AIGC实战——VQ-GAN
- 0. 前言
- 1. VQ-GAN
- 2. ViT VQ-GAN
- 小结
- 系列链接
0. 前言
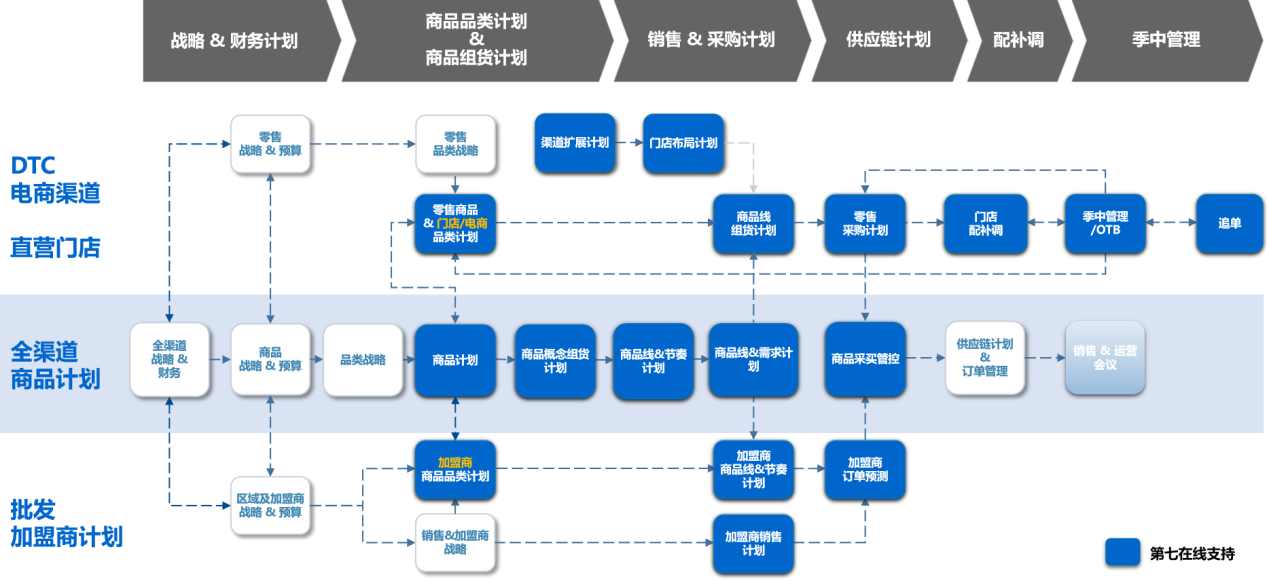
本节中,我们将介绍 VQ-GAN (Vector Quantized Generative Adversarial Network) 和 ViT VQ-GAN,它们融合了变分自编码器 (Variational Autoencoder, VAE)、Transformer 和生成对抗网络 (Generative Adversarial Network, GAN) 的思想,VQ-GAN 是 Muse (Google 提出的文本生成图像生成模型)的关键组成部分。
1. VQ-GAN
VQ-GAN (Vector Quantized GAN) 是于 2020 年提出的生成对抗网络 (Generative Adversarial Network, GAN) 架构,这种模型架构建立在以下基础上:变分自编码器 (Variational Autoencoder, VAE)学习到的表示可以是离散的,而不仅是连续的。这种模型称为 Vector Quantized VAE (VQ-VAE),能够用于生成高质量的图像,同时避免了传统连续潜空间 VAE 经常出现的一些问题,比如后验坍塌(由于过强的解码器导致学到的潜空间不具有信息性)。
离散潜空间指的是一个学习到的向量列表 (codebook),每个向量与相应的索引关联。在 VQ-VAE 中,编码器的任务是将输入图像压缩为一个较小的向量网格,然后将其与 codebook 进行比较。对于每个网格向量,选择最接近该网格方格向量的 codebook 向量(通过欧氏距离),并将其传递给解码器,如下图所示。codebook 是一个长度为
d
d
d (嵌入大小)的学习向量列表,与编码器输出和解码器输入中的通道数相匹配。例如,
e
1
e_1
e1 是一个可以解释为背景的向量。

codebook 可以看作是编码器和解码器共享的一组可学习的离散概念,以便描述给定图像的内容。VQ-VAE 需要找到使这组离散概念尽可能具有信息性的方法,以便编码器可以用对解码器有意义的特定码向量准确地标记每个网格正方形。因此,VQ-VAE 的损失函数需要在重构损失加上以下两项:对齐损失 (alignment loss) 和承诺损失 (commitment loss),以确保编码器的输出向量尽可能接近 codebook 中的向量。使用这些项替代了经典 VAE 中编码分布与标准高斯先验之间的 KL 散度项。
承诺损失 (Commitment loss) 是一种在生成对抗网络 (Generative Adversarial Network, GAN) 中使用的损失函数,旨在促使编码器网络将输入图像的特征信息有效地编码到潜在空间中。
在一般的 GAN 架构中,编码器网络负责将输入图像编码为潜在空间的向量表示,而生成器网络则将该向量映射回原始图像域。为了确保编码过程不丢失重要的图像细节和特征,我们需要鼓励编码器将不同图像之间的相似特征映射到相似的潜在向量附近。
Commitment loss 的目标是最小化潜在向量之间的平均方差,从而迫使编码器将相似图像的潜在表示映射到相近的位置,即使在生成器的输出图像上也能保持这种相似性。通过这种方式,编码器被迫"承诺"将输入图像的特征有效地编码到潜在空间中,以减小潜在向量间的差异。
通过最小化 Commitment loss,可以使编码器网络更好地捕捉图像的特征和结构,并将相似的图像编码为接近的潜在向量。这有助于提高生成图像的质量和一致性,并保持输入图像与生成图像之间的相似性。
然而,VQ-VAE 如何采样新的 codebook 以传递给解码器生成新的图像?显然,使用均匀先验(为每个网格方格均等概率选择每个编码)并不可行。例如,在 MNIST 数据集中,左上角的网格方格很有可能被编码为背景,而靠近图像中心的网格方格则不太可能被编码为背景。为了解决这个问题,VQ-VAE 使用了另一个模型,即自回归模型 PixelCNN,根据先前的编码向量预测网格中下一个编码向量。换句话说,先验由模型学习,而不像传统 VAE 中的先验是静态的。
VQ-VAE 架构的关键变化如下图所示。

首先,VQ-GAN 模型中包含了一个 GAN 判别器,它试图区分 VAE 解码器的输出和真实图像,并带有相应的对抗损失函数。与 VAE 相比,GAN 能够生成更清晰的图像,因此添加判别器改善了整体图像质量。需要注意的是,尽管名字中包含 “GAN”,但 VQ-GAN 模型仍然包含 VAE,GAN 判别器只是作为一个额外的组件而并未替代 VAE。
其次,GAN 判别器并不是一次性预测整个图像的真假,而是预测图像中的小块区域 (patch) 是真实的还是伪造的。PatchGAN 判别器会输出一个预测向量(每个区域一个预测),而不是直接预测整个图像(单个预测值)。使用 PatchGAN 判别器的好处是损失函数可以度量判别器在样式上(而非内容上)区分图像的能力。由于判别器预测的每个元素都是基于图像的一个小区域,必须使用方块的样式而不是内容来做出决策。我们知道 VAE 生成的图像在风格上比真实图像更模糊,因此 PatchGAN 判别器可以促使 VAE 解码器生成比其自然产生的图像更清晰的图像。
第三,VQ-GAN 不再使用单一的均方差重构损失来比较输入图像像素和 VAE 解码器输出的像素,而是使用感知损失项,在编码器和对应的解码器的中间层计算特征图之间的差异,这种损失函数会产生更逼真的图像生成结果。
最后,VQ-GAN 使用 Transformer (而不是 PixelCNN )作为模型的自回归部分,用于生成编码序列。Transformer 在 VQ-GAN 完全训练完毕后进行单独的训练阶段。与其以完全自回归方式使用先前的符号不同,VQ-GAN 选择仅使用滑动窗口范围内的符号来预测符号。这确保模型能够适应更大的图像,这需要更大的潜变量网格大小,因此 Transformer 需要生成更多的符号。
2. ViT VQ-GAN
Yu 等人对 VQ-GAN 进行了扩展,用 Transformer 替换 VQ-GAN 中的卷积编码器和解码器,如下图所示。
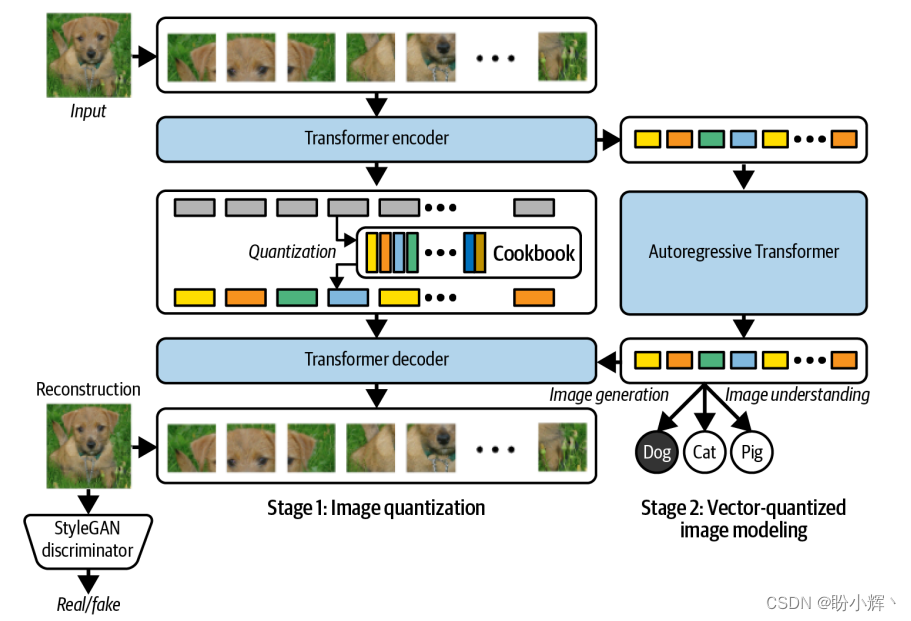
在编码器中,使用了 Vision Transformer (ViT),ViT 是一种神经网络架构,将最初设计用于自然语言处理的 Transformer 模型应用于图像数据。ViT 不使用卷积层从图像中提取特征,而是将图像分为一系列小区域,对其进行分词,然后作为输入传递给编码器 Transformer。
具体而言,在 ViT VQ-GAN 中,非重叠的输入小区域(每个大小为 8 × 8 )首先被展平,然后投影到一个低维嵌入空间中,其中添加了位置嵌入。然后,这个序列被传递给一个标准的编码器 Transformer,并根据学到的 codebook 对结果进行量化。这些整数编码随后由解码器 Transformer 模型处理,最终的输出是一个区域序列,可以重新拼接成原始图像。整个编码器-解码器模型作为自编码器进行端到端训练。
与原始 VQ-GAN 模型一样,第二阶段的训练使用自回归解码器 Transformer 生成编码序列。因此,除了 GAN 判别器和学习的 codebook 外,ViT VQ-GAN 总共还包含三个 Transformer。下图展示了 ViT VQ-GAN 生成的示例图像。
小结
在 VQ-GAN 模型中,将几种不同类型的生成模型进行有效地组合,VQ-GAN 通过额外的对抗损失项鼓励 VAE 生成更清晰的图像。使用自回归T ransformer 构建了一系列能够由 VAE 解码器解码的编码符号。ViT VQ-GAN 进一步扩展了这一思想,将 VQ-GAN 的卷积编码器和解码器替换为 Transformers。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
AIGC实战——能量模型(Energy-Based Model)
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——Transformer模型
AIGC实战——ProGAN(Progressive Growing Generative Adversarial Network)
AIGC实战——StyleGAN(Style-Based Generative Adversarial Network)








![[AI]-(第0期):认知深度学习](https://img-blog.csdnimg.cn/direct/ae6a6d303af44505939b2c817b2c08f3.png#pic_center)