1.项目分层
- ODS:原始数据,包含日志和业务数据
- DWD:根据数据对象为单位进行分流。比如订单、页面访问等。
- DIM:维度数据
- DWM:对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据
- DWS:根据某个维度将多个实时数据轻度聚合,形成主题宽表
- ADS:把ClickHouse中的数据根据可视化需求进行筛选聚合
(1).DWD
行为数据(kafka)。
1.过滤脏数据 --> 侧输出流 统计脏数据率
2.新老用户校验 -->前台校验不准,后台在进行逻辑分析
3.分流 --> 侧输出流 页面、启动、曝光、动作、错误
4.写入kafka
(2).DWD->DIM
1.过滤脏数据 -->删除数据的处理
2.读取配置表创建广播流
3.连接主流和广播流并处理
1).广播流数据:
a.解析数据
b.Phoenix建表
c.写入广播状态
2).主流数据:
a.读取字段
b.过滤字段
c.分流(添加SinkTable字段)
4.提取Kafka和Hbase流分别对应的位置
5.Hbase流:自定义Sink
6.Kafka流:自定义序列化方式
2.离线数仓架构
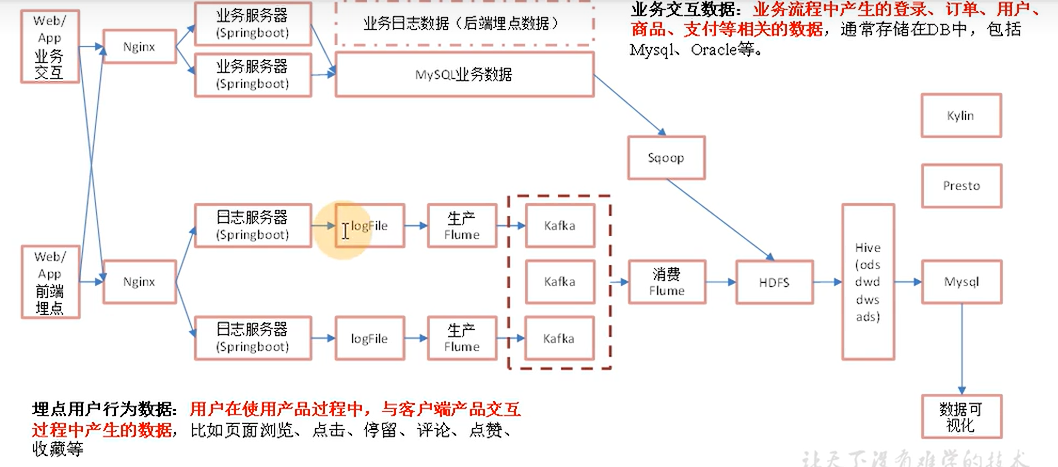
Sqoop导入数据的方式:
- 全量 where 1=1
- 增量 where 创建时间=当天
- 新增及变化 where 创建时间=当天 OR 操作时间=当天
- 特殊:只导入一次
FLUME:
- TailDirSource:
- 优点:断点续传、多目录多文件,实时监控;
- 缺点:文件更名后重新同步导致数据重复
- 注意:要使用不更名的日志打印框架(logback);修改源码,让TailDirSource只监视iNode值
- KafkaChanal:
- 优点:将数据写入kafka整了一层sink;
- 用法:
- Source+KafkaChanal+Sink
- Source+KafkaChanal
- KafkaChanal+Sink
3.实时数仓架构
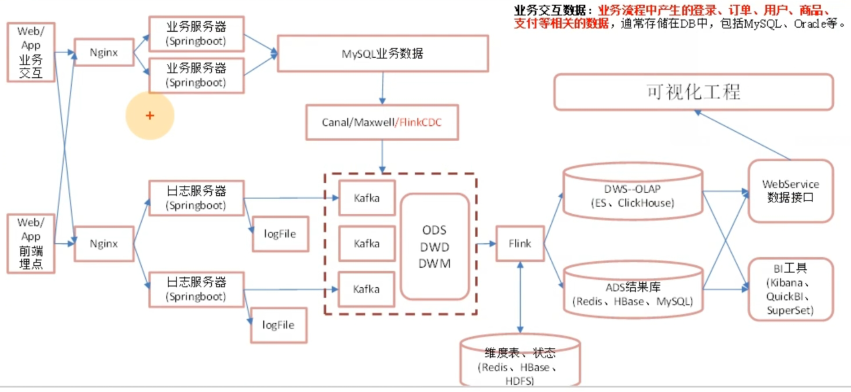
4.CDC类型
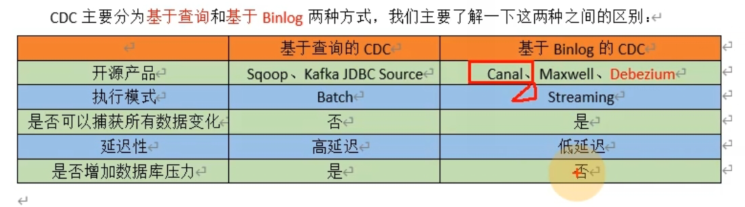
canal、maxwell、flinkcdc对比:
| canal | maxwell | flinkcdc | |
|---|---|---|---|
| 一条insert/update/delete处理多条数据 | 放在一起展示(不方便) | 分开展示 | 分开展示 |
| 初始化 | 无 | 有(单表) | 有(多库多表同时做) |
| 断点续传 | 本地磁盘 | MySQL | CK |
| 封装格式 | JSON(C/S支持自定义) | JSON | 自定义 |
| 高可用 | 集群(ZK) | 无 | 运行集群高可用 |
5.flinkcdc
官网:
https://github.com/ververica/flink-cdc-connectors
FlinkCDC同flink的版本关联:
https://ververica.github.io/flink-cdc-connectors/master/content/about.html#supported-connectors
6.业务数据采集
FlinkCDC:
- DataStream:
- 优点:多库多表
- 缺点 :需要自定义反序列化器(灵活)
- FlinkSQL
- 优点:不需要自定义反序列化器
- 缺点 :单表
7.实现动态分流