b站课程视频链接:
https://www.bilibili.com/video/BV19x411X7C6?p=1
腾讯课堂(最新,但是要花钱,我花99😢😢元买了,感觉讲的没问题,就是知识点结构有点乱,有点废话):
https://ke.qq.com/course/3707827#term_id=103855009
本笔记前面的笔记参照b站视频,【后面的画图】参考了付费视频
笔记顺序做了些调整【个人感觉逻辑顺畅】,并删掉一些不重要的内容,以及补充了个人理解
系列笔记目录【持续更新】:https://blog.csdn.net/weixin_42214698/category_11393896.html
文章目录
- 数据转换之dplyr包
- 1. 对单表格的操作
- 2. dplyr包的统计函数
- 3. 链式操作符 ——“%>% ”
- 4. 对双表格的操作
- 5.数据集的集合运算
数据转换之dplyr包
dplyr包不仅可以对单个表格进行操作,也可以对双表格进行操作。 (使用R中的iris数据集做演示)
install.packages("dplyr")
library(dplyr)
# 列出该包的函数
ls("package:dplyr")
因为dplyr包有很多函数,为了防止dplyr包中的函数名与其他函数产生冲突,使用时前面加上“包名::”
1. 对单表格的操作
# 过滤函数 选出 Sepal.Length>7 的行
dplyr::filter(iris,Sepal.Length>7)
#去除重复
# rbind是行合并 iris[1:10, ]是前10行,iris[1:15, ]是前15行 最终结果是只有前15行
dplyr::distinct(rbind(iris[1:10, ] , iris[1:15, ]))
#slice是切片的意思,可以用于取出数据任意行
dplyr::slice(iris,10:15)
#随机取样10行
dplyr::sample_n(iris,10)
#按比例随机取样 0.1是比例
dplyr::sample_frac(iris,0.1)
#按照iris中的花萼长度Sepal.Length进行排序
dplyr::arrange(iris,Sepal.Length)
#降序
dplyr::arrange(iris,desc(Sepal.Length))
#添加新的变量new,其值是Sepal.Length+Petal.Length
dplyr::mutate(iris,new=Sepal.Length+Petal.Length)
# 根据Species进行分组
> dplyr::group_by(iris,Species)
# A tibble: 150 × 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# … with 140 more rows
# ℹ Use `print(n = ...)` to see more rows
select函数:dplyr包中的数据框取子集功能,比R自带的subset函数更加强大。

2. dplyr包的统计函数
> summarise(iris,avg=mean(Sepal.Length))
avg
1 5.843333
> summarise(iris,sum=sum(Sepal.Length))
sum
1 876.5
3. 链式操作符 ——“%>% ”
它的功能是用于实现将一个函数的输出传递给下一个函数,作为下一个函数的输入。
在RStudio中可以使用ctrl+shift+M快捷键输出来。
#输出mtcars中的第10到20行
head(mtcars,20) %>% tail(10)
对iris数据集先进行分组,再求平均,最后排序
> iris %>% group_by(Species)
# A tibble: 150 × 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# … with 140 more rows
# ℹ Use `print(n = ...)` to see more rows
> iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width))
# A tibble: 3 × 2
Species avg
<fct> <dbl>
1 setosa 3.43
2 versicolor 2.77
3 virginica 2.97
> iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width)) %>%arrange(avg)
# A tibble: 3 × 2
Species avg
<fct> <dbl>
1 versicolor 2.77
2 virginica 2.97
3 setosa 3.43
4. 对双表格的操作

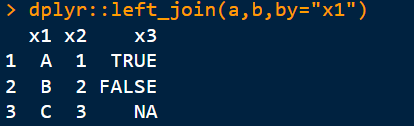
1)左连接 (以左表为基表)
dplyr::left_join(a,b,by=“x1”)
2)右连接 (以右表为基表)
dplyr::right_join(a,b,by=“x1”)
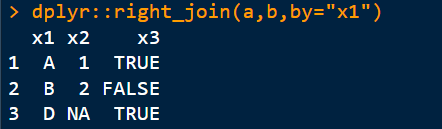
3)内连接:取x1的交集
dplyr::inner_join(a,b,by=“x1”)
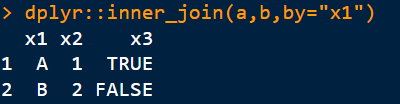
4)全连接:取x1的并集
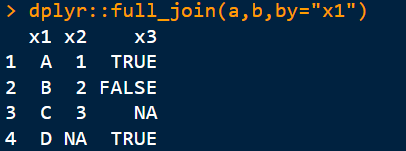
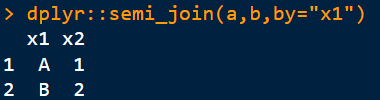
5)半连接:a与b的交集,把b中有的,a中没有的(即x3列)去掉
dplyr::semi_join(a,b,by=“x1”)
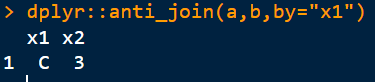
6)反连接:a与b的补集,保留a中有,而b中没有的观测
dplyr::anti_join(a,b,by=“x1”)
5.数据集的集合运算
# 前20行
first <- slice(mtcars,1:20)
# 第10~30行
second <- slice(mtcars,10:30)
1)取数据集交集:intersect(first,second)
2)取数据集并集:dplyr::union_all(first,second)
3)取非冗余的数据集并集: dplyr::union(first,second)
4)取first的补集:setdiff(first,second)