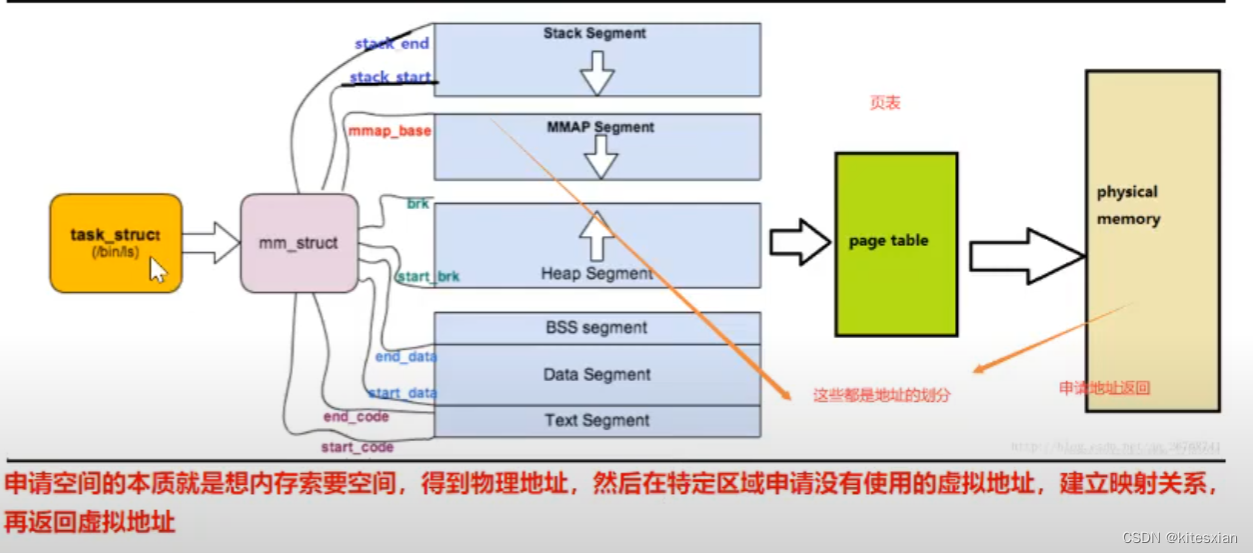
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。 与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇, 并可在噪声的空间数据库中发现任意形状的聚类。
算法流程
(1)圆心标记为聚类点画圈+判断临近点是否列入种子队列
选取一个点,以eps为半径,画一个圈,看圈内有几个临近点,临近点个数如果大于某个阈值min_points, 则认为该点为某一簇的点;如果小于 min_points,则被标记为噪声点。
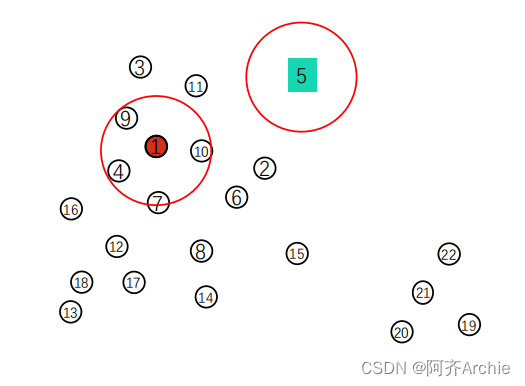
如下图,选择点1为圆心画圈,这种画圈和数数的过程实际上就是求1点的密度了,如果圈内的点足够多则1这个点的密度就足够大。下图中点1的临近点为点4,7,9,10。将点1的临近点作为种子点: seeds = [
4
,7,9,10]
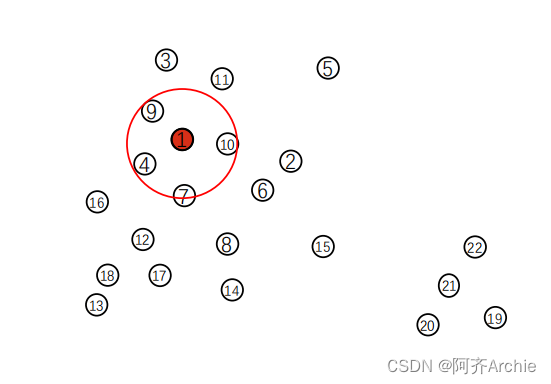
如下图中点5就是噪声点
(2)依次遍历所有种子点
1.遍历所有种子点,如果该点被标为
噪声点
,则重标为
聚类点 ;如果该点没有被标记过,则标记为
聚类点。如果该点已经被标记过了,则
不再遍历该点,跳过该点去处理下一个。
接下来以点4(聚类点)举例,其中min_points以3为举例,如下图中(红色)表示聚类点。
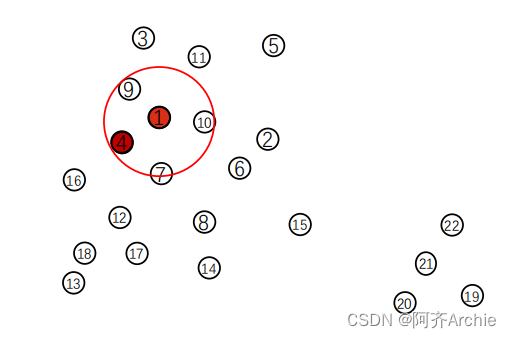
2.并且以聚类点点4为圆心,以eps为半径再次画一个圈。如果圈内点数大于min_points,将圈内点,添加到种子中seeds =
[
4
,7,9,10,1,7,9,16] (点4为圆心的圈中有临近点1,7,9,16)
过程:
- 首先标记点4为聚类点
- 然后画圈数临近点个数,判断临近点个数大于/小于min_points
- 临近点个数大于min_points则添加到种子队列
(3) 重复步骤2,直到遍历完所有的种子点
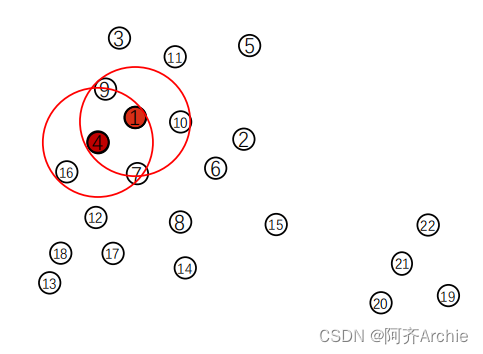
1.在上面步骤2中已经遍历完了4这个点,接下来遍历点7。
首先标记点7为聚类点(红色),seeds =
[
4
,
7
,9,10,1,7,9,16]
然后画圈数数,点7的周围有点12, 4 少于 min_points(以min_points=3举例),因此seed 不扩展
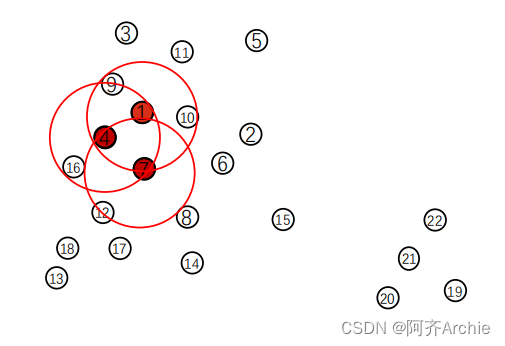
2.处理点9
首先标记点9为聚类点,seeds = [4,7,9,10,1,7,9,16]
然后以点9为中心画一个圈。点9周围有1,4,3三个数,min_points=3所以可以添加到种子队列里,添加1,4,3点,种子更新为seeds = [4,7,9,10,1,7,9,16,1,4,3]
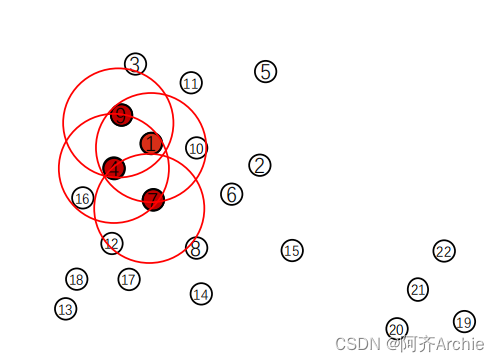
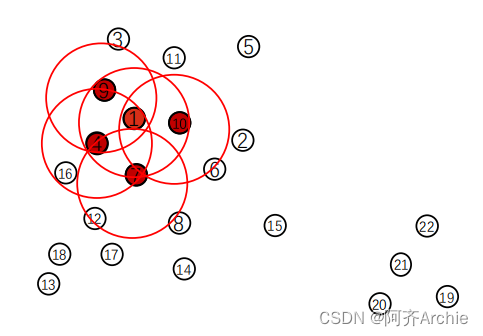
3.处理点10
首先标记点10为聚类点
然后画圈数数,点10的周围有点1,6,7
将点1,6,7添加到种子队列中,seeds =
[
4
,
7
,
9
,
10
,1,7,9,16,1,4,3,1,6,7]
4.继续顺序处理后面的点
1 已经标记过,继续下个点
seeds = [
4
,
7
,
9
,
10
,
1
,7,9,16,1,4,3,1,6,7]
7 已经标记过,继续下个点
seeds = [
4
,
7
,
9
,
10
,
1
,
7
,9,16,1,4,3,1,6,7]
9 已经标记过,继续下个点
seeds = [
4
,
7
,
9
,
10
,
1
,
7
,
9
,16,1,4,3,1,6,7]
16 周围点过少
seeds = [
4
,
7
,
9
,
10
,
1
,
7
,
9
,
16
,1,4,3,1,6,7]
......
......
依次类推,直到遍历完所有的种子点
(4) 标记完一簇后(红色的为一簇),寻找一个未被标记的点,开始新的一轮聚类
找到点5 ,周围点过少,标记为 NOISE噪声
找到点15, 周围点过少,标记为NOISE噪声
找到点 19 开始新的一轮聚类

最后,所有点标记完,聚类结束,形成了两蔟,红色一簇和蓝色一簇
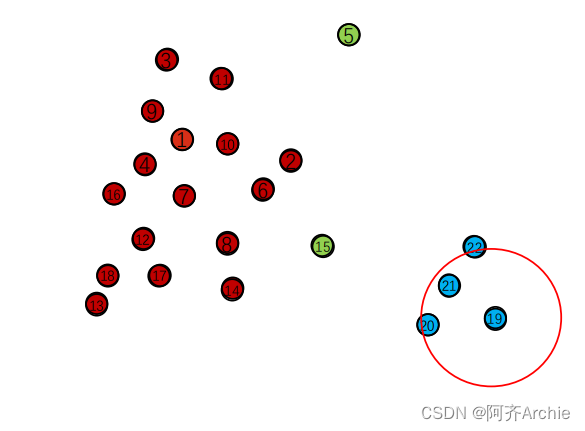
编程实现 源码下载
聚类效果:

源码下载地址:
https://download.csdn.net/download/m0_61712829/89103298![]() https://download.csdn.net/download/m0_61712829/89103298
https://download.csdn.net/download/m0_61712829/89103298
本资源包含本文聚类算法代码实现的源码,此外,还有数据分析综合课程设计,包含:SIR过程模拟与节点排序、用k-means和DBSCAN算法对银行数据进行聚类并完成用户画像、决策树与随机森林、基于奇异值分解的评分预测算法实现