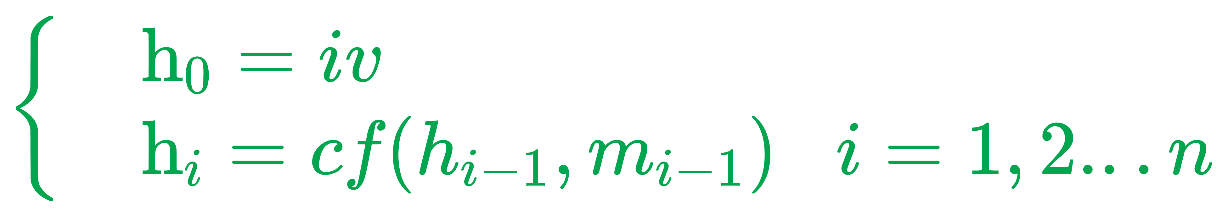一、背景
随着大模型的崛起,多模态模型如雨后春笋一样快速发展。我们可以借助多模态大模型理解物理世界中的物体,在上篇文章大模型时代,图像描述生成(image caption)怎么走?中提到基于大模型的图像描述生成效果后,随着GPT-4v的出现,多模态大模型在内容理解、以及机器人环境感知决策等方面都有了不错的运用,但对于许多任务依旧离不开检测分割,目前GPT4V给出的目标坐标效果较差,个人觉得未来GPT4V一定会融入检测分割的能力。
在日常工作或项目中有哪些开源的模型能够辅助我们完成对通用物品的识别分割与理解。近一段有一些不错的论文与开源模型值得借鉴,主要介绍个人实测效果突出的两个模型。
1)、GLEE是一个对象级的基础模型,用于定位和识别图像和视频中的对象。论文的主要贡献为:
- 通过一个统一的框架,GLEE可以在开放世界场景中完成任意物体的检测、分割、跟踪、接地和识别,以完成各种物体感知任务。
- 采用内聚学习策略,GLEE从不同监督级别的不同数据源中获取知识,以形成通用对象表示,擅长零次迁移到新数据和任务。

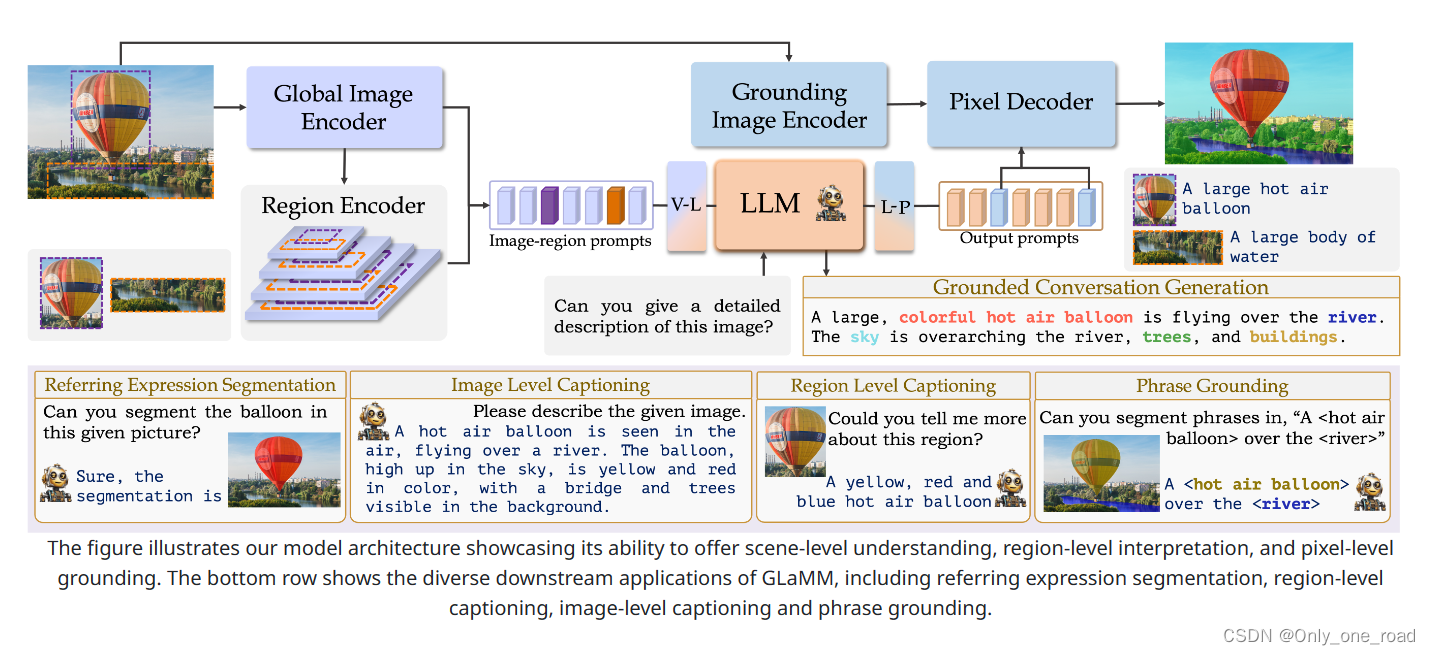
2)、Grounding Large Multimodal Model(GLaMM)
通过端到端的训练方法,实现对图像深层次理解的同时,提供了像素级别的地面分割和对话能力。对于空间理解有较大的提升。

GLaMM 包含五个核心组件,以实现可视化地面对话:全局图像编码器、区域编码器、LLM、地面图像编码器、像素解码器。这些组件是一套协同设计,既可以处理文本输入,也可以处理可选的视觉提示(图像级别和感兴趣区域),从而允许在多个粒度级别进行交互,并生成具有地面文本响应。
其他的模型如SPHINX、SceneVerse、GlaMM、智谱AI 新一代多模态大模型CogVLM、SAM系列的模型等。有了这些多模态大模型,似乎很多任务都可以用多模态来解决,但对于实际应用来说实时性与稳定性是必须兼顾的。目前工业场景中依旧是采用相对成熟的检测分割模型来实现,多模态大模型能否给日常项目带来收益呢,这个是必然可以的。数据标注的过程就是一个不错的收益,可以通过自动化的标注来减少数据成本。
二、开源工具与模型方案
目前有一些开源的自动化工具如:X-Anylabeling,里面集成了目前开源的模型,通过prompt的方式可以实现自动化的标注。整个系统的组成框架如下:

这种方式在一定程度上能给满足要求,但对于开发者来说prompt的撰写关系着最终的效果,往往合适的prompt也是需要花费很久去调试的。除此基于Python和OpenCV实现半自动标注工具为pyOpenAnnotate也开用来标注数据。很明显存在的问题就是传统方法实现,对于多数需要手动调整阈值,存在很大的弊端。
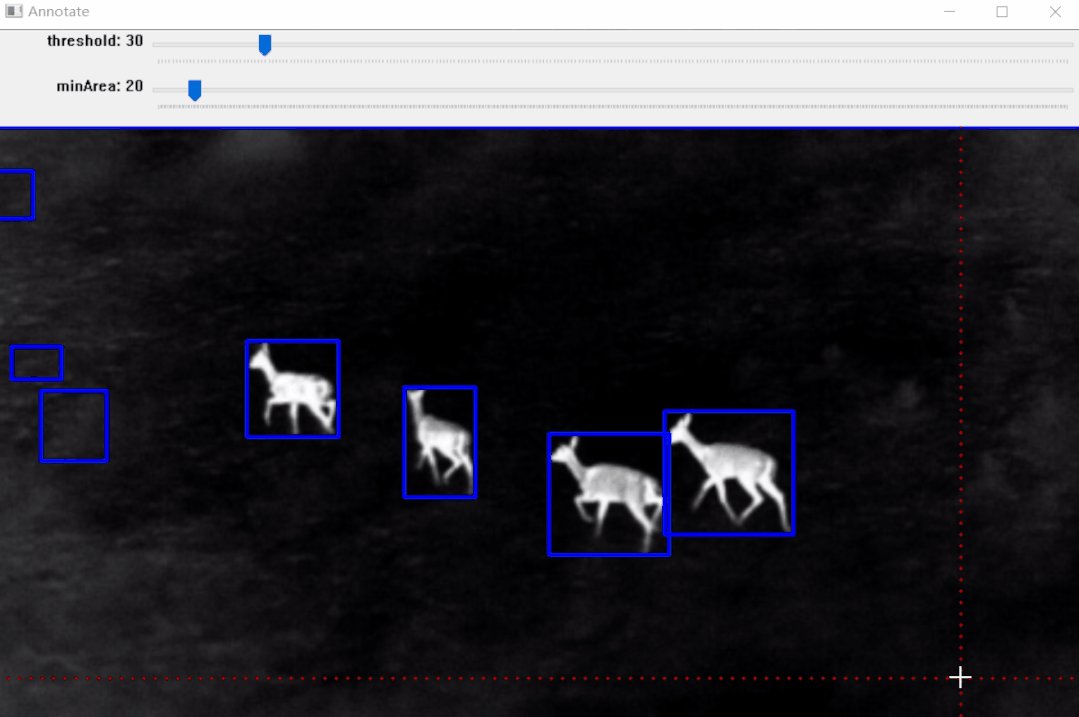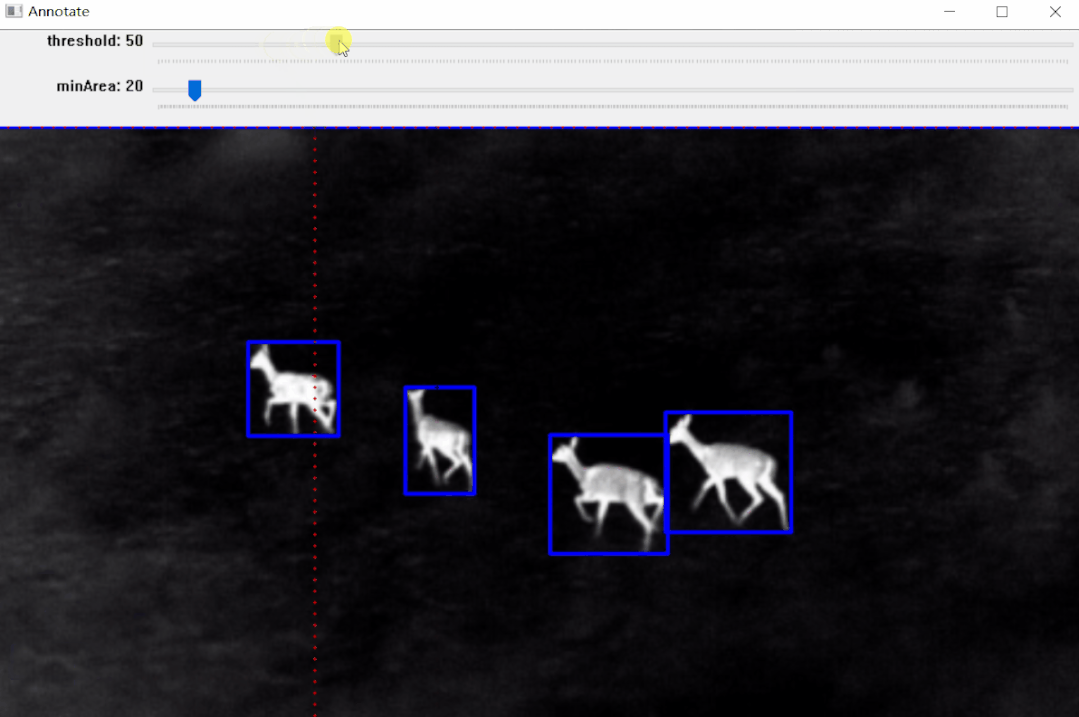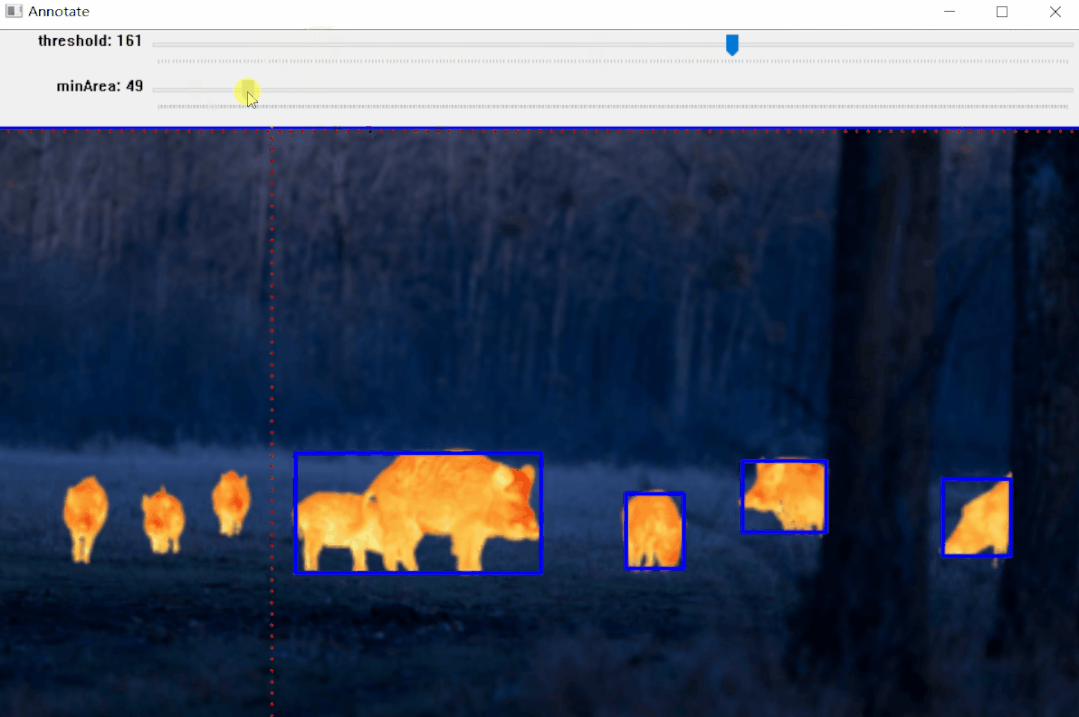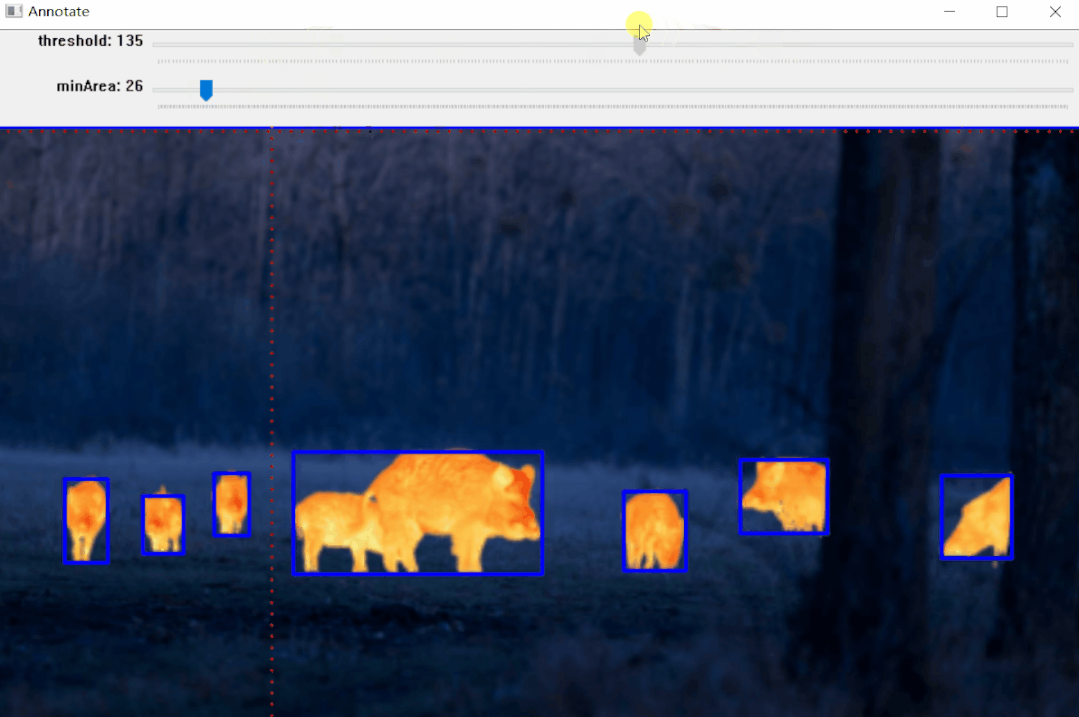
学术界也有很多值得借鉴的前沿方法。 GenSAM号称一个提示实现批量图片分割,告别逐一标注。介绍了一种名为GenSAM的测试时自适应机制,通过给定简单的文本描述,结合图像信息推理出目标对象的详细语义信息,生成无歧义的视觉提示,从而指导分割过程,效果如下。

此外还有一些不错的方法。如XMem,用户提供第一帧的注释,采用视频对象分割(VOS)在给定视频中突出显示指定的目标对象。Tracking-Anything-with-DEVA,AutoTrackingAnything采用跟踪的方法对物体实现分割。DEVA首先会分割连续的视频帧,提取目标像素级分割结果,然后在一个片段(滑窗)内将后面及帧的分割结果对齐到时间t上,之后利用片段一致性保留高支持性的目标分割结果,滤除IoU较低的分割结果(误检和低质量分割)。随后,对齐后的分割结果进行时序传播,进行固定帧数的传播以后再次和片段一致性分割结果进行融合(漏检),得到最终生成的视频分割结果。实际当中最大的问题是实时性,不过这个项目值得参考与借鉴。

三、人人可实现实时方案与效果
在实际项目中数据标注除了实例级别之外,较难的标注则是物体的某一部分,如工业零部件的端子,动物的耳朵等,这样的任务对物体的分割要求较高。具体实例如下:


现需要将左上图中的绿色框的部分分割出来,右上图是适用SAM-HQ分割的结果,粗略的看分割效果还不错,但在细粒度分割任务中不能够满足要求,中间的插孔难以分割出来。为此采用如下的方案做自动化分割标注,整个流程如下所示:
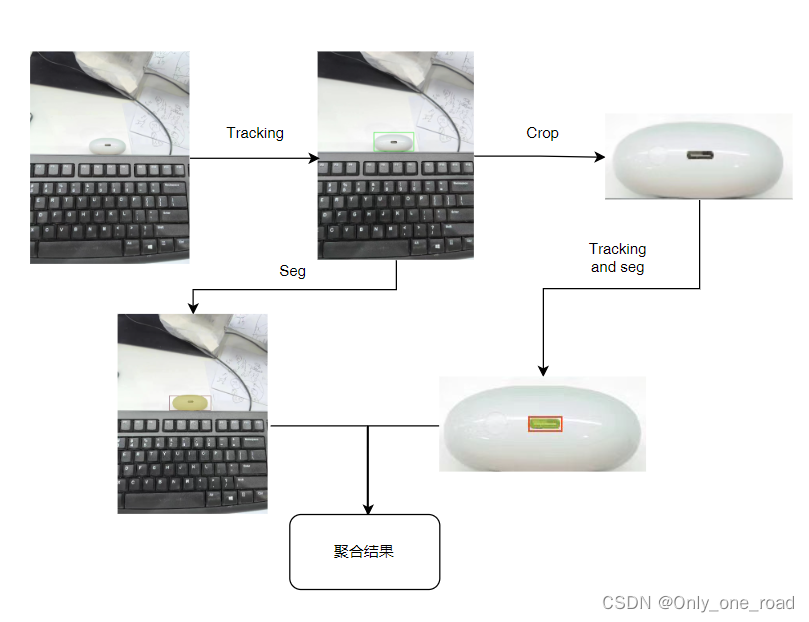
通过跟踪的方法对粗粒度与细粒度部分完成跟踪检测,结合检测结果分别进行粗细力度的分割,最终将结果整合,此方案在实测中标注质量与效率均不错。有其他想法的欢迎随时交流。
参考:
1、https://github.com/CVHub520/X-AnyLabeling
2、GitHub - jyLin8100/GenSAM: Code for AAAl 2024 paper: Relax Image-Specific Prompt Requirement in SAM: A Single Generic Prompt for Segmenting Camouflaged Objects
3、 GitHub - hkchengrex/XMem: [ECCV 2022] XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model4
4、GitHub - SysCV/sam-hq: Segment Anything in High Quality [NeurIPS 2023]