目录
简述
评估分类概述
二值分类
多类分类
对数损失
多类对数损失
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
简述
到目前为止,我们已经看到了如何根据权重来计算神经网络的输出,但是,我们还没有看到这些权重的实际来源。训练是调整神经网络权重以产生所需输出的过程。训练利用了评估,即根据预期输出评估神经网络输出的过程。
由于神经网络可以通过许多不同的方式进行训练与评估,因此我们需要一种一致的方法来对它们进行判断。目标函数评估神经网络并返回得分,训练会根据得分调整神经网络,以便取得更好的结果。通常,目标函数希望得分较低,其试图获得较低得分的过程称为最小化。你可能会设定最大化的问题,此时目标函数需要较高的得分。因此,你可以将大多数训练算法用于最小化或最大化问题。
由于神经网络可以通过许多不同的方式进行训练与评估,因此我们需要一种一致的方法来对它们进行判断。目标函数评估神经网络并返回得分,训练会根据得分调整神经网络,以便取得更好的结果。通常,目标函数希望得分较低,其试图获得较低得分的过程称为最小化。你可能会设定最大化的问题,此时目标函数需要较高的得分。因此,你可以将大多数训练算法用于最小化或最大化问题。
评估分类概述
分类是神经网络尝试将输入分为一个或多个类别的过程。评估分类网络的最简单方法是跟踪被错误分类的训练集数据项的百分比。我们通常以这种方式对人类考试评分。如你可能在学校参加了仅有选择题题型的考试,必须为选项A、B、C或D其中之一涂上阴影。如果你在10个问题的考试中选择了一个错误的选项,得分将是90%。以同样的方式,我们可以给计算机评分。但是,大多数分类算法不会简单地选择A、B、C或D。计算机通常将报告每个类别中的置信度百分比,作为分类结果。下图展示了计算机和人类可能如何对考试中的问题做出回应。

如你所见,人类应试者将第一个问题标记为“B”。计算机对“B”的信心为80%(0.8),对“A”的信心为10%(0.1)。计算机将其余的百分比分布在另外两个选项上。从最简单的意义上讲,如果正确答案为“B”,则该计算机将获得该问题得分的80%。
如果正确答案为“ D”,则该计算机将仅获得5%(0.05)的得分。
二值分类
如果神经网络必须在两个选项之间进行选择,就会发生二值分类,如对/错、是/否、正确/不正确或买入/卖出等。为了理解如何使用二值分类,我们考虑一个发行信用卡的分类系统。该分类系统必须决定如何响应新的潜在客户。该系统要么“发行信用卡”,要么“拒绝发行信用卡”。
当你只考虑两个类别时,目标函数的得分是假阳性(False Positive,FP)预测的数量和假阴性(False Negative,FN)预测的数量。假阴性和假阳性都是错误的类型,理解它们的差异非常重要。对于前面的例子,发行信用卡是阳性的。当向某人发行信用卡会带来严重的信用风险时,就会发生假阳性。当拒绝发给风险很低的人信用卡时,就会产生假阴性。
在假阳性和假阴性这两个选项中,我们可以两害相权取其轻。对于大多数发行信用卡的银行,假阳性比假阴性更糟糕。拒绝一个潜在的、好的信用卡持有人,比接受一个坏信用卡持有人更好,后者会导致银行进行昂贵的收款活动。
分类问题试图将输入分配给一个或多个类别。二值分类采用单输出神经网络,将输入分为两类。让我们考虑汽车MPG数据集。
对于汽车MPG数据集,我们可能会为制造于美国的汽车创建分类。名为origin的字段提供有关汽车总成位置的信息。因此,单输出神经元将给出一个数字,表明该汽车在美国制造的可能性。
要进行这种预测,你需要更改origin字段,让它保存一个值,这个值在1到激活函数的低端范围内。如S型激活函数范围的下限为0;对于双曲正切激活函数,其范围的下限为−1。神经网络将输出一个值,该值表明汽车在美国或其他地方制造的可能性。值接近1表示汽车来自美国的可能性更高,值接近0或−1表示汽车来自美国以外地区的可能性更高。
你必须选择一个判定临界值,将这些预测结果分为美国或非美国。如果美国为1.0,非美国为0.0,那么我们可以选择0.5作为判定临界值。因此,输出为0.6的汽车将来自美国,而输出为0.4的汽车将来自非美国。
这个神经网络在对汽车进行分类时总是会产生错误,美国制造的汽车可能会产生0.45的输出,由于神经网络的输出低于判定临界值,因此无法将汽车归入正确的类别。因为我们设计这个神经网络是为了对美国制造的汽车进行分类,所以该错误称为假阴性。换言之,神经网络表明该汽车不是美国制造的,但该汽车实际上来自美国,产生了阴性结果,因此,分为阴性是错误的。这个错误也称为2型错误。
同样,神经网络可能会错误地将非美国的汽车归类为美国的。这种错误是假阳性或1型错误。更易于产生假阳性的神经网络被称为更具“特异性(specific)”的神经网络。同样,产生更多假阴性的神经网络被称为更具“敏感性(sensitive)”的神经网络。图5-2总结了真/假、阳性/阴性、1型/2型错误,敏感性/特异性之间的关系。

设置输出神经元的判定临界值,就是选择敏感性还是特异性谁更重要。如下图所示,可以通过调整判定临界值来使神经网络更具敏感性或特异性。
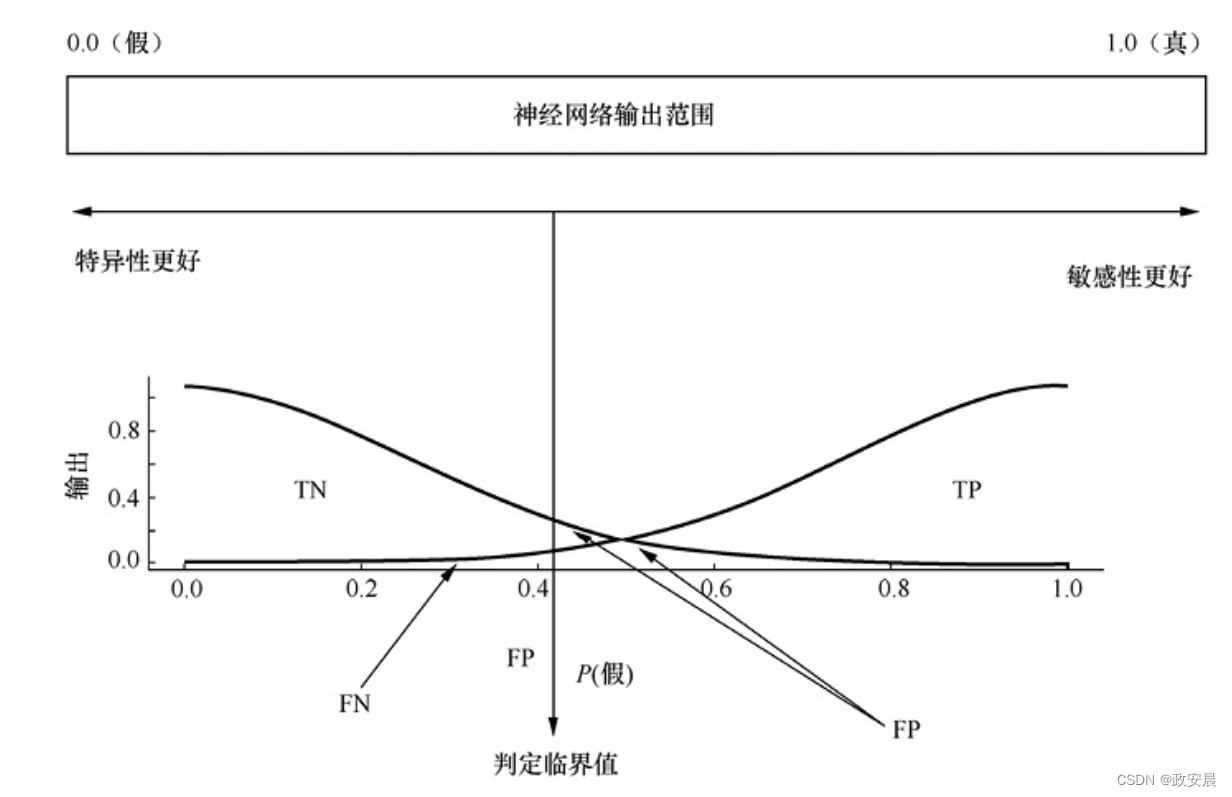
随着判定临界值线向左移动,神经网络将变得更具特异性。真阴性(True Negative,TN)区域的尺寸减小使这种特异性的提高显而易见。相反,随着判定临界值线向右移动,神经网络将变得更具敏感性。真阳性(True Positive,TP)区域的尺寸减小使这种敏感性的提高很明显。
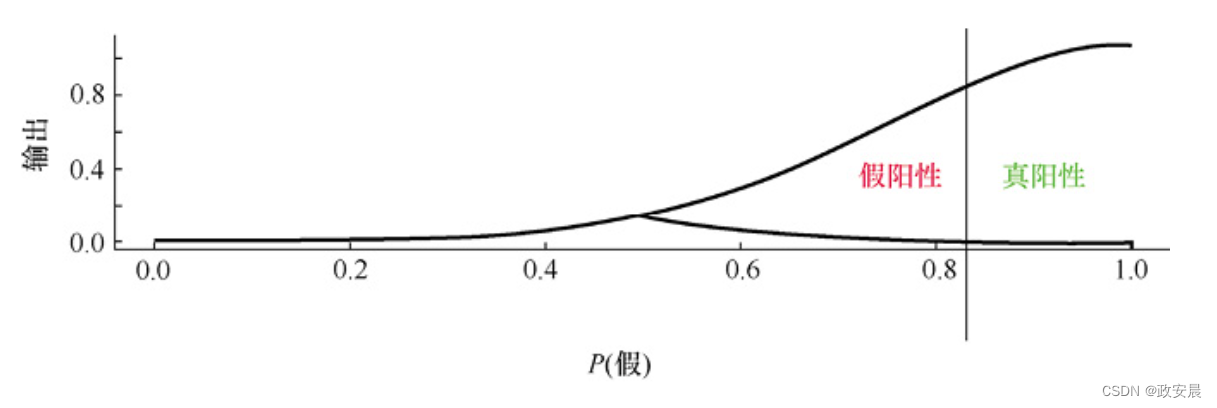
敏感性的提高通常会导致特异性降低。下图展示了旨在使神经网络非常敏感的判定临界值。
也可以对神经网络进行校准,提高特异性,如下图所示。
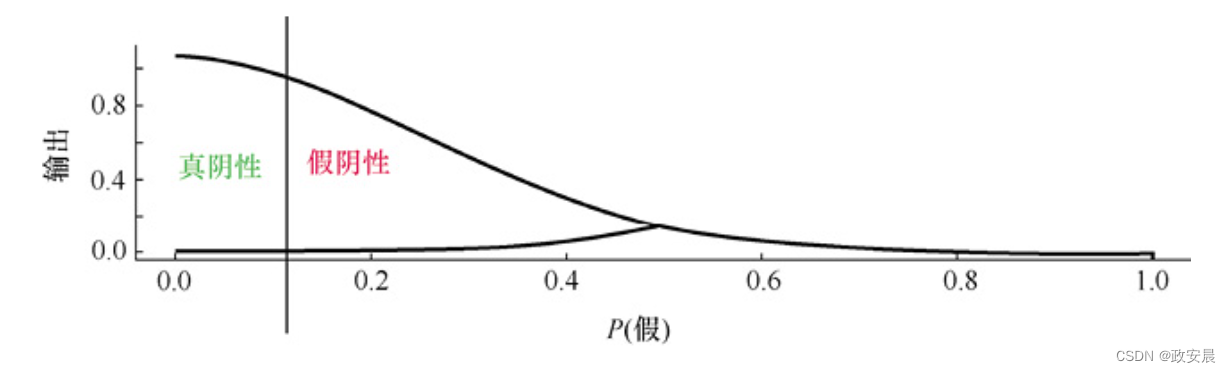
达到100%的特异性或敏感性不一定是好事。通过简单地预测每个人都没有患某种疾病,得出医学检验可以达到100%的特异性。该测试永远不会产生假阳性错误,因为它永远不会给出阳性答案。显然,该测试没有意义。高度特异性或敏感性的神经网络会产生同样的毫无意义的结果。我们需要一种方法来评估与判定临界值点无关的神经网络的总有效性。总预测率(Total Prediction Rate,TPR)结合了真阳性和真阴性的百分比。下面公式可以计算TPR:
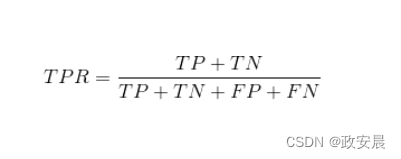
此外,你可以使用“受试者工作特征”(Receiver Operator Characteristic,ROC)曲线来可视化TPR,如下图所示。
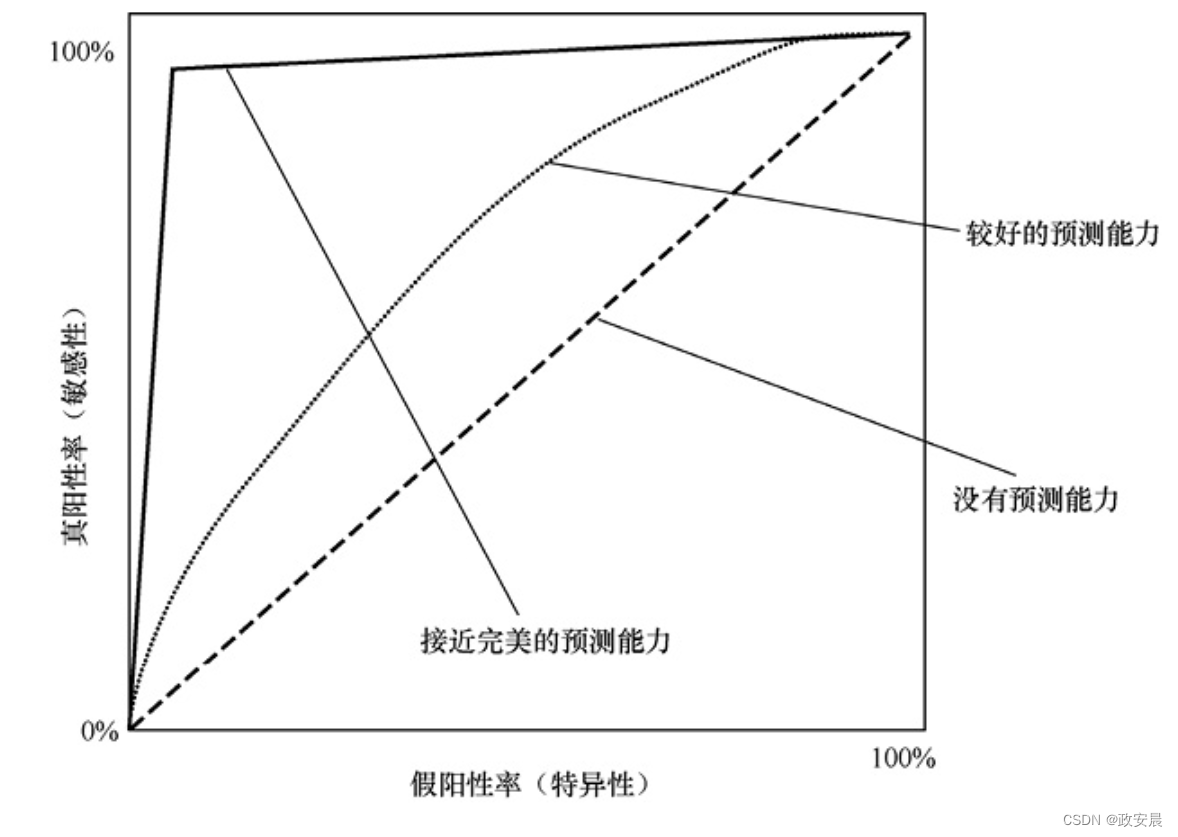
上图展示了3种不同的ROC曲线。虚线显示了具有零预测能力的ROC;点线表示预测能力较好的神经网络;实线表示预测能力接近完美的神经网络。要解读ROC图,请先看以0%标记的原点。所有ROC曲线总是从原点开始,然后移动到右上角,在这里真阳性和假阳性均为100%。y轴显示真阳性率从0%到100%。当你沿y轴向上移动时,真阳性率和假阳性率都会增加。随着真阳性率的增加,敏感性也增加,但是,特异性会下降。ROC曲线允许你选择所需的敏感性级别,但它也显示了达到该敏感性级别必须接受的假阳性率。
最差的神经网络(虚线)总是具有50%的总预测率。这样的总预测率并不比随机猜测更好。要获得100%的真阳性率,必定会有100%的假阳性率,这仍然会导致一半的预测错误。
我们可以用模拟退火在上述网址上训练神经网络。
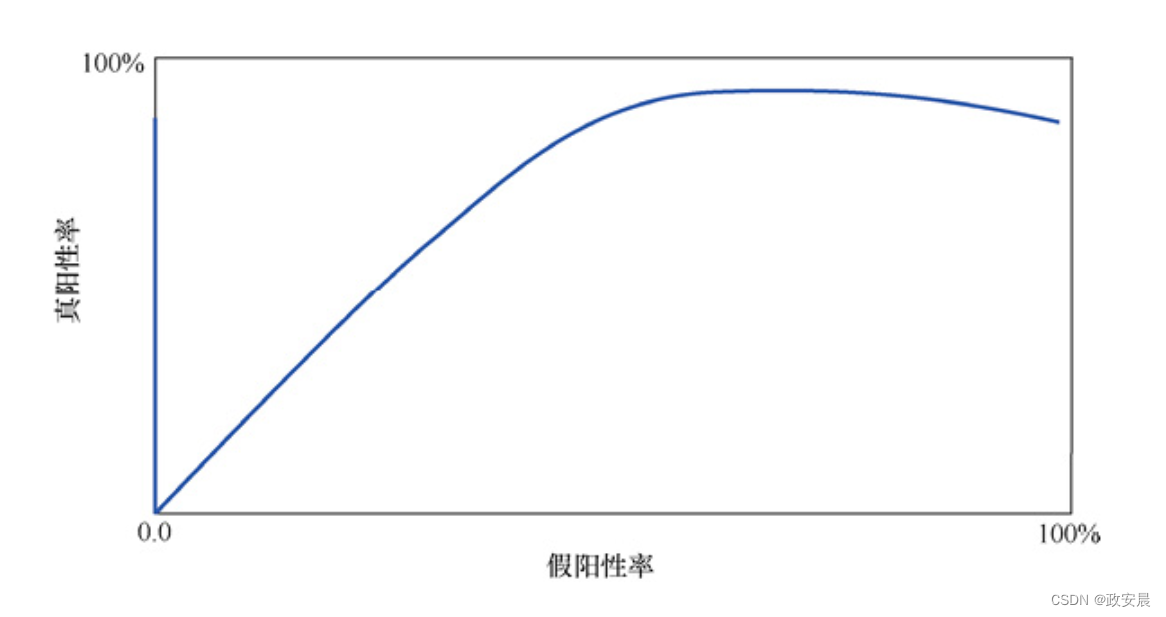
每次“退火期”(annealing epoch)完成时,该神经网络都会改进。我们可以通过均方差(Mean Squared Error,MSE)计算来衡量这种改进。随着MSE的下降,ROC曲线向左上角伸展。我们将在后文详细介绍MSE。现在,将它与预期输出进行比较,只需将它看成对神经网络误差的度量即可。较低的MSE是理想的。
下图展示了我们对神经网络进行多次迭代训练后的ROC曲线。
重要的是要注意,目标并不总是使总预测率最大化。有时,假阳性比假阴性更好。考虑一个预测桥梁倒塌的神经网络。一方面,假阳性意味着当桥梁实际安全时,程序会预测倒塌。在这种情况下,检查结构合理的桥梁会浪费工程师的时间。另一方面,假阴性意味着神经网络预测桥梁安全时,实际会倒塌。与浪费工程师的时间相比,桥梁倒塌的后果要糟得多。因此,你应该安排具有很高特异性的神经网络。
要评估神经网络的总体有效性,应考虑曲线下的面积(Area Under the Curve,AUC)。最佳AUC为1.0,这是一个100%×100%(1.0×1.0)的矩形,它将曲线下的面积推到最大。解读ROC曲线时,更有效的神经网络在曲线下方有更多空间。图5-6中显示的曲线与这种评估相符。
多类分类
如果要预测多个结果,则将需要多个输出神经元。因为单个神经元可以预测两个结果,所以带有两个输出神经元的神经网络是很少见的。如果要预测3个或更多结果,则将有3个或更多输出神经元。
考虑Fisher的鸢尾花数据集。针对3种不同物种的鸢尾花,该数据集包含了4种不同的测量值。
鸢尾花数据集的样本数据如下所示:
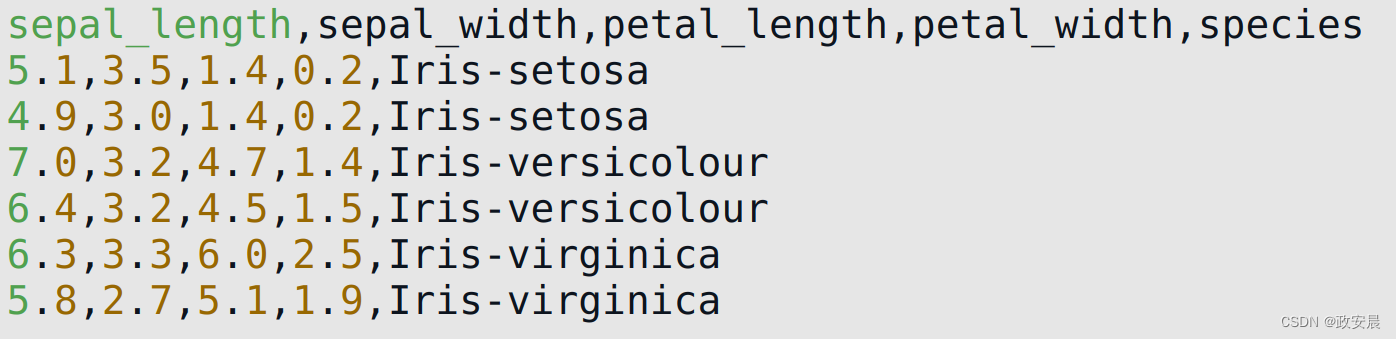
根据4个测量值可以预测这些物种。对于这种预测,这4个测量值的含义并不重要,重要的是这些测量值将指导神经网络进行预测。下图展示了可以预测鸢尾花数据集的神经网络结构。
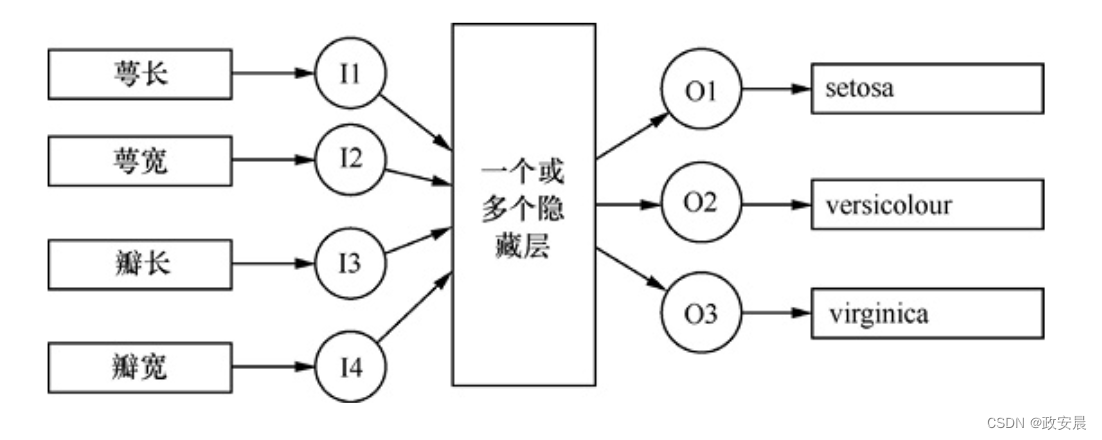
上图所示的神经网络接受4个测量结果并输出3个数字。每个输出与一个鸢尾花物种相对应。产生最高数值的输出神经元决定了预测的物种。
对数损失
分类网络可以从输入数据推导出一个分类。
如4个鸢尾花测量值可以将数据分组为3种鸢尾花。
评估分类的一种简单方法,是将它看成仅有选择题题型的考试,并返回百分比得分。尽管这种方法应用得很普遍,但是大多数机器学习模型都无法像你在学校那样回答多项选择题。
请考虑可能会在考试中出现的以下问题:
1.鸢尾花setosa会有萼片长5.1厘米、萼片宽3.5厘米、花瓣长1.4厘米、花瓣宽0.2厘米吗? A) True B) False
这正是神经网络在分类任务中必须面对的问题类型。
但是,神经网络不会回答True或False。
它会用以下方式回答问题:
True: 80%
上面的响应意味着神经网络有80%的概率确信这朵花是setosa。
这项技术如果可以应用在你的考试上,则会非常方便。如果你不能在是非题之间做出选择,只需将80%的置信度置于True上即可。得分相对容易,因为你会得到正确答案相应置信度的得分比例。
在这个例子中,如果True是正确的答案,则该问题将会获得80%的得分。
但是,对数损失(log loss)不是那么简单的。如下公式是对数损失的公式:

你应将这个公式仅用作具有两个分类结果的目标函数。其中变量[插图]是神经网络的预测,变量[插图]是已知的正确答案。在这种情况下,Yi始终为0或1。训练数据没有概率,神经网络将它分为一类(1)或另一类(0)。
变量N代表训练集中的元素数量,即测验中的问题数量。我们将结果除以N,因为这个过程按惯例求的是平均。我们在该方程前添加负号,因为对数函数在域0~1上始终为负。这个负号允许最小化训练的正得分。
你会注意到公式5-2中等号右边的两个项之间用加号(+)隔开。每个项都包含一个对数函数。因为Yi为0或1,所以这两个项之一将被0消除。如果Yi为0,则第一项为0;如果Yi为1,则第二项为0。
对于两类预测,如果你对第一类的预测是Yi,那么对第二类的预测是1−Yi。本质上,如果你对A类的预测为70%(0.7),那么对B类的预测为30%(0.3)。你的得分会根据你对正确分类的预测对数而增加。如果神经网络对A类预测为1.0,并且正确答案为A,则你的得分将增加lg(1),即0。对于对数损失,我们追求较低的得分,因此正确答案导致得分为0。以下是神经网络对正确类别的概率估计的一些对数值:
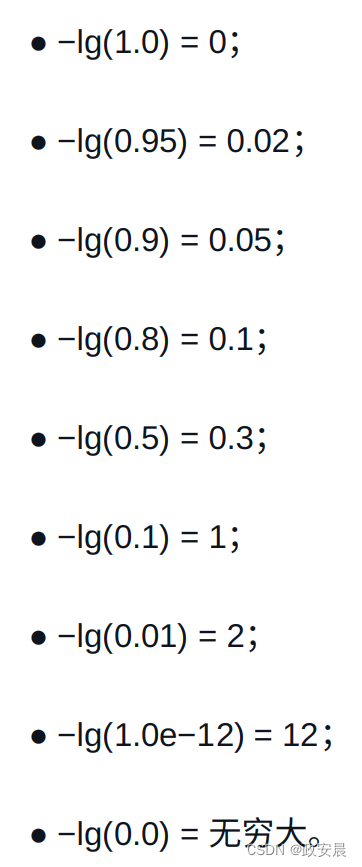
如你所见,为正确答案给出低置信度对得分的影响最大。因为lg(0)是负无穷大,所以我们通常强加一个最小值。当然,以上对数值是针对单个训练集元素的。我们将对整个训练集的对数值进行求平均。
多类对数损失
如果对两个以上的结果进行分类,则必须使用多类对数损失(multi-class log loss,mlogloss)。这个损失函数与刚才描述的二值对数损失密切相关。
下面公式是多类对数损失的公式:
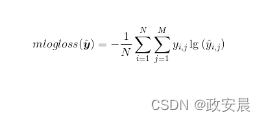
在上面公式中,N是训练集元素的数量,M是分类过程的类别数量。从概念上讲,多类对数损失函数的作用类似于单个对数损失函数。上面的等式本质上为你提供一个得分,该得分是每个数据集上正确类别预测的负对数的平均值。上面公式中最里面的求和作为一个if-then语句,仅允许Yi,j为1.0的正确分类对求和有贡献。