1.introduction
llamafactory由三个主要模块组成,Model Loader,Data Worker,Trainer。
2.Efficient fine-tuning techniques
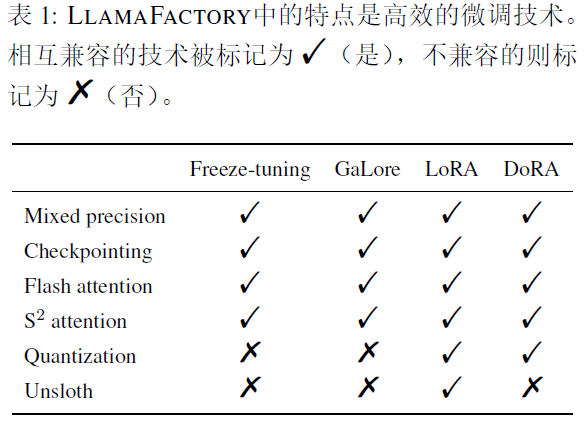
2.1 Efficient Optimization
冻结微调:冻结大部分参数,同时只在一小部分解码器层中微调剩余参数,GaLore将梯度投影到低维空间,以内存高效的方法实现全参数学习;相反,Lora冻结所有的预训练权重,并在指定层中引入一对可训练的低秩矩阵,当与量化结合时,称之为QLora。
2.2 Efficient Computation
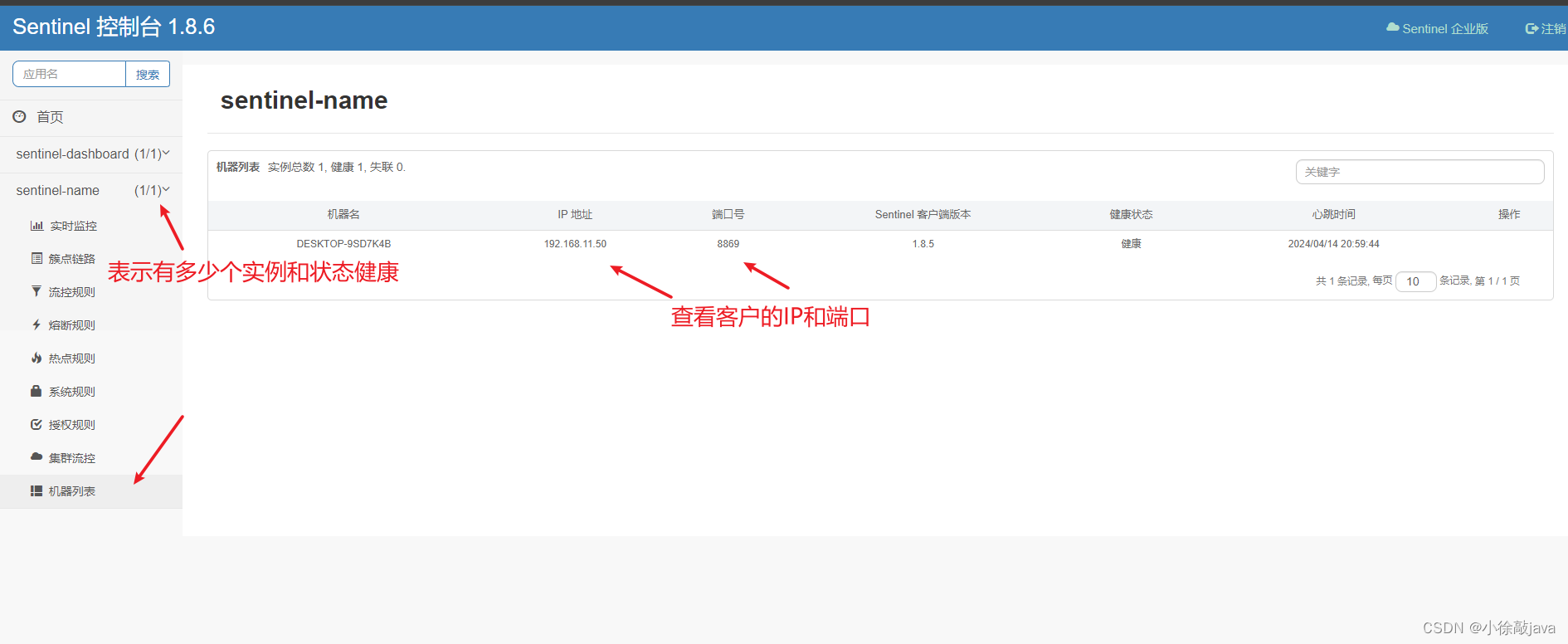
3.LLamafactory framework

3.1 ModelLoader
3.1.1 Initialization
使用transformers的AutoModel API加载模型并初始化参数,为了使框架兼容不同模型架构,建立了一个模型注册表,存储每层的类型,从而更方便的使用高效的微调技术,当word embedding的词汇大小超过tokenizer的容量时,会调整层的大小,并使用噪声均值初始化新参数,为了计算RoPE缩放的缩放因子,计算了输入序列长度的最大值与模型的上下文长度的比率。
3.1.2 Patches
为了启用flash-attention和s2-attention,使用monkey patch替换模型的前向计算。
3.1.3 Quantization
3.1.4 Adapter
PEFT
3.2 Data worker
构建了一个数据处理流程,包括数据加载,数据对齐,数据合并和预处理。将不同任务数据标准化为统一格式。

3.3 Trainer
Lora/GaLore,训练方法与Trainer独立,使用transformers进行pt和sft,trl进行rlhf和dpo,
3.4 Utilities
transformer和vllm进行输出,实现了openai风格的api。
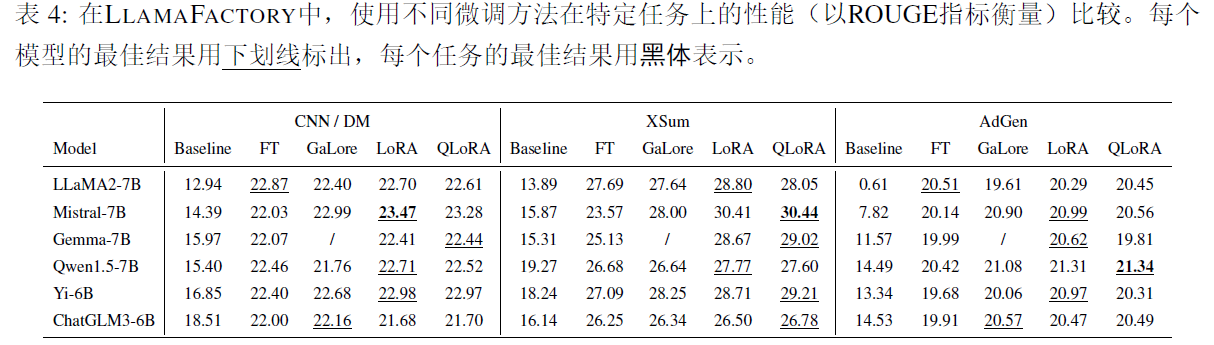
4.Empirical study
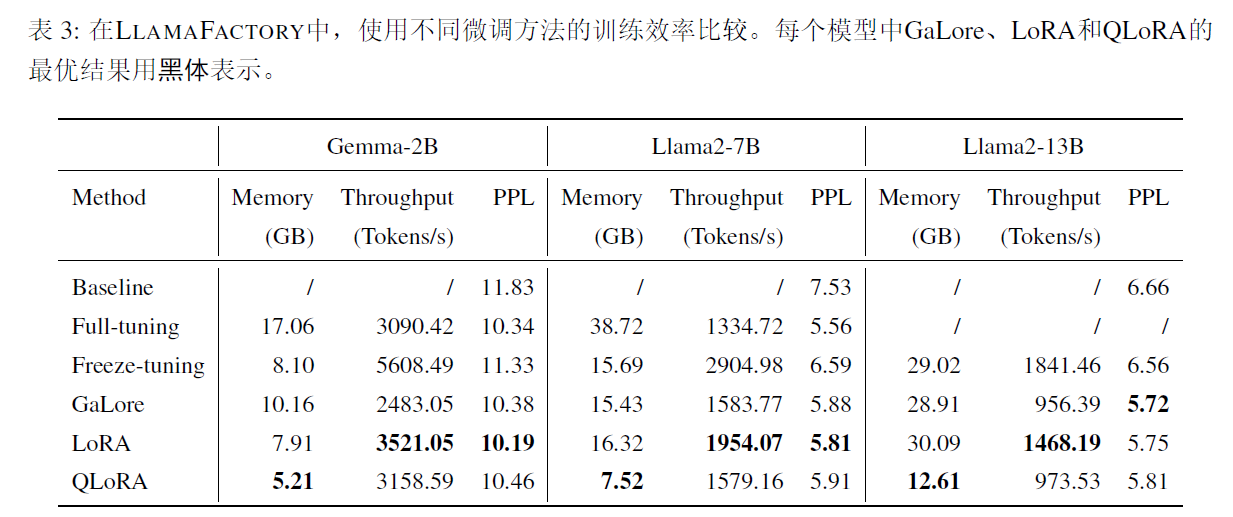
4.1 Training efficiency
PubMed数据集,包括3600w数据,提取大约40w token来构建训练样本,