1. 文本切割
在使用基于检索的生成模型(RAG)处理长文本数据时,合理的文本切割策略是提高模型性能和效率的关键。
1.1.文本切割策略核心参数
文本切割策略主要依赖于两个参数:chunksize(块大小)和overlap(重叠)。正确配置这些参数可以显著影响模型的输出质量和处理速度。
- chunk_size 基于模型的限制(embedding , LLM )
- 不同Text splitter 的优劣,如何选取
- 可视化文本切分的效果,供大家切分文本初步参考
基于模型选取chunk_size
- 首先是embedding model, 向量嵌入模型有Max Tokens 的限制,设置的chunk size不可以超过模型支持的最大长度,否则将丢失语义。

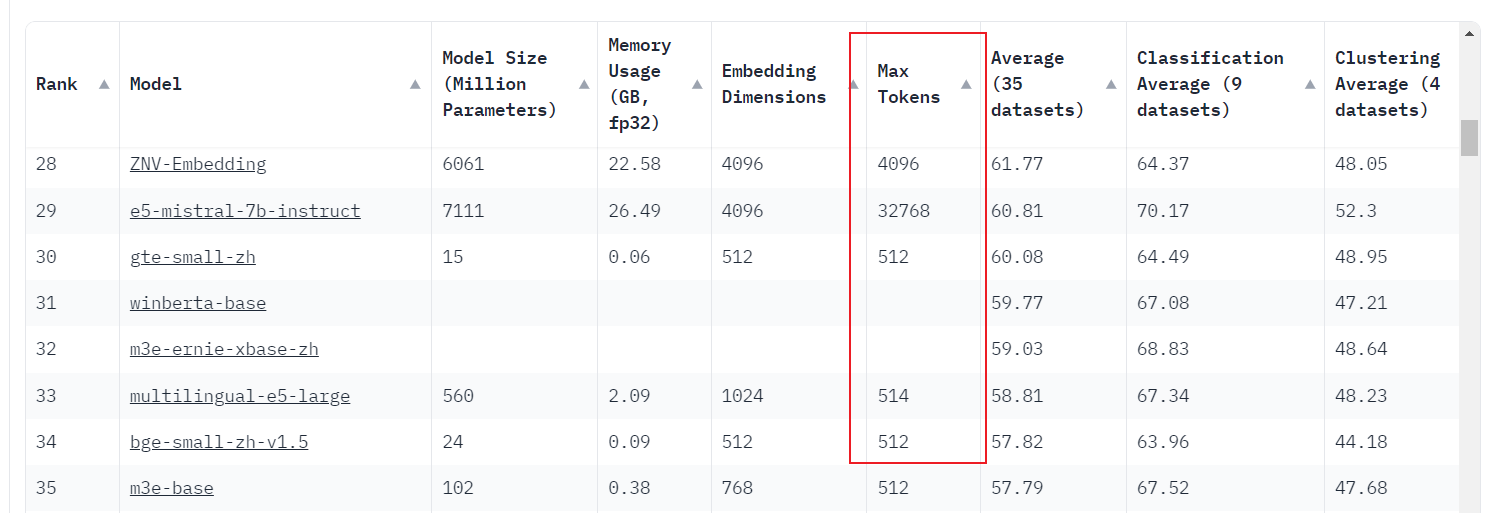
不同的embedding model 支持的 Max Tokens都有不同,具体可参考model 排行 - 其次是LLM model , 大语言模型有Max sequence length的限制,处理知识增强的时候,prompt中召回的文本不可以超出最大长度。

需要根据不同的LLM支持的最大token长度,选取合适的参数
如何查看Max Tokens
打开model 排行,查看所选模型的Max Tokens参数
1.2. 不同的文本切分策略
-
CharacterTextSplitter 这是最简单的方法。它默认基于字符(默认为"")来分割,并且通过字符的数量来衡量块的长度。
- 文本的拆分方式:按单个字符
- 区块大小的测量方式:按字符数
- chunk_size:块中的字符数
- chunk_overlap:在顺序块中重叠的字符数。跨块保留重复数据
- 分隔符:用于分割文本的字符(默认为“”)
-
RecursiveCharacterTextSplitter 基于字符列表拆分文本。文本分割工具的设计目的是为了在处理文本时,能够在不损失语义关联性的前提下,将文本有效分割成更小的单元。通过先尝试分割段落,如果段落仍然过大,再尝试分割成句子,依此类推,直至分割成单词。这种分割方法尽量保留文本的原有结构和意义,使得处理后的文本单元在语义上保持连贯性。
- “\n\n” - 段落
- “\n” - 换行
- " " - 空格
- “” - 字符
-
Document Specific Splitting
- python - RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
- json - RecursiveJsonSplitter
- Markdown - MarkdownTextSplitter
- Html - HTMLHeaderTextSplitter
-
Semantic Chunking: Embedding将文本转化为高维空间中的向量的技术,这些向量能够反映出文本的语义内容。通过文本嵌入技术,可以捕捉到文本的深层次语义信息。当比较两段文本的嵌入向量时,可以根据它们在高维空间中的距离或者角度,来推断这两段文本在语义上的相似度或者差异。利用相似度,将语义上相似的文本自动分组在一起,形成聚类,这有助于更好地理解和组织大量的文本数据。
- LlamaIndex具有SemanticSplitterNodeParser类,该类允许使用块之间的上下文关系将文档拆分为块,使用嵌入相似性自适应地选择句子之间的断点。SemanticSplitterNodeParser超参数介绍:
- buffer_size:配置块的初始窗口大小;
- breakpoint_percentile_threshold:决定在何处分割块的阈值;
- embed_model:使用的嵌入模型。
- LlamaIndex具有SemanticSplitterNodeParser类,该类允许使用块之间的上下文关系将文档拆分为块,使用嵌入相似性自适应地选择句子之间的断点。SemanticSplitterNodeParser超参数介绍:
-
代理分块: 这种分块策略探索了使用LLM来根据上下文确定块中应包含多少文本以及哪些文本的可能性。
- 为了生成初始块,参考论文《Dense X Retrieval: What Retrieval Granularity Should We Use?》,从原始文本中提取独立语句。Langchain提供了propositional-retrieval模板(https://templates.langchain.com/new?integration_name=propositional-retrieval)来实现这一点。
- 在生成命题之后,这些命题输入到基于LLM的代理。该代理确定命题是否应包括在现有块中,或者是否应创建新块。
2. 推荐的Embedding模型
请根据实际需要,选择model 排行中的模型
以下是推荐使用的支持中文的Embedding模型
| 模型名称 | 原因 | Max Tokens | Embedding Dimemtions | Huggingface 地址 |
|---|---|---|---|---|
| gte-large-zh | 由阿里巴巴达摩院开发,针对中文场景进行了优化,具有较高的性能。 | 512 | 1024 | 链接 |
| bge-large-zh-v1.5 | 北京智源人工智能研究院开发的模型,专为中文设计,在多个中文NLP任务上表现优异。 | 512 | 1024 | 链接 |
| m3e-base | M3E模型作为最新的开源中文Embedding模型,在多模态、多粒度的中文文本理解方面具有优势。 | 512 | 768 | 链接 |
| tao8k | 由Huggingface开发者amu研发并开源的模型,在特定任务上表现出色,适合用于中文领域的RAG系统。 | 512 | 1024 | 链接 |
| Massive | 通过大规模的中文句对数据集进行训练,支持中英双语的同质文本相似度计算,异质文本检索等功能。 | 2200000 | 768 | 链接 |
3. 长上下文是否替代了RAG?
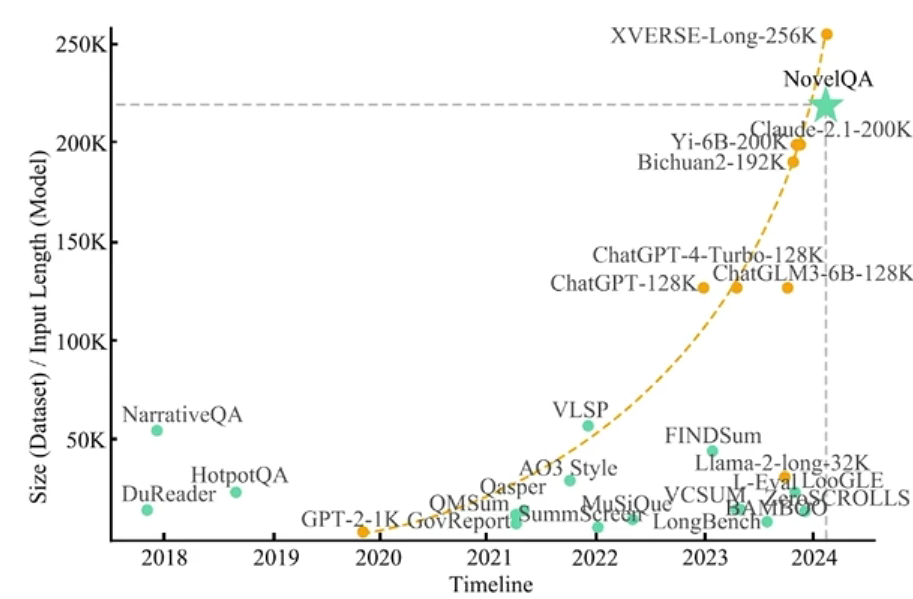
- 目前主流大模型支持的上下文长度越来越长
- Kimi支持200万字的上下文,其它的详见下图

3.1.长上下文窗口的好处
提高理解和连贯性:长上下文窗口允许模型在生成回答时,参考更多的背景信息,这使得模型能够更好地理解复杂的查询上下文,从而生成更加相关和连贯的回答
复杂任务处理能力:有些任务,如撰写文章、编程、数据分析等,需要对大量信息进行处理和引用。长上下文窗口使模型能够处理这类复杂任务提供更加深入和准确的输出
提升用户体验:用户在与模型交互时,往往希望模型能够记住并利用整个对话历史中的信息。长上下文窗口可以使模型在整个会话过程中保持信息的连续性,提供更加个性化和满意的用户体验。
3.2. 长上下文窗口与RAG的对比
| 维度 | 长上下文窗口 | RAG系统 |
|---|---|---|
| 数据需求 | 需要大量数据来训练模型,以便模型能够理解和生成与长上下文相关的文本。 | RAG系统依赖于高质量的索引数据和有效的数据预处理,以提高检索的准确性和相关性。 |
| 应用场景 | 适用于长对话、长文档总结、长期计划执行等场景,能够一次性处理较长的文本序列。 | 适用于需要结合检索外部知识的场景,如问答系统、内容推荐、自动摘要等。 |
| 成本消耗 | 长上下文窗口模型通常需要更高的算力和显存资源,导致成本较高。 | RAG系统可能需要额外的后端支持,如矢量数据库和索引库,以及优化检索策略的成本。 |
| 性能 | 长上下文窗口模型在处理长文本时性能较好,但可能存在“Lost in the Middle”的问题,即模型难以利用中间信息。 | RAG系统通过结合检索和生成,提高了模型的准确性和相关性,但性能也受到索引质量和检索策略的影响 |
GPT在大海捞针测试中的表现
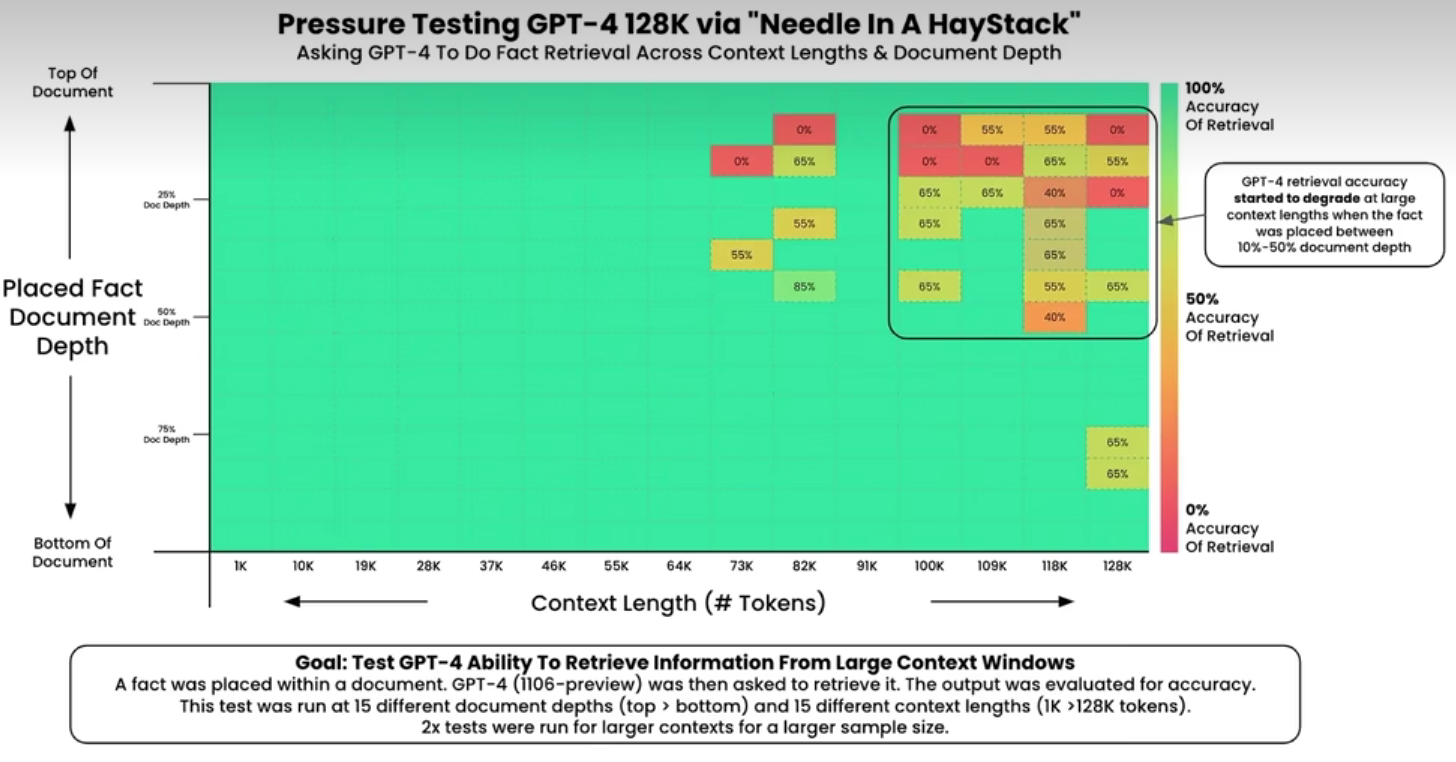
3.3. 适用场景
- 长上下文窗口:适用于一次性的单一提示场景,其中在一个提示中提交长内容,并基于这段长内容提出多个问题【一个会话中仅处理一次长内容,而非反复使用或更新】
- RAG:提供一种更灵活的方法,可以在多种数据源中检索和生成信息
3.4. 小结
长上下文窗口对RAG的影响 及未来进化方向
- 增加了RAG系统的精确度限制: 虽然很多模型能处理更长的上下文窗口,但它们无法取代RAG,因为处理复杂RAG任务仍然需要更好的系统才能投入生产。长上下文窗口允许RAG系统在检索精度较低的情况下仍然进行有意义的处理,从而促进了RAG生产的简化,提升了RAG应用的效能。
- 未来进化方向: 如果所有模型拥有真正可靠的长上下文窗口,这些模型怎么竞争?则它们会寻求降低成本和减少延迟。降低成本和减少延迟的方式之一就是尝试最小化发送到上下文窗口的信息量,这本质上是RAG的过程
总之,RAG作为一种处理信息和优化LLM性能的方法,在未来发展中有积极前景,特别是在处理大量上下文信息和提升精确度方面,此外在企业级产品中的潜力是无穷的。
参考
LLM之RAG实战(二十)| RAG分块策略的五个level