原文:
zh.annas-archive.org/md5/97bc15629f1b51a0671040c56db61b92译者:飞龙
协议:CC BY-NC-SA 4.0
第十章:哈希和符号表
我们之前看过列表,其中项目按顺序存储并通过索引号访问。索引号对计算机来说很有效。它们是整数,因此它们快速且易于操作。但是,它们并不总是对我们很有效。例如,如果我们有一个地址簿条目,索引号为 56,那个数字并没有告诉我们太多。没有什么可以将特定联系人与编号 56 联系起来。它只是列表中的下一个可用位置。
在本章中,我们将研究一个类似的结构:字典。字典使用关键字而不是索引号。因此,如果该联系人被称为James,我们可能会使用关键字James来定位该联系人。也就是说,我们不再通过调用contacts [56]来访问联系人,而是使用contacts [“james”]。
字典通常是使用哈希表构建的。顾名思义,哈希表依赖于一个称为哈希的概念。这就是我们将开始讨论的地方。
在本章中,我们将涵盖以下主题:
-
哈希
-
哈希表
-
具有元素的不同函数
哈希
哈希是将任意大小的数据转换为固定大小的数据的概念。更具体地说,我们将使用这个概念将字符串(或可能是其他数据类型)转换为整数。这可能听起来比实际复杂,所以让我们看一个例子。我们想要对表达式 hello world 进行哈希,也就是说,我们想要得到一个数值,可以说代表这个字符串。
通过使用 ord() 函数,我们可以得到任何字符的序数值。例如,ord('f') 函数返回 102。要得到整个字符串的哈希值,我们可以简单地对字符串中每个字符的序数值求和:
>>> sum(map(ord, 'hello world'))
1116

这很好地运行了。但是,请注意我们可以改变字符串中字符的顺序并得到相同的哈希值:
>>> sum(map(ord, 'world hello'))
1116
字符的序数值的总和对于字符串 gello xorld 也是相同的,因为 g 的序数值比 h 小 1,x 的序数值比 w 大 1,因此:
>>> sum(map(ord, 'gello xorld'))
1116

完美的哈希函数
完美的哈希函数是指每个字符串(目前我们只讨论字符串)都保证是唯一的。在实践中,哈希函数通常需要非常快,因此通常不可能创建一个能给每个字符串一个唯一哈希值的函数。相反,我们要接受有时会发生碰撞(两个或更多个字符串具有相同的哈希值),当发生这种情况时,我们需要想出一种解决策略。
与此同时,我们至少可以想出一种避免一些碰撞的方法。例如,我们可以添加一个乘数,使得每个字符的哈希值成为乘数值乘以字符的序数值。随着我们在字符串中的进展,乘数会增加。这在下面的函数中显示:
def myhash(s):
mult = 1
hv = 0
for ch in s:
hv += mult * ord(ch)
mult += 1
return hv
我们可以在先前使用的字符串上测试这个函数:
for item in ('hello world', 'world hello', 'gello xorld'):
print("{}: {}".format(item, myhash(item)))
运行程序,我们得到以下输出:
% python hashtest.py
hello world: 6736
world hello: 6616
gello xorld: 6742

请注意,最后一行是将第 2 行和第 3 行的值相乘得到的,例如 104 x 1 等于 104。
这次我们得到了不同的字符串的哈希值。当然,这并不意味着我们有一个完美的哈希。让我们尝试字符串 ad 和 ga:
% python hashtest.py
ad: 297
ga: 297
在这里,我们仍然得到了两个不同字符串相同的哈希值。正如我们之前所说的,这并不一定是一个问题,但我们需要想出一种解决碰撞的策略。我们很快将会看到这一点,但首先我们将研究哈希表的实现。
哈希表
哈希表是一种列表形式,其中元素是通过关键字而不是索引号访问的。至少,这是客户端代码将看到的方式。在内部,它将使用我们稍微修改过的哈希函数的版本,以便找到应该插入元素的索引位置。这给了我们快速查找,因为我们使用的是与键的哈希值对应的索引号。
我们首先创建一个类来保存哈希表的项目。这些项目需要有一个键和一个值,因为我们的哈希表是一个键-值存储:
class HashItem:
def __init__(self, key, value):
self.key = key
self.value = value
这给了我们一种非常简单的存储项目的方式。接下来,我们开始着手处理哈希表类本身。和往常一样,我们从构造函数开始:
class HashTable:
def __init__(self):
self.size = 256
self.slots = [None for i in range(self.size)]
self.count = 0
哈希表使用标准的 Python 列表来存储其元素。我们也可以使用之前开发的链表,但现在我们的重点是理解哈希表,所以我们将使用我们手头上的东西。
我们将哈希表的大小设置为 256 个元素。稍后,我们将研究如何在开始填充哈希表时扩展表的策略。现在,我们初始化一个包含 256 个元素的列表。这些元素通常被称为槽或桶。最后,我们添加一个计数器,用于记录实际哈希表元素的数量:

重要的是要注意表的大小和计数之间的区别。表的大小是指表中槽的总数(已使用或未使用)。表的计数,另一方面,只是指填充的槽的数量,或者换句话说,我们已经添加到表中的实际键-值对的数量。
现在,我们将把我们的哈希函数添加到表中。它将类似于我们在哈希函数部分演变的内容,但有一个小小的不同:我们需要确保我们的哈希函数返回一个介于 1 和 256 之间的值(表的大小)。一个很好的方法是返回哈希除以表的大小的余数,因为余数总是一个介于 0 和 255 之间的整数值。
哈希函数只是用于类内部的,我们在名称前面加下划线(_)来表示这一点。这是 Python 中用于表示某些内容是内部使用的常规约定:
def _hash(self, key):
mult = 1
hv = 0
for ch in key:
hv += mult * ord(ch)
mult += 1
return hv % self.size
目前,我们将假设键是字符串。我们将讨论如何稍后使用非字符串键。现在,只需记住_hash()函数将生成字符串的哈希值。
放置元素
我们使用put()函数添加元素到哈希表,并使用get()函数检索。首先,我们将看一下put()函数的实现。我们首先将键和值嵌入到HashItem类中,并计算键的哈希:
def put(self, key, value):
item = HashItem(key, value)
h = self._hash(key)
现在我们需要找到一个空槽。我们从与键的哈希值对应的槽开始。如果该槽为空,我们就在那里插入我们的项目。
然而,如果槽不为空并且项目的键与我们当前的键不同,那么我们就会发生冲突。这就是我们需要想办法处理冲突的地方。我们将通过在先前的哈希值上加一,并取除以哈希表的大小的余数来解决这个问题。这是一种线性解决冲突的方法,非常简单:

while self.slots[h] is not None:
if self.slots[h].key is key:
break
h = (h + 1) % self.size
我们已经找到了插入点。如果这是一个新元素(即先前包含None),那么我们将计数增加一。最后,我们将项目插入到所需位置的列表中:
if self.slots[h] is None:
self.count += 1
self.slots[h] = item
获取元素
get()方法的实现应该返回与键对应的值。我们还必须决定在表中不存在键时该怎么办。我们首先计算键的哈希:
def get(self, key):
h = self._hash(key)
现在,我们只需开始在列表中寻找具有我们正在搜索的键的元素,从具有传入键的哈希值的元素开始。如果当前元素不是正确的元素,那么就像在put()方法中一样,我们在先前的哈希值上加一,并取除以列表大小的余数。这就成为我们的新索引。如果我们找到包含None的元素,我们停止寻找。如果我们找到我们的键,我们返回值:

while self.slots[h] is not None:
if self.slots[h].key is key:
return self.slots[h].value
h = (h+ 1) % self.size
最后,我们决定如果在表中找不到键要做什么。在这里,我们将选择返回None。另一个好的选择可能是引发一个异常:
return None
测试哈希表
为了测试我们的哈希表,我们创建一个HashTable,把一些元素放进去,然后尝试检索这些元素。我们还将尝试get()一个不存在的键。还记得我们的哈希函数返回相同的哈希值的两个字符串 ad 和 ga 吗?为了确保,我们也把它们放进去,看看冲突是如何正确解决的:
ht = HashTable()
ht.put("good", "eggs")
ht.put("better", "ham")
ht.put("best", "spam")
ht.put("ad", "do not")
ht.put("ga", "collide")
for key in ("good", "better", "best", "worst", "ad", "ga"):
v = ht.get(key)
print(v)
运行这个代码返回以下结果:
% python hashtable.py
eggs
ham
spam
None
do not
collide
如你所见,查找键 worst 返回None,因为该键不存在。键ad和ga也返回它们对应的值,显示它们之间的冲突是如何处理的。
使用哈希表的[]
然而,使用put()和get()方法看起来并不是很好。我们希望能够将我们的哈希表视为一个列表,也就是说,我们希望能够使用ht["good"]而不是ht.get("good")。这可以很容易地通过特殊方法__setitem__()和__getitem__()来实现:
def __setitem__(self, key, value):
self.put(key, value)
def __getitem__(self, key):
return self.get(key)
我们的测试代码现在可以这样写:
ht = HashTable()
ht["good"] = "eggs"
ht["better"] = "ham"
ht["best"] = "spam"
ht["ad"] = "do not"
ht["ga"] = "collide"
for key in ("good", "better", "best", "worst", "ad", "ga"):
v = ht[key]
print(v)
print("The number of elements is: {}".format(ht.count))
注意,我们还打印了哈希表中的元素数量。这对我们接下来的讨论很有用。
非字符串键
在大多数情况下,只使用字符串作为键更有意义。但是,如果必要,你可以使用任何其他的 Python 类型。如果你创建了自己的类来用作键,你可能需要重写该类的特殊__hash__()函数,以便获得可靠的哈希值。
注意,你仍然需要计算哈希值的模运算和哈希表的大小,以获得插槽。这个计算应该发生在哈希表中,而不是在键类中,因为表知道自己的大小(键类不应该知道它所属的表的任何信息)。
扩大哈希表
在我们的示例中,哈希表的大小设置为 256。显然,随着我们向列表中添加元素,我们开始填满空插槽。在某个时候,所有的插槽都将被填满,表也将被填满。为了避免这种情况,我们可以在表快要填满时扩大表。
为了做到这一点,我们比较大小和计数。记住size保存了插槽的总数,count保存了包含元素的插槽的数量?如果count等于size,那么我们已经填满了表。
哈希表的负载因子给了我们一个指示,表中有多大比例的可用插槽正在被使用。它的定义如下:

当负载因子接近 1 时,我们需要扩大表格。实际上,我们应该在它达到那里之前就这样做,以避免变得太慢。0.75 可能是一个很好的值,用来扩大表格。
下一个问题是要扩大表多少。一个策略是简单地将表的大小加倍。
开放寻址
我们在示例中使用的冲突解决机制,线性探测,是开放寻址策略的一个例子。线性探测非常简单,因为我们在探测之间使用固定的间隔。还有其他的开放寻址策略,但它们都共享一个想法,即有一个插槽数组。当我们想要插入一个键时,我们会检查插槽是否已经有项目。如果有,我们会寻找下一个可用的插槽。
如果我们有一个包含 256 个插槽的哈希表,那么 256 就是哈希中最大的元素数量。此外,随着负载因子的增加,找到新元素的插入点将需要更长的时间。
由于这些限制,我们可能更喜欢使用不同的策略来解决冲突,例如链接。
链接
链接是一种解决冲突并避免哈希表中元素数量限制的策略。在链接中,哈希表中的插槽初始化为空列表:

当插入元素时,它将被追加到与该元素的哈希值对应的列表中。也就是说,如果您有两个具有相同哈希值 1167 的元素,这两个元素都将被添加到哈希表的插槽 1167 中存在的列表中:

上图显示了具有哈希值 51 的条目列表。
然后通过允许多个元素具有相同的哈希值来避免冲突。它还避免了插入的问题,因为负载因子增加时,我们不必寻找插槽。此外,哈希表可以容纳比可用插槽数量更多的值,因为每个插槽都包含一个可以增长的列表。
当然,如果特定插槽有很多项,搜索它们可能会变得非常缓慢,因为我们必须通过列表进行线性搜索,直到找到具有所需键的元素。这可能会减慢检索速度,这并不好,因为哈希表的目的是高效的:

上图演示了通过列表项进行线性搜索,直到找到匹配项。
我们可以在表插槽中使用另一个允许快速搜索的结构,而不是使用列表。我们已经看过二叉搜索树(BSTs)。我们可以简单地在每个插槽中放置一个(最初为空的)BST:

插槽 51 包含我们搜索键的 BST。但我们仍然可能会遇到一个问题:根据将项添加到 BST 的顺序,我们可能会得到一个搜索树,其效率与列表一样低。也就是说,树中的每个节点都只有一个子节点。为了避免这种情况,我们需要确保我们的 BST 是自平衡的。
符号表
符号表被编译器和解释器用来跟踪已声明的符号及其相关信息。符号表通常使用哈希表构建,因为高效地检索表中的符号很重要。
让我们看一个例子。假设我们有以下 Python 代码:
name = "Joe"
age = 27
这里有两个符号,名称和年龄。它们属于一个命名空间,可以是__main__,但如果您将其放在那里,它也可以是模块的名称。每个符号都有一个值;名称的值为Joe,年龄的值为27。符号表允许编译器或解释器查找这些值。符号名称和年龄成为哈希表中的键。与之关联的所有其他信息,例如值,都成为符号表条目的一部分。
不仅变量是符号,函数和类也是。它们都将被添加到我们的符号表中,因此当需要访问它们中的任何一个时,它们都可以从符号表中访问:

在 Python 中,每个加载的模块都有自己的符号表。符号表被赋予该模块的名称。这样,模块就充当了命名空间。我们可以有多个名为年龄的符号,只要它们存在于不同的符号表中。要访问其中任何一个,我们通过适当的符号表进行访问:

总结
在本章中,我们已经研究了哈希表。我们研究了如何编写哈希函数将字符串数据转换为整数数据。然后我们看了如何使用哈希键快速高效地查找对应于键的值。
我们还注意到哈希函数并不完美,可能会导致多个字符串具有相同的哈希值。这促使我们研究了冲突解决策略。
我们研究了如何扩展哈希表,以及如何查看表的负载因子,以确定何时扩展哈希表。
在本章的最后一节中,我们学习了符号表,通常使用哈希表构建。符号表允许编译器或解释器查找已定义的符号(变量、函数、类等)并检索有关其所有信息。
在下一章中,我们将讨论图和其他算法。
第十一章:图和其他算法
在本章中,我们将讨论图。 这是来自称为图论的数学分支的概念。
图用于解决许多计算问题。 它们的结构比我们所看到的其他数据结构要少得多,遍历等操作可能更加不寻常,我们将会看到。
在本章结束时,您应该能够做到以下几点:
-
了解图是什么
-
了解图的类型及其组成部分
-
知道如何表示图并遍历它
-
对优先队列有一个基本的概念
-
能够实现优先队列
-
能够确定列表中第 i 个最小元素
图
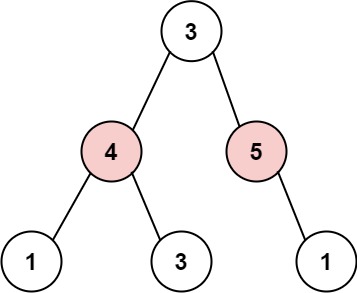
图是一组顶点和边,它们之间形成连接。 在更正式的方法中,图 G 是顶点集 V 和边集 E 的有序对,以G = (V, E)的形式给出。
这里给出了一个图的示例:

现在让我们来看一些图的定义:
-
节点或顶点:图中通常由一个点表示。 顶点或节点是 A、B、C、D 和 E。
-
边:这是两个顶点之间的连接。 连接 A 和 B 的线就是边的一个例子。
-
环:当来自节点的边与自身相交时,该边形成一个环。
-
顶点的度:这是与给定顶点相交的顶点数。 顶点 B 的度为
4。 -
邻接:这指的是节点与其邻居之间的连接。 节点 C 与节点 A 相邻,因为它们之间有一条边。
-
路径:一系列顶点,其中每对相邻的顶点都由一条边连接。
有向和无向图
图可以根据它们是无向的还是有向的进行分类。 无向图简单地将边表示为节点之间的线。 除了它们连接在一起这一事实之外,关于节点之间关系的其他信息都没有:

在有向图中,边除了连接节点外还提供方向。 也就是说,边将被绘制为带有箭头的线,箭头指示边连接两个节点的方向:

边的箭头确定了方向的流动。 在上图中,只能从A到B。 而不能从B到A。
加权图
加权图在边上添加了一些额外的信息。 这可以是指示某些内容的数值。 例如,假设以下图表表示从点A到点D的不同路径。 您可以直接从A到D,也可以选择通过B和C。 与每条边相关的是到达下一个节点所需的时间(以分钟为单位):

也许旅程AD需要您骑自行车(或步行)。 B和C可能代表公交车站。 在B,您需要换乘另一辆公交车。 最后,CD可能是到达D的短途步行。
在这个例子中,AD和ABCD代表两条不同的路径。 路径只是两个节点之间穿过的边的序列。 沿着这些路径,您会发现总共需要40分钟的旅程AD,而旅程ABCD需要25分钟。 如果您唯一关心的是时间,即使需要换乘公交车,您也最好沿着ABCD行驶。
边可以是有向的,并且可能包含其他信息,例如所花费的时间或路径上关联的其他值,这表明了一些有趣的事情。在我们之前使用的数据结构中,我们绘制的线只是连接器。即使它们有箭头从一个节点指向另一个节点,也可以通过在节点类中使用next或previous、parent或child来表示。
对于图来说,将边视为对象与节点一样是有意义的。就像节点一样,边可以包含跟随特定路径所必需的额外信息。
图表示
图可以用两种主要形式表示。一种方法是使用邻接矩阵,另一种方法是使用邻接表。
我们将使用以下图来开发图的两种表示形式:

邻接表
可以使用简单的列表来表示图。列表的索引将表示图中的节点或顶点。在每个索引处,可以存储该顶点的相邻节点:

盒子中的数字代表顶点。索引0代表顶点A,其相邻节点为B和C。
使用列表进行表示相当受限,因为我们缺乏直接使用顶点标签的能力。因此,使用字典更合适。为了表示图中的图表,我们可以使用以下语句:
graph = dict()
graph['A'] = ['B', 'C']
graph['B'] = ['E','A']
graph['C'] = ['A', 'B', 'E','F']
graph['E'] = ['B', 'C']
graph['F'] = ['C']
现在我们很容易确定顶点A有相邻顶点B和C。顶点 F 只有顶点C作为其邻居。
邻接矩阵
图可以使用邻接矩阵来表示的另一种方法。矩阵是一个二维数组。这里的想法是用 1 或 0 来表示两个顶点是否通过一条边连接。
给定邻接表,应该可以创建邻接矩阵。需要一个图的键的排序列表:
matrix_elements = sorted(graph.keys())
cols = rows = len(matrix_elements)
键的长度用于提供矩阵的维度,这些维度存储在cols和rows中。这些值在cols和rows中是相等的:
adjacency_matrix = [[0 for x in range(rows)] for y in range(cols)]
edges_list = []
然后我们设置了一个cols乘以rows的数组,并用零填充它。edges_list变量将存储构成图中边的元组。例如,节点 A 和 B 之间的边将存储为(A, B)。
使用嵌套的 for 循环填充多维数组:
for key in matrix_elements:
for neighbor in graph[key]:
edges_list.append((key,neighbor))
顶点的邻居是通过graph[key]获得的。然后,结合neighbor使用edges_list中存储的元组。
迭代的输出如下:
>>> [('A', 'B'), ('A', 'C'), ('B', 'E'), ('B', 'A'), ('C', 'A'),
('C', 'B'), ('C', 'E'), ('C', 'F'), ('E', 'B'), ('E', 'C'),
('F', 'C')]
现在需要做的是通过使用 1 来填充我们的多维数组,以标记边的存在,使用行adjacency_matrix[index_of_first_vertex][index_of_second_vertex] = 1:
for edge in edges_list:
index_of_first_vertex = matrix_elements.index(edge[0])
index_of_second_vertex = matrix_elements.index(edge[1])
adjacecy_matrix[index_of_first_vertex][index_of_second_vertex] = 1
matrix_elements数组的rows和cols从 A 到 E,索引从 0 到 5。for循环遍历我们的元组列表,并使用index方法获取要存储边的相应索引。
生成的邻接矩阵如下所示:
>>>
[0, 1, 1, 0, 0]
[1, 0, 0, 1, 0]
[1, 1, 0, 1, 1]
[0, 1, 1, 0, 0]
[0, 0, 1, 0, 0]
在第 1 列和第 1 行,0 表示 A 和 A 之间没有边。在第 2 列和第 3 行,C 和 B 之间有一条边。
图遍历
由于图不一定具有有序结构,遍历图可能更加复杂。遍历通常涉及跟踪已经访问过的节点或顶点以及尚未访问过的节点或顶点。一个常见的策略是沿着一条路径走到死胡同,然后向上走,直到有一个可以选择的路径。我们也可以迭代地从一个节点移动到另一个节点,以遍历整个图或部分图。在下一节中,我们将讨论用于图遍历的广度优先搜索和深度优先搜索算法。
广度优先搜索
广度优先搜索算法从一个节点开始,选择该节点或顶点作为其根节点,并访问相邻节点,然后探索图的下一级邻居。
考虑以下图表作为图:

该图是一个无向图的示例。我们继续使用这种类型的图来帮助解释,而不会太啰嗦。
图的邻接列表如下:
graph = dict()
graph['A'] = ['B', 'G', 'D']
graph['B'] = ['A', 'F', 'E']
graph['C'] = ['F', 'H']
graph['D'] = ['F', 'A']
graph['E'] = ['B', 'G']
graph['F'] = ['B', 'D', 'C']
graph['G'] = ['A', 'E']
graph['H'] = ['C']
为了以广度优先的方式遍历这个图,我们将使用队列。算法创建一个列表来存储已访问的节点,随着遍历过程的进行。我们将从节点 A 开始遍历。
节点 A 被排队并添加到已访问节点的列表中。之后,我们使用while循环来实现对图的遍历。在while循环中,节点 A 被出队。它未访问的相邻节点 B、G 和 D 按字母顺序排序并排队。队列现在包含节点 B、D 和 G。这些节点也被添加到已访问节点的列表中。此时,我们开始while循环的另一个迭代,因为队列不为空,这也意味着我们并没有真正完成遍历。
节点 B 被出队。在它的相邻节点 A、F 和 E 中,节点 A 已经被访问。因此,我们只按字母顺序排队节点 E 和 F。然后将节点 E 和 F 添加到已访问节点的列表中。
此时,我们的队列中包含以下节点:D、G、E 和 F。已访问节点的列表包含 A、B、D、G、E、F。
节点 D 被出队,但是它的所有相邻节点都已经被访问过,所以我们只是出队它。队列前面的下一个节点是 G。我们出队节点 G,但是我们也发现它的所有相邻节点都已经被访问,因为它们在已访问节点的列表中。节点 G 也被出队。我们也出队节点 E,因为它的所有节点都已经被访问。现在队列中唯一的节点是节点 F。
节点 F 被出队,我们意识到它的相邻节点 B、D 和 C 中,只有节点 C 还没有被访问。然后我们将节点 C 排队并将其添加到已访问节点的列表中。节点 C 被出队。节点 C 有相邻节点 F 和 H,但 F 已经被访问,只剩下节点 H。节点 H 被排队并添加到已访问节点的列表中。
最后,while循环的最后一次迭代将导致节点 H 被出队。它唯一的相邻节点 C 已经被访问过。一旦队列完全为空,循环就会中断。
在图中遍历的输出是 A、B、D、G、E、F、C、H。
广度优先搜索的代码如下所示:
from collections import deque
def breadth_first_search(graph, root):
visited_vertices = list()
graph_queue = deque([root])
visited_vertices.append(root)
node = root
while len(graph_queue) > 0:
node = graph_queue.popleft()
adj_nodes = graph[node]
remaining_elements =
set(adj_nodes).difference(set(visited_vertices))
if len(remaining_elements) > 0:
for elem in sorted(remaining_elements):
visited_vertices.append(elem)
graph_queue.append(elem)
return visited_vertices
当我们想要找出一组节点是否在已访问节点的列表中时,我们使用语句remaining_elements = set(adj_nodes).difference(set(visited_vertices))。这使用了集合对象的差异方法来找出在adj_nodes中但不在visited_vertices中的节点。
在最坏的情况下,每个顶点或节点和边都将被遍历,因此算法的时间复杂度是O(|V| + |E|),其中|V|是顶点或节点的数量,而|E|是图中边的数量。
深度优先搜索
正如其名称所示,该算法在遍历广度之前遍历图中任何特定路径的深度。因此,首先访问子节点,然后访问兄弟节点。它适用于有限图,并需要使用堆栈来维护算法的状态:
def depth_first_search(graph, root):
visited_vertices = list()
graph_stack = list()
graph_stack.append(root)
node = root
算法首先创建一个列表来存储已访问的节点。graph_stack堆栈变量用于辅助遍历过程。为了连贯起见,我们使用普通的 Python 列表作为堆栈。
起始节点称为root,并与图的邻接矩阵graph一起传递。root被推入堆栈。node = root保存堆栈中的第一个节点:
while len(graph_stack) > 0:
if node not in visited_vertices:
visited_vertices.append(node)
adj_nodes = graph[node]
if set(adj_nodes).issubset(set(visited_vertices)):
graph_stack.pop()
if len(graph_stack) > 0:
node = graph_stack[-1]
continue
else:
remaining_elements =
set(adj_nodes).difference(set(visited_vertices))
first_adj_node = sorted(remaining_elements)[0]
graph_stack.append(first_adj_node)
node = first_adj_node
return visited_vertices
while循环的主体将被执行,前提是堆栈不为空。如果node不在已访问节点的列表中,我们将其添加进去。node的所有相邻节点都被adj_nodes = graph[node]收集起来。如果所有相邻节点都已经被访问过,我们就从堆栈中弹出该节点,并将node设置为graph_stack[-1]。graph_stack[-1]是堆栈顶部的节点。continue语句跳回到while循环的测试条件的开头。
另一方面,如果并非所有相邻节点都已经被访问,那么通过使用语句remaining_elements = set(adj_nodes).difference(set(visited_vertices))来找到尚未访问的节点。
在sorted(remaining_elements)中的第一个项目被分配给first_adj_node,并被推入堆栈。然后我们将堆栈的顶部指向这个节点。
当while循环结束时,我们将返回visited_vertices。
对算法进行干扰运行将会很有用。考虑以下图表:

这样一个图的邻接列表如下所示:
graph = dict()
graph['A'] = ['B', 'S']
graph['B'] = ['A']
graph['S'] = ['A','G','C']
graph['D'] = ['C']
graph['G'] = ['S','F','H']
graph['H'] = ['G','E']
graph['E'] = ['C','H']
graph['F'] = ['C','G']
graph['C'] = ['D','S','E','F']
节点 A 被选择为我们的起始节点。节点 A 被推入堆栈,并添加到visisted_vertices列表中。这样做时,我们标记它已经被访问。堆栈graph_stack是用简单的 Python 列表实现的。我们的堆栈现在只有 A 一个元素。我们检查节点 A 的相邻节点 B 和 S。为了测试节点 A 的所有相邻节点是否都已经被访问,我们使用 if 语句:
if set(adj_nodes).issubset(set(visited_vertices)):
graph_stack.pop()
if len(graph_stack) > 0:
node = graph_stack[-1]
continue
如果所有节点都已经被访问,我们就弹出堆栈的顶部。如果堆栈graph_stack不为空,我们就将堆栈顶部的节点赋给node,并开始另一个while循环主体的执行。语句set(adj_nodes).issubset(set(visited_vertices))将在adj_nodes中的所有节点都是visited_vertices的子集时评估为True。如果 if 语句失败,这意味着还有一些节点需要被访问。我们可以通过remaining_elements = set(adj_nodes).difference(set(visited_vertices))获得这些节点的列表。
从图表中,节点B和S将被存储在remaining_elements中。我们将按字母顺序访问列表:
first_adj_node = sorted(remaining_elements)[0]
graph_stack.append(first_adj_node)
node = first_adj_node
我们对remaining_elements进行排序,并将第一个节点返回给first_adj_node。这将返回 B。我们通过将其附加到graph_stack来将节点 B 推入堆栈。我们通过将其分配给node来准备访问节点 B。
在while循环的下一次迭代中,我们将节点 B 添加到visited nodes列表中。我们发现 B 的唯一相邻节点 A 已经被访问过。因为 B 的所有相邻节点都已经被访问,我们将其从堆栈中弹出,只留下节点 A。我们返回到节点 A,并检查它的所有相邻节点是否都已经被访问。现在节点 A 只有 S 是未访问的节点。我们将 S 推入堆栈,并重新开始整个过程。
遍历的输出是 A-B-S-C-D-E-H-G-F。
深度优先搜索在解决迷宫问题、查找连通分量和查找图的桥梁等方面有应用。
其他有用的图方法
您经常关心的是找到两个节点之间的路径。您可能还希望找到节点之间的所有路径。另一个有用的方法是找到节点之间的最短路径。在无权图中,这只是它们之间边的最小数量的路径。在加权图中,正如您所见,这可能涉及计算通过一组边的总权重。
当然,在不同的情况下,您可能希望找到最长或最短的路径。
优先队列和堆
优先队列基本上是一种按优先级顺序返回项目的队列类型。这个优先级可以是,例如,最低的项目总是先弹出。虽然它被称为队列,但优先队列通常使用堆来实现,因为对于这个目的来说非常高效。
考虑到,在商店中,顾客排队等候,服务只在队列的前面提供。每个顾客都会花一些时间在队列中等待服务。如果队列中顾客的等待时间分别为 4、30、2 和 1,那么队列中的平均等待时间变为(4 + 34 + 36 + 37)/4,即27.75。然而,如果我们改变服务顺序,使等待时间最短的顾客先接受服务,那么我们会得到不同的平均等待时间。这样做,我们通过(1 + 3 + 7 + 37)/4计算我们的新平均等待时间,现在等于12,一个更好的平均等待时间。显然,按照等待时间最少的顾客开始服务是有益的。按照优先级或其他标准选择下一个项目的方法是创建优先队列的基础。
堆是满足堆属性的数据结构。堆属性规定父节点和其子节点之间必须存在一定的关系。这个属性必须适用于整个堆。
在最小堆中,父节点和子节点之间的关系是父节点必须始终小于或等于其子节点。由于这个关系,堆中最小的元素必须是根节点。
另一方面,在最大堆中,父节点大于或等于其子节点。由此可知,最大值组成了根节点。
从我们刚刚提到的内容中可以看出,堆是树,更具体地说,是二叉树。
虽然我们将使用二叉树,但实际上我们将使用一个列表来表示它。这是可能的,因为堆将存储一个完全二叉树。完全二叉树是指在开始填充下一行之前,每一行必须完全填满:

为了使索引的数学运算更容易,我们将保留列表中的第一项(索引 0)为空。之后,我们将树节点从上到下、从左到右放入列表中:

如果你仔细观察,你会注意到你可以很容易地检索任何节点 n 的子节点。左子节点位于2n,右子节点位于2n + 1。这总是成立的。
我们将看一个最小堆的实现。反过来得到最大堆的逻辑应该不难。
class Heap:
def __init__(self):
self.heap = [0]
self.size = 0
我们用零初始化我们的堆列表,以表示虚拟的第一个元素(请记住,我们只是为了简化数学而这样做)。我们还创建一个变量来保存堆的大小。这不是必需的,因为我们可以检查列表的大小,但我们总是要记得减去一个。所以我们选择保持一个单独的变量。
插入
插入一个项目本身非常简单。我们将新元素添加到列表的末尾(我们理解为树的底部)。然后我们将堆的大小增加一。
但是在每次插入后,如果需要,我们需要将新元素浮动起来。请记住,最小堆中最小的元素需要是根元素。我们首先创建一个名为float的辅助方法来处理这个问题。让我们看看它应该如何行为。想象一下我们有以下堆,并且想要插入值2:

新元素占据了第三行或级别中的最后一个插槽。它的索引值是7。现在我们将该值与其父元素进行比较。父元素位于索引7/2 = 3(整数除法)。该元素持有6,所以我们交换2:

我们的新元素已经被交换并移动到索引3。我们还没有到达堆的顶部(3 / 2 > 0),所以我们继续。我们元素的新父节点在索引3/2 = 1。所以我们比较并且如果需要的话再次交换:

在最后一次交换之后,我们得到了以下堆。请注意它如何符合堆的定义:

接下来是我们刚刚描述的实现:
def float(self, k):
我们将循环直到达到根节点,以便我们可以将元素浮动到需要到达的最高位置。由于我们使用整数除法,一旦我们低于 2,循环就会中断:
while k // 2 > 0:
比较父节点和子节点。如果父节点大于子节点,则交换两个值:
if self.heap[k] < self.heap[k//2]:
self.heap[k], self.heap[k//2] = self.heap[k//2],
self.heap[k]
最后,不要忘记向上移动树:
k //= 2
这个方法确保元素被正确排序。现在我们只需要从我们的insert方法中调用它:
def insert(self, item):
self.heap.append(item)
self.size += 1
self.float(self.size)
注意insert中的最后一行调用了float()方法来根据需要重新组织堆。
弹出
就像插入一样,pop()本身是一个简单的操作。我们移除根节点并将堆的大小减一。然而,一旦根节点被弹出,我们需要一个新的根节点。
为了尽可能简单,我们只需取列表中的最后一个项目并将其作为新的根。也就是说,我们将它移动到列表的开头。但现在我们可能不会在堆的顶部有最小的元素,所以我们执行与float操作相反的操作:让新的根节点根据需要下沉。
与插入一样,让我们看看整个操作在现有堆上是如何工作的。想象一下以下堆。我们弹出root元素,暂时使堆没有根:

由于我们不能有一个没有根的堆,我们需要用某物填充这个位置。如果我们选择将一个子节点移上去,我们将不得不弄清楚如何重新平衡整个树结构。所以,我们做一些非常有趣的事情。我们将列表中的最后一个元素移上去填充root元素的位置:

现在这个元素显然不是堆中最小的。这就是我们开始将其下沉的地方。首先我们需要确定将其下沉到哪里。我们比较两个子节点,以便较小的元素将作为根节点下沉时浮动上去:

右子节点显然更小。它的索引是3,代表根索引* 2 + 1。我们继续将我们的新根节点与该索引处的值进行比较:

现在我们的节点跳到了索引3。我们需要将其与较小的子节点进行比较。然而,现在我们只有一个子节点,所以我们不需要担心要与哪个子节点进行比较(对于最小堆来说,它总是较小的子节点):

这里不需要交换。由于没有更多的行,我们完成了。请再次注意,在sink()操作完成后,我们的堆符合堆的定义。
现在我们可以开始实现这个。在执行sink()方法之前,注意我们需要确定要将父节点与哪个子节点进行比较。好吧,让我们把这个选择放在自己的小方法中,这样代码看起来会简单一些:
def minindex(self, k):
我们可能会超出列表的末尾,在这种情况下,我们返回左子节点的索引:
if k * 2 + 1 > self.size:
return k * 2
否则,我们只需返回较小的两个子节点的索引:
elif self.heap[k*2] < self.heap[k*2+1]:
return k * 2
else:
return k * 2 + 1
现在我们可以创建sink函数:
def sink(self, k):
与之前一样,我们将循环以便将我们的元素下沉到所需的位置:
while k * 2 <= self.size:
接下来,我们需要知道左侧还是右侧的子节点进行比较。这就是我们使用minindex()函数的地方:
mi = self.minindex(k)
就像我们在float()方法中所做的那样,我们比较父节点和子节点,看看是否需要交换:
if self.heap[k] > self.heap[mi]:
self.heap[k], self.heap[mi] = self.heap[mi],
self.heap[k]
我们需要确保向下移动树,以免陷入循环:
k = mi
现在唯一剩下的就是实现pop()本身。这非常简单,因为sink()方法执行了大部分工作:
def pop(self):
item = self.heap[1]
self.heap[1] = self.heap[self.size]
self.size -= 1
self.heap.pop()
self.sink(1)
return item
测试堆
现在我们只需要一些代码来测试堆。我们首先创建我们的堆并插入一些数据:
h = Heap()
for i in (4, 8, 7, 2, 9, 10, 5, 1, 3, 6):
h.insert(i)
我们可以打印堆列表,只是为了检查元素的排序方式。如果你将其重新绘制为树形结构,你应该注意到它满足堆的所需属性:
print(h.heap)
现在我们将一个一个地弹出项目。注意项目是如何按照从低到高的顺序出来的。还要注意每次弹出后堆列表是如何改变的。最好拿出纸和笔,在每次弹出后重新绘制这个列表作为一棵树,以充分理解sink()方法的工作原理:
for i in range(10):
n = h.pop()
print(n)
print(h.heap)
在排序算法的章节中,我们将重新组织堆排序算法的代码。
一旦你的最小堆正常工作并且了解它的工作原理,实现最大堆应该是一项简单的任务。你所需要做的就是颠倒逻辑。
选择算法
选择算法属于一类算法,旨在解决在列表中找到第 i 小元素的问题。当列表按升序排序时,列表中的第一个元素将是列表中最小的项。列表中的第二个元素将是列表中第二小的元素。列表中的最后一个元素将是列表中最小的元素,但也将符合列表中最大的元素。
在创建堆数据结构时,我们已经了解到调用pop方法将返回堆中最小的元素。从最小堆中弹出的第一个元素是列表中第一个最小的元素。同样,从最小堆中弹出的第七个元素将是列表中第七小的元素。因此,要找到列表中第 i 小的元素,我们需要弹出堆i次。这是在列表中找到第 i 小的元素的一种非常简单和高效的方法。
但在第十四章中,选择算法,我们将学习另一种方法,通过这种方法我们可以在列表中找到第 i 小的元素。
选择算法在过滤嘈杂数据、查找列表中的中位数、最小和最大元素以及甚至可以应用于计算机国际象棋程序中。
摘要
本章讨论了图和堆。我们研究了使用列表和字典在 Python 中表示图的方法。为了遍历图,我们研究了广度优先搜索和深度优先搜索。
然后我们将注意力转向堆和优先队列,以了解它们的实现。本章以使用堆的概念来找到列表中第 i 小的元素而结束。
图的主题非常复杂,仅仅一章是不够的。与节点的旅程将在本章结束。下一章将引领我们进入搜索的领域,以及我们可以有效搜索列表中项目的各种方法。
第十二章:搜索
在前面章节中开发的数据结构中,对所有这些数据结构执行的一个关键操作是搜索。在本章中,我们将探讨可以用来在项目集合中查找元素的不同策略。
另一个利用搜索的重要操作是排序。在没有某种搜索操作的情况下,几乎不可能进行排序。搜索的“搜索方式”也很重要,因为它影响了排序算法的执行速度。
搜索算法分为两种广义类型。一种类型假定要对其应用搜索操作的项目列表已经排序,而另一种类型则没有。
搜索操作的性能受到即将搜索的项目是否已经排序的影响,我们将在后续主题中看到。
线性搜索
让我们把讨论重点放在线性搜索上,这是在典型的 Python 列表上执行的。

前面的列表中的元素可以通过列表索引访问。为了在列表中找到一个元素,我们使用线性搜索技术。这种技术通过使用索引从列表的开头移动到末尾来遍历元素列表。检查每个元素,如果它与搜索项不匹配,则检查下一个元素。通过从一个元素跳到下一个元素,列表被顺序遍历。
在处理本章和其他章节中的部分时,我们使用包含整数的列表来增强我们的理解,因为整数易于比较。
无序线性搜索
包含元素60、1、88、10和100的列表是无序列表的一个示例。列表中的项目没有按大小顺序排列。要在这样的列表上执行搜索操作,首先从第一个项目开始,将其与搜索项目进行比较。如果没有匹配,则检查列表中的下一个元素。这将继续进行,直到我们到达列表中的最后一个元素或找到匹配为止。
def search(unordered_list, term):
unordered_list_size = len(unordered_list)
for i in range(unordered_list_size):
if term == unordered_list[i]:
return i
return None
search函数的参数是包含我们数据的列表和我们要查找的项目,称为搜索项。
数组的大小被获取,并决定for循环执行的次数。
if term == unordered_list[i]:
...
在for循环的每次迭代中,我们测试搜索项是否等于索引指向的项目。如果为真,则无需继续搜索。我们返回发生匹配的位置。
如果循环运行到列表的末尾,没有找到匹配项,则返回None表示列表中没有这样的项目。
在无序项目列表中,没有关于如何插入元素的指导规则。这影响了搜索的方式。缺乏顺序意味着我们不能依赖任何规则来执行搜索。因此,我们必须逐个访问列表中的项目。如下图所示,对于术语66的搜索是从第一个元素开始的,然后移动到列表中的下一个元素。因此60与66进行比较,如果不相等,我们将66与1、88等进行比较,直到在列表中找到搜索项。

无序线性搜索的最坏情况运行时间为O(n)。在找到搜索项之前,可能需要访问所有元素。如果搜索项位于列表的最后位置,就会出现这种情况。
有序线性搜索
在列表的元素已经排序的情况下,我们的搜索算法可以得到改进。假设元素已按升序排序,搜索操作可以利用列表的有序性使搜索更有效。
算法简化为以下步骤:
-
顺序移动列表。
-
如果搜索项大于循环中当前检查的对象或项目,则退出并返回
None。
在迭代列表的过程中,如果搜索项大于当前项目,则没有必要继续搜索。

当搜索操作开始并且第一个元素与(5)进行比较时,没有匹配。但是因为列表中还有更多元素,搜索操作继续检查下一个元素。继续进行的更有力的原因是,我们知道搜索项可能与大于2的任何元素匹配。
经过第 4 次比较,我们得出结论,搜索项不能在6所在的位置之上找到。换句话说,如果当前项目大于搜索项,那么就意味着没有必要进一步搜索列表。
def search(ordered_list, term):
ordered_list_size = len(ordered_list)
for i in range(ordered_list_size):
if term == ordered_list[i]:
return i
elif ordered_list[i] > term:
return None
return None
if语句现在适用于此检查。elif部分测试ordered_list[i] > term的条件。如果比较结果为True,则该方法返回None。
方法中的最后一行返回None,因为循环可能会遍历列表,但仍然找不到与搜索项匹配的任何元素。
有序线性搜索的最坏情况时间复杂度为O(n)。一般来说,这种搜索被认为是低效的,特别是在处理大型数据集时。
二进制搜索
二进制搜索是一种搜索策略,通过不断减少要搜索的数据量,从而提高搜索项被找到的速度,用于在列表中查找元素。
要使用二进制搜索算法,要操作的列表必须已经排序。
二进制这个术语有很多含义,它帮助我们正确理解算法。
在每次尝试在列表中查找项目时,必须做出二进制决策。一个关键的决定是猜测列表的哪一部分可能包含我们正在寻找的项目。搜索项是否在列表的前半部分还是后半部分,也就是说,如果我们总是将列表视为由两部分组成?
如果我们不是从列表的一个单元移动到另一个单元,而是采用一个经过教育的猜测策略,我们很可能会更快地找到项目的位置。
举个例子,假设我们想要找到一本 1000 页书的中间页。我们已经知道每本书的页码是从 1 开始顺序编号的。因此可以推断,第 500 页应该正好在书的中间,而不是从第 1 页、第 2 页翻到第 500 页。假设我们现在决定寻找第 250 页。我们仍然可以使用我们的策略轻松找到这一页。我们猜想第 500 页将书分成两半。第 250 页将位于书的左侧。不需要担心我们是否能在第 500 页和第 1000 页之间找到第 250 页,因为它永远不会在那里找到。因此,使用第 500 页作为参考,我们可以打开大约在第 1 页和第 500 页之间的一半页面。这让我们更接近找到第 250 页。
以下是对有序项目列表进行二进制搜索的算法:
def binary_search(ordered_list, term):
size_of_list = len(ordered_list) - 1
index_of_first_element = 0
index_of_last_element = size_of_list
while index_of_first_element <= index_of_last_element:
mid_point = (index_of_first_element + index_of_last_element)/2
if ordered_list[mid_point] == term:
return mid_point
if term > ordered_list[mid_point]:
index_of_first_element = mid_point + 1
else:
index_of_last_element = mid_point - 1
if index_of_first_element > index_of_last_element:
return None
假设我们要找到列表中项目10的位置如下:

该算法使用while循环来迭代地调整列表中用于查找搜索项的限制。只要起始索引index_of_first_element和index_of_last_element索引之间的差异为正,while循环就会运行。
算法首先通过将第一个元素(0)的索引与最后一个元素(4)的索引相加,然后除以2找到列表的中间索引mid_point。
mid_point = (index_of_first_element + index_of_last_element)/2
在这种情况下,10并不在列表中间位置或索引上被找到。如果我们搜索的是120,我们将不得不将index_of_first_element调整为mid_point +1。但是因为10位于列表的另一侧,我们将index_of_last_element调整为mid_point-1:

现在我们的index_of_first_element和index_of_last_element的新索引分别为0和1,我们计算中点(0 + 1)/2,得到0。新的中点是0,我们找到中间项并与搜索项进行比较,ordered_list[0]得到值10。哇!我们找到了搜索项。
通过将index_of_first_element和index_of_last_element的索引重新调整,将列表大小减半,这一过程会持续到index_of_first_element小于index_of_last_element为止。当这种情况不成立时,很可能我们要搜索的项不在列表中。
这里的实现是迭代的。我们也可以通过应用移动标记搜索列表开头和结尾的相同原则,开发算法的递归变体。
def binary_search(ordered_list, first_element_index, last_element_index, term):
if (last_element_index < first_element_index):
return None
else:
mid_point = first_element_index + ((last_element_index - first_element_index) / 2)
if ordered_list[mid_point] > term:
return binary_search(ordered_list, first_element_index, mid_point-1,term)
elif ordered_list[mid_point] < term:
return binary_search(ordered_list, mid_point+1, last_element_index, term)
else:
return mid_point
对二分查找算法的这种递归实现的调用及其输出如下:
store = [2, 4, 5, 12, 43, 54, 60, 77]
print(binary_search(store, 0, 7, 2))
Output:
>> 0
递归二分查找和迭代二分查找之间唯一的区别是函数定义,以及计算mid_point的方式。在((last_element_index - first_element_index) / 2)操作之后,mid_point的计算必须将其结果加到first_element_index上。这样我们就定义了要尝试搜索的列表部分。
二分查找算法的最坏时间复杂度为O(log n)。每次迭代将列表减半,遵循元素数量的 log n 进展。
不言而喻,log x假定是指以 2 为底的对数。
插值搜索
二分查找算法的另一个变体可能更接近于模拟人类在任何项目列表上执行搜索的方式。它仍然基于尝试对排序的项目列表进行良好猜测,以便找到搜索项目的可能位置。
例如,检查以下项目列表:

要找到120,我们知道要查看列表的右侧部分。我们对二分查找的初始处理通常会首先检查中间元素,以确定是否与搜索项匹配。
更人性化的做法是选择一个中间元素,不仅要将数组分成两半,还要尽可能接近搜索项。中间位置是根据以下规则计算的:
mid_point = (index_of_first_element + index_of_last_element)/2
我们将用一个更好的公式替换这个公式,这个公式将使我们更接近搜索项。mid_point将接收nearest_mid函数的返回值。
def nearest_mid(input_list, lower_bound_index, upper_bound_index, search_value):
return lower_bound_index + (( upper_bound_index -lower_bound_index)/ (input_list[upper_bound_index] -input_list[lower_bound_index])) * (search_value -input_list[lower_bound_index])
nearest_mid函数的参数是要执行搜索的列表。lower_bound_index和upper_bound_index参数表示我们希望在其中找到搜索项的列表范围。search_value表示正在搜索的值。
这些值用于以下公式:
lower_bound_index + (( upper_bound_index - lower_bound_index)/ (input_list[upper_bound_index] - input_list[lower_bound_index])) * (search_value - input_list[lower_bound_index])
给定我们的搜索列表,44,60,75,100,120,230和250,nearest_mid将使用以下值进行计算:
lower_bound_index = 0
upper_bound_index = 6
input_list[upper_bound_index] = 250
input_list[lower_bound_index] = 44
search_value = 230
现在可以看到,mid_point将接收值5,这是我们搜索项位置的索引。二分查找将选择100作为中点,这将需要再次运行算法。
以下是典型二分查找与插值查找的更直观的区别。对于典型的二分查找,找到中点的方式如下:

可以看到,中点实际上大致站在前面列表的中间位置。这是通过列表 2 的除法得出的结果。
另一方面,插值搜索会这样移动:

在插值搜索中,我们的中点更倾向于左边或右边。这是由于在除法时使用的乘数的影响。从前面的图片可以看出,我们的中点已经偏向右边。
插值算法的其余部分与二分搜索的方式相同,只是中间位置的计算方式不同。
def interpolation_search(ordered_list, term):
size_of_list = len(ordered_list) - 1
index_of_first_element = 0
index_of_last_element = size_of_list
while index_of_first_element <= index_of_last_element:
mid_point = nearest_mid(ordered_list, index_of_first_element, index_of_last_element, term)
if mid_point > index_of_last_element or mid_point < index_of_first_element:
return None
if ordered_list[mid_point] == term:
return mid_point
if term > ordered_list[mid_point]:
index_of_first_element = mid_point + 1
else:
index_of_last_element = mid_point - 1
if index_of_first_element > index_of_last_element:
return None
nearest_mid函数使用了乘法操作。这可能产生大于upper_bound_index或小于lower_bound_index的值。当发生这种情况时,意味着搜索项term不在列表中。因此返回None表示这一点。
那么当ordered_list[mid_point]不等于搜索项时会发生什么呢?好吧,我们现在必须重新调整index_of_first_element和index_of_last_element,使算法专注于可能包含搜索项的数组部分。这就像我们在二分搜索中所做的一样。
if term > ordered_list[mid_point]:
index_of_first_element = mid_point + 1
如果搜索项大于ordered_list[mid_point]处存储的值,那么我们只需要调整index_of_first_element变量指向索引mid_point + 1。
下面的图片展示了调整的过程。index_of_first_element被调整并指向mid_point+1的索引。
 这张图片只是说明了中点的调整。在插值中,中点很少将列表均分为两半。
这张图片只是说明了中点的调整。在插值中,中点很少将列表均分为两半。
另一方面,如果搜索项小于ordered_list[mid_point]处存储的值,那么我们只需要调整index_of_last_element变量指向索引mid_point - 1。这个逻辑被捕捉在 if 语句的 else 部分中index_of_last_element = mid_point - 1。

这张图片展示了重新计算index_of_last_element对中点位置的影响。
让我们使用一个更实际的例子来理解二分搜索和插值算法的内部工作原理。
假设列表中有以下元素:
[ 2, 4, 5, 12, 43, 54, 60, 77]
索引 0 存储了 2,索引 7 找到了值 77。现在,假设我们想在列表中找到元素 2。这两种不同的算法会如何处理?
如果我们将这个列表传递给插值search函数,nearest_mid函数将返回一个等于0的值。仅仅通过一次比较,我们就可以找到搜索项。
另一方面,二分搜索算法需要三次比较才能找到搜索项,如下图所示:

第一个计算出的mid_point是3。第二个mid_point是1,最后一个找到搜索项的mid_point是0。
选择搜索算法
二分搜索和插值搜索操作的性能比有序和无序线性搜索函数都要好。由于在列表中顺序探测元素以找到搜索项,有序和无序线性搜索的时间复杂度为O(n)。当列表很大时,这会导致性能非常差。
另一方面,二分搜索操作在尝试搜索时会将列表切成两半。在每次迭代中,我们比线性策略更快地接近搜索项。时间复杂度为O(log n)。尽管使用二分搜索可以获得速度上的提升,但它不能用于未排序的项目列表,也不建议用于小型列表。
能够找到包含搜索项的列表部分在很大程度上决定了搜索算法的性能。在插值搜索算法中,计算中间值以获得更高概率的搜索项。插值搜索的时间复杂度为O(log(log n)),这比其变体二分搜索更快。
摘要
在本章中,我们考察了两种搜索算法。讨论了线性搜索和二分搜索算法的实现以及它们的比较。本节还讨论了二分搜索变体——插值搜索。在接下来的章节中,知道使用哪种搜索操作将是相关的。
在下一章中,我们将利用所学知识对项目列表执行排序操作。
第十三章:排序
当收集到数据时,总会有必要对数据进行排序。排序操作对所有数据集都是常见的,无论是名称集合、电话号码还是简单的待办事项列表。
在本章中,我们将学习一些排序技术,包括以下内容:
-
冒泡排序
-
插入排序
-
选择排序
-
快速排序
-
堆排序
在我们对这些排序算法的处理中,我们将考虑它们的渐近行为。一些算法相对容易开发,但性能可能较差。其他一些稍微复杂的算法将表现出色。
排序后,对一组项目进行搜索操作变得更加容易。我们将从最简单的排序算法开始–冒泡排序算法。
排序算法
在本章中,我们将介绍一些排序算法,这些算法的实现难度各不相同。排序算法根据它们的内存使用、复杂性、递归性质、是否基于比较等等因素进行分类。
一些算法使用更多的 CPU 周期,因此具有较差的渐近值。其他算法在对一些值进行排序时会消耗更多的内存和其他计算资源。另一个考虑因素是排序算法如何适合递归或迭代表达。有些算法使用比较作为排序元素的基础。冒泡排序算法就是一个例子。非比较排序算法的例子包括桶排序和鸽巢排序。
冒泡排序
冒泡排序算法的思想非常简单。给定一个无序列表,我们比较列表中的相邻元素,每次只放入正确的大小顺序,只有两个元素。该算法依赖于一个交换过程。
取一个只有两个元素的列表:

要对这个列表进行排序,只需将它们交换到正确的位置,2 占据索引 0,5 占据索引 1。为了有效地交换这些元素,我们需要一个临时存储区域:

冒泡排序算法的实现从交换方法开始,如前面的图像所示。首先,元素5将被复制到临时位置temp。然后元素2将被移动到索引0。最后,5将从 temp 移动到索引1。最终,元素将被交换。列表现在将包含元素:[2, 5]。以下代码将交换unordered_list[j]的元素与unordered_list[j+1]的元素,如果它们不是按正确顺序排列的:
temp = unordered_list[j]
unordered_list[j] = unordered_list[j+1]
unordered_list[j+1] = temp
现在我们已经能够交换一个两元素数组,使用相同的思想对整个列表进行排序应该很简单。
我们将在一个双重嵌套循环中运行这个交换操作。内部循环如下:
for j in range(iteration_number):
if unordered_list[j] > unordered_list[j+1]:
temp = unordered_list[j]
unordered_list[j] = unordered_list[j+1]
unordered_list[j+1] = temp
在实现冒泡排序算法时,知道交换的次数是很重要的。要对诸如[3, 2, 1]的数字列表进行排序,我们需要最多交换两次元素。这等于列表长度减 1,iteration_number = len(unordered_list)-1。我们减去1是因为它恰好给出了最大迭代次数:

通过在精确两次迭代中交换相邻元素,最大的数字最终位于列表的最后位置。
if 语句确保如果两个相邻元素已经按正确顺序排列,则不会发生不必要的交换。内部的 for 循环只会在我们的列表中精确发生两次相邻元素的交换。
然而,你会意识到第一次运行 for 循环并没有完全排序我们的列表。这个交换操作必须发生多少次,才能使整个列表排序好呢?如果我们重复整个交换相邻元素的过程多次,列表就会排序好。外部循环用于实现这一点。列表中元素的交换会导致以下动态变化:

我们意识到最多需要四次比较才能使我们的列表排序好。因此,内部和外部循环都必须运行 len(unordered_list)-1 次,才能使所有元素都排序好:
iteration_number = len(unordered_list)-1
for i in range(iteration_number):
for j in range(iteration_number):
if unordered_list[j] > unordered_list[j+1]:
temp = unordered_list[j]
unordered_list[j] = unordered_list[j+1]
unordered_list[j+1] = temp
即使列表包含许多元素,也可以使用相同的原则。冒泡排序也有很多变体,可以最小化迭代和比较的次数。
冒泡排序是一种高度低效的排序算法,时间复杂度为 O(n2),最佳情况为 O(n)。通常情况下,不应该使用冒泡排序算法来对大型列表进行排序。然而,在相对较小的列表上,它的性能还是相当不错的。
有一种冒泡排序算法的变体,如果在内部循环中没有比较,我们就会简单地退出整个排序过程。在内部循环中不需要交换元素的情况下,表明列表已经排序好了。在某种程度上,这可以帮助加快通常被认为是缓慢的算法。
插入排序
通过交换相邻元素来对一系列项目进行排序的想法也可以用于实现插入排序。在插入排序算法中,我们假设列表的某个部分已经排序好了,而另一部分仍然未排序。在这种假设下,我们遍历列表的未排序部分,一次选择一个元素。对于这个元素,我们遍历列表的排序部分,并按正确的顺序将其插入,以使列表的排序部分保持排序。这是很多语法。让我们通过一个例子来解释一下。
考虑以下数组:

该算法首先使用 for 循环在索引 1 和 4 之间运行。我们从索引 1 开始,因为我们假设索引 0 的子数组已经按顺序排序好了:

在循环执行开始时,我们有以下情况:
for index in range(1, len(unsorted_list)):
search_index = index
insert_value = unsorted_list[index]
在每次运行 for 循环时,unsorted_list[index] 处的元素被存储在 insert_value 变量中。稍后,当我们找到列表排序部分的适当位置时,insert_value 将被存储在该索引或位置上:
for index in range(1, len(unsorted_list)):
search_index = index
insert_value = unsorted_list[index]
while search_index > 0 and unsorted_list[search_index-1] >
insert_value :
unsorted_list[search_index] = unsorted_list[search_index-1]
search_index -= 1
unsorted_list[search_index] = insert_value
search_index 用于向 while 循环提供信息–确切地指出在列表的排序部分中需要插入的下一个元素的位置。
while 循环向后遍历列表,受两个条件的控制:首先,如果 search_index > 0,那么意味着列表的排序部分还有更多的元素;其次,while 循环运行时,unsorted_list[search_index-1] 必须大于 insert_value。unsorted_list[search_index-1] 数组将执行以下操作之一:
-
在第一次执行
while循环之前,指向unsorted_list[search_index]之前的一个元素 -
在第一次运行
while循环后,指向unsorted_list[search_index-1]之前的一个元素
在我们的列表示例中,while 循环将被执行,因为 5 > 1。在 while 循环的主体中,unsorted_list[search_index-1] 处的元素被存储在 unsorted_list[search_index] 处。search_index -= 1 使列表遍历向后移动,直到它的值为 0。
我们的列表现在是这样的:

while循环退出后,search_index的最后已知位置(在这种情况下为0)现在帮助我们知道在哪里插入insert_value:

在for循环的第二次迭代中,search_index将具有值2,这是数组中第三个元素的索引。此时,我们从左向右(朝向索引0)开始比较。100将与5进行比较,但由于100大于5,while循环将不会执行。100将被自己替换,因为search_index变量从未被减少。因此,unsorted_list[search_index] = insert_value将不会产生任何效果。
当search_index指向索引3时,我们将2与100进行比较,并将100移动到2所存储的位置。然后我们将2与5进行比较,并将5移动到最初存储100的位置。此时,while循环将中断,2将存储在索引1中。数组将部分排序,值为[1, 2, 5, 100, 10]。
前面的步骤将再次发生一次,以便对列表进行排序。
插入排序算法被认为是稳定的,因为它不会改变具有相等键的元素的相对顺序。它也只需要的内存不多于列表消耗的内存,因为它是原地交换。
它的最坏情况值为O(n²),最佳情况为O(n)。
选择排序
另一个流行的排序算法是选择排序。这种排序算法简单易懂,但效率低下,其最坏和最佳渐近值为O(n²)。它首先找到数组中最小的元素,并将其与数据交换,例如,数组索引[0]处的数据。然后再次执行相同的操作;然而,在找到第一个最小元素后,列表剩余部分中的最小元素将与索引[1]处的数据交换。
为了更好地解释算法的工作原理,让我们对一组数字进行排序:

从索引0开始,我们搜索列表中在索引1和最后一个元素的索引之间存在的最小项。找到这个元素后,它将与索引0处找到的数据交换。我们只需重复此过程,直到列表变得有序。
在列表中搜索最小项是一个递增的过程:

对元素2和5进行比较,选择2作为较小的元素。这两个元素被交换。
交换操作后,数组如下所示:

仍然在索引0处,我们将2与65进行比较:

由于65大于2,所以这两个元素不会交换。然后在索引0处的元素2和索引3处的元素10之间进行了进一步的比较。不会发生交换。当我们到达列表中的最后一个元素时,最小的元素将占据索引0。
一个新的比较集将开始,但这一次是从索引1开始。我们重复整个比较过程,将存储在那里的元素与索引2到最后一个索引之间的所有元素进行比较。
第二次迭代的第一步将如下所示:

以下是选择排序算法的实现。函数的参数是我们想要按升序排列的未排序项目列表的大小:
def selection_sort(unsorted_list):
size_of_list = len(unsorted_list)
for i in range(size_of_list):
for j in range(i+1, size_of_list):
if unsorted_list[j] < unsorted_list[i]:
temp = unsorted_list[i]
unsorted_list[i] = unsorted_list[j]
unsorted_list[j] = temp
算法从使用外部for循环开始遍历列表size_of_list,多次。因为我们将size_of_list传递给range方法,它将产生一个从0到size_of_list-1的序列。这是一个微妙的注释。
内部循环负责遍历列表,并在遇到小于unsorted_list[i]指向的元素时进行必要的交换。注意,内部循环从i+1开始,直到size_of_list-1。内部循环开始在i+1之间搜索最小的元素,但使用j索引:

上图显示了算法搜索下一个最小项的方向。
快速排序
快速排序算法属于分治算法类,其中我们将问题分解为更简单的小块来解决。在这种情况下,未排序的数组被分解成部分排序的子数组,直到列表中的所有元素都处于正确的位置,此时我们的未排序列表将变为已排序。
列表分区
在我们将列表分成更小的块之前,我们必须对其进行分区。这是快速排序算法的核心。要对数组进行分区,我们必须首先选择一个枢轴。数组中的所有元素将与此枢轴进行比较。在分区过程结束时,小于枢轴的所有元素将位于枢轴的左侧,而大于枢轴的所有元素将位于数组中枢轴的右侧。
枢轴选择
为了简单起见,我们将任何数组中的第一个元素作为枢轴。这种枢轴选择会降低性能,特别是在对已排序列表进行排序时。随机选择数组中间或最后一个元素作为枢轴也不会改善情况。在下一章中,我们将采用更好的方法来选择枢轴,以帮助我们找到列表中的最小元素。
实施
在深入代码之前,让我们通过使用快速排序算法对列表进行排序的步骤。首先要理解分区步骤非常重要,因此我们将首先解决该操作。
考虑以下整数列表。我们将使用以下分区函数对此列表进行分区:

def partition(unsorted_array, first_index, last_index):
pivot = unsorted_array[first_index]
pivot_index = first_index
index_of_last_element = last_index
less_than_pivot_index = index_of_last_element
greater_than_pivot_index = first_index + 1
...
分区函数接收我们需要分区的数组作为参数:其第一个元素的索引和最后一个元素的索引。
枢轴的值存储在pivot变量中,而其索引存储在pivot_index中。我们没有使用unsorted_array[0],因为当调用未排序数组参数时,索引0不一定指向该数组中的第一个元素。枢轴的下一个元素的索引,first_index + 1,标记了我们开始在数组中寻找大于pivot的元素的位置,greater_than_pivot_index = first_index + 1。
less_than_pivot_index = index_of_last_element标记了列表中最后一个元素的位置,即我们开始搜索小于枢轴的元素的位置:
while True:
while unsorted_array[greater_than_pivot_index] < pivot and
greater_than_pivot_index < last_index:
greater_than_pivot_index += 1
while unsorted_array[less_than_pivot_index] > pivot and
less_than_pivot_index >= first_index:
less_than_pivot_index -= 1
在执行主while循环之前,数组如下所示:

第一个内部while循环每次向右移动一个索引,直到落在索引2上,因为该索引处的值大于43。此时,第一个while循环中断并不再继续。在第一个while循环的条件测试中,只有当while循环的测试条件评估为True时,才会评估greater_than_pivot_index += 1。这使得对大于枢轴的元素的搜索向右侧的下一个元素进行。
第二个内部while循环每次向左移动一个索引,直到落在索引5上,其值20小于43:

此时,内部while循环都无法继续执行:
if greater_than_pivot_index < less_than_pivot_index:
temp = unsorted_array[greater_than_pivot_index]
unsorted_array[greater_than_pivot_index] =
unsorted_array[less_than_pivot_index]
unsorted_array[less_than_pivot_index] = temp
else:
break
由于greater_than_pivot_index < less_than_pivot_index,if 语句的主体交换了这些索引处的元素。else 条件在任何时候greater_than_pivot_index变得大于less_than_pivot_index时打破无限循环。在这种情况下,这意味着greater_than_pivot_index和less_than_pivot_index已经交叉。
我们的数组现在是这样的:

当less_than_pivot_index等于3且greater_than_pivot_index等于4时,执行 break 语句。
一旦我们退出while循环,我们就会交换unsorted_array[less_than_pivot_index]的元素和less_than_pivot_index的元素,后者作为枢轴的索引返回:
unsorted_array[pivot_index]=unsorted_array[less_than_pivot_index]
unsorted_array[less_than_pivot_index]=pivot
return less_than_pivot_index
下面的图片显示了代码在分区过程的最后一步中如何交换 4 和 43:

回顾一下,第一次调用快速排序函数时,它是围绕索引0的元素进行分区的。在分区函数返回后,我们得到数组[4, 3, 20, 43, 89, 77]。
正如你所看到的,元素43右边的所有元素都更大,而左边的元素更小。分区完成了。
使用分割点 43 和索引 3,我们将递归地对两个子数组[4, 30, 20]和[89, 77]进行排序,使用刚刚经历的相同过程。
主quick sort函数的主体如下:
def quick_sort(unsorted_array, first, last):
if last - first <= 0:
return
else:
partition_point = partition(unsorted_array, first, last)
quick_sort(unsorted_array, first, partition_point-1)
quick_sort(unsorted_array, partition_point+1, last)
quick sort函数是一个非常简单的方法,不超过 6 行代码。繁重的工作由partition函数完成。当调用partition方法时,它返回分区点。这是unsorted_array中的一个点,左边的所有元素都小于枢轴,右边的所有元素都大于它。
当我们在分区进度之后立即打印unsorted_array的状态时,我们清楚地看到了分区是如何进行的:
Output:
[43, 3, 20, 89, 4, 77]
[4, 3, 20, 43, 89, 77]
[3, 4, 20, 43, 89, 77]
[3, 4, 20, 43, 77, 89]
[3, 4, 20, 43, 77, 89]
退一步,让我们在第一次分区发生后对第一个子数组进行排序。[4, 3, 20]子数组的分区将在greater_than_pivot_index在索引2和less_than_pivot_index在索引1时停止。在那一点上,两个标记被认为已经交叉。因为greater_than_pivot_index大于less_than_pivot_index,while循环的进一步执行将停止。枢轴 4 将与3交换,而索引1将作为分区点返回。
快速排序算法的最坏情况复杂度为O(n²),但在对大量数据进行排序时效率很高。
堆排序
在第十一章中,图和其他算法,我们实现了(二叉)堆数据结构。我们的实现始终确保在元素被移除或添加到堆后,使用 sink 和 float 辅助方法来维护堆顺序属性。
堆数据结构可以用来实现称为堆排序的排序算法。回顾一下,让我们创建一个简单的堆,其中包含以下项目:
h = Heap()
unsorted_list = [4, 8, 7, 2, 9, 10, 5, 1, 3, 6]
for i in unsorted_list:
h.insert(i)
print("Unsorted list: {}".format(unsorted_list))
堆h被创建,并且unsorted_list中的元素被插入。在每次调用insert方法后,堆顺序属性都会通过随后调用float方法得到恢复。循环终止后,我们的堆顶部将是元素4。
我们堆中的元素数量是10。如果我们在堆对象h上调用pop方法 10 次并存储实际弹出的元素,我们最终得到一个排序好的列表。每次pop操作后,堆都会重新调整以保持堆顺序属性。
heap_sort方法如下:
class Heap:
...
def heap_sort(self):
sorted_list = []
for node in range(self.size):
n = self.pop()
sorted_list.append(n)
return sorted_list
for循环简单地调用pop方法self.size次。循环终止后,sorted_list将包含一个排序好的项目列表。
insert方法被调用n次。与float方法一起,insert操作的最坏情况运行时间为O(n log n),pop方法也是如此。因此,这种排序算法的最坏情况运行时间为O(n log n)。
总结
在本章中,我们探讨了许多排序算法。快速排序比其他排序算法表现要好得多。在讨论的所有算法中,快速排序保留了它所排序的列表的索引。在下一章中,我们将利用这一特性来探讨选择算法。
第十四章:选择算法
与在无序项目列表中查找元素相关的一组有趣的算法是选择算法。通过这样做,我们将回答与选择一组数字的中位数和选择列表中第 i 个最小或最大元素等问题有关的问题。
在本章中,我们将涵盖以下主题:
-
通过排序进行选择
-
随机选择
-
确定性选择
通过排序进行选择
列表中的项目可能会经历统计查询,如查找平均值、中位数和众数值。查找平均值和众数值不需要对列表进行排序。但是,要在数字列表中找到中位数,必须首先对列表进行排序。查找中位数需要找到有序列表中间位置的元素。但是,如果我们想要找到列表中的最后一个最小的项目或列表中的第一个最小的项目呢?
要找到无序项目列表中的第 i 个最小数字,重要的是要获得该项目出现的位置的索引。但是因为元素尚未排序,很难知道列表中索引为 0 的元素是否真的是最小的数字。
处理无序列表时要做的一个实际和明显的事情是首先对列表进行排序。一旦列表排序完成,就可以确保列表中的第零个元素将包含列表中的第一个最小元素。同样,列表中的最后一个元素将包含列表中的最后一个最小元素。
假设也许在执行搜索之前无法负担排序的奢侈。是否可能在不必首先对列表进行排序的情况下找到第 i 个最小的元素?
随机选择
在上一章中,我们研究了快速排序算法。快速排序算法允许我们对无序项目列表进行排序,但在排序算法运行时有一种保留元素索引的方式。一般来说,快速排序算法执行以下操作:
-
选择一个枢轴。
-
围绕枢轴对未排序的列表进行分区。
-
使用步骤 1和步骤 2递归地对分区列表的两半进行排序。
一个有趣且重要的事实是,在每个分区步骤之后,枢轴的索引在列表变得排序后也不会改变。正是这个属性使我们能够在一个不太完全排序的列表中工作,以获得第 i 个最小的数字。因为随机选择是基于快速排序算法的,它通常被称为快速选择。
快速选择
快速选择算法用于获取无序项目列表中的第 i 个最小元素,即数字。我们将算法的主要方法声明如下:
def quick_select(array_list, left, right, k):
split = partition(array_list, left, right)
if split == k:
return array_list[split]
elif split < k:
return quick_select(array_list, split + 1, right, k)
else:
return quick_select(array_list, left, split-1, k)
quick_select函数的参数是列表中第一个元素的索引和最后一个元素的索引。第三个参数k指定了第 i 个元素。允许大于或等于零(0)的值,这样当k为 0 时,我们知道要在列表中搜索第一个最小的项目。其他人喜欢处理k参数,使其直接映射到用户正在搜索的索引,以便第一个最小的数字映射到排序列表的 0 索引。这都是个人偏好的问题。
对partition函数的方法调用,split = partition(array_list, left, right),返回split索引。split数组的这个索引是无序列表中的位置,其中right到split-1之间的所有元素都小于split数组中包含的元素,而split+1到left之间的所有元素都大于split数组中包含的元素。
当partition函数返回split值时,我们将其与k进行比较,以找出split是否对应于第 k 个项目。
如果split小于k,那么意味着第 k 个最小的项目应该存在或者在split+1和right之间被找到:

在前面的例子中,一个想象中的无序列表在索引 5 处发生了分割,而我们正在寻找第二小的数字。由于 5<2 为false,因此进行递归调用以搜索列表的另一半:quick_select(array_list, left, split-1, k)。
如果split索引小于k,那么我们将调用quick_select:

分区步骤
分区步骤与快速排序算法中的步骤完全相同。有几点值得注意:
def partition(unsorted_array, first_index, last_index):
if first_index == last_index:
return first_index
pivot = unsorted_array[first_index]
pivot_index = first_index
index_of_last_element = last_index
less_than_pivot_index = index_of_last_element
greater_than_pivot_index = first_index + 1
while True:
while unsorted_array[greater_than_pivot_index] < pivot and
greater_than_pivot_index < last_index:
greater_than_pivot_index += 1
while unsorted_array[less_than_pivot_index] > pivot and
less_than_pivot_index >= first_index:
less_than_pivot_index -= 1
if greater_than_pivot_index < less_than_pivot_index:
temp = unsorted_array[greater_than_pivot_index]
unsorted_array[greater_than_pivot_index] =
unsorted_array[less_than_pivot_index]
unsorted_array[less_than_pivot_index] = temp
else:
break
unsorted_array[pivot_index] =
unsorted_array[less_than_pivot_index]
unsorted_array[less_than_pivot_index] = pivot
return less_than_pivot_index
在函数定义的开头插入了一个 if 语句,以处理first_index等于last_index的情况。在这种情况下,这意味着我们的子列表中只有一个元素。因此,我们只需返回函数参数中的任何一个,即first_index。
总是选择第一个元素作为枢轴。这种选择使第一个元素成为枢轴是一个随机决定。通常不会产生良好的分割和随后的良好分区。然而,最终将找到第 i 个元素,即使枢轴是随机选择的。
partition函数返回由less_than_pivot_index指向的枢轴索引,正如我们在前一章中看到的。
从这一点开始,您需要用铅笔和纸跟随程序执行,以更好地了解如何使用分割变量来确定要搜索第 i 小项的列表的部分。
确定性选择
随机选择算法的最坏情况性能为O(n²)。可以改进随机选择算法的一部分以获得O(n)的最坏情况性能。这种算法称为确定性选择。
确定性算法的一般方法如下:
-
选择一个枢轴:
-
将无序项目列表分成每组五个元素。
-
对所有组进行排序并找到中位数。
-
递归重复步骤 1和步骤 2,以获得列表的真实中位数。
-
使用真实中位数来分区无序项目列表。
-
递归进入可能包含第 i 小元素的分区列表的部分。
枢轴选择
在随机选择算法中,我们选择第一个元素作为枢轴。我们将用一系列步骤替换该步骤,以便获得真实或近似中位数。这将改善关于枢轴的列表的分区:
def partition(unsorted_array, first_index, last_index):
if first_index == last_index:
return first_index
else:
nearest_median =
median_of_medians(unsorted_array[first_index:last_index])
index_of_nearest_median =
get_index_of_nearest_median(unsorted_array, first_index,
last_index, nearest_median)
swap(unsorted_array, first_index, index_of_nearest_median)
pivot = unsorted_array[first_index]
pivot_index = first_index
index_of_last_element = last_index
less_than_pivot_index = index_of_last_element
greater_than_pivot_index = first_index + 1
现在让我们来研究分区函数的代码。nearest_median变量存储给定列表的真实或近似中位数:
def partition(unsorted_array, first_index, last_index):
if first_index == last_index:
return first_index
else:
nearest_median =
median_of_medians(unsorted_array[first_index:last_index])
....
如果unsorted_array参数只有一个元素,则first_index和last_index将相等。因此无论如何都会返回first_index。
然而,如果列表大小大于 1,我们将使用数组的部分调用median_of_medians函数,由first_index和last_index标记。返回值再次存储在nearest_median中。
中位数的中位数
median_of_medians函数负责找到任何给定项目列表的近似中位数。该函数使用递归返回真实中位数:
def median_of_medians(elems):
sublists = [elems[j:j+5] for j in range(0, len(elems), 5)]
medians = []
for sublist in sublists:
medians.append(sorted(sublist)[len(sublist)/2])
if len(medians) <= 5:
return sorted(medians)[len(medians)/2]
else:
return median_of_medians(medians)
该函数首先将列表elems分成每组五个元素。这意味着如果elems包含 100 个项目,则语句sublists = [elems[j:j+5] for j in range(0, len(elems), 5)]将创建 20 个组,每个组包含五个或更少的元素:
medians = []
for sublist in sublists:
medians.append(sorted(sublist)[len(sublist)/2])
创建一个空数组并将其分配给medians,它存储分配给sublists的每个五个元素数组中的中位数。
for 循环遍历sublists中的列表列表。对每个子列表进行排序,找到中位数,并将其存储在medians列表中。
medians.append(sorted(sublist)[len(sublist)/2])语句将对列表进行排序,并获取存储在其中间索引的元素。这成为五个元素列表的中位数。由于列表的大小较小,使用现有的排序函数不会影响算法的性能。
我们从一开始就明白,我们不会对列表进行排序以找到第 i 小的元素,那么为什么要使用 Python 的排序方法呢?嗯,由于我们只对五个或更少的非常小的列表进行排序,因此该操作对算法的整体性能的影响被认为是可以忽略的。
此后,如果列表现在包含五个或更少的元素,我们将对medians列表进行排序,并返回位于其中间索引的元素:
if len(medians) <= 5:
return sorted(medians)[len(medians)/2]
另一方面,如果列表的大小大于五,我们将再次递归调用median_of_medians函数,并向其提供存储在medians中的中位数列表。
例如,以下数字列表:
[2, 3, 5, 4, 1, 12, 11, 13, 16, 7, 8, 6, 10, 9, 17, 15, 19, 20, 18, 23, 21, 22, 25, 24, 14]
我们可以使用代码语句sublists = [elems[j:j+5] for j in range(0, len(elems), 5)]将此列表分成每个五个元素一组,以获得以下列表:
[[2, 3, 5, 4, 1], [12, 11, 13, 16, 7], [8, 6, 10, 9, 17], [15, 19, 20, 18, 23], [21, 22, 25, 24, 14]]
对每个五个元素的列表进行排序并获取它们的中位数,得到以下列表:
[3, 12, 9, 19, 22]
由于列表的大小为五个元素,我们只返回排序列表的中位数,或者我们将再次调用median_of_median函数。
分区步骤
现在我们已经获得了近似中位数,get_index_of_nearest_median函数使用first和last参数指示的列表边界:
def get_index_of_nearest_median(array_list, first, second, median):
if first == second:
return first
else:
return first + array_list[first:second].index(median)
如果列表中只有一个元素,我们再次只返回第一个索引。arraylist[first:second]返回一个索引为 0 到list-1大小的数组。当我们找到中位数的索引时,由于新的范围索引[first:second]代码返回,我们会丢失它所在的列表部分。因此,我们必须将arraylist[first:second]返回的任何索引添加到first中,以获得找到中位数的真实索引:
swap(unsorted_array, first_index, index_of_nearest_median)
然后,我们使用交换函数将unsorted_array中的第一个元素与index_of_nearest_median进行交换。
这里显示了交换两个数组元素的实用函数:
def swap(array_list, first, second):
temp = array_list[first]
array_list[first] = array_list[second]
array_list[second] = temp
我们的近似中位数现在存储在未排序列表的first_index处。
分区函数将继续进行,就像快速选择算法的代码一样。分区步骤之后,数组看起来是这样的:

def deterministic_select(array_list, left, right, k):
split = partition(array_list, left, right)
if split == k:
return array_list[split]
elif split < k :
return deterministic_select(array_list, split + 1, right, k)
else:
return deterministic_select(array_list, left, split-1, k)
正如您已经观察到的那样,确定选择算法的主要功能看起来与其随机选择对应物完全相同。在初始array_list围绕近似中位数进行分区后,将与第 k 个元素进行比较。
如果split小于k,则会递归调用deterministic_select(array_list, split + 1, right, k)。这将在数组的一半中寻找第 k 个元素。否则,将调用deterministic_select(array_list, left, split-1, k)函数。
总结
本章已经探讨了如何在列表中找到第 i 小的元素的方法。已经探讨了简单地对列表进行排序以执行查找第 i 小元素的操作的平凡解决方案。
还有可能不一定要在确定第 i 小的元素之前对列表进行排序。随机选择算法允许我们修改快速排序算法以确定第 i 小的元素。
为了进一步改进随机选择算法,以便我们可以获得O(n)的时间复杂度,我们着手寻找中位数的中位数,以便在分区期间找到一个良好的分割点。
从下一章开始,我们将改变重点,深入探讨 Python 的面向对象编程概念。
第十五章:面向对象设计
在软件开发中,设计通常被认为是编程之前的步骤。这并不正确;实际上,分析、编程和设计往往重叠、结合和交织。在本章中,我们将涵盖以下主题:
-
面向对象的含义
-
面向对象设计和面向对象编程之间的区别
-
面向对象设计的基本原则
-
基本的统一建模语言(UML)及其不邪恶的时候
介绍面向对象
每个人都知道什么是对象:我们可以感知、感觉和操作的有形物体。我们最早接触的对象通常是婴儿玩具。木块、塑料形状和超大拼图块是常见的第一个对象。婴儿很快学会了某些对象会做某些事情:铃响、按钮被按下,杠杆被拉动。
在软件开发中,对象的定义并没有太大的不同。软件对象可能不是可以拿起、感知或感觉的有形物体,但它们是能够做某些事情并且可以对它们做某些事情的模型。形式上,一个对象是一组数据和相关行为。
那么,知道了什么是对象,什么是面向对象呢?在词典中,oriented的意思是朝向。因此,面向对象意味着在功能上朝向建模对象。这是用于建模复杂系统的众多技术之一。它通过描述一组通过它们的数据和行为相互作用的对象来定义。
如果你读过一些炒作,你可能会遇到面向对象分析、面向对象设计、面向对象分析与设计和面向对象编程等术语。这些都是与面向对象相关的概念。
事实上,分析、设计和编程都是软件开发的各个阶段。将它们称为面向对象只是指定了正在追求的软件开发水平。
面向对象分析(OOA)是查看一个问题、系统或任务(某人想要将其转化为应用程序)并识别对象和对象之间交互的过程。分析阶段关乎于需要做什么。
分析阶段的输出是一组需求。如果我们能够在一个步骤中完成分析阶段,我们将把一个任务,比如我需要一个网站,转化为一组需求。例如,这里有一些关于网站访问者可能需要做的需求(斜体表示动作,粗体表示对象):
-
回顾我们的历史
-
申请 工作
-
浏览、比较和订购 产品
在某种程度上,分析是一个误称。我们之前讨论的婴儿并不分析木块和拼图块。相反,她探索她的环境,操纵形状,并看看它们可能适合在哪里。一个更好的说法可能是面向对象的探索。在软件开发中,分析的初始阶段包括采访客户,研究他们的流程,并排除可能性。
面向对象设计(OOD)是将这些要求转化为实现规范的过程。设计师必须命名对象,定义行为,并正式指定哪些对象可以激活其他对象上的特定行为。设计阶段关乎于如何完成事情。
设计阶段的输出是一个实现规范。如果我们能够在一个步骤中完成设计阶段,我们将把面向对象分析期间定义的需求转化为一组类和接口,这些类和接口可以在(理想情况下)任何面向对象编程语言中实现。
面向对象编程(OOP)是将这个完全定义的设计转化为一个完全满足 CEO 最初要求的工作程序的过程。
是的,没错!如果世界符合这个理想,我们可以按照这些阶段一步一步地按照完美的顺序进行,就像所有旧教科书告诉我们的那样。通常情况下,现实世界要复杂得多。无论我们多么努力地分隔这些阶段,我们总会发现在设计时需要进一步分析的事情。当我们编程时,我们会发现设计中需要澄清的特性。
21 世纪的大部分开发都是以迭代开发模型进行的。在迭代开发中,任务的一小部分被建模、设计和编程,然后程序被审查和扩展,以改进每个功能并在一系列短期开发周期中包括新功能。
本书的其余部分是关于面向对象编程的,但在本章中,我们将在设计的背景下介绍基本的面向对象原则。这使我们能够理解这些(相当简单的)概念,而不必与软件语法或 Python 的错误信息争论。
对象和类
因此,对象是具有相关行为的数据集合。我们如何区分对象的类型?苹果和橙子都是对象,但有一个常见的谚语说它们不能相提并论。苹果和橙子在计算机编程中并不经常被建模,但让我们假设我们正在为一个水果农场做库存应用。为了便于理解,我们可以假设苹果放在桶里,橙子放在篮子里。
现在,我们有四种对象:苹果、橙子、篮子和桶。在面向对象建模中,用于表示对象类型的术语是类。因此,在技术术语中,我们现在有四个对象类。
理解对象和类之间的区别很重要。类描述对象。它们就像创建对象的蓝图。你可能在桌子上看到三个橙子。每个橙子都是一个独特的对象,但所有三个都具有与一个类相关的属性和行为:橙子的一般类。
我们库存系统中的四个对象类之间的关系可以使用统一建模语言(通常简称为UML,因为三个字母的缩写永远不会过时)类图来描述。这是我们的第一个类图:

这张图表显示橙子与篮子以某种方式相关联,而苹果也以某种方式与桶相关联。关联是两个类相关的最基本方式。
UML 在经理中非常受欢迎,有时会受到程序员的贬低。UML 图表的语法通常相当明显;当你看到一个 UML 图表时,你不必阅读教程就能(大部分)理解发生了什么。UML 也相当容易绘制,而且相当直观。毕竟,许多人在描述类及其关系时,自然会画出盒子和它们之间的线。基于这些直观图表的标准使程序员能够与设计师、经理和彼此进行轻松的沟通。
然而,一些程序员认为 UML 是浪费时间。他们引用迭代开发,他们会认为用花哨的 UML 图表制定的正式规范在实施之前就会变得多余,并且维护这些正式图表只会浪费时间,对任何人都没有好处。
这取决于所涉及的公司结构,这可能是真的,也可能不是真的。然而,每个由多个人组成的编程团队都会偶尔坐下来详细讨论他们当前正在处理的子系统的细节。在这些头脑风暴会议中,UML 非常有用,可以进行快速而轻松的沟通。即使那些嘲笑正式类图的组织也倾向于在设计会议或团队讨论中使用某种非正式版本的 UML。
此外,你将要与之交流的最重要的人是你自己。我们都认为自己能记住我们所做的设计决策,但在未来总会有*我为什么那样做?*的时刻。如果我们保存我们在开始设计时做初始图表的纸屑,最终我们会发现它们是有用的参考资料。
然而,本章并不意味着是 UML 的教程。互联网上有许多这方面的教程,以及大量关于这个主题的书籍。UML 涵盖的远不止类和对象图表;它还有用例、部署、状态变化和活动的语法。在这个面向对象设计的讨论中,我们将处理一些常见的类图表语法。你可以通过示例了解结构,并在你自己的团队或个人设计会议中下意识地选择受 UML 启发的语法。
我们的初始图表虽然是正确的,但没有提醒我们苹果是放在桶里的,或者一个苹果可以放在多少个桶里。它只告诉我们苹果与桶子有某种关联。类之间的关联通常是显而易见的,不需要进一步解释,但我们可以根据需要添加进一步的说明。
UML 的美妙之处在于大多数东西都是可选的。我们只需要在图表中指定与当前情况相符的信息。在一个快速的白板会议中,我们可能只是快速地在方框之间画线。在正式文件中,我们可能会更详细地说明。在苹果和桶子的情况下,我们可以相当有信心地说这个关联是许多苹果放在一个桶里,但为了确保没有人将其与一个苹果糟蹋一个桶混淆,我们可以增强图表如下所示:

这个图表告诉我们橙子放在篮子里,有一个小箭头显示了什么放在什么里。它还告诉我们在关联的两端可以使用的对象的数量。一个Basket可以容纳许多(用表示)Orange对象。任何一个Orange可以放在一个Basket*里。这个数字被称为对象的多重性。你可能也听说过它被描述为基数。这些实际上是稍微不同的术语。基数是指集合中实际的项目数量,而多重性指定了集合可以有多小或多大。
我有时会忘记关系线的哪一端应该有哪个多重性数字。靠近类的多重性是该类的对象可以与关联的另一端的任何一个对象相关联的数量。对于苹果放在桶子的关联,从左到右阅读,Apple类的许多实例(即许多Apple对象)可以放在任何一个Barrel中。从右到左阅读,一个Barrel可以与任何一个Apple相关联。
指定属性和行为
我们现在对一些基本的面向对象术语有了了解。对象是可以相互关联的类的实例。对象实例是具有自己一组数据和行为的特定对象;我们面前桌子上的一个特定的橙子被称为是橙子类的一个实例。这已经足够简单了,但让我们深入探讨一下这两个词的含义,数据和行为。
数据描述对象
让我们从数据开始。数据代表特定对象的个体特征。一个类可以定义所有该类对象共享的特定特征集。任何特定对象可以对给定特征具有不同的数据值。例如,我们桌子上的三个橙子(如果我们没有吃掉)可能每个重量都不同。橙子类可以有一个重量属性来表示这个数据。橙子类的所有实例都有一个重量属性,但是每个橙子对于这个属性有不同的值。属性不必是唯一的,任何两个橙子可能重量相同。作为一个更现实的例子,代表不同客户的两个对象可能对于名字属性有相同的值。
属性经常被称为成员或属性。一些作者认为这些术语有不同的含义,通常是属性是可设置的,而属性是只读的。在 Python 中,只读的概念相当无意义,所以在本书中,我们会看到这两个术语可以互换使用。此外,正如我们将在第十九章中讨论的那样,property关键字在 Python 中对于特定类型的属性有特殊的含义。
在我们的水果库存应用程序中,果农可能想要知道橙子来自哪个果园,何时采摘,以及重量是多少。他们可能还想跟踪每个篮子存放在哪里。苹果可能有颜色属性,桶可能有不同的大小。这些属性中的一些也可能属于多个类(我们可能也想知道何时采摘苹果),但是对于这个第一个例子,让我们只向我们的类图添加一些不同的属性:

根据我们的设计需要多么详细,我们还可以为每个属性指定类型。属性类型通常是大多数编程语言中标准的原始数据类型,例如整数、浮点数、字符串、字节或布尔值。然而,它们也可以表示数据结构,如列表、树或图,或者更重要的是其他类。这是设计阶段可以与编程阶段重叠的一个领域。一个编程语言中可用的各种原始数据类型或对象可能与另一个编程语言中可用的不同:

通常,在设计阶段我们不需要过于关注数据类型,因为在编程阶段会选择实现特定的细节。对于设计来说,通用名称通常足够了。如果我们的设计需要列表容器类型,Java 程序员可以选择在实现时使用LinkedList或ArrayList,而 Python 程序员(就是我们!)可能会在list内置和tuple之间进行选择。
到目前为止,在我们的水果种植示例中,我们的属性都是基本的原始数据类型。然而,有一些隐含的属性我们可以明确表示——关联。对于给定的橙子,我们可能有一个属性指向包含该橙子的篮子。
行为是动作
现在我们知道了数据是什么,最后一个未定义的术语是行为。行为是可以在对象上发生的动作。可以在特定对象类上执行的行为称为方法。在编程级别上,方法就像结构化编程中的函数,但是它们神奇地可以访问与该对象关联的所有数据。与函数一样,方法也可以接受参数并返回值。
方法的参数以对象列表的形式提供给它。在特定调用期间传递给方法的实际对象实例通常被称为参数。这些对象被方法用于执行其所需的行为或任务。返回的值是该任务的结果。
我们已经将我们比较苹果和橙子的例子扩展成了一个基本的(虽然牵强)库存应用程序。让我们再扩展一下,看看是否会出现问题。可以与橙子相关联的一个动作是采摘。如果考虑实现,采摘需要做两件事:
-
通过更新橙子的篮子属性将橙子放入篮子中
-
将橙子添加到给定篮子上的橙子列表中。
因此,采摘需要知道它正在处理的篮子是哪一个。我们通过给采摘方法一个篮子参数来实现这一点。由于我们的果农还销售果汁,我们可以在橙子类中添加一个挤方法。当调用时,挤方法可能会返回所取得的果汁量,同时将橙子从其所在的篮子中移除。
篮子类可以有一个卖的动作。当篮子被卖出时,我们的库存系统可能会更新一些尚未指定的对象的数据,用于会计和利润计算。或者,我们的橙子篮在我们卖出之前可能会变坏,所以我们添加了一个丢弃的方法。让我们把这些方法添加到我们的图表中:

向个别对象添加属性和方法使我们能够创建一个相互作用的对象系统。系统中的每个对象都是某个类的成员。这些类指定了对象可以保存的数据类型以及可以在其上调用的方法。每个对象中的数据可能与同一类的其他实例处于不同的状态;由于状态的不同,每个对象对方法调用的反应可能会有所不同。
面向对象的分析和设计主要是弄清楚这些对象是什么,以及它们应该如何相互作用。接下来的部分描述了可以用来使这些交互尽可能简单和直观的原则。
隐藏细节并创建公共接口
在面向对象设计中对对象进行建模的关键目的是确定该对象的公共接口。接口是其他对象可以访问以与该对象交互的属性和方法的集合。它们不需要,通常也不允许访问对象的内部工作。
一个常见的现实世界的例子是电视。我们与电视的接口是遥控器。遥控器上的每个按钮代表着可以在电视对象上调用的方法。当我们作为调用对象访问这些方法时,我们不知道也不关心电视是通过有线连接、卫星接收器还是互联网设备接收信号。我们不关心调整音量时发送的电子信号,或者声音是发往扬声器还是耳机。如果我们打开电视以访问内部工作,例如将输出信号分成外部扬声器和一副耳机,我们将会失去保修。
这种隐藏对象实现的过程称为信息隐藏。有时也被称为封装,但封装实际上是一个更全面的术语。封装的数据不一定是隐藏的。封装,字面上来说,是创建一个胶囊(想象一下制作一个时间胶囊)。如果你把一堆信息放进一个时间胶囊里,然后锁上并埋起来,它既被封装又被隐藏。另一方面,如果时间胶囊没有被埋起来,是解锁的或者是由透明塑料制成的,里面的物品仍然被封装,但没有信息隐藏。
封装和信息隐藏之间的区别在设计层面上基本上是无关紧要的。许多实际参考资料都将这些术语互换使用。作为 Python 程序员,我们实际上并不需要真正的信息隐藏(我们将在《Python 对象》一章中讨论这一点的原因),因此更全面的封装定义是合适的。
然而,公共接口非常重要。它需要仔细设计,因为将来很难更改它。更改接口将破坏任何正在访问它的客户对象。我们可以随意更改内部,例如使其更有效,或者在本地和网络上访问数据,客户对象仍然可以使用公共接口与之通信,而无需修改。另一方面,如果我们通过更改公开访问的属性名称或方法可以接受的参数的顺序或类型来更改接口,所有客户类也必须进行修改。在设计公共接口时,保持简单。始终根据使用的便捷性而不是编码的难度来设计对象的接口(这个建议也适用于用户界面)。
记住,程序对象可能代表真实对象,但这并不意味着它们是真实对象。它们是模型。建模的最大好处之一是能够忽略不相关的细节。我小时候制作的模型汽车外观看起来像一辆真正的 1956 年的雷鸟,但显然它不能跑。当我还太小不能开车时,这些细节过于复杂和无关紧要。这个模型是对真实概念的抽象。
抽象是与封装和信息隐藏相关的另一个面向对象的术语。抽象意味着处理最适合特定任务的细节级别。这是从内部细节中提取公共接口的过程。汽车的驾驶员需要与转向、油门和刹车进行交互。发动机、传动系统和刹车子系统的工作对驾驶员并不重要。另一方面,技工在不同的抽象级别上工作,调整发动机和排气刹车。这是汽车的两个抽象级别的例子:

现在,我们有几个指涉相似概念的新术语。让我们用几句话总结所有这些行话:抽象是使用单独的公共和私有接口封装信息的过程。私有接口可能会受到信息隐藏的影响。
从所有这些定义中得出的重要教训是使我们的模型能够被必须与其交互的其他对象理解。这意味着要特别注意细节。确保方法和属性具有合理的名称。在分析系统时,对象通常代表原始问题中的名词,而方法通常是动词。属性可能显示为形容词或更多名词。相应地为您的类、属性和方法命名。
在设计接口时,想象自己是对象,并且你非常注重隐私。除非你认为让其他对象访问关于你的数据对你最有利,否则不要让它们访问。除非你确定你希望它们能够这样做,否则不要给它们一个接口来强迫你执行特定的任务。
组合
到目前为止,我们已经学会了将系统设计为一组相互作用的对象,其中每个交互都涉及以适当的抽象级别查看对象。但我们还不知道如何创建这些抽象级别。有多种方法可以做到这一点;我们将在第二十一章中讨论一些高级设计模式,迭代器模式。但是,大多数设计模式都依赖于两个基本的面向对象原则,即组合和继承。组合更简单,所以我们从它开始。
组合是将几个对象收集在一起创建一个新对象的行为。当一个对象是另一个对象的一部分时,组合通常是一个不错的选择。我们已经在机械示例中看到了组合的第一个迹象。燃油汽车由发动机、变速器、起动机、前灯和挡风玻璃等众多部件组成。发动机又由活塞、曲轴和气门组成。在这个例子中,组合是提供抽象级别的一种好方法。汽车对象可以提供驾驶员所需的接口,同时也可以访问其组件部件,这为技师提供了更深层次的抽象,适合于诊断问题或调整发动机时进一步分解这些组件部件。
汽车是一个常见的组合示例,但在设计计算机系统时并不是特别有用。物理对象很容易分解成组件对象。人们至少自古希腊时代以来一直在做这件事,最初假设原子是物质的最小单位(当然,他们当时无法接触到粒子加速器)。计算机系统通常比物理对象更简单,但是在这种系统中识别组件对象并不会自然发生。
面向对象系统中的对象有时代表诸如人、书籍或电话等物理对象。然而更多时候,它们代表抽象的概念。人有名字,书有标题,电话用于打电话。电话、标题、账户、名字、约会和付款通常不被认为是物理世界中的对象,但它们在计算机系统中经常被建模为组件。
让我们尝试建模一个更加面向计算机的例子来看看组合是如何发挥作用的。我们将研究一个计算机化的国际象棋游戏的设计。这在 80 年代和 90 年代是学者们非常受欢迎的消遣。人们曾经预测计算机有一天会能够击败人类国际象棋大师。当这在 1997 年发生时(IBM 的深蓝击败了世界国际象棋冠军加里·卡斯帕罗夫),人们对这个问题的兴趣减弱了。如今,计算机总是赢。
作为基本的高层分析,国际象棋是由两个玩家之间进行的,使用一个包含八个 8x8 网格中的六十四个位置的棋盘的国际象棋套装。棋盘上可以有两组十六个棋子,可以以不同的方式由两个玩家交替轮流 移动。每个棋子可以吃掉其他棋子。棋盘将需要在每个回合之后在计算机屏幕上绘制自己。
我用斜体标识了描述中一些可能的对象,并使用粗体标识了一些关键方法。这是将面向对象分析转化为设计的常见第一步。在这一点上,为了强调组合,我们将专注于棋盘,而不会过多担心玩家或不同类型的棋子。
让我们从可能的最高抽象级别开始。我们有两个玩家通过轮流走棋与国际象棋棋盘交互:

这看起来不太像我们早期的类图,这是一件好事,因为它不是一个!这是一个对象图,也称为实例图。它描述了系统在特定时间点的状态,并描述了对象的特定实例,而不是类之间的交互。请记住,两个玩家都是同一个类的成员,所以类图看起来有点不同:

该图表明只有两个玩家可以与一个国际象棋棋盘交互。这也表明任何一个玩家一次只能玩一个国际象棋棋盘。
然而,我们正在讨论组合,而不是 UML,所以让我们考虑一下国际象棋棋盘由什么组成。我们暂时不关心玩家由什么组成。我们可以假设玩家有心脏和大脑等器官,但这些对我们的模型无关紧要。事实上,没有什么能阻止说的玩家本身就是深蓝,它既没有心脏也没有大脑。
然后,国际象棋棋盘由棋盘和 32 个棋子组成。棋盘又包括 64 个位置。你可以争辩说棋子不是国际象棋棋盘的一部分,因为你可以用不同的棋子替换国际象棋棋盘中的棋子。虽然在计算机版本的国际象棋中这是不太可能或不可能的,但这向我们介绍了聚合。
聚合几乎与组合完全相同。不同之处在于聚合对象可以独立存在。一个位置不可能与不同的国际象棋棋盘相关联,所以我们说棋盘由位置组成。但是,棋子可能独立于国际象棋棋盘存在,因此被称为与该棋盘处于聚合关系。
区分聚合和组合的另一种方法是考虑对象的生命周期。如果组合(外部)对象控制相关(内部)对象的创建和销毁,那么组合是最合适的。如果相关对象独立于组合对象创建,或者可以比组合对象存在更久,那么聚合关系更合理。另外,请记住,组合是聚合;聚合只是组合的一种更一般的形式。任何组合关系也是聚合关系,但反之则不然。
让我们描述我们当前的国际象棋棋盘组合,并为对象添加一些属性来保存组合关系:

组合关系在 UML 中表示为实心菱形。空心菱形代表聚合关系。你会注意到棋盘和棋子以与将它们的引用存储为国际象棋棋盘的一部分,方式完全相同。这表明,一旦再次实践中,聚合和组合之间的区别通常在设计阶段过后就不再重要。在实现时,它们的行为方式大致相同。然而,当你的团队讨论不同对象如何交互时,区分它们可能有所帮助。通常情况下,你可以将它们视为相同的东西,但当你需要区分它们时(通常是在谈论相关对象存在多长时间时),了解区别是很重要的。
继承
我们讨论了对象之间的三种关系:关联、组合和聚合。然而,我们还没有完全指定我们的国际象棋棋盘,而这些工具似乎并不能给我们提供所有我们需要的功能。我们讨论了玩家可能是人类,也可能是具有人工智能的软件。说玩家与人类关联,或者说人工智能实现是玩家对象的一部分,似乎都不太合适。我们真正需要的是能够说Deep Blue 是一个玩家,或者加里·卡斯帕罗夫是一个玩家的能力。
is a关系是由继承形成的。继承是面向对象编程中最著名、最知名和最常用的关系。继承有点像家谱。我的祖父姓菲利普斯,我父亲继承了这个姓氏。我从他那里继承了它。在面向对象编程中,一个类可以从另一个类继承属性和方法,而不是从一个人那里继承特征和行为。
例如,我们的国际象棋棋盘上有 32 个棋子,但只有六种不同类型的棋子(兵、车、象、马、国王和皇后),每种棋子在移动时的行为都不同。所有这些棋子类都有属性,比如颜色和它们所属的国际象棋棋盘,但它们在国际象棋棋盘上绘制时也有独特的形状,并且移动方式不同。让我们看看这六种类型的棋子如何从Piece类继承:

空心箭头表示各个棋子类从Piece类继承。所有子类都自动从基类继承chess_set和color属性。每个棋子提供一个不同的形状属性(在渲染棋盘时绘制在屏幕上),以及一个不同的move方法,以在每一轮中将棋子移动到棋盘上的新位置。
我们实际上知道Piece类的所有子类都需要有一个move方法;否则,当棋盘试图移动棋子时,它会感到困惑。我们可能希望创建国际象棋的一个新版本,其中有一个额外的棋子(巫师)。我们当前的设计将允许我们设计这个棋子,而不给它一个move方法。然后当棋盘要求棋子移动时,它会出错。
我们可以通过在Piece类上创建一个虚拟的移动方法来解决这个问题。然后子类可以用更具体的实现覆盖这个方法。默认实现可能会弹出一个错误消息,说该棋子无法移动。
在子类中重写方法可以开发非常强大的面向对象系统。例如,如果我们想要实现一个具有人工智能的Player类,我们可以提供一个calculate_move方法,该方法接受一个Board对象,并决定将哪个棋子移动到哪里。一个非常基本的类可能会随机选择一个棋子和方向,然后相应地移动它。然后我们可以在子类中重写这个方法,使用 Deep Blue 的实现。第一个类适合与一个新手玩;后者将挑战一个国际象棋大师。重要的是,类中的其他方法,比如通知棋盘选择了哪个移动的方法,不需要改变;这个实现可以在两个类之间共享。
在国际象棋棋子的情况下,提供移动方法的默认实现并没有太多意义。我们只需要指定移动方法在任何子类中都是必需的。这可以通过使Piece成为一个抽象类,并声明abstract的移动方法来实现。抽象方法基本上是这样说的:
我们要求这种方法存在于任何非抽象子类中,但我们拒绝在这个类中指定实现。
事实上,可能会创建一个根本不实现任何方法的类。这样的类只会告诉我们类应该做什么,但绝对不会提供如何做的建议。在面向对象的术语中,这样的类被称为接口。
继承提供了抽象
让我们来探讨面向对象术语中最长的单词。多态性是指根据实现了哪个子类来对待一个类的能力。我们已经在我们描述的棋子系统中看到了它的作用。如果我们进一步设计,我们可能会发现Board对象可以接受玩家的移动并调用棋子的move函数。棋盘不需要知道它正在处理什么类型的棋子。它只需要调用move方法,适当的子类将负责将其移动为Knight或Pawn。
多态性很酷,但在 Python 编程中很少使用这个词。Python 在允许将对象的子类视为父类的基础上又迈出了一步。在 Python 中实现的棋盘可以接受任何具有move方法的对象,无论是主教棋子、汽车还是鸭子。当调用move时,Bishop将在棋盘上对角线移动,汽车将驾驶到某个地方,而鸭子将根据心情游泳或飞行。
在 Python 中,这种多态性通常被称为鸭子类型:如果它走起来像鸭子或游泳像鸭子,那它就是鸭子。我们不在乎它是否真的是一只鸭子(是一个是继承的基石),只在乎它是游泳还是走路。雁和天鹅可能很容易提供我们所寻找的鸭子般的行为。这使得未来的设计者可以创建新类型的鸟类,而无需实际指定水鸟的继承层次结构。它还允许他们创建完全不同的插入行为,原始设计者从未计划过。例如,未来的设计者可能能够创建一个行走、游泳的企鹅,它可以使用相同的接口,而从未暗示企鹅是鸭子。
多重继承
当我们想到我们自己家族谱中的继承时,我们会发现我们不仅从一个父类那里继承特征。当陌生人告诉一个骄傲的母亲她的儿子有他父亲的眼睛时,她通常会回答类似于,是的,但他有我的鼻子。
面向对象设计也可以包括这种多重继承,它允许子类从多个父类中继承功能。在实践中,多重继承可能会很棘手,一些编程语言(最著名的是 Java)严格禁止它。然而,多重继承也有其用途。最常见的用途是创建具有两组不同行为的对象。例如,一个设计用于连接扫描仪并发送扫描文档的传真的对象可能是通过从两个独立的scanner和faxer对象继承而创建的。
只要两个类具有不同的接口,子类从它们两者继承通常不会有害。但是,如果我们从提供重叠接口的两个类继承,情况就会变得混乱。例如,如果我们有一个具有move方法的摩托车类,还有一个同样具有move方法的船类,我们想将它们合并成终极两栖车时,当我们调用move时,结果类如何知道该做什么?在设计层面上,这需要解释,在实现层面上,每种编程语言都有不同的方式来决定调用哪个父类的方法,或以什么顺序调用。
通常,处理它的最佳方式是避免它。如果你的设计出现这样的情况,你很可能做错了。退一步,重新分析系统,看看是否可以取消多重继承关系,转而使用其他关联或组合设计。
继承是扩展行为的一个非常强大的工具。它也是面向对象设计相对于早期范例的最具市场潜力的进步之一。因此,它通常是面向对象程序员首先使用的工具。然而,重要的是要认识到拥有一把锤子并不会把螺丝钉变成钉子。继承是明显的“是一个”关系的完美解决方案,但它可能会被滥用。程序员经常使用继承来在两种只有遥远关联的对象之间共享代码,而看不到“是一个”关系。虽然这不一定是一个坏设计,但这是一个很好的机会去问他们为什么决定以这种方式设计,以及是否不同的关系或设计模式更合适。
案例研究
让我们通过对一个现实世界的例子进行几次迭代的面向对象设计,将我们所有新的面向对象的知识联系在一起。我们将要建模的系统是一个图书馆目录。图书馆几个世纪以来一直在跟踪他们的库存,最初使用卡片目录,最近使用电子库存。现代图书馆有基于网络的目录,我们可以在家里查询。
让我们从分析开始。当地的图书管理员要求我们编写一个新的卡片目录程序,因为他们古老的基于 Windows XP 的程序既难看又过时。这并没有给我们太多细节,但在我们开始寻求更多信息之前,让我们考虑一下我们已经对图书馆目录了解的情况。
目录包含书籍列表。人们搜索它们以找到特定主题的书籍,特定标题的书籍,或者特定作者的书籍。书籍可以通过国际标准书号(ISBN)来唯一标识。每本书都有一个杜威十进制分类法(DDS)号码,用于帮助在特定书架上找到它。
这个简单的分析告诉我们系统中一些明显的对象。我们很快确定Book是最重要的对象,其中已经提到了几个属性,比如作者、标题、主题、ISBN 和 DDS 号码,以及作为书籍管理者的编目。
我们还注意到一些其他可能需要或不需要在系统中建模的对象。为了编目的目的,我们只需要在书上搜索作者的author_name属性。然而,作者也是对象,我们可能想要存储一些关于作者的其他数据。当我们思考这一点时,我们可能会记起一些书籍有多个作者的情况。突然间,在对象上有一个单一的author_name属性的想法似乎有点愚蠢。与每本书相关联的作者列表显然是一个更好的想法。
作者和书籍之间的关系显然是关联,因为你永远不会说“一本书是一个作者”(这不是继承),而说“一本书有一个作者”,虽然在语法上是正确的,但并不意味着作者是书籍的一部分(这不是聚合)。事实上,任何一个作者可能与多本书相关联。
我们还应该注意名词(名词总是对象的好候选者)shelf。书架是需要在编目系统中建模的对象吗?我们如何识别单独的书架?如果一本书存放在一个书架的末尾,后来因为前一个书架插入了一本新书而移到了下一个书架的开头,会发生什么?
DDS 旨在帮助在图书馆中找到实体书籍。因此,将 DDS 属性与书籍一起存储应该足以找到它,无论它存放在哪个书架上。因此,我们可以暂时将书架从我们竞争对象的列表中移除。
系统中的另一个有问题的对象是用户。我们需要了解特定用户的任何信息吗,比如他们的姓名、地址或逾期书目清单?到目前为止,图书管理员只告诉我们他们想要一个目录;他们没有提到跟踪订阅或逾期通知。在我们的脑海中,我们还注意到作者和用户都是特定类型的人;在未来可能会有一个有用的继承关系。
为了编目的目的,我们决定暂时不需要识别用户。我们可以假设用户将搜索目录,但我们不必在系统中积极对他们进行建模,只需提供一个允许他们搜索的界面即可。
我们已经确定了书上的一些属性,但目录有什么属性?任何一个图书馆有多个目录吗?我们需要对它们进行唯一标识吗?显然,目录必须有它包含的书的集合,但这个列表可能不是公共接口的一部分。
行为呢?目录显然需要一个搜索方法,可能是作者、标题和主题的分开搜索。书上有什么行为?它需要一个预览方法吗?或者预览可以通过第一页属性而不是方法来识别吗?
前面讨论中的问题都是面向对象分析阶段的一部分。但在这些问题中,我们已经确定了一些设计中的关键对象。事实上,你刚刚看到的是分析和设计之间的几个微迭代。
很可能,这些迭代都会在与图书管理员的初次会议中发生。然而,在这次会议之前,我们已经可以为我们已经明确定义的对象勾勒出一个最基本的设计,如下所示:

拿着这个基本的图表和一支铅笔,我们与图书管理员会面。他们告诉我们这是一个很好的开始,但图书馆不仅仅提供书籍;他们还有 DVD、杂志和 CD,这些都没有 ISBN 或 DDS 号码。所有这些类型的物品都可以通过 UPC 号码唯一识别。我们提醒图书管理员,他们必须在书架上找到物品,而且这些物品可能不是按 UPC 号码组织的。
图书管理员解释说每种类型都是以不同的方式组织的。CD 主要是有声书,他们只有两打库存,所以它们是按作者的姓氏组织的。DVD 根据类型划分,然后按标题进一步组织。杂志按标题组织,然后按卷和期号进一步细分。书籍,正如我们猜测的那样,是按 DDS 号码组织的。
没有以前的面向对象设计经验,我们可能会考虑将 DVD、CD、杂志和书籍分别添加到我们的目录中,并依次搜索每一个。问题是,除了某些扩展属性和识别物品的物理位置之外,这些物品的行为都大致相同。这就是继承的工作!我们迅速更新我们的 UML 图表如下:

图书管理员理解了我们勾画的图表的要点,但对locate功能有点困惑。我们使用了一个特定的用例来解释,用户正在搜索单词bunnies。用户首先向目录发送搜索请求。目录查询其内部项目列表,找到了一个标题中带有bunnies的书和一个 DVD。此时,目录并不关心它是否持有 DVD、书、CD 还是杂志;在目录看来,所有项目都是一样的。然而,用户想知道如何找到这些实体项目,因此如果目录只返回一个标题列表,那就不够完善了。因此,它调用了两个发现的项目的locate方法。书的locate方法返回一个 DDS 号码,可以用来找到放置书的书架。DVD 通过返回 DVD 的流派和标题来定位。然后用户可以访问 DVD 部分,找到包含该流派的部分,并按标题排序找到特定的 DVD。
当我们解释时,我们勾画了一个 UML序列图,解释了各种对象是如何进行通信的:

虽然类图描述了类之间的关系,序列图描述了对象之间传递的特定消息序列。从每个对象悬挂的虚线是描述对象的生命周期的生命线。每个生命线上的较宽的框表示对象中的活动处理(没有框的地方,对象基本上是空闲的,等待发生某些事情)。生命线之间的水平箭头表示特定的消息。实线箭头表示被调用的方法,而带有实心头的虚线箭头表示方法返回值。
半箭头表示发送到对象或从对象发送的异步消息。异步消息通常意味着第一个对象调用第二个对象的方法,该方法立即返回。经过一些处理后,第二个对象调用第一个对象的方法来给它一个值。这与正常的方法调用相反,正常的方法调用在方法中进行处理,并立即返回一个值。
与所有 UML 图表一样,序列图只有在需要时才能最好使用。为了画图而画图是没有意义的。但是,当您需要传达两个对象之间的一系列交互时,序列图是一个非常有用的工具。
很遗憾,到目前为止,我们的类图仍然是一种混乱的设计。我们注意到 DVD 上的演员和 CD 上的艺术家都是人的类型,但与书籍作者的处理方式不同。图书管理员还提醒我们,他们的大部分 CD 都是有声书,有作者而不是艺术家。
我们如何处理为标题做出贡献的不同类型的人?一个明显的实现是创建一个Person类,包括人的姓名和其他相关细节,然后为艺术家、作者和演员创建这个类的子类。然而,在这里真的需要继承吗?对于搜索和编目的目的,我们并不真的关心表演和写作是两种非常不同的活动。如果我们正在进行经济模拟,给予单独的演员和作者类,并不同的calculate_income和perform_job方法是有意义的,但对于编目的目的,知道这个人如何为项目做出贡献就足够了。经过深思熟虑,我们意识到所有项目都有一个或多个Contributor对象,因此我们将作者关系从书籍移动到其父类中:

Contributor/LibraryItem关系的多重性是多对多,如一个关系两端的*****字符所示。任何一个图书馆项目可能有多个贡献者(例如,DVD 上的几位演员和一位导演)。许多作者写了很多书,所以他们可以附属于多个图书馆项目。
这个小改变,虽然看起来更清洁、更简单,但丢失了一些重要的信息。我们仍然可以知道谁为特定的图书馆项目做出了贡献,但我们不知道他们是如何贡献的。他们是导演还是演员?他们是写了有声书,还是为书朗读的声音?
如果我们可以在Contributor类上添加一个contributor_type属性就好了,但是当处理多才多艺的人既写书又导演电影时,这种方法就会失效。
一个选择是向我们的LibraryItem子类中添加属性来保存我们需要的信息,比如Book上的Author,或者CD上的Artist,然后将这些属性的关系都指向Contributor类。问题在于,我们失去了很多多态的优雅。如果我们想列出项目的贡献者,我们必须寻找该项目上的特定属性,比如Authors或Actors。我们可以通过在LibraryItem类上添加一个GetContributors方法来解决这个问题,子类可以重写这个方法。然后目录永远不必知道对象正在查询的属性;我们已经抽象了公共接口:

仅仅看这个类图,就感觉我们在做错事。它又臃肿又脆弱。它可能做了我们需要的一切,但感觉很难维护或扩展。关系太多,任何一个类的修改都会影响太多的类。看起来就像意大利面和肉丸。
现在我们已经探讨了继承作为一个选项,并发现它不够理想,我们可能会回顾我们之前基于组合的图表,其中Contributor直接附属于LibraryItem。经过一些思考,我们可以看到,实际上我们只需要再添加一个关系到一个全新的类,来标识贡献者的类型。这是面向对象设计中的一个重要步骤。我们现在正在向设计中添加一个旨在支持其他对象的类,而不是对初始需求的任何部分进行建模。我们正在重构设计,以便系统中的对象,而不是现实生活中的对象。重构是程序或设计维护中的一个重要过程。重构的目标是通过移动代码、删除重复代码或复杂关系,来改进设计,以获得更简单、更优雅的设计。
这个新类由一个贡献者和一个额外的属性组成,用于标识该人对给定LibraryItem所做贡献的类型。对于特定的LibraryItem可以有许多这样的贡献,一个贡献者可以以相同的方式为不同的项目做出贡献。以下的图表很好地传达了这个设计:

首先,这种组合关系看起来不如基于继承的关系自然。然而,它的优势在于允许我们添加新类型的贡献,而不必在设计中添加一个新类。当子类有某种专业化时,继承是最有用的。专业化是在子类上创建或更改属性或行为,使其在某种程度上与父类不同。创建一堆空类仅用于识别不同类型的对象似乎有些愚蠢(这种态度在 Java 和其他一切都是对象的程序员中不太普遍,但在更务实的 Python 设计师中很常见)。如果我们看继承版本的图表,我们会看到一堆实际上什么都不做的子类:

有时候,重要的是要认识到何时不使用面向对象的原则。这个不使用继承的例子很好地提醒我们,对象只是工具,而不是规则。
练习
这是一本实用书,不是教科书。因此,我不会为你创建一堆虚假的面向对象分析问题,让你分析和设计。相反,我想给你一些可以应用到自己项目中的想法。如果你有以前的面向对象经验,你就不需要在这一章节上花太多精力。然而,如果你已经使用 Python 一段时间,但从来没有真正关心过所有的类的东西,这些都是有用的心理锻炼。
首先,想想你最近完成的一个编程项目。确定设计中最突出的对象。尽量想出这个对象的尽可能多的属性。它有以下属性吗:颜色?重量?大小?利润?成本?名称?ID 号码?价格?风格?
思考属性类型。它们是基本类型还是类?其中一些属性实际上是伪装成行为?有时,看起来像数据的东西实际上是从对象的其他数据计算出来的,你可以使用一个方法来进行这些计算。这个对象还有哪些其他方法或行为?哪些对象调用了这些方法?它们与这个对象有什么样的关系?
现在,想想即将开始的项目。项目是什么并不重要;它可能是一个有趣的业余项目,也可能是一个价值数百万美元的合同。它不必是一个完整的应用程序;它可能只是一个子系统。进行基本的面向对象分析。确定需求和相互作用的对象。勾画出一个包含该系统最高抽象级别的类图。确定主要相互作用的对象。确定次要支持对象。详细了解一些最有趣的对象的属性和方法。将不同的对象带入不同的抽象级别。寻找可以使用继承或组合的地方。寻找应该避免使用继承的地方。
目标不是设计一个系统(尽管如果你的兴趣和时间允许,你当然可以这样做)。目标是思考面向对象的设计。专注于你曾经参与过的项目,或者未来打算参与的项目,这样做就更真实了。
最后,访问你最喜欢的搜索引擎,查找一些关于 UML 的教程。有数十种教程,找一个适合你的学习方法的。为你之前确定的对象勾画一些类图或序列图。不要太过于纠结于记忆语法(毕竟,如果重要的话,你总是可以再次查阅);只需对这种语言有所了解。你的大脑中会留下一些东西,如果你能快速勾画出下一个面向对象讨论的图表,那么交流会变得更容易一些。
总结
在本章中,我们快速浏览了面向对象范式的术语,重点放在面向对象设计上。我们可以将不同的对象分为不同的类别,并通过类接口描述这些对象的属性和行为。抽象、封装和信息隐藏是高度相关的概念。对象之间有许多不同类型的关系,包括关联、组合和继承。UML 语法对于乐趣和沟通可能会有用。
在下一章中,我们将探讨如何在 Python 中实现类和方法。