本文首发于公众号:机器感知

https://mp.weixin.qq.com/s/HlVV3VnqocBI4XBOT6RFHg
A Multi-Level Framework for Accelerating Training Transformer Models
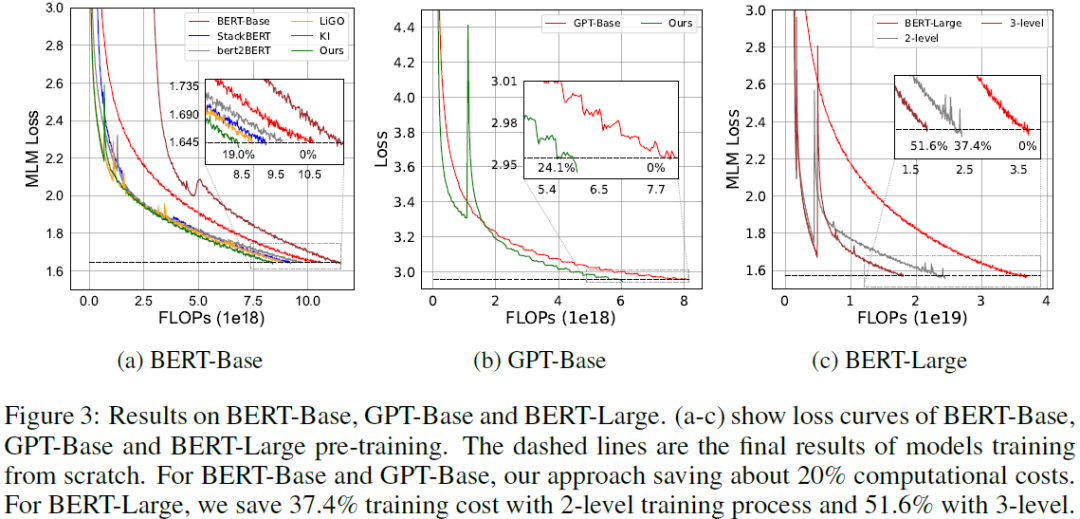
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of mode......
Latent Guard: a Safety Framework for Text-to-image Generation

With the ability to generate high-quality images, text-to-image (T2I) models can be exploited for creating inappropriate content. To prevent misuse, existing safety measures are either based on text blacklists, which can be easily circumvented, or harmful content classification, requiring large datasets for training and offering low flexibility. Hence, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation. Inspired by blacklist-based approaches, Latent Guard learns a latent space on top of the T2I model's text encoder, where it is possible to check the presence of harmful concepts in the input text embeddings. Our proposed framework is composed of a data generation pipeline specific to the task using large language models, ad-hoc architectural components, and a contrastive learning strategy to benefit from the generated data. The effectiveness of our method is verified on three datasets and against four baselines. Code and data w......
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation

Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporati......
Toward a Theory of Tokenization in LLMs

While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{\text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation a......
OccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
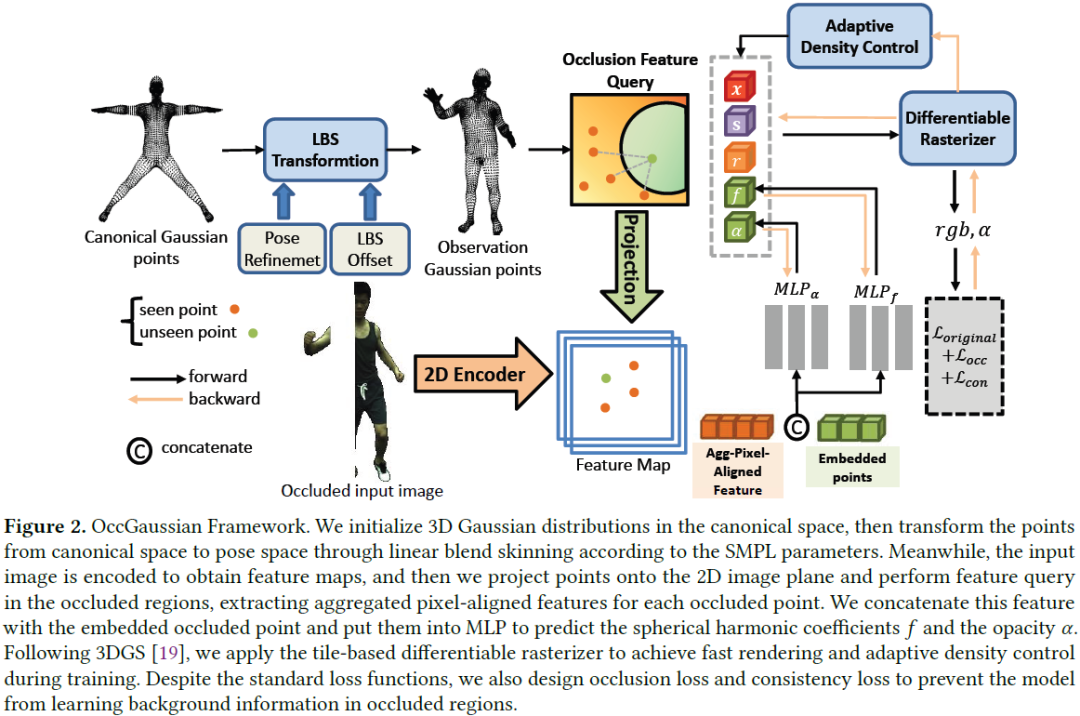
Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the fe......
3D Human Scan With A Moving Event Camera
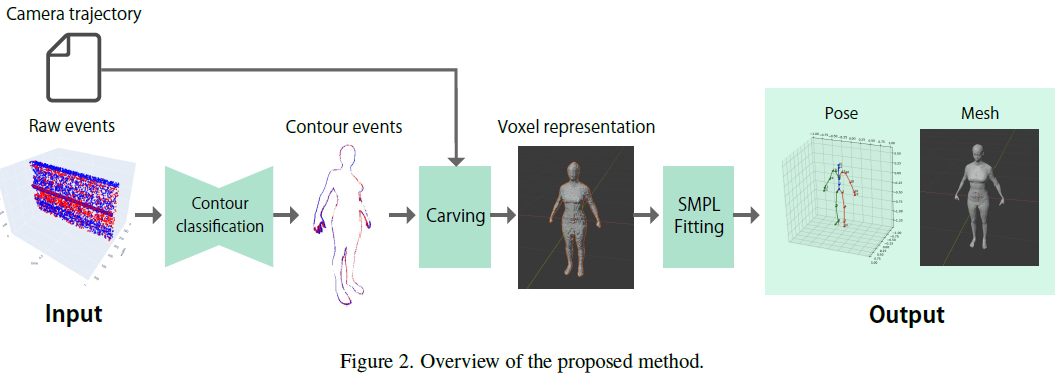
Capturing the 3D human body is one of the important tasks in computer vision with a wide range of applications such as virtual reality and sports analysis. However, conventional frame cameras are limited by their temporal resolution and dynamic range, which imposes constraints in real-world application setups. Event cameras have the advantages of high temporal resolution and high dynamic range (HDR), but the development of event-based methods is necessary to handle data with different characteristics. This paper proposes a novel event-based method for 3D pose estimation and human mesh recovery. Prior work on event-based human mesh recovery require frames (images) as well as event data. The proposed method solely relies on events; it carves 3D voxels by moving the event camera around a stationary body, reconstructs the human pose and mesh by attenuated rays, and fit statistical body models, preserving high-frequency details. The experimental results show that the proposed meth......
FusionPortableV2: A Unified Multi-Sensor Dataset for Generalized SLAM Across Diverse Platforms and Scalable Environments
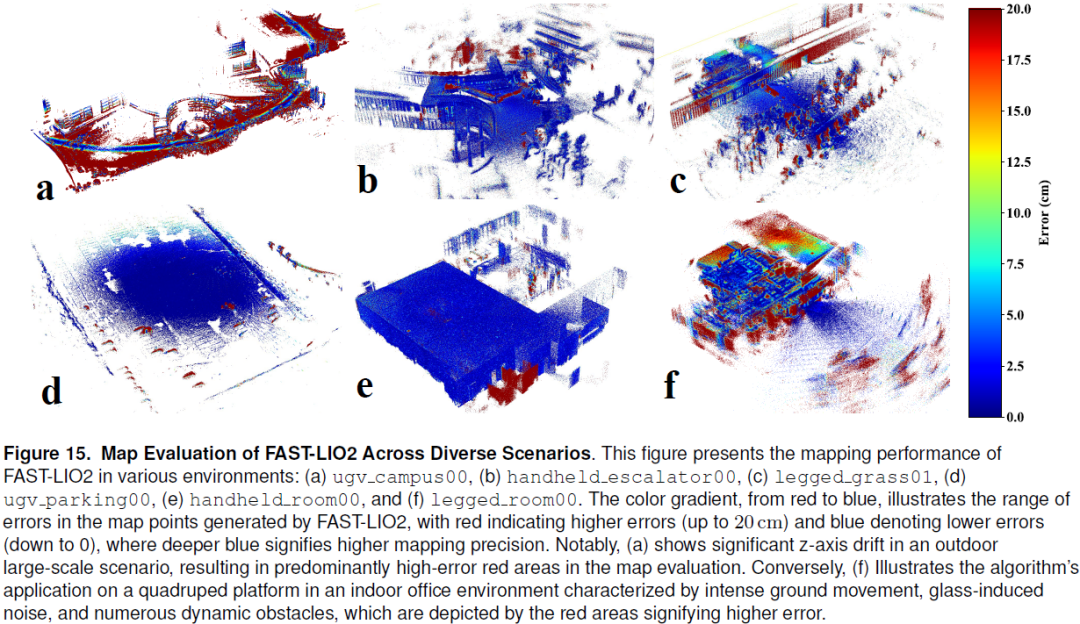
Simultaneous Localization and Mapping (SLAM) technology has been widely applied in various robotic scenarios, from rescue operations to autonomous driving. However, the generalization of SLAM algorithms remains a significant challenge, as current datasets often lack scalability in terms of platforms and environments. To address this limitation, we present FusionPortableV2, a multi-sensor SLAM dataset featuring notable sensor diversity, varied motion patterns, and a wide range of environmental scenarios. Our dataset comprises $27$ sequences, spanning over $2.5$ hours and collected from four distinct platforms: a handheld suite, wheeled and legged robots, and vehicles. These sequences cover diverse settings, including buildings, campuses, and urban areas, with a total length of $38.7km$. Additionally, the dataset includes ground-truth (GT) trajectories and RGB point cloud maps covering approximately $0.3km^2$. To validate the utility of our dataset in advancing SLAM research, w......