C代码编译过程
在这篇文章中,我们将探讨C语言代码的编译流程以及进程在运行时的内存布局。编译过程通常包括几个关键步骤:预处理、编译、汇编和链接。
预处理阶段主要是处理源代码文件中的宏定义、头文件包含和条件编译指令。在此阶段,编译器不会进行语法检查,只是简单地扩展宏和合并头文件。
编译阶段,编译器开始检查语法错误,并将经过预处理的代码转换成汇编语言文件。这一步是代码从高级语言到低级语言的关键转换过程。
汇编阶段涉及将汇编语言文件转化为机器可以理解的目标文件,即二进制格式。
链接阶段是将一个或多个目标文件合并成一个单独的可执行文件。这一步也处理了程序中的外部依赖和库函数的引用。
进程的内存分布
● 程序运行起来(没有结束前)就是一个进程
● 对于一个C语言程序而言,内存空间主要由五个部分组成 代码区(text)、数据区(data)、未初始化数据区(bss),堆(heap) 和 栈(stack) 组成
○ 有些人直接把data和bss合起来叫做静态区或全局区
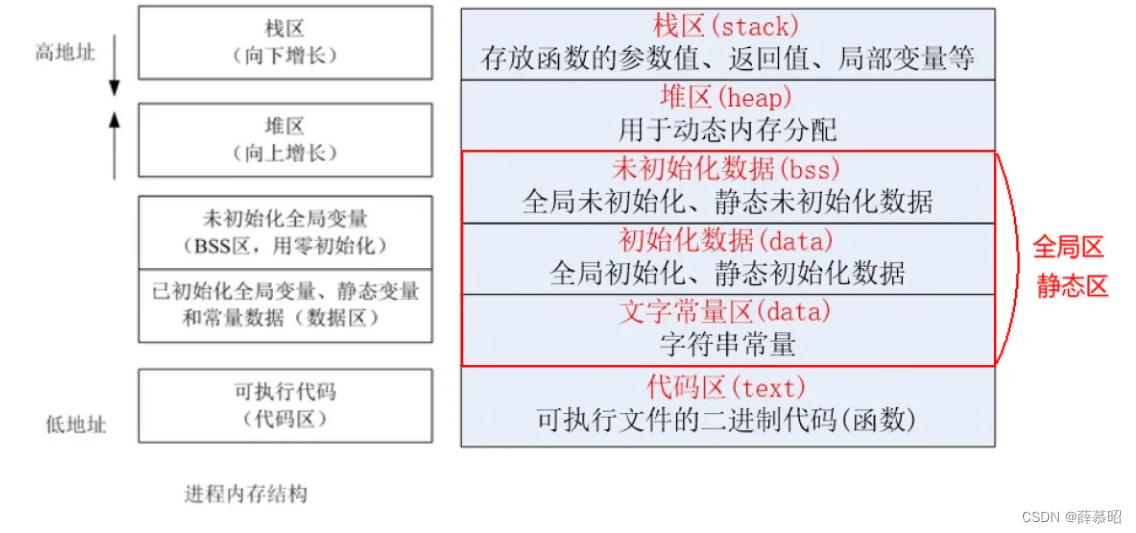
● 代码区(text segment)
○ 加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
● 未初始化数据区(BSS)
○ 加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)的生存周期为整个程序运行过程。
● 全局初始化数据区/静态数据区(data segment)
○ 加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。
● 栈区(stack)
○ 栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
● 堆区(heap)
○ 堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
结尾
深入了解C代码的编译过程和进程内存布局,对于我们来说是非常有益的。通过理解代码是如何转换为可执行程序,并了解程序在内存中的布局方式,我们可以更好地优化代码,提高程序的性能和稳定性。