MySQL之SQL的执行流程
- MySQL架构
- 连接层
- 服务层
- 存储引擎
- 连接
- 查看连接
- 连接与线程
- 连接超时
- 最大连接
- 会话与全局
- 查询缓存
- 语法解析和预处理
- 词法解析
- 语法解析
- 预处理
- 查询优化器
- 优化器
- 查询执行计划
- 存储引擎
- 存储引擎概述
- 常用存储引擎
- MyISAM
- InnoDB
- MEMORY
- 存储引擎的选择
- 执行引擎
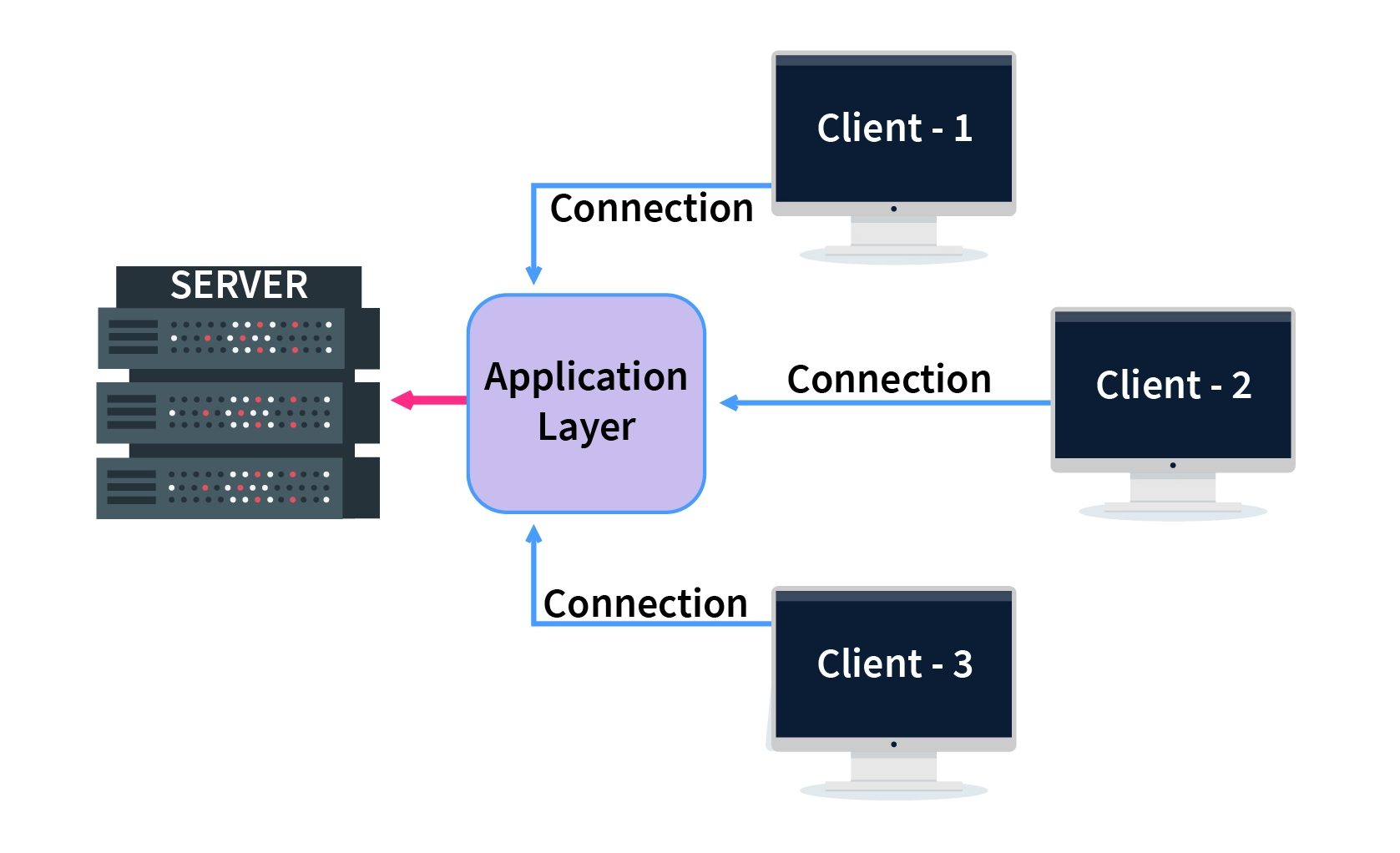
MySQL架构
从整体上,可以把MySQL分成三层:
客户端对接的连接层
真正执行操作的服务层
跟硬件打交道的存储引擎层
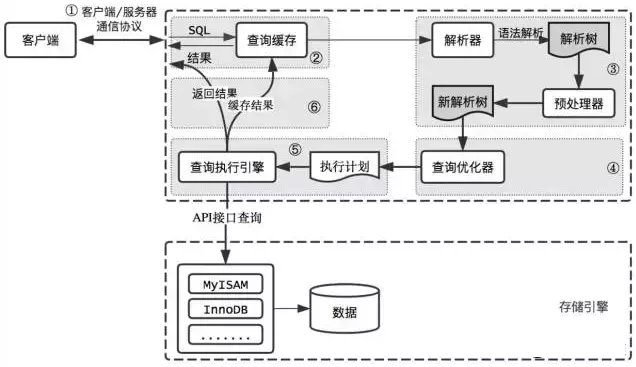
连接层
客户端要连接MySQL服务器3306端口,必须跟服务端建立连接。
管理所有的连接,验证客户端的身份和权限,这些功能在连接层完成。
服务层
连接层会把SQL语句交给服务层,这里面又包含一系列的流程:
查询缓存的判断
根据SQL调用相应的接口
对SQL语句进行词法和语法的解析
然后就是优化器,MySQL底层会根据一定的规侧对SQL语句进行优化,最后再交给执行器去执行。
存储引擎
存储引擎就是数据真正存放的地方,在MySQL里面支持不同的存储引擎。再往下就是内存或者磁盘。
连接
MySQL服务监听端口默认是3306
客户端连接服务端:可以是同步、异步的、长连接、短连接、TCP、Unix Socket等方式
MySQL有专门处理连接的模块,连接的时候需要验证权限
查看连接
查看MySQL当前有多少个连接,使用show status命令,模糊匹配Thread:
mysql> show global status like'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 0 |
| Threads_connected | 1 |
| Threads_created | 1 |
| Threads_running | 1 |
+-------------------+-------+
4 rows in set (0.01 sec)
参数说明:
Threads_cached:缓存中的线程连接数
Threads_connected:当前打开的连接数
Threads_created:为处理连接创建的线程数
Threads_running:非睡眠状态的连接数,通常指并发连接数
连接与线程
客户端连接和服务端线程的关系:
客户端每产生一个连接或者一个会话,在服务端就会创建一个线程来处理
分配线程话,保持连接会消耗服务端的资源。MySQL会把长时间不活动的(SLEEP)连接自动断开
连接超时
连接超时参数:
默认28800 秒,8 小时。
# 非交互式超时时间, 如JDBC 程序
show global variables like'wait _timeout';
# 交互式超时时间, 如数据库工具
show global variables like'interactive_ timeout';
最大连接
MySQL服务允许最大连接数(并发数),在5.7版本中默认是151个,最大可以设置成100000
mysql> show variables like'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 500 |
+-----------------+-------+
1 row in set (0.01 sec)
会话与全局
MySQL中的参数(变量)分为`session`和`global`级别,分别是在当前会话中生效和全局生效
并不是每个参数都有两个级别,比如max_connections就只有全局级别
当没有带参数的时候, 默认是session级别,包括查询和修改。如修改—个参数以后,在本窗口查询生效, 但其他窗口不生效
因此,如果是临时修改,则修改session级别,如果需要在其他会话中生效,必须显式地加上global参数
查询缓存
MySQL内部自带了一个缓存模块,MySQL缓存默认是关闭状态,即不推荐使用。
mysql> show variables like 'query_cache%';
+------------------------------+----------+
| Variable_name | Value |
+------------------------------+----------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 33554432 |
| query_cache_type | OFF |
| query_cache_wlock_invalidate | OFF |
+------------------------------+----------+
5 rows in set (0.01 sec)
MySQL自带缓存应用场景有限
要求SQL语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的SQL
表里面任何一条数据发生变化的时候,这张表所有缓存都会失效
在MySQL8.0中,查询缓存已经被移除
通常缓存这一块还是交由ORM框架(如yBatis默认开启一级缓存)、或使用独立缓存服务
语法解析和预处理
语法解析使用
Parser解析器模块,预处理使用Preprocessor预处理模块
语法解析和预处理就是:对语句基于SQL语法进行词法和语法分析和语义的解析。
词法解析
词法解析就是把一个完整的SQL语句打碎成一个个的单词,记录每个单词/符号是什么类型,从哪里开始到哪里结束。
语法解析
语法解析会对SQL做一些语法检查,如单引号有没有闭合,然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构。这个数据结构叫做解析树
预处理
预处理会检查生成的解析树,解决解析器无法解析的语义。如检查表和列名是否存在,检查名字和别名,保证没有歧义。预处理之后得到一个新的解析树。
查询优化器
优化器
查询优化器使用MySQL的查询优化器的模块(Optimizer)
一条SQL语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。
查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL里面使用的是基于开销(coSt)的优化器,那种执行计划开销最小,就用哪种。
查看查询开销:
mysql> show status like 'Last_query_cost';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| Last_query_cost | 0.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
查询执行计划
经过优化器优化完之后,优化器最终会把解析树变成一个查询执行计划,查询执丸行计划是一个数据结构。
M小ySQL提供一个执行计划的工具。在SQL语句前面加上EXPLAIN,就可以看到执行计划的信息。
mysql> EXPLAIN select * from user where id=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
如果需要得到更详细的信息,可以使用:FORMAT=JSON
mysql> EXPLAIN FORMAT=JSON select * from user where id=1;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1.00"
},
"table": {
"table_name": "user",
"access_type": "const",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"id"
],
"key_length": "4",
"ref": [
"const"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.00",
"eval_cost": "0.20",
"prefix_cost": "0.00",
"data_read_per_join": "776"
},
"used_columns": [
"id",
"name",
"age"
]
}
}
} |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
存储引擎
存储引擎概述
默认情况下,每个数据库有一个自己文件夹。创建表后,在该文件夹下会产生与表名相关的文件。任何一个存储引擎都有一个fm文件,这个是表结构定义文件。不同的存储引擎存放数据的方式不一样,产生的文件也不一样。
innodb存储引擎是1个
memory存储引擎没有
myisam存储引擎是2个
查看数据库数据存放路径
mysql> show variables like 'datadir';
+---------------+-------------------+
| Variable_name | Value |
+---------------+-------------------+
| datadir | /www/server/data/ |
+---------------+-------------------+
1 row in set (0.01 sec)
创建数据库与不同存储引擎的数据表
CREATE DATABASE mydb;
CREATE TABLE `user-InnoDB` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `user-MyISAM` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
CREATE TABLE `user-MEMORY` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MEMORY DEFAULT CHARSET=utf8
查看验证
[root@administrator mydb]# pwd
/www/server/data/mydb
[root@administrator mydb]# ls
db.opt user@002dInnoDB.frm user@002dInnoDB.ibd user@002dMEMORY.frm user@002dMyISAM.frm user@002dMyISAM.MYD user@002dMyISAM.MYI
常用存储引擎
MyISAM
MyISAM应用范围比较小。表级锁定限制了读/写的性能,通常用于只读或以读为主的工作。
特点:
支持表级别的锁(插入和更新会锁表)
不支持事务
拥有较高的插入(insert)和查询(select)速度
存储了表的行数(count速度更快
InnoDB
InnoDB是mysq5.7中的默认存储引擎。
InnoDB是一个事务安全的MySQL存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。
InnoDB使用行级锁,提高多用户并发性和性能。
InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。
为了保持数据完整性,InnoDB还支持外键引用完整性约束
适合经常更新的表,存在并发读写或者有事务处理的业务系统
特点:
支持事务,支持外键,因此数据的完整性、一致性更高
支持行级别的锁和表级别的锁
支持读写并发,写不阻塞读
特殊的索引存放方式,可以减少O,提升查询效率
MEMORY
MEMORY将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中快速访问。
InnoDB及其缓冲池内存区域提供了一种通用、持久的方法来将大部分或所有数据保存在内存中,而ndbcluster为大型分布式数据集提供了快速的键值查找。
特点:
把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失。只适合做临时表。
将表中的数据存储到内存中
存储引擎的选择
MySQL支持多种存储引擎,主要使用三种:
InnoDB、AyISAM、MEMORY
具体参考:https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
一张表的存储引擎,是在创建表的时候指定的,使用ENGINE关键字,如:ENGINE=InnoDB。没有指定的时候,数据库使用默认的存储引擎
5.5.5之前,默认的存储引擎是AyISAM
5.5.5之后,默认的存储擎是InnoDB
MySQL之所以支持这么多的存储引擎,就是因为有不同的业务需求,一种存储引擎不能提供所有的特性。
如果对数据致性要求比较高,需要事务支持,可以选择InnoDB
如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM
如果需要一个用于查询的临时表,可以选择MEMORY
当所有存储引擎不满足需求,可自定义存储引擎:https://dev.mysql.com/doc/internals/en/custom-engine.html
注意:每个存储引擎都有自己对应的服务
show engine innodb status;
执行引擎
执行引擎是利用存储引擎提供的相应的AP来完成操作,完成后把数据返回给客户端。
即使修改表的存储引擎,由于不同功能的存储引擎实现的API是相同的,因此操作方式也不需要做任何改变