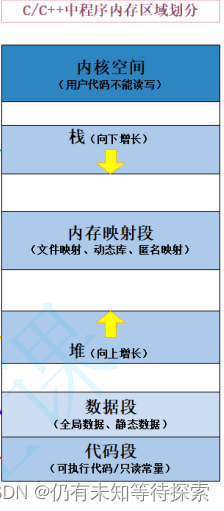
好久没有讲算法了,今天我们就来谈谈“初学者”的第二个坑,深度优先搜索,其实也就是递归。
写在最前
相信很多人都和我一样刚开始的时候完全不知道怎么下手,甚至可以说是毫无头绪,那么我们来理一理递归到底要怎么写。
简说递归
递归就是指函数多次调用他自己本身,类似于循环结构,但是递归比循环结构更加灵活,循环能完成的题都可以改写成递归的形式,但是递归能做的题不一定能写出循环结构。递归相对于循环结构代码更加简洁,思路更加清晰,但是对于初学者而言,递归的难点在于构造,即写出递归的函数。
递归的格式——三要素
void f(){
if(...)//终止条件
return ;
f();//继续调用自己
}
一:终止条件
递归一定需要一个终止条件,即满足条件后就不再递归了,这也就和循环一样,当满足循环的终止条件就不在继续循环了,否则程序就是一个死循环
二:总是在尝试将一个问题化简到更小的规模
递归的目的就是把一个大的问题分解成若干个小的问题,直到这个小问题可以直接求解为止(结
束条件)。比如求n个数之和,如果用递归编写,我们设f函数表示求和,那么f(n)表示n个数之和。我们要知道n个数之和得先知道n-1个数之和,要知道n-1个数之和得先知道n-2个数之和,一直递归下去,最后我们需要先知道1个数之和,而一个数之和就是他本身,答案可以直接得到,就可以结束递归了。
三:父问题与子问题不能有重叠的部分
由于递归是把问题规模不停的缩小,把一个大的问题分解成若干个小问题,最后再把这些小问题的结果综合得到答案,所以分解过程中,问题之间不能重叠,当然也不能遗漏。
递归和递推的区别
递推一般是顺着推,通过已知量推导出目标量,主要用于存在递推公式的题目,使用递推就比较方
便。而递归则是逆推,通过目标量倒着推导到已知量,再逆着把已知量带入得到结果,一般适用于目标的初始状态比较复杂以及没有明确的递推公式的情况。递归的好处是屏蔽了整个计算流程,只考虑结果和边界值,剩下的都由计算机来完成。但是递归相对于递推有一个最大的问题在于过程比较冗余,效率比较低,而且递归要借助系统栈,递归次数过大容易爆栈。
上手例题
其实对于我来说,多练才能有感觉,所以来练题吧!
最大公约数和最小公倍数
题目传送门
题目描述
给定两个正整数 a , b a,b a,b,求他们的最大公约数(gcd)和最小公倍数(lcm)。这两个整数均在 int 范围内。
输入格式
两个整数 a a a 和 b b b,用空格分隔。
输出格式
两个整数表示答案,用空格隔开。
样例 #1
样例输入 #1
6 15
样例输出 #1
3 30
求两个数的最大公约数可以直接多次用辗转相除法,当两个数可以整除的时候,就表示除数就是最大公约数,也可以是当除数为0时,被除数就为最大公约数,这就是循环或者递归的终止条件。而最小公倍数就是用两个数的积除以最大公约数就可以了
#include<bits/stdc++.h>
#define LL long long
using namespace std;
LL gcd(LL a,LL b){
if (a%b==0)return b;
return gcd(b,a%b);
}
int main(){
LL x,y;
cin>>x>>y;
if (x>=y)
cout<<gcd(x,y)<<" "<<x*y/gcd(x,y);
else cout<<gcd(y,x)<<" "<<x*y/gcd(y,x);
return 0;
}
这个地方教你们一个投机取巧的办法:
在c++中有个直接就可以求出最大公约数的函数那就是__gcd
所以我们就可以这样写
#include<bits/stdc++.h>
#define LL long long
using namespace std;
int main(){
LL x,y;
cin>>x>>y;
if (x>=y)
cout<<__gcd(x,y)<<" "<<x*y/__gcd(x,y);
else cout<<__gcd(y,x)<<" "<<x*y/__gcd(x,y);
return 0;
}
【模板】快速幂
题目传送门
题目描述
给你三个整数 a , b , p a,b,p a,b,p,求 a b m o d p a^b \bmod p abmodp。
输入格式
输入只有一行三个整数,分别代表 a , b , p a,b,p a,b,p。
输出格式
输出一行一个字符串 a^b mod p=s,其中
a
,
b
,
p
a,b,p
a,b,p 分别为题目给定的值,
s
s
s 为运算结果。
样例 #1
样例输入 #1
2 10 9
样例输出 #1
2^10 mod 9=7
提示
样例解释
2 10 = 1024 2^{10} = 1024 210=1024, 1024 m o d 9 = 7 1024 \bmod 9 = 7 1024mod9=7。
数据规模与约定
对于 100 % 100\% 100% 的数据,保证 0 ≤ a , b < 2 31 0\le a,b < 2^{31} 0≤a,b<231, a + b > 0 a+b>0 a+b>0, 2 ≤ p < 2 31 2 \leq p \lt 2^{31} 2≤p<231。
求乘方在我们学习循环的时候就已经掌握了,但是该题的数据范围很大,直接把n个数相乘在效率上不能满足需要,我们需要思考更加快捷的方法。比如如果我们要求2的10次方,其实没必要依次相乘,可以考虑先求出2的5次方,再把两个2的5次方相乘即可,如果我们不知道2的5次方是多少,可以再求出2的2次方=4,再把两个4相乘,最后再乘以2就得到了2的5次方=32的答案,即可以得到2的十次方=1024。快速幂就是把指数函数的指数不停的对半分,这样两部分的答案就是相同的,只需要计算一半的结果,但是要注意奇数和偶数的问题。
#include<bits/stdc++.h>
using namespace std;
int x,p,m;
long long f(int o,int q){
if (q==0)return 1;
long long cmp=f(o,q/2);
cmp=cmp*cmp%m;
if (q%2==1)cmp*=o%m;
return cmp%m;
}
int main(){
cin>>x>>p>>m;
cout<<f(x,p);
return 0;
}
1211:判断元素是否存在
题目传送门
【题目描述】
有一个集合M是这样生成的:(1) 已知k是集合M的元素; (2) 如果y是M的元素,那么,2y+1和3y+1都是M的元素;(3) 除了上述二种情况外,没有别的数能够成为M的一个元素。
问题:任意给定k和x,请判断x是否是M的元素。这里的k是无符号整数,x 不大于 100000,如果是,则输出YES,否则,输出NO。
【输入】
输入整数 k 和 x, 逗号间隔。
【输出】
如果是,则输出 YES,否则,输出NO。
【输入样例】
0,22
【输出样例】
YES
该题的本质是求数k是否可以不停的通过×2+1和×3+1的操作变成数x。我们可以用递归实现,递归终止条件为k=x,但是这个终止条件不全面,因为可能k永远变不成x,就会导致死循环,所以当k>x的时候,递归也要终止。即当k=x的时候,返回值为1,表示可能,当k>x时,返回值为0,表示不可能。只要k可以通过任意一种变换得到x,那么就表示可能,变化的时候分为两种,只要任意一种变化达到要求即为可能,所以用||连接。
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int cmp=0;char ch=0;
while (ch<'0'||ch>'9')ch=getchar();
while (ch>='0'&&ch<='9')cmp=cmp*10+ch-'0',ch=getchar();
return cmp;
}//在写的时候练了一下快读,可以试试,挺快的
int f(int a,int b){
if (a==b)return 1;
if (a>b)return 0;
return f(3*a+1,b)||f(2*a+1,b);
}
int main(){
int k=read(),x=read();
if (f(k,x)==1)cout<<"YES";
else cout<<"NO";
return 0;
}
斐波那契数列(递归)
Description
斐波那契数列是一种神奇的数列,生活中很多案例都和斐波那契数列有关,比如兔子的繁衍。已知斐波那契数列前两项分别是1、1,此后的每一项都是前两项之和,1,1,2,3,5,8,13,21,34,55,89,144…在数学上记做f(n)=f(n-1)+f(n-2),现要求出斐波那契数列的第n项。 该题问递归模板题,请问递归方法求解。
Format
Input
第一个一个正整数n表示求斐波那契数列第n项,n<=60。
Output
斐波那契数列第n项,注意答案的范围。
Samples
Sample Input 1
10
Sample Output 1
55
Limitation
对于100%的数据,保证1<=n<=60;
在我们学习循环的时候就已经练习过斐波那契数列的题,现在学习了递归之后,是否可以把斐波那契数列的求解方法改写成递归形式呢?当n=1||n=2时,答案为1,其他时候答案为f(n-1)+f(n-2)。
但是当我们编译代码时,输入n=60编译器却迟迟无法出现结果,这是为什么呢?使用递归和循环解决这个问题的效率有什么区别吗?我们会发现,相比较递推,递归的计算量比较大,即很多值重复计算,比如f(3)。在递归计算f(4)的时候,f(3),f(2),f(1)的值都计算出来了,后面再递归f(3)的时候,又算了一遍。
当n比较大的时候,使用递归的方法时,程序中有大量值被重复计算,比如先递归计算了f(3),下一次有会重新去递归计算f(3),重复了很多次,效率特别低。那么有没有办法解决这个呢?当我们计算出f(x)的答案的时候,这个答案以后如果需要用到,那么没有必要再重新去计算一次,而是可以直接调用之前算出的答案,这就就避免了同一个答案多次求解,所以我们可以开一个数组存储f(x)的答案,如果下一次需要用到f(x)的值,当f(x)的值存在的时候,直接返回。
#include<bits/stdc++.h>
using namespace std;
int a[21]={0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765};//投机取巧了一下
inline int read(){
int x=0;
char ch=0;
while (ch>'9'||ch<'0')ch=getchar();
while (ch<='9'&&ch>='0')x=x*10+ch-'0',ch=getchar();
return x;
}
long long f(int k){
if (k<=20)return a[k];
return f(k-1)+f(k-2);
}
int main(){
int n=read();
cout<<f(n);
return 0;
}
上述方法投机取巧了一下,正确的做法应该是这样
#include <bits/stdc++.h>
using namespace std;
long long n,a[101001],z,y;
long long f(long long x)
{
if(x==1||x==2)
return a[x]=1;
if(a[x]!=0)
return a[x];
return a[x]=f(x-1)+f(x-2);
}
int main()
{
cin>>z;
y=f(z);
cout<<y;
}
递归的优化
当我们使用递归求解问题的时候,如果中间答案会被多次访问到,为了效率低下,我们可以开一个数组把答案存储起来,当下次需要用到该答案的时候,直接调用结果,这样每个答案只会被求解一次,大大提高了效率。这种方法叫记忆化搜索,这种解题策略我们将会在后面详细学习。
数的计算(递归)
Description
给出自然数n,要求按如下方式构造数列:
只有一个数字n的数列是一个合法的数列。
在一个合法的数列的末尾加入一个自然数,但是这个自然数不能超过该数列最后一项的一半,可以得到一个新的合法数列。
请你求出,一共有多少个合法的数列。两个合法数列a,b不同当且仅当两数列长度不同或存在一个正整数i≤|a|,使得ai≠bi。. 该题为递归模板题,请用递归方法实现。
Format
Input
输入只有一行一个整数,表示n。
Output
输出一行一个整数,表示合法的数列个数。
Samples
Sample Input 1
6
Sample Output 1
6
Limitation
对于全部的测试点,保证1≤n≤10^3。
这道题我们在学习递推的时候做过,难点在于找出递推公式,如果我们不知道递推公式,可以直接用递归暴力搜索所有的可能性,累加起来就是答案,不过效率很低,只需要再加上记忆化搜索就是正解。对于每一个数,无论他在哪一位,可以构造的满足条件的数是不变的,所以我们可以开一个数组a[i]表示数字i可以构造的数的个数。如果当前这一位上是数字x,那么下一位可能是[x/2,0],a[x]=a[0]+a[1]+…a[x/2]。当a[x]的答案求解出来后如果下一次又分解到a[x]的时候,就可以直接调用答案。
#include<bits/stdc++.h>
using namespace std;
int a[2100];
inline int read(){
int x=0;
char ch=0;
while (ch<'0'||ch>'9')ch=getchar();
while (ch<='9'&&ch>='0')x=x*10+ch-'0',ch=getchar();
return x;
}
int f(int k){
if (a[k]!=0)return a[k];
a[k]=1;
for (int i=1;i<=k/2;i++){
a[k]+=f(i);
}
return a[k];
}
int main(){
int n=read();
cout<<f(n);
return 0;
}
分解因数(递归)
【题目描述】
给出一个正整数aa,要求分解成若干个正整数的乘积,即a=a1×a2×a3×…×an,并且1<a1≤a2≤a3≤…≤an,问这样的分解的种数有多少。注意到a=a也是一种分解。
该题为递归模板题,请问递归方法求解。
【输入】
第1行是测试数据的组数n,后面跟着n行输入。每组测试数据占1行,包括一个正整数a(1<a<32768)。
【输出】
n行,每行输出对应一个输入。输出应是一个正整数,指明满足要求的分解的种数。
【输入样例】
2
2
20
【输出样例】
1
4
【数据范围】
对于100%的数据,1<=n<=100.
该题和之前的分解不一样的地方在于不知道因数的个数,而且分解方案不止一种,用循环很难实现。我们仍然考虑用递归去尝试所有可能性再统计答案。分解的时候存在限制,即下一个因子>=上一个因子,一定要满足这个条件,否则答案就是错误的。那么我们在递归的时候就需要知道两个参数,一个是当前需要分解数x,另一个是上一个因子k,那么下一次枚举因子的范围就是[k,sqrt(x)],因为要保证下一个因子比当前因子大,所以不能枚举到x。
比如x=12,k=2时,下一次的枚举范围应该是[2,3],而不能是[2,12],如果枚举到了6,后面还剩下2,不满足小于的条件,而且由于并没有完全分解,所以这不能算是一种答案,这种答案之前一定枚举过,存在重复的情况,所以右端点一定是i*i<=x。当一个数分解到不能在分解为止,说明这就是一种具体的方案,答案数累加1,因为答案需要在不同的函数中累加,所以计数器要开成全局变量,这样答案才会一直累加。
该题是否可以用记忆化搜索呢?对于一个数x,他的分解方式是相同的,看上去可以用记忆化,但是实际上不行,因为要考虑上一次分解的因子是多少,上一次分解的因子不同,对于数x分解的方式也不同,比如同样分解到了16,上一个因子是2,那么下一个因子可以从2开始,但是如果上一个因子是4,那么下一个因子就只能从4开始,最终的答案是不一样的,所以该题不可以用记忆化搜索。一道题是否可以用记忆化搜索关键在于当前这种状态下的答案是否一定相同,如果一定相同,那么可以,否则就不可以。
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int x=0;
char ch=0;
while (ch<'0'||ch>'9')ch=getchar();
while (ch<='9'&&ch>='0')x=x*10+ch-'0',ch=getchar();
return x;
}
int f(int k,int st){
int cnt=0;
if (k==1)return 1;
for (int i=st;i<=k;i++){
if (k%i==0)cnt+=f(k/i,i);
}
return cnt;
}
int main(){
int n=read();
for (int i=0;i<n;i++){
int cmp=read();
cout<<f(cmp,2)<<endl;
}
return 0;
}
艾玛累死了,码了7000多个字,如果这样你都还不会,那就真的没救了,想想接下来还要讲回溯就心累,赶快把你们手中的赞和收藏送出来吧!