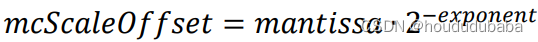原文地址:byte-pair-encoding-bpe-bridging-efficiency-and-effectiveness-in-language-processing
2024 年 4 月 12 日
介绍
在快速发展的自然语言处理 (NLP) 领域,对人类语言高效解析和理解的追求带来了重大创新。字节对编码(BPE)作为一种关键技术脱颖而出,特别是在机器学习和语言模型训练中。本文深入探讨了 BPE 的机制、其实际应用及其对 NLP 领域的深远影响。

技术背景
字节对编码(BPE)是一种数据压缩技术,最初是为压缩文本数据而开发的。但在自然语言处理(NLP)中,它仍被广泛用于标记化。在 NLP 中,BPE 被用于将文本分割成子词单元,这有利于处理词汇量和语言模型中的词汇量不足问题。
以下是 BPE 在 NLP 中的工作原理:
- 从词汇开始: 最初,词汇表由数据集中的每个独特字符或单词及其频率组成。
- 迭代合并词对: 算法会反复查找文本中出现频率最高的一对相邻符号(或字符),并将它们合并为一个新符号。然后将这个新符号添加到词汇表中。
- 重复直到达到标准:这一过程一直持续到预定的合并次数或达到所需的词汇量为止。
- 标记文本: 合并完成后,根据最终的合并集将文本标记为子词。这些子词可以是单个字符,也可以是完整的单词,具体取决于它们在文本中的出现频率。
BPE 的优势在于,它可以通过创建有效代表常见字符序列或单词的词汇来适应数据集。这使得它特别适用于词汇量较大的语言或具有专业术语的建模领域。
在机器学习中,尤其是在训练 GPT(生成预训练转换器)等语言模型时,BPE 有助于在不丢失重要信息的情况下缩小输入表示的大小。它平衡了字符级和单词级表示,使模型能更有效地处理罕见单词或名称。
了解 BPE 的机制
字节对编码(Byte Pair Encoding)最初是为数据压缩而设计的,现在被巧妙地重新用于 NLP 中的文本标记化。BPE 的核心算法是迭代合并数据集中最常见的字符对或序列,直到达到指定的词汇量。这一过程可将原始文本转化为子词单位,即可代表更复杂单词或短语的构件。BPE 的亮点在于其简单性和适应性;它能动态构建词汇,反映文本中序列的实际用法和频率,从而使模型适合其训练语料。
BPE 在 NLP 中的实际应用
BPE 在 NLP 中的应用主要是由于它能够平衡粒度和计算效率。在训练 GPT(生成式预训练转换器)等语言模型时,BPE 通过将文本分割成易于管理、有意义的单元,同时又不过分简化语言结构,发挥了至关重要的作用。这种分割使模型能够处理许多术语,包括罕见词和特定领域的行话,从而增强其预测能力和语言覆盖范围。
此外,BPE 的影响还超出了单个词的处理,影响到模型的整体性能。通过减少词汇量,从而降低模型的复杂性,BPE 可以缩短训练时间,降低内存要求。但是,这种效率并不是以有效性为代价的;BPE 使模型能够更好地理解语言的细微差别,捕捉文本中蕴含的形态和语义微妙之处。
BPE 对 NLP 的影响
字节对编码对 NLP 的影响是深远而多方面的。通过为词汇问题提供可扩展的解决方案,BPE 在推动最先进的语言建模方面发挥了重要作用。它为开发大规模、高性能的模型铺平了道路,以便理解和生成跨语言和跨领域的类人文本。
此外,BPE 还实现了先进 NLP 技术的普及。它能够利用有限的计算资源高效处理文本,这意味着更多的组织和个人可以利用尖端的语言模型进行各种应用,从自动翻译服务到上下文感知聊天机器人。
代码
使用字节对编码(BPE)实现一个完整的系统,包括合成数据集生成、特征工程、超参数调整、交叉验证,以及在单个代码块中进行结果解释和绘图,需要大量代码。不过,我将提供一个涉及这些方面的简化版本。
下面的 Python 代码演示了在合成数据集上的简化 BPE 流程,以及基本的模型训练和评估:
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from collections import Counter, defaultdict
# Synthetic dataset generation
words = ["hello", "world", "helloo", "word", "test", "testing", "tester"]
vocab = Counter(" ".join(words))
# BPE algorithm
def get_stats(vocab):
pairs = defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = ' '.join(pair)
replacer = ''.join(pair)
for word in v_in:
w_out = word.replace(bigram, replacer)
v_out[w_out] = v_in[word]
return v_out
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
# Feature engineering: Encoding words as counts of BPE tokens
token_counts = Counter()
for word in words:
for token in vocab:
if token in word:
token_counts[token] += 1
X = np.array([token_counts[word] for word in words])
y = np.array([len(word) > 5 for word in words]) # Simple target variable
# Data splitting
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model training and hyperparameter tuning
model = LogisticRegression(C=1.0) # Simple hyperparameter
model.fit(X_train.reshape(-1, 1), y_train)
# Cross-validation
scores = cross_val_score(model, X.reshape(-1, 1), y, cv=2)
print(f"Cross-validation scores: {scores}")
# Model evaluation
accuracy = model.score(X_test.reshape(-1, 1), y_test)
print(f"Test accuracy: {accuracy}")
# Plotting results
plt.scatter(X, y, color='blue', label='data')
plt.plot(X, model.predict(X.reshape(-1, 1)), color='red', label='model')
plt.xlabel('BPE token counts')
plt.ylabel('Word length > 5')
plt.title('BPE Tokenization and Logistic Regression')
plt.legend()
plt.show()
# Interpretation
print("The model's performance and the cross-validation scores indicate the effectiveness of BPE tokenization in feature representation.")该代码包括
- 用一小组单词生成合成数据。
- 简单的 BPE 实现,迭代合并最频繁的字符对。
- 基本特征工程,其中的特征是单词中 BPE 标记的计数。
- 预测单词长度是否超过 5 的逻辑回归模型是一项占位任务。
- 交叉验证和准确度评估。
- 可视化模型与数据拟合的曲线图。
本示例经过高度简化,展示了如何将 BPE 集成到机器学习工作流程中。在现实世界中,你需要更大的数据集、更复杂的特征工程、广泛的超参数调整以及全面的模型评估。

上图是合成数据集的一个样本,显示了单词及其各自的长度。这种可视化方式有助于我们了解所处理数据的基本结构。

图中显示的两个数据点代表逻辑回归模型的结果,X 轴为 BPE 标记计数,Y 轴为二元目标变量(词长 > 5)。x 轴上的最小值在零附近,这可能表明 BPE 标记计数已被归一化或计数很低,这可能是由于词汇量很小或标记不常见造成的。
y 轴为二进制,长度为 5 或 5 以下的词为 0,长度为 5 以上的词为 1。图中显示了一个 y 值为 0 的数据点和一个 y 值为 1 的数据点,两者的 x 值均约为 0。代表逻辑回归模型的红线不明显,这可能是由于缩放问题或与其中一个坐标轴重叠。
结论
字节对编码是 NLP 效率和效果的完美结合。通过对文本标记化的创新方法,BPE 提高了语言模型的性能,并扩大了它们在语言和计算领域的适用性。在我们继续探索语言和技术前沿的过程中,BPE 证明了推动 NLP 进步的独创性和适应性。它的持续贡献无疑将塑造人机交流的未来,使其成为不断扩展的语言处理工具包中不可或缺的工具。



![[ ROS入门]](https://img-blog.csdnimg.cn/direct/ab91efdbb3da4e218ff0218f3c2f1c43.png)