1.模拟生成的数据
import random
def generate_data(level, num_samples):
if level not in [2, 3, 4]:
return None
data_list = []
for _ in range(num_samples):
# 构建指定等级的数据
data = str(level)
for _ in range(321):
data += str(random.randint(0, 9))
data_list.append(data)
return data_list
def save_data_to_txt(data, filename):
with open(filename, 'a') as f:
for item in data:
f.write("%s\n" % item)
print(f"Data saved to {filename}")
# 创建一个文件用于存储所有数据
output_filename = "combined_data.txt"
# 生成等级为2的一万条数据,并保存到文件
level_2_data = generate_data(2, 100)
save_data_to_txt(level_2_data, output_filename)
# 生成等级为3的一万条数据,并保存到文件
level_3_data = generate_data(3, 100)
save_data_to_txt(level_3_data, output_filename)
# 生成等级为4的一万条数据,并保存到文件
level_4_data = generate_data(4, 100)
save_data_to_txt(level_4_data, output_filename)
将生成数据和对应的指标的表结合修改
import os
import pandas as pd
def multiply_lists(list1, list2):
if len(list1) != len(list2):
return None
result = []
result.append(str(list2[0]))
for i in range(1, len(list1)):
result.append(str(list1[i] * list2[i]))
return "".join(result)
def save_data_to_txt(data, filename):
try:
with open(filename, 'a') as f:
f.write(data + "\n")
print(f"数据已保存到 {filename}")
except Exception as e:
print(f"保存数据时发生错误:{e}")
# 读取Excel文件
df = pd.read_excel('F:\python level Guarantee 2.0\LG.xlsx', header=None)
# 将每一行转换为列表
rows_as_lists = df.values.tolist()
print(rows_as_lists)
level2 = rows_as_lists.pop()
print(rows_as_lists)
level3 = rows_as_lists.pop()
print(rows_as_lists)
level4 = rows_as_lists.pop()
output_filename = "F:/python level Guarantee 2.0/test.txt"
with open('F:/python level Guarantee 2.0/combined_data.txt', 'r', encoding='utf-8') as f:
data_str_list = [line.strip() for line in f]
for i in data_str_list:
data = list(i)
if int(data[0]) == int(level2[0]):
result = multiply_lists(data, level2)
save_data_to_txt(result, output_filename)
if int(data[0]) == int(level3[0]):
result = multiply_lists(data, level3)
save_data_to_txt(result, output_filename)
if int(data[0]) == int(level4[0]):
result = multiply_lists(data, level4)
save_data_to_txt(result, output_filename)
2.trian
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
import numpy as np
from torch.utils.tensorboard import SummaryWriter
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.net = nn.Sequential(
nn.Linear(321, 159),
nn.ReLU(),
nn.Linear(159,81),
nn.ReLU(),
nn.Linear(81, 3),
)
def forward(self, input):
return self.net(input)
class DataRemake(Dataset):
def __init__(self, path):
self.data, self.label = self.transform(path)
self.len = len(self.label)
def __getitem__(self, index):
label = self.label[index]
data = self.data[index]
return label, data
def __len__(self):
return self.len
def transform(self, path):
data_tensor_list = []
label_list = []
with open(path, mode='r', encoding='utf-8') as fp:
data_str_list = [line.strip() for line in fp]
for i in data_str_list:
data = list(i)
label = int(data[0])
# 转换标签为 one-hot 编码
if label == 2:
label = [1, 0, 0]
elif label == 3:
label = [0, 1, 0]
elif label == 4:
label = [0, 0, 1]
else:
raise ValueError(f"未知的标签值:{label}")
data = data[1:]
# 检查数据的长度并进行处理
if len(data) != 321:
# 如果数据长度不是321,进行填充或截断操作
if len(data) < 322:
# 填充数据,这里假设用0填充
data.extend([0] * (321 - len(data)))
else:
# 截断数据
data = data[:321]
data = np.array(list(map(float, data))).astype(np.float32)
label = np.array(label).astype(np.float32)
data = torch.from_numpy(data)
label = torch.from_numpy(label)
data_tensor_list.append(data)
label_list.append(label)
return data_tensor_list, label_list
# 路径可能需要根据实际情况修改
train_data = DataRemake('result1.txt')
train_dataloader = DataLoader(dataset=train_data, batch_size=10)
net = Model().to(DEVICE)
optimizer = torch.optim.SGD(net.parameters(), lr=0.005)
loss_func = nn.MSELoss().to(DEVICE)
list_pre = []
writer = SummaryWriter('logs')
# 在每个epoch结束时,记录损失值
for epoch in range(1000):
for labels, datas in train_dataloader:
labels = labels.to(DEVICE)
datas = datas.to(DEVICE)
output = net(datas)
loss = loss_func(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
list_pre.append(output)
print('epoch:{} \n loss:{}'.format(epoch, round(loss.item(), 10)))
# 记录损失值到TensorBoard
writer.add_scalar('Loss/train', loss.item(), epoch)
# 记得在训练结束后关闭SummaryWriter
writer.close()
# 保存模型
torch.save(net.state_dict(), 'model.pth')
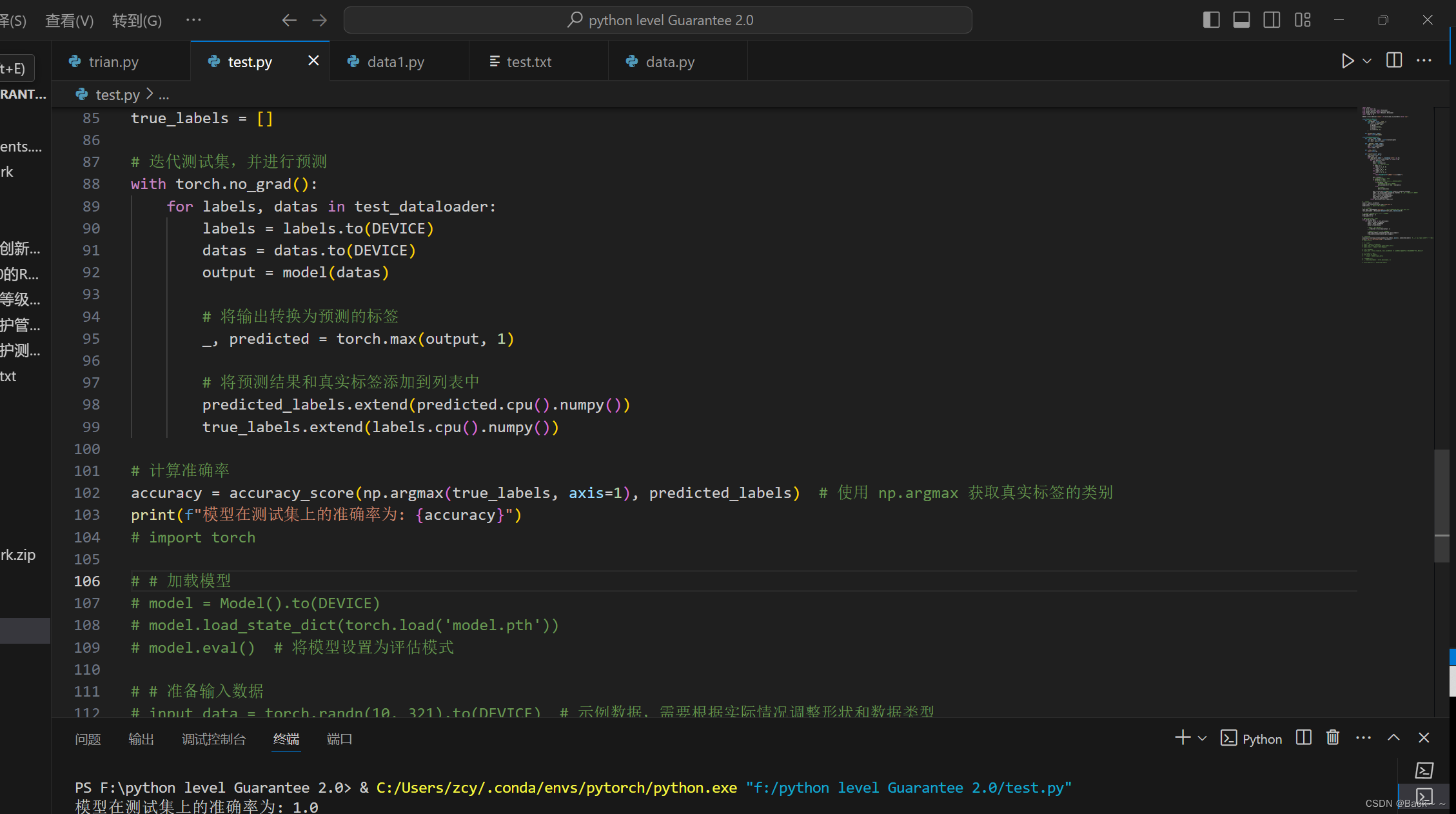
3.test
import torch
from torch import nn
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score
from torch.utils.data import Dataset, DataLoader
import numpy as np
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.net = nn.Sequential(
nn.Linear(321, 159),
nn.ReLU(),
nn.Linear(159,81),
nn.ReLU(),
nn.Linear(81, 3),
)
def forward(self, input):
return self.net(input)
class DataRemake(Dataset):
def __init__(self, path):
self.data, self.label = self.transform(path)
self.len = len(self.label)
def __getitem__(self, index):
label = self.label[index]
data = self.data[index]
return label, data
def __len__(self):
return self.len
def transform(self, path):
data_tensor_list = []
label_list = []
with open(path, mode='r', encoding='utf-8') as fp:
data_str_list = [line.strip() for line in fp]
for i in data_str_list:
data = list(i)
label = int(data[0])
# 转换标签为 one-hot 编码
if label == 2:
label = [1, 0, 0]
elif label == 3:
label = [0, 1, 0]
elif label == 4:
label = [0, 0, 1]
else:
raise ValueError(f"未知的标签值:{label}")
data = data[1:]
# 检查数据的长度并进行处理
if len(data) != 321:
# 如果数据长度不是321,进行填充或截断操作
if len(data) < 322:
# 填充数据,这里假设用0填充
data.extend([0] * (321 - len(data)))
else:
# 截断数据
data = data[:321]
data = np.array(list(map(float, data))).astype(np.float32)
label = np.array(label).astype(np.float32) # 转换标签数据类型为浮点型
data = torch.from_numpy(data)
label = torch.from_numpy(label)
data_tensor_list.append(data)
label_list.append(label)
return data_tensor_list, label_list
# 加载模型
model = Model().to(DEVICE)
model.load_state_dict(torch.load('model.pth'))
model.eval() # 将模型设置为评估模式
# 准备测试数据
test_data = DataRemake('test.txt') # 假设测试数据的路径为'test_data.txt'
test_dataloader = DataLoader(dataset=test_data, batch_size=10)
# 初始化用于存储预测结果和真实标签的列表
predicted_labels = []
true_labels = []
# 迭代测试集,并进行预测
with torch.no_grad():
for labels, datas in test_dataloader:
labels = labels.to(DEVICE)
datas = datas.to(DEVICE)
output = model(datas)
# 将输出转换为预测的标签
_, predicted = torch.max(output, 1)
# 将预测结果和真实标签添加到列表中
predicted_labels.extend(predicted.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
# 计算准确率
accuracy = accuracy_score(np.argmax(true_labels, axis=1), predicted_labels) # 使用 np.argmax 获取真实标签的类别
print(f"模型在测试集上的准确率为: {accuracy}")
# import torch
# # 加载模型
# model = Model().to(DEVICE)
# model.load_state_dict(torch.load('model.pth'))
# model.eval() # 将模型设置为评估模式
# # 准备输入数据
# input_data = torch.randn(10, 321).to(DEVICE) # 示例数据,需要根据实际情况调整形状和数据类型
# # 使用模型进行预测
# with torch.no_grad():
# output = model(input_data)
# # 获取预测结果
# _, predicted_labels = torch.max(output, 1)
# print("预测结果:", predicted_labels)