"进程地址空间" = "虚拟地址空间" = "地址空间";
"进程内存" ≠ "虚拟内存";
32位系统虚拟地址空间为4GB,一般使用不完,用户和内核都使用不完;
前言:一个程序要执行,我们可以让他独享偌大的内存,它执行完了,再执行第二个程序....以此类推,总之,我们CPU找谁,我们就调谁进内存,但是存在两个问题:第一,一般程序没有那么大,实在是浪费硬件资源;第二:两个程序在硬盘与内存之间的切换实在是浪费时间,特别是磁盘,速度明显慢于内存;
我们可以让每个程序占用物理内存的一部分,我们划分好区域,但是存在安全问题:程序A对于B程序占用的空间由于运行错误,进行了错误的写操作,导致B程序运行错误。
那么现代OS是怎么做的?加了一层抽象:虚拟内存;

MMU(内存管理单元)负责虚拟地址->物理地址;
TLB则是为了加速翻译;
总之,有了它们俩,CPU可以通过虚拟地址找到物理地址;
其实我们平常代码中%p打印出来的这些全都是虚拟地址:
#include<unistd.h>
#include<iostream>
int global = 0;
int main()
{
pid_t id = fork();
if(id==0)
{
global = 190;
std::cout<<"Child-> "<<&id<<" "<<&global<<" "<<global<<std::endl;
}
else{
std::cout<<"father-> "<<&id<<" "<<&global<<" "<<global<<std::endl;
}
return 0;
}执行结果:
father-> 0x7fff33094fec 0x601194 0
Child-> 0x7fff33094fec 0x601194 190我们可以看到全局变量global初始值为0,父进程调用fork();系统调用创建子进程后,子进程对global做出了改变,打印出来确实也变了,但是地址竟然是一样的,同一块内存(如果是物理内存的话)不可能存在两种值;所以这个打印出来的地址是“假的”地址,是一种假象;
正是虚拟内存让程序各自拥有一个独立的空间(如下):

你的代码中的值根据其属性,存在不同区域,OS会建立上图这个进程地址空间和物理内存之间的一个映射;对于global这个变量,虚拟地址映射的其实是同一块物理地址,如果你仅仅是去读取global的值,它们找的是同一个地方,但如果子进程要对这个区域执行写操作,就会触发一个缺页异常,然后OS会拷贝这个区域并重新建立新的映射,然后恢复执行你的代码去修改它,这样也有好处:如果你不写的话,两份代码共用了内存,节省了空间;

每一个进程都有自己的虚拟地址空间,映射到物理内存;
每个进程都有自己的进程控制块(在Linux源码中是一个struct task_struct{};),用于OS更好地管理每个进程,它里面有一个mm_struct{};如下,它将虚拟内存分割为了我们上面图中的几块区域;而OS的页表建立起了它与物理内存之间的联系;
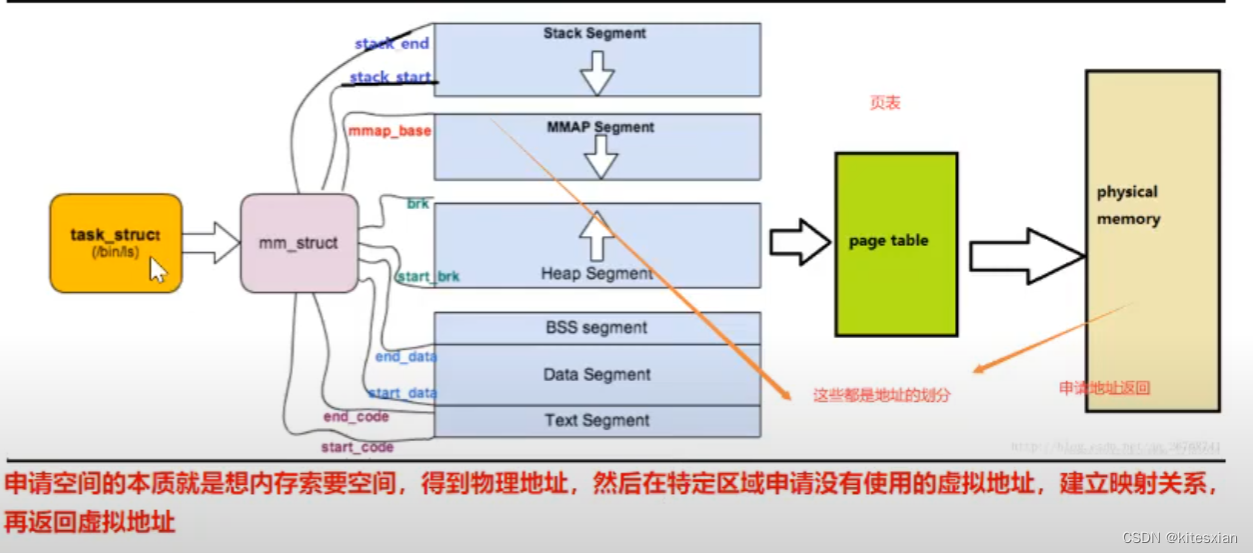
(图片来自:链接)
内存之后就是磁盘,这又涉及到换入和换出,分页分段....
我觉得我还是没有理解:virtual memory vs process address space .
大家可以看一下这个:链接