代码链接见文末
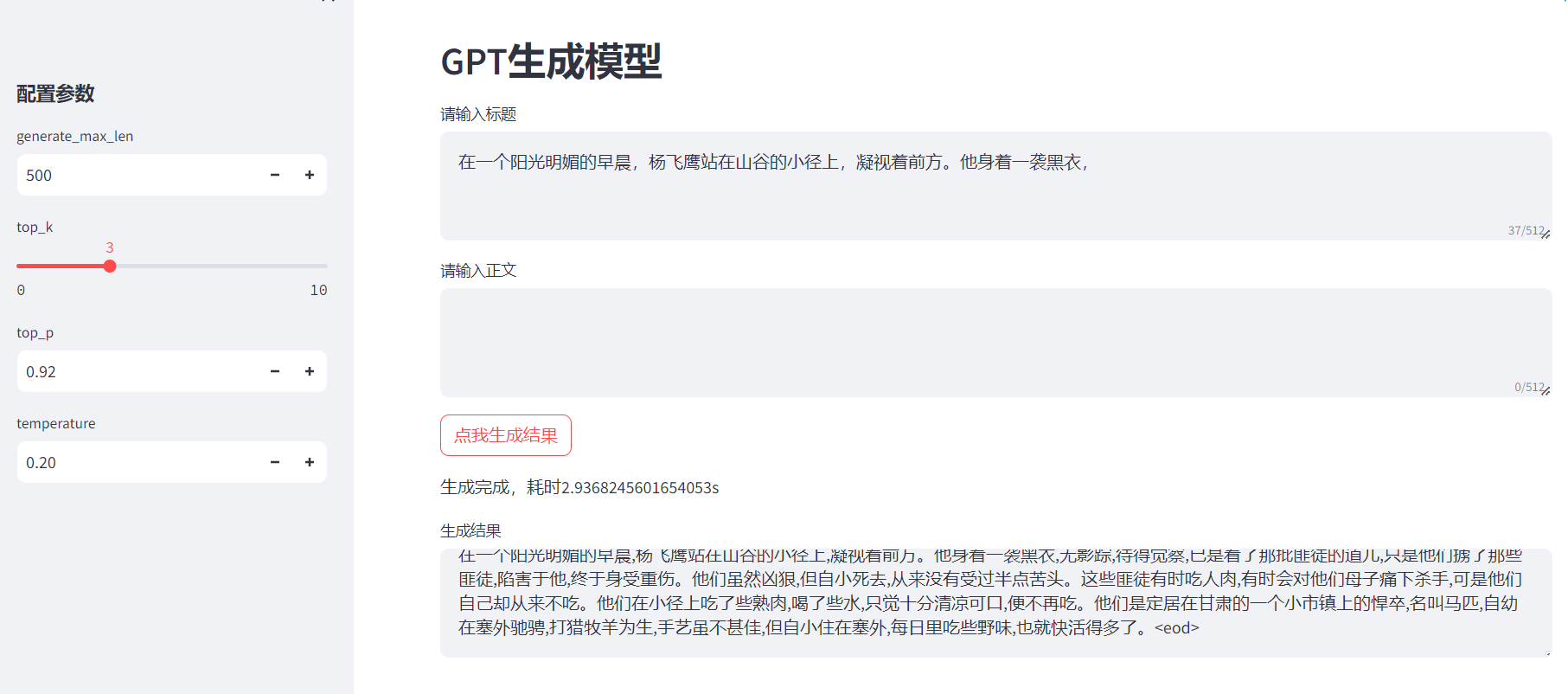
效果图:
1.数据样本生成方法
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
其中train.pkl是处理后的文件
因此,我们首先需要执行preprocess.py进行预处理操作,配置参数:
--data_path data/novel --save_path data/train.pkl --win_size 200 --step 200

其中--vocab_file是语料表,一般不用修改,--log_path是日志路径

预处理流程如下:
- 首先,初始化tokenizer
-
读取作文数据集目录下的所有文件,预处理后,对于每条数据,使用滑动窗口对其进行截断
-
最后,序列化训练数据
代码如下:
# 初始化tokenizer
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")#pip install jieba
eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
sep_id = tokenizer.sep_token_id
# 读取作文数据集目录下的所有文件
train_list = []
logger.info("start tokenizing data")
for file in tqdm(os.listdir(args.data_path)):
file = os.path.join(args.data_path, file)
with open(file, "r", encoding="utf8")as reader:
lines = reader.readlines()
title = lines[1][3:].strip() # 取出标题
lines = lines[7:] # 取出正文内容
article = ""
for line in lines:
if line.strip() != "": # 去除换行
article += line
title_ids = tokenizer.encode(title, add_special_tokens=False)
article_ids = tokenizer.encode(article, add_special_tokens=False)
token_ids = title_ids + [sep_id] + article_ids + [eod_id]
# train_list.append(token_ids)
# 对于每条数据,使用滑动窗口对其进行截断
win_size = args.win_size
step = args.step
start_index = 0
end_index = win_size
data = token_ids[start_index:end_index]
train_list.append(data)
start_index += step
end_index += step
while end_index+50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集
data = token_ids[start_index:end_index]
train_list.append(data)
start_index += step
end_index += step
# 序列化训练数据
with open(args.save_path, "wb") as f:
pickle.dump(train_list, f)2.模型训练过程
(1) 数据与标签
在训练过程中,我们需要根据前面的内容预测后面的内容,因此,对于每一个词的标签需要向后错一位。最终预测的是每一个位置的下一个词的token_id的概率。
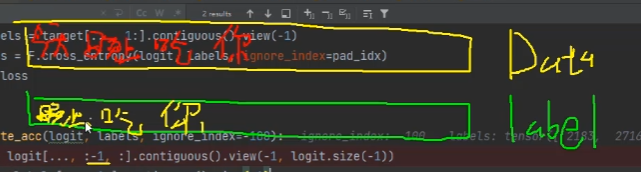
(2)训练过程
对于每一轮epoch,我们需要统计该batch的预测token的正确数与总数,并计算损失,更新梯度。
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,
epoch, args):
model.train()
device = args.device
ignore_index = args.ignore_index
epoch_start_time = datetime.now()
total_loss = 0 # 记录下整个epoch的loss的总和
epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量
epoch_total_num = 0 # 每个epoch中,预测的word的总数量
for batch_idx, (input_ids, labels) in enumerate(train_dataloader):
# 捕获cuda out of memory exception
try:
input_ids = input_ids.to(device)
labels = labels.to(device)
outputs = model.forward(input_ids, labels=labels)
logits = outputs.logits
loss = outputs.loss
loss = loss.mean()
# 统计该batch的预测token的正确数与总数
batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)
# 统计该epoch的预测token的正确数与总数
epoch_correct_num += batch_correct_num
epoch_total_num += batch_total_num
# 计算该batch的accuracy
batch_acc = batch_correct_num / batch_total_num
total_loss += loss.item()
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
# 进行一定step的梯度累计之后,更新参数
if (batch_idx + 1) % args.gradient_accumulation_steps == 0:
# 更新参数
optimizer.step()
# 更新学习率
scheduler.step()
# 清空梯度信息
optimizer.zero_grad()
if (batch_idx + 1) % args.log_step == 0:
logger.info(
"batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(
batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))
del input_ids, outputs
except RuntimeError as exception:
if "out of memory" in str(exception):
logger.info("WARNING: ran out of memory")
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
else:
logger.info(str(exception))
raise exception
# 记录当前epoch的平均loss与accuracy
epoch_mean_loss = total_loss / len(train_dataloader)
epoch_mean_acc = epoch_correct_num / epoch_total_num
logger.info(
"epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))
# save model
logger.info('saving model for epoch {}'.format(epoch + 1))
model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))
if not os.path.exists(model_path):
os.mkdir(model_path)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(model_path)
logger.info('epoch {} finished'.format(epoch + 1))
epoch_finish_time = datetime.now()
logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))
return epoch_mean_loss(3)部署与网页预测展示
app.py既是模型预测文件,又能够在网页中展示,这需要我们下载一个依赖库:
pip install streamlit

生成下一个词流程,每次只根据当前位置的前context_len个token进行生成:
- 第一步,先将输入文本截断成训练的token大小,训练时我们采用的200,截断为后200个词
-
第二步,预测的下一个token的概率,采用温度采样和topk/topp采样
最终,我们不断的以自回归的方式不断生成预测结果
这里指定模型目录

进入项目路径

执行streamlit run app.py
 生成效果:
生成效果:
数据与代码链接:https://pan.baidu.com/s/1XmurJn3k_VI5OR3JsFJgTQ?pwd=x3ci
提取码:x3ci