欢迎来到博主的专栏——c++编程
博主ID:代码小豪
文章目录
- 构造函数
- 默认构造函数
- 析构函数
- 默认析构函数
构造函数
以一个日期类为例。
class Data {
private:
int _year;
int _month;
int _day;
};
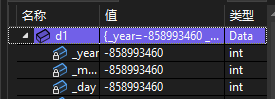
这个类实例化出来的对象内的值都是编译器默认初始化的随机值。
Data d1;//d1是Data类实例化出来的对象
如果我们想要将对象内部的值进行初始化,通常会使用以下两种方案。
方案1,设计一个初始化的成员函数。当对象创建后,调用这个初始化函数完成对象的初始化。
class Data {
public:
void DtatInit(int year=2024, int month=4, int day=13)//初始化成员变量的函数
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
当每个对象创建后,就调用这个初始化函数,完成对象的初始化。
Data d1;
Data d2;
d1.DtatInit();//初始化d1
d2.DtatInit(2004, 2, 14);//初始化d2
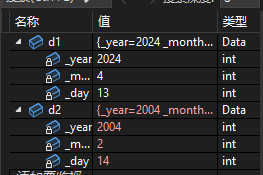
但是这种方法有一个缺点,对象的初始化需要依靠一个初始化的函数,这就会导致使用者偶尔会在创建对象之后忘记将这个对象初始化,导致程序崩溃。这是完全有可能的,因为编译器不会对对象没有初始化而报错,这就需要程序员花费精力去程序当中找寻出错的原因。而在多人合作编程的情况下,这种问题会越发显著。
因此c++推出类的构造函数,构造函数能在对象的创建时自动调用,构造函数有以下特点:
(1)函数名与类名相同
(2)无返回值
(3)对象实例化时自动调用构造函数
(4)构造函数可以重载
(5)构造函数不可以在对象创建之后调用
构造函数中的无返回值并不是函数返回类型为void,而是不使用任何返回类型作为函数的返回值。
还是以Data类为例。
构造函数的声明要符合函数名与类名相同,且无返回值。因此Data类构造函数如下:
class Data {
public:
Data(int year,int month,int day)//构造函数
{
_year = year;
_month = month;
_day = day;
}
Data()//构造函数的重载函数
{
_year = 2024;
_month = 4;
_day = 13;
}
private:
int _year;
int _month;
int _day;
};
由于构造函数支持重载,因此我们可以定义多种类型的构造函数。如上图,其中一个构造函数有参数,另一个构造函数没有参数,没有参数的构造函数是对象创建时默认调用的构造函数。使用方式如下:
Data d1(2004,2,14);//自动调用有参数的构造函数
Data d2;//自动调用无参数的构造函数
此时Data类的两个对象会按照设定的构造函数形式进行初始化。
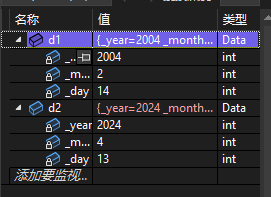
d1调用的有参的构造函数,参数为year=2004,month=2,day=14.因此d1的初始化结构如下,而d2调用的无参构造函数,若是调用无参的构造函数,不能加上"()",否则报错。
构造函数还可以使用缺省形式,如:
class Data {
public:
Data(int year=2024,int month=4,int day=13)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
这样会更加灵活。
默认构造函数
无论用户有没写构造函数,在创建对象时,编译器都会自动调用构造函数。这么一说大家可能觉得有点匪夷所思,毕竟有些类是没有写构造函数的,如果没写构造函数也要调用的话,为什么编译器不报错呢?
这是因为编译器在用户没有创建构造函数时,会自动生成一个构造函数,编译器生成的构造函数规则如下:
(1)类中的内置类型成员默认初始化
(2)类中的自定义类型调用其默认构造函数
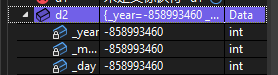
类中的内置成员(如int,double,char)的初始化根据不同的编译器会初始化成不同的值,这是由于c++标准并没有规定生成的构造函数将内置类型初始化的标准值,因此初始化的结果由编译器的创作者决定。比如vs2022中的内置类型的默认初始化的值是一个随机值:
类中的自定义类型调用的则是默认构造函数,那么什么是默认构造函数呢?
默认构造函数,即创建对象对象时可以无参调用的构造函数。
Data d2;//自动调用无参数的构造函数
那么什么样的构造函数能够满足无参调用呢?
(1)无参数的构造函数
(2)全缺省的构造函数
(3)编译器生成的构造函数
以上三种构造函数都是默认构造函数。
如果函数有无参的构造函数或者全缺省的构造函数(类中只能存在无参构造函数与全缺省构造函数其中之一),那么编译器就不会生成构造函数,反之,若是类中没有定义无参构造函数和全缺省构造函数,则会调用编译器生成的构造函数。
既然使用编译器的构造函数会导致成员随机值,那么这个自动生成的构造函数很鸡肋啊。无论编译器有没有生成构造函数,自定义类型的成员值都是随机值,那么这个构造函数的作用是什么呢?
我们将目光转移到编译器生成的构造函数的第二条特性上
(2)类中的自定义类型调用其默认构造函数
类中的成员可以是其他类的对象、结构体、联合体等自定义类型的数据。那么初始化他们则不是随机值,而是调用这些自定义类型的默认构造函数。
比如在Data类中,新增一个Time类,这个Time类用来记录时分秒。
class Time {
public:
Time(int hour=22,int min=37,int second=58)//Time的默认构造函数
{
_hour = hour;
_min = min;
_second = second;
}
private:
int _hour;
int _min;
int _second;
};
class Data {
private:
int _year;
int _month;
int _day;
Time t;
};
此时若是创建一个Data类型的对象,就能发现对象当中t的值被Time类中的构造函数初始化了。
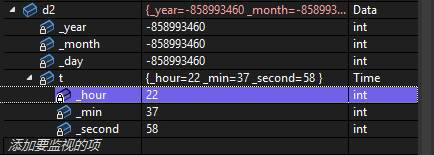
所以这里可以得出编译器生成的构造函数的主要作用是为了初始化类中的自定义类型,而内置类型的初始化需要自己定义一个默认构造函数,这样子当别的类包含其他类时,能将其他类一起初始化。
注意这个过程是可以嵌套的,比如类a包含类b,类b包含类c,那么创建a对象时,调用b的默认构造函数,b中又会调用c的默认构造函数。
析构函数
析构函数的作用与构造函数的作用相反,相反的点体现在以下方面:
(1)调用的时机不同:析构函数在对象销毁之后自动调用
(2)调用的目的不同:构造函数的目的是在对象创建时进行初始化,而析构函数的目的是在对象离开生命周期准备销毁时,将对象中的资源进行释放。
析构函数的特性如下:
- 析构函数名是在类名前加上字符 ~。
- 无参数无返回值类型。
- 一个类只能有一个析构函数。若未显式定义,系统会自动生成默认的析构函数。注意:析构 函数不能重载
- 对象生命周期结束时,C++编译系统系统自动调用析构函数
析构函数的命名方式很巧妙,既然析构函数是构造函数的相反面,那么析构函数的命名规则就是在构造函数的基础之上加个取反符(~),寓意析构函数的性质与构造函数相反。
以栈类stack为例。他的析构函数如下:
typedef int STDataType;
class stack {
public:
stack(int capacity = 4)//栈的默认构造函数
{
_stack = (STDataType*)malloc(sizeof(STDataType) * capacity);
_capacity = capacity;
_top = 0;
}
~stack()//栈的析构函数
{
free(_stack);
_top = 0;
_stack = NULL;
_capacity = 0;
}
private:
STDataType* _stack;
int _top;
int _capacity;
};
不是什么类都需要析构函数的,若是类中没有动态内存开辟出来资源空间需要清理,那么这个类不需要写一个析构函数了。在stack类中,成员变量_stack中的空间是malloc出来的动态内存,这个空间是需要释放的,否则会导致内存泄漏(这里的知识涉及C语言的动态内存分配)。
因此我们可以设置一个析构函数用来及时释放空间
默认析构函数
事实上析构函数大部分情况下都使用不上参数,编译器在类中没有析构函数时,也会生成一个析构函数,编译器的析构函数不对内置类型成员产生作用(任意的指针类型都是内置类型),只会调用自定义成员调用其析构函数。
比如现在有一个嵌套stack类的类_stack.
class _stack
{
private:
int i;
stack s1;
};
_stack类没有设置析构函数,因此当_stack类的对象销毁时,会调用编译器生成的析构函数,而编译器生成的析构函数的作用是调用s1的默认析构函数,因此在_stack类的对象销毁时,会调用s1的默认析构函数,将s1中的空间也进行销毁。
总结:构造函数和析构函数的目的都是为了减少对象初始化,以及对象开辟的资源没有及时清理带来的麻烦。
构造函数会在对象创建之处完成成员变量的初始化,而对嵌套对象调用其构造函数又能对嵌套的对象完成初始化,以此类推,减少了初始化不正确带来的麻烦。
而析构函数也会在对象即将销毁时调用,减少了内存泄漏出现的次数