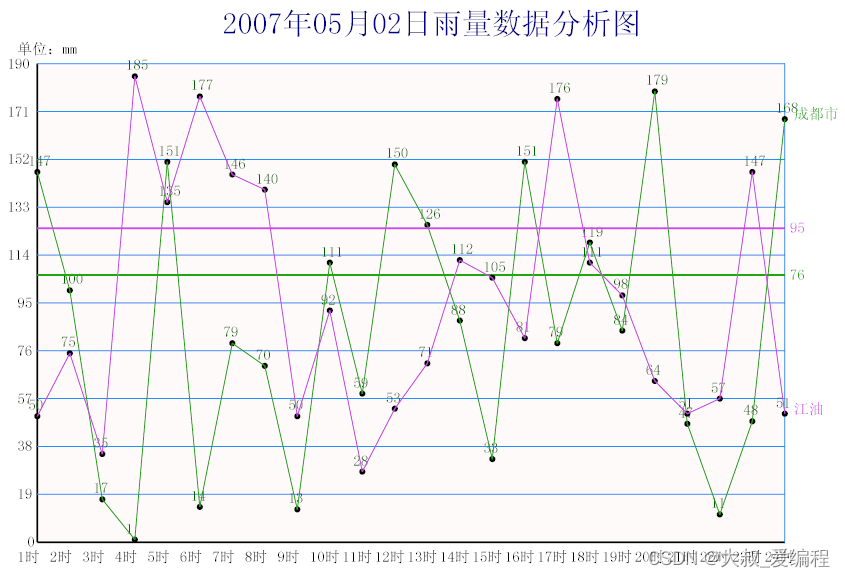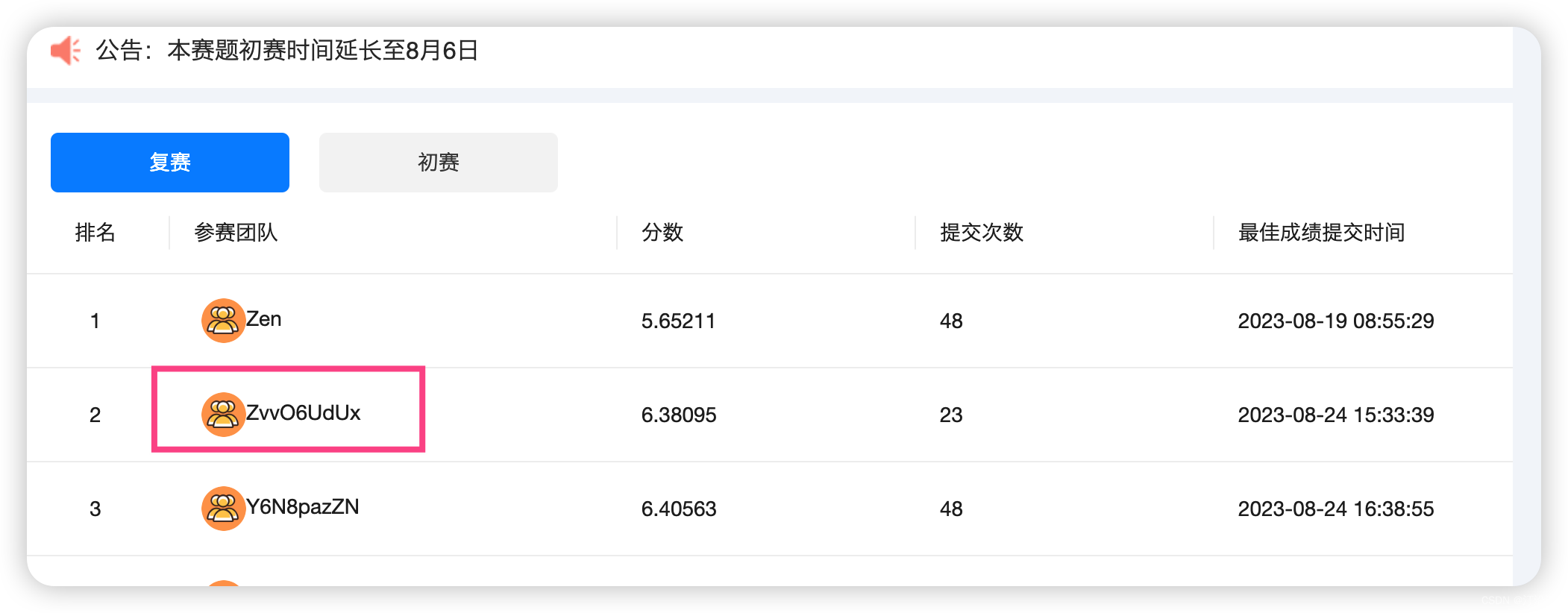
2024 iFLYTEK A.I.开发者大赛-讯飞开放平台
TabNet: 模型也是我在这个比赛一个意外收获,这个模型在比赛之中可用。但是需要GPU资源,否则运行真的是太慢了。后面针对这个模型我会写出如何使用的方法策略。
比赛结束后有与其他两位选手聊天,他们都是对数据做了很多分析,有的甚至直接使用Lasso就work了,效果还挺不错的。特征工程无敌呀。
真个代码部分,了解下有关特征工程的部分就行了,模型部分可以慢慢消化。当作一个新的知识点学习吧。
直接上代码
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.model_selection import KFold
from pytorch_tabnet.metrics import Metric
from pytorch_tabnet.tab_model import TabNetRegressor
import torch
from torch.optim import Adam, SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau, CosineAnnealingWarmRestarts
from sklearn.metrics import mean_absolute_error
import traceback
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['PingFang HK'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题
pd.set_option('precision', 10)
pd.set_option('display.max_rows', None)
# 时间解析模块
def parse_date(train_df=None):
train_df['datetime'] = pd.to_datetime(train_df['时间'])
train_df['timestamp'] = train_df['datetime'].astype('int64') / 10000000
train_df['year'] = train_df['datetime'].dt.year
train_df['month'] = train_df['datetime'].dt.month
train_df['day'] = train_df['datetime'].dt.day
train_df['hour'] = train_df['datetime'].dt.hour
train_df["minute"] = train_df['datetime'].dt.minute
train_df['dayofweek'] = train_df['datetime'].dt.dayofweek
# train_df['datetime'].dt.dayofmonth
return train_df
def same_position_tempture_resid(train_df, index=[]):
for i in index:
train_df[f'下部温度{i}_resid'] = train_df[f'下部温度{i}'] - train_df[f'下部温度设定{i}']
train_df[f'下部温度{i}_dist_4'] = train_df[f'下部温度设定4'] - train_df[f'下部温度设定{i}']
train_df[f'下部温度{i}_dist_4_moth_100'] = (train_df[f'下部温度{i}_dist_4'] >= 99) * 1
return train_df
df_train = pd.read_csv("../data/train.csv")
df_test = pd.read_csv("../data/test.csv")
submit = pd.read_csv("../data/submit.csv")
df_train = parse_date(df_train)
df_test = parse_date(df_test)
df_train = df_train.sort_values("datetime")
df_train = df_train.reset_index(drop=True)
df_train['train'] = 1
df_train.loc[1057, '下部温度9'] = 829
df_test = df_test.sort_values("datetime")
df_test = df_test.reset_index(drop=True)
df_test['train'] = 0
flow_cols = [col for col in df_train.columns if "流量" in col]
up_temp_sets = [col for col in df_train.columns if "上部温度设定" in col]
down_temp_sets = [col for col in df_train.columns if "下部温度设定" in col]
up_tempture = [col for col in df_train.columns if "上部温度" in col and col not in up_temp_sets]
down_tempture = [col for col in df_train.columns if "下部温度" in col and col not in down_temp_sets]
# train_df.columns.tolist()
import re
small_cols = ['下部温度5', '上部温度8', '上部温度9',
'上部温度10',
'上部温度11',
'上部温度12',
'上部温度13',
'上部温度14',
'上部温度15',
'上部温度16',
'上部温度17',
'下部温度3',
'下部温度4',
'下部温度6',
'下部温度7',
'下部温度8',
'下部温度9',
'下部温度10',
'下部温度11',
'下部温度12',
'下部温度13',
'下部温度14',
'下部温度15',
'下部温度16',
'下部温度17'] + [
'上部温度1',
'上部温度2',
'上部温度3',
'上部温度4',
'上部温度5',
'上部温度6',
'上部温度7',
'下部温度1',
'下部温度2',
]
def get_same_temp(test_df, cols):
for col in cols:
nums = re.findall("\d+", col)
num = nums[0]
if "上部温度" in col:
print(num, col)
test_df[col] = test_df[f'上部温度设定{num}']
elif "下部温度" in col:
test_df[col] = test_df[f'下部温度设定{num}']
return test_df
df_test = get_same_temp(df_test, small_cols)
df = pd.concat([df_train, df_test])
df = df.sort_values(['year', 'month', 'day', 'hour', "minute"])
df = df.reset_index(drop=True)
down_label = ['下部温度1', '下部温度2', '下部温度3']
up_label = ['上部温度7', '上部温度1', '上部温度2', '上部温度3', '上部温度4', '上部温度5', '上部温度6']
cat_cols = ['year', 'month', 'day', 'hour', 'minute', 'dayofweek']
keep_cols = df_test.columns.tolist()
def resid_model(y, y_pred):
# residual plots
y_pred = pd.Series(y_pred, index=y.index)
resid = y - y_pred
mean_resid = resid.mean()
std_resid = resid.std()
z = abs(resid) / (y + 0.01)
# print(z)
n_outliers = sum(abs(resid) > 10000)
outliers = y[(abs(resid) > 10000)].index
print(outliers)
plt.figure(figsize=(15, 5))
ax_131 = plt.subplot(1, 3, 1)
plt.plot(y, y_pred, '.')
plt.xlabel('y')
plt.ylabel('y_pred');
plt.title('corr = {:.3f}'.format(np.corrcoef(y, y_pred)[0][1]))
ax_132 = plt.subplot(1, 3, 2)
plt.plot(y, y - y_pred, '.')
plt.xlabel('y')
plt.ylabel('y - y_pred');
plt.title('std resid = {:.3f}'.format(std_resid))
ax_133 = plt.subplot(1, 3, 3)
z.plot.hist(bins=50, ax=ax_133)
plt.xlabel('z')
plt.title('{:.0f} samples with z>3'.format(n_outliers))
plt.show()
# return outliers
def get_down_tempture_sets_resid(df, diffed_col="下部温度设定4",
diff_col='下部温度设定1'):
distacnce = 0
if "上部" in diff_col:
print(f"----- {diff_col}_diff_{diffed_col}")
df['上部温度设定4_diff_上部温度设定1'] = df['上部温度设定4'] - df['上部温度设定1']
df[f'{diffed_col}_diff_{diff_col}'] = df[diffed_col] - df[diff_col]
df['上部温度设定4_div_上部温度设定1'] = df['上部温度设定4'] / df['上部温度设定1']
df[f'{diffed_col}_div_{diff_col}'] = df[diffed_col] / df[diff_col]
df['flag'] = (df['上部温度设定4_diff_上部温度设定1'] > 300) * 1
else:
df['下部温度设定4_diff_下部温度设定1'] = df['下部温度设定4'] - df['下部温度设定1']
df['下部温度设定4_div_下部温度设定1'] = df['下部温度设定4'] / df['下部温度设定1']
df[f'{diffed_col}_diff_{diff_col}'] = df[diffed_col] - df[diff_col]
df[f'{diffed_col}_div_{diff_col}'] = df[diffed_col] / df[diff_col]
distacnce = 300
df['flag'] = (df['下部温度设定4_diff_下部温度设定1'] > 300) * 1
return df
def get_same_type_tempure(row, df_train, label, woindows):
try:
heads = woindows
train_flag = int(row['train'])
hour = row['hour']
minute = row['minute']
timesamp = row['timestamp']
flag = row['flag']
nums = re.findall("\d+", label)
num = int(nums[0])
chars = re.findall("(\w+)(\d+)", label)[0][0]
label_map_set_col = f"{chars}设定{num}"
set_temps = row[label_map_set_col]
# (df_train[label_map_set_col]==set_temps)&
df_temp_ = df_train[
(df_train[label_map_set_col] == set_temps) & (df_train['flag'] == flag) & (df_train['hour'] == hour) & (
df_train['timestamp'] < timesamp)]
df_temp = df_temp_.tail(woindows)
# df_temp_2 = df_temp_.head(30)
if len(df_temp) == 0:
return set_temps, set_temps, 0, set_temps, set_temps, set_temps
min_ = df_temp[label].min()
max_ = df_temp[label].max()
std_ = df_temp[label].std()
mean_ = df_temp[label].mean()
median_ = df_temp[label].median()
ewm_ = df_temp[label].ewm(span=heads, adjust=False).mean().values[-1]
del df_temp
return min_, max_, std_, mean_, median_, ewm_
except Exception as e:
print(traceback.format_exc())
def predict_result(df, train_df=None, result_df=None, label="下部温度1"):
result_cols = result_df.columns.tolist()
nums = re.findall("\d+", label)
num = nums[0]
chars = re.findall("(\w+)(\d+)", label)[0][0]
df[f'{label}_new_label'] = (df[label] - df[f"{chars}设定{num}"])
label_new = f'{label}_new_label'
label_map_set_col = f"{chars}设定{num}"
df[f'{label_map_set_col}_ratio'] = df[label_map_set_col].pct_change()
# df[f'{label_map_set_col}_ratio']
if chars in "下部温度":
balance_col = "下部温度设定4"
new_cols = [f'{balance_col}_diff_{label_map_set_col}', f'{balance_col}_div_{label_map_set_col}',
'下部温度设定4_diff_下部温度设定1', '下部温度设定4_div_下部温度设定1']
else:
balance_col = "上部温度设定4"
new_cols = list(set(['上部温度设定4_diff_上部温度设定1', '上部温度设定4_div_上部温度设定1',
f'{balance_col}_diff_{label_map_set_col}', f'{balance_col}_div_{label_map_set_col}']))
down_df = get_down_tempture_sets_resid(df, balance_col, diff_col=label_map_set_col)
train_df = down_df[down_df['train'] == 1].reset_index(drop=True)
his_feats = []
for wind in [7, 28]:
his_feat = [f"{label}_min_{wind}", f"{label}_max_{wind}",
f"{label}_std_{wind}", f"{label}_mean_{wind}",
f"{label}_median_{wind}", f"{label}_ewm_{wind}"]
his_feats.extend(his_feat)
down_df[his_feat] = down_df.apply(lambda x: get_same_type_tempure(x, train_df, label, wind), axis=1,
result_type="expand")
# return down_df
# print(down_df[his_feats].isna().sum())
down_df = down_df.fillna(-99)
for use_flag in [0, 1]:
max_epoches = 60
if use_flag==1:
max_epoches = 100
df_train = down_df[(down_df['train'] == 1) & (down_df['flag'] == use_flag)].reset_index(drop=True)
# df_train = down_train_df
df_test = down_df[(down_df['train'] == 0) & (down_df['flag'] == use_flag)].reset_index(drop=True)
# print(df_test.unique())
print("Nan shape", df_test[his_feats].isna().sum())
# print(df_test[df_test[his_feats].isna()].head())
print(down_df.shape, df_train.shape, df_test.shape)
feats = [f'流量{num}',
'上部温度设定1',
'year', 'month', 'day', 'hour',
'minute', 'dayofweek', ] + new_cols + [f'{label_map_set_col}_ratio'] + his_feats
feats = list(set(feats))
cat_cols = ['year', 'month', 'day', 'hour', 'minute', 'dayofweek']
cat_idxs = [i for i, f in enumerate(feats) if f in cat_cols]
cat_dims = [df_train[i].nunique() for i in cat_cols]
# print(df_train[feats].head())
# print(cat_idxs)
# print(cat_dims)
tabnet_params = dict(
cat_idxs=[],
cat_dims=[],
cat_emb_dim=1,
n_d=16,
n_a=16,
n_steps=2, # 模型获取能力代表
gamma=2,
n_independent=2,
n_shared=2,
lambda_sparse=0,
optimizer_fn=Adam,
optimizer_params=dict(lr=(2e-2)),
mask_type="entmax",
scheduler_params=dict(T_0=200, T_mult=1, eta_min=1e-4, last_epoch=-1, verbose=False),
# 学习速率自动调整
scheduler_fn=CosineAnnealingWarmRestarts,
seed=42,
verbose=10,
)
split = 5
# kf = KFold(n_splits=split, shuffle=False, random_state=2021)
folds = KFold(n_splits=split, shuffle=True, random_state=1314) # 1314
oof = np.zeros((len(df_train), 1))
importance = 0
pred_y = np.zeros(len(df_test))
val_all = []
# for fold, (train_idx, val_idx) in enumerate(train_splits):
for fold, (train_idx, val_idx) in enumerate(folds.split(df_train)):
print(f'--------------------------- {len(train_idx)}', fold)
val_all.extend(val_idx)
print(f'Training fold {fold + 1}')
X_train, X_val = df_train.loc[train_idx, feats].values, df_train.loc[val_idx, feats].values
y_train, y_val = df_train.loc[train_idx, label_new].values.reshape(-1, 1), df_train.loc[
val_idx, label_new].values.reshape(-1, 1)
model = TabNetRegressor(**tabnet_params)
model.fit(
X_train, y_train,
eval_set=[(X_val, y_val)],
max_epochs=max_epoches,
patience=50,
batch_size=64,
virtual_batch_size=32,
num_workers=8,
drop_last=False,
eval_metric=[MYMAE],
loss_fn=my_mean
)
oof[val_idx] = model.predict(X_val)
# print(model.predict(df_test[feats].values))
pred_y += model.predict(df_test[feats].values).flatten() / split
# if save_model:
# joblib.dump(value=model, filename=f'../model/lgb_5fold_{fold}.m')
print(f'labe = {label} use_flag = {use_flag} mae = ',
mean_absolute_error(oof.reshape(-1) + df_train[label_map_set_col], df_train[label]))
# resid_model(df_train[label_new], oof)
result_df = result_df[result_cols]
df_test[label + "_add"] = pred_y
result_df = result_df.merge(df_test[cat_cols + [label + "_add"] + his_feats], on=cat_cols, how="left")
# print(result_df.head())
result_df.loc[~result_df[label + "_add"].isna(), label] = result_df.loc[~result_df[
label + "_add"].isna(), label + "_add"] + result_df.loc[~result_df[
label + "_add"].isna(), label_map_set_col]
return result_df.reset_index(drop=True)[result_cols + his_feats]
# df['day'].nunique()
class MYMAE(Metric):
def __init__(self):
self._name = "mymae"
self._maximize = False
def __call__(self, y_true, y_score):
return mean_absolute_error(y_true, y_score)
def my_mean(y_pred, y_true):
return torch.mean(torch.abs(y_true - y_pred)).clone()
# up_label+down_label
for label in tqdm((down_label + up_label)[5:]):
print(f"-------------------{label}")
df_test = predict_result(df, df_train, df_test[keep_cols], label)
df_test['上部温度1'] = df_test['上部温度1'].clip(upper=410)
x = pd.concat([df_train, df_test]).sort_values(['year', 'month', 'day', 'hour', "minute"]).reset_index(drop=True)
submit = pd.read_csv("../data/submit.csv")
submit_cols = submit.columns.tolist()
df_test[submit_cols].to_csv("../data/tabnet_submit_his_winds_label_last_5.csv",index=False, encoding='utf_8_sig')