、双链表和循环链表。我们将在本章更详细地讨论这些数据结构。我们还将在接下来的小节中讨论各种重要操作,如append操作、delete操作以及可以在这些列表上执行的traversing和searching操作。
单链表
单链表是一种只有两个连续节点之间的指针的列表。它只能以单个方向遍历;也就是说,您可以从列表中的第一个节点到最后一个节点,但不能从最后一个节点移动到第一个节点。
实际上,我们可以使用之前创建的节点类来实现一个非常简单的单链表。例如,我们创建三个存储三个字符串的节点n1、n2和n3:
>>> n1 = Node('eggs')
>>> n2 = Node('ham')
>>> n3 = Node('spam')
接下来,我们将节点链接在一起,形成一个链:
>>> n1.next = n2
>>> n2.next = n3
要遍历列表,您可以像下面这样做。我们首先将current变量设置为列表中的第一个项目,然后通过循环遍历整个列表,如下面的代码所示:
current = n1
while current:
print(current.data)
current = current.next
在循环中,我们打印出当前元素,然后将current设置为指向列表中的下一个元素。我们一直这样做,直到我们到达列表的末尾。
然而,这种简单的列表实现存在几个问题:
-
程序员需要做太多的手动工作
-
这太容易出错了(这是第一点的结果)
-
列表的内部工作过于暴露给程序员
我们将在接下来的章节中解决所有这些问题。
单链表类
列表是一个与节点不同的概念。我们首先创建一个非常简单的类来保存我们的列表。我们从一个构造函数开始,它保存对列表中第一个节点的引用(在下面的代码中是tail)。由于这个列表最初是空的,我们将首先将这个引用设置为None:
class SinglyLinkedList:
def __init__ (self):
self.tail = None
追加操作
我们需要执行的第一个操作是向列表追加项目。这个操作有时被称为插入操作。在这里,我们有机会隐藏Node类。我们的列表类的用户实际上不应该与Node对象交互。这些纯粹是内部使用的。
第一次尝试append()方法可能如下所示:
class SinglyLinkedList:
# ...
def append(self, data):
# Encapsulate the data in a Node
node = Node(data)
if self.tail == None:
self.tail = node
else:
current = self.tail
while current.next:
current = current.next
current.next = node
我们封装数据在一个节点中,以便它具有下一个指针属性。从这里开始,我们检查列表中是否存在任何现有节点(即self.tail是否指向一个Node)。如果是None,我们将新节点设置为列表的第一个节点;否则,我们通过遍历列表找到插入点,将最后一个节点的下一个指针更新为新节点。
考虑以下示例代码以追加三个节点:
>>> words = SinglyLinkedList()
>>> words.append('egg')
>>> words.append('ham')
>>> words.append('spam')
列表遍历将按照我们之前讨论的方式进行。您将从列表本身获取列表的第一个元素,然后通过next指针遍历列表:
>>> current = words.tail
>>> while current:
print(current.data)
current = current.next
更快的追加操作
在前一节中,追加方法存在一个大问题:它必须遍历整个列表以找到插入点。当列表中只有一些项目时,这可能不是问题,但当列表很长时,这将是一个大问题,因为我们需要每次遍历整个列表来添加一个项目。每次追加都会比上一次略慢。追加操作的当前实现速度降低了O(n),这在长列表的情况下是不可取的。
为了解决这个问题,我们不仅存储了对列表中第一个节点的引用,还存储了对最后一个节点的引用。这样,我们可以快速地在列表的末尾追加一个新节点。追加操作的最坏情况运行时间现在从O(n)降低到了O(1)。我们所要做的就是确保前一个最后一个节点指向即将追加到列表中的新节点。以下是我们更新后的代码:
class SinglyLinkedList:
def init (self):
# ...
self.tail = None
def append(self, data):
node = Node(data)
if self.head:
self.head.next = node
self.head = node
else:
self.tail = node
self.head = node
请注意正在使用的约定。我们追加新节点的位置是通过self.head。self.tail变量指向列表中的第一个节点。
获取列表的大小
我们希望能够通过计算节点的数量来获取列表的大小。我们可以通过遍历整个列表并在遍历过程中增加一个计数器来实现这一点:
def size(self):
count = 0
current = self.tail
while current:
count += 1
current = current.next
return count
这很好用。但是,列表遍历可能是一个昂贵的操作,我们应该尽量避免。因此,我们将选择另一种重写方法。我们在SinglyLinkedList类中添加一个 size 成员,在构造函数中将其初始化为0。然后我们在追加方法中将 size 增加一:
class SinglyLinkedList:
def init (self):
# ...
self.size = 0
def append(self, data):
# ...
self.size += 1
因为我们现在只是读取节点对象的 size 属性,而不是使用循环来计算列表中节点的数量,所以我们将最坏情况的运行时间从O(n)降低到了O(1)。
改进列表遍历
如果您注意到,在列表遍历的早期,我们向客户/用户公开了节点类。但是,希望客户端节点不要与节点对象进行交互。我们需要使用node.data来获取节点的内容,使用node.next来获取下一个节点。我们可以通过创建一个返回生成器的方法来访问数据。如下所示:
def iter(self):
current = self.tail
while current:
val = current.data
current = current.next
yield val
现在,列表遍历变得简单得多,看起来也好得多。我们可以完全忽略列表之外有一个叫做节点的东西:
for word in words.iter():
print(word)
注意,由于iter()方法产生节点的数据成员,我们的客户端代码根本不需要担心这一点。
删除节点
您将在列表上执行的另一个常见操作是删除节点。这可能看起来很简单,但我们首先必须决定如何选择要删除的节点。它是由索引号还是由节点包含的数据来确定的?在这里,我们将选择根据节点包含的数据来删除节点。
以下是在从列表中删除节点时考虑的特殊情况的图示:

当我们想要删除两个节点之间的一个节点时,我们所要做的就是使前一个节点指向其下一个要删除的节点的后继节点。也就是说,我们只需将要删除的节点从链表中切断,并直接指向下一个节点,如前面的图所示。
delete()方法的实现可能如下所示:
def delete(self, data):
current = self.tail
prev = self.tail
while current:
if current.data == data:
if current == self.tail:
self.tail = current.next
else:
prev.next = current.next
self.count -= 1
return
prev = current
current = current.next
删除节点的delete操作的时间复杂度为O(n)。
列表搜索
我们可能还需要一种方法来检查列表是否包含某个项目。由于我们之前编写的iter()方法,这种方法非常容易实现。循环的每次通过将当前数据与正在搜索的数据进行比较。如果找到匹配项,则返回True,否则返回False:
def search(self, data):
for node in self.iter():
if data == node:
return True
return False
清除列表
我们可能需要快速清除列表;有一种非常简单的方法可以做到。我们可以通过简单地将指针头和尾清除为None来清除列表:
def clear(self):
""" Clear the entire list. """
self.tail = None
self.head = None
双向链表
我们已经讨论了单链表以及可以在其上执行的重要操作。现在,我们将在本节中专注于双向链表的主题。
双向链表与单链表非常相似,因为我们使用了将字符串节点串在一起的相同基本概念,就像在单链表中所做的那样。单链表和双链表之间唯一的区别在于,在单链表中,每个连续节点之间只有一个链接,而在双链表中,我们有两个指针——一个指向下一个节点,一个指向前一个节点。请参考以下节点的图表;有一个指向下一个节点和前一个节点的指针,它们设置为None,因为没有节点连接到这个节点。考虑以下图表:

单链表中的节点只能确定与其关联的下一个节点。然而,没有办法或链接可以从这个引用节点返回。流动的方向只有一种。
在双向链表中,我们解决了这个问题,并且不仅可以引用下一个节点,还可以引用前一个节点。考虑以下示例图表,以了解两个连续节点之间链接的性质。这里,节点A引用节点B;此外,还有一个链接返回到节点A:

由于存在指向下一个和前一个节点的两个指针,双向链表具有某些功能。
双向链表可以在任何方向进行遍历。在双向链表中,可以很容易地引用节点的前一个节点,而无需使用变量来跟踪该节点。然而,在单链表中,可能难以返回到列表的开始或开头,以便在列表的开头进行一些更改,而在双向链表的情况下现在非常容易。
双向链表节点
创建双向链表节点的 Python 代码包括其初始化方法、prev指针、next指针和data实例变量。当新建一个节点时,所有这些变量默认为None:
class Node(object):
def __init__ (self, data=None, next=None, prev=None):
self.data = data
self.next = next
self.prev = prev
prev变量引用前一个节点,而next变量保留对下一个节点的引用,data变量存储数据。
双向链表类
双向链表类捕获了我们的函数将要操作的数据。对于size方法,我们将计数实例变量设置为0;它可以用来跟踪链表中的项目数量。当我们开始向列表中插入节点时,head和tail将指向列表的头部和尾部。考虑以下用于创建类的 Python 代码:
class DoublyLinkedList(object):
def init (self):
self.head = None
self.tail = None
self.count = 0
我们采用了一个新的约定,其中self.head指向列表的起始节点,而self.tail指向添加到列表中的最新节点。这与我们在单链表中使用的约定相反。关于头部和尾部节点指针的命名没有固定的规则。
双链表还需要返回列表大小、向列表中插入项目以及从列表中删除节点的功能。我们将在以下子部分中讨论并提供关于双链表的重要功能和代码。让我们从附加操作开始。
附加操作
append操作用于在列表的末尾添加元素。重要的是要检查列表的head是否为None。如果是None,则表示列表为空,否则列表有一些节点,并且将向列表添加一个新节点。如果要向空列表添加新节点,则应将head指向新创建的节点,并且列表的尾部也应通过head指向该新创建的节点。经过这一系列步骤,头部和尾部现在将指向同一个节点。以下图示了当向空列表添加新节点时,双链表的head和tail指针:

以下代码用于将项目附加到双链表:
def append(self, data):
""" Append an item to the list. """
new_node = Node(data, None, None)
if self.head is None:
self.head = new_node
self.tail = self.head
else:
new_node.prev = self.tail
self.tail.next = new_node
self.tail = new_node
self.count += 1
上述程序的If部分用于将节点添加到空节点;如果列表不为空,则将执行上述程序的else部分。如果要将新节点添加到列表中,则新节点的前一个变量应设置为列表的尾部:
new_node.prev = self.tail
尾部的下一个指针(或变量)必须设置为新节点:
self.tail.next = new_node
最后,我们更新尾部指针以指向新节点:
self.tail = new_node
由于附加操作将节点数增加一,因此我们将计数器增加一:
self.count += 1
以下图示了向现有列表附加操作的可视表示:

删除操作
与单链表相比,双链表中的删除操作更容易。
与单链表不同,我们需要在遍历整个列表的整个长度时始终跟踪先前遇到的节点,双链表避免了整个步骤。这是通过使用前一个指针实现的。
在双链表中,delete操作可能会遇到以下四种情况:
-
未找到要删除的搜索项在列表中
-
要删除的搜索项位于列表的开头
-
要删除的搜索项位于列表的末尾
-
要删除的搜索项位于列表的中间
要删除的节点是通过将数据实例变量与传递给方法的数据进行匹配来识别的。如果数据与节点的数据变量匹配,则将删除该匹配的节点。以下是从双链表中删除节点的完整代码。我们将逐步讨论此代码的每个部分:
def delete(self, data):
""" Delete a node from the list. """
current = self.head
node_deleted = False
if current is None: #Item to be deleted is not found in the list
node_deleted = False
elif current.data == data: #Item to be deleted is found at starting of list
self.head = current.next
self.head.prev = None
node_deleted = True
elif self.tail.data == data: #Item to be deleted is found at the end of list.
self.tail = self.tail.prev
self.tail.next = None
node_deleted = True
else:
while current: #search item to be deleted, and delete that node
if current.data == data:
current.prev.next = current.next
current.next.prev = current.prev
node_deleted = True
current = current.next
if node_deleted:
self.count -= 1
最初,我们创建一个node_deleted变量来表示列表中被删除的节点,并将其初始化为False。如果找到匹配的节点并随后删除,则将node_deleted变量设置为True。在删除方法中,current变量最初设置为列表的head(即指向列表的self.head)。请参阅以下代码片段:
def delete(self, data):
current = self.head
node_deleted = False
...
接下来,我们使用一组if...else语句来搜索列表的各个部分,找出具有指定数据的节点,该节点将被删除。
首先,我们在head节点处搜索要删除的数据,如果在head节点处匹配数据,则将删除该节点。由于current指向head,如果current为None,则表示列表为空,没有节点可以找到要删除的节点。以下是其代码片段:
if current is None:
node_deleted = False
但是,如果current(现在指向头部)包含正在搜索的数据,这意味着我们在head节点找到了要删除的数据,那么self.head被标记为指向current节点。由于现在head后面没有节点了,self.head.prev被设置为None。考虑以下代码片段:
elif current.data == data:
self.head = current.next
self.head.prev = None
node_deleted = True
同样,如果要删除的节点位于列表的“尾部”,我们通过将其前一个节点指向None来删除最后一个节点。这是双向链表中“删除”操作的第三种可能情况,搜索要删除的节点可能在列表末尾找到。self.tail被设置为指向self.tail.prev,self.tail.next被设置为None,因为后面没有节点了。考虑以下代码片段:
elif self.tail.data == data:
self.tail = self.tail.prev
self.tail.next = None
node_deleted = True
最后,我们通过循环整个节点列表来搜索要删除的节点。如果要删除的数据与节点匹配,则删除该节点。要删除节点,我们使用代码current.prev.next = current.next使current节点的前一个节点指向当前节点的下一个节点。在那之后,我们使用current.next.prev = current.prev使current节点的下一个节点指向current节点的前一个节点。考虑以下代码片段:
else
while current:
if current.data == data:
current.prev.next = current.next
current.next.prev = current.prev
node_deleted = True
current = current.next
为了更好地理解双向链表中的删除操作的概念,请考虑以下示例图。在下图中,有三个节点,A,B和C。要删除列表中间的节点B,我们实质上会使A指向C作为其下一个节点,同时使C指向A作为其前一个节点:

进行此操作后,我们得到以下列表:

最后,检查node_delete变量以确定是否实际删除了节点。如果删除了任何节点,则将计数变量减少1,这可以跟踪列表中节点的总数。以下代码片段减少了删除任何节点时的计数变量1:
if node_deleted:
self.count -= 1
列表搜索
在双向链表中搜索项目与在单向链表中的方式类似。我们使用iter()方法来检查所有节点中的数据。当我们遍历列表中的所有数据时,每个节点都与contain方法中传递的数据进行匹配。如果我们在列表中找到项目,则返回True,表示找到了该项目,否则返回False,这意味着在列表中未找到该项目。其 Python 代码如下:
def contain(self, data):
for node_data in self.iter():
if data == node_data:
return True
return False
双向链表中的追加操作具有运行时间复杂度O(1),删除操作具有复杂度O(n)。
循环列表
循环链表是链表的特殊情况。在循环链表中,端点彼此相连。这意味着列表中的最后一个节点指向第一个节点。换句话说,我们可以说在循环链表中,所有节点都指向下一个节点(在双向链表的情况下还指向前一个节点),没有结束节点,因此没有节点将指向Null。循环列表可以基于单向链表和双向链表。在双向循环链表的情况下,第一个节点指向最后一个节点,最后一个节点指向第一个节点。考虑以下基于单向链表的循环链表的图示,其中最后一个节点C再次连接到第一个节点A,从而形成循环列表:

下图显示了基于双向链表的循环链表概念,其中最后一个节点C通过next指针再次连接到第一个节点A。节点A也通过previous指针连接到节点C,从而形成一个循环列表:

在这里,我们将看一个单链表循环列表的实现。一旦我们理解了基本概念,实现双链表循环列表应该是直截了当的。
我们可以重用我们在子节中创建的节点类——单链表。事实上,我们也可以重用大部分SinglyLinkedList类的部分。因此,我们将专注于循环列表实现与普通单链表不同的方法。
追加元素
要在单链表循环列表中追加一个元素,我们只需包含一个新功能,使新添加或追加的节点指向tail节点。这在以下代码中得到了演示。与单链表实现相比,多了一行额外的代码,如粗体所示:
def append(self, data):
node = Node(data)
if self.head:
self.head.next = node
self.head = node
else:
self.head = node
self.tail = node
self.head.next = self.tail
self.size += 1
在循环列表中删除元素
要删除循环列表中的一个节点,看起来我们可以类似于在追加操作中所做的方式来做。只需确保head指向tail。在删除操作中只有一行需要更改。只有当我们删除tail节点时,我们需要确保head节点被更新为指向新的尾节点。这将给我们以下实现(粗体字代码行是单链表中删除操作实现的一个补充):
def delete(self, data):
current = self.tail
prev = self.tail
while current:
if current.data == data:
if current == self.tail:
self.tail = current.next
self.head.next = self.tail
else:
prev.next = current.next
self.size -= 1
return
prev = current
current = current.next
然而,这段代码存在一个严重的问题。在循环列表的情况下,我们不能循环直到current变成None,因为在循环链表的情况下,当前节点永远不会指向None。如果删除一个现有节点,你不会看到这一点,但是尝试删除一个不存在的节点,你将陷入无限循环。
因此,我们需要找到一种不同的方法来控制while循环。我们不能检查current是否已经到达head,因为那样它永远不会检查最后一个节点。但我们可以使用prev,因为它比current落后一个节点。然而,有一个特殊情况。在第一个循环迭代中,current和prev将指向相同的节点,即尾节点。我们希望确保循环在这里运行,因为我们需要考虑单节点列表。更新后的删除方法现在如下所示:
def delete(self, data):
current = self.tail
prev = self.tail
while prev == current or prev != self.head:
if current.data == data:
if current == self.tail:
self.tail = current.next
self.head.next = self.tail
else:
prev.next = current.next
self.size -= 1
return
prev = current
current = current.next
遍历循环列表
遍历循环链表非常方便,因为我们不需要寻找起始点。我们可以从任何地方开始,只需要在再次到达相同节点时小心停止遍历。我们可以使用我们在本章开头讨论过的iter()方法。它应该适用于我们的循环列表;唯一的区别是在遍历循环列表时,我们必须提及一个退出条件,否则程序将陷入循环并无限运行。我们可以通过使用一个计数变量来创建一个退出条件。考虑以下示例代码:
words = CircularList()
words.append('eggs')
words.append('ham')
words.append('spam')
counter = 0
for word in words.iter():
print(word)
counter += 1
if counter > 1000:
break
一旦我们打印出 1,000 个元素,我们就会跳出循环。
总结
在本章中,我们研究了链表。我们学习了列表的基本概念,如节点和指向其他节点的指针。我们实现了这些类型列表中发生的主要操作,并看到了最坏情况的运行时间是如何比较的。
在下一章中,我们将看两种通常使用列表实现的其他数据结构——栈和队列。
第五章:栈和队列
在本章中,我们将在上一章学到的技能基础上创建特殊的列表实现。我们仍然坚持使用线性结构。在接下来的章节中,我们将深入了解更复杂的数据结构的细节。
在本章中,我们将了解栈和队列的概念。我们还将使用各种方法在 Python 中实现这些数据结构,如lists和node。
在本章中,我们将涵盖以下内容:
-
使用各种方法实现栈和队列
-
栈和队列的一些真实应用示例
技术要求
你应该有一台安装了 Python 的计算机系统。本章讨论的概念的所有程序都在书中提供,也可以在以下链接的 GitHub 存储库中找到:github.com/PacktPublishing/Hands-On-Data-Structures-and-Algorithms-with-Python-Second-Edition/tree/master/Chapter05。
栈
栈是一种存储数据的数据结构,类似于厨房里的一堆盘子。你可以把一个盘子放在栈的顶部,当你需要一个盘子时,你从栈的顶部拿走它。最后添加到栈上的盘子将首先从栈中取出。同样,栈数据结构允许我们从一端存储和读取数据,最后添加的元素首先被取出。因此,栈是一种后进先出(LIFO)结构:

前面的图表描述了一堆盘子。只有将一个盘子放在堆的顶部才有可能添加一个盘子。从盘子堆中移除一个盘子意味着移除堆顶上的盘子。
栈上执行的两个主要操作是push和pop。当元素被添加到栈顶时,它被推送到栈上。当要从栈顶取出元素时,它被弹出栈。有时使用的另一个操作是peek,它可以查看栈顶的元素而不将其弹出。
栈用于许多事情。栈的一个非常常见的用途是在函数调用期间跟踪返回地址。假设我们有以下程序:
def b():
print('b')
def a():
b()
a()
print("done")
当程序执行到a()的调用时,发生以下情况:
-
首先将当前指令的地址推送到栈上,然后跳转到
a的定义 -
在函数
a()内部,调用函数b() -
函数
b()的返回地址被推送到栈上 -
一旦
b()函数和函数执行完毕,返回地址将从栈中弹出,这将带我们回到函数a()。 -
当函数
a中的所有指令完成时,返回地址再次从栈中弹出,这将带我们回到main函数和print语句
栈也用于在函数之间传递数据。考虑以下示例。假设你的代码中有以下函数调用:
somefunc(14, 'eggs', 'ham', 'spam')
内部发生的是,函数传递的值14, 'eggs', 'ham'和'spam'将依次被推送到栈上,如下图所示:

当代码调用jump到函数定义时,a, b, c, d的值将从栈中弹出。首先弹出spam元素并赋值给d,然后将ham赋值给c,依此类推:
def somefunc(a, b, c, d):
print("function executed")
栈实现
栈可以使用节点在 Python 中实现。我们首先创建一个node类,就像在上一章中使用列表一样:
class Node:
def __init__(self, data=None):
self.data = data
self.next = None
正如我们讨论的,一个节点包含数据和列表中下一个项目的引用。在这里,我们将实现一个栈而不是列表;然而,节点的相同原则在这里也适用——节点通过引用链接在一起。
现在让我们来看一下stack类。它的开始方式与单链表类似。我们需要两样东西来实现使用节点的栈:
-
首先,我们需要知道位于栈顶的节点,以便我们能够通过这个节点应用
push和pop操作。 -
我们还希望跟踪栈中节点的数量,因此我们向栈类添加一个
size变量。考虑以下代码片段用于栈类:
class Stack:
def __init__(self):
self.top = None
self.size = 0
推送操作
push操作是栈上的一个重要操作;它用于在栈顶添加一个元素。我们在 Python 中实现推送功能以了解它是如何工作的。首先,我们检查栈是否已经有一些项目或者它是空的,当我们希望在栈中添加一个新节点时。
如果栈已经有一些元素,那么我们需要做两件事:
-
新节点必须使其下一个指针指向先前位于顶部的节点。
-
我们通过将
self.top指向新添加的节点,将这个新节点放在栈的顶部。请参阅以下图表中的两条指令:

如果现有栈为空,并且要添加的新节点是第一个元素,我们需要将此节点作为元素的顶部节点。因此,self.top将指向这个新节点。请参阅以下图表:

以下是stack中push操作的完整实现:
def push(self, data):
node = Node(data)
if self.top:
node.next = self.top
self.top = node
else:
self.top = node
self.size += 1
弹出操作
现在,我们需要栈的另一个重要功能,那就是pop操作。它读取栈的顶部元素并将其从栈中移除。pop操作返回栈的顶部元素,并且如果栈为空则返回None。
要在栈上实现pop操作:
-
首先,检查栈是否为空。在空栈上不允许
pop操作。 -
如果栈不为空,可以检查顶部节点是否具有其
next属性指向其他节点。这意味着栈中有元素,并且顶部节点指向栈中的下一个节点。要应用pop操作,我们必须更改顶部指针。下一个节点应该在顶部。我们通过将self.top指向self.top.next来实现这一点。请参阅以下图表以了解这一点:

- 当栈中只有一个节点时,在弹出操作后栈将为空。我们必须将顶部指针更改为
None。见下图:

- 移除这样一个节点会导致
self.top指向None:

- 如果栈不为空,如果栈的顶部节点具有其
next属性指向其他节点,则可以将栈的大小减少1。以下是 Python 中stack的pop操作的完整代码:
def pop(self):
if self.top:
data = self.top.data
self.size -= 1
if self.top.next:
self.top = self.top.next
else:
self.top = None
return data
else:
return None
查看操作
还有另一个可以应用在栈上的重要操作——peek方法。这个方法返回栈顶的元素,而不从栈中删除它。peek和pop之间唯一的区别是,peek方法只返回顶部元素;然而,在pop方法的情况下,顶部元素被返回并且也从栈中删除。
弹出操作允许我们查看顶部元素而不改变栈。这个操作非常简单。如果有顶部元素,则返回其数据;否则,返回None(因此,peek的行为与pop相匹配):
def peek(self):
if self.top
return self.top.data
else:
return None
括号匹配应用
现在让我们看一个示例应用程序,展示我们如何使用我们的堆栈实现。我们将编写一个小函数,用于验证包含括号((,[或{)的语句是否平衡,即关闭括号的数量是否与开放括号的数量匹配。它还将确保一个括号对确实包含在另一个括号中:
def check_brackets(statement):
stack = Stack()
for ch in statement:
if ch in ('{', '[', '('):
stack.push(ch)
if ch in ('}', ']', ')'):
last = stack.pop()
if last is '{' and ch is '}':
continue
elif last is '[' and ch is ']':
continue
elif last is '(' and ch is ')':
continue
else:
return False
if stack.size > 0:
return False
else:
return True
我们的函数解析传递给它的语句中的每个字符。如果它得到一个开放括号,它将其推送到堆栈上。如果它得到一个关闭括号,它将堆栈的顶部元素弹出并比较两个括号,以确保它们的类型匹配,(应该匹配),[应该匹配],{应该匹配}。如果它们不匹配,我们返回False;否则,我们继续解析。
一旦我们到达语句的末尾,我们需要进行最后一次检查。如果堆栈为空,那么很好,我们可以返回True。但是如果堆栈不为空,那么我们有一个没有匹配的关闭括号,我们将返回False。我们可以使用以下代码测试括号匹配器:
sl = (
"{(foo)(bar)}hellois)a)test",
"{(foo)(bar)}hellois)atest",
"{(foo)(bar)}hellois)a)test))"
)
for s in sl:
m = check_brackets(s)
print("{}: {}".format(s, m))
只有三个语句中的第一个应该匹配。当我们运行代码时,我们得到以下输出:

上述代码的输出是True,False和False。
总之,堆栈数据结构的push和pop操作吸引了*O(1)*的复杂性。堆栈数据结构很简单;然而,它被用于实现许多真实世界应用中的功能。浏览器中的后退和前进按钮是使用堆栈实现的。堆栈也用于实现文字处理器中的撤销和重做功能。
队列
另一种特殊的列表类型是队列数据结构。队列数据结构非常类似于你在现实生活中习惯的常规队列。如果你曾经在机场排队或在邻里商店排队等待你最喜欢的汉堡,那么你应该知道队列是如何工作的。
队列是非常基础和重要的概念,因为许多其他数据结构都是建立在它们之上的。
队列的工作方式如下。通常,第一个加入队列的人会首先被服务,每个人都将按照加入队列的顺序被服务。首先进入,先出的首字母缩写 FIFO 最好地解释了队列的概念。FIFO代表先进先出。当人们站在队列中等待轮到他们被服务时,服务只在队列的前端提供。人们只有在被服务时才会离开队列,这只会发生在队列的最前面。请参见以下图表,其中人们站在队列中,最前面的人将首先被服务:

要加入队列,参与者必须站在队列中的最后一个人后面。这是队列接受新成员的唯一合法方式。队列的长度并不重要。
我们将提供各种队列的实现,但这将围绕 FIFO 的相同概念。首先添加的项目将首先被读取。我们将称添加元素到队列的操作为enqueue。当我们从队列中删除一个元素时,我们将称之为dequeue操作。每当一个元素被入队时,队列的长度或大小增加 1。相反,出队的项目会减少队列中的元素数量 1。
为了演示这两个操作,以下表格显示了从队列中添加和删除元素的效果:
| 队列操作 | 大小 | 内容 | 操作结果 |
|---|---|---|---|
Queue() | 0 | [] | 创建了一个空的队列对象。 |
Enqueue Packt | 1 | ['Packt'] | 队列中添加了一个 Packt 项目。 |
Enqueue 发布 | 2 | ['发布', 'Packt'] | 队列中添加了一个 发布 项目。 |
Size() | 2 | ['Publishing', 'Packt'] | 返回队列中的项目数,在此示例中为 2。 |
Dequeue() | 1 | ['Publishing'] | Packt项目被出队并返回。(这个项目是第一个添加的,所以它被第一个移除。) |
Dequeue() | 0 | [] | Publishing项目被出队并返回。(这是最后添加的项目,所以最后返回。) |
基于列表的队列
队列可以使用各种方法实现,例如list、stack和node。我们将逐一讨论使用所有这些方法实现队列的方法。让我们从使用 Python 的list类实现队列开始。这有助于我们快速了解队列。必须在队列上执行的操作封装在ListQueue类中:
class ListQueue:
def __init__(self):
self.items = []
self.size = 0
在初始化方法__init__中,items实例变量设置为[],这意味着创建时队列为空。队列的大小也设置为零。enqueue和dequeue是队列中重要的方法,我们将在下一小节中讨论它们。
入队操作
enqueue操作将项目添加到队列中。它使用list类的insert方法在列表的前面插入项目(或数据)。请参阅以下代码以实现enqueue方法:
def enqueue(self, data):
self.items.insert(0, data) # Always insert items at index 0
self.size += 1 # increment the size of the queue by 1
重要的是要注意我们如何使用列表实现队列中的插入。概念是我们在列表的索引0处添加项目;这是数组或列表中的第一个位置。要理解在列表的索引0处添加项目时队列的工作原理的概念,请考虑以下图表。我们从一个空列表开始。最初,我们在索引0处添加一个项目1。接下来,我们在索引0处添加一个项目2;它将先前添加的项目移动到下一个索引。
接下来,当我们再次在索引0处向列表中添加一个新项目3时,已添加到列表中的所有项目都会被移动,如下图所示。同样,当我们在索引0处添加项目4时,列表中的所有项目都会被移动:

因此,在我们使用 Python 列表实现队列时,数组索引0是唯一可以向队列中插入新数据元素的位置。insert操作将列表中现有的数据元素向上移动一个位置,然后将新数据插入到索引0处创建的空间中。
为了使我们的队列反映新元素的添加,大小增加了1:
self.size += 1
我们可以使用 Python 列表的shift方法作为在0处实现插入的另一种方法。
出队操作
dequeue操作用于从队列中删除项目。该方法返回队列中的顶部项目并将其从队列中删除。以下是dequeue方法的实现:
def dequeue(self):
data = self.items.pop() # delete the topmost item from the queue
self.size -= 1 # decrement the size of the queue by 1
return data
Python 的list类有一个名为pop()的方法。pop方法执行以下操作:
-
从列表中删除最后一个项目
-
将从列表中删除的项目返回给用户或调用它的代码
列表中的最后一个项目被弹出并保存在data变量中。在方法的最后一行,返回数据。
考虑以下图表作为我们的队列实现,其中添加了三个元素—1、2和3。执行dequeue操作时,数据为1的节点从队列的前面移除,因为它是最先添加的:

队列中的结果元素如下所示:

由于一个原因,enqueue操作非常低效。该方法必须首先将所有元素向前移动一个空间。想象一下,列表中有 100 万个元素需要在每次向队列添加新元素时进行移动。这将使大型列表的入队过程非常缓慢。
基于堆栈的队列
队列也可以使用两个栈来实现。我们最初设置了两个实例变量来在初始化时创建一个空队列。这些是帮助我们实现队列的栈。在这种情况下,栈只是允许我们在其上调用push和pop方法的 Python 列表,最终允许我们获得enqueue和dequeue操作的功能。以下是Queue类:
class Queue:
def __init__(self):
self.inbound_stack = []
self.outbound_stack = []
inbound_stack只用于存储添加到队列中的元素。不能对此堆栈执行其他操作。
入队操作
enqueue方法用于向队列中添加项目。这个方法非常简单,只接收要附加到队列的data。然后将此数据传递给queue类中inbound_stack的append方法。此外,append方法用于模拟push操作,将元素推送到栈的顶部。以下代码是使用 Python 中的栈实现enqueue的方法:
def enqueue(self, data):
self.inbound_stack.append(data)
要将数据enqueue到inbound_stack,以下代码可以完成任务:
queue = Queue()
queue.enqueue(5)
queue.enqueue(6)
queue.enqueue(7)
print(queue.inbound_stack)
队列中inbound_stack的命令行输出如下:
[5, 6, 7]
出队操作
dequeue操作用于按添加的项目顺序从队列中删除元素。添加到我们的队列中的新元素最终会出现在inbound_stack中。我们不是从inbound_stack中删除元素,而是将注意力转移到另一个栈,即outbound_stack。我们只能通过outbound_stack删除队列中的元素。
为了理解outbound_stack如何用于从队列中删除项目,让我们考虑以下示例。
最初,我们的inbound_stack填充了元素5、6和7,如下图所示:

我们首先检查outbound_stack是否为空。由于开始时它是空的,我们使用pop操作将inbound_stack的所有元素移动到outbound_stack。现在inbound_stack变为空,而outbound_stack保留元素。我们在下图中展示了这一点,以便更清楚地理解:

现在,如果outbound_stack不为空,我们继续使用pop操作从队列中删除项目。在前面的图中,当我们对outbound_stack应用pop操作时,我们得到了元素5,这是正确的,因为它是第一个添加的元素,应该是从队列中弹出的第一个元素。这样outbound_stack就只剩下两个元素了:

以下是队列的dequeue方法的实现:
def dequeue(self):
if not self.outbound_stack:
while self.inbound_stack:
self.outbound_stack.append(self.inbound_stack.pop())
return self.outbound_stack.pop()
if语句首先检查outbound_stack是否为空。如果不为空,我们继续使用pop方法删除队列前端的元素,如下所示:
return self.outbound_stack.pop()
如果outbound_stack为空,那么在弹出队列的前端元素之前,inbound_stack中的所有元素都将移动到outbound_stack中:
while self.inbound_stack:
self.outbound_stack.append(self.inbound_stack.pop())
while循环将在inbound_stack中有元素的情况下继续执行。
self.inbound_stack.pop()语句将删除添加到inbound_stack的最新元素,并立即将弹出的数据传递给self.outbound_stack.append()方法调用。
让我们考虑一个示例代码,以理解队列上的操作。我们首先使用队列实现向队列中添加三个项目,即5、6和7。接下来,我们应用dequeue操作从队列中删除项目。以下是代码:
queue = Queue()
queue.enqueue(5)
queue.enqueue(6)
queue.enqueue(7)
print(queue.inbound_stack)
queue.dequeue()
print(queue.inbound_stack)
print(queue.outbound_stack)
queue.dequeue()
print(queue.outbound_stack)
上述代码的输出如下:
[5, 6, 7]
[]
[7, 6]
[7]
前面的代码片段首先向队列添加元素,并打印出队列中的元素。接下来调用dequeue方法,然后再次打印队列时观察到元素数量的变化。
使用两个栈实现队列非常重要,关于这个问题在面试中经常被提出。
基于节点的队列
使用 Python 列表来实现队列是一个很好的开始,可以让我们了解队列的工作原理。我们也可以通过使用指针结构来实现自己的队列数据结构。
可以使用双向链表实现队列,并且在这个数据结构上进行插入和删除操作,时间复杂度为*O(1)*。
node类的定义与我们在讨论双向链表时定义的Node相同。如果双向链表能够实现 FIFO 类型的数据访问,那么它可以被视为队列,其中添加到列表中的第一个元素是要被移除的第一个元素。
队列类
queue类与双向链表list类和Node类非常相似,用于在双向链表中添加节点:
class Node(object):
def __init__(self, data=None, next=None, prev=None):
self.data = data
self.next = next
self.prev = prev
class Queue:
def __init__(self):
self.head = None
self.tail = None
self.count = 0
在创建queue类实例时,self.head和self.tail指针最初设置为None。为了保持Queue中节点数量的计数,这里还维护了count实例变量,最初设置为0。
入队操作
通过enqueue方法向Queue对象添加元素。元素或数据通过节点添加。enqueue方法的代码与我们在第四章中讨论的双向链表的append操作非常相似,列表和指针结构。
入队操作从传递给它的数据创建一个节点,并将其附加到队列的tail,如果队列为空,则将self.head和self.tail都指向新创建的节点。队列中元素的总数增加了一行self.count += 1。如果队列不为空,则新节点的previous变量设置为列表的tail,并且尾部的下一个指针(或变量)设置为新节点。最后,我们更新尾指针指向新节点。代码如下所示:
def enqueue(self, data):
new_node = Node(data, None, None)
if self.head is None:
self.head = new_node
self.tail = self.head
else:
new_node.prev = self.tail
self.tail.next = new_node
self.tail = new_node
self.count += 1
出队操作
使我们的双向链表作为队列的另一个操作是dequeue方法。这个方法移除队列前面的节点。为了移除self.head指向的第一个元素,使用了一个if语句:
def dequeue(self):
current = self.head
if self.count == 1:
self.count -= 1
self.head = None
self.tail = None
elif self.count > 1:
self.head = self.head.next
self.head.prev = None
self.count -= 1
current被初始化为指向self.head。如果self.count为1,那么意味着列表中只有一个节点,也就是队列。因此,要移除相关的节点(由self.head指向),self.head和self.tail变量被设置为None。
如果队列有多个节点,那么头指针会移动到self.head之后的下一个节点。
在执行if语句之后,该方法返回被head指向的节点。此外,在这两种情况下,即初始计数为1和大于1时,变量self.count都会减少1。
有了这些方法,我们已经实现了一个队列,很大程度上借鉴了双向链表的思想。
还要记住,将我们的双向链表转换成队列的唯一方法是enqueue和dequeue方法。
队列的应用
队列可以在许多实际的计算机应用程序中用于实现各种功能。例如,可以通过排队打印机要打印的内容,而不是为网络上的每台计算机提供自己的打印机。当打印机准备好打印时,它将选择队列中的一个项目(通常称为作业)进行打印。它将按照不同计算机给出的命令的顺序打印出来。
操作系统也会对要由 CPU 执行的进程进行排队。让我们创建一个应用程序,利用队列来创建一个简单的媒体播放器。
媒体播放器队列
大多数音乐播放器软件允许用户将歌曲添加到播放列表中。点击播放按钮后,主播放列表中的所有歌曲都会依次播放。使用队列可以实现歌曲的顺序播放,因为排队的第一首歌曲是要播放的第一首歌曲。这符合 FIFO 首字母缩写。我们将实现自己的播放列表队列以按 FIFO 方式播放歌曲。
我们的媒体播放器队列只允许添加曲目以及播放队列中的所有曲目。在一个完整的音乐播放器中,线程将被用于改进与队列的交互方式,同时音乐播放器继续用于选择下一首要播放、暂停或停止的歌曲。
track类将模拟音乐曲目:
from random import randint
class Track:
def __init__(self, title=None):
self.title = title
self.length = randint(5, 10)
每个曲目都保存了歌曲的标题的引用,以及歌曲的长度。歌曲的长度是在5和10之间的随机数。Python 中的随机模块提供了randint函数,使我们能够生成随机数。该类表示包含音乐的任何 MP3 曲目或文件。曲目的随机长度用于模拟播放歌曲或曲目所需的秒数。
要创建几个曲目并打印出它们的长度,我们需要做以下操作:
track1 = Track("white whistle")
track2 = Track("butter butter")
print(track1.length)
print(track2.length)
前面代码的输出如下:
6
7
根据生成的两个曲目的随机长度,您的输出可能会有所不同。
现在,让我们创建我们的队列。使用继承,我们只需从queue类继承:
import time
class MediaPlayerQueue(Queue):
def __init__(self):
super(MediaPlayerQueue, self).__init__()
通过调用super来适当初始化队列。这个类本质上是一个队列,它在队列中保存了一些曲目对象。要将曲目添加到队列,需要创建一个add_track方法:
def add_track(self, track):
self.enqueue(track)
该方法将track对象传递给队列super类的enqueue方法。这将实际上使用track对象(作为节点的数据)创建一个Node,并将尾部(如果队列不为空)或头部和尾部(如果队列为空)指向这个新节点。
假设队列中的曲目是按照添加的第一首曲目到最后一首曲目的顺序依次播放(FIFO),那么play函数必须循环遍历队列中的元素:
def play(self):
while self.count > 0:
current_track_node = self.dequeue()
print("Now playing {}".format(current_track_node.data.title))
time.sleep(current_track_node.data.length)
self.count用于计算何时向我们的队列添加了曲目以及何时曲目已被出队。如果队列不为空,对dequeue方法的调用将返回队列前端的节点(其中包含track对象)。然后,print语句通过节点的data属性访问曲目的标题。为了进一步模拟播放曲目,time.sleep()方法会暂停程序执行,直到曲目的秒数已经过去:
time.sleep(current_track_node.data.length)
媒体播放器队列由节点组成。当一首曲目被添加到队列时,该曲目会隐藏在一个新创建的节点中,并与节点的数据属性相关联。这就解释了为什么我们通过对dequeue的调用返回的节点的数据属性来访问节点的track对象:

您可以看到,我们的node对象不仅仅存储任何数据,而是在这种情况下存储曲目。
让我们来试试我们的音乐播放器:
track1 = Track("white whistle")
track2 = Track("butter butter")
track3 = Track("Oh black star")
track4 = Track("Watch that chicken")
track5 = Track("Don't go")
我们使用随机单词创建了五个曲目对象作为标题:
print(track1.length)
print(track2.length)
>> 8 >> 9
由于随机长度,输出应该与您在您的机器上得到的不同。
接下来,创建MediaPlayerQueue类的一个实例:
media_player = MediaPlayerQueue()
曲目将被添加,play函数的输出应该按照我们排队的顺序打印出正在播放的曲目:
media_player.add_track(track1)
media_player.add_track(track2)
media_player.add_track(track3)
media_player.add_track(track4)
media_player.add_track(track5)
media_player.play()
前面代码的输出如下:
>>Now playing white whistle
>>Now playing butter butter
>>Now playing Oh black star
>>Now playing Watch that chicken
>>Now playing Don't go
在程序执行时,可以看到曲目按照它们排队的顺序播放。在播放曲目时,系统还会暂停与曲目长度相等的秒数。
摘要
在这一章中,我们利用了我们对链接节点的知识来创建其他数据结构,即“栈”和“队列”。我们已经看到了这些数据结构如何紧密地模仿现实世界中的栈和队列。我们探讨了具体的实现,以及它们不同的类型。我们随后将应用栈和队列的概念来编写现实生活中的程序。
在下一章中,我们将考虑树。将讨论树的主要操作,以及适用它们数据结构的不同领域。
第六章:度
树是一种分层的数据结构。在其他数据结构(如列表、队列和栈)中,我们已经讨论过的项目是以顺序方式存储的。然而,在树数据结构的情况下,项目之间存在父子关系。树数据结构的顶部称为根节点。这是树中所有其他节点的祖先。
树数据结构非常重要,因为它们在各种重要应用中使用。树被用于许多事情,如解析表达式、搜索、存储数据、操作数据、排序、优先队列等。某些文档类型,如 XML 和 HTML,也可以以树形式表示。我们将在本章中看一些树的用途。
在本章中,我们将涵盖以下主题:
-
树的术语和定义
-
二叉树和二叉搜索树
-
树的遍历
-
三叉搜索树
技术要求
本章讨论的所有源代码都在本书的 GitHub 存储库中提供,网址为github.com/PacktPublishing/Hands-On-Data-Structures-and-Algorithms-with-Python-3.x-Second-Edition/tree/master/Chapter06。
术语
让我们考虑与树数据结构相关的一些术语。
要理解树,我们首先需要了解与其相关的基本概念。树是一种数据结构,其中数据以分层形式组织。以下图表包含一个典型的树,由字符节点 A 到 M 标记:

以下是与树相关的术语列表:
-
节点:在前面的图表中,每个圈起来的字母代表一个节点。节点是实际存储数据的任何数据结构。
-
根节点:根节点是树中所有其他节点都连接到的第一个节点。在每棵树中,始终存在一个唯一的根节点。我们示例树中的根节点是节点 A。
-
子树:树的子树是具有其节点作为其他树的后代的树。例如,节点 F、K 和 L 形成原始树的子树,其中包含所有节点。
-
给定节点的子节点总数称为该节点的度。只包含一个节点的树的度为 0。在前面的图表中,节点 A 的度为 2,节点 B 的度为 3,节点 C 的度为 3,同样,节点 G 的度为 1。
-
叶节点:叶节点没有任何子节点,是给定树的终端节点。叶节点的度始终为 0。在前面的图表中,节点 J、E、K、L、H、M 和 I 都是叶节点。
-
边:树中任意两个节点之间的连接称为边。给定树中边的总数将最多比树中的总节点数少一个。前面示例树结构中显示了一个边的示例。
-
父节点:树中具有进一步子树的节点是该子树的父节点。例如,节点 B 是节点 D、E 和 F 的父节点,节点 F 是节点 K 和 L 的父节点。
-
子节点:这是连接到其父节点的节点,是该节点的后代节点。例如,节点 B 和 C 是节点 A 的子节点,而节点 H、G 和 I 是节点 C 的子节点。
-
兄弟节点:具有相同父节点的所有节点是兄弟节点。例如,节点 B 和 C 是兄弟节点,同样,节点 D、E 和 F 也是兄弟节点。
-
层级:树的根节点被认为是在第 0 级。根节点的子节点被认为在第 1 级,第 1 级节点的子节点被认为在第 2 级,依此类推。例如,根节点在第 0 级,节点 B 和 C 在第 1 级,节点 D、E、F、H、G 和 I 在第 2 级。
-
树的高度:树中最长路径上的节点总数是树的高度。例如,在前面的树示例中,树的高度为 4,因为最长路径
A-B-D-J或A-C-G-M或A-B-F-K都有 4 个节点。 -
深度:节点的深度是从树的根到该节点的边的数量。在前面的树示例中,节点 H 的深度为 2。
我们将通过考虑树中的节点并抽象出一个类来开始处理树。
树节点
在线性数据结构中,数据项按顺序依次存储,而非线性数据结构将数据项以非线性顺序存储,其中一个数据项可以连接到多个数据项。线性数据结构中的所有数据项可以在一次遍历中遍历,而在非线性数据结构中这是不可能的。树是非线性数据结构;它们以与数组、列表、栈和队列等其他线性数据结构不同的方式存储数据。
在树数据结构中,节点按照父-子关系排列。树中的节点之间不应该有循环。树结构有节点形成层次结构,没有节点的树称为空树。
首先,我们将讨论一种最重要和特殊的树,即二叉树。二叉树是节点的集合,树中的节点可以有零个、1 个或 2 个子节点。简单的二叉树最多有两个子节点,即左子节点和右子节点。例如,在下面的二叉树示例中,有一个根节点,它有两个子节点(左子节点、右子节点):

如果二叉树的所有节点都有零个或两个子节点,并且没有一个节点有 1 个子节点,则称树为满二叉树。如果二叉树完全填满,底层可能有一个例外,从左到右填充,则称为完全二叉树。
就像我们之前的实现一样,节点是数据的容器,并且持有对其他节点的引用。在二叉树节点中,这些引用是指左右子节点。让我们看一下下面的 Python 代码,构建一个二叉树node类:
class Node:
def __init__(self, data):
self.data = data
self.right_child = None
self.left_child = None
为了测试这个类,我们首先要创建四个节点——n1、n2、n3和n4:
n1 = Node("root node")
n2 = Node("left child node")
n3 = Node("right child node")
n4 = Node("left grandchild node")
接下来,我们根据二叉树的属性将节点连接起来。我们让n1成为根节点,n2和n3成为它的子节点。最后,我们将n4作为n2的左子节点。看一下下面的图表,看看我们如何将这些节点连接起来:

接下来的代码片段应该按照前面的图表连接节点:
n1.left_child = n2
n1.right_child = n3
n2.left_child = n4
在这里,我们设置了一个非常简单的四个节点的树结构。我们想要在树上执行的第一个重要操作是遍历。为了理解遍历,让我们遍历这棵二叉树的左子树。我们将从根节点开始,打印出节点,并向下移动到下一个左节点。我们一直这样做,直到我们到达左子树的末端,就像这样:
current = n1
while current:
print(current.data)
current = current.left_child
遍历上述代码块的输出如下:
root node
left child node
left grandchild node
树的遍历
访问树中所有节点的方法称为树的遍历。这可以通过深度优先搜索(DFS)或广度优先搜索(BFS)来完成。我们将在接下来的小节中讨论这两种方法。
深度优先遍历
在深度优先遍历中,我们从根开始遍历树,并尽可能深入每个子节点,然后继续遍历到下一个兄弟节点。我们使用递归方法进行树遍历。深度优先遍历有三种形式,即中序、前序和后序。
中序遍历和中缀表示法
中序树遍历的工作方式如下。首先,我们检查当前节点是否为空或空。如果不为空,我们遍历树。在中序树遍历中,我们按照以下步骤进行:
-
我们开始遍历左子树,并递归调用“中序”函数
-
接下来,我们访问根节点
-
最后,我们遍历右子树,并递归调用“中序”函数
因此,在“中序”树遍历中,我们按照(左子树、根、右子树)的顺序访问树中的节点。
让我们考虑一个示例来理解中序树遍历:

在“中序”遍历的示例二叉树中,首先,我们递归访问根节点 A 的左子树。节点 A 的左子树以节点 B 为根,所以我们再次转到节点 B 的左子树,即节点 D。我们递归地转到节点 D 的左子树,以便我们得到根节点 D 的左子树。因此,我们首先访问左子节点,即 G,然后访问根节点 D,然后访问右子节点 H。
接下来,我们访问节点 B,然后访问节点 E。这样,我们已经访问了根节点 A 的左子树。所以下一步,我们访问根节点 A。之后,我们将访问根节点 A 的右子树。在这里,我们转到根节点 C 的左子树,它是空的,所以下一步我们访问节点 C,然后访问节点 C 的右子节点,即节点 F。
因此,这个示例树的中序遍历是“G-D-H-B-E-A-C-F”。
树的递归函数的 Python 实现,以返回树中节点的“中序”列表如下:
def inorder(self, root_node):
current = root_node
if current is None:
return
self.inorder(current.left_child)
print(current.data)
self.inorder(current.right_child)
我们通过打印访问的节点来访问节点。在这种情况下,我们首先递归调用“中序”函数与current.left_child,然后访问根节点,最后我们再次递归调用“中序”函数与current.right_child。
中缀表示法(也称为逆波兰表示法)是一种常用的表示算术表达式的表示法,其中操作符放置在操作数之间。通常使用这种方式来表示算术表达式,因为这是我们在学校通常学到的方式。例如,操作符被插入(插入)在操作数之间,如3 + 4。必要时,可以使用括号来构建更复杂的表达式,例如(4 + 5) * (5 - 3)。
表达式树是一种特殊的二叉树,可用于表示算术表达式。表达式树的中序遍历产生中缀表示法。例如,考虑以下表达式树:

前面的表达式树的中序遍历给出了中缀表示法,即(5 + 3)。
前序遍历和前缀表示法
前序树遍历的工作方式如下。首先,我们检查当前节点是否为空或空。如果不为空,我们遍历树。前序树遍历的工作方式如下:
-
我们从根节点开始遍历
-
接下来,我们遍历左子树,并递归调用“前序”函数与左子树
-
接下来,我们遍历右子树,并递归调用“前序”函数与右子树
因此,要以前序方式遍历树,我们按照根节点、左子树和右子树节点的顺序访问树。
考虑以下示例树以了解前序遍历:

在上面的二叉树示例中,首先我们访问根节点A。接下来,我们转到根节点A的左子树。节点A的左子树以节点B为根,因此我们访问这个根节点,然后转到根节点B的左子树,即节点D。然后我们访问节点D,并转到根节点D的左子树,然后我们访问左子节点G,它是根节点D的子树。接下来,我们访问根节点D的右子节点,即节点H。接着,我们访问根节点B的右子树的右子节点,即节点E。因此,以这种方式,我们已经访问了根节点A和以根节点A为根的左子树。现在,我们将访问根节点A的右子树。在这里,我们访问根节点C,然后我们转到根节点C的左子树,它为空,所以下一步,我们访问节点C的右子节点,即节点F。
这个示例树的前序遍历将是A-B-D-G-H-E-C-F。
pre-order树遍历的递归函数如下:
def preorder(self, root_node):
current = root_node
if current is None:
return
print(current.data)
self.preorder(current.left_child)
self.preorder(current.right_child)
前缀表示法通常被称为波兰表示法。在这种表示法中,运算符位于其操作数之前。前缀表示法是 LISP 程序员熟知的。例如,要添加两个数字 3 和 4 的算术表达式将显示为+ 3 4。由于没有运算符优先级的歧义,因此不需要括号:* + 4 5 - 5 3。
让我们考虑另一个例子,即(3 +4) * 5。这也可以用前缀表示法表示为* (+ 3 4) 5。
表达式树的前序遍历将得到算术表达式的前缀表示法。例如,考虑以下表达式树:

上述树的前序遍历将以前缀表示法给出表达式为+- 8 3 3。
后序遍历和后缀表示法
post-order树遍历的工作方式如下。首先,我们检查当前节点是否为空。如果不为空,我们遍历树。post-order树遍历的工作方式如下:
-
我们开始遍历左子树并递归调用
postorder函数 -
接下来,我们遍历右子树并递归调用
postorder函数 -
最后,我们访问根节点
因此,简而言之,关于post-order树遍历,我们按照左子树、右子树和最后根节点的顺序访问树中的节点。
考虑以下示例树以理解后序树遍历:

在上图中,我们首先递归访问根节点A的左子树。我们到达最后的左子树,也就是根节点 D,然后我们访问它的左节点,即节点G。然后,我们访问右子节点 H,然后我们访问根节点 D。按照相同的规则,我们接下来访问节点B的右子节点,即节点E。然后,我们访问节点B。接着,我们遍历节点A的右子树。在这里,我们首先到达最后的右子树并访问节点F,然后我们访问节点C。最后,我们访问根节点A。
这个示例树的后序遍历将是G-H-D-E-B-F-C-A。
树遍历的post-order方法的实现如下:
def postorder(self, root_node):
current = root_node
if current is None:
return
self.postorder(current.left_child)
self.postorder(current.right_child)
print(current.data)
后缀或逆波兰表示法(RPN)将运算符放在其操作数之后,如3 4 +。与波兰表示法一样,运算符的优先级不会引起混淆,因此永远不需要括号:4 5 + 5 3 - *。
以下表达式树的后序遍历将给出算术表达式的后缀表示法:

上述表达式树的后缀表示法是8 3 -3 +。
广度优先遍历
广度优先遍历从树的根开始,然后访问树的下一级上的每个节点。然后,我们移动到树的下一级,依此类推。这种树遍历方式是广度优先的,因为它在深入树之前通过遍历一个级别上的所有节点来扩展树。
让我们考虑以下示例树,并使用广度优先遍历方法遍历它:

在前面的图表中,我们首先访问level 0的根节点,即值为4的节点。我们通过打印出它的值来访问这个节点。接下来,我们移动到level 1并访问该级别上的所有节点,即值为2和8的节点。最后,我们移动到树的下一级,即level 3,并访问该级别上的所有节点。该级别上的节点是1,3,5和10。
因此,该树的广度优先遍历如下:4,2,8,1,3,5和10。
这种遍历模式是使用队列数据结构实现的。从根节点开始,我们将其推入队列。访问队列前面的节点(出队)并打印或存储以供以后使用。左节点被添加到队列,然后是右节点。由于队列不为空,我们重复这个过程。
该算法的 Python 实现将根节点4入队,出队并访问该节点。接下来,节点2和8入队,因为它们分别是下一级的左节点和右节点。节点2出队以便访问。接下来,它的左节点和右节点,即节点1和3,入队。此时队列前面的节点是8。我们出队并访问节点8,然后将其左节点和右节点入队。这个过程一直持续到队列为空。
广度优先遍历的 Python 实现如下:
from collections import deque
class Tree:
def breadth_first_traversal(self):
list_of_nodes = []
traversal_queue = deque([self.root_node])
我们将根节点入队,并在list_of_nodes列表中保留访问过的节点的列表。使用dequeue类来维护队列:
while len(traversal_queue) > 0:
node = traversal_queue.popleft()
list_of_nodes.append(node.data)
if node.left_child:
traversal_queue.append(node.left_child)
if node.right_child:
traversal_queue.append(node.right_child)
return list_of_nodes
如果traversal_queue中的元素数量大于零,则执行循环体。队列前面的节点被弹出并附加到list_of_nodes列表中。第一个if语句将左子节点入队,如果提供了左节点则存在。第二个if语句对右子节点执行相同的操作。
list_of_nodes列表在最后一个语句中返回。
二叉树
二叉树是每个节点最多有两个子节点的树。二叉树中的节点以左子树和右子树的形式组织。如果树有一个根 R 和两个子树,即左子树T1和右子树T2,那么它们的根分别称为左继和右继。
以下图表是一个具有五个节点的二叉树的示例:

以下是我们对前面图表的观察:
-
每个节点都保存对右节点和左节点的引用,如果节点不存在
-
根节点用5表示
-
根节点有两个子树,左子树有一个节点,即值为3的节点,右子树有三个节点,值分别为7,6和9。
-
值为3的节点是左继节点,而值为7的节点是右继节点
常规的二叉树在树中排列元素方面没有其他规则。它只需满足每个节点最多有两个子节点的条件。
二叉搜索树
二叉搜索树(BST)是一种特殊的二叉树。它是计算机科学应用中最重要和最常用的数据结构之一。二叉搜索树是一棵结构上是二叉树的树,并且非常有效地在其节点中存储数据。它提供非常快速的搜索操作,插入和删除等操作也非常简单和方便。
如果树中任意节点的值大于其左子树中所有节点的值,并且小于或等于其右子树中所有节点的值,则称二叉树为二叉搜索树。例如,如果K1、K2和K3是三个节点树中的关键值(如下图所示),则应满足以下条件:
-
K2<=K1的关键值
-
关键值K3>K1
以下图表描述了这一点:

让我们考虑另一个例子,以便更好地理解二叉搜索树。考虑以下树:

这是 BST 的一个例子。在这棵树中,左子树中的所有节点都小于或等于该节点的值。同样,该节点的右子树中的所有节点都大于父节点的值。
测试我们的树是否具有 BST 的属性时,我们注意到根节点左子树中的所有节点的值都小于 5。同样,右子树中的所有节点的值都大于 5。这个属性适用于 BST 中的所有节点,没有例外。
考虑另一个二叉树的例子,让我们看看它是否是二叉搜索树。尽管以下图表看起来与前一个图表相似,但它并不符合 BST 的条件,因为节点7大于根节点5;然而,它位于根节点的左侧。节点4位于其父节点7的右子树中,这是不正确的。因此,以下图表不是二叉搜索树:

二叉搜索树实现
让我们开始在 Python 中实现 BST。我们需要跟踪树的根节点,因此我们首先创建一个Tree类,其中包含对根节点的引用:
class Tree:
def __init__(self):
self.root_node = None
这就是维护树状态所需的全部内容。让我们在下一节中研究树上的主要操作。
二叉搜索树操作
二叉搜索树上可以执行的操作包括插入、删除、查找最小值、查找最大值、搜索等。我们将在后续小节中讨论它们。
查找最小和最大节点
二叉搜索树的结构使得查找具有最大或最小值的节点非常容易。
要找到树中具有最小值的节点,我们从树的根开始遍历,并每次访问左节点,直到到达树的末端。类似地,我们递归遍历右子树,直到到达末端,以找到树中具有最大值的节点。
例如,考虑以下图表;我们从节点6向下移动到3,然后从节点3移动到1,以找到具有最小值的节点。类似地,要找到树中具有最大值的节点,我们从根向树的右侧移动,然后从节点6移动到节点8,然后从节点8移动到节点10以找到具有最大值的节点。以下是一个 BST 树的例子:

找到最小和最大节点的概念也适用于子树。因此,根节点为8的子树中的最小节点是节点7。同样,该子树中具有最大值的节点是10。
返回最小节点的 Python 实现如下:
def find_min(self):
current = self.root_node
while current.left_child:
current = current.left_child
return current
while循环继续获取左节点并访问它,直到最后一个左节点指向None。这是一个非常简单的方法。
同样,以下是返回最大节点的方法的代码:
def find_max(self):
current = self.root_node
while current.right_child:
current = current.right_child
return current
在 BST 中查找最小值或最大值的运行时间复杂度为 O(h),其中h是树的高度。
基本上还有两个其他操作,即insert和delete,它们对 BST 非常重要。在对树应用这些操作时,确保我们保持 BST 树的属性是很重要的。
插入节点
在二叉搜索树上实现的最重要的操作之一是在树中插入数据项。正如我们已经讨论过的,关于二叉搜索树的属性,对于树中的每个节点,左子节点应该包含小于其自身值的数据,右子节点应该包含大于其值的数据。因此,我们必须确保每当我们在树中插入一个项目时,二叉搜索树的属性都得到满足。
例如,通过在树中插入数据项5、3、7和1来创建一个二叉搜索树。考虑以下内容:
-
插入 5:我们从第一个数据项5开始。为此,我们将创建一个数据属性设置为5的节点,因为它是第一个节点。
-
插入 3:现在,我们想添加值为3的第二个节点,以便将数据值3与根节点5的现有节点值进行比较:
由于节点值3小于5,它将被放置在节点5的左子树中。我们的 BST 将如下所示:

树满足 BST 规则,即左子树中的所有节点都小于父节点。
- 插入 7:要向树中添加值为7的另一个节点,我们从值为5的根节点开始比较:

由于7大于5,值为7的节点被放置在此根节点的右侧。
- 插入 1:让我们添加另一个值为1的节点。从树的根开始,我们比较1和5:

这个比较表明1小于5,所以我们转到5的左节点,即值为3的节点:

当我们将1与3进行比较时,由于1小于3,我们向下移动到节点3的下一级并向左移动。然而,那里没有节点。因此,我们创建一个值为1的节点,并将其与节点3的左指针关联,以获得以下结构。在这里,我们有4个节点的最终二叉搜索树:

我们可以看到这个例子只包含整数或数字。因此,如果我们需要在二叉搜索树中存储字符串数据,在这种情况下字符串将按字母顺序进行比较。如果我们想在 BST 中存储自定义数据类型,我们必须确保我们的类支持排序。
给出了在 BST 中添加节点的insert方法的 Python 实现如下:
def insert(self, data):
node = Node(data)
if self.root_node is None:
self.root_node = node
else:
current = self.root_node
parent = None
while True:
parent = current
if node.data < parent.data:
current = current.left_child
if current is None:
parent.left_child = node
return
else:
current = current.right_child
if current is None:
parent.right_child = node
return
现在,让我们逐步理解insert函数的每条指令。我们将从函数声明开始:
def insert(self, data):
到目前为止,您已经习惯了我们将数据封装在节点中的事实。这样,我们将node类隐藏在客户端代码中,客户端只需要处理树:
node = Node(data)
首先将进行检查,以找出是否有根节点。如果没有,新节点将成为根节点(没有根节点的树是不允许的):
if self.root_node is None:
self.root_node = node
else:
当我们沿着树向下走时,我们需要跟踪我们正在处理的当前节点以及其父节点。current变量总是用于此目的:
current = self.root_node
parent = None
while True:
parent = current
在这里,我们必须进行比较。如果新节点中保存的数据小于当前节点中保存的数据,那么我们检查当前节点是否有左子节点。如果没有,这就是我们插入新节点的地方。否则,我们继续遍历:
if node.data < current.data:
current = current.left_child
if current is None:
parent.left_child = node
return
现在,我们需要处理大于或等于的情况。如果当前节点没有右子节点,那么新节点将被插入为右子节点。否则,我们向下移动并继续寻找插入点:
else:
current = current.right_child
if current is None:
parent.right_child = node
return
在 BST 中插入一个节点需要O(h)的时间,其中h是树的高度。
删除节点
BST 上的另一个重要操作是节点的删除或移除。在这个过程中,我们需要考虑三种情况。我们要删除的节点可能有以下情况:
-
没有子节点:如果没有叶节点,直接删除节点
-
一个子节点:在这种情况下,我们交换该节点的值与其子节点的值,然后删除该节点
-
两个子节点:在这种情况下,我们首先找到中序后继或前驱,与其交换值,然后删除该节点
第一种情况是最容易处理的。如果要删除的节点没有子节点,我们只需将其从其父节点中删除:

在上面的示例中,节点A没有子节点,所以我们将它从其父节点,即节点Z中删除。
另一方面,当我们要删除的节点只有一个子节点时,该节点的父节点被指向该节点的子节点。让我们看一下下面的图表,我们要删除节点6,它只有一个子节点,即节点5:

为了删除只有一个子节点的节点6,我们将节点9的左指针指向节点5。在这里,我们需要确保子节点和父节点的关系遵循二叉搜索树的属性。
当我们要删除的节点有两个子节点时,会出现更复杂的情况。考虑以下示例树,我们要删除节点9,它有两个子节点:

我们不能简单地用节点6或13替换节点9。我们需要找到节点9的下一个最大的后代。这是节点12。要到达节点12,我们移动到节点9的右节点,然后向左移动以找到最左边的节点。节点12被称为节点9的中序后继。第二步类似于查找子树中的最大节点。
我们用节点9的值替换节点9的值,并删除节点12。删除节点12后,我们得到了一个更简单的节点删除形式,这是之前讨论过的。节点 12 没有子节点,所以我们相应地应用了删除没有子节点的节点的规则。
我们的node类没有父节点的引用。因此,我们需要使用一个辅助方法来搜索并返回带有其父节点的节点。这个方法类似于搜索方法:
def get_node_with_parent(self, data):
parent = None
current = self.root_node
if current is None:
return (parent, None)
while True:
if current.data == data:
return (parent, current)
elif current.data > data:
parent = current
current = current.left_child
else:
parent = current
current = current.right_child
return (parent, current)
唯一的区别是在更新循环内的当前变量之前,我们用parent = current存储它的父节点。实际删除节点的方法始于这个搜索:
def remove(self, data):
parent, node = self.get_node_with_parent(data)
if parent is None and node is None:
return False
# Get children count
children_count = 0
if node.left_child and node.right_child:
children_count = 2
elif (node.left_child is None) and (node.right_child is None):
children_count = 0
else:
children_count = 1
我们将父节点和找到的节点分别传递给parent和node,使用parent, node = self.get_node_with_parent(data)。了解要删除的节点有多少个子节点是很重要的,我们在if语句中这样做。
在我们知道要删除的节点有多少个子节点之后,我们需要处理节点可以被删除的各种情况。if语句的第一部分处理了节点没有子节点的情况:
if children_count == 0:
if parent:
if parent.right_child is node:
parent.right_child = None
else:
parent.left_child = None
else:
self.root_node = None
在要删除的节点只有一个子节点的情况下,if语句的elif部分执行以下操作:
elif children_count == 1:
next_node = None
if node.left_child:
next_node = node.left_child
else:
next_node = node.right_child
if parent:
if parent.left_child is node:
parent.left_child = next_node
else:
parent.right_child = next_node
else:
self.root_node = next_node
next_node用于跟踪单个节点,该节点是要删除的节点的子节点。然后,我们将parent.left_child或parent.right_child连接到next_node。
最后,我们处理了要删除的节点有两个子节点的情况:
...
else:
parent_of_leftmost_node = node
leftmost_node = node.right_child
while leftmost_node.left_child:
parent_of_leftmost_node = leftmost_node
leftmost_node = leftmost_node.left_child
node.data = leftmost_node.data
在查找中序后继时,我们移动到右节点,使用leftmost_node = node.right_child。只要左节点存在,leftmost_node.left_child将计算为True,并且while循环将运行。当我们到达最左边的节点时,它要么是叶节点(意味着它将没有子节点),要么有一个右子节点。
我们使用node.data = leftmost_node.data来更新即将被删除的节点的值为中序后继的值:
if parent_of_leftmost_node.left_child == leftmost_node:
parent_of_leftmost_node.left_child = leftmost_node.right_child
else:
parent_of_leftmost_node.right_child = leftmost_node.right_child
上述语句允许我们正确地将左子树节点的父节点与任何子节点连接起来。请注意等号右侧保持不变。这是因为中序后继只能有一个右子节点作为其唯一子节点。
remove操作的时间复杂度为O(*h*),其中h是树的高度。
搜索树
二叉搜索树是一种树形数据结构,其中所有节点都遵循这样的属性:节点的左子树中的所有节点具有较低的键值,在其右子树中具有较大的键值。因此,搜索具有给定键值的元素非常容易。让我们考虑一个示例二叉搜索树,其中的节点为1、2、3、4、8、5和10,如下图所示:

在上述树中,如果我们想要搜索值为5的节点,则我们从根节点开始,并将其与根节点进行比较。由于节点5的值大于根节点值4,我们移动到右子树。在右子树中,我们有节点8作为根节点;我们将节点5与节点8进行比较。由于要搜索的节点的值小于节点8,我们移动到左子树。当我们移动到左子树时,我们将左子树节点5与值为5的所需节点进行比较。这是一个匹配,所以我们返回“找到项目”。
以下是二叉搜索树中searching方法的实现:
def search(self, data):
current = self.root_node
while True:
if current is None:
return None
elif current.data is data:
return data
elif current.data > data:
current = current.left_child
else:
current = current.right_child
在上述代码中,如果找到数据,我们将返回数据,如果未找到数据,则返回None。我们从根节点开始搜索。接下来,如果要搜索的数据项不存在于树中,则我们将返回None给客户端代码。我们也可能已经找到了数据,如果是这种情况,我们将返回数据。
如果我们要搜索的数据小于当前节点的数据,则我们向树的左侧移动。此外,在代码的else部分中,我们检查我们要查找的数据是否大于当前节点中保存的数据,这意味着我们向树的右侧移动。
最后,我们可以编写一些客户端代码来测试 BST 的工作原理。我们必须创建一棵树,并在1和10之间插入一些数字。然后,我们搜索该范围内的所有数字。存在于树中的数字将被打印出来:
tree = Tree()
tree.insert(5)
tree.insert(2)
tree.insert(7)
tree.insert(9)
tree.insert(1)
for i in range(1, 10):
found = tree.search(i)
print("{}: {}".format(i, found))
二叉搜索树的好处
二叉搜索树与数组和链表相比是更好的选择。对于大多数操作,如搜索、插入和删除,BST 都很快,而数组提供了快速的搜索,但在插入和删除操作上相对较慢。同样,链表在执行插入和删除操作时效率很高,但在执行搜索操作时速度较慢。在二叉搜索树中搜索元素的“最佳情况”运行时间复杂度为O(log n),而“最坏情况”时间复杂度为O(n),而在列表中搜索的“最佳情况”和“最坏情况”时间复杂度均为O(n)。
以下表格提供了数组、链表和二叉搜索树数据结构的比较:
| 属性 | 数组 | 链表 | BST |
|---|---|---|---|
| 数据结构 | 线性。 | 线性。 | 非线性。 |
| 易用性 | 创建和使用都很容易。搜索、插入和删除的平均情况复杂度为O(n)。 | 插入和删除很快,特别是使用双向链表。 | 元素访问、插入和删除都很快,平均情况复杂度为O(log n)。 |
| 访问复杂度 | 访问元素容易。复杂度为O(1)。 | 只能进行顺序访问,所以很慢。平均和最坏情况下的复杂度是O(n)。 | 访问很快,但当树不平衡时很慢,最坏情况下的复杂度为O(n)。 |
| 搜索复杂度 | 平均和最坏情况下的复杂度是O(n)。 | 由于顺序搜索,所以很慢。平均和最坏情况下的复杂度是O(n)。 | 搜索的最坏情况复杂度是O(n)。 |
| 插入复杂度 | 插入很慢。平均和最坏情况下的复杂度是O(n)。 | 平均和最坏情况下的复杂度是O(1)。 | 插入的最坏情况复杂度是O(n)。 |
| 删除复杂度 | 删除很慢。平均和最坏情况下的复杂度是O(n)。 | 平均和最坏情况下的复杂度是O(1)。 | 删除的最坏情况复杂度是O(n)。 |
让我们举个例子来理解何时使用二叉搜索树来存储数据是一个好选择。假设我们有以下数据节点——5,3,7,1,4,6和9。如果我们使用列表来存储这些数据,最坏的情况将需要我们搜索整个包含七个元素的列表来找到这个项目。因此,在这个数据节点中,需要七次比较来搜索项目9:

然而,如果我们使用二叉搜索树来存储这些值,如下图所示,在最坏的情况下,我们需要三次比较来搜索项目9:

然而,重要的是要注意搜索效率也取决于我们如何构建二叉搜索树。如果树没有被正确构建,它可能会很慢。例如,如果我们按照{1,3,4,5,6,7,9}的顺序将元素插入到树中,如下图所示,那么树将不会比列表更有效:

因此,选择自平衡树有助于改善搜索操作。在这里,我们应该注意,二叉搜索树在大多数情况下是更好的选择;然而,我们应该尝试平衡树。
平衡树
我们已经在前一节中看到,如果节点按顺序插入到树中,它会变得很慢,行为上更像一个列表;也就是说,每个节点恰好有一个子节点。为了提高树数据结构的性能,我们通常希望尽可能减少树的高度,通过填充树中的每一行来平衡树。这个过程称为平衡树。
有不同类型的自平衡树,如红黑树、AA 树和替罪羊树。这些树在修改树的每个操作期间平衡树,比如插入或删除。还有一些外部算法来平衡树。这些方法的好处是你不需要在每次操作中都平衡树,可以在需要时再进行平衡。
表达树
算术表达式由操作数和运算符的组合表示,其中运算符可以是一元或二元。算术表达式也可以使用二叉树表示,称为表达式树。这种树结构也可以用于解析算术和布尔表达式。在表达式树中,所有叶节点包含操作数,非叶节点包含运算符。我们还应该注意,表达式树的子树(右子树或左子树)在一元运算符的情况下将为空。
例如,3 + 4的表达式树如下所示:

对于稍微复杂的表达式(4 + 5) * (5-3),我们将得到以下结果:

算术表达式可以用三种符号表示(即中缀、后缀和前缀),如前一节中关于树遍历的讨论所述。因此,对于给定的算术表达式,评估表达式树变得容易。逆波兰符号提供更快的计算。我们将在以下小节中向您展示如何构建给定后缀符号的表达式树。
解析逆波兰表达式
现在,我们将为后缀表示法中的表达式构建树。然后,我们将计算结果。我们将使用一个简单的树实现。为了保持简单,因为我们将通过合并较小的树来增加树,我们只需要一个树节点实现:
class TreeNode:
def __init__(self, data=None):
self.data = data
self.right = None
self.left = None
为了构建树,我们将使用堆栈列出项目。让我们创建一个算术表达式并设置我们的堆栈:
expr = "4 5 + 5 3 - *".split()
stack = Stack()
由于 Python 是一种试图具有合理默认值的语言,其split()方法默认在空格上拆分。(如果您考虑一下,这很可能是您所期望的。)结果将是expr是一个包含值4、5、+、5、3、-和*的列表。
expr列表的每个元素将是运算符或操作数。如果我们得到一个操作数,那么我们将其嵌入树节点并将其推送到堆栈上。另一方面,如果我们得到一个运算符,那么我们将运算符嵌入树节点,并将其两个操作数弹出到节点的左右子节点中。在这里,我们必须确保第一个弹出进入右子节点;否则,我们将在减法和除法中出现问题。
以下是构建树的代码:
for term in expr:
if term in "+-*/":
node = TreeNode(term)
node.right = stack.pop()
node.left = stack.pop()
else:
node = TreeNode(int(term))
stack.push(node)
请注意,在操作数的情况下,我们执行了从string到int的转换。如果您希望支持浮点操作数,可以使用float()。
在此操作结束时,我们应该在堆栈中有一个单一元素,并且该元素包含完整的树。如果我们想要评估表达式,我们将构建以下小函数:
def calc(node):
if node.data is "+":
return calc(node.left) + calc(node.right)
elif node.data is "-":
return calc(node.left) - calc(node.right)
elif node.data is "*":
return calc(node.left) * calc(node.right)
elif node.data is "/":
return calc(node.left) / calc(node.right)
else:
return node.data
在上述代码中,我们将一个节点传递给函数。如果节点包含操作数,那么我们只需返回该值。如果我们得到一个运算符,那么我们将在节点的两个子节点上执行运算符表示的操作。然而,由于一个或多个子节点也可能包含运算符或操作数,我们在两个子节点上递归调用calc()函数(要记住每个节点的所有子节点也都是节点)。
现在,我们只需要从堆栈中弹出根节点并将其传递给calc()函数。然后,我们应该得到计算的结果:
root = stack.pop()
result = calc(root)
print(result)
运行此程序应该产生结果18,这是(4 + 5) * (5 - 3)的结果。
堆
堆数据结构是树的一种特殊形式,其中节点以特定方式排序。堆分为max堆和min堆。
在max堆中,每个父节点的值必须始终大于或等于其子节点。由此可知,根节点必须是树中最大的值。考虑以下最大堆的图表,其中所有节点的值都大于其子节点的值:

在min堆中,每个父节点必须小于或等于其两个子节点。因此,根节点包含最小值。考虑以下最小堆的图表,其中所有节点的值都小于其子节点的值:

堆用于许多不同的事情。首先,它们用于实现优先级队列。还有一种非常高效的排序算法,称为堆排序,它使用堆。我们将在后续章节中深入研究这些内容。
三元搜索树
三元树是一种数据结构,树的每个节点最多可以包含3个子节点。与二叉搜索树相比,它不同之处在于二叉树中的节点最多可以有2个子节点,而三元树中的节点最多可以有3个子节点。三元树数据结构也被认为是字典树数据结构的特殊情况。在字典树数据结构中,当我们使用字典树数据结构存储字符串时,每个节点包含 26 个指向其子节点的指针,而在三元搜索树数据结构中,我们有 3 个指向其子节点的指针。
三元搜索树可以表示如下:
-
每个节点都存储一个字符
-
它具有指向存储与当前节点相等值的节点的等指针
-
它具有指向存储小于当前节点值的节点的左指针
-
它具有指向存储大于当前节点值的节点的右指针
-
每个节点都有一个标志变量,用于跟踪该节点是否是字符串的结尾
为了更好地理解三元搜索树数据结构,我们将通过一个示例来演示,其中我们将字符串PUT,CAT,SIT,SING和PUSH插入到一个空的三元树中,如下图所示:

将值插入三元搜索树与在二叉搜索树中进行的方式非常相似。在三元搜索树中,我们遵循以下步骤将字符串插入三元搜索树:
-
由于树最初为空,我们首先创建根节点,其中包含第一个字符P,然后我们为字符U创建另一个节点,最后是字符T。
-
接下来,我们希望添加单词CAT。首先,我们将第一个字符C与根节点字符P进行比较。由于不匹配,并且它小于根节点,我们在根节点的左侧为字符C创建一个新节点。此外,我们创建了字符A和T的节点。
-
接下来,我们添加一个新单词SIT。首先,我们将第一个字符S与根节点字符P进行比较。由于不匹配,并且字符S大于字符P,我们在右侧为字符S创建一个新节点。此外,我们创建了字符I和T的节点。
-
接下来,我们将单词SING插入到三叉搜索树中。我们首先将第一个字符S与根节点进行比较。由于不匹配,并且字符S大于根节点P,我们查看右侧的下一个字符,即S。这里,字符匹配,因此我们比较下一个字符I;这也匹配。接下来,我们将字符N与树中的字符T进行比较。这里,字符不匹配,因此我们移动到节点T的左侧。在这里,我们为字符N创建一个新节点。此外,我们为字符G创建另一个新节点。
-
然后,在三叉搜索树中添加一个新节点PUSH。首先,我们比较单词的第一个字符,即P,与根节点。由于匹配,我们查看三叉树中的下一个字符。这里,字符U也与单词的下一个字符匹配。因此,我们查看单词的下一个字符,即S。它与树中的下一个字符T不匹配。因此,我们在节点T的左侧为字符S创建一个新节点,因为字符S小于T。接下来,我们为下一个字符H创建另一个节点。
请注意,三叉树中的每个节点都通过使用标志变量来跟踪哪个节点是叶节点或非叶节点。
三叉搜索树非常适用于字符串搜索相关的应用,比如当我们希望搜索所有以特定前缀开头的字符串,或者当我们希望搜索以特定数字开头的电话号码,拼写检查等等。
总结
在本章中,我们研究了树数据结构及其用途。特别是我们研究了二叉树,这是树的一个子类型,其中每个节点最多有两个子节点。我们还看了二叉树如何作为可搜索的数据结构与 BST 一起使用。广度优先和深度优先搜索遍历模式也通过使用队列递归在 Python 中实现。
我们还看了二叉树如何用来表示算术或布尔表达式。然后,我们构建了一个表达式树来表示算术表达式。之后,我们向您展示了如何使用栈来解析以逆波兰表示法编写的表达式,构建表达式树,并最终遍历它以获得算术表达式的结果。
最后,我们提到了堆,这是树结构的一种特殊形式。我们在本章至少尝试奠定了堆的理论基础,以便在接下来的章节中为不同的目的实现堆。
在下一章中,我们将讨论哈希表和符号表的细节。