3.1 名词


属性分类
数据库实体属性分类主要包括以下几个方面:
-
标识属性 (Key Attribute / Identifier):
- 这些属性是用来唯一识别实体实例的关键属性,也称为主键(Primary Key)。在数据库表中,每个实体的实例(即一行记录)应当有一个或多个属性共同构成其唯一标识,不允许重复。例如,在顾客表中,顾客ID就是一个标识属性。
-
非标识属性 (Non-key Attribute / Non-Identifier):
- 这些属性不是用来唯一确定实体实例的属性,它们提供了关于实体实例其他方面的描述信息。例如,顾客表中的姓名、性别、出生日期、联系方式等都是非标识属性。
-
单一属性 (Simple Attribute):
- 单一属性只能取一个值,比如年龄、工资等。
-
复合属性 (Composite Attribute):
- 复合属性由多个子属性组成,这些子属性共同描述了一个整体概念。例如,地址可以是一个复合属性,包含街道、城市、省份、邮政编码等多个部分。
-
多值属性 (Multivalued Attribute):
- 在某些情况下,一个属性可以有多个值。在关系数据库中,这类属性通常通过关联表来实现,比如一个人有多部电话号码。
-
派生属性 (Derived Attribute):
- 派生属性的值可以根据其他属性的值计算得出,而不是直接存储在数据库中。例如,年龄可以从出生日期计算得到。
-
关联实体属性 (Relationship Attribute):
- 这类属性指向另一个实体或者实体集,表明两个实体之间的联系。在关系数据库中,这通常表现为外键(Foreign Key),比如在一个订单表中,客户ID就是一个关联实体属性,它链接到客户表的主键。
-
时间属性 (Temporal Attribute):
- 记录实体生命周期中的时间点或时间段的属性,如创建日期、更新日期、有效期等。
-
枚举属性 (Enumerated Attribute):
- 属性值仅能从预定义的一组选项中选取,如性别属性可能只有“男”、“女”和其他几个预设值。
结合以上分类,设计数据库时应该充分理解实体的属性,并根据实际需求合理安排属性的数据类型、是否允许为空、是否是索引列等特性。
考点:会区分各种码(候选码,主码,外码,全码)
3.2 关系代数
表达式:
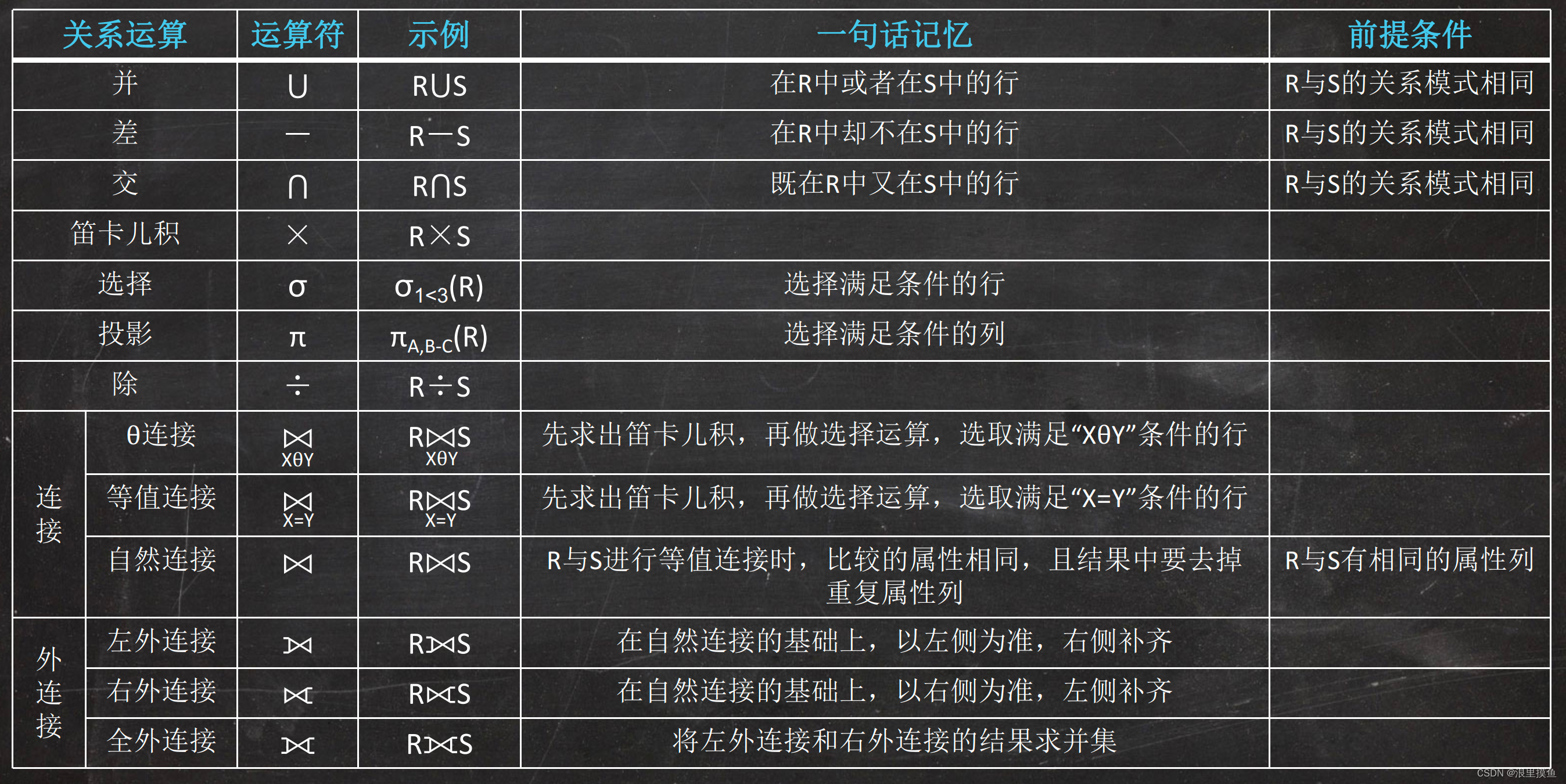
R在前S在后为例
1. 选择:根据选择条件获取列(sql中:where)。

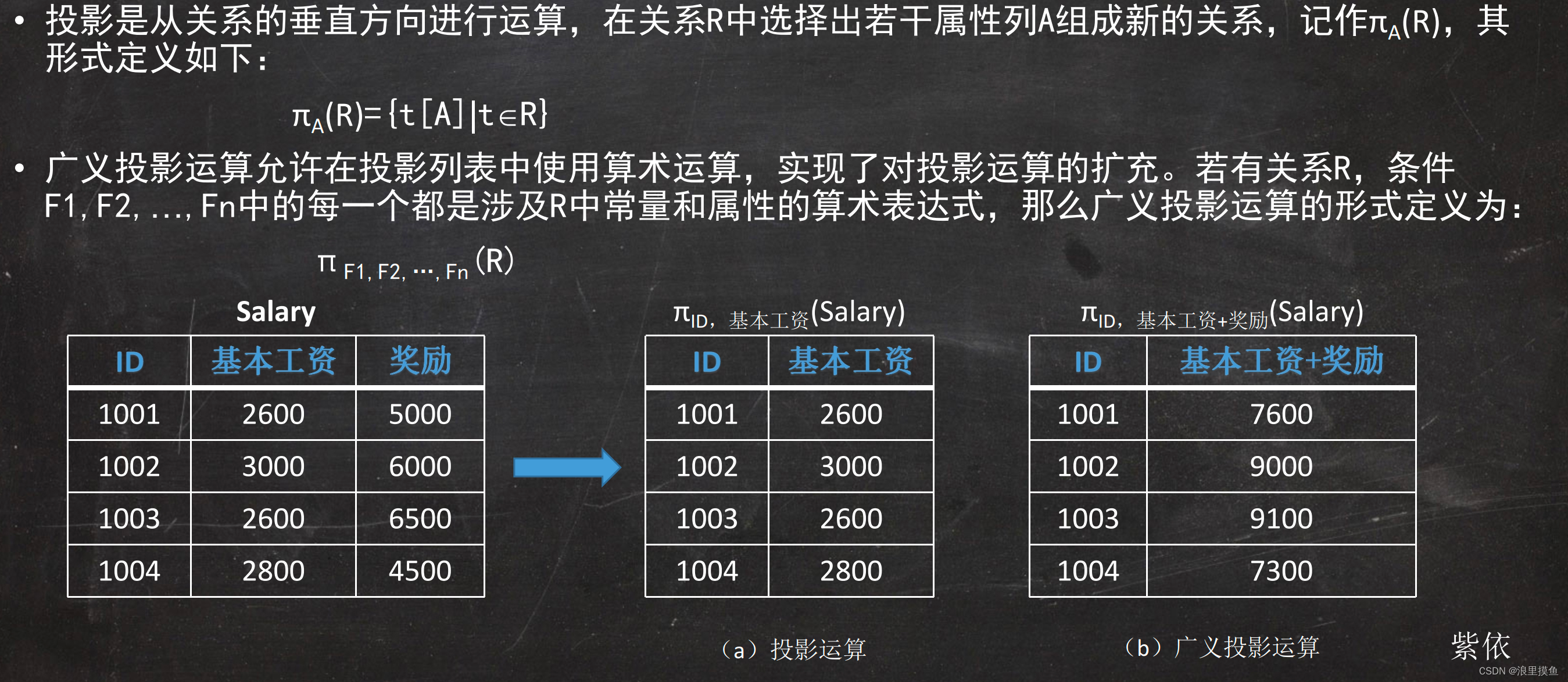
2. 投影
选择想要的列(类似于select),针对列进行计算。
3. 并
R与S 相同的合并,R与S 不同的元组放下面
4. 交
R与S 相同的合并,不同的不要
5. 差
R与S 相同的减掉,R不同的留着
6. 笛卡尔积
R表中的每一行都与S表中的每一行组合一次 R X S,select * form a,b

图片指路—写的非常易懂
7. 除
如果把笛卡尔积看作“乘法”运算,则除法运算可以看作这个“乘法”的逆运算。
R
÷
S
R÷S
R÷S
网上好多写步骤的真的好难懂,易懂图解指路
假设我们手里面有一张数据库如下:
现在我们有一个问题,就是我们想要找出学习最积极的那位学生,也就是选修了所有课程的那个学生,先暂时放弃除法运算,以我们最朴素的情感,用自己的逻辑来解决这道题目,按照自己的想法,就像设计一个程序一样,需要几步做出这个问题以下是按照我自己的想法:
首先,把SC表拆了,把每个学生单独做成一个表,如下:
然后问题就变成了拆开之后的表格和C表一一比对,找出拆开之后的三个表格中的Course属性和C表一模一样(也就是拆开之后包含了所有课程的表),然后找出那个人是谁,然后问题就解决了
实际上,我们的除法运算就是这个逻辑,但是除法运算的更为严谨,以下是除法运算的的步骤(SC ÷ C),这里我们仍然采用我们上面使用的数据库,直接说结论(SC ➗ C)能找出答案
第一步:找出C表中和SC表中相同的属性,也就是C属性,对C属性做投影操作(也就是找出总的课程有多少门)
第二步:找出SC表中和C表不相同的属性,也就是S属性,也对S属性做投影操作(找出一共有几个学生)
第三步:找出SC表中S的象集(每个学生分别都选了些什么课)
最后一步就是进行比对,只有张三的象集包含了所有C表中的所有课程,所以(SC ➗ C = 张三)




再来看一下步骤:
1.取S中和R相同的属性(投影),去重
2.找R中不同于S的属性,取不同的属性列,对该列进行去重
3. 求R中2中列对应的像集
4. 判断包含关系(哪个像集包含1中所有值)
8. 重命名
9. 连接
1. θ \theta θ 连接
笛卡尔积之后选择


2.等值连接

3. 自然连接
相同属性值值相同的留下,去掉重复属性。

10. 外连接
左连接(left join) 左侧为准右侧填充
右连接(right join)

3.3 元组演算
3.4 域演算
3.5 查询优化

3.6 关系规范化
这一章主要学习四大范式
第一范式
若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式