0. 前言:
今天写第一篇Linux内核调度子系统的文章,首先整理PELT负载追踪方法,之前的基础知识在后续的文章中share出来。文章的写成基本上是在几位内核大佬的文章基础之上完成的,有些地方的文字是直接引用的,但本文只用于学习,如果有侵犯请联系本人删除。首先给出参考过的文章链接:
CFS调度器:负载跟踪与更新——郑琦
PELT 算法浅析——内核工匠
Linux进程调度器-CPU负载——LoyenWang
CFS调度器(4)-PELT(per entity load tracking)
其次,本文代码部分是参考linux kernel 5.10源码。
1. 基本概念和数据结构
为了做到Per-entity的负载跟踪,时间(物理时间,不是虚拟时间)被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。
如果在该周期内,runnable的时间是x,那么对系统负载的贡献就是(x/1024)。当然,一个实体在一个计算周期内的负载可能会超过1024us,这是因为我们会累积在过去周期中的负载,当然,对于过去的负载我们在计算的时候需要乘一个衰减因子。
如果我们让Li表示在周期pi中该调度实体的对系统负载贡献,那么一个调度实体对系统负载的总贡献可以表示为:
L = L0 + L1*y + L2*y2 + L3*y3 + ...
其中y是衰减因子。通过上面的公式可以看出:
(1) 调度实体对系统负载的贡献值是一个序列之和组成
(2) 最近的负载值拥有最大的权重
(3) 过去的负载也会被累计,但是是以递减的方式来影响负载计算。
y已经确定:y ^32等于0.5,那么y=0.9785,一个调度实体的负载贡献经过32个周期(1024us)后,对当前时间的的符合贡献值会衰减一半。
重要数据结构
Linux中使用struct sched_avg来记录调度实体和CFS运行队列的负载信息,因此struct sched_entity、struct cfs_rq和struct rq结构体中,都包含了struct sched_avg,字段介绍如下:
// 5.10.34 /include/linux/sched.h
struct sched_avg {
u64 last_update_time; //上一次负载更新的时间,主要用于计算时间差;
u64 load_sum; //可运行时间带来的负载贡献总和,包括等待调度时间和正在运行时间;
u64 runnable_sum;
u32 util_sum; //正在运行时间带来的负载贡献总和;
/* 上次更新时,未满一个pelt计算周期(1024us)的部分 */
u32 period_contrib; //上一次负载更新时,对1024求余的值;
unsigned long load_avg;
unsigned long runnable_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;
| 成员 | 描述 |
| last_update_time | sched avg会定期更新,last_update_time是上次更新的时间点(当进程迁核时last_update_time会先置为0,入队后的负载更新时会设置为cfs的last_update_time) |
| load_sum load_avg | load_sum是经过时间负载贡献值加权的实际负载(进程的重要性是不同的),load_weight*contrib,体现进程权重对负载的影响; load_avg是由load_sum计算的平均负载 |
| runnable_sum runnable_avg | runnable_sum是基于runnable(runnable+running)进程数的时间负载贡献值加权得到(认为进程之间的重要性是相同的),runnable_weight* contrib; runnable_avg是runnable负载的均值 注: runnable_weight:进程=1(se->on_rq),cfs_rq=h_nr_running |
| util_sum util_avg | util_sum是基于running的负载; util_avg是running负载均值 |
| util_est | 预估负载,当任务阻塞时,其负载会不断衰减,如果阻塞时间很长,则根据pelt计算出来的负载会很小,当任务重新被唤醒参与调度时,由于负载小对于性能需求的响应会变差,因此util_est是用阻塞前的util_avg和其历史值计算的,本质是为了拉高性能。 |
| period_contrib | period_contrib是中间计算值,当前周期(1ms)的负载值 |
内核在se、cfs_rq和rq记录了负载值:
struct sched_entity { //include/linux/sched.h
struct sched_avg avg;
};
//struct sched_rt_entity 和 sched_dl_entity没有sched_avg变量。
/********************************************/
struct cfs_rq { //kernel/sched/sched.h
struct sched_avg avg;
};
/********************************************/
struct rq { //kernel/sched/sched.h
struct sched_avg avg_rt;
struct sched_avg avg_dl;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ
struct sched_avg avg_irq;
#endif
#ifdef CONFIG_SCHED_THERMAL_PRESSURE
struct sched_avg avg_thermal;
#endif
};2. 负载更新时机
内核需要经常更新维护cfs rq和se上的load avg,以便让任务负载、CPU负载能够及时更新。update_load_avg函数用来更新se及其cfs rq的负载。具体的更新的时间点总是和调度事件相关,例如一个任务阻塞的时候,把之前处于running状态的时间增加的负载更新到系统中。而在任务被唤醒的时候,需要根据其睡眠时间,对其负载进行衰减。具体调用update_load_avg函数的时机包括: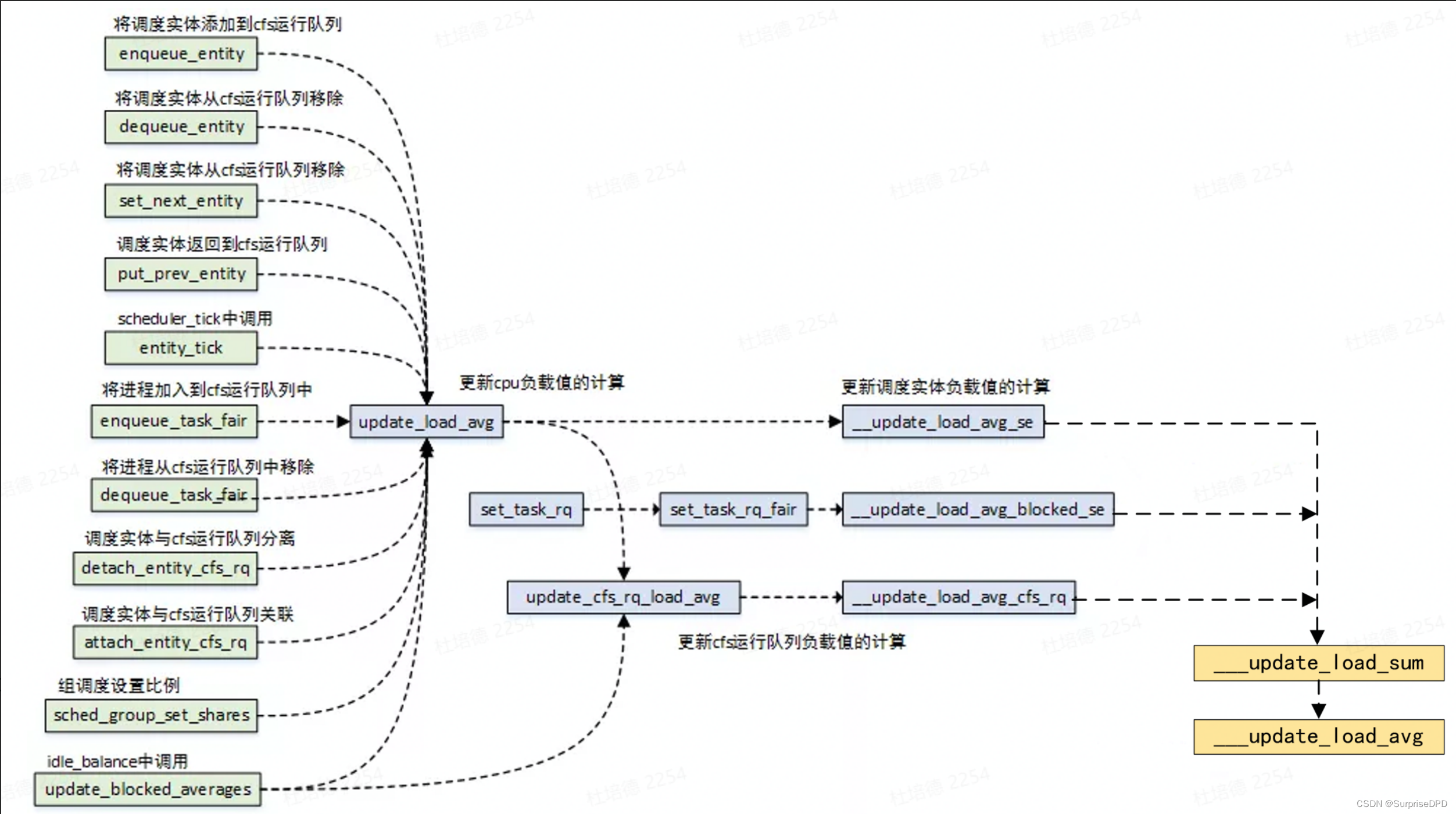
上图可见调度实体的相关操作,包括入队出队操作,都会进行负载的更新计算。最终会调用__update_load_avg()完成计算。
在5.10.34 kernel中的一条更新负载的路线:
// kernel/sched/fair.c
enqueue_entity()
-> update_load_avg()
-> update_cfs_rq_load_avg()
-> __update_load_avg_cfs_rq()
-> ___update_load_sum()
-> accumulate_sum()
-> decay_load()
-> __accumulate_pelt_segments()
-> ___update_load_avg()从上面函数调用关系和函数名可知,需要先计算*_sum,然后得到*_avg值。
3. Pelt时间计算
广义负载和两个量相关:时间和计算能力,cpu计算能力差异主要在于大小核和频率。
相同负载的进程,跑在不同的cpu算力上时间必然不同,不能只根据时间计算,因此在做负载追踪的时候必须对时间进行加权,这就是计算时间负载的原因。
在update_load_avg中我们首先需要关注pelt时间:
/* Update task and its cfs_rq load average */
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
u64 now = cfs_rq_clock_pelt(cfs_rq);
/* 追代码后可知:now = rq->clock_pelt - rq->lost_idle_time; */
}可看到在计算负载load_sum开始之前,获取的是rq的pelt当前时间。
在进程调度的过程中,pelt时间的更新主要由 update_rq_clock来完成,在调度相关代码中有以下一些调用的地方:
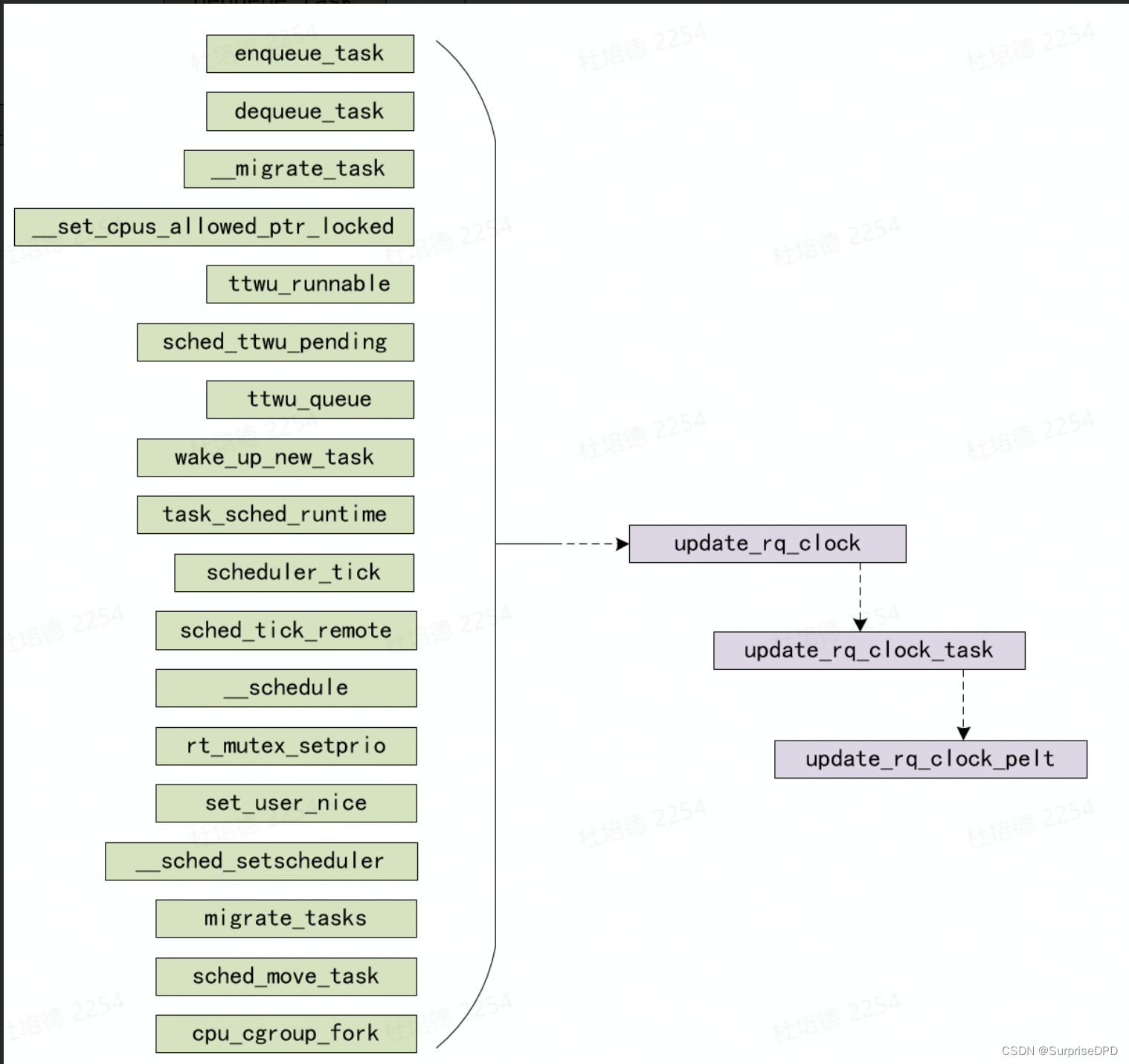
update_rq_clock()代码如下:
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_update_flags & RQCF_ACT_SKIP)
return;
#ifdef CONFIG_SCHED_DEBUG
if (sched_feat(WARN_DOUBLE_CLOCK))
SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED);
rq->clock_update_flags |= RQCF_UPDATED;
#endif
delta = sched_clock_cpu(cpu_of(rq)) - rq->clock; //计算实际时间差值
if (delta < 0)
return;
rq->clock += delta;
update_rq_clock_task(rq, delta);
}
EXPORT_SYMBOL_GPL(update_rq_clock);可以看到,update_rq_clock会去找到rq所在cpu,并获取到cpu的运行时间,计算现在到上次更新rq->clock的差值,然后更新rq->clock。
update_rq_clock_task(rq)更新的是当前rq->clock_task值,该值在更新过程中减掉了中断时间等的时间,目的是为了得到进程实际运行的时间。在代码最后调用了update_rq_clock_pelt来更新和pelt计算相关的时间。更新pelt时间的函数调用关系如下:
update_rq_clock()
-> update_rq_clock_task()
-> update_rq_clock_peltupdate_rq_clock_pelt代码:
static inline void update_rq_clock_pelt(struct rq *rq, s64 delta)
{
if (unlikely(is_idle_task(rq->curr))) {
/* The rq is idle, we can sync to clock_task */
rq->clock_pelt = rq_clock_task(rq);
return;
}
delta = cap_scale(delta, arch_scale_cpu_capacity(cpu_of(rq)));// 形参delta=rq->clock_task的增量
delta = cap_scale(delta, arch_scale_freq_capacity(cpu_of(rq)));
rq->clock_pelt += delta;
}update_rq_clock_pelt主要实现:
a. 如果是idle进程,则rq->clock_pelt= rq->clock_task;
b. 否则,需要根据具体运行的Cpu计算能力和CPU频率两方面对时间进行加权。
c. 最后将加权后的时间累加到rq->clock_pelt上。
注:cpu_scale 和 freq_scale的计算公式如下:

cpu_scale在void topology_normalize_cpu_scale(void)函数中初始化的。
代码中的pelt时间负载增量的具体加权计算过程如下:
delta = (rq->clock_task的delta) * cpu_scale >>SCHED_CAPACITY_SHIFT * freq_scale >>SCHED_CAPACITY_SHIFT
// SCHED_CAPACITY_SHIFT = 10 由此,根据进程所在cpu的算力,归一化pelt时间,然后更新到rq->clock_pelt中。
cpu_scale是当前cpu向最大核最高频做归一化;
freq_scale是当前cpu向本cpu的最高频率做归一化。
其中cpu_scale计算中的V1和V2的计算量纲是:
dmips-mhz: 表示cpu在1MHz的频率下,每秒钟可以执行多少dmips
4. *_sum计算
本节主要解释___update_load_sum函数内部的计算过程。
本节使用的*_sum是load_sum,runnable_sum和util_sum的代称,他们是cpu上表征负载的三个维度。load_sum是任务负载,任务是有权重的;runnable_sum是等待负载;util_sum是cpu的利用率。
负载计算示意图如下:
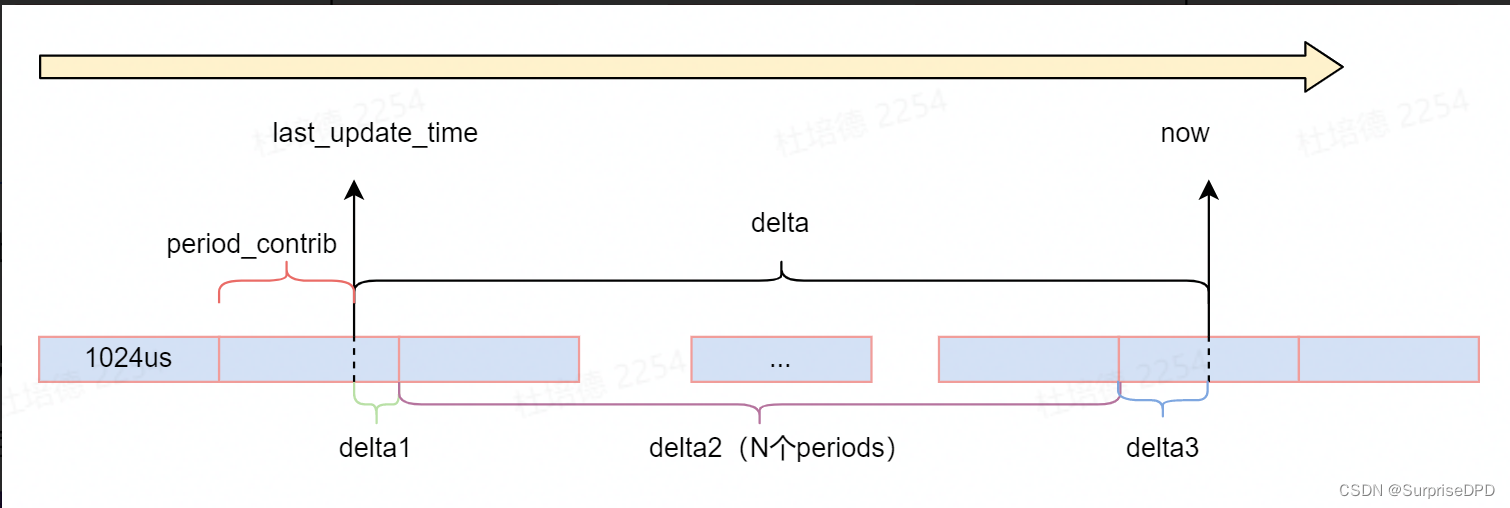
4.1 总体负载计算
每次更新总体负载分为两段计算,一段为last_update_time之前的过去负载(last_update_time之前的时间),只要直接衰减;一段是当前负载,也就是本次更新时这段时间内的负载,是由时间负载贡献值contrib加权计算得到。
先将总体负载计算代码放在这:
/*
* delta: pelt时间差值
*/
static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
delta += sa->period_contrib;
periods = delta / 1024; /* A period is 1024us (~1ms) */
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods);
sa->runnable_sum = decay_load(sa->runnable_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
delta %= 1024;
if (load) {
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
}
sa->period_contrib = delta;
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}4.2 过去负载衰减计算方法
第一段过去负载,只需要对过去的负载直接衰减periods个周期。
// kernel/sched/pelt.c
accumulate_sum(){
sa->load_sum = decay_load(sa->load_sum, periods); //load_sum衰减
sa->runnable_sum = decay_load(sa->runnable_sum, periods); //util_sum衰减
sa->util_sum = decay_load((u64)(sa->util_sum), periods); //util_sum衰减
}decay_load()函数用于计算衰减val*(y^n)的值,内核的实现:
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
/* LOAD_AVG_PERIOD=32,即32*63(~2016ms)前的负载对当前的贡献忽略不计 */
if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
local_n = n;
/* 1、因为y^32=0.5,所以y^n可以变为1/2^(n/32) * y^(n%32) */
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
/* val = val * (1/2)^(local_n/32) */
val >>= local_n / LOAD_AVG_PERIOD;
/* local_n = local_n%32 */
local_n %= LOAD_AVG_PERIOD;
}
/* 2、将y^(n%32)的一共32中32种取值,提前计算好再乘以2^32(提高计算精度),
* 结果记录在runnable_avg_yN_inv数组中,这样mul_u64_u32_shr函数计算的
* (val*runnable_avg_yN_inv[local_n])/2^32即为val*y^n的值,
* 此时decay_load()函数的时间复杂度从原始版本的O(n)变为了O(1)
*/
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32);
return val;
}内核采用了查表的方式计算32个周期以内的时间负载贡献值,以避免浮点计算,有32个衰减值如下:
// kernel-5.10.34 kernel/sched/sched-pelt.h
static const u32 pelt32_runnable_avg_yN_inv[] __maybe_unused = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};4.3 当前时间负载贡献值
第二段为当前负载,由三种实际负载组成,分别由load、runnable或util通过加权时间负载贡献值得到,此处只讲解时间负载贡献值contrib的计算。从第4节图中可知,时间负载贡献值contrib的计算分为三段:delta1,delta2和delta3,分别对每段时间做衰减并累加求和。参考第1小节时间衰减的计算思想,可得计算公式如下:
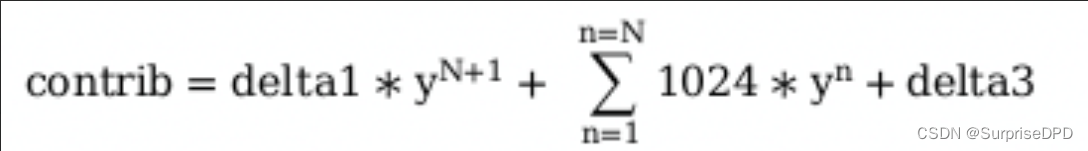
*_sum的计算函数代码如下:
/*
* delta: pelt时间差值
*/
static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
delta += sa->period_contrib;
periods = delta / 1024; /* A period is 1024us (~1ms) */
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods);
sa->runnable_sum = decay_load(sa->runnable_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
delta %= 1024;
if (load) {
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
}
sa->period_contrib = delta;
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}对照第4节开头的图和上述代码,我们梳理计算过程:
/****step 1 计算总时间差 ****/
contrib = delta = now - last_update_time = 实际时间差
/****step 2 加上之前不够整周期的值,为了计算出实际需要衰减多少个周期****/
delta += sa->period_contrib //加上了last_update_time之前的不够一个周期的部分
periods = delta / 1024 = 过去的整周期
/****step 3 对过去的load做衰减,对应4.2计算过程 ****/
sa->load_sum = decay_load(sa->load_sum, periods)//sa->load_sum衰减periods个周期
sa->runnable_sum和sa->util_sum同理
/****step 4 计算delta3 ,delta3另算,因为不需要任何衰减 ****/
delta %= 1024; //delta=delta3
/****step 5 计算负载贡献值 ****/
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
= __accumulate_pelt_segments(periods, delta1,delta3)
= delta1衰减periods个周期+ 47742 - (47742衰减periods个周期) -1024 +delta3
/****step 6 period_contrib赋值为delta3 ****/
sa->period_contrib = delta = delta3
/****step 7 根据传入的形参计算以下各*_sum值 ****/
sa->load_sum += load * contrib; //在原load_sum衰减后基础上,加上现在的负载*contrib
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT; 在__accumulate_pelt_segments函数实现了具体的contrib的计算:
static u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
c1 = decay_load((u64)d1, periods);
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3;
}关于delta2的实际计算公式如代码中所写:47742 - (47742衰减periods个周期) -1024 ,该公式是简化后的公式,根据注释可推导公式如下:
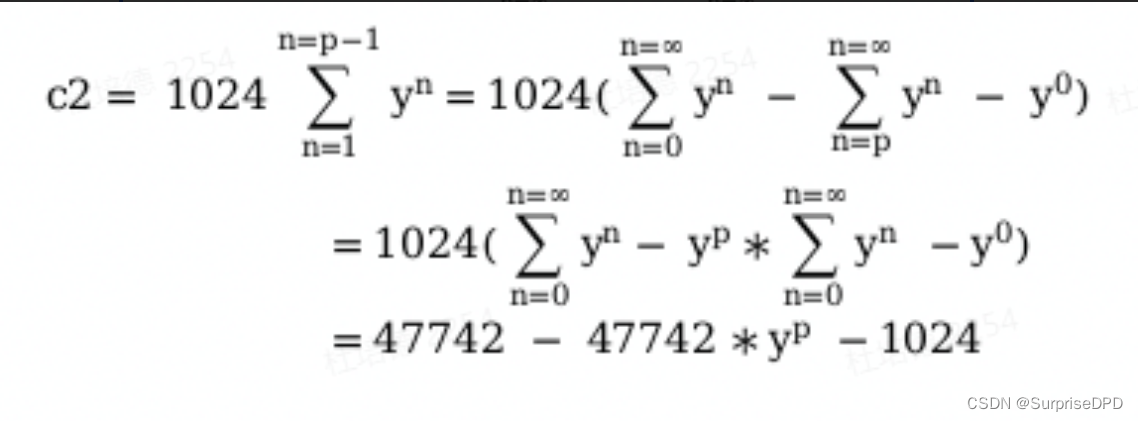
由于y=0.9785, 对y^n(0<= n < 无穷大) 求和, 对等比数列取无穷大极限,极限值为47742。因此delta2的衰减计算值可以推到得到如代码中表示的结果。
因此我们可以得到时间负载贡献值contrib的完整计算公式是:
contrib = delta1衰减periods个周期 + 47742-(47742衰减periods个周期) -1024 + delta34.4 形参差异决定实际负载
accumulate函数的参数: load, runnable, running会影响sa各值的计算。___update_load_sum函数传入的参数对*_sum计算的影响如下:
se的*_sum更新参数:
__update_load_avg_se(){
___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se),cfs_rq->curr == se)//se的实际负载,load_sum更新取决于se是否在队列上,runnable_sum更新取决于se的runnable,util_sum更新取决于cfs_rq的curr是否是当前se
}static inline long se_runnable(struct sched_entity *se)
{
if (entity_is_task(se)) //如果是进程,则返回是否在rq上,如果不在队列中,那runnable_sum也就没必要增加当前进程的负载
return !!se->on_rq;
else
return se->runnable_weight;// 如果是进程组,则是进程组的cfs_rq的进程数
}
//在struct sched_entity结构体中对runnable_weight的描述:
/* cached value of my_q->h_nr_running 也就是等同于该进程组的cfs_rq上的进程数*/
unsigned long runnable_weight;因此:
调用accumulate_sum(delta, sa, 0或1 , 0或1, 1或0)
关于*_sum的计算可以带入accumulate_sum函数中计算,此处不赘述。
load_sum += 1/0 * contrib = 1/0 *contrib
runnable += 1/0 * contirb << 10
util_sum += 1/0 *contrib << 10
cfs_rq的*_sum更新参数:
__update_load_avg_cfs_rq(){
___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
cfs_rq->h_nr_running,
cfs_rq->curr != NULL)
//cfs_rq的实际负载,load_sum更新取决于cfs_rq的load.weight是否为0,runnable_sum更新取决于cfs_rq的进程数,util_sum更新取决于cfs_rq的调度实体curr是否在cpu上运行
}因此:
调用accumulate_sum(delta, sa, load.weight >>10 , 进程数, 1或0)
load_sum += load.weight >>10 * contrib = load.weight * 1024 *contrib
runnable += 进程数 * contirb << 10
util_sum += 是否在cpu上 *contrib << 10
rt_rq的*_sum更新参数:
update_rt_rq_load_avg(){
___update_load_sum(now, &rq->avg_rt,
running,
running,
running)
//rt_rq的实际负载,*_sum更新取决于当前调度类是否是rt调度类(curr_class == &rt_sched_class),所以running=1
}因此:
调用accumulate_sum(delta, sa, 1, 1, 1)
load_sum += 1 * contrib
runnable += 1 * contirb << 10 = contrib *1024
util_sum += 1 * contrib << 10 = contrib *1024
5. *_avg计算
___update_load_avg实现根据load_sum计算load_avg。
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load)
{
u32 divider = get_pelt_divider(sa); //=47742 -1024 + sa->period_contrib,即load_sum的最大值
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_avg = div_u64(sa->runnable_sum, divider);
WRITE_ONCE(sa->util_avg, sa->util_sum / divider);
}从上述代码可知,*_avg的计算公式是:
sa->load_avg = load * sa->load_sum / max_load_sum
sa->runnable_avg = sa->runnable_sum / max_load_sum
sa->util_avg = sa->util_sum / max_load_sumcfs_rq和se的load_sum和load_avg的计算存在差异如下:
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq)
{
if (___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
cfs_rq->h_nr_running,
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1);
trace_pelt_cfs_tp(cfs_rq);
return 1;
}
return 0;
}根据传入的参数,cfs_rq的*_sum计算:
sa->load_sum = cfs_rq->load.weight >> 10 * contrib
sa->runnable_sum = cfs_rq->h_nr_running * contrib << 10
sa->util_sum =(cfs_rq->curr != NULL ) * contrib << 10根据传入的参数,cfs_rq的*_avg计算:
// max_load_sum = 47742 -1024 + sa->period_contrib
sa->load_avg = sa->load_sum * 1 / max_load_sum = cfs_rq->load.weight >> 10 * contrib / (47742 -1024 + sa->period_contrib)
sa->runnable_avg = sa->runnable_sum / max_load_sum = cfs_rq->h_nr_running * contrib << 10 / (47742 -1024 + sa->period_contrib)
sa->running_avg = sa-> util_sum / max_load_sum = (cfs_rq->curr != NULL ) * contrib << 10 / (47742 -1024 + sa->period_contrib)根据传入的参数,se的*_sum计算:
int __update_load_avg_se(u64 now, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se),
cfs_rq->curr == se)) {
___update_load_avg(&se->avg, se_weight(se));
cfs_se_util_change(&se->avg);
trace_pelt_se_tp(se);
return 1;
}
return 0;
}sa->load_sum = ( !!se->on_rq ) * contrib
sa->runnable_sum = se_runnable(se) * contrib << 10 // 如果se是task,se_runnable(se)是!!se->on_rq; 如果se是调度组,se_runnable(se)是se->runnable_weight
sa->util_sum =(cfs_rq->curr == se ) * contrib << 10根据传入的参数,se的*_avg计算:
sa->load_avg = se->load.weight >> 10 * ( !!se->on_rq ) * contrib / max_load_sum
sa->runnable_avg = sa->runnable_sum / max_load_sum = se_runnable(se) * contrib << 10 / max_load_sum
sa->util_avg = sa-> util_sum / max_load_sum = (cfs_rq->curr == se ) * contrib << 10 / max_load_sum6. 预估负载util_est
参考:PELT算法中的预估利用率 util_est,eas k5.4 (七):v4.17 - Util(ization) Est(imated)
由于在 PELT 算法下任务的 util 增加减少的都比较慢,对于长时间休眠后的重负载任务,其 util 增加的比较慢,导致不能及时触发提频和迁核。为了补救 PELT 的这一缺陷,引入了预估负载。在任务(休眠)出队列时更新任务的预估负载,当任务入队列时将出队列时的负载加到cfs_rq的预估负载上。
struct util_est {
unsigned int enqueued;
unsigned int ewma; //
#define UTIL_EST_WEIGHT_SHIFT 2
#define UTIL_AVG_UNCHANGED 0x80000000
} __attribute__((__aligned__(sizeof(u64))));
/*
* struct util_est - 预估 FAIR 任务的利用率(utilization)
* @enqueued:task/cpu 的瞬时预估利用率
* @ewma:任务的指数加权移动平均 (EWMA) 利用率,即预估负载
*
* 每次任务完成唤醒时,都会将新样本添加到移动平均值中。
* 样本权重的选择使 EWMA 对任务工作负载的瞬态变化相对不敏感。
*
* enqueued 属性对于 tasks (se)和 cpus (cfs_rq)的含义略有不同:
* - task:上次任务出队时任务的 util_avg
* - cfs_rq:该 CPU 上每个 RUNNABLE 任务的 util_est.enqueued 总和。因此,任务(非cfs_rq)的 util_est.enqueued 表示该任务当前排队的 CPU 估计利用率的贡献。
*
* 仅对于我们跟踪过去瞬时估计利用率的移动平均值的任务。这允许吸收其他周期性任务的利用率的零星下降。
* UTIL_AVG_UNCHANGED标志用于同步util_est和util_avg更新。当一个任务退出队列时,如果它的util_avg在此期间没有更新,那么它的util_est不应该被更新。
*/6.1 任务出队、入队
只有在task每次出队的时候task的util_est也出队并更新util_est:
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
...
util_est_dequeue();//出队时将当前进程的负载从cfs_rq上减掉(入队再加上)
util_est_update();//重新计算预估负载,只有dequeue_task_fair调用了该函数
...
}在task入队时task的util_est入队:
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
...
/*
* The code below (indirectly) updates schedutil which looks at
* the cfs_rq utilization to select a frequency.
* Let's add the task's estimated utilization to the cfs_rq's
* estimated utilization, before we update schedutil.
*/
util_est_enqueue(&rq->cfs, p);
...
}在task出队时调用util_est_dequeue将task的util_est从cfs_rq上减掉:
static inline void util_est_dequeue(struct cfs_rq *cfs_rq,
struct task_struct *p)
{
unsigned int enqueued;
/* Update root cfs_rq's estimated utilization */
enqueued = cfs_rq->avg.util_est.enqueued;
// 一般都是task_util_est < enqueued 的,这样做的目的就是为了保证计算出来不出现负值
enqueued -= min_t(unsigned int, enqueued, _task_util_est(p));
WRITE_ONCE(cfs_rq->avg.util_est.enqueued, enqueued);
}上述代码具体步骤是:
- 先拿到cfs_rq的util_est.enqueued
- 获取任务p的预估负载,具体调用_task_util_est
- 然后从cfs_rq的util_est.enqueued中减掉任务的预估负载
在task入队时调用util_est_enqueue将task的util_est加到cfs_rq上:
static inline void util_est_enqueue(struct cfs_rq *cfs_rq,
struct task_struct *p)
{
unsigned int enqueued;
/* Update root cfs_rq's estimated utilization */
enqueued = cfs_rq->avg.util_est.enqueued;
enqueued += _task_util_est(p);
WRITE_ONCE(cfs_rq->avg.util_est.enqueued, enqueued);
}6.2 任务的预估负载
_task_util_est用于获取任务的预估负载:
static inline unsigned long _task_util_est(struct task_struct *p)
{
struct util_est ue = READ_ONCE(p->se.avg.util_est);
//返回ue.ewma和ue.enqueued两者最大的一个
return max(ue.ewma, (ue.enqueued & ~UTIL_AVG_UNCHANGED));
}
//UTIL_AVG_UNCHANGED标志用于将util_est与util_avg更新同步。当一个任务离开队列时,如果它的util_avg在此期间没有更新,那么它的util_est就不应该被更新6.3 预估负载的更新
util_est_update用于在任务出队的时候更新预估负载:
static inline void util_est_update(struct cfs_rq *cfs_rq,
struct task_struct *p,
bool task_sleep)
{
ue = p->se.avg.util_est;
/* 1. 如果pelt没有更新,也就上文中介绍的util_avg等没更新,则UTIL_AVG_UNCHANGED是0x80000000,和ue.enqueued与等于0,就退出了 */
if (ue.enqueued & UTIL_AVG_UNCHANGED)
return;
last_enqueued_diff = ue.enqueued;
/*如果内核允许FASTUP,则当ewma小于enqueued时,直接将enqueued赋值给ewma就return*/
/* 2. 在task的util_avg大于EWMA时重置EWMA为util_avg,移动平均值仅用于平滑利用率下降*/
ue.enqueued = task_util(p);
if (sched_feat(UTIL_EST_FASTUP)) {
if (ue.ewma < ue.enqueued) {
ue.ewma = ue.enqueued;
goto done;
}
}
/* 3. 实际负载(util_avg)与移动平均值的差值*/
last_ewma_diff = ue.enqueued - ue.ewma;
last_enqueued_diff -= ue.enqueued; // 实际负载的差值
/*当任务的 EWMA 变化量在其上次激活值的1% 左右时,跳过更新任务的估计利用率*/
if (within_margin(last_ewma_diff, UTIL_EST_MARGIN)) {
if (!within_margin(last_enqueued_diff, UTIL_EST_MARGIN))
goto done;
return;
}
//当前负载大于最大计算能力则返回
if (task_util(p) > capacity_orig_of(cpu_of(rq_of(cfs_rq))))
return;
/*
* Update Task's estimated utilization
*
* When *p completes an activation we can consolidate another sample
* of the task size. This is done by storing the current PELT value
* as ue.enqueued and by using this value to update the Exponential
* Weighted Moving Average (EWMA):
*
* ewma(t) = w * task_util(p) + (1-w) * ewma(t-1)
* = w * task_util(p) + ewma(t-1) - w * ewma(t-1)
* = w * (task_util(p) - ewma(t-1)) + ewma(t-1)
* = w * ( last_ewma_diff ) + ewma(t-1)
* = w * (last_ewma_diff + ewma(t-1) / w)
*
* Where 'w' is the weight of new samples, which is configured to be
* 0.25, thus making w=1/4 ( >>= UTIL_EST_WEIGHT_SHIFT)
*/
/* 4. 重新计算ewma */
ue.ewma <<= UTIL_EST_WEIGHT_SHIFT;
ue.ewma += last_ewma_diff;
ue.ewma >>= UTIL_EST_WEIGHT_SHIFT;
done:
ue.enqueued |= UTIL_AVG_UNCHANGED;
WRITE_ONCE(p->se.avg.util_est, ue);
}如代码所述, 如果内核允许FASTUP,则当ewma小于enqueued时,直接将enqueued赋值给ewma就返回;否则就如代码中注释写的ue.ewma的计算公式更新ewma , 具体计算如下:
ewma(t) = w * task_util(p) + (1-w) * ewma(t-1)
==> 整理后:w * (last_ewma_diff + ewma(t-1) / w),w 取1/4
简化公式如下:
ewma_now = (last_ewma_diff + ewma_last*4)/4
=( ue.enqueued - ue.ewma)/4 + ewma_last
= ( ue.enqueued - ewma_last)/4 + ewma_last
也就是说每次更新的是ewma,只增加或减少差值的1/4.
经研究,此处使用ewma(指数加权移动平均值)只是为了简化计算,降低计算复杂度和空间复杂度。
6.4 UTIL_AVG_UNCHANGED
UTIL_AVG_UNCHANGED标志位
UTIL_AVG_UNCHANGED使用task util_est.enqueued最后一个bit,标识task的util_avg是否被更新过了。只有task的util_avg被更新过,才会更新task的util_est。对于频繁运行的u秒级小task(util_avg最小更新粒度是1ms),不会在每次dequeue时更新util_est,这样减小了更新util_est的开销,同时也减小了在task util_avg未更新时的无意义操作。
util_est->enqueued的标志位在哪清零?
__update_load_avg_se -> cfs_se_util_change(&se->avg)把task的avg->util_est.enqueued的UTIL_AVG_UNCHANGED位清零,即更新task和它所在的rq util后,置位标志位,标示task的util已经发生变化了。
static inline void cfs_se_util_change(struct sched_avg *avg)
{
unsigned int enqueued;
if (!sched_feat(UTIL_EST))
return;
/* Avoid store if the flag has been already reset */
enqueued = avg->util_est.enqueued;
if (!(enqueued & UTIL_AVG_UNCHANGED))
return;
/* Reset flag to report util_avg has been updated */
enqueued &= ~UTIL_AVG_UNCHANGED;
WRITE_ONCE(avg->util_est.enqueued, enqueued);
}UTIL_AVG_UNCHANGED在哪置位?
在util_est_update最后将ue.enqueued的UTIL_AVG_UNCHANGED标志位置位:
static inline void util_est_update(struct cfs_rq *cfs_rq,
struct task_struct *p,
bool task_sleep)
{
done:
ue.enqueued |= UTIL_AVG_UNCHANGED;
WRITE_ONCE(p->se.avg.util_est, ue);
}