PBXAI:将疾病预测转为沿知识图谱的随机游走
- PBXAI = 知识图谱构建 + 病人特征与知识图谱连接 + 强化学习 + 疾病发展路径的生成
- PBXAI 流程
- PBXAI 算法设计
论文: https://arxiv.org/ftp/arxiv/papers/2010/2010.08300.pdf
代码:https://github.com/ZJU-BMI/PBXAI
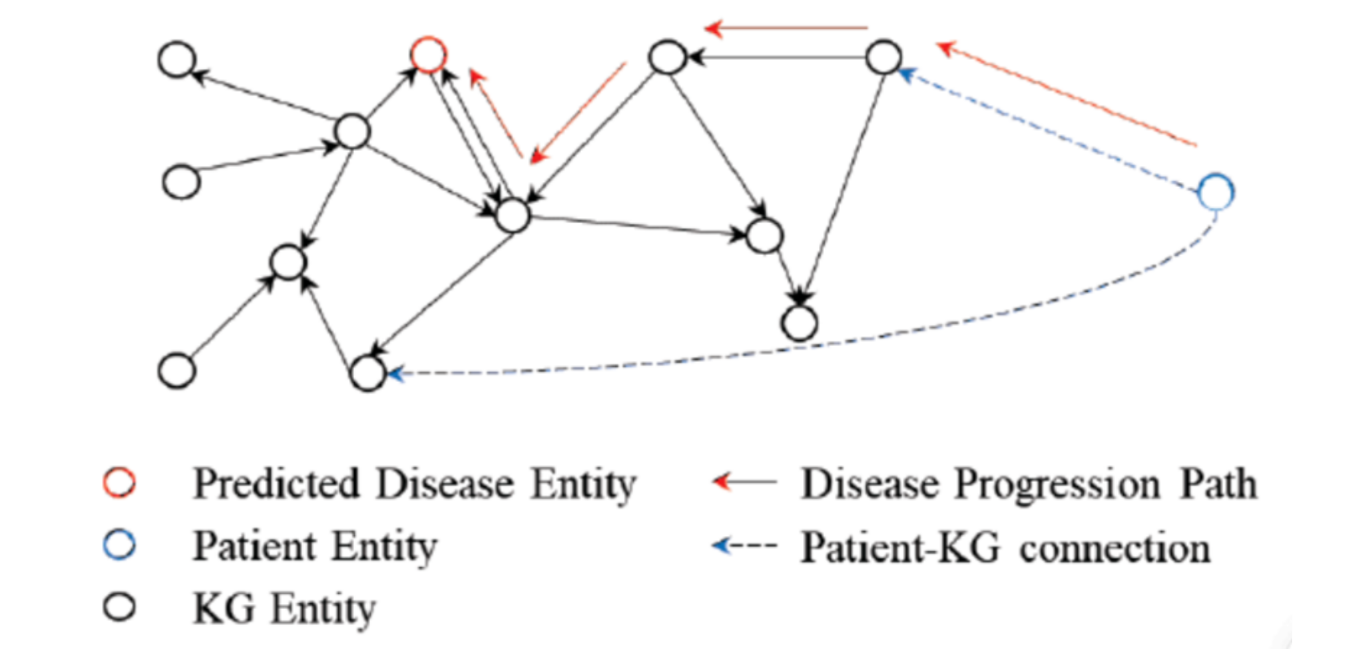
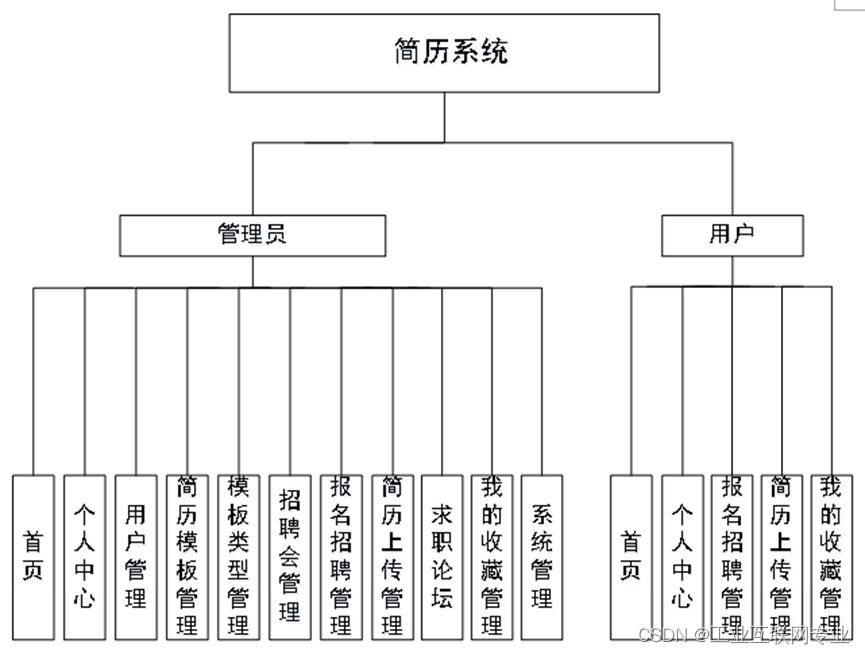
在图中,不同的圆圈代表不同类型的实体:
- 红色圆圈表示被预测的疾病实体
- 蓝色圆圈代表患者实体
- 黑色空心圆圈则是KG中的其他实体。
箭头指示了实体之间的关系,红色箭头表示疾病发展路径,蓝色虚线表示患者实体与知识图谱中实体的连接。
患者实体通过具体的疾病或风险因素与KG中的相关实体相连,然后模型会预测患者可能发展出的疾病以及这些疾病的发展路径。
这些路径是根据强化学习模块的策略生成的,模块由患者的电子健康记录数据训练而来。
图说明如何通过分析患者当前的健康状况和历史数据,预测其未来可能发展的疾病及路径。
基于医学知识的知识图谱,通过模拟患者的健康轨迹预测疾病风险,其中模型学习过程由患者的电子健康记录驱动。
-
基于经过验证的医学知识构建一个知识图谱来记录疾病和风险因素之间的关系。
-
然后,一个数学对象沿着知识图谱行走,从一个患者实体开始行走,该实体根据患者当前的疾病或者风险因素连接知识图谱,停止在疾病的实体,数学对象的生成轨迹表示患者的疾病发展路径,对象的行走策略由强化学习模块控制,该模块由电子健康记录数据训练。
关键要素:
- 知识图谱(KG): 由实体集(疾病、疾病类别、风险因素等)和关系集构成,表示各种医学概念及其互相之间的关系。
- 患者实体: 患者的健康数据转化成一个向量,可以链接到KG的相应实体。
- 强化学习模块: 用于预测疾病的模型,通过随机游走过程模拟患者的疾病进展路径。
- 状态: 在每个时间步,由患者当前信息和历史路径信息组成。
- 行动: 状态下可能的转移,例如从一个疾病状态转移到另一个。
- 奖励: 预测正确时给予的正向反馈,用于指导RL模型学习。
链条梳理:
- 建立知识图谱: 包含医学实体(如糖尿病)及其相关性(如糖尿病与肥胖的关联)。
- 处理患者数据: 将患者的EHR数据分为角色(患者当前的疾病状态)和特征(其他健康指标)。
- 预测过程: 利用RL模块,从患者当前的状况出发,模拟在KG中的游走过程,预测患者未来可能发展的疾病。
举例说明(糖尿病):
假设有一个患者现在有高血糖和超重风险,这些通过患者角色向量链接到KG。
- 在KG中,这些状态与糖尿病有直接的连接。
- RL模块开始模拟患者未来的病程,探索从当前状态到糖尿病的路径。
- 如果预测成功(即患者确实发展成糖尿病),模型会收到奖励,这有助于未来更准确的预测。
通过这个过程,可以生成一个患者可能从高血糖和超重状态进展到糖尿病的可解释路径,为医生提供关于病情发展的洞见和潜在的干预点。
PBXAI = 知识图谱构建 + 病人特征与知识图谱连接 + 强化学习 + 疾病发展路径的生成
这个复杂的模型解决的是如何使用医学知识图谱(KG)和病人的电子健康记录(EHR)数据,通过强化学习(RL)来预测疾病发展路径的问题。
子解法1:知识图谱构建
- 之所以使用知识图谱,是因为它可以存储医学概念之间的关系,例如“冠心病”可能导致“心力衰竭”。
子解法2:病人特征与知识图谱连接
- 之所以要连接病人特征和知识图谱,是因为这可以直接将病人的实际病情(例如高血压)映射到图谱中的相应实体上。
子解法3:强化学习
- 之所以用RL模型,是因为它可以控制一个数学对象(代表病人)在知识图谱中的路径,模拟疾病的发展过程。
子解法4:疾病发展路径的生成
- 之所以要生成疾病发展路径,是因为这提供了一种对疾病预测的直观解释,帮助医生理解模型的决策过程。
举例:假设我们要预测病人是否会发展成糖尿病:
- 在知识图谱中,我们已经有了糖尿病及其相关的风险因素和后果。
- 我们从病人的EHR中获取其特征(比如血糖水平、体重等),并将这些信息与知识图谱连接。
- RL模型通过学习这些数据,开始在图谱中为病人找到可能发展成糖尿病的路径。
- 最终,RL模型不仅可以预测病人是否会得糖尿病,还可以展示从当前状况到糖尿病发展的整个过程。
通过这种方法,模型不仅给出了是否会发展成糖尿病的预测结果,而且还能给出一个解释,即病人从现在的健康状况到最终可能发展成糖尿病的具体路径。
这对于医生来说非常有用,因为他们不仅看到了预测结果,还看到了为什么会有这样的预测,从而可以更好地制定治疗计划。
PBXAI 流程

这幅图展示的是一种基于知识图谱(KG)和强化学习(RL)的疾病预测模型框架。
这里是它的主要组成部分和步骤:
-
知识图谱(KG):展示了一系列相互关联的实体(如疾病、症状、生理特征等),这些通过箭头连接,表示它们之间的关系。每个箭头(如 r1, r2, r3)表示一个实体之间的特定类型的关联。
-
病人实体:代表特定病人的节点,通过他们的个性化特征(如年龄、性别、病史等)与知识图谱连接。
-
病人数据(EHR):电子健康记录中的病人特征和特征性状被用来在模型中代表一个病人实体。
-
RL代理:强化学习算法的“智能体”,它在知识图谱中导航以预测疾病。它通过两个主要组成部分进行工作:
- Actor(演员):根据当前状态和行动空间(A_t)来生成策略向量 π,决定下一步行动。
- Critic(评论家):评估当前状态的价值,生成一个估计的状态值 v。
-
行动和状态:智能体的行动(a_t)受到当前可能的行动空间(A_t)和当前状态(s_t)的限制。在这个模型中,状态是病人的特征、当前实体和历史轨迹的组合。
-
奖励(r_t):当智能体执行一个行动时,它会得到一个奖励,这个奖励反映了行动的结果是否有利于达到预测正确疾病的目标。
整体来看,这个模型是通过结合医学知识(通过KG)和病人的个人数据来预测疾病的发展,同时通过强化学习提供决策的可解释性。
智能体的目标是找到最佳路径,以预测未来可能发生的疾病,并为这个预测提供一个可解释的途径。
- 知识图谱中的糖尿病实体:在知识图谱(KG)中,糖尿病会是一个实体。
它可能与其他实体如“高血糖”、“肥胖”、“遗传倾向”等通过某种类型的关系(例如因果关系、共发生关系)相连接。
-
病人实体:假设有一个病人的电子健康记录(EHR)显示他有预糖尿病的症状,他的病人实体就会包括这些信息,如血糖水平、体重指数(BMI)、家族病史等。
-
模型预测过程:RL代理开始在KG中为这个病人导航。
从病人实体出发,RL代理考虑当前的病人特征(如预糖尿病症状)、与病人实体直接连接的KG中的实体(如“高血糖”节点),以及历史信息来决定下一步行动。
这个决定过程包括两部分:Actor(生成下一步的策略向量 π)和Critic(评估当前决策的状态值 v)。
- 生成疾病进展路径:RL代理的每一步行动都旨在探索糖尿病可能的发展路径。
例如,如果病人实体连接到“高血糖”,然后是“肥胖”,RL代理可能会预测下一步的疾病发展实体为“2型糖尿病”。
- 奖励和学习:如果RL代理的行动(预测)与实际发生的疾病(比如病人确实发展成了糖尿病)匹配,那么它会得到正向奖励(r_t),从而加强这个预测路径的权重。
随着越来越多的EHR数据被训练,模型就会在预测糖尿病的任务上变得更加精确。
最终,通过这个过程,模型能够不仅预测病人可能发展的疾病,而且还能提供一条清晰的疾病进展路径,这为医生提供了可解释的决策支持。
这样,医生可以更好地理解为什么模型会预测某个病人有高糖尿病风险,以及可以采取哪些预防措施。
PBXAI 算法设计

这个图展示的是一个算法的伪代码,具体是疾病预测和路径推理的算法。这个算法是如何工作的,我会用中文逐步解释:
输入:
- 病人表示 ( p_e ),
- 时间范围 ( T ),
- 知识图谱 ( G_c ),
- 病人实体 ( p ),
- Beam搜索集合 ( [K_0, K_2, …, K_{T-1}] ),
- 预测疾病数量 ( D )。
输出:
- 疾病概率集合 ( P ),
- 路径集合 ( R_T ),
- 路径概率集合 ( Q_T )。
算法步骤:
-
初始化:
- 路径集 ( R_0 ) 初始化为包含病人实体 ( p ) 的集合。
- 路径概率集 ( Q_0 ) 初始化为 1。
- 疾病概率集 ( P ) 初始化为 0。
-
时间步迭代:从 0 到 ( T-1 ):
- 初始化下一时间步的路径集 ( R_{t+1} ) 和路径概率集 ( Q_{t+1} ) 为空集合。
-
遍历每个行动:对于每个可能的行动 ( a ) 和边 ( e ) 在 ( R_t ) 和 ( Q_t ) 中:
- 根据当前行动生成新的路径 ( \hat{P} )。
- 设置当前状态 ( S_t ) (包含病人表示、当前实体和历史轨迹)。
- 获取行动空间 ( A_t ) 根据 ( G_c ) 和 ( e_t )。
- 生成策略 ( \pi ) 和行动空间 ( A_t )。
- 删除概率不在 top ( K_t ) 中的行动。
- 对于 ( A_t ) 中的每个行动 ( a ):
- 保存新的路径 ( \hat{P} ) 和 ( (r_{t+1}, e_{t+1}) ) 到 ( R_{t+1} )。
- 保存新的概率 ( \pi_t(a) ) 乘以 ( \hat{Q} ) 到 ( Q_{t+1} )。
-
遍历路径和概率:对于每个 ( \hat{P} ) 在 ( R_T ) 和 ( \hat{Q} ) 在 ( Q_T ):
- 如果路径的末端 ( e_r ) 是一个疾病实体:
- 更新该疾病实体的概率 ( P )。
- 如果路径的末端 ( e_r ) 是一个疾病实体:
-
返回结果:最后返回疾病概率 ( P ),路径 ( R_T ),和路径概率 ( Q_T )。
这个算法的核心是通过迭代地模拟在知识图谱上的随机游走来预测病人未来可能发展出的疾病,同时生成每种疾病发展的概率和对应的路径。
这个过程考虑了病人的历史病情和当前状态,并使用RL方法来优化预测的路径。
通过这种方法,可以得到可解释的疾病进展路径和每种疾病的概率,从而为临床决策提供支持。
假设我们要用这个算法预测一个病人是否会发展成糖尿病。
-
输入和初始化:
- 输入病人的基本信息,如性别、年龄、体重指数(BMI)、血糖水平,这些数据形成病人的特征表示 ( p_e )。
- 确定时间范围 ( T ),比如我们要预测病人在未来5年内的健康变化。
- 输入知识图谱 ( G_c ),它包含了诸如“高血糖”可能导致“糖尿病”的医学关系。
- 病人实体 ( p ) 将是与病人特征表示 ( p_e ) 相连的节点。
- 初始化路径集合 ( R_0 ) 为只包含病人实体 ( p ) 的集合,路径概率 ( Q_0 ) 为1,疾病概率集合 ( P ) 为0。
-
时间步迭代:
- 从 ( t = 0 ) 到 ( t = T-1 )(例如从0到4,代表5年),为每一年重复以下步骤。
-
行动和路径生成:
- 对于每一步 ( t ),根据病人当前的健康状态和知识图谱生成可能的下一步行动。
- 例如,如果病人当前状态是“高血糖”,算法将探索从“高血糖”到“糖尿病”的路径。
- 根据算法计算出的概率,保留最有可能的路径,并删除那些不太可能的行动。
-
遍历所有路径:
- 最终,我们会得到一系列可能的疾病发展路径 ( R_T ) 和每条路径对应的概率 ( Q_T )。
- 如果这些路径中的最终节点是“糖尿病”,并且这个结果在未来确实会发生,疾病概率集合 ( P ) 将更新,增加糖尿病发生的概率。
-
结果返回:
- 算法完成后,我们会得到一个关于病人在未来可能发展成糖尿病的概率 ( P ),以及如何到达这个结论的路径 ( R_T ) 和这些路径的概率 ( Q_T )。
通过这个例子,可以看到这个算法如何结合个人健康数据和医学知识来预测疾病,并且提供一条明确的解释路径。
这对于医生来说非常有用,因为它帮助他们理解病人未来健康风险的概率,并根据这些信息制定预防措施。
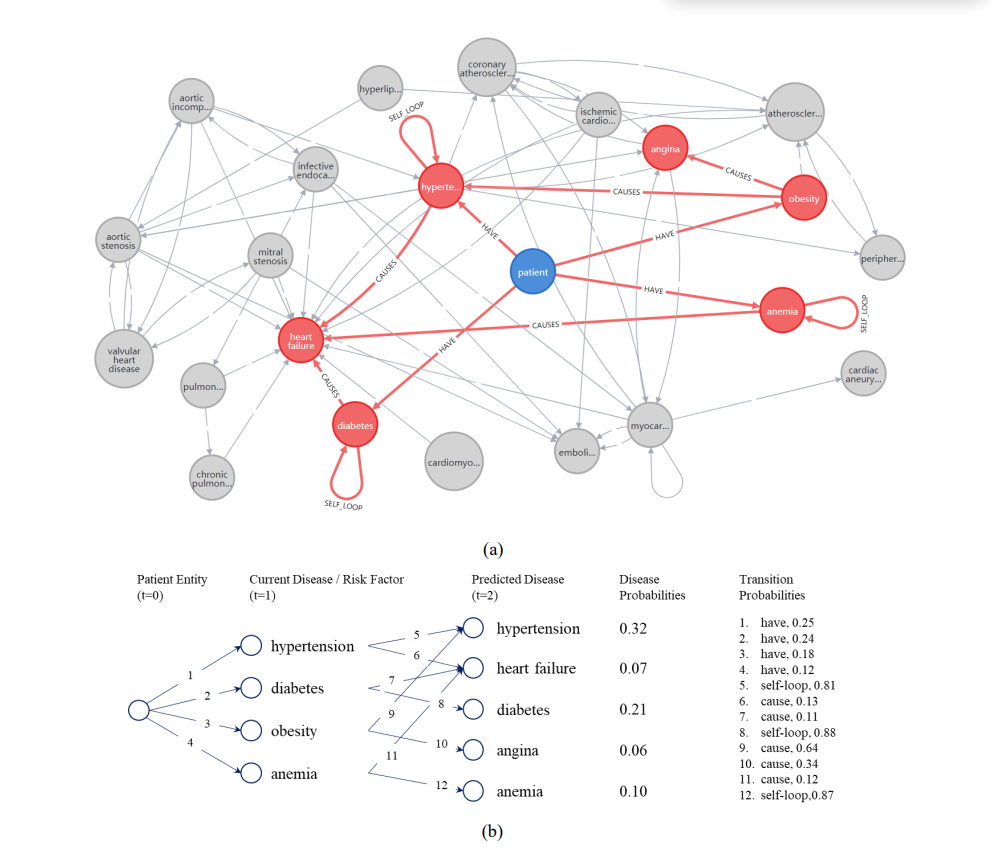
这个图包括了两部分,展示了一个基于知识图谱(KG)的疾病预测模型的工作原理和结果。
(a) 部分是一个知识图谱的可视化,其中:
- 蓝色圆圈代表患者实体。
- 红色圆圈代表被预测的疾病实体。
- 灰色圆圈代表知识图谱中的其他实体。
- 实线箭头代表疾病之间的因果关系,如 “导致”。
- 虚线箭头代表患者与疾病或风险因素之间的关系,如 “有”。
这张图展示了从患者当前的健康状况(高血压、糖尿病、肥胖、贫血)出发,模型是如何预测未来可能出现的疾病(高血压、心力衰竭、糖尿病、心绞痛、贫血)的。
(b) 部分是一个流程图和表格,总结了知识图谱中的路径和预测结果:
- 流程图左侧显示了从患者实体到当前疾病和风险因素的路径。
- 右侧表格列出了预测的疾病、它们的概率以及从当前疾病或风险因素到预测疾病的转移概率。
表格展示了每种预测疾病的概率以及相应的转移概率,例如,患者从现在的高血压、糖尿病、肥胖、贫血状态,预测未来可能继续患有高血压(自循环概率0.88)、糖尿病(自循环概率0.81)、贫血(自循环概率0.87);而心力衰竭(因为高血压、糖尿病、肥胖而发生的概率分别为0.12、0.11、0.34)和心绞痛(因肥胖而发生的概率0.64)的概率较低。
整体来看,这个图解释了一个复杂的医疗预测模型如何工作,并提供了对预测结果的深入解释。