第五章 深度学习
四、Tensorflow
8. 模型保存与加载
8.1 什么是模型保存与加载
模型训练可能是一个很长的过程,如果每次执行预测之前都重新训练,会非常耗时,所以几乎所有人工智能框架都提供了模型保存与加载功能,使得模型训练完成后,可以保存到文件中,供其它程序使用或继续训练。
8.2 模型保存与加载 API
模型保存与加载通过 tf.train.Saver 对象完成,实例化对象:
- saver = tf.train.Saver(var_list=None, max_to_keep=5) - var_list: 要保存和还原的变量,可以是一个 dict 或一个列表 - max_to_keep: 要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件
(如 max_to_keep=5 表示保留 5 个检查点文件)
保存:saver.save(sess, ‘/tmp/ckpt/model’)
加载:saver.restore(sess, ‘/tmp/ckpt/model’)
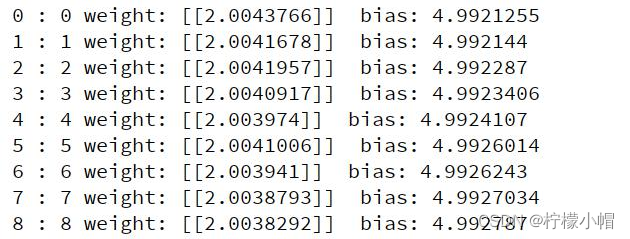
8.3 案例 1:模型保存/加载

从执行结果可以看出,如果模型之前经过训练,直接从之前的参数值开始执行迭代,而不是从第一次给的初始值开始。
9. 数据读取
9.1 文件读取机制
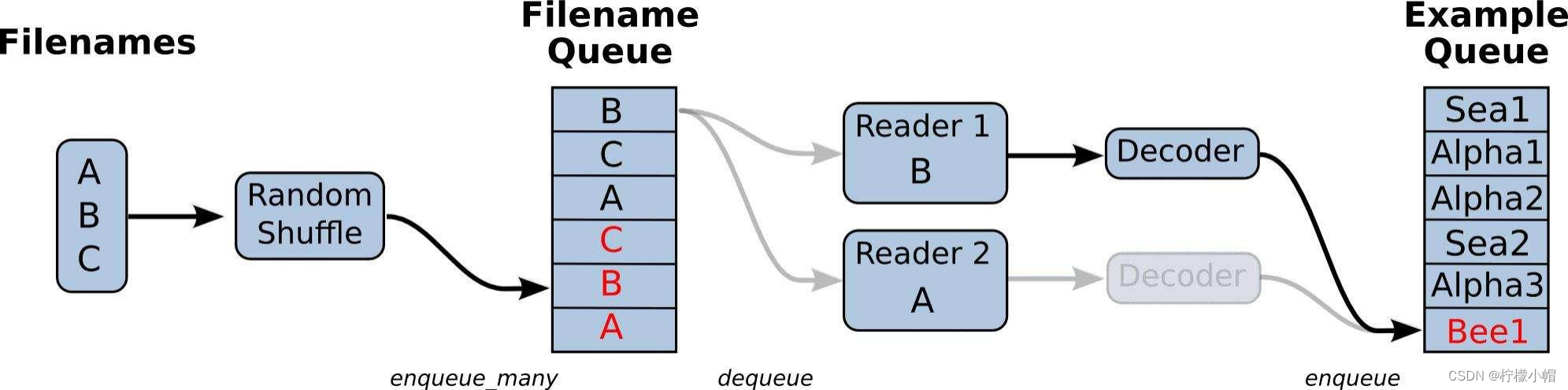
TensorFlow 文件读取分为三个步骤:
- 第一步:将要读取的文件放入文件名队列
- 第二步:读取文件内容,并实行解码
- 第三步:批处理,按照指定笔数构建成一个批次取出
9.2 文件读取 API
9.2.1 文件队列构造
生成一个先入先出的队列, 文件阅读器会需要它来读取数据
- tf.train.string_input_producer(string_tensor, shuffle=True)
- string_tensor: 含有文件名的一阶张量
- shuffle: 是否打乱文件顺序
- 返回:文件队列
9.2.2 文件读取
- 文本文件读取:tf.TextLineReader
- 读取 CSV 文件,默认按行读取
- 二进制文件读取:tf.FixedLengthRecordReader(record_bytes)
- 读取每个记录是固定字节的二进制文件
- record_bytes: 每次读取的字节数
- 通用读取方法:read(file_queue)
- 从队列中读取指定数量(行,字节)的内容
- 返回值:一个 tensor 元组,(文件名, value)
9.2.3 文件内容解码
解码文本文件:tf.decode_csv(records, record_defaults)
- 将 CSV 文件内容转换为张量,与 tf.TextLineReader 搭配使用
- 参数:
- records: 字符串,对应文件中的一行
- record_defaults: 类型
- 返回:tensor 对象列表
解码二进制文件:tf.decode_raw(input_bytes, out_type)
- 将字节转换为由数字表示的张量,与 tf.FixedLengthRecordReader 搭配使用
- 参数:
- input_bytes - 待转换字节
- out_type - 输出类型
- 返回:转换结果
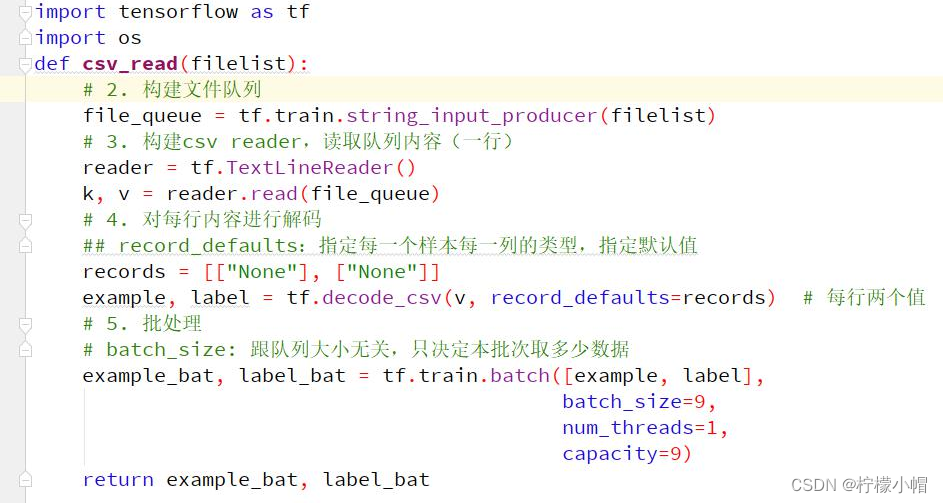
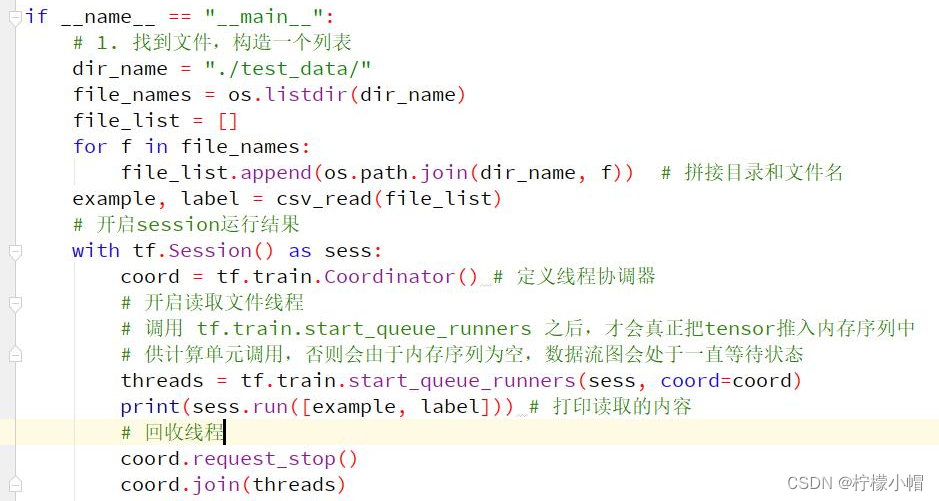
9.3 案例 2:CSV 文件读取
9.4 图片文件读取 API
图像读取器:tf.WholeFileReader
- 功能:将文件的全部内容作为值输出的 reader
- read 方法:读取文件内容,返回文件名和文件内容
图像解码器:
- tf.image.decode_jpeg(constants) : 解码 jpeg 格式
- tf.image.decode_png(constants) : 解码 png 格式
- 返回值:3-D 张量,[height, width, channels]
修改图像大小:tf.image.resize(images, size)
- images:图片数据,3-D 或 4-D 张量
- 3-D:[长,宽,通道]
- 4-D:[数量, 长,宽,通道]
- size:1-D int32 张量,[长、宽] (不需要传通道数)
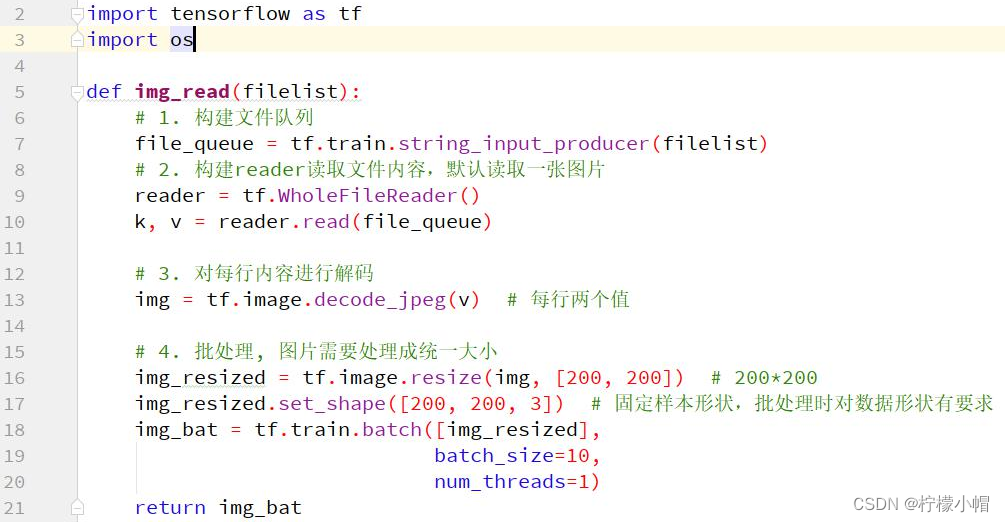
9.5 案例 3:图片文件读取
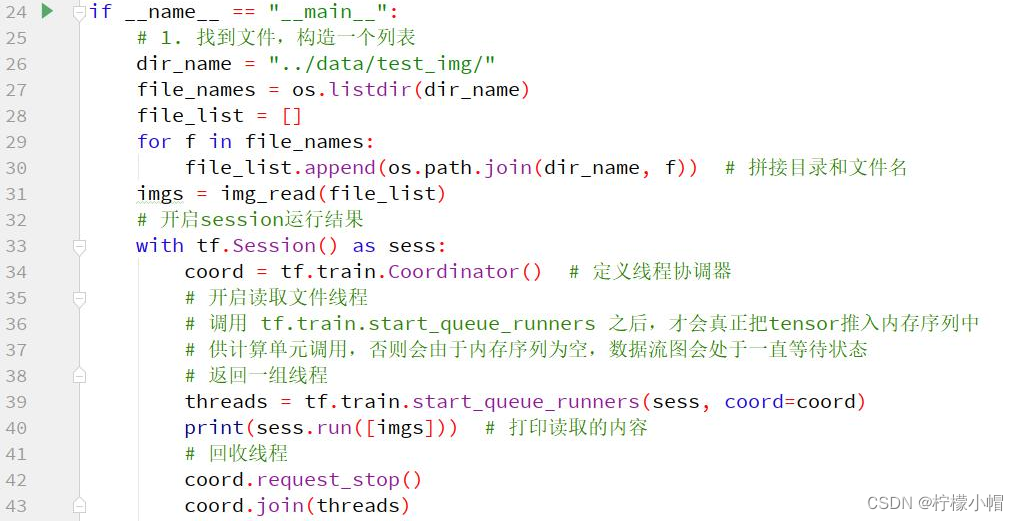
10. 手写体识别
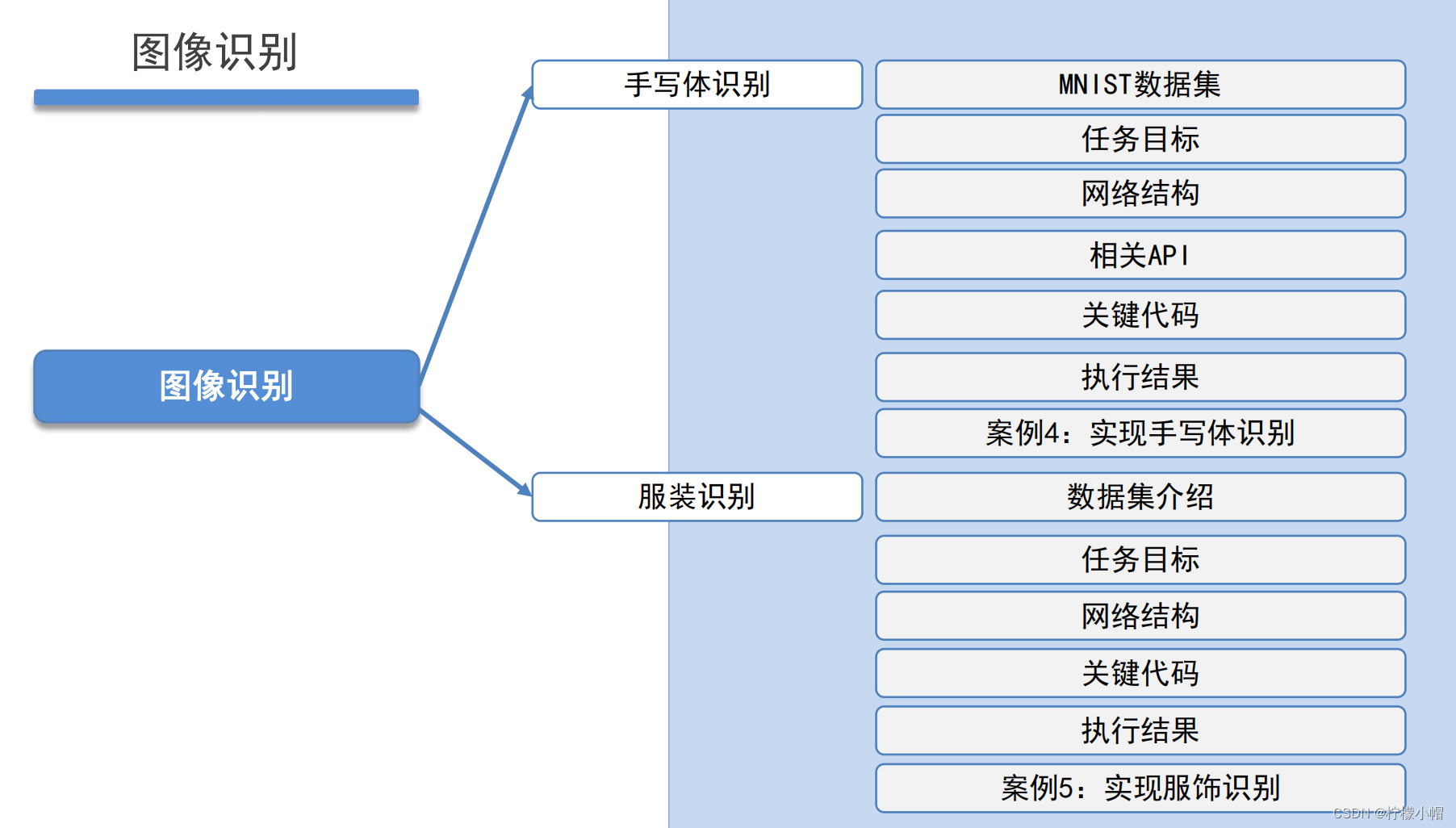
10.1 MNIST 数据集
手写数字的数据集,来自美国国家标准与技术研究所(National Institute of Standards and Technology,NIST),发布于 1998 年。
样本来自 250 个不同人的手写数字,50%高中学生,50%是人口普查局的工作人员。
数字从 0 ~ 9,图片大小是 28×28 像素,训练数据集包含 60000 个样本,测试数据集包含 10000 个样本。数据集的标签是长度为 10 的一维数组,数组中每个元素索引号表示对应数字出现的概率。
下载地址:http://yann.lecun.com/exdb/mnist/
10.2 任务目标
根据训练集样本进行模型训练
保存模型
加载模型,用于新的手写体数字识别
10.3 网络结构
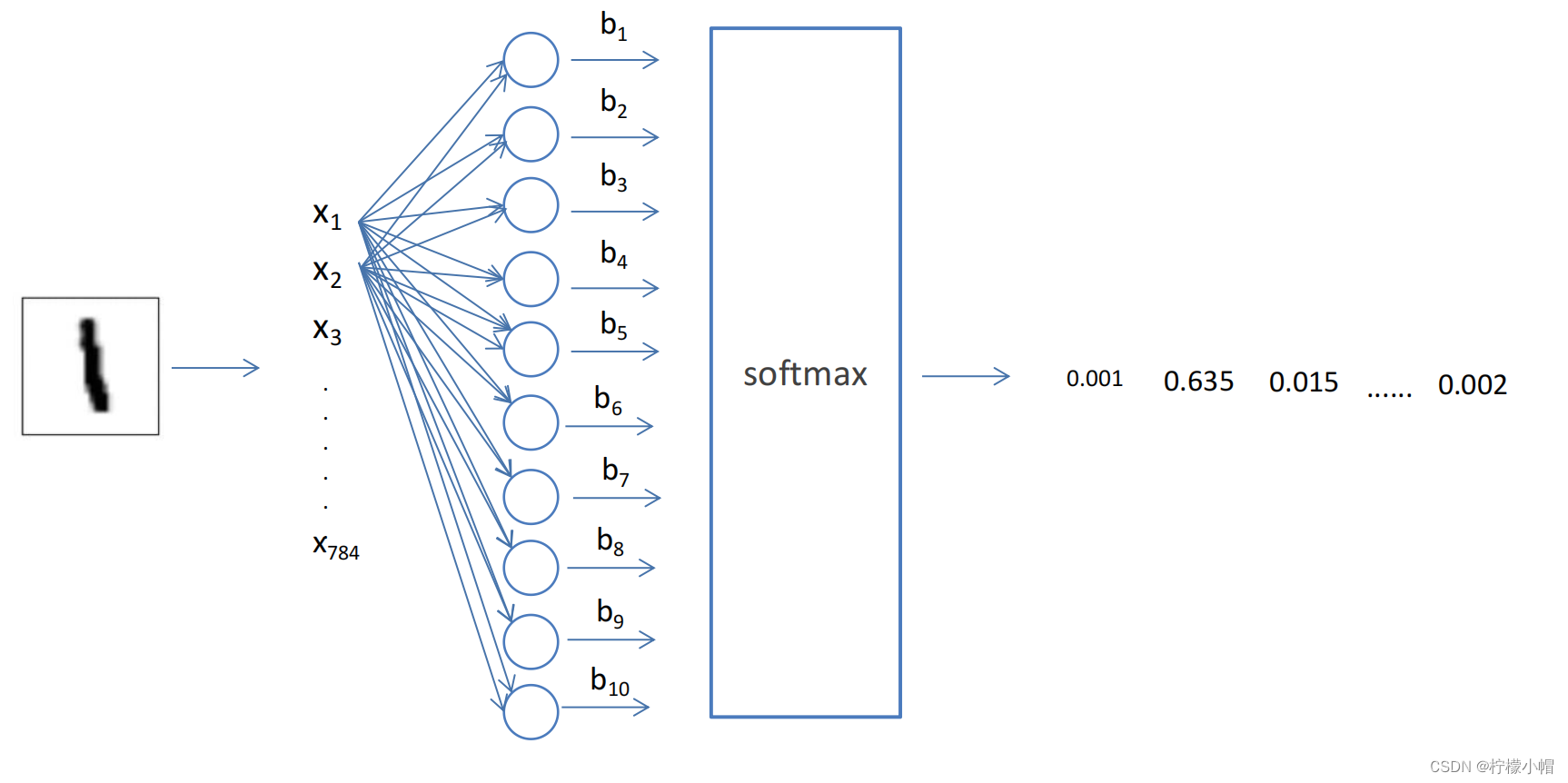
10.4 相关 API
tf.matmul():执行矩阵乘法计算
tf.nn.softmax():softmax 激活函数
tf.reduce_sum():指定维度上求张量和
tf.train.GradientDescentOptimizer():优化器,执行梯度下降
tf.argmax():返回张量最大元素的索引值
10.5 关键代码
定义数据

模型搭建
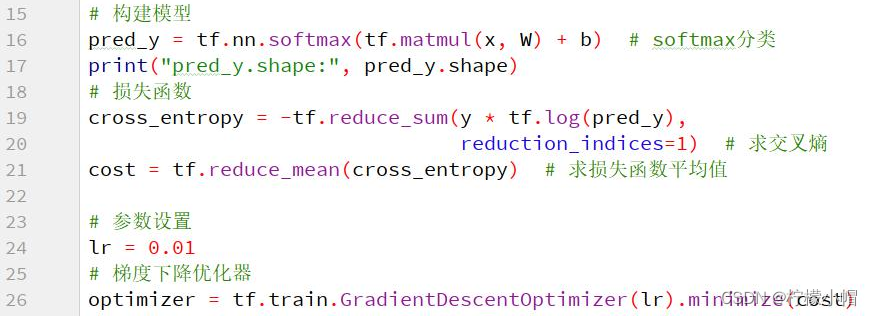
执行训练
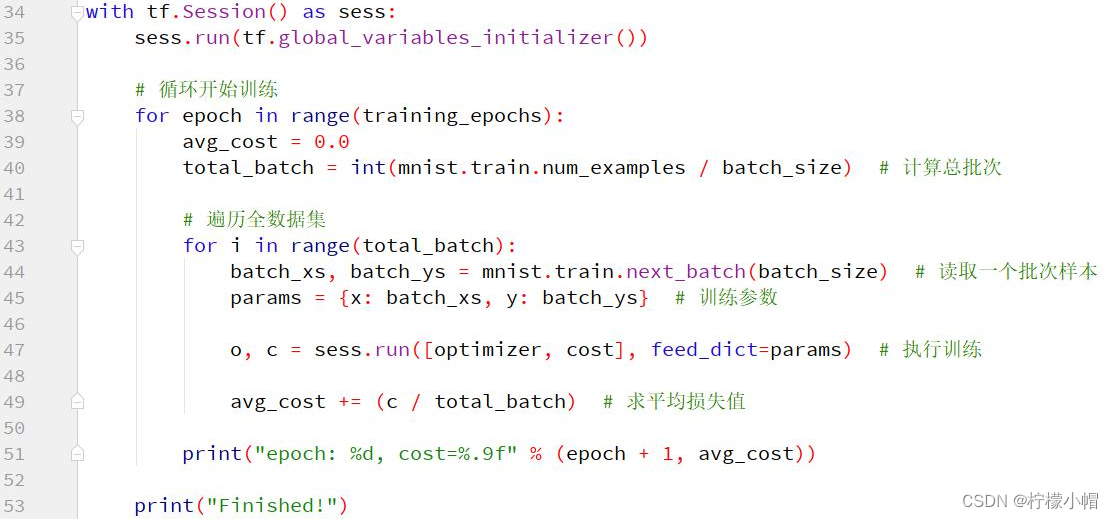
模型评估

模型测试

10.6 执行结果
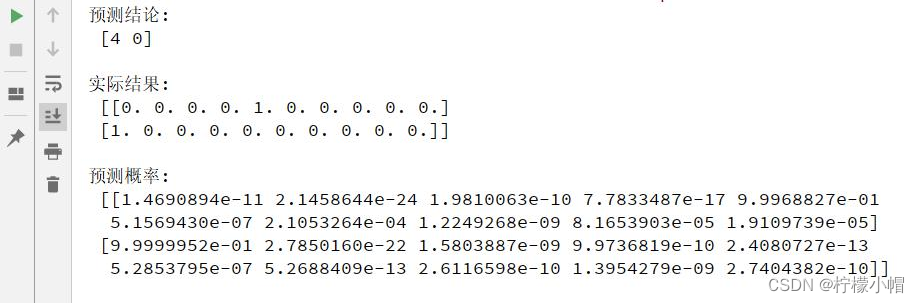
11. 服饰识别
11.1 数据集介绍
是来自 Zalando 文章的数据集,是时尚版的 MNIST。包括 60,000 个训练集数据,10,000 个测试集数据,每个数据为 28x28 灰度图像,一共有 10 类:
| 0 | T-shirt/top | T 恤 |
|---|---|---|
| 1 | Trouser | 裤子 |
| 2 | Pullover | 套衫 |
| 3 | Dress | 衣服 |
| 4 | Coat | 外套 |
| 5 | Sandal | 凉鞋 |
| 6 | Shirt | 衬衫 |
| 7 | Sneaker | 运动鞋 |
| 8 | Bag | 包 |
| 9 | Ankle boot | 短靴 |

11.2 任务目标
搭建卷积神经网络模型
根据训练集样本进行模型训练
用于新的服饰图片识别
11.3 网络结构
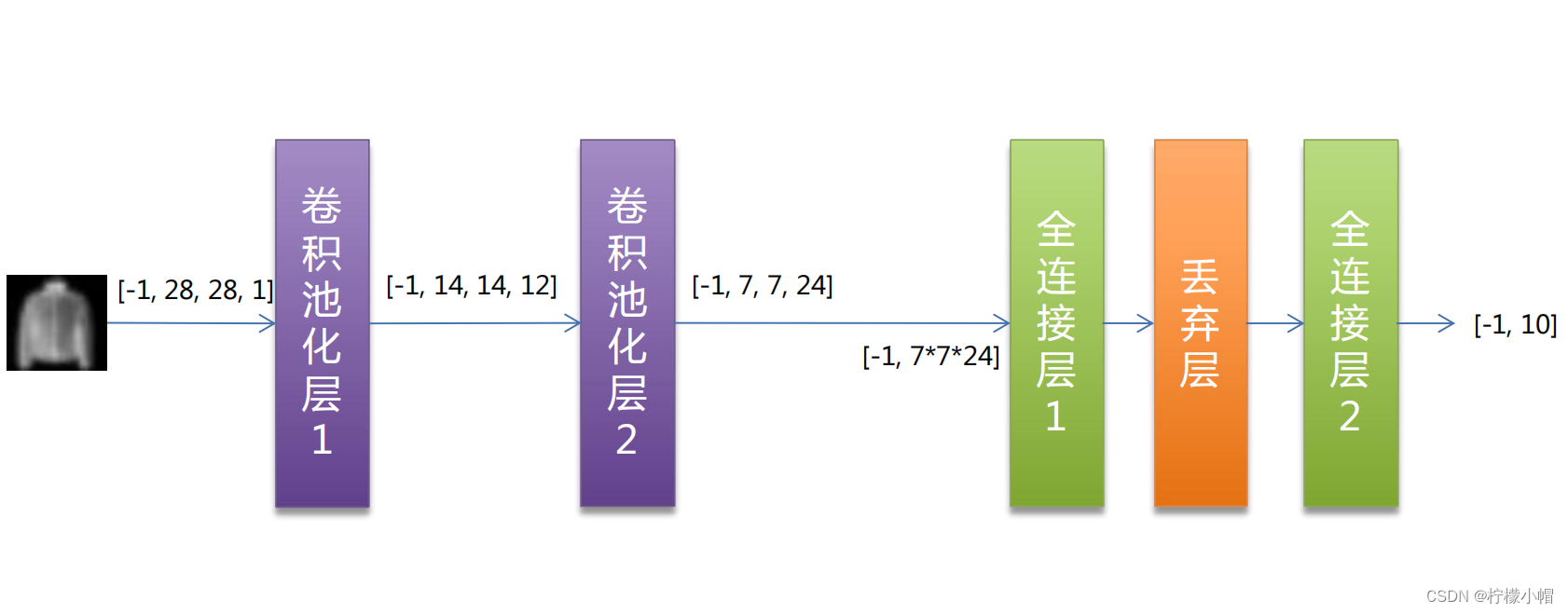
11.4 关键代码



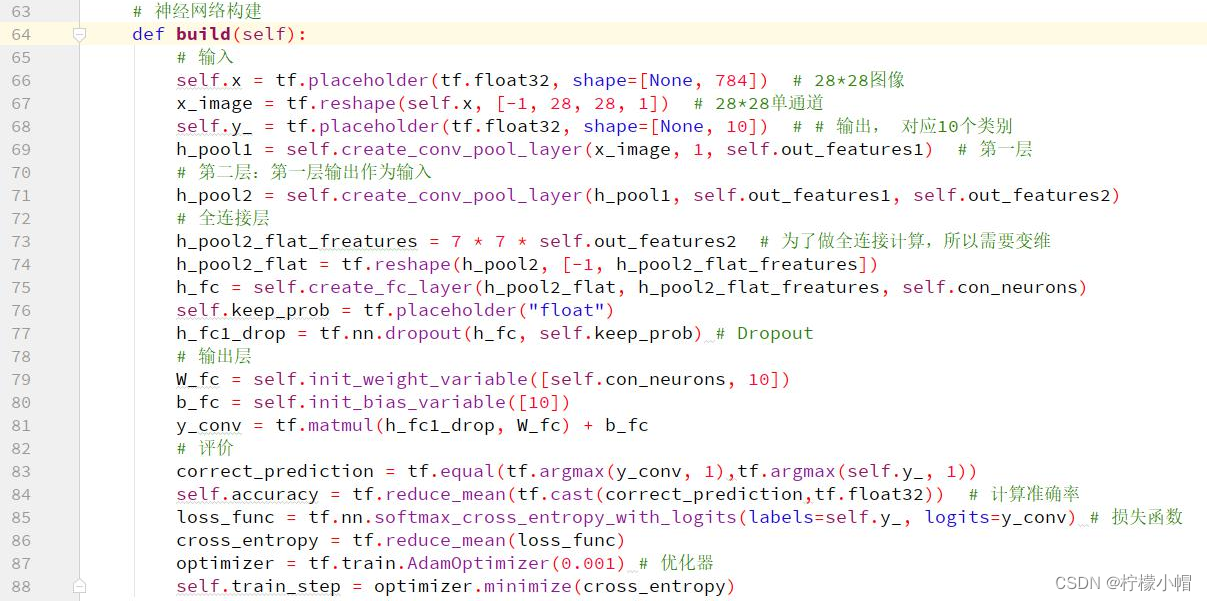
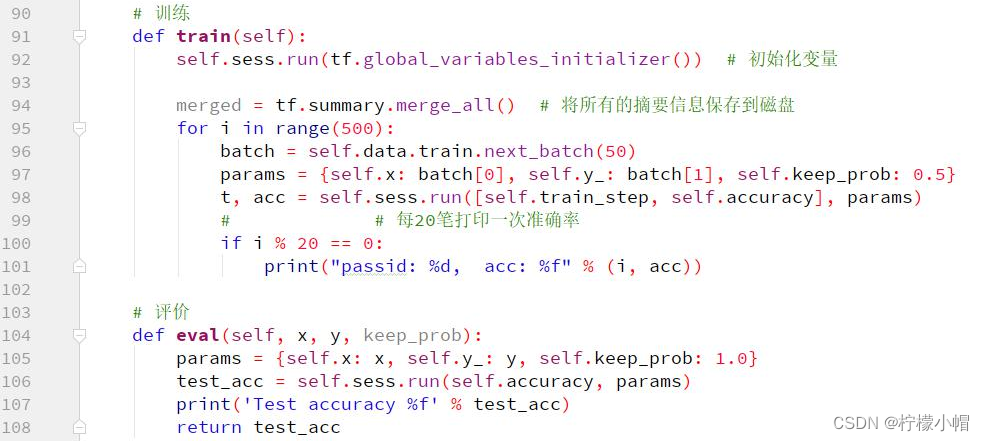
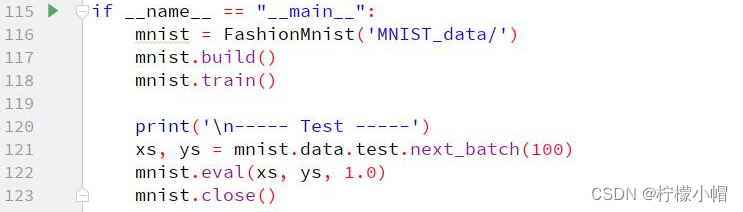
11.5 执行结果
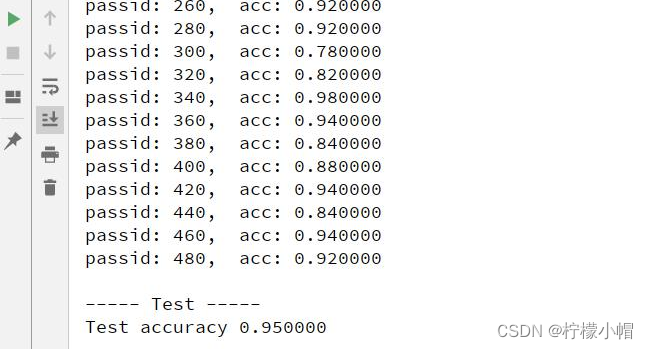












![数据结构课程设计(八)---排序算法比较 [排序]](https://img-blog.csdnimg.cn/direct/eda8ecd7ff3f4943b307844d3fe040b0.png)