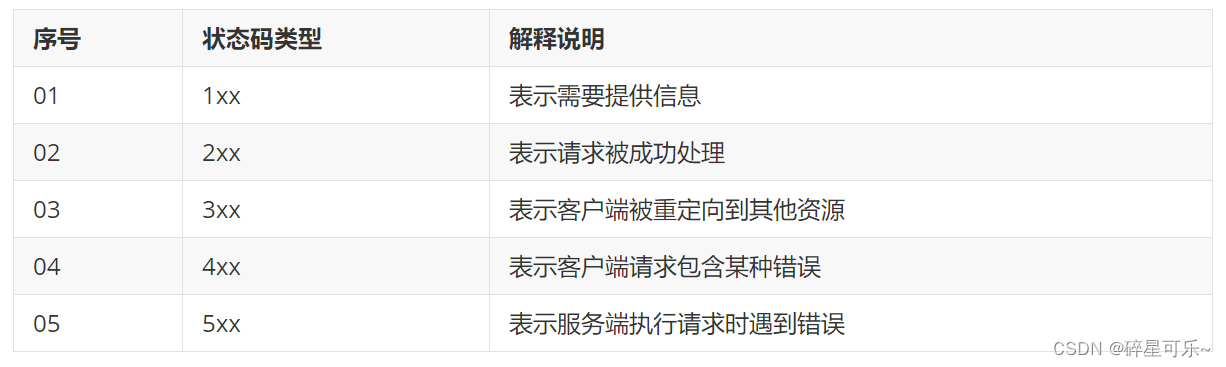
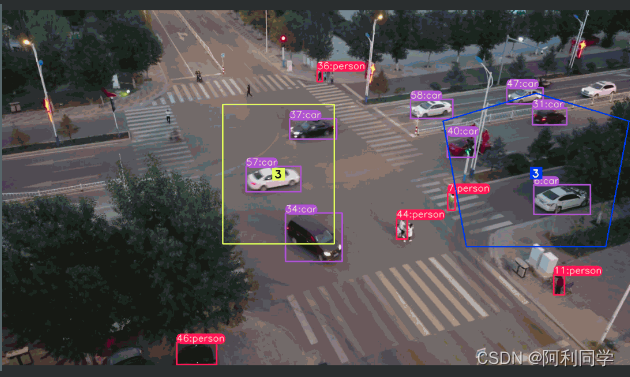
由于数据工程、仿真测试工程,咱们不得不进入AIGC图片视频生成领域。兜兜转转,这一篇与智驾场景特别密切。23年4月,英伟达Nvidia联合几所大学发布了带文本条件融合、时空注意力的Video Latent Diffusion Models。提出一种基于LDM的高分辨率视频合成方法,通过在压缩的低维潜空间训练扩散模型,实现高质量图像合成并避免过多的计算需求,可用于生成高分辨率且时间连贯的驾驶场景视频,并能够将文本转化为视频进行创意内容创作。
内容相当硬核,主要贡献有:
- 长约 5 分钟高分辨率、时间连贯的驾驶场景视频生成(约1年后发布的Sora,60秒)。
- 个性化文本到创意视频内容生成的首次实现。
Video Latent Diffusion Models 堆栈:
- 将图像LDM转换成视频生成器。在图像LDM的潜在空间中引入时间维度,并在编码的图像序列上训练这些时间层,同时固定空间层。具体来说利用预先训练或者现有图像LDM,首先生成高质量关键帧,在渲染成T个连续帧的视频时对样本进行时间对齐,最后形成连贯的视频。
- 改造为预测模型以生成较长视频。按照预测模型prediction models的方式训练模型,即给定S个context frames,预测T − S帧。在推理过程中,为了生成长视频,迭代应用采样过程,重用最新预测作为新的上下文。
- 实现高帧率。使用相同的插值模型分两步进行时间插值实现高帧率。
- 生成超分辨率的长视频。进一步视频微调video fine-tune公开可用的潜在稳定扩散上采样器latent Stable Diffusion upsampler,从而实现4×放大,形成时序一致的超分视频(可选)。
主要优势:
-
该方法在驾驶场景、创意内容生成两个实际应用场景中取得了优秀的性能,并且可以将公开的、先进的文本到图像Stable Diffusion转化为文本到视频潜在扩散模型Video LDM。
论文名称:Align your Latents:High-Resolution Video Synthesis with Latent Diffusion Models.
论文地址:https://arxiv.org/abs/2304.08818
项目地址:Align your Latents (nvidia.com)
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
Abstract
潜在扩散模型Latent Diffusion Models,LDM通过在压缩的低维潜在空间中训练扩散模型,实现了高质量图像合成,同时避免过多计算需求。在这里,我们将LDM范式应用于高分辨率视频生成,这是一个特别资源密集型的任务。我们首先只在图像上预先训练LDM;然后,我们通过在潜在空间扩散模型中引入时间维度并对编码图像序列(即视频)进行微调,将图像生成器转换为视频生成器。类似的,我们在时间上对齐扩散模型上采样器,将它们转换为时间一致的视频超分辨率模型。我们专注于两个相关的实际应用:通过文本到视频建模模拟野外驾驶数据和创意内容创作。特别是,我们在分辨率为 512 × 1024 的真实驾驶视频上验证了我们的视频潜在扩散模型Video LDM,实现了最先进的性能。此外,我们的方法可以轻松利用现成的预训练图像 LDM,因为在这种情况下我们只需要训练一个时间对齐模型。这样做,我们将公开可用的、最先进的文生图Stable Diffusion转化为高效和富有表现力的文生视频模型,分辨率为1280 × 2048。我们表明,以这种方式训练的时间层可以推广到不同的文本到图像LDM。利用这一特性,我们展示了个性化文本到视频生成的第一个结果,为未来内容创建开辟了令人兴奋的方向。
1. Introduction
由于底层建模技术的最新突破,图像生成模型受到了前所未有的关注。当今最强大的模型建立在生成对抗网络、自回归transformer和最近的扩散模型上。扩散模型DMs特别具有理想的优势;它们提供了一个健壮且可扩展的训练目标,并且通常比基于transformer的同类产品参数密集度更低。然而,虽然在图像域取得了很大进展,但视频建模却落后了——主要是由于与视频数据训练相关的计算成本巨大,以及缺乏大规模、通用和公开可用的视频数据集。虽然有大量关于视频生成的文献
- Stochastic variational video prediction.
- Generating long videos of dynamic scenes.
- Stochastic video generation with a learned prior.
- Stochastic latent residual video prediction.
- Long video generation with time-agnostic vqgan and timesensitive transformer.
- Cogvideo: Large-scale pretraining for textto-video generation via transformers.
- Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2
- A good image generator is what you need for high-resolution video synthesis.
- Decomposing motion and content for natural video sequence prediction.
- Generating videos with scene dynamics.
- Scaling autoregressive video models.
- Godiva: Generating open-domain videos from natural descriptions.
- Visual synthesis pretraining for neural visual world creation.
- Videogpt: Video generation using vq-vae and transformers.
- Generating videos with dynamics-aware implicit generative adversarial networks.
但大多数作品,包括以前的视频DM,只生成相对较低的分辨率,通常是短的视频。
- Flexible diffusion modeling of long videos.
- Video diffusion models.
- Diffusion models for video prediction and infilling.
- Masked Conditional Video Diffusion for Prediction, Generation, and lnterpolation.
- Diffusion Probabilistic Modeling for Video Generation.
在这里,我们将视频模型应用于现实世界的问题并生成高分辨率、长的视频。具体来说,我们关注两个相关的真实世界视频生成问题:
- 高分辨率实时驾驶数据的视频生成,这在自动驾驶的背景下作为模拟引擎具有很大的潜力。
- 用于创意内容生成的文本引导视频合成。

为此,我们在潜在扩散模型基础上,在高分辨率图像上进行训练时,可以减少沉重的计算负担。我们提出了视频潜在扩散模型Video LDM,并将LDM扩展到高分辨率视频生成,这是一个计算特别密集型的任务。与之前用于视频生成的 DM 的工作相比,我们首先在像素上预训练我们的 Video LDM(或使用可用的预训练图像 LDM),从而允许我们利用大规模图像数据集。然后我们将LDM图像生成器转换为视频生成器,在潜在空间 DM 中引入时间维度,并在编码的图像序列(即视频(图 2)上训练这些时间层,同时固定预训练的空间层。
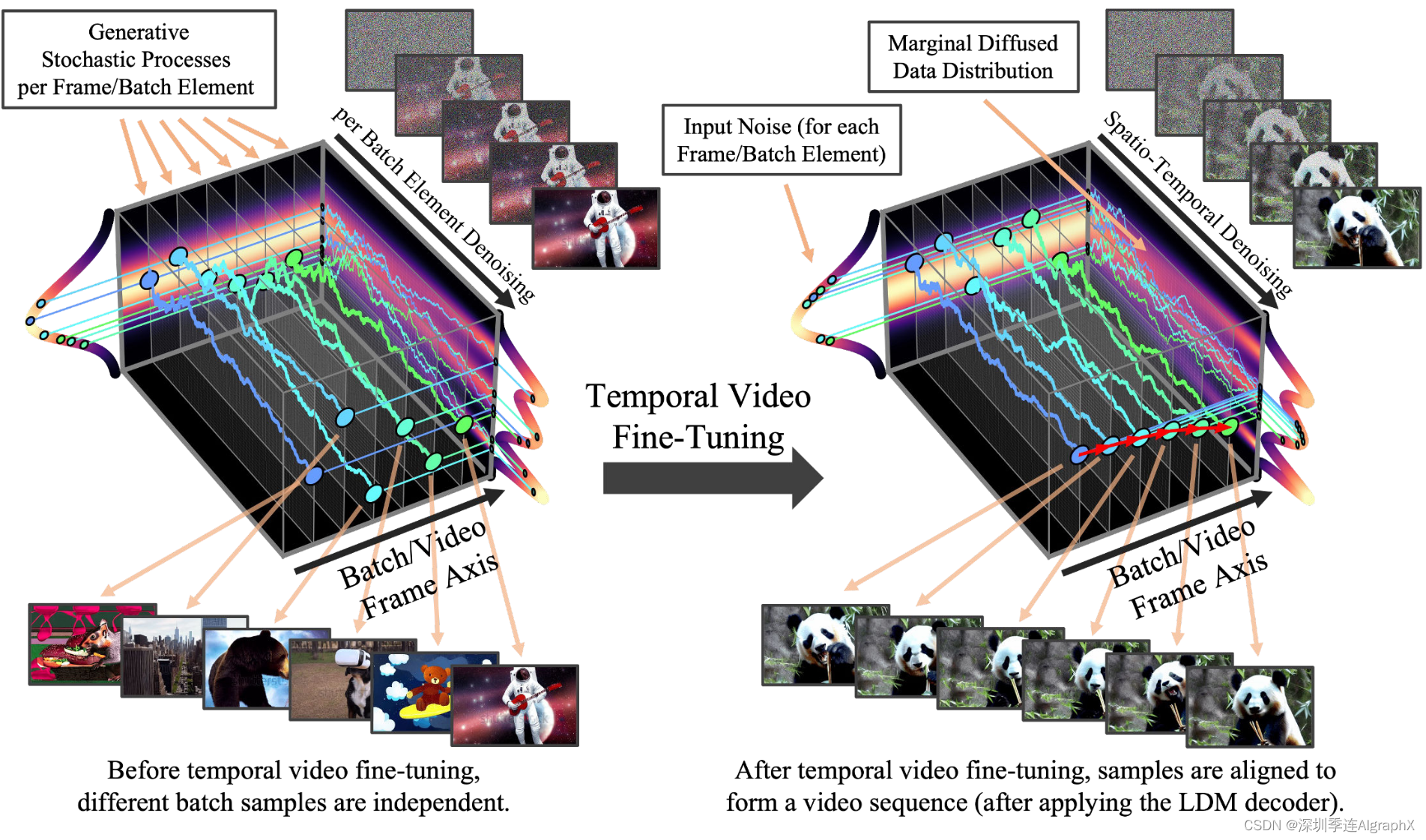
Figure 2.Temporal Video Fine-Tuning.我们将预先训练的图像扩散模型转化为时间一致的视频生成器。最初,由模型合成的同一批次不同图像是独立的。在时间视频微调之后,对样本进行时间对齐并形成连贯视频。对于一维扩散模型,微调之前后的随机生成过程是可视化的。为了清晰起见,该图对应于像素空间中的对齐。在实践中,我们在LDM潜在空间中进行对准,并应用LDM解码器后获得视频(见图3)。我们还在像素或潜在空间中对扩散模型上采样器进行视频微调。
我们同样微调LDM的解码器,以实现像素空间中的时间一致性(图3)。
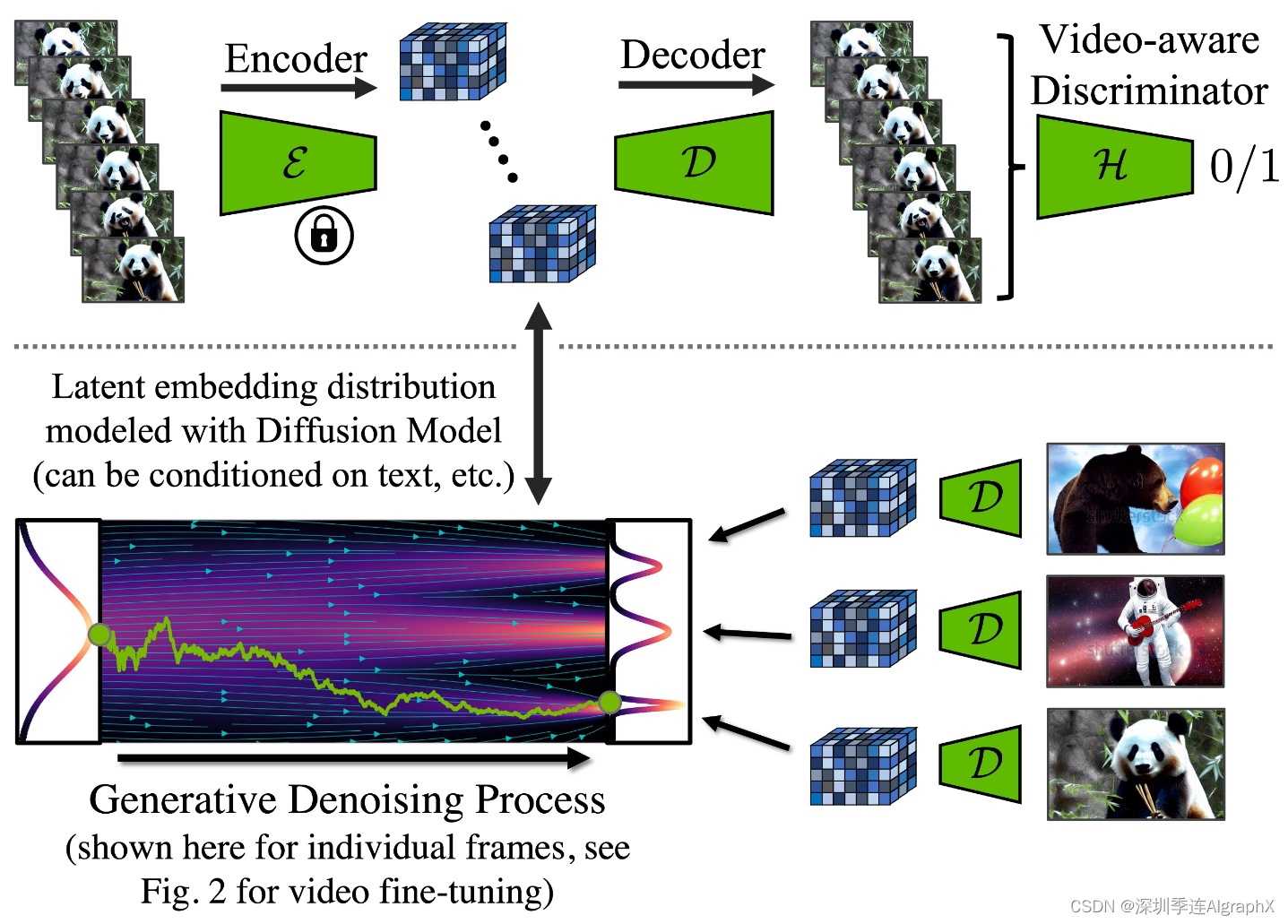
图 3。顶部:在时间解码器微调期间,我们使用冻结编码器单独处理视频序列,并在帧之间执行时间重建。我们还使用了一个视频识别鉴别器。底部:在LDM中,扩散模型在潜在空间中训练。它合成潜在特征,然后通过解码器将其转换为图像。请注意,底部可视化是针对单个帧的;参见图2,实践中,对整个视频进行建模,并通过视频微调潜在扩散模型,以生成时间上一致的帧序列。
备注:将原本文生图的VAE扩展,在解码器部分也加入时序层,在视频数据上微调,使用对抗损失训练,VAE作为生成器,用一个3D卷积构成patch-wise判别器。
为了进一步增强空间分辨率,我们还在时间上对齐像素空间和潜在DM上采样器,广泛用于图像超分辨率,将它们转换为时间一致的视频超分辨率模型。在LDM的基础上,我们的方法可以以计算和内存有效的方式生成全局连贯和长的视频。对于以非常高的分辨率生成,视频上采样器只需要在本地操作,保持训练和计算需求低。消融方法在 512 × 1024 的真实驾驶场景视频上进行测试,实现了最先进的视频质量,并生成几分钟长度的视频。我们还视频微调了一个强大、公开可用的文本到图像Stable Diffusion,并将其转化为一个高效、功能强大的文本到视频生成器,分辨率为1280 × 2048。由于在这种情况下我们只需要训练时间对齐层,我们可以使用相对较小的字幕视频训练集。通过将训练好的时间层转移到不同的微调文本到图像LDM中,我们首次展示了个性化的文本到视频生成。我们希望我们的工作为高效的数字内容创建和自动驾驶模拟开辟了新的途径。
Contributions
- 我们提出了一种有效的方法来训练基于LDM的高分辨率、长期一致的视频生成模型。我们的关键见解是利用预先训练的图像扩散模型,并通过插入学习以时间一致的方式对齐图像的时间层,将它们转换为视频生成器(图2和图3)。
- 进一步对文献中普遍存在的超分辨率扩散模型进行了时间微调。
- 在真实的驾驶场景视频上实现了最先进的高分辨率视频生成,可以生成分钟级长视频。
- 将公开可用的稳定扩散文本到图像LDM转换为强大且富有表现力的文本到视频LDM。
- 学习到的时间层可以与不同的图像模型权重(例如,DreamBooth)相结合。
2. Background
详细扩散模型、潜在扩散模型内容,请参见以下内容。
51-33 LDM 潜在扩散模型-CSDN博客
51-36 DiT,视频生成模型Sora背后的核心技术
51-37 由浅入深理解 Stable Diffusion 3-CSDN博客
3. Latent Video Diffusion Models

3.1. Turning Latent Image into Video Generators
我们有效训练视频生成模型的关键见解是重用预训练的固定图像生成模型;一个由 θ 参数化的 LDM。形式上,将包含图像LDM和处理像素维度上输入的神经网络层表示为空间层spatial layers Li/θ,i 为层索引layer index。然而,尽管这样的模型能够以高质量的合成单个帧,但直接使用它渲染 T 个连续帧的视频将失败,因为模型没有时间意识temporal awareness。因此,我们引入了额外的时间神经网络层 temporal neural network layers Li/φ,它们与现有的空间层 Li/θ 交错,并学习以时间一致方式对齐单个帧。

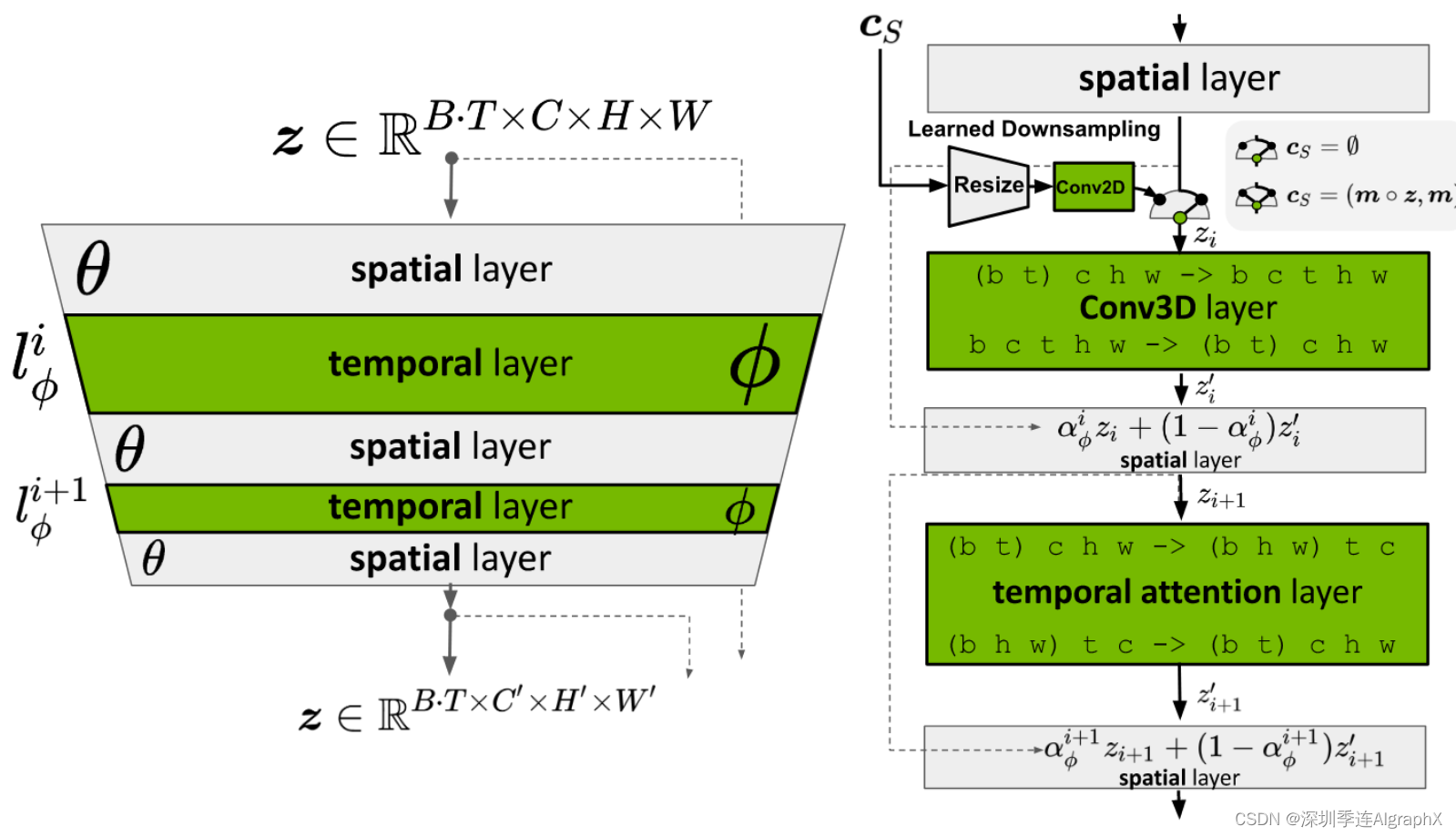
图4。左图:我们通过插入时间层将预先训练的LDM转化为视频生成器,时间层学习将帧对齐到时间一致的序列中。在优化过程中,图像主干θ保持固定,并且仅训练时间层Li/φ的参数φ,参考方程2。右图:在训练过程中,基本模型θ将长度为T的输入序列解释为一批图像。对于时间层Li/φ,这些批次被重整形为视频格式。它们的输出z′与空间输出z相结合,使用可学习的融合参数α。在推理过程中,跳过时间层(αi/φ=1)产生原始图像模型。为方便展示,只显示了一个U-Net块。B 表示批量大小,T 序列长度,C 个输入通道,H和W表示输入的空间维度。当训练预测模型时,cS是可选的上下文条件。
我们从逐帧编码输入视频 开始。空间层将视频解释为一批独立的图像(通过将时间轴变换到批处理维度),对于每个时间混合层Li/φ,我们重整reshape回视频维度如下(使用einops notation):

为了清楚起见,我们添加了批次维度 b。换句话说,空间层在批次维度 b 中独立处理所有 B·T 编码视频帧,而时间层 Li/φ(z′, c) 在新时间维度 t 中处理整个视频。此外,c 是(可选)条件信息,例如文本提示。
在每个时间层之后,输出 z' 与 z 特征融合为 ![]() ; αi/φ ∈[0, 1] 表示一个可学习的参数(参见附录 D)。
; αi/φ ∈[0, 1] 表示一个可学习的参数(参见附录 D)。
备注:每个temporal layer输出后都需要和temporal layer前的特征进行融合。
在实践中,我们实现了两种不同类型的时间混合层:
- 时间注意力 temporal attention
- 基于 3D 卷积的残差块 residual blocks based on 3D convolutions
参见图4,使用正弦嵌入作为时间的位置编码。
然后,我们使用与底层图像模型相同的噪声调度来训练视频感知时间主干video-aware temporal backbone,重要的是,我们固定空间层Li/θ,只训练优化时间层Li/φ,
![]()
其中 zτ 表示扩散编码 z = (x)。这样,我们通过简单地跳过时间块来保留原生图像生成能力,例如通过为每一层设置 αi/φ = 1。
备注:如果αi/φ设置为1,就是原本的图像生成LDM。
我们策略的一个关键优势是可以使用巨大的图像数据集对空间层进行预训练,而通常没有广泛可用的视频数据用于时间层训练。
Temporal Autoencoder Finetuning
我们的视频模型建立在预先训练的图像LDM之上。虽然这提高了效率,但LDM的自动编码器只在图像上进行训练,在编码和解码时间连贯的图像序列时会导致闪烁伪影flickering artifacts。
为了解决这个问题,我们为自动编码器autoencoder的解码器decoder引入了额外的时间层temporal layers,固定住encoder,使用从 3D 卷积构建的时间鉴别器对视频数据进行微调,参见图3。
注意,编码器与图像训练保持不变,这样就可以重用编码视频帧潜在空间中运行的图像DM。如表 3 中的重建 FVD 分数所示,这一步对于获得良好的结果至关重要。

3.2. Prediction Models for Long-Term Generation
尽管第3.1节中描述的方法在生成短视频序列方面是有效的,但在合成非常长的视频时,它有其局限性。因此,我们按照prediction models的方式训练模型,给定S个context frames,预测T − S frames,其中T是全部frames的长度。我们通过引入一个时间二进制掩码 mS 来实现这一点,该掩码掩盖了模型必须预测的 T - S 帧。我们将此掩码和掩码编码后的视频帧输入模型以进行调节。
具体来说,使用LDM的图像编码器 进行编码,乘以掩码,然后通过学习的下采样操作处理后,(通道与掩码连接)输入到时间层Li/φ中,如图4所示。设cS = (mS◦z, mS)表示掩码和masked图像拼接的空间条件。Loss如下,
备注:encoder后的图像特征先和mS相乘后,然后和mS concat在一起组成cS = (mS◦z, mS),经过一个learned downsampling输入到temporal layer。其中cS作为作为条件输入。
![]()
其中 pS 表示(分类)掩码采样分布。在实践中,我们学习了以 0、1 或 2 个上下文帧为条件的预测模型,允许如下所述的无分类器指导。
在推理过程中,为了生成长视频,我们可以迭代地应用采样过程,重用最新的预测作为新上下文。第一个初始序列是通过从基本图像扩散模型生成单个上下文帧,然后根据该帧生成序列来生成的;之后,我们以两个上下文帧为条件来编码(详见附录)。为了稳定这一过程,我们发现使用无分类器扩散引导是有益的,我们在采样过程中引导模型
![]()
其中 s≥1 表示引导尺度,我们删除了 τ 和其他信息 c 的显式条件以提高可读性。我们将此指导称为上下文指导。
3.3. Temporal Interpolation for High Frame Rates
高分辨率视频不仅具有高空间分辨率的特点,而且具有高时间分辨率,即高帧率。为此,我们将高分辨率视频的生成过程分为两部分:第一个是第 3.1 节和第 3.2 节中描述的过程,它可以生成语义变化较大的关键帧,但(由于内存限制)仅在相对较低的帧速率下。对于第二部分,我们引入了一个额外的模型,其任务是在给定的关键帧之间进行插值。为了实现这一点,我们使用了3.2 节中引入的掩蔽条件机制。然而,与预测不同,我们现在屏蔽要插值的帧——否则,该机制保持不变,即图像模型被细化为视频插值模型。在我们的实验中,我们在两个给定的关键帧之间预测三个帧,从而训练一个 T → 4T 插值模型。为了实现更大的帧速率,我们在 T → 4T 和 4T → 16T 机制(使用具有不同 fps 的视频)中同时训练模型,由二元条件指定。我们的预测和插值模型的训练方法受到最近的工作启发,这些工作使用类似的掩蔽技术(另见附录 C)。
- Flexible diffusion modeling of long videos.
- Diffusion models for video prediction and infilling.
- Masked Conditional Video Diffusion for Prediction, Generation, and lnterpolation.
备注:为了实现高帧率,首先生成稀疏的关键帧。然后,使用相同的插值模型分两步进行时间插值,以实现高帧率。
3.4. Temporal Fine-tuning of SR Models
尽管LDM机制已经提供了良好的原始分辨率,但我们的目标是将其推向百万像素范围。我们从级联扩散模型Cascaded DM,CDM中汲取灵感,并使用 DM 进一步将 Video LDM 输出放大 4 倍。对于我们的驾驶视频合成实验,我们使用像素空间 DM(第 4.1 节)并缩放到 512 × 1024;对于我们的文本到视频模型,我们使用 LDM 上采样器(第 4.2 节)并缩放到 1280 × 2048。我们使用噪声水平条件的噪声增强并训练超分辨率 (SR) 模型 gθ,φ(在图像或潜伏期上)。损失函数变为:
![]()
其中, ![]() , 表示通过concatenation提供给模型的低分辨率噪声图像。
, 表示通过concatenation提供给模型的低分辨率噪声图像。
τγ 是噪声调度 ατ , στ 之后添加到低分辨率图像中的噪声量。
由于独立上采样视频帧会导致时间一致性较差,我们还使该 SR 模型具有视频感知能力。我们遵循 3.1 节中介绍具有空间层Li/θ和时间层Li/φ的机制,类似地视频微调upscaler,以长度为T的低分辨率序列为条件,逐帧连接低分辨率视频图像。由于upscaler在本地运行,我们只在patch上高效地进行所有训练,然后进行卷积应用到模型。
总体而言,我们认为 LDM 与上采样器 DM 的组合是高效高分辨率视频合成的理想选择。一方面,我们的Video LDM的主要LDM组件利用计算效率高的压缩潜在空间来执行所有视频建模。这允许我们使用大批量并联合编码更多的视频帧,这有利于长期视频建模,而不需要过多的内存需求,因为所有的视频预测和插值都是在潜在空间中进行的。另一方面,上采样器可以以高效的patch方式进行训练,因此同样节省计算资源并减少内存消耗,并且由于低分辨率条件,它也不需要捕获长期时间相关性。因此,该组件不需要预测和插值框架。
备注:为了实现高分辨率生成,我们进一步利用空间扩散模型上采样器,并对它们进行时间对齐,以进行视频上采样。
4. Experiments
Datasets
由于我们专注于驾驶场景视频生成和文生视频,我们使用两个相应的数据集/模型:
(i)真实驾驶场景(RDS)视频的内部数据集。该数据集由683,060个视频组成,每个视频分辨率为512 × 1024 (H × W),帧率高达30帧/秒。此外,视频具有二进制夜间/白天标签、场景中汽车数量的注释(“拥挤”),数据的一个子集也有汽车边界框。
(ii)我们使用WebVid-10M数据集将公开可用的稳定扩散图像LDM转换为视频LDM。WebVid-10M 由 10.7M 视频字幕对组成,共有 52K 视频小时。我们将视频的大小调整为320 × 512。
(iii)此外,我们展示了在Mountain Biking dataset数据集的实验。
Evaluation Metrics
为了评估我们的模型,我们使用FID和Fŕechet Video Distance,FVD。由于FVD是不可靠的,我们还进行了人工评估。对于我们的文本到视频实验,我们还评估了CLIP相似度(CLIPSIM)和 Video Inception Score (IS)。
Model Architectures and Sampling
我们的图像LDM基于Stable Diffusion。他们使用卷积编码器和解码器,它们的潜在空间 DM 架构建立在 U-Net 之上。 我们的像素空间上采样器 DM 使用相同的图像 DM 主干 。在所有实验中,使用DDIM进行DM采样。进一步的架构、训练、评估、采样和数据集细节可以在附录中找到。
4.1. High-Resolution Driving Video Synthesis
我们在真实的驾驶场景RDS数据上训练我们的视频LDM,包括一个4×像素空间视频上采样器。我们以白天/黑夜标签和拥挤为条件,并在训练期间随机丢弃这些标签以允许无分类器的指导和无条件合成(我们在这里不以边界框为条件)。按照上面提出的训练策略,我们首先在视频帧上独立训练图像主干LDM(空间层),然后我们在视频上训练时间层。我们还在 RDS 数据上训练 Long Video GAN (LVG) 用作主要基线,这是之前在长高分辨率视频生成最新技术。表1(左)显示了我们在128×256分辨率下没有上采样器,视频LDM主要结果。我们展示了我们的模型在拥挤和白天/黑夜之间有和没有条件的情况下的性能。我们的视频LDM通常优于LVG,添加条件进一步减少了FVD。

表 2 显示了我们人工评估:我们的样本在真实性方面通常优于 LVG,并且来自我们的条件模型的样本也比无条件样本更受欢迎。

接下来,我们将video fine-tuned pixel-space upsampler与独立的frame-wise image upsampler(表3)进行比较,使用128 × 256 30帧/秒的ground truth视频作为条件。我们发现上采样器的时间对齐对于高性能至关重要。如果视频帧是独立上采样的,FVD会显著下降,这表明时间一致性的丧失。正如预期的那样,FID 基本上不受影响,因为当独立上采样时,各个帧仍然具有高质量。在图 1(底部)和图 7(顶部)中,我们展示了组合视频 LDM 和视频上采样器模型的条件样本。我们观察到高质量的视频。

此外,使用本文预测方法,可以生成非常长的、时间连贯的高分辨率驾驶视频。我们对此进行了长达 5 分钟的验证;有关结果,请参见附录和补充视频。
4.1.1 Ablation Studies
为了显示设计选择的有效性(第 3 节),我们将 Video LDM 的较小版本与 RDS 数据集上的各种基线进行比较,并在表 1(右)中显示结果。首先,使用与我们的Video LDM完全相同的架构,我们将时间微调策略应用于预先训练的像素空间图像扩散模型,这明显优于我们的。
此外,我们训练了一个端到端LDM,其整个参数集{θ, φ}是在RDS视频上学习的,没有与我们的Video LDM相比,θ的图像预训练导致FID和FVD的退化严重。另一个重要的架构选择是引入 3D 卷积层,因为它们允许我们在空间上将上下文帧 cS 馈送到网络。该模型实现了比仅使用注意力的时间模型更低的 FVD 和 FID 分数,该模型使用同一组空间层 θ 并且具有相同数量的可训练参数。最后,我们看到可以通过应用上下文指导来进一步降低 FVD 分数,同时牺牲由增加的 FID 分数指示的一些视觉质量。
此外,我们对视频微调压缩模型解码器的影响进行了分析(参考第3.1.1节)。在RDS 数据集上,我们将微调策略应用于这些压缩模型的解码器,并将重建视频/图像帧的 FVD/FID 分数与其非视频微调对应物的 FVD/FID 分数进行比较。视频微调导致数量级的改进,如表 3 所示。
4.1.2 Driving Scenario Simulation
在野外驾驶场景上训练的高分辨率视频生成器可以潜在地用作强大的模拟引擎。我们在图7中定性地探讨了这一点。给定一个初始帧,我们的视频模型可以生成几种不同的似是而非的未来预测。此外,我们还在数据上训练了一个单独的边界框条件图像LDM(仅用于图像合成)。用户现在可以通过指定不同汽车的边界框手动创建感兴趣的场景组成,生成相应的图像,然后使用该图像作为视频LDM的初始化,然后可以以多模态方式预测不同的场景(图7底部)。
4.2. Text-to-Video with Stable Diffusion
我们的Video LDM方法不是首先训练我们自己的图像LDM主干,而是可以利用现有的图像LDM,并将它们变成视频生成器。为了证明这一点,我们将公开可用的文本到图像LDM稳定扩散转化为文本到视频生成器。具体来说,使用 WebVid-10M 文本字幕视频数据集,我们训练了一个时间对齐的稳定扩散版本,用于文本条件视频合成。我们在WebVid的帧上简要微调稳定的扩散空间层,然后插入时间对齐层并训练它们(分辨率为320 × 512)。我们还在这些对齐层中添加了文本条件。此外,我们进一步视频微调公开可用的潜在稳定扩散上采样器,从而实现4×放大,并允许我们以1280×2048的分辨率生成视频。我们生成由113帧组成的视频,例如,我们可以渲染成长度为4.7秒的剪辑,以24帧/秒或3.8秒的剪辑 30 fps 的速度长度。训练模型的样本如图1和图6所示。虽然WebVid-10M由高质量、真实生活视频组成,但我们能够在视频训练数据之外生成我们能够制作出极具表现力和艺术性的视频。这表明图像LDM主干的一般图像生成能力很容易转化为视频生成,即使我们训练的视频数据集在多样性和风格上要小得多且有限。视频LDM有效地将图像模型中的样式和表达式与从WebVid视频中学习到的运动和时间一致性相结合。
我们在UCF101和MSR-VTT(Tabs)上评估了zero-shot文本到视频的生成。评估细节参见附录 G 。除了 Make-A-Video 之外,我们显著优于所有基线。在 UCF-101 上,我们 IS 仍然超过。Make-A-Video 是并行工作,完全专注于文本到视频,并使用比我们更多的视频数据进行训练。我们仅使用 WebVid-10M; MakeA-Video 还使用 HD-VILA-100M。
在附录 D 中,我们展示了如何应用我们的模型“时间卷积”和“空间卷积”,从而实现更长和空间扩展的生成,而无需上采样器和预测模型。
4.2.1 Personalized Text-to-Video with Dreambooth
由于我们在视频LDM中有单独的空间和时间层,因此出现了一个问题,即在一个图像LDM主干上训练的时间层是否会转移到其他模型检查点(例如微调)。我们针对个性化的文本到视频生成测试这一点:使用 DreamBooth,我们在某些对象的一小组图像上微调我们的稳定扩散空间主干,将它们的身份绑定到稀有文本标记(“sks”)。然后,我们将先前视频调整的稳定扩散(没有 DreamBooth)中的时间层插入到原始稳定扩散模型的新 DreamBooth 版本中,并使用与 DreamBooth 训练图像相关的令牌生成视频。我们发现可以生成个性化的连贯视频,正确捕捉Dreambooth训练图像的身份。这验证了我们的时间层可以推广到其他图像LDM。据我们所知,我们是第一个展示个性化文本到视频的模型。
5. Conclusions
我们提出了视频潜在扩散模型,以实现高效的高分辨率视频生成。关键设计选择是建立在预先训练的图像扩散模型基础上,并通过时间对齐层对它们进行时间视频微调,将它们转换为视频生成器。为了保持计算效率,利用LDM,在时间上对齐后可选地与超分辨率DM相结合。Video LDM可以合成几分钟长、高分辨率、时间连贯的驾驶场景视频。我们还将公开可用的稳定扩散文本到图像LDM转换为高效的文本到视频LDM,并表明学习到的时间层转移到不同的模型检查点,并将其用于个性化的文本到视频生成。我们希望该工作可以使模拟器在自动驾驶研究更有效,并帮助民主化高质量的视频内容创建。