PrimeKG:为精准医学分析设计的多模态知识图谱
- PrimeKG简介
- 数据资源和覆盖范围
- 构建方法和技术细节
- PrimeKG多模态知识图谱的概览
- 构建PrimeKG的过程
- PrimeKG 数据
- 多模态特性和临床应用
- PrimeKG 设计逻辑
论文:https://www.nature.com/articles/s41597-023-01960-3
PrimeKG简介
PrimeKG,一个面向精准医学的知识图谱,它提供了疾病的整体视图。
PrimeKG整合了20个高质量资源,以4050249种关系描述了17080种疾病,这些关系代表了10个主要的生物学尺度,包括疾病相关的蛋白质扰动、生物学过程和途径、解剖学和表型尺度,以及所有已批准和试验性药物及其治疗作用。
他们将PrimeKG的图形结构与药物和疾病临床指南的文本描述相结合,以实现多模式分析。
与其他知识图谱不同的是,PrimeKG特别强调了包括药物的适应症、禁忌症和非标签用途等通常缺失的药物-疾病关系。
数据资源和覆盖范围
PrimeKG的构建基于包括Bgee基因表达知识库、DisGeNET基因-疾病关联数据库、DrugBank药物数据库在内的20种主要数据资源。
这些资源提供了包括蛋白质、基因、药物、疾病、解剖学结构和生物过程等广泛的生物医学实体数据,确保了知识图谱的丰富性和多样性。
构建方法和技术细节
在构建PrimeKG过程中,我们采用了一系列技术步骤来标准化和整合各种数据资源。
这包括选择适合每种节点的本体、协调数据集到统一格式,并解决不同数据源之间的重叠问题。
此外,我们还对药物和疾病节点进行了临床特征的补充,包括药物的作用机理和疾病的临床描述,以增强图谱的实用性和信息的完整性。
PrimeKG多模态知识图谱的概览
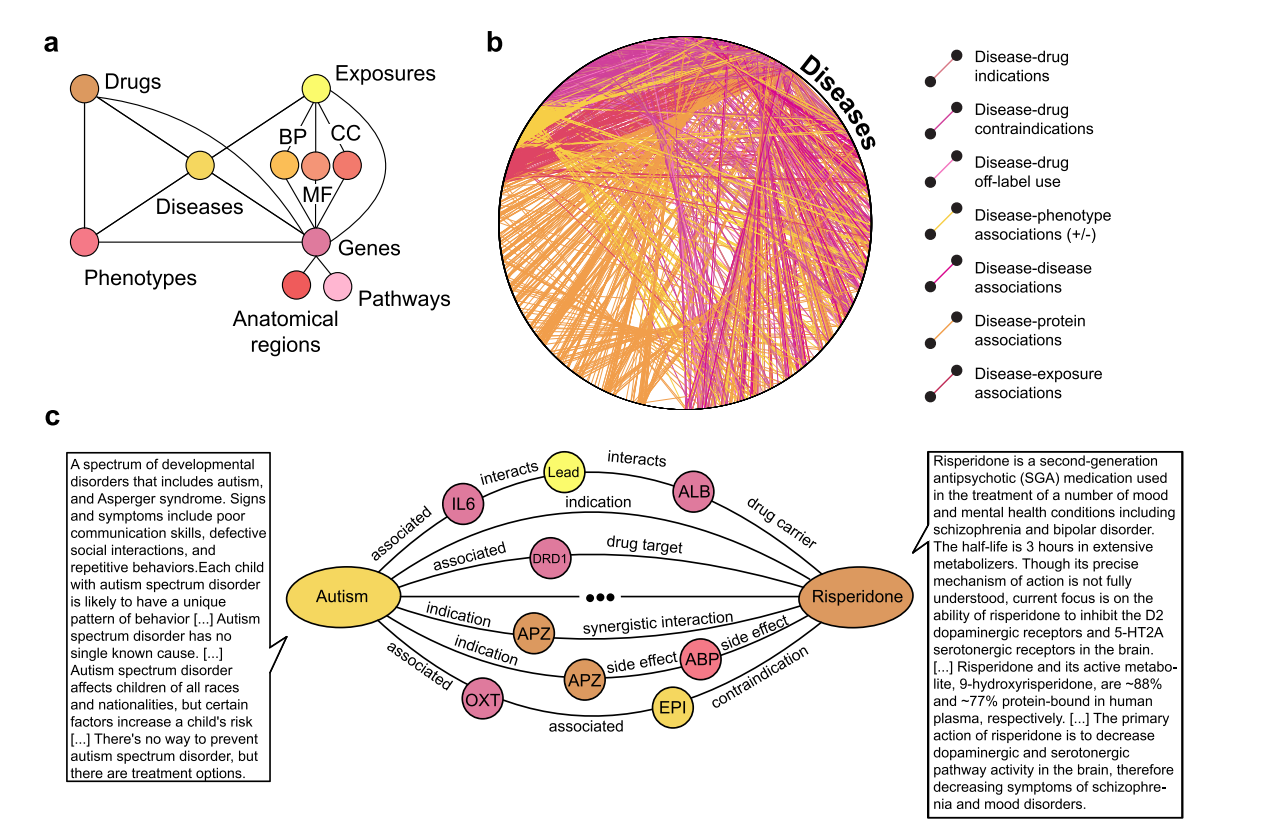
在子图a中,显示了知识图谱中不同类型的节点及其相互之间的关系。
例如,药物、疾病、基因等节点之间是如何通过不同类型的边相连的。
子图b展示了所有疾病节点在PrimeKG中与其他节点类型的关系。
在子图c中,提供了一个具体案例,展示了自闭症(Autism)和利培酮(Risperidone)之间的路径,以及对应药物和疾病节点的文本描述,这显示了知识图谱的多模态特性。
构建PrimeKG的过程
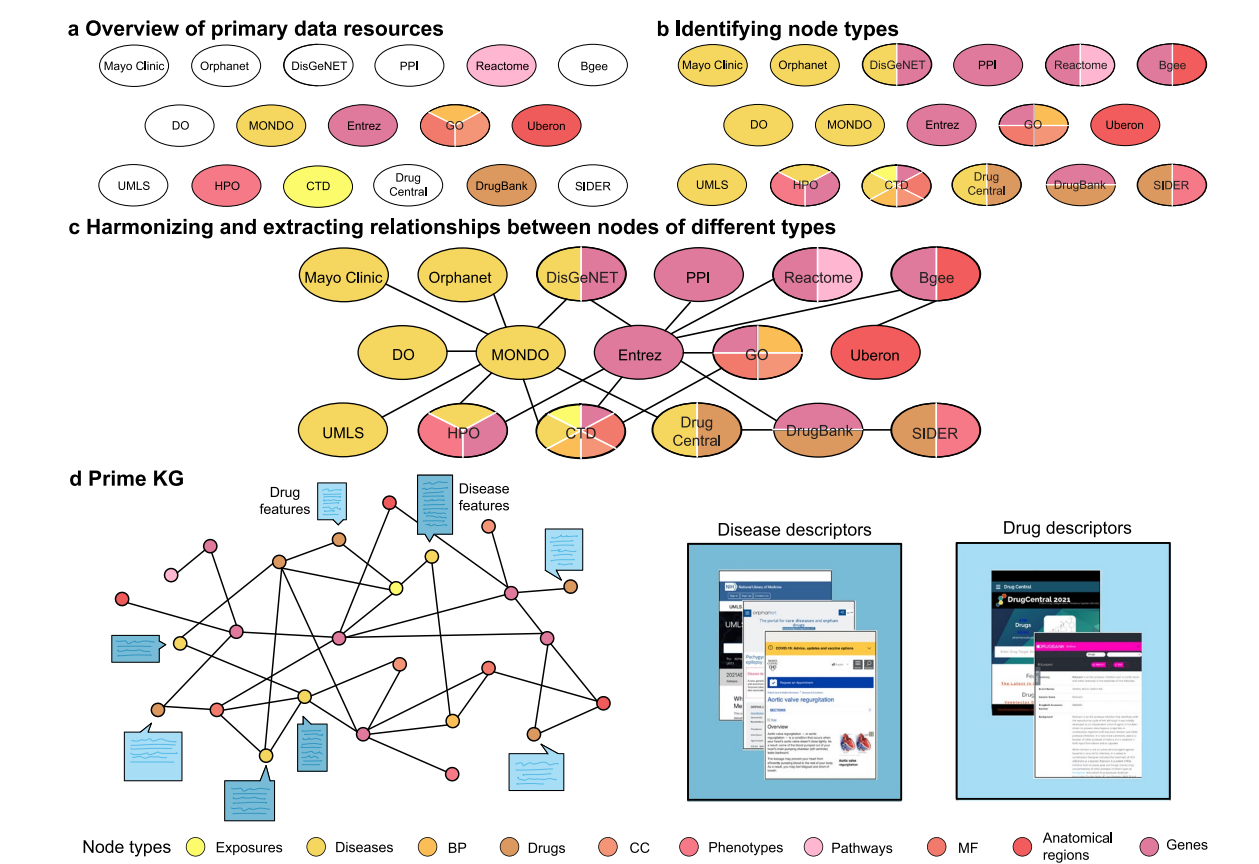
子图a列出了为PrimeKG策划的20种主要数据资源,以及它们如何用于确定不同节点类型的唯一标识符。
子图b和c展示了如何确定节点类型,并从各个数据源中提取不同类型节点之间的关系。
最后,子图d描绘了整个PrimeKG,以及药物和疾病节点的临床特征是如何被集成的。
PrimeKG 数据

PrimeKG中不同类型节点的数量和所占的百分比,以及每种节点类型所对应的数据来源。
例如,疾病节点由来自多个数据源(如CTD、DisGeNET、Disease Ontology等)的信息组成。
多模态特性和临床应用
PrimeKG不仅是一个生物医学数据的集合,它还融合了临床意义深远的文本描述,使其成为一个真正多模态的知识图谱。
这一特性使PrimeKG能够在科研和临床应用中发挥重要作用,特别是通过自闭症谱系障碍的案例研究,我们验证了其在解释疾病临床表现方面的相关性和有效性。
PrimeKG 设计逻辑
问题1: 如何在单一平台上整合分散在不同数据源的生物医学信息?
解法: 数据集成和标准化
-
子解法1: 选择适合每种节点类型的本体
- 特征: 确保知识图谱中不同数据源的信息能够相互对应。
- 例子: 使用MONDO本体统一疾病信息,因为它融合了多个疾病相关的本体,确保了数据的一致性。
-
子解法2: 将数据格式化为标准化的格式并解决重叠问题
- 特征: 使不同来源的数据能够兼容并减少重复。
- 例子: 对药物-疾病关系中的数据进行重叠检查,确保每一种药物或疾病在图谱中只对应一个唯一的节点。
-
子解法3: 构建一个包含所有关系的网络图
- 特征: 显示不同生物医学实体之间的关联性。
- 例子: 在知识图谱中,疾病节点被密集地连接到药物、基因、表型等其他节点类型,揭示了潜在的生物学机制。
问题2: 如何使知识图谱支持临床决策和科研?
解法: 加入多模态临床信息
-
子解法1: 融合文本描述和数值数据
- 特征: 提供对药物和疾病更全面的理解。
- 例子: 药物节点不仅包含作用机理的描述,还有分子重量等量化信息,这有助于研究药物动力学和药效学。
-
子解法2: 更新和维护知识图谱
- 特征: 确保知识图谱反映最新的科研发现和临床指南。
- 例子: 通过定期整合新的临床试验数据和治疗指南,PrimeKG能够支持最新的精准医疗研究。
这样的解法组合不仅解决了数据分散和标准化的问题,还确保了知识图谱的实用性和时效性,使其能够适应快速发展的医学领域的需求。